Foley-Omni: A Unified Multimodal Generation Model from Task-Level Audio Synthesis to Complete Video Soundtrack Generation
Pith reviewed 2026-06-28 08:36 UTC · model grok-4.3
The pith
A unified model generates complete video soundtracks by jointly synthesizing speech, sound effects, and music.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Foley-Omni extends isolated task-level audio synthesis to complete video soundtrack generation by jointly modeling speech, sound effects, and music within a shared latent generation process, achieving competitive performance with expert systems on individual tasks while improving speech intelligibility, audiovisual consistency, and perceptual quality for mixed soundtrack generation.
What carries the argument
A shared latent generation process that jointly models speech, sound effects, and music from the same video input.
If this is right
- Video production pipelines can use one model instead of multiple expert systems for soundtrack creation.
- Joint generation reduces mismatches between speech, effects, and music in the final audio track.
- The V2ST-Bench benchmark allows direct comparison of complete versus piecemeal soundtrack methods.
- Speech remains more intelligible when the model sees the full audio context during generation.
Where Pith is reading between the lines
- The same joint-modeling approach could extend to generating audio for longer or multi-shot videos without drift in consistency.
- End-to-end media systems might combine this audio model directly with video generation models to produce both picture and sound from text or image prompts.
- Production teams could test whether the unified model reduces manual mixing time compared with current separate-tool workflows.
Load-bearing premise
Training one model on all three audio types together produces better overall consistency than separate expert systems without creating new conflicts or lowering quality on any single component.
