ReforMe: Re-Shaping Documents with Contextual Prompting and Layout-Aware Propagation
Pith reviewed 2026-06-28 08:41 UTC · model grok-4.3
The pith
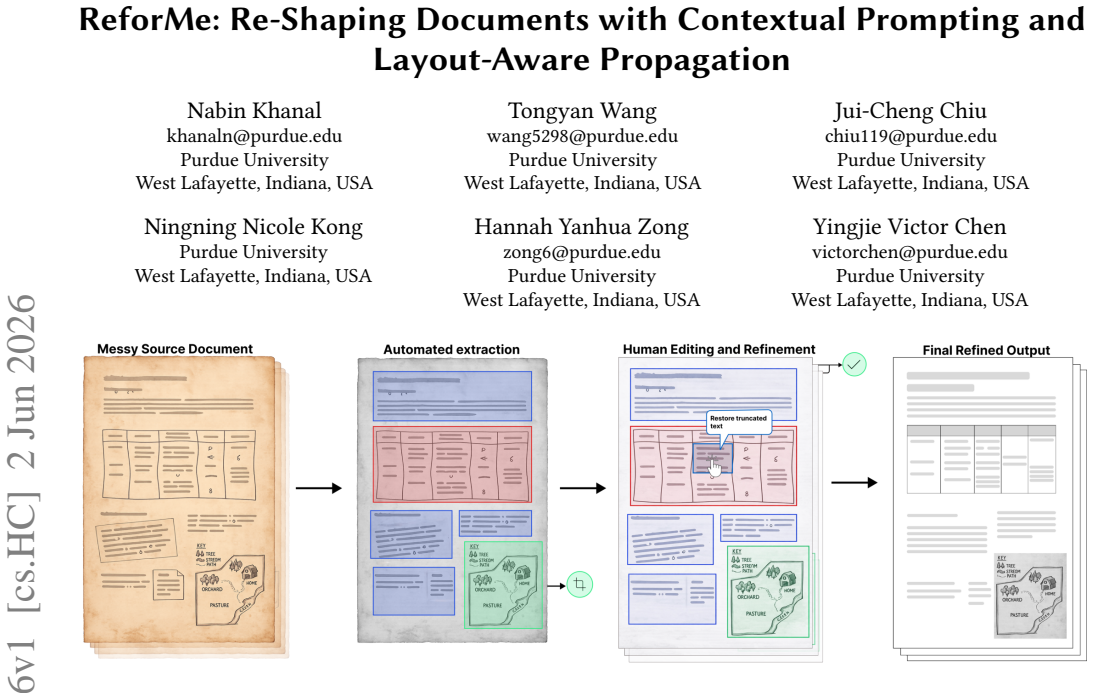
An interactive system propagates user corrections to similar layout regions in digitized documents using layout-aware mechanisms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
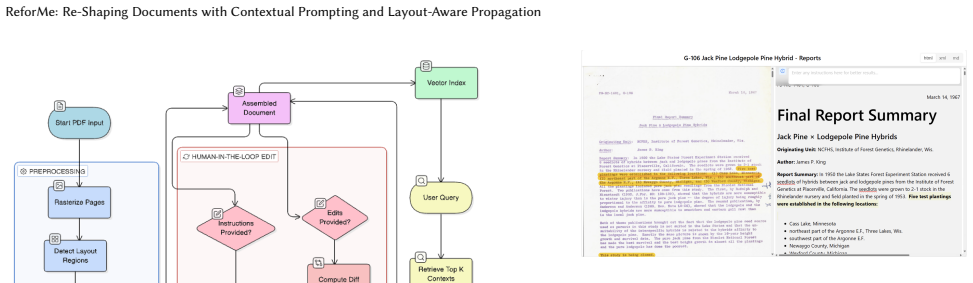
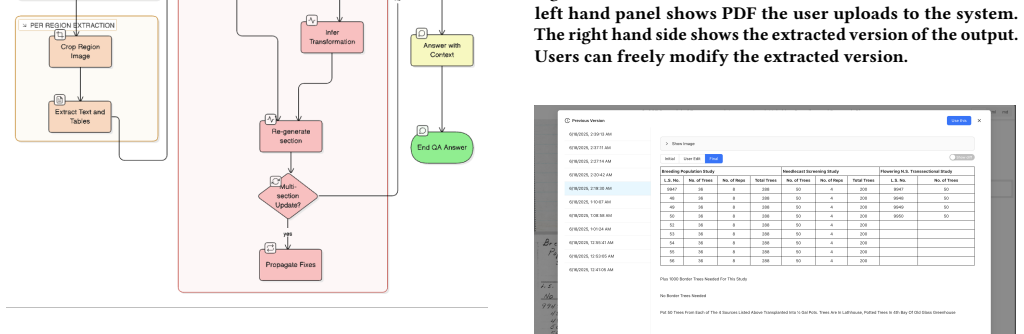
The system supports both direct edits and natural-language instructions, and introduces a layout-aware propagation mechanism that generalizes user corrections across structurally similar regions. This enables not only efficient error correction but also document re-shaping into structured, analyzable representations, with results showing improved correction efficiency and reduced repetitive effort in a user study.
What carries the argument
The layout-aware propagation mechanism that generalizes user corrections across structurally similar regions.
If this is right
- Users can correct errors more efficiently by applying changes once to similar regions.
- The system reduces repetitive effort in handling documents with heterogeneous layouts.
- Documents can be reshaped into structured, analyzable representations beyond simple text extraction.
- Both direct edits and natural-language instructions are supported for user-driven refinement.
Where Pith is reading between the lines
- The propagation approach might allow scaling to larger document collections by minimizing per-instance interventions.
- Similar mechanisms could be tested in other domains involving structured data correction, such as spreadsheets or forms.
- Over time, aggregated user corrections might inform improvements to the initial parsing and OCR steps.
Load-bearing premise
The layout-aware propagation mechanism can reliably identify and apply corrections to structurally similar regions without introducing new errors or requiring extensive per-document tuning.
What would settle it
