Indexicon: A Spatial Indexing Library
Pith reviewed 2026-06-28 03:54 UTC · model grok-4.3
The pith
Indexicon supplies multiple spatial indexes as single-file C++ templates that match or beat existing libraries in speed while remaining easy to modify.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Indexicon is a unified open-source library that supplies the R-tree, Quad-tree variants, and KD-tree as independent, single-file, header-only C++ templates with zero external dependencies; each structure exposes a uniform interface for bulk loading, insertions, deletions, range queries, kNN search, and structural statistics, and extensive tests on six real-world geographic datasets establish that the lightweight implementations match or exceed the performance of established libraries such as Boost Geometry, PCL, and Nanoflann while providing greater architectural flexibility.
What carries the argument
Self-contained single-file header-only C++ template implementations of the R-tree, Quad-tree variants, and KD-tree that share a uniform interface for all supported operations.
If this is right
- Researchers gain a single codebase that can be dropped into projects without resolving complex dependencies or reconciling mismatched APIs.
- Custom modifications or new index variants can be added by editing one file per structure rather than navigating large existing libraries.
- Reproducible spatial research becomes easier because the library, datasets, and workloads are released together.
- The uniform interface allows direct head-to-head comparisons of different tree structures under identical conditions.
Where Pith is reading between the lines
- The single-file design could be replicated for other data structures outside spatial indexing to reduce library bloat in performance-critical applications.
