KD-NVC: A Search-and-Distill Framework to Accelerate Neural Video Coding
Pith reviewed 2026-06-28 04:14 UTC · model grok-4.3
The pith
A two-stage search-and-distill pipeline produces lightweight neural video codecs that decode 1080p video at 69 FPS while keeping rate-distortion performance comparable to VTM-LDB.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
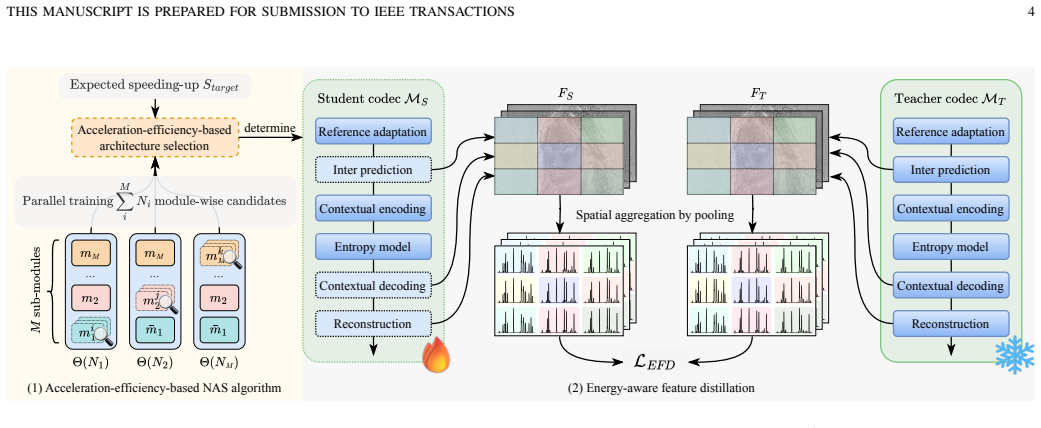
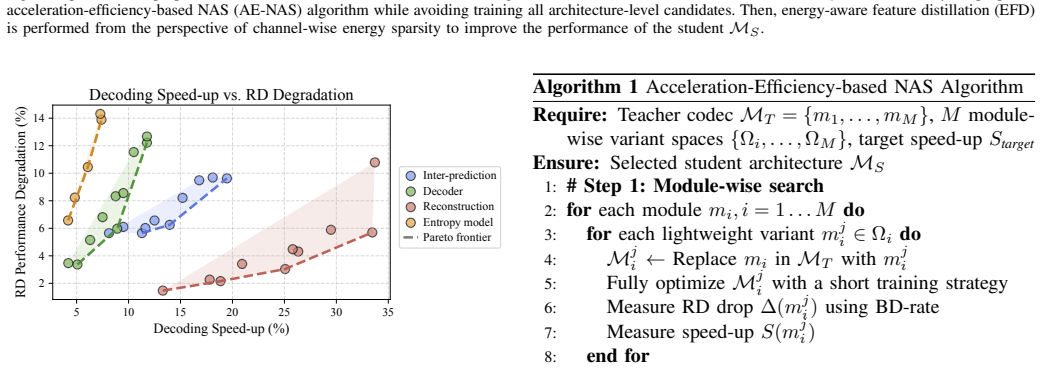
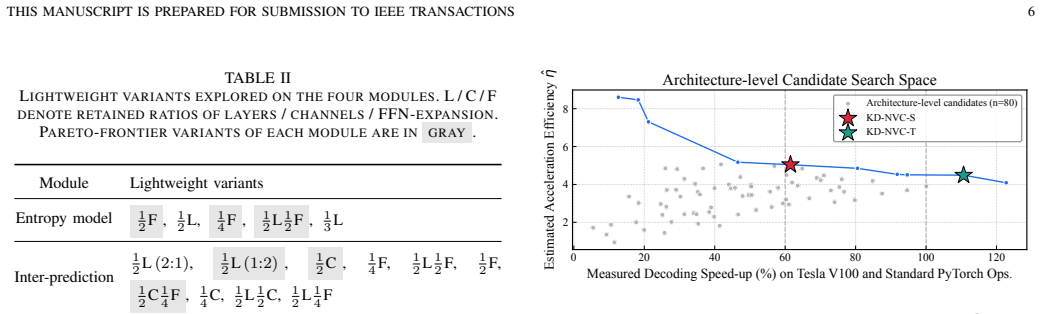
The authors establish that an acceleration-efficiency-based neural architecture search can identify per-module student architectures by exploring module-wise Pareto frontiers and using an acceleration-efficiency metric to avoid exhaustive training, after which an energy-aware feature distillation loss that aligns spatially-aggregated feature-energy signatures transfers the rate-induced sparsity patterns, enabling student codecs to achieve real-time decoding speeds with rate-distortion performance comparable to the teacher and to VTM-LDB.
