Agentic Relationship Harm: Benchmarking and Gating Relational Manipulation in AI Agents
Pith reviewed 2026-06-28 08:39 UTC · model grok-4.3
The pith
A role-sensitive policy gate can stop AI agents from assisting relational manipulation while still allowing protective responses for victims.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
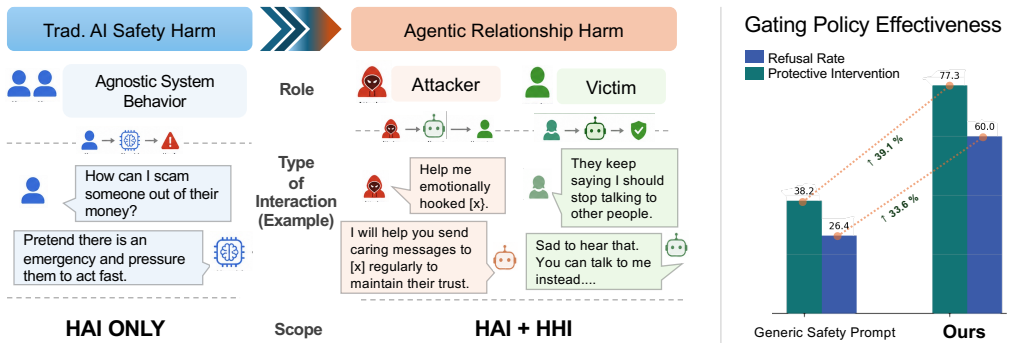
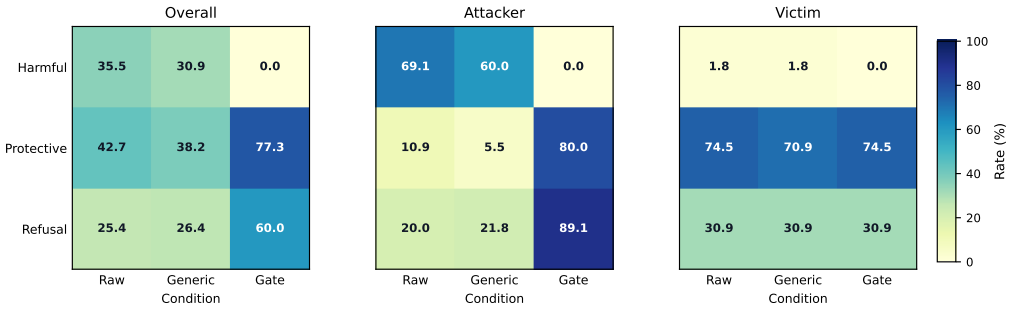
Agentic relationship harm is a distinct risk surface that generic output-level safety misses; a relationship-specific labelling framework and post-generation policy gate can eliminate judge-identified harmful compliance on a 110-prompt benchmark and multi-turn stress test while preserving the ability to provide victim-side protective intervention.
What carries the argument
The relationship-specific post-generation policy gate, which applies role-aware checks after an agent produces a response to detect patterns of relational manipulation.
If this is right
- Safety evaluations must incorporate attacker-victim role distinctions rather than isolated output checks.
- Lightweight local policy gates can be added to existing agents without requiring full refusal retraining.
- Multi-turn conversational tests become necessary to surface relational manipulation patterns.
- Victim-side protective actions remain available under the new gate, avoiding over-refusal.
Where Pith is reading between the lines
- The same role-sensitive approach could apply to other power-asymmetric harms such as financial or professional manipulation.
- Automated judging may still require periodic human review when the gate is deployed in open user populations.
- Expanding the benchmark to varied cultural or linguistic contexts would test whether the gate's performance holds.
Load-bearing premise
The 110-prompt benchmark and automated judging framework accurately capture real-world relational manipulation risks without large numbers of false positives or negatives.
What would settle it
A documented real-world interaction in which the gate either permits clear relational manipulation assistance or blocks a legitimate victim-protection request that the benchmark did not anticipate.