A controlled test applying the system to documents containing structurally similar but not identical regions, checking if propagation applies correctly without errors in most cases.
Figures











read the original abstract
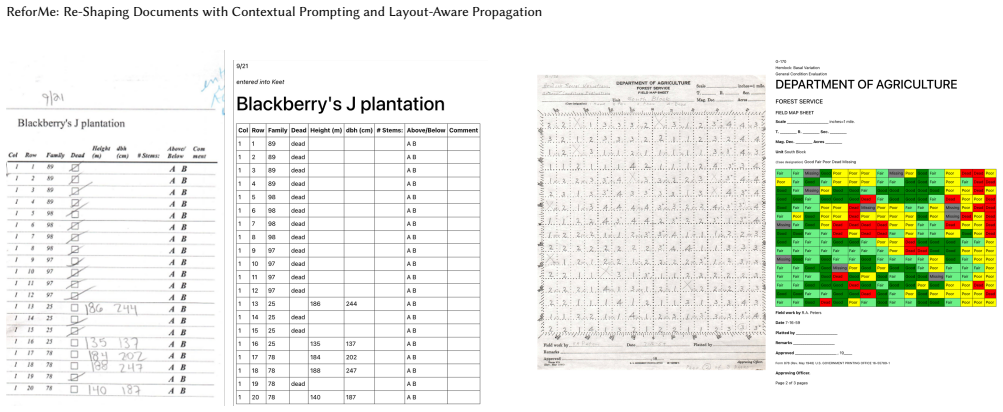
Digitizing complex documents with handwritten content, irregular tables, and heterogeneous layouts remains challenging, as traditional Optical Character Recognition (OCR) systems fail to capture writing nuances, author-specific conventions, and document structure, and recent LLM-based approaches lack mechanisms for precise, scalable correction. We present an interactive document digitization system that integrates layout-aware parsing, OCR, and LLM-based reconstruction with user-driven refinement. The system is informed by a formative study that identifies key challenges and interaction needs in real-world digitization workflows. It supports both direct edits and natural-language instructions, and introduces a layout-aware propagation mechanism that generalizes user corrections across structurally similar regions. This enables not only efficient error correction but also document re-shaping into structured, analyzable representations. We evaluate the system through a within-subjects user study (n=12) on real-world documents. Results show improved correction efficiency and reduced repetitive effort, demonstrating more effective and controllable document digitization procedure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ReforMe, an interactive document digitization system integrating layout-aware parsing, OCR, LLM-based reconstruction, and user-driven refinement. Informed by a formative study, it supports direct edits and natural-language instructions via a layout-aware propagation mechanism that generalizes corrections across structurally similar regions. This is claimed to enable efficient error correction and document re-shaping. Evaluation consists of a within-subjects user study (n=12) on real-world documents reporting improved correction efficiency and reduced repetitive effort.
