Self-Optimizing Control of Continuous Processes Based on Reinforcement Learning
Pith reviewed 2026-06-28 05:23 UTC · model grok-4.3
The pith
Reinforcement learning embeds self-optimizing control structures in an actor network to optimize variables through environment interaction without explicit constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
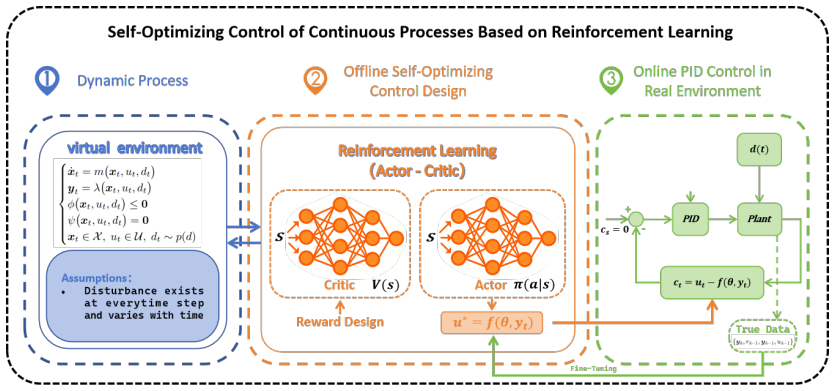
Embedding the self-optimizing control controlled-variable structure inside the actor network of a reinforcement-learning agent, together with economic-indicator reward functions, enables the agent to discover and optimize controlled variables through environment interaction while implicitly accounting for implementability and steady-state uniqueness; online fine-tuning then compensates for model mismatch and yields improved dynamic performance under real-time disturbances.
What carries the argument
Actor network that directly incorporates the SOC controlled-variable selection structure, trained by policy gradients on economic rewards.
If this is right
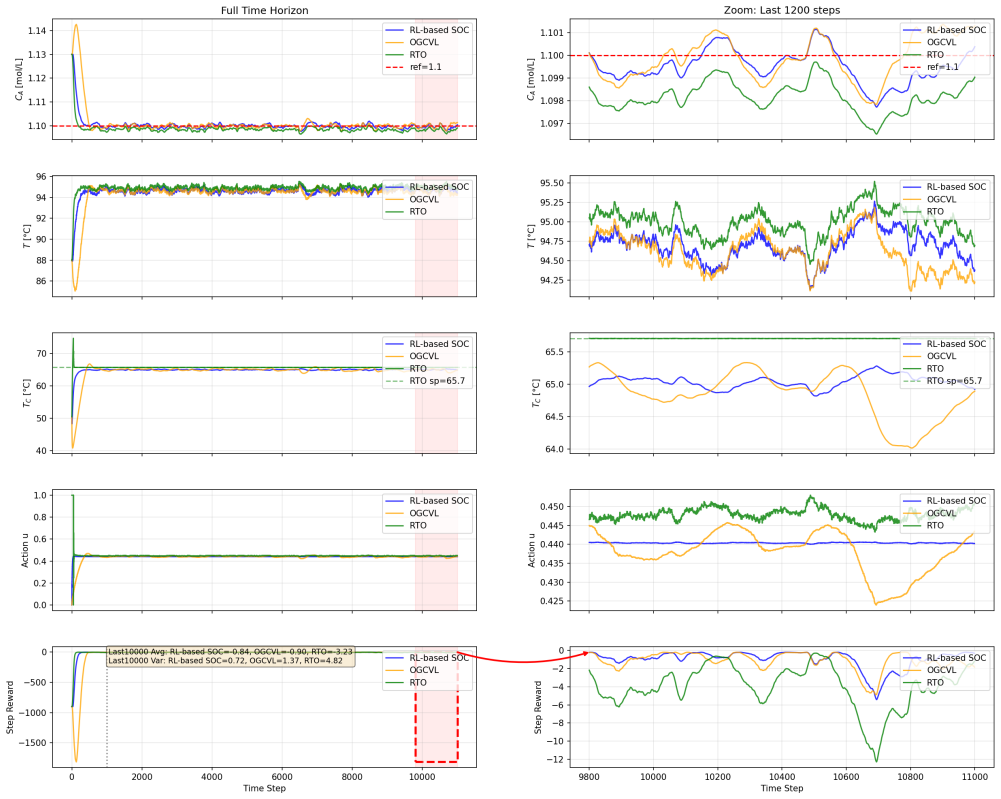
- Dynamic performance improves under real-time disturbances relative to steady-state data methods.