What carries the argument
The acceleration-efficiency-based neural architecture search (AE-NAS) that determines module-wise architectures via Pareto frontiers and an acceleration-efficiency metric, together with the energy-aware feature distillation (EFD) loss that aligns spatially-aggregated feature-energy signatures.
If this is right
- The KD-NVC framework outperforms prior codec-oriented distillation methods on rate-distortion-speed trade-offs.
- The resulting student models reach 69 FPS decoding for 1080p video on an RTX 5060.
- Rate-distortion performance stays comparable to both the original teacher model and the VTM-LDB anchor.
- Module-wise rather than uniform architecture reduction yields better overall efficiency for heterogeneous NVC sub-modules.
- The two-stage separation of search and distillation lowers the cost of finding suitable lightweight architectures.
Where Pith is reading between the lines
- The same energy-signature alignment could be tested on neural image codecs or point-cloud codecs that also operate under rate constraints.
- The acceleration-efficiency metric could be adapted to target different hardware platforms by changing the cost model inside the search.
- If the sparsity transfer holds, similar distillation losses might improve other compression-aware student models without requiring full retraining.
- Measuring energy signatures on intermediate feature maps from different video content classes would test whether the transferred patterns generalize beyond the training distribution.
Load-bearing premise
Aligning the spatially-aggregated feature-energy signatures between teacher and student transfers the rate-constraint-induced sparsity patterns that are necessary to preserve compression performance.
What would settle it
Running the student architecture both with and without the EFD loss on the same training data and measuring whether the version without EFD shows a clear increase in rate-distortion cost or a mismatch in measured feature-energy sparsity on a held-out test set.
Figures



read the original abstract
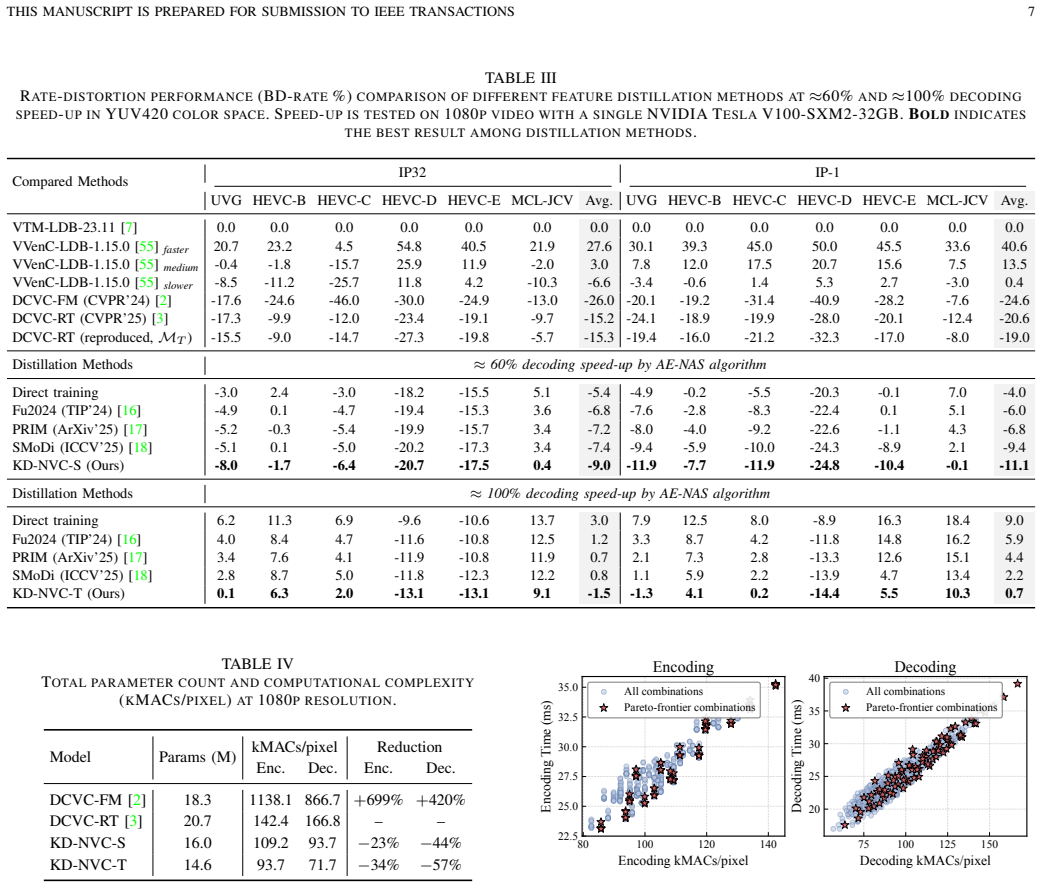
While neural video coding (NVC) has achieved remarkable rate-distortion performance, real-time decoding on edge devices has become an important demand but remains limited by high complexity. Knowledge distillation (KD) is widely used for model acceleration, yet its application to NVC faces critical challenges. Specifically, the heterogeneity of NVC sub-modules renders uniform architectural reduction suboptimal, necessitating a per-module design for better rate-distortion-speed trade-off. However, searching for diverse architectures via existing neural architecture search (NAS) algorithms is unaffordable due to the expensive training cost of neural video codecs. Moreover, after the lightweight architecture is determined, existing distillation methods