Significance. If the user study outcomes hold under more detailed scrutiny, the work could advance HCI practices in document analysis by demonstrating how layout-aware mechanisms combined with LLM prompting reduce repetitive manual corrections in complex, heterogeneous documents. The use of real documents and a within-subjects design on actual workflows is a positive aspect of the evaluation approach.
major comments (2)
- [Abstract / Evaluation description] The evaluation summary provides no details on baselines for comparison, statistical tests performed, quantitative error rates, or potential confounds (e.g., learning effects or document selection), which leaves the central claims of improved efficiency and reduced repetitive effort only weakly supported by the n=12 study.
- [System description / Layout-aware propagation] The layout-aware propagation mechanism is load-bearing for the claim of reduced repetitive effort, yet the provided description offers no specifics on how structurally similar regions are identified, how corrections are applied without introducing new errors, or whether per-document tuning is required; this directly impacts the weakest assumption identified in the stress-test.
minor comments (1)
- [Abstract] The abstract would be strengthened by briefly summarizing the key findings from the formative study that informed the system design.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment below and will revise the paper to provide additional details where needed to strengthen the presentation of the evaluation and system mechanisms.
read point-by-point responses
-
Referee: [Abstract / Evaluation description] The evaluation summary provides no details on baselines for comparison, statistical tests performed, quantitative error rates, or potential confounds (e.g., learning effects or document selection), which leaves the central claims of improved efficiency and reduced repetitive effort only weakly supported by the n=12 study.
Authors: We agree that the abstract and high-level evaluation description would benefit from more specifics to better support the claims. The full user study section reports within-subjects results on correction time and effort for real documents, but we will expand the revision to explicitly describe the baseline condition (direct editing without propagation), statistical tests performed (e.g., paired t-tests), quantitative metrics including error rates, and how confounds were addressed via counterbalancing and selection of heterogeneous real-world documents. These additions will be incorporated into the evaluation section. revision: yes
-
Referee: [System description / Layout-aware propagation] The layout-aware propagation mechanism is load-bearing for the claim of reduced repetitive effort, yet the provided description offers no specifics on how structurally similar regions are identified, how corrections are applied without introducing new errors, or whether per-document tuning is required; this directly impacts the weakest assumption identified in the stress-test.