- Controlled-variable trajectories remain smooth without added regularization penalties.
- Hyperparameter tuning effort decreases because the structure is learned rather than hand-designed.
- Online fine-tuning restores performance when the process model changes.
Where Pith is reading between the lines
- The same embedding could allow control redesign when operating conditions shift without restarting from a full steady-state optimization.
- Removing explicit constraints may reduce the engineering effort needed when moving to processes with many candidate controlled variables.
- The approach suggests a route toward fully model-free SOC when combined with further online adaptation.
Load-bearing premise
Interaction with the environment lets the RL agent discover controlled variables that are both implementable and lead to unique steady states without any explicit constraints or regularization terms.
What would settle it
Running the same continuous stirred-tank reactor experiments and finding that the RL controller produces larger output oscillations or slower disturbance rejection than the objective-guided steady-state method would falsify the performance claim.
Figures

read the original abstract
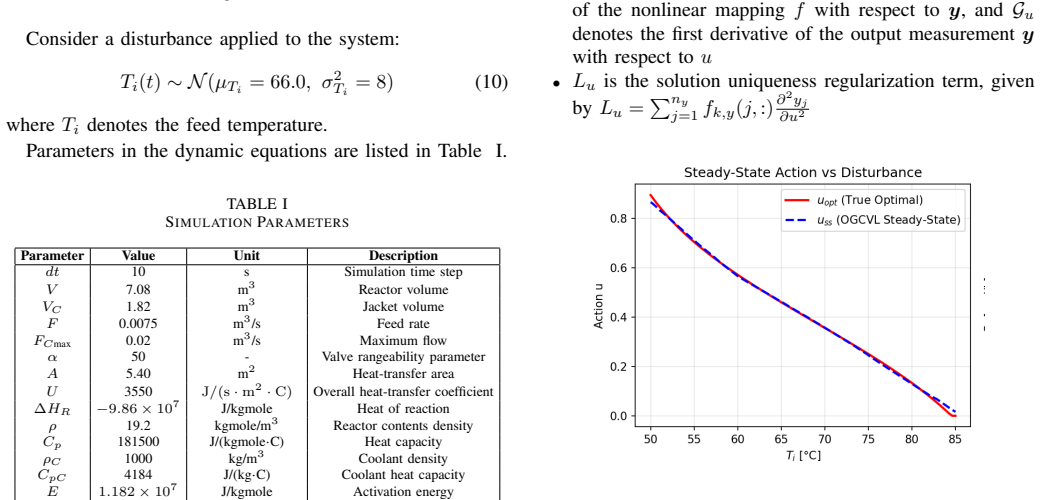
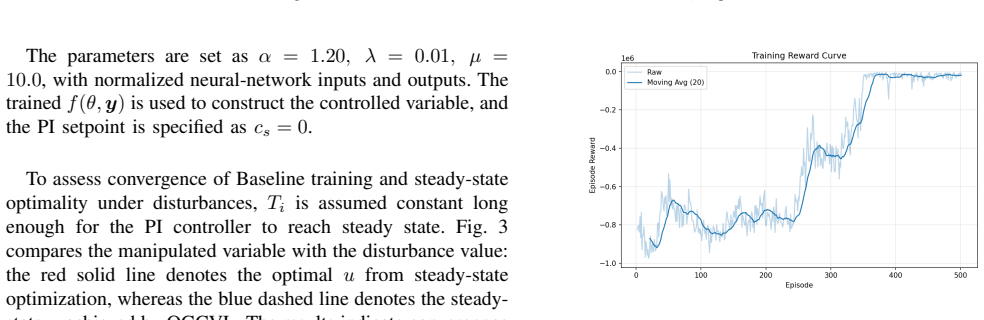
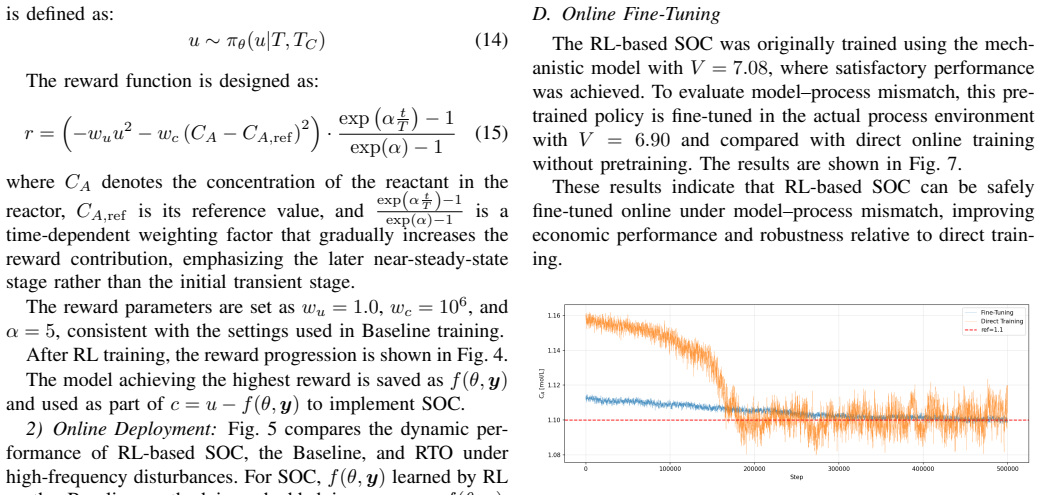
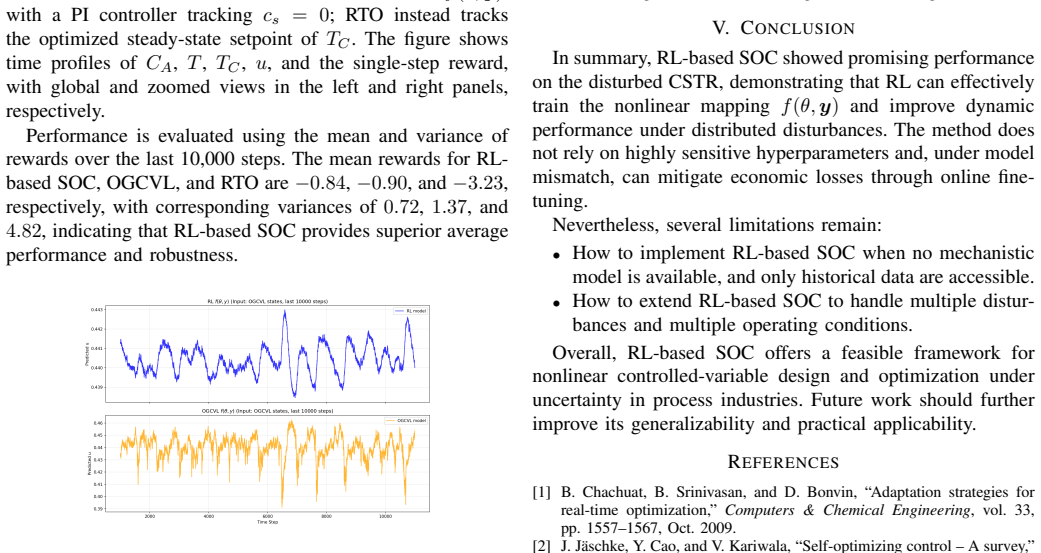
This paper addresses the Self-Optimizing Control (SOC) problem in industrial continuous processes and proposes a Reinforcement-Learning (RL)-based SOC approach to improve dynamic performance under high-frequency disturbances. In the proposed framework, the SOC controlled variable structure is embedded in the Actor network, and reward functions are designed based on economic indicators. Through interaction with the