SIGMA: A Versatile Streaming Graph Partitioner for Vertex- and Edge-Balanced Distributed GNN Training
Pith reviewed 2026-06-28 08:24 UTC · model grok-4.3
The pith
A single streaming graph partitioner supports both vertex and edge partitioning for distributed GNN training while enforcing vertex and edge balance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
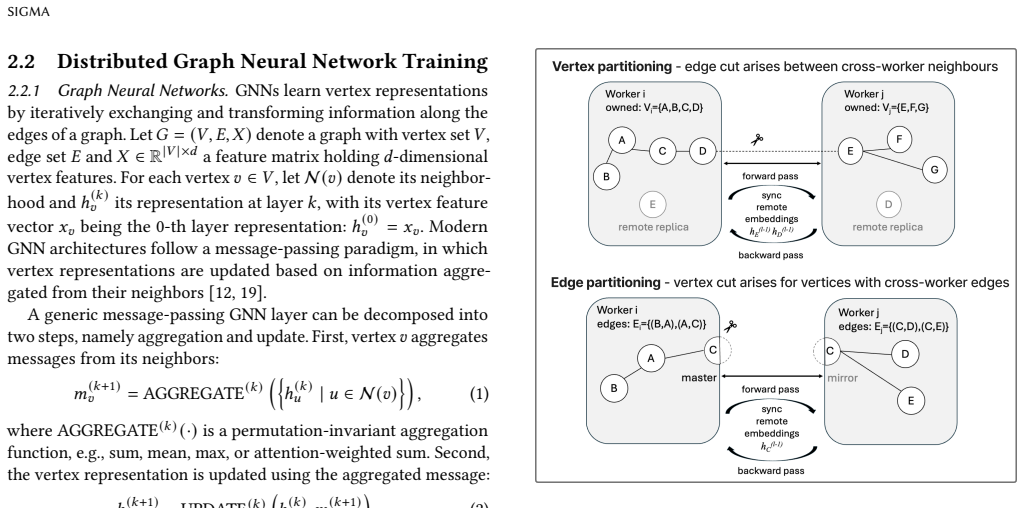
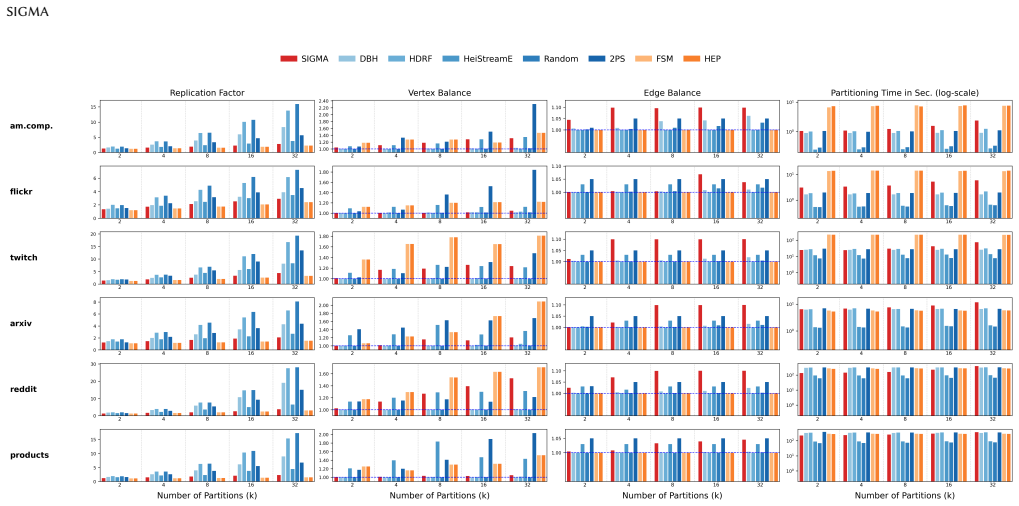
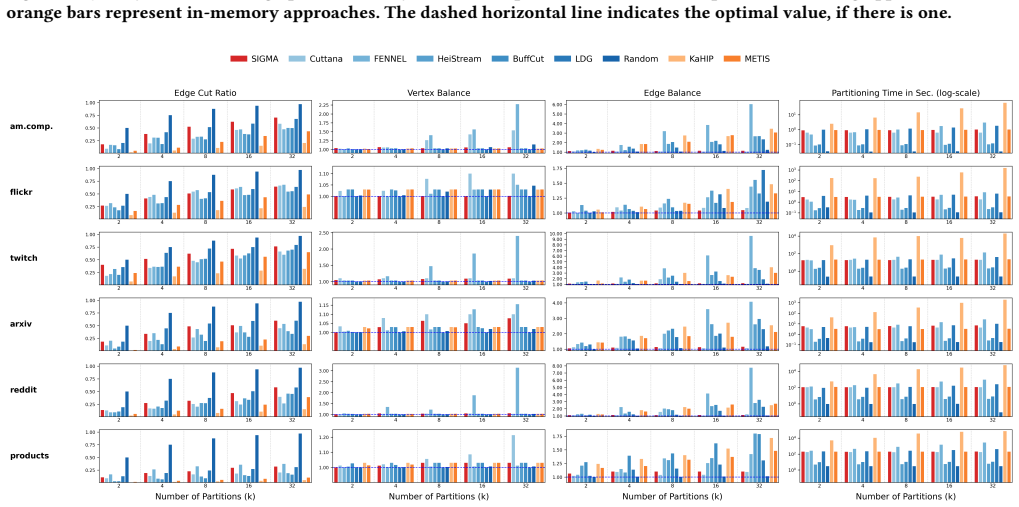
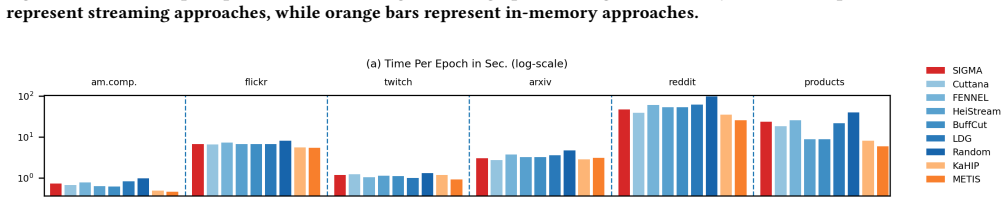
SIGMA (Streaming Integrated Graph Partitioning with Multi-objective Awareness) supports both vertex and edge partitioning inside one multi-objective, multi-constraint streaming framework. It can be configured for edgecut-oriented vertex partitioning or vertex-cut-oriented edge partitioning while balancing vertices and edges together. A clustering-based preprocessing stage adds global structure information while keeping streaming speed and scalability. On six benchmark graphs and two systems (Dist-GNN for edge partitioning and DistDGL for vertex partitioning), SIGMA delivers competitive partition quality, training speed, and memory use compared with streaming baselines and with METIS, KaHIP,
What carries the argument
Unified multi-objective multi-constraint streaming partitioning framework with an added clustering preprocessing stage.
If this is right
- One partitioner can be reused across both edge-partitioned and vertex-partitioned GNN training systems.
- Multi-constraint balancing can be maintained while still optimizing communication cost.
- Streaming methods can reach quality levels close to in-memory partitioners on graphs from several domains.
- Partition quality, training time, and memory use can be traded off inside a single configuration interface.
Where Pith is reading between the lines
- GNN training pipelines could drop multiple specialized partitioners in favor of one configurable streaming tool.
- The same approach might extend to other distributed graph workloads that need both vertex and edge balance.
- Removing the clustering stage on very large graphs would let users test how much quality depends on the preprocessing step.
Load-bearing premise
The clustering preprocessing step can add enough global graph information to raise partition quality without losing the speed and scalability of pure streaming methods.
What would settle it
Run SIGMA on a very large graph where the clustering stage takes longer than the total training time saved by the improved partitions.