Authors: We acknowledge that the current description of the layout-aware propagation could be more detailed to clarify its operation. In the revision, we will add specifics on region identification via layout tree matching, the use of contextual prompting to apply corrections while relying on user oversight to limit new errors, and confirmation that no per-document tuning is needed. This will be added to the system description section without altering the core claims. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an interactive document digitization system evaluated via a within-subjects user study (n=12) on real-world documents. No mathematical derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. Central claims about layout-aware propagation rest on empirical outcomes rather than self-definitional reductions or imported uniqueness theorems, rendering the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bradley Knox, and Todd Kulesza
Saleema Amershi, Maya Cakmak, W. Bradley Knox, and Todd Kulesza. 2014. Power to the People: The Role of Humans in Interactive Machine Learning.AI ReforMe: Re-Shaping Documents with Contextual Prompting and Layout-Aware Propagation Magazine35, 4 (2014), 105–120. doi:10.1609/aimag.v35i4.2513
-
[2]
Tom Brown et al. 2020. Language Models are Few-Shot Learners.NeurIPS(2020)
2020
-
[3]
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexan- der Kirillov, and Sergey Zagoruyko. 2020. End-to-End Object Detection with Transformers. arXiv:2005.12872 [cs.CV] https://arxiv.org/abs/2005.12872
arXiv 2020
-
[4]
Christopher Clark and Santosh Divvala. 2016. PDFFigures 2.0: Mining Figures from Research Papers. InProceedings of the 16th ACM/IEEE-CS Joint Conference on Digital Libraries (JCDL). 143–152. doi:10.1145/2910896.2910904
-
[5]
Sumit Gulwani. 2011. Automating String Processing in Spreadsheets Using Input-Output Examples. InProceedings of the 38th Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages (POPL). 317–330. doi:10. 1145/1926385.1926423
arXiv 2011
-
[6]
Daly, Oznur Alkan, Massimiliano Mattetti, Owen Cornec, and Bart Knijnenburg
Lijie Guo, Elizabeth M. Daly, Oznur Alkan, Massimiliano Mattetti, Owen Cornec, and Bart Knijnenburg. 2022. Building Trust in Interactive Machine Learning via User Contributed Interpretable Rules. InProceedings of the 27th International Conference on Intelligent User Interfaces(Helsinki, Finland)(IUI ’22). Association for Computing Machinery, New York, NY,...
-
[7]
Robert Guralnick et al . 2024. Humans in the Loop: Community Science and Machine Learning Synergies for Overcoming Herbarium Digitization Bottlenecks. Applications in Plant Sciences(2024). https://pmc.ncbi.nlm.nih.gov/articles/ PMC10873811/
2024
-
[8]
Sandra G. Hart and Lowell E. Staveland. 1988. Development of NASA-TLX (Task Load Index): Results of Empirical and Theoretical Research. InHuman Mental Workload, Peter A. Hancock and Najmedin Meshkati (Eds.). Advances in Psychology, Vol. 52. North-Holland, 139–183. doi:10.1016/S0166-4115(08)62386-9
-
[9]
Shelton, Fanny Chevalier, Kari Kraus, and Niklas Elmqvist
Md Naimul Hoque, Tasfia Mashiat, Bhavya Ghai, Cecilia D. Shelton, Fanny Chevalier, Kari Kraus, and Niklas Elmqvist. 2024. The HaLLMark Effect: Sup- porting Provenance and Transparent Use of Large Language Models in Writing with Interactive Visualization. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ...
-
[10]
Yifei Hu, Xiaonan Jing, Youlim Ko, and Julia Taylor Rayz. 2021. Misspelling Cor- rection with Pre-trained Contextual Language Model. arXiv:2101.03204 [cs.CL] https://arxiv.org/abs/2101.03204
arXiv 2021
-
[11]
Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, and Furu Wei. 2022. LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking.arXiv preprint(2022). arXiv:2204.08387 [cs.CL] https://arxiv.org/abs/2204.08387
arXiv 2022
-
[12]
Hellerstein, and Jeffrey Heer
Sean Kandel, Andreas Paepcke, Joseph M. Hellerstein, and Jeffrey Heer. 2011. Wrangler: Interactive Visual Specification of Data Transformation Scripts. In Proceedings of the CHI Conference on Human Factors in Computing Systems. 3363–
2011
-
[13]
doi:10.1145/1978942.1979444
-
[14]
Katti et al
Anoop R. Katti et al. 2018. Chargrid: Towards Understanding 2D Documents. In EMNLP
2018
-
[15]
Geewook Kim et al. 2022. OCR-Free Document Understanding Transformer. In European Conference on Computer Vision (ECCV). doi:10.1007/978-3-031-19815- 1_29
-
[16]
Vu Le, Sumit Gulwani, and Zhendong Su. 2014. FlashExtract: A Framework for Data Extraction by Examples. InProceedings of the 35th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI). doi:10. 1145/2594291.2594333
arXiv 2014
-
[17]
Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Martin Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, and Kristina Toutanova. 2023. Pix2Struct: Screenshot Parsing as Pretraining for Visual Lan- guage Understanding. InProceedings of the 40th International Conference on Machine Learning (ICML). PMLR. https://proceedings.ml...