overlook the feature-energy sparsity induced by the rate-constraint, which is essential for maintaining compression performance. To address these issues, we propose a two-stage distillation framework KD-NVC. In the first stage, we introduce an acceleration-efficiency-based neural architecture search (AE-NAS) algorithm. It explores the module-wise Pareto frontier to adaptively allocate the acceleration budget across heterogeneous modules. Also, it introduces the acceleration-efficiency metric to determine the final student architecture without practically training all architecture-level candidates. In the second stage, we design an energy-aware feature distillation (EFD) loss that aligns the spatially-aggregated feature-energy signatures between the teacher and student codecs, transferring the rate-induced sparsity patterns for better compression efficiency. Experimental results demonstrate that the proposed framework consistently outperforms existing codec-oriented distillation methods, and achieves 69 FPS decoding at 1080p on RTX 5060 while maintaining comparable RD performance to VTM-LDB.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes KD-NVC, a two-stage search-and-distill framework for accelerating neural video codecs. Stage 1 uses an acceleration-efficiency-based NAS (AE-NAS) that explores module-wise Pareto frontiers and an acceleration-efficiency metric to select student architectures without training all candidates. Stage 2 introduces an energy-aware feature distillation (EFD) loss that aligns spatially-aggregated feature-energy signatures to transfer rate-constraint-induced sparsity patterns. The central empirical claim is that this consistently outperforms prior codec-oriented distillation methods while achieving 69 FPS 1080p decoding on an RTX 5060 with RD performance comparable to VTM-LDB.
Significance. If the results hold, the work would be significant for practical deployment of neural video coding on edge devices, where real-time decoding remains a bottleneck. The per-module NAS allocation and the targeted handling of rate-induced feature sparsity address domain-specific challenges that uniform KD approaches overlook. The AE-NAS efficiency metric is a pragmatic engineering contribution that could reduce search cost in similar heterogeneous codec settings.
major comments (2)
- [EFD loss (second stage)] EFD loss description (second stage): the claim that aligning spatially-aggregated feature-energy signatures transfers rate-induced sparsity patterns and is essential for maintaining compression performance is load-bearing for the outperformance claim, yet the manuscript provides no ablation or causal validation (e.g., comparing RD when sparsity patterns are matched vs. mismatched while holding architecture fixed) to show that spatial aggregation preserves the local rate-allocation details rather than discarding them.