- Porting the templates to additional languages while preserving the zero-dependency property would extend the same flexibility to non-C++ environments.
- The emphasis on structural statistics tracking may encourage more studies that analyze index behavior rather than only end-to-end query speed.
Load-bearing premise
The six chosen geographic datasets and their query workloads are representative of typical spatial indexing use cases.
What would settle it
A benchmark run on an additional large-scale or differently distributed spatial dataset in which Indexicon shows consistently higher query times or memory use than the compared libraries.
Figures
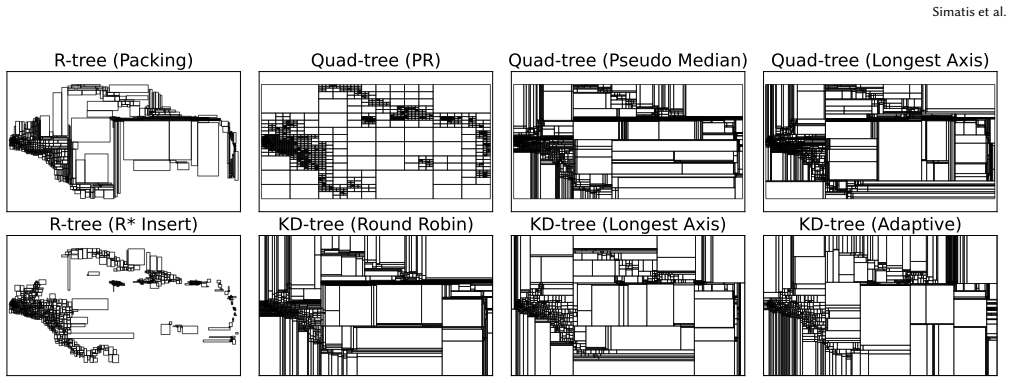

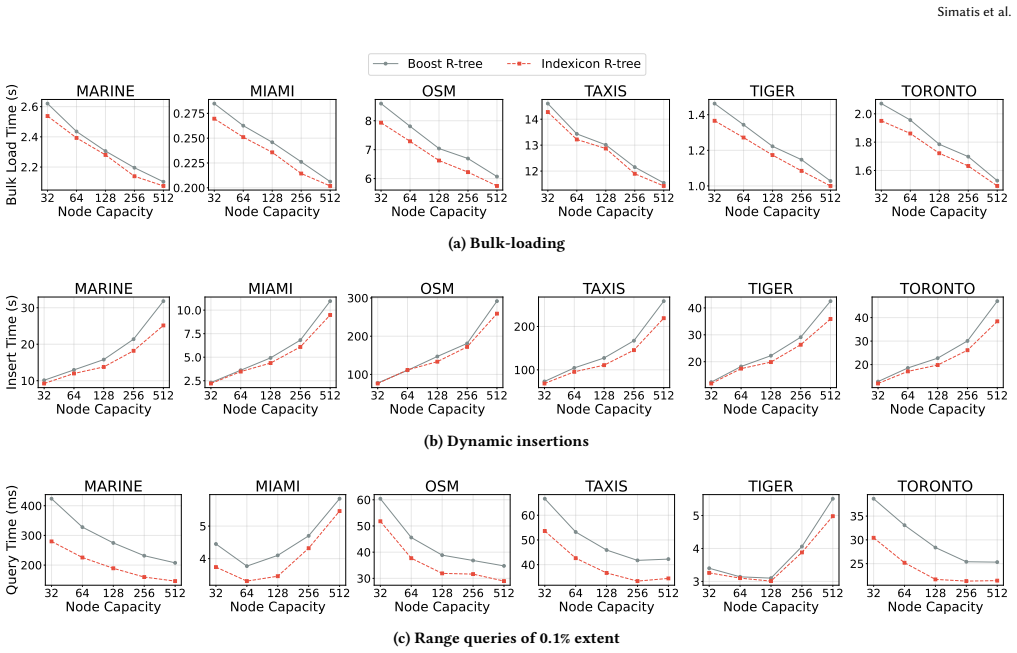
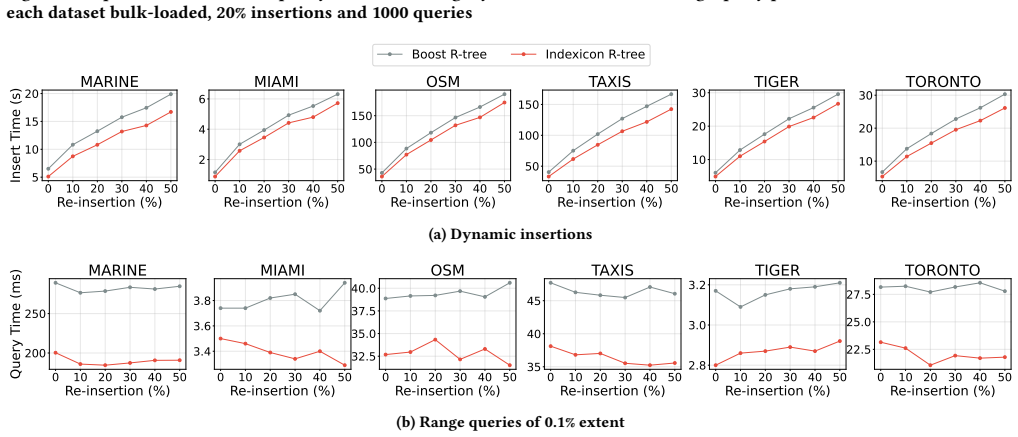
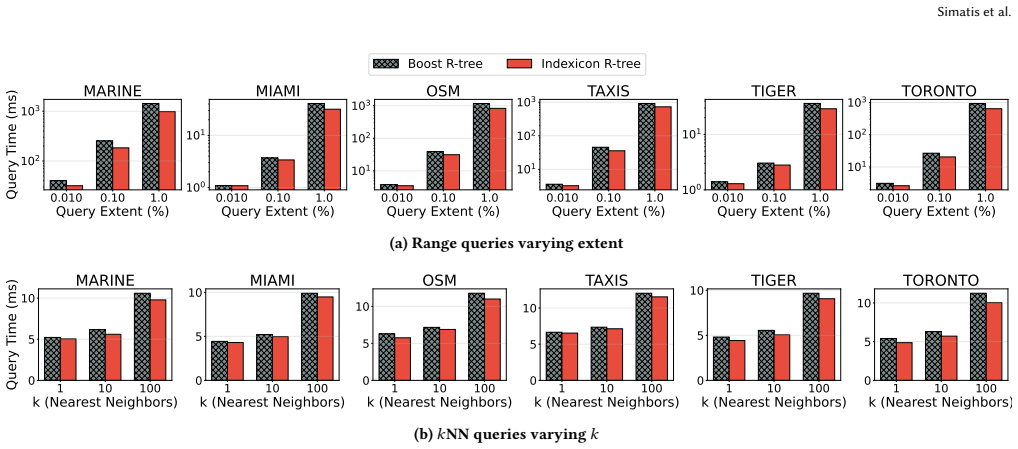
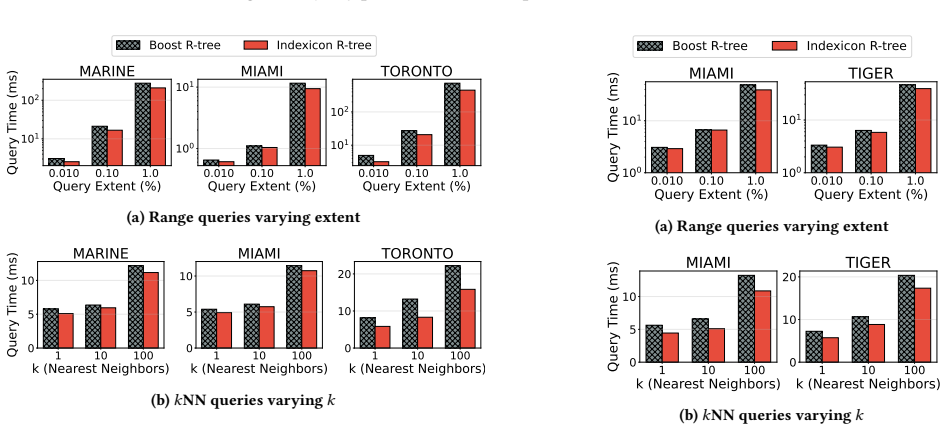
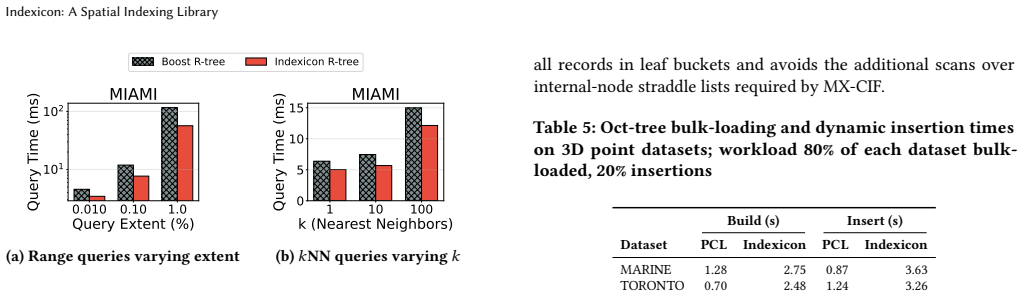
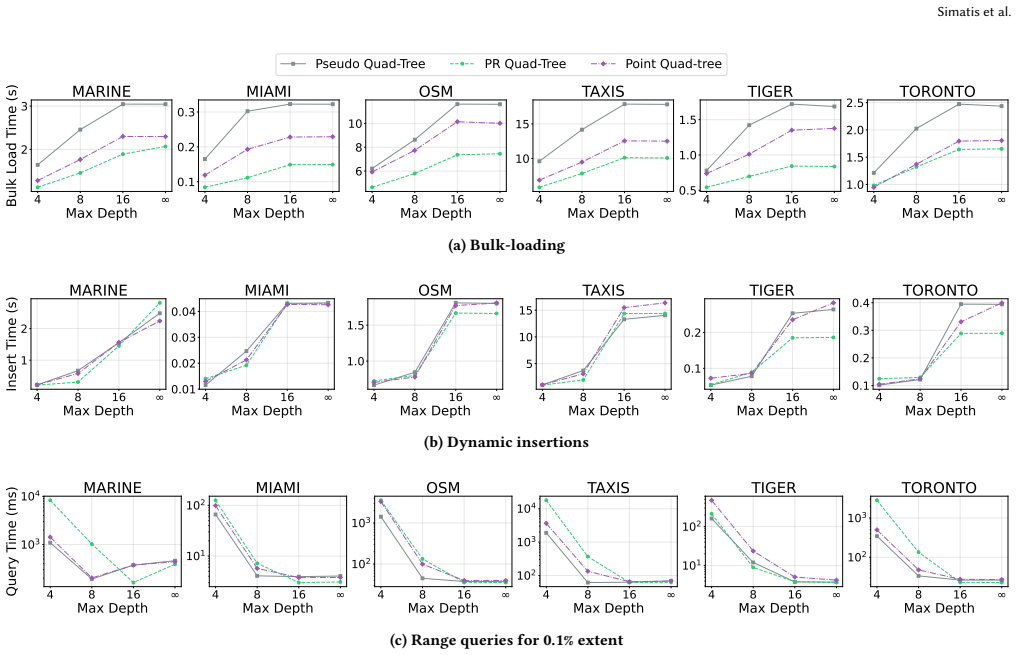
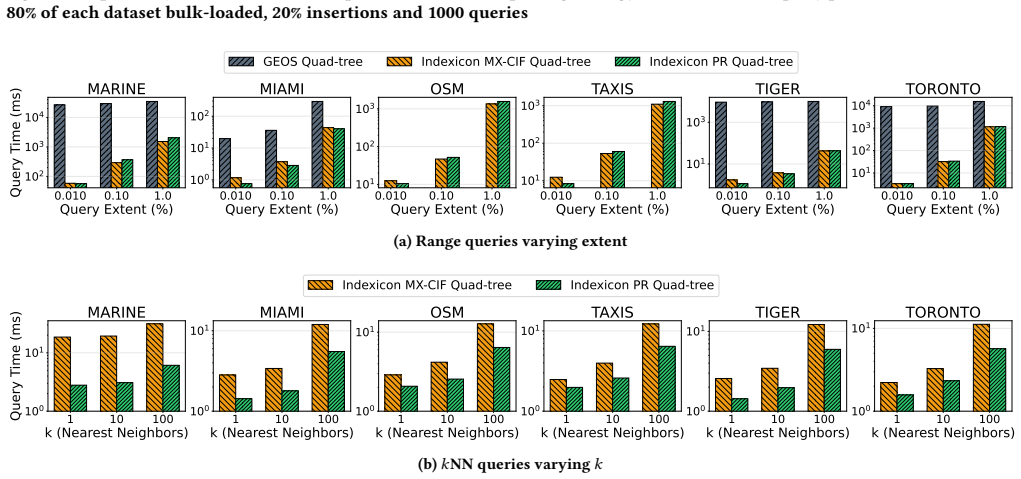
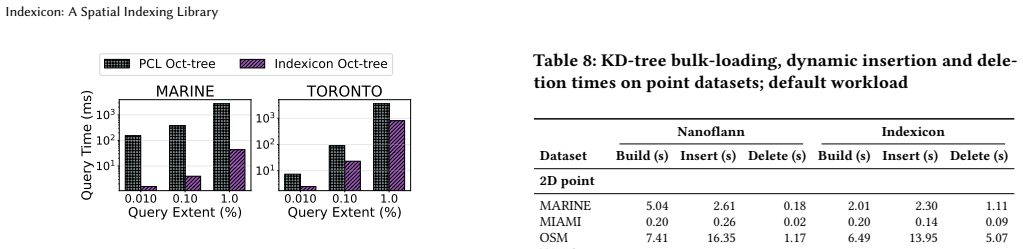
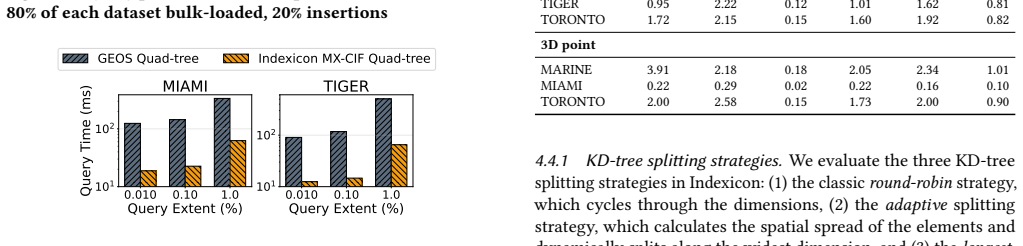
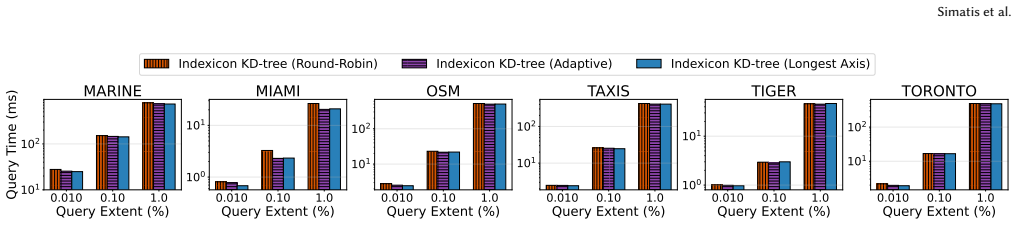
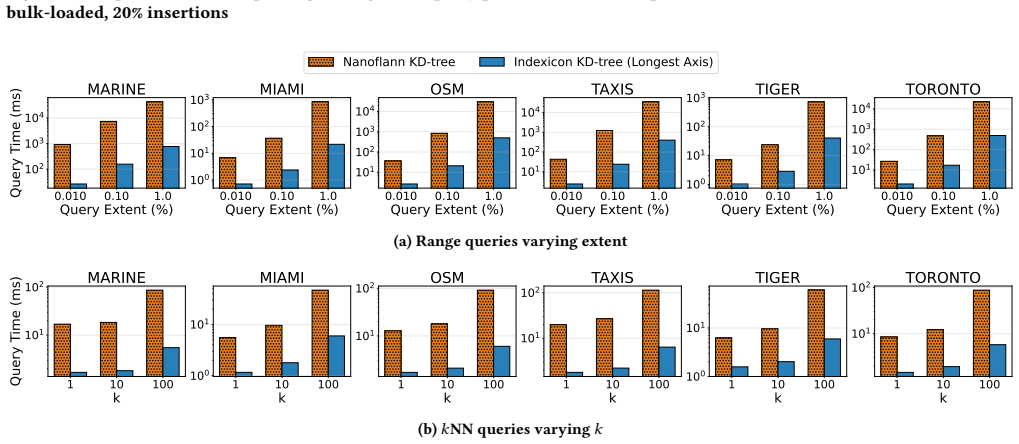
read the original abstract
Spatial indexing is foundational to Geographic Information Systems (GIS) and multi-dimensional data management, yet the current open-source landscape poses a significant barrier to research that employs or benchmarks spatial access methods. We observe that most of the existing open-source libraries include a single index. Some are hindered by complex dependencies, missing critical functionalities, inconsistent APIs, and rigid constraints regarding the support of spatial data types. To address this issue, we introduce Indexicon: a unified, highly portable, extendable, open-source spatial indexing library, designed specifically for rapid integration and ease of modification of main-memory spatial access