Figures


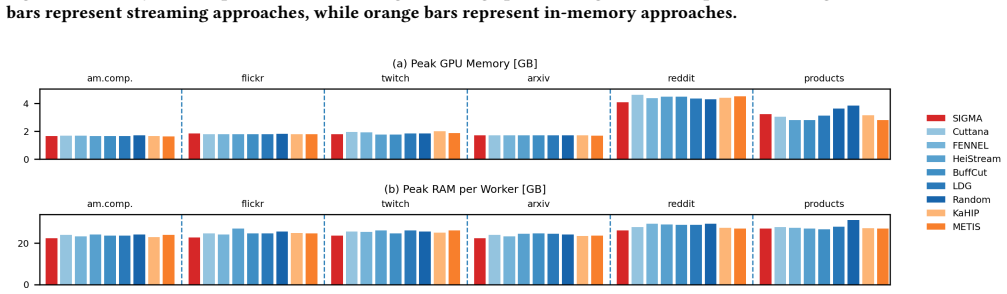
read the original abstract
Distributed Graph Neural Network (GNN) training depends critically on how the underlying graph is partitioned across compute resources. Existing graph partitioners focus either on vertex partitioning or edge partitioning and typically optimize only a single communication objective (edge cut or vertex cut) under a single balance constraint (vertex balance or edge balance). We present SIGMA (Streaming Integrated Graph Partitioning with Multi-objective Awareness), a versatile streaming graph partitioner that supports both vertex and edge partitioning within a unified multi-objective, multi-constraint framework. Depending on the target distributed GNN system, SIGMA can be configured for edgecut-oriented vertex partitioning or vertex-cut-oriented edge partitioning while simultaneously accounting for both vertex and edge balancing. A clustering-based preprocessing stage incorporates global graph structure to improve partition quality while preserving the efficiency and scalability advantages of streaming partitioning. We evaluate SIGMA on six benchmark graphs spanning diverse domains and scales using two distributed GNN training systems: Dist-GNN (edge-partitioned) and DistDGL (vertex-partitioned). Across both settings, SIGMA consistently achieves strong performance, showing its ability to navigate complex trade-offs between partition quality, training efficiency, and memory consumption, frequently outperforming streaming baselines while remaining competitive with high-quality in-memory partitioners such as METIS, KaHIP and HEP. These results demonstrate that a unified streaming partitioner can effectively address the communication, compute, and memory challenges of distributed GNN training across fundamentally different system architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce SIGMA, a versatile streaming graph partitioner that supports both vertex- and edge-balanced partitioning for distributed GNN training in a unified multi-objective framework. It uses a clustering-based preprocessing to incorporate global structure while maintaining streaming efficiency, and evaluates on six graphs with two systems (Dist-GNN and DistDGL), claiming to outperform streaming baselines and compete with in-memory partitioners.
Significance. If the claims hold, particularly the preservation of streaming advantages in the preprocessing stage, this work would provide a significant practical tool for optimizing distributed GNN training across different architectures, addressing key challenges in communication, compute, and memory.
major comments (1)
- Abstract: The assertion that the clustering-based preprocessing 'incorporates global graph structure to improve partition quality while preserving the efficiency and scalability advantages of streaming partitioning' is load-bearing for the central claim. The manuscript must demonstrate that this stage does not require non-streaming global access or multiple passes, as this directly affects whether the unified framework can be deployed at scale on the largest graphs without reverting to in-memory costs.
minor comments (2)
- The abstract refers to 'strong performance' and 'frequently outperforming' without specifying the quantitative metrics, error bars, or data; the evaluation section should present these details clearly to support the cross-system claims.
- The method description would benefit from explicit pseudocode or complexity analysis for the multi-objective balancing to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for identifying this load-bearing claim in the abstract. We agree that explicit demonstration of the preprocessing stage's streaming properties is necessary and will revise the manuscript to provide it.
read point-by-point responses
-
Referee: Abstract: The assertion that the clustering-based preprocessing 'incorporates global graph structure to improve partition quality while preserving the efficiency and scalability advantages of streaming partitioning' is load-bearing for the central claim. The manuscript must demonstrate that this stage does not require non-streaming global access or multiple passes, as this directly affects whether the unified framework can be deployed at scale on the largest graphs without reverting to in-memory costs.