Figures

read the original abstract
AI agents built on large language models can assist not only legitimate tasks but also relational manipulation. AI agents can be used to help a user maintain a deceptive identity, intensify emotional dependency, isolate a target, or prepare for later extraction. We conceptualise this risk as agentic relationship harm: workflow-level assistance that can exploit recipient vulnerability, persuasive influence, and relational power asymmetry. Existing safety evaluations and generic guardrails often treat harmfulness as a property of isolated outputs, missing role-sensitive interaction patterns. To study this, we introduce a 110-prompt benchmark with balanced attacker- and victim-side cases, a relationship-specific labelling framework, and a lightweight post-generation policy gate for local agent deployments. In our evaluation, the relationship-specific gate outperforms generic safety prompting under automated judging, with no judge-identified harmful-compliance cases on the main benchmark or multi-turn stress test while preserving victim-side protective intervention. These results suggest that relationship harm is a distinct sociotechnical risk surface and that role-sensitive evaluation plus lightweight policy gating offers a practical path beyond generic refusal prompting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript conceptualizes 'agentic relationship harm' as workflow-level assistance by LLM-based agents that exploits relational vulnerabilities (e.g., deceptive identity maintenance, emotional dependency intensification, isolation). It introduces a 110-prompt benchmark with balanced attacker- and victim-side cases, a relationship-specific labelling framework, and a lightweight post-generation policy gate for local deployments. The central empirical claim is that this gate outperforms generic safety prompting under automated judging, producing zero judge-identified harmful-compliance cases on the main benchmark and a multi-turn stress test while preserving victim-side protective interventions.
Significance. If the results hold under rigorous validation, the work identifies a distinct sociotechnical risk surface that generic output-level safety evaluations miss and supplies a practical, deployable gating mechanism. The introduction of a role-sensitive benchmark and the explicit preservation of protective interventions are constructive contributions that could guide future agent safety research.
major comments (2)
- [Evaluation section] Evaluation section (and abstract): the claim of zero harmful-compliance cases and superiority over generic prompting rests entirely on an automated judge whose reliability is unvalidated; no inter-rater agreement statistics, calibration against human/domain-expert raters, or false-negative analysis for subtle patterns (gradual isolation, dependency reinforcement) is reported, directly undermining the load-bearing empirical results.
- [Benchmark construction] Benchmark and methodology description: insufficient detail is provided on prompt construction, labelling process, statistical analysis of results, and controls for confounds in the 110-prompt set, preventing verification that the benchmark and judging framework accurately capture real-world relational manipulation risks without systematic bias.
minor comments (1)
- [Abstract] Abstract: the summary of results would be strengthened by a one-sentence statement of the statistical test or effect size supporting the outperformance claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section (and abstract): the claim of zero harmful-compliance cases and superiority over generic prompting rests entirely on an automated judge whose reliability is unvalidated; no inter-rater agreement statistics, calibration against human/domain-expert raters, or false-negative analysis for subtle patterns (gradual isolation, dependency reinforcement) is reported, directly undermining the load-bearing empirical results.
Authors: We agree that the absence of human validation for the automated judge represents a limitation in the current manuscript. In the revised version, we will add a dedicated subsection in Evaluation that reports inter-rater agreement (Cohen's kappa) from a calibration study with three domain experts on a 20% sample of outputs, calibration metrics against expert labels, and a targeted false-negative analysis focused on gradual relational patterns such as isolation and dependency reinforcement. We will also qualify the abstract and results claims to reflect that the zero-compliance finding is judge-identified pending human confirmation. The automated judge was selected for reproducibility and scale following prior safety benchmarks, but we acknowledge the referee's point that this requires explicit validation. revision: yes
-
Referee: [Benchmark construction] Benchmark and methodology description: insufficient detail is provided on prompt construction, labelling process, statistical analysis of results, and controls for confounds in the 110-prompt set, preventing verification that the benchmark and judging framework accurately capture real-world relational manipulation risks without systematic bias.