What would settle it
A side-by-side test on mixed soundtrack tasks where the unified model scores lower than a pipeline of separate expert systems on audiovisual consistency or perceptual quality metrics.
Figures

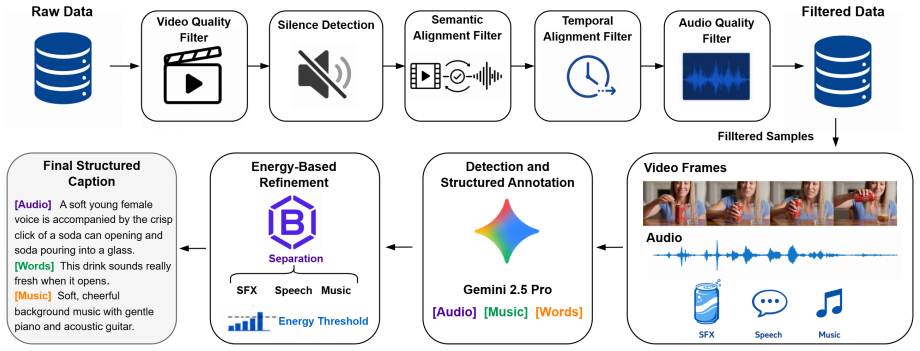
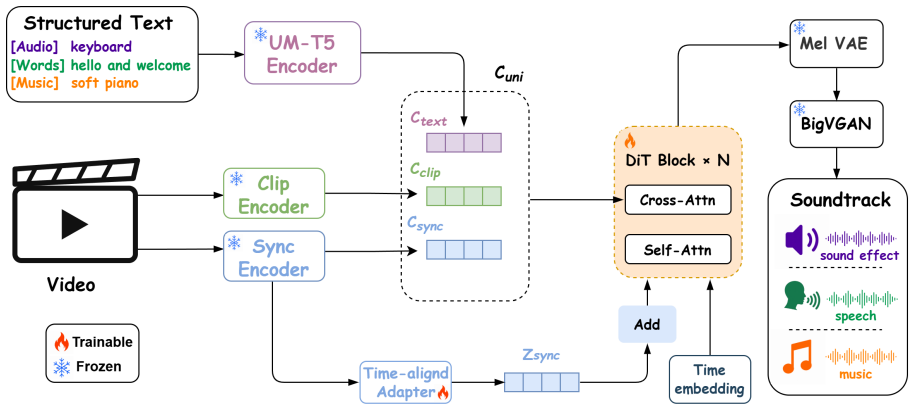


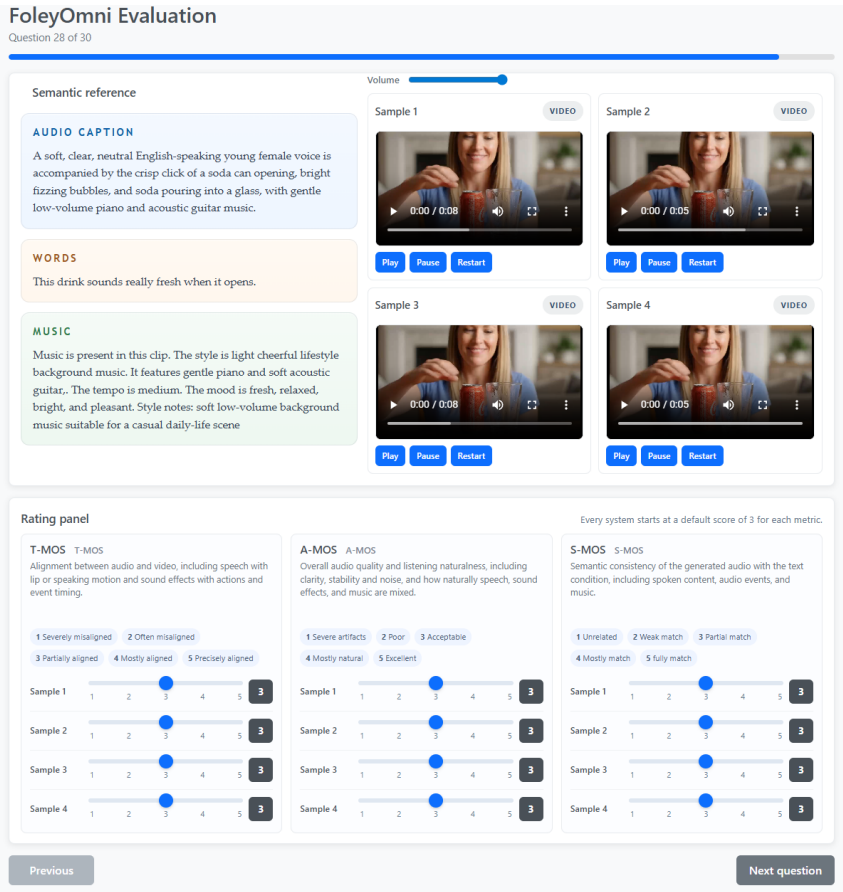
read the original abstract
Recent unified audio generation models can support diverse tasks across speech, sound effects, and music, but most of them still focus on isolated task-level synthesis. However, real video production often requires multiple components of a complete audio track to be generated jointly and consistently for the same video. We present Foley-Omni, a unified multimodal audio generation model that extends isolated task-level synthesis to complete video soundtrack generation by jointly modeling speech, sound effects, and music within a shared latent generation process. To support training and reproducible evaluation, we develop an audiovisual data curation pipeline and introduce V2ST-Bench, a benchmark for holistic video soundtrack generation evaluation. Experiments show that Foley-Omni achieves competitive performance with expert systems on individual synthesis tasks, while improving speech intelligibility, audiovisual consistency and perceptual quality for mixed soundtrack generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Foley-Omni, a unified multimodal audio generation model that jointly models speech, sound effects, and music in a shared latent process to extend from isolated task-level synthesis to complete video soundtrack generation. It introduces an audiovisual data curation pipeline and V2ST-Bench benchmark, claiming competitive results versus expert systems on single tasks plus gains in intelligibility, audiovisual consistency, and perceptual quality on mixed soundtracks.