Authors: We agree this requires clarification. The clustering preprocessing in SIGMA is a single-pass streaming procedure: it maintains a small set of local cluster centroids updated incrementally as edges are streamed, without ever loading the full adjacency matrix or requiring a second pass. We will add (1) pseudocode in Section 3.2, (2) a memory-complexity argument showing O(1) auxiliary space per vertex independent of graph size, and (3) empirical timing on the largest evaluated graphs confirming the preprocessing remains linear and sub-linear in memory relative to in-memory partitioners. The abstract wording will be tightened to reference these additions. revision: yes
Circularity Check
No circularity: algorithmic description + empirical evaluation only
full rationale
The paper contains no equations, derivations, fitted parameters, or self-citation chains that reduce claims to inputs by construction. The contribution is a described streaming partitioning algorithm (with a clustering preprocessing stage) plus benchmark comparisons against METIS/KaHIP/HEP and baselines on Dist-GNN/DistDGL. These are externally falsifiable empirical results, not self-referential predictions. The skeptic concern about preprocessing scalability is a correctness/assumption issue, not circularity per the rules.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zainab Abbas, Vasiliki Kalavri, Paris Carbone, and Vladimir Vlassov. 2018. Stream- ing graph partitioning: an experimental study.Proc. VLDB Endow.11, 11 (July 2018), 1590–1603. doi:10.14778/3236187.3236208
-
[2]
Linus Baumgärtner, Adil Chhabra, Marcelo Fonseca Faraj, and Christian Schulz
-
[3]
BuffCut: Prioritized Buffered Streaming Graph Partitioning.arXiv preprint arXiv:2602.21248(2026). SIGMA
arXiv 2026
-
[4]
2016.Recent Advances in Graph Partitioning
Aydın Buluç, Henning Meyerhenke, Ilya Safro, Peter Sanders, and Christian Schulz. 2016.Recent Advances in Graph Partitioning. Springer International Publishing, Cham, 117–158. doi:10.1007/978-3-319-49487-6_4
-
[5]
Ümit Çatalyürek, Karen Devine, Marcelo Faraj, Lars Gottesbüren, Tobias Heuer, Henning Meyerhenke, Peter Sanders, Sebastian Schlag, Christian Schulz, Daniel Seemaier, et al. 2023. More recent advances in (hyper) graph partitioning.Comput. Surveys55, 12 (2023), 1–38
2023
-
[6]
Xu Cheng, Liang Yao, Feng He, Yukuo Cen, Yufei He, Chenhui Zhang, Wenzheng Feng, Hongyun Cai, and Jie Tang. 2025. LPS-GNN: Deploying Graph Neural Networks on Graphs with 100-Billion Edges.arXiv preprint arXiv:2507.14570 (2025)
arXiv 2025
-
[7]
Adil Chhabra, Shai Dorian Peretz, and Christian Schulz. 2025. CluStRE: Streaming Graph Clustering with Multi-Stage Refinement. In23rd International Symposium on Experimental Algorithms (SEA 2025) (Leibniz International Proceedings in Informatics (LIPIcs), Vol. 338), Petra Mutzel and Nicola Prezza (Eds.). Schloss Dagstuhl – Leibniz-Zentrum für Informatik, ...