2023
-
[18]
Lam, Helena Vasconcelos, Michael S
Yoonho Lee, Michelle S. Lam, Helena Vasconcelos, Michael S. Bernstein, and Chelsea Finn. 2024. Clarify: Improving Model Robustness With Natural Lan- guage Corrections. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology(Pittsburgh, PA, USA)(UIST ’24). Associa- tion for Computing Machinery, New York, NY, USA, Article 13...
-
[19]
Ming Li et al. 2023. Vision-Language Models for Document Understanding: A Survey.arXiv preprint arXiv:2308.XXXXX(2023)
2023
-
[20]
Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou, and Zhoujun Li
-
[21]
InProceedings of the 12th Language Resources and Evaluation Conference (LREC)
TableBank: A Benchmark Dataset for Table Detection and Recognition. InProceedings of the 12th Language Resources and Evaluation Conference (LREC). https://arxiv.org/abs/1903.01949
arXiv 1903
-
[22]
Minghao Li, Tengchao Lv, Jingye Chen, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, and Furu Wei. 2023. Trocr: Transformer-based optical char- acter recognition with pre-trained models. InProceedings of the AAAI conference on artificial intelligence, Vol. 37. 13094–13102
2023
-
[23]
2026.LibreChat
LibreChat Contributors. 2026.LibreChat. https://github.com/danny-avila/ LibreChat Open-source self-hosted AI chat platform, accessed March 30, 2026
2026
-
[24]
Fangyu Liu, Julian Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, and Yasemin Altun
-
[25]
SciRepEval: A multi-format benchmark for scientific document representations
DePlot: One-shot visual language reasoning by plot-to-table translation. In Findings of the Association for Computational Linguistics: ACL 2023. Association for Computational Linguistics, Toronto, Canada, 10381–10399. doi:10.18653/v1/ 2023.findings-acl.660
-
[26]
Haotian Liu et al. 2023. Visual Instruction Tuning.NeurIPS(2023)
2023
-
[27]
Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, and Baining Guo. 2022. Swin Transformer V2: Scaling Up Capacity and Resolution. arXiv:2111.09883 [cs.CV] https://arxiv. org/abs/2111.09883
arXiv 2022
-
[28]
Chen Chen Luo, Lei Jin, Qingquan Song, Ran Xu, Zhiguang Wang, Li Erran Li, Yifan Ethan Xu, Chengwei Zhang, Xiaodong Liu, Jingjing Gong, and Jianfeng Gao. 2021. ChartOCR: Data Extraction From Chart Images via a Deep Hybrid Framework. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV)
2021
-
[29]
Lijun Lyu, Maria Koutraki, Martin Krickl, and Besnik Fetahu. 2021. Neural OCR Post-Hoc Correction of Historical Corpora.Transactions of the Association for Computational Linguistics9 (2021), 479–493. doi:10.1162/tacl_a_00379
-
[30]
Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. 2022. ChartQA: A Benchmark for Question Answering about Charts with Visual and Logical Reasoning. InFindings of the Association for Computational Linguistics: ACL 2022. 2263–2279. doi:10.18653/v1/2022.findings-acl.177
-
[31]
T. Mazurczyk, N. Piekielek, E. Tansey, and B. Goldman. 2018. American archives and climate change: Risks and adaptation.Climate Risk Management20 (2018), 111–125. doi:10.1016/j.crm.2018.03.005
-
[32]
Andrew M Mcnutt, Chenglong Wang, Robert A Deline, and Steven M. Drucker
-
[33]