environment, the RL agent optimizes controlled variables while implicitly considering implementability and steady-state uniqueness. Online fine-tuning is further introduced to alleviate model mismatch. Experiments on a continuous stirred-tank reactor with disturbances compare the proposed RL-based SOC method with the Objective-Guided Controlled Variable Learning Approach based on steady-state data. The results show that the RL method achieves improved dynamic performance under real-time disturbances, generates smooth controlled variable outputs without explicit regularization, reduces hyperparameter-tuning complexity, and enhances adaptability through online adjustment. Overall, the proposed RL-based SOC approach provides an effective solution for nonlinear process control and offers a promising reference for future studies involving multiple disturbances, multiple operating conditions, and model-free scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a reinforcement learning (RL)-based framework for self-optimizing control (SOC) of continuous industrial processes. It embeds the SOC controlled-variable structure directly in the Actor network and designs rewards from economic indicators. The central claim is that interaction with the environment allows the RL agent to optimize controlled variables while implicitly enforcing implementability and steady-state uniqueness, without explicit constraints or regularization; online fine-tuning is added for model mismatch. Simulation experiments on a continuous stirred-tank reactor (CSTR) under real-time disturbances report improved dynamic performance, smoother outputs, and better adaptability compared with an objective-guided steady-state baseline.