-
[8]
Adil Chhabra, Marcelo Fonseca Faraj, Christian Schulz, and Daniel Seemaier
-
[9]
Buffered streaming edge partitioning.arXiv preprint arXiv:2402.11980 (2024)
arXiv 2024
-
[10]
Marcelo Fonseca Faraj and Christian Schulz. 2022. Buffered streaming graph partitioning.ACM Journal of Experimental Algorithmics27 (2022), 1–26
2022
-
[11]
Lars Gottesbüren, Tobias Heuer, Peter Sanders, Christian Schulz, and Daniel Seemaier. 2021. Deep Multilevel Graph Partitioning. In29th Annual European Symposium on Algorithms, ESA 2021 (LIPIcs, Vol. 204). Schloss Dagstuhl - Leibniz- Zentrum für Informatik, 48:1–48:17. doi:10.4230/LIPIcs.ESA.2021.48
-
[12]
R. L. Graham. 1969. Bounds on Multiprocessing Timing Anomalies.SIAM J. Appl. Math.17, 2 (1969), 416–429. arXiv:https://doi.org/10.1137/0117039 doi:10. 1137/0117039
-
[13]
Milad Rezaei Hajidehi, Sraavan Sridhar, and Margo Seltzer. 2024. CUTTANA: Scalable Graph Partitioning for Faster Distributed Graph Databases and Analytics. Proc. VLDB Endow.18, 1 (Sept. 2024), 14–27. doi:10.14778/3696435.3696437
-
[14]
Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs.Advances in neural information processing systems30 (2017)
2017
-
[15]
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. 2020. Open graph benchmark: Datasets for machine learning on graphs.Advances in neural information processing systems 33 (2020), 22118–22133
2020
-
[16]
Xin Huang, Weipeng Zhuo, Minh Phu Vuong, Shiju Li, Jongryool Kim, Bradley Rees, and Chul-Ho Lee. 2024. Catgnn: Cost-efficient and scalable distributed training for graph neural networks.arXiv e-prints(2024), arXiv–2404
2024
-
[17]
Nilesh Jain, Guangdeng Liao, and Theodore L. Willke. 2013. GraphBuilder: scalable graph ETL framework. InFirst International Workshop on Graph Data Management Experiences and Systems(New York, New York)(GRADES ’13). Association for Computing Machinery, New York, NY, USA, Article 4, 6 pages. doi:10.1145/2484425.2484429
-
[18]
Shengwei Ji, Shengjie Li, Fei Liu, and Qiang Xu. 2025. LocalDGP: local degree- balanced graph partitioning for lightweight GNNs: S. Ji et al.Applied Intelligence 55, 2 (2025), 109
2025
-
[19]
George Karypis and Vipin Kumar. 1997. METIS: A software package for parti- tioning unstructured graphs, partitioning meshes, and computing fill-reducing orderings of sparse matrices. (1997)
1997
-
[20]
George Karypis and Vipin Kumar. 1998. Multilevel algorithms for multi- constraint graph partitioning. InProceedings of the 1998 ACM/IEEE Conference on Supercomputing(San Jose, CA)(SC ’98). IEEE Computer Society, USA, 1–13
1998
-
[21]
Kipf and Max Welling
Thomas N. Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. InInternational Conference on Learning Repre- sentations. https://openreview.net/forum?id=SJU4ayYgl
2017
-
[22]
Shuangli Li, Jingbo Zhou, Tong Xu, Liang Huang, Fan Wang, Haoyi Xiong, Weili Huang, Dejing Dou, and Hui Xiong. 2021. Structure-aware interactive graph neural networks for the prediction of protein-ligand binding affinity. In Proceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining. 975–985
2021
-
[23]
Chengjun Liu, Zhuo Peng, Weiguo Zheng, and Lei Zou. 2024. FSM: a fine-grained splitting and merging framework for dual-balanced graph partition.Proceedings of the VLDB Endowment17, 9 (2024), 2378–2391
2024
-
[24]
Yang Liu, Xiang Ao, Zidi Qin, Jianfeng Chi, Jinghua Feng, Hao Yang, and Qing He. 2021. Pick and choose: a GNN-based imbalanced learning approach for fraud detection. InProceedings of the web conference 2021. 3168–3177
2021
-
[25]