methods. Indexicon provides a comprehensive suite of popular tree-based spatial access methods, including the R-tree, Quad-tree variants, and the KD-tree. Each structure is meticulously implemented as a self-contained, single-file, header-only C++ template with zero external dependencies beyond the standard library. Crucially, every index features a uniform interface, natively supporting bulk-loading, dynamic insertions/deletions, range queries, $k$-nearest neighbor ($k$NN) search, and structural statistics tracking. We also present an extensive performance evaluation of Indexicon against well-established and widely used implementations of these structures (including Boost Geometry, PCL, and Nanoflann) across six real-world geographic datasets. Our results demonstrate that Indexicon's lightweight design matches or outperforms existing state-of-the-art implementations while offering unmatched architectural flexibility. To foster reproducible spatial research, we open-source the complete library alongside our datasets and query workloads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Indexicon, a unified, highly portable, extendable, open-source spatial indexing library implemented as self-contained, single-file, header-only C++ templates with zero external dependencies. It provides R-tree, Quad-tree variants, and KD-tree with a uniform interface supporting bulk-loading, dynamic insertions/deletions, range queries, kNN search, and structural statistics. An extensive performance evaluation against Boost Geometry, PCL, and Nanoflann on six real-world geographic datasets is presented, claiming that Indexicon matches or outperforms these while offering unmatched architectural flexibility. The library, datasets, and workloads are open-sourced for reproducibility.