- [Experimental results] Experimental results section: the reported 69 FPS at 1080p and consistent outperformance over existing distillation methods are presented without the supporting details (baselines, error bars, ablation tables isolating AE-NAS vs. EFD, or hardware measurement protocol) needed to verify that the gains are attributable to the proposed components rather than training schedule or architecture choice alone.
minor comments (2)
- [AE-NAS description] Notation for the acceleration-efficiency metric should be defined explicitly with its formula before being used to select the final architecture.
- [Abstract and method] The abstract and method sections would benefit from a clear statement of the precise VTM-LDB configuration (profile, GOP structure) used for the RD comparison.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments. We address each major comment point-by-point below, outlining revisions that will strengthen the manuscript while preserving its core contributions.
read point-by-point responses
-
Referee: [EFD loss (second stage)] EFD loss description (second stage): the claim that aligning spatially-aggregated feature-energy signatures transfers rate-induced sparsity patterns and is essential for maintaining compression performance is load-bearing for the outperformance claim, yet the manuscript provides no ablation or causal validation (e.g., comparing RD when sparsity patterns are matched vs. mismatched while holding architecture fixed) to show that spatial aggregation preserves the local rate-allocation details rather than discarding them.
Authors: We thank the referee for this observation. The EFD loss is motivated by the need to transfer rate-constraint-induced sparsity patterns, with spatial aggregation intended to retain local rate-allocation information in a compact form. While the manuscript shows overall gains relative to prior distillation methods, we agree that an explicit causal ablation would provide stronger validation. In the revised version, we will add an ablation comparing RD performance under matched versus mismatched sparsity patterns (architecture fixed) to demonstrate that spatial aggregation preserves the relevant details. revision: yes
-
Referee: [Experimental results] Experimental results section: the reported 69 FPS at 1080p and consistent outperformance over existing distillation methods are presented without the supporting details (baselines, error bars, ablation tables isolating AE-NAS vs. EFD, or hardware measurement protocol) needed to verify that the gains are attributable to the proposed components rather than training schedule or architecture choice alone.
Authors: We agree that additional experimental details are required for full reproducibility and attribution of gains. The revised manuscript will expand this section to include: explicit baseline specifications and comparisons, error bars from repeated runs, ablation tables that isolate AE-NAS from EFD contributions, and a precise description of the hardware measurement protocol used to obtain the 69 FPS 1080p decoding result on RTX 5060. These changes will clarify that improvements stem from the proposed components. revision: yes
Circularity Check
No circularity: empirical engineering framework with no derivations or self-referential reductions
full rationale
The manuscript describes a two-stage KD-NVC framework (AE-NAS for architecture search followed by EFD loss for feature-energy alignment) as an empirical contribution. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the text. Performance claims rest on experimental results rather than any chain that reduces to its own inputs by construction. This matches the default expectation for non-theoretical papers; the reader's assessment of score 2.0 is consistent with minor or absent circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Heterogeneity of NVC sub-modules renders uniform architectural reduction suboptimal, necessitating per-module design
- domain assumption Feature-energy sparsity induced by the rate-constraint is essential for maintaining compression performance