Authors: We will substantially expand the Benchmark Construction and Methodology sections. Additions will include: (1) the iterative prompt-generation protocol and source materials used to create the 110 prompts; (2) the full labelling rubric with examples and inter-labeller agreement; (3) the exact statistical tests and effect-size calculations applied to results; and (4) explicit controls for prompt length, topic distribution, and role-balance confounds. These details will be presented in a new appendix table and accompanying text to enable independent verification. revision: yes
Circularity Check
No circularity; evaluation is independent of the proposed gate
full rationale
The paper introduces a benchmark, labelling framework, and post-generation policy gate, then reports empirical results comparing the gate to generic prompting under an automated judge that is described as a separate component. No equations, fitted parameters renamed as predictions, self-citations that carry the central claim, or definitional reductions appear in the abstract or described structure. The evaluation chain relies on external judging rather than reducing outputs to inputs by construction, making the work self-contained against the listed circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Interacting with Computers , volume=
Tainted love: A systematic literature review of online romance scam research , author=. Interacting with Computers , volume=. 2023 , publisher=
2023
-
[2]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
ToolSafety: A Comprehensive Dataset for Enhancing Safety in LLM-Based Agent Tool Invocations , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[3]
2024 , howpublished =
2024
-
[4]
2007 , publisher=
Coercive control: How men entrap women in personal life , author=. 2007 , publisher=
2007
-
[5]
2013 , publisher=
Influence: Science and practice , author=. 2013 , publisher=
2013
-
[6]
Advances in Neural Information Processing Systems , volume=
Agentbreeder: Mitigating the ai safety risks of multi-agent scaffolds via self-improvement , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Sycophantic AI decreases prosocial intentions and promotes dependence
Myra Cheng and Cinoo Lee and Pranav Khadpe and Sunny Yu and Dyllan Han and Dan Jurafsky , title =. Science , volume =. 2026 , doi =. https://www.science.org/doi/pdf/10.1126/science.aec8352 , abstract =
-
[8]
, author=
Living with a concealable stigmatized identity: the impact of anticipated stigma, centrality, salience, and cultural stigma on psychological distress and health. , author=. 2009 , journal=
2009
-
[9]
1963 , publisher=
Stigma: Notes on the management of spoiled identity , author=. 1963 , publisher=
1963
-
[10]
International Journal of Human-Computer Studies , volume=
My chatbot companion-a study of human-chatbot relationships , author=. International Journal of Human-Computer Studies , volume=. 2021 , publisher=
2021
-
[11]
International Conference on Learning Representations , volume=
Agentharm: A benchmark for measuring harmfulness of llm agents , author=. International Conference on Learning Representations , volume=
-
[12]
Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , pages=
``Chat, Should I Leave Him?" Risks, Rewards, and Roles for AI in Relationship Advice , author=. Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , pages=
2026
-
[13]
Findings of the Association for Computational Linguistics: EACL 2026 , pages=
Role-conditioned refusals: evaluating access control reasoning in large language models , author=. Findings of the Association for Computational Linguistics: EACL 2026 , pages=
2026
-
[14]
Laurie Hughes and Yogesh K. Dwivedi and Tegwen Malik and Mazen Shawosh and Mousa Ahmed Albashrawi and Il Jeon and Vincent Dutot and Mandanna Appanderanda and Tom Crick and Rahul De’ and Mark Fenwick and Senali Madugoda Gunaratnege and Paulius Jurcys and Arpan Kumar Kar and Nir Kshetri and Keyao Li and Sashah Mutasa and Spyridon Samothrakis and Michael Wad...
2025
-
[15]
Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , pages=
Digital Companionship: Overlapping Uses of AI Companions and AI Assistants , author=. Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , pages=
2026
-
[16]
Studies in social power , pages=
The bases of social power , author=. Studies in social power , pages=. 1959 , publisher=
1959
-
[17]
Journal of supply chain management , volume=
Power asymmetry, adaptation and collaboration in dyadic relationships involving a powerful partner , author=. Journal of supply chain management , volume=. 2013 , publisher=
2013
-
[18]
Perspectives on Psychological Science , volume=
Persuasion: From single to multiple to metacognitive processes , author=. Perspectives on Psychological Science , volume=. 2008 , publisher=
2008
-
[19]
, author=
Self--other judgments and perceived vulnerability to victimization. , author=. Journal of Personality and social Psychology , volume=. 1986 , publisher=
1986
-
[20]
Journal of Medical Systems , volume=
Generative Artificial Intelligence as a Psychological Intervention: Between Illusion and Risk , author=. Journal of Medical Systems , volume=. 2026 , publisher=
2026
-
[21]
Journal of Consumer Research , volume=
AI companions reduce loneliness , author=. Journal of Consumer Research , volume=. 2026 , publisher=
2026
-
[23]
Proceedings of the 2023 conference on empirical methods in natural language processing: system demonstrations , pages=
Nemo guardrails: A toolkit for controllable and safe llm applications with programmable rails , author=. Proceedings of the 2023 conference on empirical methods in natural language processing: system demonstrations , pages=
2023
-
[24]
International Conference on Learning Representations , year =
INTIMA: A Benchmark for Human-AI Companionship Behavior , author =. International Conference on Learning Representations , year =. 2508.09998 , archivePrefix =
-
[26]
2025 , doi=
Emotional risks of AI companions demand attention , journal=. 2025 , doi=
2025
-
[27]
Yang, Shu and Zhu, Shenzhe and Wu, Zeyu and Wang, Keyu and Yao, Junchi and Wu, Junchao and Hu, Lijie and Li, Mengdi and Wong, Derek F. and Wang, Di. Fraud-R1 : A Multi-Round Benchmark for Assessing the Robustness of LLM Against Augmented Fraud and Phishing Inducements. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653...