Christian Mayer, Ruben Mayer, Muhammad Adnan Tariq, Heiko Geppert, Larissa Laich, Lukas Rieger, and Kurt Rothermel. 2018. ADWISE : Adaptive window- based streaming edge partitioning for high-speed graph processing. In2018 IEEE 38th International Conference on Distributed Computing Systems. IEEE, Piscataway, NJ, 685–695
2018
-
[26]
Ruben Mayer and Hans-Arno Jacobsen. 2021. Hybrid edge partitioner: Parti- tioning large power-law graphs under memory constraints. InProceedings of the 2021 International Conference on Management of Data. 1289–1302
2021
-
[27]
Ruben Mayer, Kamil Orujzade, and Hans-Arno Jacobsen. 2022. Out-of-core edge partitioning at linear run-time. In2022 IEEE 38th International conference on data engineering (ICDE). IEEE, 2629–2642
2022
-
[28]
Vasimuddin Md, Sanchit Misra, Guixiang Ma, Ramanarayan Mohanty, Evange- los Georganas, Alexander Heinecke, Dhiraj Kalamkar, Nesreen K Ahmed, and Sasikanth Avancha. 2021. Distgnn: Scalable distributed training for large-scale graph neural networks. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 1–14
2021
-
[29]
Nikolai Merkel, Ruben Mayer, Tawkir Ahmed Fakir, and Hans-Arno Jacobsen
-
[30]
In2023 IEEE 39th International Conference on Data Engineering (ICDE)
Partitioner Selection with EASE to Optimize Distributed Graph Processing. In2023 IEEE 39th International Conference on Data Engineering (ICDE). 2400–2414. doi:10.1109/ICDE55515.2023.00185
-
[31]
Nikolai Merkel, Daniel Stoll, Ruben Mayer, and Hans-Arno Jacobsen. 2025. An Experimental Comparison of Partitioning Strategies for Distributed Graph Neu- ral Network Training. InProceedings 28th International Conference on Extending Database Technology, EDBT 2025, Barcelona, Spain, March 25-28, 2025. OpenPro- ceedings.org, 171–184. doi:10.48786/EDBT.2025.14
-
[32]
Joel Nishimura and Johan Ugander. 2013. Restreaming graph partitioning: simple versatile algorithms for advanced balancing. InProceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Chicago, Illinois, USA)(KDD ’13). Association for Computing Machinery, New York, NY, USA, 1106–1114. doi:10.1145/2487575.2487696
-
[33]
Fabio Petroni, Leonardo Querzoni, Khuzaima Daudjee, Shahin Kamali, and Gior- gio Iacoboni. 2015. Hdrf: Stream-based partitioning for power-law graphs. In Proceedings of the 24th ACM international on conference on information and knowl- edge management. 243–252
2015
-
[34]
Benedek Rozemberczki and Rik Sarkar. 2021. Twitch Gamers: a Dataset for Evaluating Proximity Preserving and Structural Role-based Node Embeddings. arXiv:2101.03091 [cs.SI]
arXiv 2021
-
[35]
Payberah, Fatemeh Rahimian, Vladimir Vlassov, and Seif Haridi
Hooman Peiro Sajjad, Amir H. Payberah, Fatemeh Rahimian, Vladimir Vlassov, and Seif Haridi. 2016. Boosting Vertex-Cut Partitioning for Streaming Graphs. In2016 IEEE International Congress on Big Data (BigData Congress). 1–8. doi:10. 1109/BigDataCongress.2016.10
2016
-
[36]
Peter Sanders and Christian Schulz. 2013. KaHIP v3. 00–Karlsruhe High Quality Partitioning–User Guide.arXiv preprint arXiv:1311.1714(2013)
arXiv 2013
-
[37]
2019.Graph Partitioning: Formulations and Applications to Big Data
Christian Schulz and Darren Strash. 2019.Graph Partitioning: Formulations and Applications to Big Data. Springer International Publishing, Cham, 858–864. doi:10.1007/978-3-319-77525-8_312
-
[38]
Oleksandr Shchur, Maximilian Mumme, Aleksandar Bojchevski, and Stephan Günnemann. 2018. Pitfalls of graph neural network evaluation.arXiv preprint arXiv:1811.05868(2018)
Pith/arXiv arXiv 2018
-
[39]
Fengzhao Shi, Yanan Cao, Yanmin Shang, Yuchen Zhou, Chuan Zhou, and Jia Wu