Reference graph
Works this paper leans on
-
[1]
Auto-encoding variational bayes,
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” in Proceedings of the International Conference on Learning Representa- tions (ICLR), 2014
2014
-
[2]
Neural video compression with feature modulation,
J. Li, B. Li, and Y . Lu, “Neural video compression with feature modulation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 26 099–26 108
2024
-
[3]
Towards practical real-time neural video compression,
Z. Jia, B. Li, J. Li, W. Xie, L. Qi, H. Li, and Y . Lu, “Towards practical real-time neural video compression,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 12 543–12 552
2025
-
[4]
NVC-1B: Scaling up neural video coding models,
C. Tang, X. Sheng, L. Li, D. Liu, and F. Wu, “NVC-1B: Scaling up neural video coding models,”IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–17, 2026
2026
-
[5]
Overview of the high efficiency video coding (HEVC) standard,
G. J. Sullivan, J.-R. Ohm, W.-J. Han, and T. Wiegand, “Overview of the high efficiency video coding (HEVC) standard,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 22, no. 12, pp. 1649– 1668, 2012
2012
-
[6]
Overview of the H.264/A VC video coding standard,
T. Wiegand, G. J. Sullivan, G. Bjontegaard, and A. Luthra, “Overview of the H.264/A VC video coding standard,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 13, no. 7, pp. 560–576, 2003
2003
-
[7]
VTM-23.11, https://vcgit.hhi.fraunhofer.de/jvet/VVCSoftware VTM, 2024, accessed on: 2026-05-01
2024
-
[8]
DVC: An end-to-end deep video compression framework,
G. Lu, W. Ouyang, D. Xu, X. Zhang, C. Cai, and Z. Gao, “DVC: An end-to-end deep video compression framework,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 11 006–11 015
2019
-
[9]
Neural video compression with diverse contexts,
J. Li, B. Li, and Y . Lu, “Neural video compression with diverse contexts,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 22 616–22 626
2023
-
[10]
ECVC: Exploiting non- local correlations in multiple frames for contextual video compression,
W. Jiang, J. Li, K. Zhang, and L. Zhang, “ECVC: Exploiting non- local correlations in multiple frames for contextual video compression,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 7331–7341
2025
-
[11]
I 2VC: A unified framework for intra-& inter-frame video compression,
M. Liu, C. Xu, Y . Gu, C. Yao, and Y . Zhao, “I 2VC: A unified framework for intra-& inter-frame video compression,”arXiv preprint arXiv:2405.14336, 2024
-
[12]
Generative neural video compression via video diffusion prior,
Q. Mao, H. Cheng, T. Yang, L. Jin, and S. Ma, “Generative neural video compression via video diffusion prior,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2026, pp. 43 239–43 248
2026
-
[13]
AsymL- LIC: Asymmetric lightweight learned image compression,
S. Wang, Z. Cheng, D. Feng, G. Lu, L. Song, and W. Zhang, “AsymL- LIC: Asymmetric lightweight learned image compression,” inProceed- ings of the IEEE International Conference on Visual Communications and Image Processing (VCIP), 2024, pp. 1–5
2024
-
[14]
Very deep convolutional networks for large-scale image recognition,
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” inProceedings of the International Conference on Learning Representations (ICLR), 2015
2015
-
[15]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778
2016
-
[16]
Fast and high-performance learned image compression with improved checkerboard context model, deformable residual module, and knowl- edge distillation,
H. Fu, F. Liang, J. Liang, Y . Wang, Z. Fang, G. Zhang, and J. Han, “Fast and high-performance learned image compression with improved checkerboard context model, deformable residual module, and knowl- edge distillation,”IEEE Transactions on Image Processing, vol. 33, pp. 4702–4715, 2024
2024
-
[17]
Effi- cient learned image compression through knowledge distillation,
F. Allemand, A. Fiandrotti, S. Chaudhuri, and A. E. Mazouz, “Effi- cient learned image compression through knowledge distillation,”arXiv preprint arXiv:2509.10366, 2025
-
[18]
Knowledge distillation for learned image compression,