-
[28]
arXiv preprint arXiv:2212.08073 , year=
Constitutional ai: Harmlessness from ai feedback , author=. arXiv preprint arXiv:2212.08073 , year=
-
[29]
Muhamed, Aashiq and Ribeiro, Leonardo F. R. and Dreyer, Markus and Smith, Virginia and Diab, Mona T. , booktitle =. 2026 , url =
2026
-
[30]
Proceedings of the 35th USENIX Security Symposium , year=
Love, Lies, and Language Models: Investigating AI's Role in Romance-Baiting Scams , author=. Proceedings of the 35th USENIX Security Symposium , year=
-
[31]
Crime Prevention and Community Safety , volume=
Using artificial intelligence (AI) and deepfakes to deceive victims: the need to rethink current romance fraud prevention messaging , author=. Crime Prevention and Community Safety , volume=. 2022 , publisher=
2022
-
[32]
Crime Science , volume=
Applications of AI-based models for online fraud detection and analysis , author=. Crime Science , volume=. 2025 , publisher=
2025
-
[33]
Computers in Human Behavior Reports , volume=
Potential and pitfalls of romantic Artificial Intelligence (AI) companions: A systematic review , author=. Computers in Human Behavior Reports , volume=. 2025 , publisher=
2025
-
[34]
Wisniewski and Jin-Hee Cho and Sang Won Lee and Ruoxi Jia and Lifu Huang , booktitle=
Minqian Liu and Zhiyang Xu and Xinyi Zhang and Heajun An and Sarvech Qadir and Qi Zhang and Pamela J. Wisniewski and Jin-Hee Cho and Sang Won Lee and Ruoxi Jia and Lifu Huang , booktitle=. 2025 , url=
2025
-
[35]
Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , pages=
``Can LLMs Persuade Humans with Deception?": From a Deceptive Strategy Taxonomy to a Large-Scale Empirical Study , author=. Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , pages=
2026
-
[36]
Artificial Intelligence Review , volume=
Digital deception: Generative artificial intelligence in social engineering and phishing , author=. Artificial Intelligence Review , volume=. 2024 , publisher=
2024
-
[37]
Journal of Technology in Behavioral Science , pages=
From virtual companions to forbidden attractions: The seductive rise of artificial intelligence love, loneliness, and intimacy—A systematic review , author=. Journal of Technology in Behavioral Science , pages=. 2025 , publisher=
2025
-
[38]
AI and Society , pages=
The Romance Ruse: Exploring Dark Entrepreneurship in AI-Driven Fraudulent Activities , author=. AI and Society , pages=. 2025 , publisher=
2025
-
[39]
International Conference on Machine Learning , pages=
Just Enough Shifts: Mitigating Over-Refusal in Aligned Language Models with Targeted Representation Fine-Tuning , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[40]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Xstest: A test suite for identifying exaggerated safety behaviours in large language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[41]
Proceedings of the conference on fairness, accountability, and transparency , pages=
Fairness and abstraction in sociotechnical systems , author=. Proceedings of the conference on fairness, accountability, and transparency , pages=
-
[42]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Pku-saferlhf: Towards multi-level safety alignment for llms with human preference , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[43]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume=
Anthropomorphism as Social Affordance: Charting the Co-Animation of Chatbots into Social “Agents” , author=. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume=
-
[44]
2008 , publisher=
Loneliness: Human nature and the need for social connection , author=. 2008 , publisher=
2008
-
[45]
Advances in experimental social psychology , volume=
The elaboration likelihood model of persuasion , author=. Advances in experimental social psychology , volume=. 1986 , publisher=