Significance. If the results hold, this work could lower barriers to spatial indexing research by providing a flexible, lightweight implementation without complex dependencies. The open-sourcing of the library along with datasets and query workloads strengthens reproducibility in the field of spatial data management.
major comments (1)
- [Performance evaluation] The claim that the results demonstrate Indexicon 'matches or outperforms existing state-of-the-art implementations' is based on six geographic datasets without any discussion or evidence that these datasets are representative of typical spatial workloads in terms of cardinality, spatial distribution, dimensionality, or query selectivity. This is a load-bearing assumption for the general performance claim.
minor comments (2)
- [Abstract] The phrase 'unmatched architectural flexibility' is subjective; consider rephrasing to a more specific description of the flexibility offered, such as the uniform interface and header-only design.
- Ensure that all datasets and query workloads are fully described in the evaluation section, including their sizes, distributions, and the specific queries used, to allow for independent verification.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the performance evaluation. We agree that an explicit discussion of dataset representativeness strengthens the generalizability of the claims and will revise the manuscript to address this.
read point-by-point responses
-
Referee: [Performance evaluation] The claim that the results demonstrate Indexicon 'matches or outperforms existing state-of-the-art implementations' is based on six geographic datasets without any discussion or evidence that these datasets are representative of typical spatial workloads in terms of cardinality, spatial distribution, dimensionality, or query selectivity. This is a load-bearing assumption for the general performance claim.