Significance. If validated, the approach would provide a data-driven route to SOC that reduces reliance on explicit regularization and hyperparameter tuning while handling high-frequency disturbances. The embedding of SOC structure in the Actor and use of economic rewards represent a concrete integration of RL with process-control objectives, with potential reference value for model-free or multi-condition scenarios.
major comments (1)
- [Abstract / Proposed framework] Abstract / Proposed framework: The load-bearing claim that the RL agent 'implicitly considers implementability and steady-state uniqueness' through environment interaction alone (without explicit constraints or regularization) is not supported by a demonstrated mechanism. Neither the reward design nor the Actor embedding is shown to prevent selection of non-unique or non-implementable controlled variables under high-frequency disturbances; the CSTR comparison to the steady-state baseline does not isolate whether reported smoothness and dynamic gains arise from this implicit capability or from unstated factors such as reward shaping or training procedure.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract / Proposed framework] Abstract / Proposed framework: The load-bearing claim that the RL agent 'implicitly considers implementability and steady-state uniqueness' through environment interaction alone (without explicit constraints or regularization) is not supported by a demonstrated mechanism. Neither the reward design nor the Actor embedding is shown to prevent selection of non-unique or non-implementable controlled variables under high-frequency disturbances; the CSTR comparison to the steady-state baseline does not isolate whether reported smoothness and dynamic gains arise from this implicit capability or from unstated factors such as reward shaping or training procedure.