Significance. If the experimental claims hold under rigorous evaluation, the work would be significant for shifting audio generation research toward holistic, consistent soundtrack synthesis rather than isolated components, with potential practical impact on video production. The V2ST-Bench contribution supports reproducible evaluation of joint generation.
major comments (2)
- Abstract: the central claims of 'competitive performance with expert systems on individual synthesis tasks' and 'improving speech intelligibility, audiovisual consistency and perceptual quality for mixed soundtrack generation' are stated without any quantitative metrics, baselines, error bars, dataset sizes, or statistical tests, preventing verification that the data support the claims.
- Abstract: the description of the 'shared latent generation process' for jointly modeling speech, sound effects, and music supplies no architecture details, loss functions, conditioning mechanisms, or training procedure, which are load-bearing for assessing whether joint modeling avoids new conflicts or quality losses.
Simulated Author's Rebuttal
We thank the referee for the review and the opportunity to clarify points regarding the abstract. The abstract is intentionally concise as a high-level summary; all quantitative details and methodological specifics are provided in the body of the manuscript, which we reference below. We address each major comment directly.
read point-by-point responses
-
Referee: Abstract: the central claims of 'competitive performance with expert systems on individual synthesis tasks' and 'improving speech intelligibility, audiovisual consistency and perceptual quality for mixed soundtrack generation' are stated without any quantitative metrics, baselines, error bars, dataset sizes, or statistical tests, preventing verification that the data support the claims.
Authors: The abstract summarizes the primary findings at a high level to respect length constraints. Verification of the claims is enabled by the full experimental results in Section 4, which include quantitative metrics, baseline comparisons, error bars, dataset sizes from the curation pipeline in Section 3.1, and statistical tests. Tables 1–3 and associated figures report these values for both single-task and mixed-track settings, directly supporting the stated improvements in intelligibility, consistency, and quality. revision: no
-
Referee: Abstract: the description of the 'shared latent generation process' for jointly modeling speech, sound effects, and music supplies no architecture details, loss functions, conditioning mechanisms, or training procedure, which are load-bearing for assessing whether joint modeling avoids new conflicts or quality losses.
Authors: The abstract again provides only a brief overview. Complete architecture details (including the shared latent space design and Figure 2), loss functions (Equations 4–6), conditioning mechanisms, and training procedure are specified in Section 3. This section also discusses how joint modeling maintains quality across modalities without introducing conflicts, with supporting ablation studies and results in Section 4.3. revision: no
Circularity Check
No significant circularity
full rationale
The paper presents a new model, data pipeline, and benchmark, with performance claims resting explicitly on experimental comparisons rather than any derivation chain. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or described structure. The central claims of competitive task performance and joint-generation gains are framed as empirical outcomes, making the work self-contained against external benchmarks without reduction to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2507.06261 , year=
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
-
[2]
2025 , howpublished=
Veo 3: Tech report , author=. 2025 , howpublished=
2025
-
[3]
High-Resolution Image Synthesis with Latent Diffusion Models , booktitle =
Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj. High-Resolution Image Synthesis with Latent Diffusion Models , booktitle =
-
[4]
Lipman, Yaron and Chen, Ricky T. Q. and Ben-Hamu, Heli and Nickel, Maximilian and Le, Matt , title =. The Eleventh International Conference on Learning Representations (ICLR) , year =
-
[5]
arXiv preprint arXiv:2403.03206 , year =
Esser, Patrick and Kulal, Sumith and Blattmann, Andreas and others , title =. arXiv preprint arXiv:2403.03206 , year =
-
[6]
arXiv preprint arXiv:2505.13447 , year =
Geng, Zhengyang and others , title =. arXiv preprint arXiv:2505.13447 , year =
-
[7]
, title =
