SURF: Separation via Unsupervised Remixing Flow
Pith reviewed 2026-06-28 05:04 UTC · model grok-4.3
The pith
An unsupervised flow matching model separates sources from mixtures by remixing teacher estimates to train a student model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SURF shows that source separation can be performed unsupervised by using a remixing step to convert a teacher model's estimates into mixture-consistent training targets for a student flow model, thereby learning the source distribution from mixtures alone and yielding a new state-of-the-art among unsupervised methods on image and audio benchmarks.
What carries the argument
The remixing step that converts teacher estimates into training targets for the student flow model.
If this is right
- The model learns source separation directly from observed mixtures without any clean source data.
- It achieves new state-of-the-art results among unsupervised methods on image and audio benchmarks.
- Supervised training on clean sources becomes unnecessary for reaching high separation quality.
- The approach supplies new insight into objectives optimized by the Wake-Sleep algorithm.
Where Pith is reading between the lines
- The remixing bootstrap could be tested with diffusion models to see whether the same unsupervised gains appear outside flow matching.
- Separation performance in new domains such as video or sensor arrays might improve if the method avoids any need for clean training examples from those domains.
- Iterating the teacher-student loop multiple times, in the spirit of repeated wake-sleep cycles, could be checked for further gains on the same benchmarks.
Load-bearing premise
The remixing step that converts teacher estimates into training targets for the student flow model produces sufficiently accurate supervision signals without introducing systematic bias or collapse.
What would settle it
Training SURF on a standard audio or image separation benchmark and finding that the student model produces no improvement over the teacher or collapses to trivial outputs would show the remixing step fails to supply usable supervision.
Figures
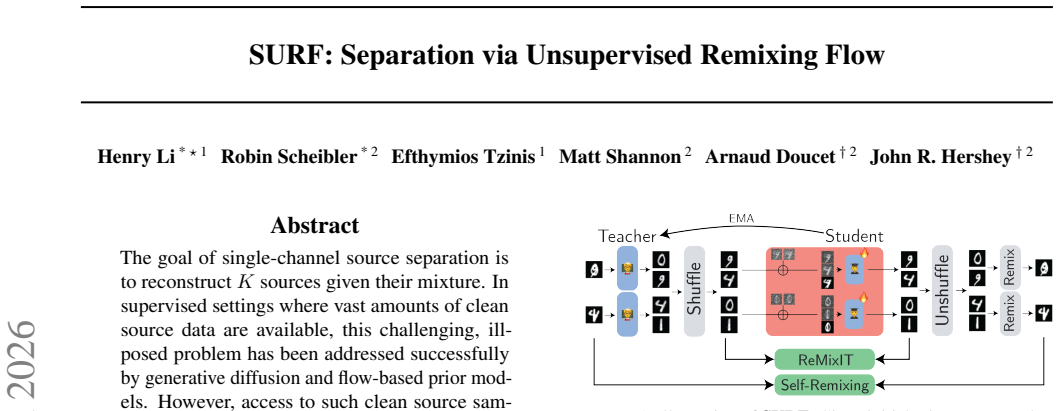
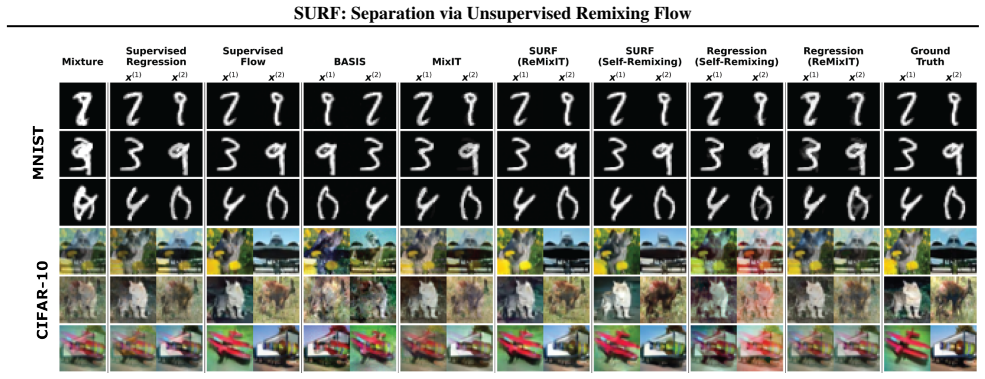




read the original abstract
The goal of single-channel source separation is to reconstruct $K$ sources given their mixture. In supervised settings where vast amounts of clean source data are available, this challenging, ill-posed problem has been addressed successfully by generative diffusion and flow-based prior models. However, access to such clean source samples is often limited, and even when available, supervised models are vulnerable to domain shifts. To bridge this gap, we present Separation via Unsupervised Remixing Flow (SURF), an unsupervised flow matching approach for source separation that learns directly from observed mixtures. This method relies on a novel combination of state-of-the-art supervised flow matching and regression-based self-supervised techniques. At a high level, starting from a teacher model, we utilize a "remixing" step to bootstrap the learning of a student flow model from the teacher's estimates. We provide insights into the objectives optimized by this approach and draw a novel connection to the Wake-Sleep algorithm. Empirical evaluations on image and audio benchmarks demonstrate that SURF establishes a new state-of-the-art, significantly outperforming existing unsupervised methods. See our demo page for examples. https://google.github.io/df-conformer/surf/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SURF, an unsupervised flow-matching method for single-channel source separation. It starts from a teacher model, applies a remixing step to convert the teacher's estimates into training targets for a student flow model, and optimizes a combination of supervised flow matching and regression-based self-supervision. The approach is connected to the Wake-Sleep algorithm, and the authors claim that empirical results on image and audio benchmarks establish a new state-of-the-art among unsupervised methods.