Authors: The reward is constructed directly from economic performance indicators of the closed-loop process. Any controlled-variable selection that is non-implementable or yields non-unique steady states necessarily produces inconsistent or suboptimal economic returns when the agent interacts with the full nonlinear dynamics; the policy gradient therefore drives the Actor away from such selections without needing an auxiliary penalty term. The Actor embedding restricts outputs to the exact linear-combination form required by SOC, so the search space itself excludes structurally invalid candidates. In the CSTR experiments the only difference between the RL agent and the steady-state baseline is the online interaction with disturbances; the observed smoothness and improved dynamic metrics therefore arise from the learned policy rather than from unstated reward shaping. We maintain that the mechanism is demonstrated by the training procedure and the empirical outcome, though we acknowledge it is empirical rather than a formal proof. revision: no
Circularity Check
No significant circularity in the RL-based SOC derivation
full rationale
The paper proposes embedding the SOC structure in the Actor network and using economic-indicator rewards, with optimization occurring via standard RL environment interaction. This does not reduce to a self-definitional equivalence, a fitted parameter renamed as prediction, or a load-bearing self-citation chain. No uniqueness theorem or ansatz is imported from prior author work, and the method is compared to an external baseline (Objective-Guided Controlled Variable Learning Approach). The derivation chain remains independent of its own outputs and is self-contained against the described external validation.
Axiom & Free-Parameter Ledger
free parameters (1)
- RL reward scaling and network hyperparameters
axioms (1)
- domain assumption The continuous process can be treated as a Markov decision process suitable for standard RL algorithms.
Reference graph
Works this paper leans on
-
[1]
Alstad, Vidar and Skogestad, Sigurd , langid =. Null
-
[2]
Wayne , year = 2024, series =
Bequette, B. Wayne , year = 2024, series =. Process Control: Modeling, Design, and Simulation , shorttitle =
2024
-
[3]
Computers & Chemical Engineering , volume =
Adaptation Strategies for Real-Time Optimization , author =. Computers & Chemical Engineering , volume =. doi:10.1016/j.compchemeng.2009.04.014 , urldate =
-
[4]
and Skogestad, Sigurd and Morud, John C
Halvorsen, Ivar J. and Skogestad, Sigurd and Morud, John C. and Alstad, Vidar , year = 2003, month = jul, journal =. Optimal. doi:10.1021/ie020833t , urldate =
-
[5]
Optimal Controlled Variables for Polynomial Systems , author =
-
[6]
J. Self-Optimizing Control --. Annual Reviews in Control , volume =. doi:10.1016/j.arcontrol.2017.03.001 , urldate =
-
[7]
Journal of Process Control , volume =
Self-Optimizing Control with Active Set Changes , author =. Journal of Process Control , volume =. doi:10.1016/j.jprocont.2012.02.015 , urldate =
-
[8]
Marchetti, A. and Chachuat, B. and Bonvin, D. , year = 2007, journal =. doi:10.3182/20070606-3-MX-2915.00006 , urldate =
-
[9]
Proximal Policy Optimization Algorithms
Schulman, John and Wolski, Filip and Dhariwal, Prafulla and Radford, Alec and Klimov, Oleg , year = 2017, month = aug, number =. Proximal. doi:10.48550/arXiv.1707.06347 , urldate =. arXiv , langid =:1707.06347 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1707.06347 2017
-
[10]
Ye, Lingjian and Cao, Yi and He, Yuchen and Zhou, Chenchen and Su, Hongxin and Tang, Xinhui and Yang, Shuanghua , year = 2023, month = sep, journal =. Generalized. doi:10.1021/acs.iecr.3c01685 , urldate =
-
[11]
Ye, Lingjian and Cao, Yi and Yuan, Xiaofeng , year = 2015, month = dec, journal =. Global. doi:10.1021/acs.iecr.5b00844 , urldate =
-
[12]
Global Self-Optimizing Control with Active-Set Changes:
Ye, Lingjian and Cao, Yi and Yang, Shuanghua , year = 2022, month = mar, journal =. Global Self-Optimizing Control with Active-Set Changes:. doi:10.1016/j.compchemeng.2022.107662 , urldate =
-
[13]
Zhou, Chenchen and Su, Hongxin and Tang, Xinhui and Cao, Yi and Yang, Shuang-Hua and Ye, Lingjian , year = 2025, month = jan, journal =. Generalized. doi:10.1021/acs.iecr.4c02644 , urldate =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.