Liu, Haohe and Chen, Zehua and Yuan, Yi and Mei, Xinhao and Liu, Xubo and Mandic, Danilo and Wang, Wenwu and Plumbley, Mark D. , title =. Proceedings of the 40th International Conference on Machine Learning (ICML) , year =
-
[8]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
Tango 2: Aligning diffusion-based text-to-audio generations through direct preference optimization , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[9]
, title =
Liu, Haohe and Tian, Qiao and Yuan, Yi and Liu, Xubo and Mei, Xinhao and Kong, Qiuqiang and Wang, Yuping and Wang, Wenwu and Wang, Yuxuan and Plumbley, Mark D. , title =. IEEE/ACM Transactions on Audio, Speech, and Language Processing , year =
-
[10]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[11]
arXiv preprint arXiv:2406.02430 , year=
Seed-tts: A family of high-quality versatile speech generation models , author=. arXiv preprint arXiv:2406.02430 , year=
-
[12]
arXiv preprint arXiv:2505.17589 , year=
Cosyvoice 3: Towards in-the-wild speech generation via scaling-up and post-training , author=. arXiv preprint arXiv:2505.17589 , year=
-
[13]
IEEE Transactions on Audio, Speech and Language Processing , year=
Wavjourney: Compositional audio creation with large language models , author=. IEEE Transactions on Audio, Speech and Language Processing , year=
-
[14]
arXiv preprint arXiv:2502.05139 , year=
Meta audiobox aesthetics: Unified automatic quality assessment for speech, music, and sound , author=. arXiv preprint arXiv:2502.05139 , year=
-
[15]
arXiv preprint arXiv:2506.19774 , year=
Kling-foley: Multimodal diffusion transformer for high-quality video-to-audio generation , author=. arXiv preprint arXiv:2506.19774 , year=
-
[16]
The Eleventh International Conference on Learning Representations , year =
BigVGAN: A Universal Neural Vocoder with Large-Scale Training , author=. The Eleventh International Conference on Learning Representations , year =
-
[17]
IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=
Wavcaps: A chatgpt-assisted weakly-labelled audio captioning dataset for audio-language multimodal research , author=. IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=. 2024 , publisher=
2024
-
[18]
arXiv preprint arXiv:2506.02863 , year=
Capspeech: Enabling downstream applications in style-captioned text-to-speech , author=. arXiv preprint arXiv:2506.02863 , year=
-
[19]
2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE) , pages=
DepOwl: detecting dependency bugs to prevent compatibility failures , author=. 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE) , pages=. 2021 , organization=
2021
-
[20]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Learning individual speaking styles for accurate lip to speech synthesis , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[21]
arXiv preprint , year =
Dinkel, Heinrich and others , title =. arXiv preprint , year =
-
[22]
Classifier-Free Diffusion Guidance , author=
-
[23]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Luo, Simian and others , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[24]
ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Synchformer: Efficient synchronization from sparse cues , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
2024
-
[25]
arXiv preprint arXiv:2508.16930 , year=
Hunyuanvideo-foley: Multimodal diffusion with representation alignment for high-fidelity foley audio generation , author=. arXiv preprint arXiv:2508.16930 , year=
-
[26]
International Journal of Computer Vision , volume=
Foleycrafter: Bring silent videos to life with lifelike and synchronized sounds , author=. International Journal of Computer Vision , volume=. 2026 , publisher=
2026
-
[27]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Simple and Controllable Music Generation , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[28]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Mustango: Toward Controllable Text-to-Music Generation , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[29]
arXiv preprint arXiv:2604.10708 , year=
Audio-Omni: Extending Multi-modal Understanding to Versatile Audio Generation and Editing , author=. arXiv preprint arXiv:2604.10708 , year=
-
[30]
arXiv preprint arXiv:2407.07464 , year=
Video-to-audio generation with hidden alignment , author=. arXiv preprint arXiv:2407.07464 , year=
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
V2C: Visual voice cloning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[32]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Emodubber: Towards high quality and emotion controllable movie dubbing , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[33]