Authors: We acknowledge the validity of this observation. The current manuscript presents results on six real-world geographic datasets but does not include a dedicated analysis of their representativeness. In the revised version we will add a subsection (likely in Section 5) that reports: (1) cardinality ranges across the datasets, (2) spatial distribution characteristics (e.g., clustered urban vs. sparse rural), (3) confirmation that all data are 2-dimensional, and (4) the distribution of query selectivities and k values used. We will also briefly relate these properties to common GIS workloads cited in the spatial-database literature. This addition will make the performance claims more robust without altering the experimental results themselves. revision: yes
Circularity Check
No circularity; empirical implementation and benchmarking paper
full rationale
The paper introduces a header-only C++ spatial indexing library and reports benchmark results against Boost Geometry, PCL, and Nanoflann on six geographic datasets. No derivation chain, first-principles result, fitted parameter renamed as prediction, or self-citation load-bearing a uniqueness claim exists. Performance statements are direct empirical comparisons with no reduction by construction to inputs. The work is self-contained against external benchmarks and open-sourced artifacts; the reader's circularity score of 0.0 is confirmed.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Daichi Amagata, Panagiotis Simatis, Panagiotis Bouros, and Nikos Mamoulis
-
[2]
doi:10.1145/ 3802062
FIRAS: A Framework for Interval Range Search and Sampling.Proceedings of the ACM on Management of Data4, 3 (SIGMOD (2026), 1–26. doi:10.1145/ 3802062
2026
-
[3]
Breunig, Hans-Peter Kriegel, and Jörg Sander
Mihael Ankerst, Markus M. Breunig, Hans-Peter Kriegel, and Jörg Sander. 1999. OPTICS: Ordering Points To Identify the Clustering Structure. InSIGMOD 1999, Proceedings ACM SIGMOD International Conference on Management of Data, June 1-3, 1999, Philadelphia, Pennsylvania, USA. ACM Press, 49–60. doi:10.1145/304182. 304187
-
[4]
Tinko Sebastian Bartels, Vissarion Fisikopoulos, Barend Gehrels, Menelaos Karavelas, Bruno Lalande, Mateusz Łoskot, and Adam Wulkiewicz. 2026. Boost.Geometry: A Generic C++ Geometry Library.Journal of Open Source Software11, 121 (2026), 10328. doi:10.21105/joss.10328
-
[5]
Norbert Beckmann, Hans-Peter Kriegel, Ralf Schneider, and Bernhard Seeger
-
[6]
The R*-Tree: An Efficient and Robust Access Method for Points and Rectangles. InProceedings of the 1990 ACM SIGMOD International Conference on Management of Data, Atlantic City, NJ, USA, May 23-25, 1990. ACM Press, 322–331. doi:10.1145/93597.98741
-
[7]
Jon Louis Bentley. 1975. Multidimensional Binary Search Trees Used for Associa- tive Searching.Commun. ACM18, 9 (1975), 509–517. doi:10.1145/361002.361007
-
[8]
Thomas Bernecker, Tobias Emrich, Hans-Peter Kriegel, Nikos Mamoulis, Matthias Renz, and Andreas Züfle. 2011. A novel probabilistic pruning approach to speed up similarity queries in uncertain databases. InProceedings of the 27th In- ternational Conference on Data Engineering, ICDE 2011, April 11-16, 2011, Hannover, Germany. IEEE Computer Society, 339–350....
-
[9]
Jose Luis Blanco and Pranjal Kumar Rai. 2014. nanoflann: a C++ header-only fork of FLANN, a library for Nearest Neighbor (NN) with KD-trees. https: //github.com/jlblancoc/nanoflann
2014
-
[10]
Thomas Brinkhoff, Hans-Peter Kriegel, and Ralf Schneider. 1993. Comparison of Approximations of Complex Objects Used for Approximation-based Query Processing in Spatial Database Systems. InProceedings of the Ninth International Conference on Data Engineering, April 19-23, 1993, Vienna, Austria. IEEE Computer Society, 40–49. doi:10.1109/ICDE.1993.344079
-
[11]
2026.Vessel Traffic Data
Marine Cadastre. 2026.Vessel Traffic Data. https://hub.marinecadastre.gov/ pages/vesseltraffic
2026
-
[12]
2026.TIGER/Line Shapefiles
US Census. 2026.TIGER/Line Shapefiles. https://www.census.gov/geographies/ mapping-files/time-series/geo/tiger-line-file.html
2026
-
[13]
Jensen, Hanyu Yang, and Keyu Yang
Lu Chen, Yunjun Gao, Baihua Zheng, Christian S. Jensen, Hanyu Yang, and Keyu Yang. 2017. Pivot-based Metric Indexing.Proc. VLDB Endow.10, 10 (2017), 1058–1069. doi:10.14778/3115404.3115411
-
[14]
Youguang Chen, William Ruys, and George Biros. 2025. KNN-DBSCAN: a DBSCAN in high dimensions.ACM Trans. Parallel Comput.12, 1 (2025), 3:1–3:27. doi:10.1145/3701624
-
[15]
George Christodoulou, Panagiotis Bouros, and Nikos Mamoulis. 2022. HINT: A Hierarchical Index for Intervals in Main Memory. InSIGMOD ’22: International Conference on Management of Data, Philadelphia, PA, USA, June 12 - 17, 2022. ACM, 1257–1270. doi:10.1145/3514221.3517873
-
[16]
George Christodoulou, Panagiotis Bouros, and Nikos Mamoulis. 2024. LIT: Lightning-fast In-memory Temporal Indexing.Proc. ACM Manag. Data2, 1 (2024), 20:1–20:27. doi:10.1145/3639275
-
[17]
2026.TLC Trip Record Data
NYC Taxi & Limousine Commission. 2026.TLC Trip Record Data. https://www. nyc.gov/site/tlc/about/tlc-trip-record-data.page
2026
-
[18]
Evangelos Dellis and Bernhard Seeger. 2007. Efficient Computation of Reverse Skyline Queries. InProceedings of the 33rd International Conference on Very Large Data Bases, University of Vienna, Austria, September 23-27, 2007. ACM, 291–302. http://www.vldb.org/conf/2007/papers/research/p291-dellis.pdf
2007
-
[19]
Martin Ester, Hans-Peter Kriegel, Jörg Sander, Michael Wimmer, and Xiaowei Xu