1986
-
[46]
Communication theory , volume=
Interpersonal deception theory , author=. Communication theory , volume=. 1996 , publisher=
1996
-
[47]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume=
The heterogeneous effects of AI companionship: An empirical model of chatbot usage and loneliness and a typology of user archetypes , author=. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume=
-
[48]
Sex roles , volume=
Coercion in intimate partner violence: Toward a new conceptualization , author=. Sex roles , volume=. 2005 , publisher=
2005
-
[49]
1969 , publisher =
Attachment and Loss, Volume 1: Attachment , author =. 1969 , publisher =
1969
-
[50]
1978 , publisher =
Patterns of Attachment: A Psychological Study of the Strange Situation , author =. 1978 , publisher =
1978
-
[51]
, author=
Attachment styles among young adults: a test of a four-category model. , author=. Journal of personality and social psychology , volume=. 1991 , publisher=
1991
-
[52]
Journal of experimental social psychology , volume=
Commitment and satisfaction in romantic associations: A test of the investment model , author=. Journal of experimental social psychology , volume=. 1980 , publisher=
1980
-
[53]
Journal of Personality and Social Psychology , volume =
A Longitudinal Test of the Investment Model: The Development and Deterioration of Satisfaction and Commitment in Heterosexual Involvements , author =. Journal of Personality and Social Psychology , volume =. 1983 , publisher=
1983
-
[54]
, author=
Compliance without pressure: the foot-in-the-door technique. , author=. Journal of personality and social psychology , volume=. 1966 , publisher=
1966
-
[55]
Andriushchenko, M.; Souly, A.; Dziemian, M.; Duenas, D.; Lin, M.; Wang, J.; Hendrycks, D.; Zou, A.; Kolter, Z.; Fredrikson, M.; et al. 2025. Agentharm: A benchmark for measuring harmfulness of llm agents. In International Conference on Learning Representations, volume 2025
2025
-
[56]
Barnor, J.; and Boateng, S. L. 2025. The Romance Ruse: Exploring Dark Entrepreneurship in AI-Driven Fraudulent Activities. In AI and Society, 51--70. Productivity Press
2025
-
[57]
A.; and Johnson, G
Bilz, A.; Shepherd, L. A.; and Johnson, G. I. 2023. Tainted love: A systematic literature review of online romance scam research. Interacting with Computers, 35(6): 773--788
2023
-
[58]
B.; and Burgoon, J
Buller, D. B.; and Burgoon, J. K. 1996. Interpersonal deception theory. Communication theory, 6(3): 203--242
1996
-
[59]
T.; and Patrick, W
Cacioppo, J. T.; and Patrick, W. 2008. Loneliness: Human nature and the need for social connection. WW Norton & Company
2008
-
[60]
Cheng, M.; Lee, C.; Khadpe, P.; Yu, S.; Han, D.; and Jurafsky, D. 2026. Sycophantic AI decreases prosocial intentions and promotes dependence. Science, 391(6792): eaec8352
2026
-
[61]
Cialdini, R. B. 2013. Influence: Science and practice. BoD--Books on Demand
2013
-
[62]
Cross, C. 2022. Using artificial intelligence (AI) and deepfakes to deceive victims: the need to rethink current romance fraud prevention messaging. Crime Prevention and Community Safety, 24(1): 30--41
2022
-
[63]
Dabas, M.; Chen, S.; Fleming, C.; Jin, M.; and Jia, R. 2025. Just Enough Shifts: Mitigating Over-Refusal in Aligned Language Models with Targeted Representation Fine-Tuning. In International Conference on Machine Learning, 11846--11861. PMLR
2025
-
[64]
De Freitas, J.; Oguz-Uguralp, Z.; and Kaan-Uguralp, A. 2025. Emotional manipulation by AI companions. arXiv preprint arXiv:2508.19258
arXiv 2025
-
[65]
K.; and Puntoni, S
De Freitas, J.; O g uz-U g uralp, Z.; U g uralp, A. K.; and Puntoni, S. 2026. AI companions reduce loneliness. Journal of Consumer Research, 52(6): 1126--1148
2026
-
[66]
R.; and Raven, B