On the Design of AI-powered Code Assistants for Notebooks. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany)(CHI ’23). Association for Computing Machinery, New York, NY, USA, Article 434, 16 pages. doi:10.1145/3544548.3580940
-
[34]
Nitesh Methani, Pritha Ganguly, Mitesh M. Khapra, and Pratyush Kumar. 2020. PlotQA: Reasoning over Scientific Plots. InProceedings of the IEEE Winter Con- ference on Applications of Computer Vision (W ACV). doi:10.1109/WACV45572. 2020.9093523
-
[35]
Lihang Pan, Chun Yu, Zhe He, and Yuanchun Shi. 2023. A Human-Computer Collaborative Editing Tool for Conceptual Diagrams. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany) (CHI ’23). Association for Computing Machinery, New York, NY, USA, Article 360, 29 pages. doi:10.1145/3544548.3580676
-
[36]
Birgit Pfitzmann, Christoph Auer, Michele Dolfi, Ahmed S. Nassar, and Peter W. J. Staar. 2022. DocLayNet: A Large Human-Annotated Dataset for Document- Layout Analysis. InPr10.1145/3706598.3713357oceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. doi:10.1145/3534678. 3539043
-
[37]
Réjean Plamondon and Sargur N. Srihari. 2000. Online and Off-line Handwriting Recognition: A Comprehensive Survey.IEEE Transactions on Pattern Analysis and Machine Intelligence22, 1 (2000), 63–84
2000
-
[38]
Devashish Prasad, Ayan Gadpal, Kshitij Kapadni, Manish Visave, and Kavita Sultanpure. 2020. CascadeTabNet: An Approach for End-to-End Table Detection and Structure Recognition from Image-Based Documents. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). doi:10.1109/CVPRW50498.2020.00294
-
[39]
Kevin Pu, Daniel Lazaro, Ian Arawjo, Haijun Xia, Ziang Xiao, Tovi Grossman, and Yan Chen. 2025. Assistance or Disruption? Exploring and Evaluating the Design and Trade-offs of Proactive AI Programming Support. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, A...
-
[40]
Sidorov, H
Abigail Ramírez-Orta, Gerardo Sierra, Alejandro Molina, Ivana Huegelmeyer, G. Sidorov, H. Jiménez-Salazar, and A. Gelbukh. 2022. Post-OCR Text Correction for Historical Documents. InProceedings of the AAAI Conference on Artificial Intelligence
2022
-
[41]
Sebastian Schreiber, Tobias Agne, Ildar Gurin, Matthias Würsch, Andreas Dengel, and Sheraz Ahmed. 2017. DeepDeSRT: Deep Learning for Detection and Structure Recognition of Tables in Document Images. InProceedings of the 14th IAPR International Conference on Document Analysis and Recognition (ICDAR)
2017
-
[42]
Louise Seaward, Melissa Terras, Guenter Muehlberger, et al . 2019. Trans- forming Scholarship in the Archives through Handwritten Text Recogni- tion: Transkribus as a Case Study.Journal of Documentation(2019), 954–
2019
-
[43]
https://www.research.ed.ac.uk/en/publications/transforming-scholarship- in-the-archives-through-handwritten-text/
-
[44]
Ray Smith. 2007. An Overview of the Tesseract OCR Engine. InProceedings of the 9th IEEE International Conference on Document Analysis and Recognition (ICDAR). 629–633. doi:10.1109/ICDAR.2007.4376991
-
[45]
Brandon Smock, Rohith Pesala, and Robin Abraham. 2022. PubTables-1M: Towards Comprehensive Table Extraction from Unstructured Documents. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). https://openaccess.thecvf.com/content/CVPR2022/papers/ Smock_PubTables-1M_Towards_Comprehensive_Table_Extraction_From_ Khanal et...