Findings of ACL , year =
Cong, Gaoxiang and others , title =. Findings of ACL , year =
-
[34]
International conference on machine learning , pages=
Robust speech recognition via large-scale weak supervision , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[35]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Imagebind: One embedding space to bind them all , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[36]
Fr 'echet Audio Distance: A Reference-free Metric for Evaluating Music Enhancement Algorithms , author=. Proc. Interspeech , pages=
-
[37]
2024 IEEE 5th International Symposium on the Internet of Sounds (IS2) , pages=
Remastering divide and remaster: A cinematic audio source separation dataset with multilingual support , author=. 2024 IEEE 5th International Symposium on the Internet of Sounds (IS2) , pages=. 2024 , organization=
2024
-
[38]
arXiv preprint arXiv:2507.09862 , year=
Speakervid-5m: A large-scale high-quality dataset for audio-visual dyadic interactive human generation , author=. arXiv preprint arXiv:2507.09862 , year=
-
[39]
arXiv preprint arXiv:2601.02731 , year=
Omni2Sound: Towards Unified Video-Text-to-Audio Generation , author=. arXiv preprint arXiv:2601.02731 , year=
-
[40]
2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
CelebV-Text: A Large-Scale Facial Text-Video Dataset , author=. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=. 2023 , organization=
2023
-
[41]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Dualdub: Video-to-soundtrack generation via joint speech and background audio synthesis , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[42]
arXiv preprint arXiv:2509.24773 , year=
VSSFlow: Unifying Video-conditioned Sound and Speech Generation via Joint Learning , author=. arXiv preprint arXiv:2509.24773 , year=
-
[43]
arXiv preprint arXiv:2503.22208 , year=
DeepSound-V1: Start to think step-by-step in the audio generation from videos , author=. arXiv preprint arXiv:2503.22208 , year=
-
[44]
ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Audiogen-omni: A unified multimodal diffusion transformer for video-synchronized audio, speech, and song generation , author=. ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2026 , organization=
2026
-
[45]
arXiv preprint arXiv:2509.17765 , year =
Xu, Jin and Guo, Zhifang and Hu, Hangrui and Chu, Yunfei and Wang, Xiaohuan and He, Jingren and others , title =. arXiv preprint arXiv:2509.17765 , year =
-
[46]
Gemini: A Family of Highly Capable Multimodal Models , year =
-
[47]
ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Vggsound: A large-scale audio-visual dataset , author=. ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2020 , organization=
2020
-
[48]
Keith Ito and Linda Johnson , title =
-
[49]
arXiv preprint arXiv:2511.22229 , year=
VSpeechLM: A Visual Speech Language Model for Visual Text-to-Speech Task , author=. arXiv preprint arXiv:2511.22229 , year=
-
[50]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Mmaudio: Taming multimodal joint training for high-quality video-to-audio synthesis , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[51]
Interspeech 2019 , year=
LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech , author=. Interspeech 2019 , year=
2019
-
[52]
2017 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=
Audio set: An ontology and human-labeled dataset for audio events , author=. 2017 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=. 2017 , organization=
2017
-
[53]
Proceedings of the 18th International Society for Music Information Retrieval Conference (ISMIR) , year =
Fonseca, Eduardo and Pons, Jordi and Favory, Xavier and Font, Frederic and Bogdanov, Dmitry and Ferraro, Andrea and Oramas, Sergio and Porter, Alastair and Serra, Xavier , title =. Proceedings of the 18th International Society for Music Information Retrieval Conference (ISMIR) , year =
-
[54]
Agostinelli, Andrea and Denk, Timo I. and Borsos, Zal. arXiv preprint arXiv:2301.11325 , year =
-
[55]
Proceedings of the 28th ACM international conference on multimedia , pages=
A lip sync expert is all you need for speech to lip generation in the wild , author=. Proceedings of the 28th ACM international conference on multimedia , pages=
-
[56]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025 , pages=
Prosody-enhanced acoustic pre-training and acoustic-disentangled prosody adapting for movie dubbing , author=. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025 , pages=. 2025 , organization=
2025
-