Y . Chen, Z. Lyu, B. He, N. Cao, G. Chen, G. Lu, and W. Zhang, “Knowledge distillation for learned image compression,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025, pp. 4996–5006
2025
-
[19]
Unicompress: Enhancing multi-data medical image com- pression with knowledge distillation,
R. Yang, Y . Chen, Z. Zhang, X. Liu, Z. Li, K. He, Z. Xiong, J. Suo, and Q. Dai, “Unicompress: Enhancing multi-data medical image com- pression with knowledge distillation,”arXiv preprint arXiv:2405.16850, 2024
-
[20]
Free-VSC: Free semantics from visual foundation models for unsupervised video semantic compression,
Y . Tian, G. Lu, and G. Zhai, “Free-VSC: Free semantics from visual foundation models for unsupervised video semantic compression,” in THIS MANUSCRIPT IS PREPARED FOR SUBMISSION TO IEEE TRANSACTIONS 10 Proceedings of the European Conference on Computer Vision (ECCV), 2024, pp. 163–183
2024
-
[21]
SMC++: Masked learning of unsupervised video semantic compression,
Y . Tian, X. Ling, C. Geng, Q. Hu, G. Lu, and G. Zhai, “SMC++: Masked learning of unsupervised video semantic compression,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 48, no. 2, pp. 1992–2011, 2026
1992
-
[22]
Symmetric entropy-constrained video coding for machines,
Y . Sun, M. Liu, C. Yao, Q. Tang, J. Jin, W. Lin, F. Dufaux, and Y . Zhao, “Symmetric entropy-constrained video coding for machines,”
-
[23]
Symmetric Entropy-Constrained Video Coding for Machines
[Online]. Available: https://arxiv.org/abs/2510.15347
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Single- step diffusion-based video coding with semantic-temporal guidance,
N. Xue, Z. Jia, J. Li, B. Li, Z. Zheng, Y . Zhang, and Y . Lu, “Single- step diffusion-based video coding with semantic-temporal guidance,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2026, pp. 9752–9761
2026
-
[25]
Temporal context min- ing for learned video compression,
X. Sheng, J. Li, B. Li, L. Li, D. Liu, and Y . Lu, “Temporal context min- ing for learned video compression,”IEEE Transactions on Multimedia, vol. 25, pp. 7311–7322, 2023
2023
-
[26]
Spatial decomposition and temporal fusion based inter prediction for learned video compression,
X. Sheng, L. Li, D. Liu, and H. Li, “Spatial decomposition and temporal fusion based inter prediction for learned video compression,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 7, pp. 6460–6473, 2024
2024
-
[27]
Joint autoregressive and hierarchical priors for learned image compression,
D. Minnen, J. Ball ´e, and G. D. Toderici, “Joint autoregressive and hierarchical priors for learned image compression,” inProceedings of Advances in Neural Information Processing Systems (NeurIPS), vol. 31, 2018
2018
-
[28]
Y . Zhang and F. Zhu, “Leveraging second-order curvature for efficient learned image compression: Theory and empirical evidence,” 2026. [Online]. Available: https://arxiv.org/abs/2601.20769
-
[29]
Deep contextual video compression,
J. Li, B. Li, and Y . Lu, “Deep contextual video compression,” in Proceedings of Advances in Neural Information Processing Systems (NeurIPS), vol. 34, 2021, pp. 18 114–18 125
2021
-
[30]
Learned video compression via heterogeneous deformable compensation network,
H. Wang, Z. Chen, and C. W. Chen, “Learned video compression via heterogeneous deformable compensation network,”IEEE Transactions on Multimedia, vol. 26, pp. 1855–1866, 2024
2024
-
[31]
Hybrid spatial-temporal entropy modeling for neural video compression,
J. Li, B. Li, and Y . Lu, “Hybrid spatial-temporal entropy modeling for neural video compression,” inProceedings of the ACM International Conference on Multimedia (ACM MM), 2022, pp. 1503–1511
2022
-
[32]
Prediction and reference quality adaptation for learned video compression,
X. Sheng, L. Li, D. Liu, and H. Li, “Prediction and reference quality adaptation for learned video compression,”IEEE Transactions on Image Processing, vol. 34, pp. 2285–2300, 2025
2025
-
[33]
Perceptual learned video compression with recurrent conditional gan,
R. Yang, R. Timofte, and L. Van Gool, “Perceptual learned video compression with recurrent conditional gan,” inProceedings of the International Joint Conference on Artificial Intelligence (IJCAI), 2022, pp. 1537–1544