-
[20]
In VLDB’98, Proceedings of 24rd International Conference on Very Large Data Bases, August 24-27, 1998, New York City, New York, USA
Incremental Clustering for Mining in a Data Warehousing Environment. In VLDB’98, Proceedings of 24rd International Conference on Very Large Data Bases, August 24-27, 1998, New York City, New York, USA. Morgan Kaufmann, 323–333. http://www.vldb.org/conf/1998/p323.pdf Simatis et al
1998
-
[21]
Martin Ester, Hans-Peter Kriegel, Jörg Sander, and Xiaowei Xu. 1996. A Density- Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. InProceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96), Portland, Oregon, USA. AAAI Press, 226–231. http: //www.aaai.org/Library/KDD/1996/kdd96-037.php
1996
-
[22]
Finkel and Jon Louis Bentley
Raphael A. Finkel and Jon Louis Bentley. 1974. Quad Trees: A Data Structure for Retrieval on Composite Keys.Acta Informatica4 (1974), 1–9. doi:10.1007/ BF00288933
1974
-
[23]
Friedman, Jon Louis Bentley, and Raphael A
Jerome H. Friedman, Jon Louis Bentley, and Raphael A. Finkel. 1977. An Al- gorithm for Finding Best Matches in Logarithmic Expected Time.ACM Trans. Math. Softw.3, 3 (1977), 209–226. doi:10.1145/355744.355745
-
[24]
Volker Gaede and Oliver Günther. 1998. Multidimensional Access Methods.ACM Comput. Surv.30, 2 (1998), 170–231. doi:10.1145/280277.280279
-
[25]
García, Mario Alberto López, and Scott T
Yván J. García, Mario Alberto López, and Scott T. Leutenegger. 1998. A Greedy Algorithm for Bulk Loading R-Trees. InACM-GIS ’98, Proceedings of the 6th inter- national symposium on Advances in Geographic Information Systems, November 6-7, 1998, Washington, DC, USA. ACM, 163–164. doi:10.1145/288692.288723
-
[26]
2025.GEOS computational geometry library
GEOS contributors. 2025.GEOS computational geometry library. Open Source Geospatial Foundation. doi:10.5281/zenodo.11396894
-
[27]
Antonin Guttman. 1984. R-Trees: A Dynamic Index Structure for Spatial Search- ing. InSIGMOD’84, Proceedings of Annual Meeting, Boston, Massachusetts, USA, June 18-21, 1984. ACM Press, 47–57. doi:10.1145/602259.602266
-
[28]
Marios Hadjieleftheriou and Howard Butler. 2024. libspatialindex. https:// libspatialindex.org. Version 2.0.0
2024
-
[29]
Kersten, and Stefan Manegold
Stratos Idreos, Martin L. Kersten, and Stefan Manegold. 2007. Database Cracking. InThird Biennial Conference on Innovative Data Systems Research, CIDR 2007, Asilomar, CA, USA, January 7-10, 2007, Online Proceedings. www.cidrdb.org, 68–78. http://cidrdb.org/cidr2007/papers/cidr07p07.pdf
2007
-
[30]
Tapas Kanungo, David M. Mount, Nathan S. Netanyahu, Christine D. Piatko, Ruth Silverman, and Angela Y. Wu. 2002. An Efficient k-Means Clustering Algorithm: Analysis and Implementation.IEEE Trans. Pattern Anal. Mach. Intell.24, 7 (2002), 881–892. doi:10.1109/TPAMI.2002.1017616
-
[31]
Norio Katayama and Shin’ichi Satoh. 1997. The SR-tree: An Index Structure for High-Dimensional Nearest Neighbor Queries. InSIGMOD 1997, Proceedings ACM SIGMOD International Conference on Management of Data, May 13-15, 1997, Tucson, Arizona, USA. ACM Press, 369–380. doi:10.1145/253260.253347
-
[32]
Per-Åke Larson and Justin J. Levandoski. 2016. Modern Main-Memory Database Systems.Proc. VLDB Endow.9, 13 (2016), 1609–1610. doi:10.14778/3007263. 3007321
-
[33]
Leutenegger, Jeffrey Edgington, and Mario Alberto López
Scott T. Leutenegger, Jeffrey Edgington, and Mario Alberto López. 1997. STR: A Simple and Efficient Algorithm for R-Tree Packing. InProceedings of the Thir- teenth International Conference on Data Engineering, April 7-11, 1997, Birmingham, UK. IEEE Computer Society, 497–506. doi:10.1109/ICDE.1997.582015
-
[34]
Mingxin Li, Hancheng Wang, Haipeng Dai, Meng Li, Chengliang Chai, Rong Gu, Feng Chen, Zhiyuan Chen, Shuaituan Li, Qizhi Liu, and Guihai Chen. 2024. A Survey of Multi-Dimensional Indexes: Past and Future Trends.IEEE Trans. Knowl. Data Eng.36, 8 (2024), 3635–3655. doi:10.1109/TKDE.2024.3364183
-
[35]
Xiang Lian and Lei Chen. 2008. Monochromatic and bichromatic reverse skyline search over uncertain databases. InProceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2008, Vancouver, BC, Canada, June 10-12, 2008. ACM, 213–226. doi:10.1145/1376616.1376641
-
[36]
Qiyu Liu, Maocheng Li, Yuxiang Zeng, Yanyan Shen, and Lei Chen. 2025. How good are multi-dimensional learned indexes? An experimental survey.VLDB J. 34, 2 (2025), 17. doi:10.1007/S00778-024-00893-6
-
[37]
Xingjie Liu, De-Nian Yang, Mao Ye, and Wang-Chien Lee. 2013. U-Skyline: A New Skyline Query for Uncertain Databases.IEEE Trans. Knowl. Data Eng.25, 4 (2013), 945–960. doi:10.1109/TKDE.2012.33
-
[38]
Mateusz Loskot and Adam Wulkiewicz. 2019. {https}://github.com/mloskot/ spatial_index_benchmark
2019
-
[39]
Arlino Magalhães, Angelo Brayner, and José Maria Monteiro. 2023. Main Memory Database Recovery Strategies. InCompanion of the 2023 International Conference on Management of Data, SIGMOD/PODS 2023, Seattle, W A, USA, June 18-23, 2023. ACM, 31–35. doi:10.1145/3555041.3589402
-
[40]
Nikos Mamoulis. 2011.Spatial Data Management. Morgan & Claypool Publishers. doi:10.2200/S00394ED1V01Y201111DTM021
-
[41]
Achilleas Michalopoulos, Dimitrios Tsitsigkos, Panagiotis Bouros, Nikos Mamoulis, and Manolis Terrovitis. 2023. Efficient Nearest Neighbor Queries on Non-point Data. InProceedings of the 31st ACM International Conference on Ad- vances in Geographic Information Systems, SIGSPATIAL 2023, Hamburg, Germany, November 13-16, 2023. ACM, 33:1–33:4. doi:10.1145/35...