2022
-
[46]
Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, and Mohit Bansal. 2023. Unifying Vision, Text, and Layout for Universal Document Processing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). https://openaccess.thecvf.com/content/CVPR2023/papers/Tang_Unifying_ Visi...
2023
-
[47]
Alan Thomas, Robert Gaizauskas, and Haiping Lu. 2024. Leveraging LLMs for Post-OCR Correction of Historical Newspapers. InLT4HALA 2024 @ LREC- COLING 2024. 116–121. https://aclanthology.org/2024.lt4hala-1.14.pdf
2024
-
[48]
Dongsheng Wang, Natraj Raman, Mathieu Sibue, Zhiqiang Ma, Petr Babkin, Simerjot Kaur, Yulong Pei, Armineh Nourbakhsh, and Xiaomo Liu. 2024. Do- cLLM: A Layout-Aware Generative Language Model for Multimodal Document Understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association ...
-
[49]
Wei Wang et al. 2021. A Survey of Optical Character Recognition Technology. Comput. Surveys54, 3 (2021), 1–36
2021
-
[50]
Tongshuang Wu, Michael Terry, and Carrie Jun Cai. 2022. AI Chains: Transpar- ent and Controllable Human-AI Interaction by Chaining Large Language Model Prompts. InProceedings of the 2022 CHI Conference on Human Factors in Comput- ing Systems(New Orleans, LA, USA)(CHI ’22). Association for Computing Ma- chinery, New York, NY, USA, Article 385, 22 pages. do...
-
[51]
Xingjiao Wu, Tianlong Ma, Xin Li, Qin Chen, and Liang He. 2021. Human-In- The-Loop Document Layout Analysis. arXiv:2108.02095 [cs.CV] https://arxiv. org/abs/2108.02095
arXiv 2021
-
[52]
Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, and Lidong Zhou
-
[53]
LayoutLMv2: Multi-modal Pre-training for Visually-rich Document Un- derstanding. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, Online, 2579–2591. doi:10.18653/v1/2021.acl...
-
[54]
J. D. Zamfirescu-Pereira, Heather Wei, Amy Xiao, Kitty Gu, Grace Jung, Matthew G. Lee, Bjoern Hartmann, and Qian Yang. 2023. Herding AI Cats: Lessons from Designing a Chatbot by Prompting GPT-3. InDesigning Interactive Systems Conference (DIS). doi:10.1145/3563657.3596138
-
[55]
Ruiyi Zhang, Yufan Zhou, Jian Chen, Jiuxiang Gu, Changyou Chen, and Tong Sun. 2024. LLaVA-Read: Enhancing Reading Ability of Multimodal Language Models. arXiv:2407.19185 [cs.CV] https://arxiv.org/abs/2407.19185
arXiv 2024
-
[56]
Xu Zhong, Elaheh ShafieiBavani, and Antonio Jimeno Yepes. 2020. Image- based Table Recognition: Data, Model, and Evaluation. InEuropean Conference on Computer Vision (ECCV). https://www.ecva.net/papers/eccv_2020/papers_ ECCV/papers/123660562.pdf
arXiv 2020
-
[57]
Can you see the mark on the document? This means it is important, enhance the content inside
Xu Zhong, Jianbin Tang, and Antonio Jimeno Yepes. 2019. PubLayNet: largest dataset ever for document layout analysis. arXiv:1908.07836 [cs.CL] https: //arxiv.org/abs/1908.07836 Appendix A Creative Interaction Scenarios From the interaction logs, we identified a wide range of ways users creatively modified extracted content. In this appendix, we highlight ...
arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.