2022
-
[34]
Real-time neural video compression with unified intra and inter coding,
H. Xiang, Y . Bian, L. Li, J. Wu, X. Zhang, and D. Liu, “Real-time neural video compression with unified intra and inter coding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2026, pp. 35 217–35 226
2026
-
[35]
Integer-centric neural video compression,
Z. Jia, W. Xie, Z. Guo, B. Li, J. Li, H. Li, and Y . Lu, “Integer-centric neural video compression,”Submitted to ICLR 2026 Conference, 2025. [Online]. Available: https://openreview.net/forum?id=KCQo0fXtFH
2026
-
[36]
On the quantization of neural video codecs,
H.-T. Phung, Y .-H. Lin, C.-H. Wu, R. Conceic ¸˜ao, Y .-H. Chen, M. Porto, L. V . Agostini, and W.-H. Peng, “On the quantization of neural video codecs,”Submitted to ICLR 2026 Conference, 2025. [Online]. Available: https://openreview.net/forum?id=dLqDqzlDxZ
2026
-
[37]
MobileNVC: Real-time 1080p neural video compression on a mobile device,
T. van Rozendaal, T. Singhal, H. Le, G. Sautiere, A. Said, K. Buska, A. Raha, D. Kalatzis, H. Mehta, F. Mayer, L. Zhang, M. Nagel, and A. Wiggers, “MobileNVC: Real-time 1080p neural video compression on a mobile device,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2024, pp. 4311–4321
2024
-
[38]
MobileCodec: neural inter-frame video compression on mobile devices,
H. Le, L. Zhang, A. Said, G. Sautiere, Y . Yang, P. Shrestha, F. Yin, R. Pourreza, and A. Wiggers, “MobileCodec: neural inter-frame video compression on mobile devices,” inProceedings of the 13th ACM Multimedia Systems Conference (MMSys), August 2022, pp. 324–330. [Online]. Available: https://doi.org/10.1145/3524273.3532906
-
[39]
Ultra-fast neural video compression,
J. Li, W. Xie, Z. Jia, B. Li, Z. Guo, X. Zhang, and Y . Lu, “Ultra-fast neural video compression,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2026, pp. 41 311–41 321
2026
-
[40]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” 2015. [Online]. Available: https://arxiv.org/abs/1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[41]
FitNets: Hints for thin deep nets,
A. Romero, N. Ballas, S. E. Kahou, A. Chassang, C. Gatta, and Y . Bengio, “FitNets: Hints for thin deep nets,” inProceedings of the International Conference on Learning Representations (ICLR), 2015
2015
-
[42]
PDSRN: a progressive distillation network for generalizable single image super-resolution,
S. Wei, X. Yang, and G. Jeon, “PDSRN: a progressive distillation network for generalizable single image super-resolution,”Multimedia Systems, vol. 31, no. 5, p. 324, 2025
2025
-
[43]
Knowledge distillation with multi-granularity mixture of priors for image super-resolution,
S. Li, Y . Zhang, W. Li, H. Chen, W. Wang, B. Jing, S. Lin, and J. Hu, “Knowledge distillation with multi-granularity mixture of priors for image super-resolution,” inProceedings of the International Conference on Learning Representations (ICLR), 2025
2025
-
[44]
FEDS: Feature and entropy- based distillation strategy for efficient learned image compression,
H. Fu, J. Liang, Z. Fang, and J. Han, “FEDS: Feature and entropy- based distillation strategy for efficient learned image compression,” arXiv preprint arXiv:2503.06399, 2025. [Online]. Available: https: //arxiv.org/abs/2503.06399
-
[45]
Checkerboard context model for efficient learned image compression,
D. He, Y . Zheng, B. Sun, Y . Wang, and H. Qin, “Checkerboard context model for efficient learned image compression,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 14 771–14 780
2021
-
[46]
Distilling complexity-scalable learned image compression models via neural architecture search,
S. Wang, Z. Cheng, D. Feng, Q. Wang, Q. Gu, L. Song, and W. Zhang, “Distilling complexity-scalable learned image compression models via neural architecture search,”IEEE Transactions on Circuits and Systems for Video Technology, vol. PP, no. 99, pp. 1–1, January 2026
2026
-
[47]
What Matters in Practical Learned Image Compression