[57]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Learning to Dub Movies via Hierarchical Prosody Models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[58]
Proceedings of NAACL-HLT , pages=
AudioCaps: Generating Captions for Audios in The Wild , author=. Proceedings of NAACL-HLT , pages=
-
[59]
2015 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=
Librispeech: an asr corpus based on public domain audio books , author=. 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=. 2015 , organization=
2015
-
[60]
The Journal of the Acoustical Society of America , volume =
Cooke, Martin and Barker, Jon and Cunningham, Stuart and Shao, Xu , title =. The Journal of the Acoustical Society of America , volume =
-
[61]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year =
Afouras, Triantafyllos and Chung, Joon Son and Senior, Andrew and Vinyals, Oriol and Zisserman, Andrew , title =. IEEE Transactions on Pattern Analysis and Machine Intelligence , year =
-
[62]
arXiv preprint arXiv:2508.13618 , year=
TalkVid: A Large-Scale Diversified Dataset for Audio-Driven Talking Head Synthesis , author=. arXiv preprint arXiv:2508.13618 , year=
-
[63]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
From Faces to Voices: Learning Hierarchical Representations for High-quality Video-to-Speech , author=. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=. 2025 , organization=
2025
-
[64]
Interspeech , pages =
Kilgour, Kevin and Zuluaga, Mauricio and Roblek, Dominik and Sharifi, Matthew , title =. Interspeech , pages =
-
[65]
The Eleventh International Conference on Learning Representations , year =
Flow Matching for Generative Modeling , author=. The Eleventh International Conference on Learning Representations , year =
-
[66]
arXiv preprint arXiv:2604.14148 , year=
Seedance 2.0: Advancing video generation for world complexity , author=. arXiv preprint arXiv:2604.14148 , year=
-
[67]
ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation , author=. ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2023 , organization=
2023
-
[68]
13th Asian Conference on Computer Vision, ACCV 2016 , pages=
Out of time: Automated lip sync in the wild , author=. 13th Asian Conference on Computer Vision, ACCV 2016 , pages=. 2017 , organization=
2016
-
[69]
International Conference on Learning Representations , volume=
Lipvoicer: Generating speech from silent videos guided by lip reading , author=. International Conference on Learning Representations , volume=
-
[70]
Interspeech 2022 , year=
UTMOS: UTokyo-SaruLab System for VoiceMOS Challenge 2022 , author=. Interspeech 2022 , year=
2022
-
[71]
Journal of chiropractic medicine , volume=
A guideline of selecting and reporting intraclass correlation coefficients for reliability research , author=. Journal of chiropractic medicine , volume=. 2016 , publisher=
2016
-
[72]
International Conference on Learning Representations , volume=
Maskgct: Zero-shot text-to-speech with masked generative codec transformer , author=. International Conference on Learning Representations , volume=
-
[73]
International Conference on Learning Representations (ICLR) , year =
Shi, Bowen and Hsu, Wei-Ning and Lakhotia, Kushal and Mohamed, Abdelrahman , title =. International Conference on Learning Representations (ICLR) , year =
-
[74]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
Peebles, William and Xie, Saining , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[75]
International Conference on Learning Representations (ICLR) , year =
Liu, Xingchao and Gong, Chengyue and Liu, Qiang , title =. International Conference on Learning Representations (ICLR) , year =
-
[76]
Proceedings of NAACL-HLT , year =
Xue, Linting and Constant, Noah and Roberts, Adam and Kale, Mihir and Al-Rfou, Rami and Siddhant, Aditya and others , title =. Proceedings of NAACL-HLT , year =
-
[77]
The Eleventh International Conference on Learning Representations , year =
UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining , author=. The Eleventh International Conference on Learning Representations , year =
-
[78]
Neurocomputing , year =
Su, Jianlin and Lu, Yu and Pan, Shengfeng and Wen, Bo and Liu, Yunfeng , title =. Neurocomputing , year =
-
[79]
International Conference on Machine Learning (ICML) , year =
Radford, Alec and Kim, Jong Wook and Hallacy, Chris and Ramesh, Aditya and Goh, Gabriel and Agarwal, Sandhini and others , title =. International Conference on Machine Learning (ICML) , year =
-
[80]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Ho, Jonathan and Jain, Ajay and Abbeel, Pieter , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.