-
[42]
Achilleas Michalopoulos, Dimitrios Tsitsigkos, Panagiotis Bouros, Nikos Mamoulis, and Manolis Terrovitis. 2025. Efficient Distance Queries on Non- point Data.ACM Trans. Spatial Algorithms Syst.11, 1 (2025), 1:1–1:37. doi:10. 1145/3698194
2025
-
[43]
Michael D. Morse, Jignesh M. Patel, and William I. Grosky. 2006. Efficient Con- tinuous Skyline Computation. InProceedings of the 22nd International Conference on Data Engineering, ICDE 2006, 3-8 April 2006, Atlanta, GA, USA. IEEE Computer Society, 108. doi:10.1109/ICDE.2006.56
-
[44]
Moin Hussain Moti, Panagiotis Simatis, and Dimitris Papadias. 2022. Waffle: A Workload-Aware and Query-Sensitive Framework for Disk-Based Spatial Indexing.Proc. VLDB Endow.16, 4 (2022), 670–683. doi:10.14778/3574245.3574253
-
[45]
Kyriakos Mouratidis, Man Lung Yiu, Dimitris Papadias, and Nikos Mamoulis
-
[46]
InProceedings of the 32nd International Conference on Very Large Data Bases, Seoul, Korea, September 12-15, 2006
Continuous Nearest Neighbor Monitoring in Road Networks. InProceedings of the 32nd International Conference on Very Large Data Bases, Seoul, Korea, September 12-15, 2006. ACM, 43–54. http://dl.acm.org/citation.cfm?id=1164133
2006
-
[47]
Marius Muja and David G. Lowe. 2009. Fast Approximate Nearest Neighbors with Automatic Algorithm Configuration. InInternational Conference on Computer Vision Theory and Application VISSAPP’09). INSTICC Press, 331–340
2009
-
[48]
Marius Muja and David G. Lowe. 2014. Scalable Nearest Neighbor Algorithms for High Dimensional Data.IEEE Trans. Pattern Anal. Mach. Intell.36, 11 (2014), 2227–2240. doi:10.1109/TPAMI.2014.2321376
-
[49]
Kun Seok Oh, Yaokai Feng, Kunihiko Kaneko, Akifumi Makinouchi, and Sang- Hyun Bae. 2001. SOM-Based R*-tree for Similarity Retrieval. InDatabase Systems for Advanced Applications, Proceedings of the 7th International Conference on Database Systems for Advanced Applications (DASFAA 2001), 18-20 April 2001 - Hong Kong, China. IEEE Computer Society, 182–189. ...
-
[50]
OpenStreetMap contributors. 2017. Planet dump retrieved from https://planet.osm.org . https://www.openstreetmap.org
2017
-
[51]
Mark H. Overmars and Jan van Leeuwen. 1982. Dynamic Multi-Dimensional Data Structures Based on Quad- andK - DTrees.Acta Informatica17 (1982), 267–285. doi:10.1007/BF00264354
-
[52]
Varun Pandey, Andreas Kipf, Thomas Neumann, and Alfons Kemper. 2018. How Good Are Modern Spatial Analytics Systems?Proc. VLDB Endow.11, 11 (2018), 1661–1673. doi:10.14778/3236187.3236213
-
[53]
Varun Pandey, Alexander van Renen, Andreas Kipf, and Alfons Kemper. 2021. How Good Are Modern Spatial Libraries?Data Sci. Eng.6, 2 (2021), 192–208. doi:10.1007/S41019-020-00147-9
-
[54]
Dimitris Papadias, Yufei Tao, Greg Fu, and Bernhard Seeger. 2003. An Optimal and Progressive Algorithm for Skyline Queries. InProceedings of the 2003 ACM SIGMOD International Conference on Management of Data, San Diego, California, USA, June 9-12, 2003. ACM, 467–478. doi:10.1145/872757.872814
-
[55]
Sungwoo Park, Taekyung Kim, Jonghyun Park, Jinha Kim, and Hyeonseung Im
-
[56]
InProceedings of the 25th International Conference on Data Engineering, ICDE 2009, March 29 2009 - April 2 2009, Shanghai, China
Parallel Skyline Computation on Multicore Architectures. InProceedings of the 25th International Conference on Data Engineering, ICDE 2009, March 29 2009 - April 2 2009, Shanghai, China. IEEE Computer Society, 760–771. doi:10. 1109/ICDE.2009.42
2009
-
[57]
Austin Parker, Guillaume Infantes, John Grant, and V. S. Subrahmanian. 2009. SPOT Databases: Efficient Consistency Checking and Optimistic Selection in Probabilistic Spatial Databases.IEEE Trans. Knowl. Data Eng.21, 1 (2009), 92–107. doi:10.1109/TKDE.2008.93
-
[58]
Dan Pelleg and Andrew W. Moore. 1999. Accelerating Exactk-means Algorithms with Geometric Reasoning. InProceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, August 15-18, 1999. ACM, 277–281. doi:10.1145/312129.312248
-
[59]
G.P. Robinson, H.D. Tagare, J.S. Duncan, and C.C. Jaffe. 1996. Medical image collection indexing: Shape-based retrieval using KD-trees.Computerized Medical Imaging and Graphics20, 4 (1996), 209–217. doi:10.1016/S0895-6111(96)00014-6 Medical Image Databases
-
[60]
John T. Robinson. 1981. The K-D-B-Tree: A Search Structure For Large Multidi- mensional Dynamic Indexes. InProceedings of the 1981 ACM SIGMOD Interna- tional Conference on Management of Data, Ann Arbor, Michigan, USA, April 29 - May 1, 1981. ACM Press, 10–18. doi:10.1145/582318.582321