-
[40]
InProceedings of the ACM web conference 2022
H2-fdetector: A gnn-based fraud detector with homophilic and heterophilic connections. InProceedings of the ACM web conference 2022. 1486–1494
2022
-
[41]
Anurag Shrivastava, RVS Praveen, RaviTeja Aida, Krishna Vemuri, Srinikhil Saisatya Vemuri, and Saif O Husain. 2025. A Comparative Analysis of Graph Neural Networks for Social Network Data Mining. In2025 World Skills Conference on Universal Data Analytics and Sciences (WorldSUAS). IEEE, 1–6
2025
-
[42]
Slota, Kamesh Madduri, and Sivasankaran Rajamanickam
George M. Slota, Kamesh Madduri, and Sivasankaran Rajamanickam. 2014. PuLP: Scalable multi-objective multi-constraint partitioning for small-world networks. In2014 IEEE International Conference on Big Data (Big Data). 481–490. doi:10. 1109/BigData.2014.7004265
arXiv 2014
-
[43]
Isabelle Stanton and Gabriel Kliot. 2012. Streaming graph partitioning for large distributed graphs. InProceedings of the 18th ACM SIGKDD international confer- ence on Knowledge discovery and data mining. 1222–1230
2012
-
[44]
Charalampos Tsourakakis, Christos Gkantsidis, Bozidar Radunovic, and Milan Vojnovic. 2014. Fennel: Streaming graph partitioning for massive scale graphs. InProceedings of the 7th ACM international conference on Web search and data mining. 333–342
2014
-
[45]
Roger Waleffe, Devesh Sarda, Jason Mohoney, Emmanouil-Vasileios Vlatakis- Gkaragkounis, Theodoros Rekatsinas, and Shivaram Venkataraman. 2025. Ar- mada: Memory-Efficient Distributed Training of Large-Scale Graph Neural Net- works.arXiv preprint arXiv:2502.17846(2025)
arXiv 2025
-
[46]
Lingfei Wu, Yu Chen, Kai Shen, Xiaojie Guo, Hanning Gao, Shucheng Li, Jian Pei, and Bo Long. 2023. Graph neural networks for natural language processing: A survey.Foundations and Trends in Machine Learning16, 2 (2023), 119–328
2023
-
[47]
Shiwen Wu, Fei Sun, Wentao Zhang, Xu Xie, and Bin Cui. 2022. Graph neural networks in recommender systems: a survey.ACM computing surveys55, 5 (2022), 1–37
2022
-
[48]
Cong Xie, Ling Yan, Wu-Jun Li, and Zhihua Zhang. 2014. Distributed power- law graph computing: Theoretical and empirical analysis.Advances in neural information processing systems27 (2014)
2014
-
[49]
Jiacheng Xiong, Zhaoping Xiong, Kaixian Chen, Hualiang Jiang, and Mingyue Zheng. 2021. Graph neural networks for automated de novo drug design.Drug discovery today26, 6 (2021), 1382–1393
2021
-
[50]
Hao Yuan, Yajiong Liu, Yanfeng Zhang, Xin Ai, Qiange Wang, Chaoyi Chen, Yu Gu, and Ge Yu. 2024. Comprehensive Evaluation of GNN Training Systems: A Hoffmann et al. Data Management Perspective.Proc. VLDB Endow.17, 6 (Feb. 2024), 1241–1254. doi:10.14778/3648160.3648167
-
[51]
Hanqing Zeng, Hongkuan Zhou, Ajitesh Srivastava, Rajgopal Kannan, and Viktor Prasanna. 2020. GraphSAINT: Graph Sampling Based Inductive Learning Method. InInternational Conference on Learning Representations. https://openreview.net/ forum?id=BJe8pkHFwS
2020
-
[52]
Da Zheng, Chao Ma, Minjie Wang, Jinjing Zhou, Qidong Su, Xiang Song, Quan Gan, Zheng Zhang, and George Karypis. 2020. DistDGL: Distributed graph neural network training for billion-scale graphs. In2020 IEEE/ACM 10th Workshop on Irregular Applications: Architectures and Algorithms (IA3). IEEE, 36–44
2020
-
[53]
Zhongshu Zhu, Bin Jing, Xiaopei Wan, Zhizhen Liu, Lei Liang, et al. 2024. Glisp: A scalable gnn learning system by exploiting inherent structural properties of graphs.arXiv preprint arXiv:2401.03114(2024)
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.