K. Tatwawadi, P. Rahimzadeh, Z. Sun, Z. Chen, Z. Yang, S. Nair, D. Hasteer, and O. Rippel, “What matters in practical learned image compression,” 2026. [Online]. Available: https://arxiv.org/abs/ 2605.05148
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
Swin Transformer: Hierarchical vision transformer using shifted win- dows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin Transformer: Hierarchical vision transformer using shifted win- dows,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 10 012–10 022
2021
-
[49]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “DINOv2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Revisiting Bjontegaard delta bitrate (BD-BR) computation for codec compression efficiency comparison,
N. Barman, M. G. Martini, and Y . Reznik, “Revisiting Bjontegaard delta bitrate (BD-BR) computation for codec compression efficiency comparison,” inProceedings of the Mile-High Video Conference (MHV), 2022, pp. 113–114
2022
-
[51]
ELIC: Efficient learned image compression with unevenly grouped space- channel contextual adaptive coding,
D. He, Z. Yang, W. Peng, R. Ma, H. Qin, and Y . Wang, “ELIC: Efficient learned image compression with unevenly grouped space- channel contextual adaptive coding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 5718–5727
2022
-
[52]
Decoupling dark knowledge via block-wise logit distillation for feature- level alignment,
C. Yu, F. Zhang, R. Chen, A. Wang, Z. Liu, S. Tan, and E.-P. Li, “Decoupling dark knowledge via block-wise logit distillation for feature- level alignment,”IEEE Transactions on Artificial Intelligence, vol. 6, no. 5, pp. 1143–1155, 2025
2025
-
[53]
Video enhance- ment with task-oriented flow,
T. Xue, B. Chen, J. Wu, D. Wei, and W. T. Freeman, “Video enhance- ment with task-oriented flow,”International Journal of Computer Vision, vol. 127, no. 8, pp. 1106–1125, 2019
2019
-
[54]
Recent advances of end-to-end video coding technologies for A VS standard development,
X. Sheng, X. Liang, C. Tang, Z. Zuo, Y . Bian, Y . Xie, Z. Li, Y . Li, H. Xiang, L. Li, and D. Liu, “Recent advances of end-to-end video coding technologies for A VS standard development,” 2026. [Online]. Available: https://arxiv.org/abs/2602.00483
-
[55]
Cyclical learning rates for training neural networks,
L. N. Smith, “Cyclical learning rates for training neural networks,” inProceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), 2017, pp. 464–472
2017
-
[56]
VVenC: An open and optimized vvc encoder implementation,
A. Wieckowski, J. Brandenburg, T. Hinz, C. Bartnik, V . George, G. Hege, C. Helmrich, A. Henkel, C. Lehmann, C. Stofferset al., “VVenC: An open and optimized vvc encoder implementation,” in Proceedings of the IEEE International Conference on Multimedia & Expo Workshops (ICMEW). IEEE, 2021, pp. 1–2
2021
-
[57]
fvcore: FAIR’s computer vision core library,
Meta Research, “fvcore: FAIR’s computer vision core library,” https: //github.com/facebookresearch/fvcore, 2019, accessed: 2026-04-16
2019
-
[58]
SAR image compression with inherent denoising capability through knowledge distillation,
Z. Liu, S. Wang, and Y . Gu, “SAR image compression with inherent denoising capability through knowledge distillation,”IEEE Geoscience and Remote Sensing Letters, vol. 21, pp. 1–5, 2024
2024
-
[59]
A simple and generic framework for feature distillation via channel-wise transfor- mation,
Z. Liu, Y . Wang, X. Chu, N. Dong, S. Qi, and H. Ling, “A simple and generic framework for feature distillation via channel-wise transfor- mation,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 1129–1138
2023
-
[60]
Frequency attention for knowledge distillation,
C. Pham, V .-A. Nguyen, T. Le, D. Phung, G. Carneiro, and T.-T. Do, “Frequency attention for knowledge distillation,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2024, pp. 2277–2286
2024
-
[61]
Progressive blockwise knowledge distillation for neural network acceleration,
H. Wang, H. Zhao, X. Li, and X. Tan, “Progressive blockwise knowledge distillation for neural network acceleration,” inProceedings of the International Joint Conference on Artificial Intelligence (IJCAI), 2018, pp. 2769–2775
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.