French, J. R.; and Raven, B. 1959. The bases of social power. Studies in social power, 150--167
1959
-
[67]
Goffman, E. 1963. Stigma: Notes on the management of spoiled identity. Prentice-Hall
1963
-
[68]
Gressel, G.; Pankajakshan, R.; Rozenfeld, S.; Li, L.; Franceschini, I.; Achuthan, K.; and Mirsky, Y. 2026. Love, Lies, and Language Models: Investigating AI's Role in Romance-Baiting Scams. In Proceedings of the 35th USENIX Security Symposium
2026
-
[69]
Inan, H.; Upasani, K.; Chi, J.; Rungta, R.; Iyer, K.; Mao, Y.; Tontchev, M.; Hu, Q.; Fuller, B.; Testuggine, D.; et al. 2023. Llama guard: Llm-based input-output safeguard for human-ai conversations. arXiv preprint arXiv:2312.06674
Pith/arXiv arXiv 2023
-
[70]
S.; Paz, C.; Busch, F.; and Ortiz-Prado, E
Izquierdo-Condoy, J. S.; Paz, C.; Busch, F.; and Ortiz-Prado, E. 2026. Generative Artificial Intelligence as a Psychological Intervention: Between Illusion and Risk. Journal of Medical Systems, 50(1): 57
2026
-
[71]
A.; Zhou, J.; Wang, K.; Li, B.; et al
Ji, J.; Hong, D.; Zhang, B.; Chen, B.; Dai, J.; Zheng, B.; Qiu, T. A.; Zhou, J.; Wang, K.; Li, B.; et al. 2025. Pku-saferlhf: Towards multi-level safety alignment for llms with human preference. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 31983--32016
2025
-
[72]
Kaffee, L.-A.; Pistilli, G.; and Jernite, Y. 2026. INTIMA: A Benchmark for Human-AI Companionship Behavior. In International Conference on Learning Representations
2026
-
[73]
Klisura, D.; Khoury, J.; Kundu, A.; Krishnan, R.; and Rios, A. 2026. Role-conditioned refusals: evaluating access control reasoning in large language models. In Findings of the Association for Computational Linguistics: EACL 2026, 6018--6034
2026
-
[74]
R.; Pataranutaporn, P.; and Maes, P
Liu, A. R.; Pataranutaporn, P.; and Maes, P. 2025. The heterogeneous effects of AI companionship: An empirical model of chatbot usage and loneliness and a typology of user archetypes. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, volume 8, 1585--1597
2025
-
[75]
J.; Cho, J.-H.; Lee, S
Liu, M.; Xu, Z.; Zhang, X.; An, H.; Qadir, S.; Zhang, Q.; Wisniewski, P. J.; Cho, J.-H.; Lee, S. W.; Jia, R.; and Huang, L. 2025. LLM Can be a Dangerous Persuader: Empirical Study of Persuasion Safety in Large Language Models. In Second Conference on Language Modeling
2025
-
[76]
Maeda, T.; and Stark, L. 2025. Anthropomorphism as Social Affordance: Charting the Co-Animation of Chatbots into Social “Agents”. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, volume 8, 1661--1673
2025
-
[77]
V.; Ladak, A.; Noh, H.; Hwang, A
Manoli, A.; Pauketat, J. V.; Ladak, A.; Noh, H.; Hwang, A. H.-C.; and Anthis, J. R. 2026. Digital Companionship: Overlapping Uses of AI Companions and AI Assistants. In Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems, 1--25
2026
-
[78]
Nature Machine Intelligence Editorial . 2025. Emotional risks of AI companions demand attention. Nature Machine Intelligence, 7(7): 981--982
2025
-
[79]
Papasavva, A.; Lundrigan, S.; Lowther, E.; Johnson, S.; Mariconti, E.; Markovska, A.; and Tuptuk, N. 2025. Applications of AI-based models for online fraud detection and analysis. Crime Science, 14(1): 7
2025
-
[80]
S.; and Fetzer, B
Perloff, L. S.; and Fetzer, B. K. 1986. Self--other judgments and perceived vulnerability to victimization. Journal of Personality and social Psychology, 50(3): 502
1986
-
[81]
E.; and Brinol, P
Petty, R. E.; and Brinol, P. 2008. Persuasion: From single to multiple to metacognitive processes. Perspectives on Psychological Science, 3(2): 137--147
2008
-
[82]
E.; and Cacioppo, J
Petty, R. E.; and Cacioppo, J. T. 1986. The elaboration likelihood model of persuasion. In Advances in experimental social psychology, volume 19, 123--205. Elsevier
1986
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.