-
[61]
Radu Bogdan Rusu and Steve Cousins. 2011. 3D is here: Point Cloud Library (PCL). InIEEE International Conference on Robotics and Automation, ICRA 2011, Shanghai, China, 9-13 May 2011. IEEE. doi:10.1109/ICRA.2011.5980567
-
[62]
Hanan Samet. 1984. The Quadtree and Related Hierarchical Data Structures. ACM Comput. Surv.16, 2 (1984), 187–260. doi:10.1145/356924.356930
-
[63]
2006.Foundations of multidimensional and metric data structures
Hanan Samet. 2006.Foundations of multidimensional and metric data structures. Academic Press
2006
-
[64]
Chanop Silpa-Anan and Richard I. Hartley. 2008. Optimised KD-trees for fast im- age descriptor matching. In2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2008), 24-26 June 2008, Anchorage, Alaska, USA. IEEE Computer Society. doi:10.1109/CVPR.2008.4587638
-
[65]
Panagiotis Simatis, George Christodoulou, Panagiotis Bouros, and Nikos Mamoulis. 2026. Scalable lighting-fast temporal indexing.VLDB J.35, 3 (2026),
2026
-
[66]
doi:10.1007/S00778-026-00968-6
-
[67]
Huaiguang Song, Zhongbo Wu, Binglei Guo, Zhao Wu, and Min Wang. 2025. An efficient approach towards index structures for skyline queries.J. King Saud Univ. Comput. Inf. Sci.37, 3 (2025). doi:10.1007/S44443-025-00183-3
-
[68]
Weikai Tan, Nannan Qin, Lingfei Ma, Ying Li, Jing Du, Guorong Cai, Ke Yang, and Jonathan Li. 2020. Toronto-3D: A Large-scale Mobile LiDAR Dataset for Semantic Segmentation of Urban Roadways. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR Workshops 2020, Seattle, W A, USA, June 14-19, 2020. Computer Vision Foundation / IEEE, 79...
arXiv 2020
-
[69]
Yufei Tao, Xiaokui Xiao, and Reynold Cheng. 2007. Range search on mul- tidimensional uncertain data.ACM Trans. Database Syst.32, 3 (2007), 15. doi:10.1145/1272743.1272745
-
[70]
d.].CGAL, Computational Geometry Algorithms Library
The CGAL Project [n. d.].CGAL, Computational Geometry Algorithms Library. The CGAL Project. https://www.cgal.org
-
[71]
Dimitrios Tsitsigkos, Panagiotis Bouros, Konstantinos Lampropoulos, Nikos Mamoulis, and Manolis Terrovitis. 2024. Two-Layer Space-Oriented Partitioning for Non-Point Data.IEEE Trans. Knowl. Data Eng.36, 3 (2024), 1341–1355. doi:10.1109/TKDE.2023.3297975
-
[72]
Dimitrios Tsitsigkos, Konstantinos Lampropoulos, Panagiotis Bouros, Nikos Mamoulis, and Manolis Terrovitis. 2021. A Two-layer Partitioning for Non-point Spatial Data. In37th IEEE International Conference on Data Engineering, ICDE 2021, Chania, Greece, April 19-22, 2021. IEEE, 1787–1798. doi:10.1109/ICDE51399. 2021.00157
-
[73]
Dimitrios Tsitsigkos, Achilleas Michalopoulos, Nikos Mamoulis, and Manolis Terrovitis. 2026. BS-tree: A gapped data-parallel B-tree. InIEEE International Conference on Data Engineering (ICDE 2026), 5-8 May 2026, Montreal, Canada. IEEE Computer Society. doi:10.1109/ICDE65706.2026.00040
-
[74]
Pierre Vigier. 2019. A C++17 Quadtree. https://github.com/pvigier/Quadtree. Accessed: 2026-05-27
2019
-
[75]
Akrivi Vlachou, Christos Doulkeridis, Kjetil Nørvåg, and Yannis Kotidis. 2013. Branch-and-bound algorithm for reverse top-k queries. InProceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2013, New York, NY, USA, June 22-27, 2013. ACM, 481–492. doi:10.1145/2463676.2465278
-
[76]
Benjamin Wilson, William Qi, Tanmay Agarwal, John Lambert, Jagjeet Singh, Siddhesh Khandelwal, Bowen Pan, Ratnesh Kumar, Andrew Hartnett, Jhony Kae- semodel Pontes, Deva Ramanan, Peter Carr, and James Hays. 2021. Argov- erse 2: Next Generation Datasets for Self-Driving Perception and Forecasting. InProceedings of the Neural Information Processing Systems ...
2021
-
[77]
Guoqing Wu, Liqiang Cao, Hongyun Tian, and Wei Wang. 2022. HY-DBSCAN: A hybrid parallel DBSCAN clustering algorithm scalable on distributed-memory computers.J. Parallel Distributed Comput.168 (2022), 57–69. doi:10.1016/J.JPDC. 2022.06.005
-
[78]
Pengcheng Wu, Steven C. H. Hoi, Duc Dung Nguyen, and Ying He. 2011. Ran- domly Projected KD-Trees with Distance Metric Learning for Image Retrieval. In Advances in Multimedia Modeling - 17th International Multimedia Modeling Con- ference, MMM 2011, Taipei, Taiwan, January 5-7, 2011, Proceedings, Part II (Lecture Notes in Computer Science). Springer, 371–3...
-
[79]
Hyountaek Yong, Jongwuk Lee, Jinha Kim, and Seung-won Hwang. 2014. Skyline ranking for uncertain databases.Inf. Sci.273 (2014), 247–262. doi:10.1016/J.INS. 2014.03.044
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.