Significance. If the remixing procedure can be shown to yield stable, unbiased targets, the method would offer a practical route to high-quality separation without clean source data, addressing a key limitation of supervised flow-based priors. The explicit connection drawn to Wake-Sleep supplies a useful conceptual bridge between self-supervised regression and generative flow matching.
major comments (2)
- [Abstract / remixing-step description] Abstract and the section describing the teacher-to-student remixing loop: the central unsupervised claim requires that the remixed targets are free of systematic bias and do not induce collapse. No derivation is supplied showing that the fixed point of the combined flow-matching plus regression objective coincides with the true posterior, nor is a stability argument given for the case when the teacher itself is noisy.
- [remixing-step description] The flow-matching loss applied to the remixed targets: in an ill-posed inverse problem any consistent bias present in the teacher estimates will be amplified rather than corrected. The manuscript should supply either a concrete counter-example test or an analysis demonstrating that the procedure remains stable under realistic teacher error.
minor comments (1)
- [Abstract] The abstract states that evaluations were performed on both image and audio benchmarks but does not name the specific datasets or metrics used to support the SOTA claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for stronger theoretical grounding of the remixing procedure. We address each major point below and will revise the manuscript to incorporate additional analysis and empirical tests as outlined.
read point-by-point responses
-
Referee: [Abstract / remixing-step description] Abstract and the section describing the teacher-to-student remixing loop: the central unsupervised claim requires that the remixed targets are free of systematic bias and do not induce collapse. No derivation is supplied showing that the fixed point of the combined flow-matching plus regression objective coincides with the true posterior, nor is a stability argument given for the case when the teacher itself is noisy.
Authors: We agree that a formal derivation of the fixed point and a stability argument for noisy teachers would strengthen the unsupervised claim. The current manuscript provides intuition via the Wake-Sleep connection but does not include such a derivation. In revision we will add a dedicated subsection that analyzes the fixed-point behavior of the combined objective under the assumption of an unbiased teacher and explicitly discusses the limitations when teacher estimates contain systematic noise. We will also report additional diagnostics from our existing experiments confirming the absence of collapse on the evaluated benchmarks. revision: partial
-
Referee: [remixing-step description] The flow-matching loss applied to the remixed targets: in an ill-posed inverse problem any consistent bias present in the teacher estimates will be amplified rather than corrected. The manuscript should supply either a concrete counter-example test or an analysis demonstrating that the procedure remains stable under realistic teacher error.
Authors: This concern is well-taken. We will add to the revised manuscript both a brief theoretical discussion of bias propagation under the joint loss and a new synthetic experiment that injects controlled levels of teacher error (additive Gaussian noise on source estimates) and measures the resulting student performance. This will serve as a concrete stability test under realistic error conditions. revision: yes
Circularity Check
No circularity: derivation relies on external Wake-Sleep connection and empirical benchmarks
full rationale
The abstract and description present SURF as a bootstrap combining supervised flow matching with regression-based self-supervision via remixing, explicitly linked to the established Wake-Sleep algorithm. No equations are supplied that reduce the student objective to a direct redefinition or fit of the teacher outputs by construction, nor are any load-bearing self-citations invoked to justify uniqueness or the remixing operator. The central claims rest on independent empirical results on image and audio benchmarks rather than on any internal definitional closure, satisfying the criteria for a self-contained derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
D’Alembert, J
Le R. D’Alembert, J. , title=
-
[2]
Zhang, Wangyou and Scheibler, Robin and Saijo, Kohei and Cornell, Samuele and Li, Chenda and Ni, Zhaoheng and Kumar, Anurag and Pirklbauer, Jan and Sach, Marvin and Watanabe, Shinji and Fingscheidt, Tim and Qian, Yanmin , month = sep, year =
-
[3]
Denoising Diffusion Probabilistic Models , booktitle = P_NeurIPS, author =
-
[4]
2023 , pages =
Peebles, William and Xie, Saining , title =. 2023 , pages =
2023
-
[5]
Audio Speech Lang
IEEE/ACM Trans. Audio Speech Lang. Process. , author =. 2023 , pages =
2023
-
[6]
2023 , pages =
Analysing Diffusion-based Generative Approaches Versus Discriminative Approaches for Speech Restoration , booktitle = P_ICASSP, author =. 2023 , pages =
2023
-
[7]
Looking to Listen at the Cocktail Party: Audio-visual Speech Separation , author =
-
[8]
Diffusion models for audio restoration: A review
Lemercier, Jean-Marie and Richter, Julius and Welker, Simon and Moliner, Eloi and V \"a lim \"a ki, Vesa and Gerkmann, Timo. Diffusion models for audio restoration: A review. IEEE Signal Process. Mag
-
[9]
ICCV , year=
FlowDPS: Flow-Driven Posterior Sampling for Inverse Problems , author=. ICCV , year=
-
[10]
2006 , pages =
Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks , booktitle = P_ICML, author =. 2006 , pages =
2006
-
[11]
Simple and
Xu, Qiantong and Baevski, Alexei and Auli, Michael , year =. Simple and
-
[12]
Single and
Lay, Bunlong and Lemercier, Jean-Marie and Richter, Julius and Gerkmann, Timo , month = jan, year =. Single and
-
[13]
IEEE/ACM Trans
Speech. IEEE/ACM Trans. Audio Speech Lang. Process. , author =. 2023 , pages =
2023
-
[14]
SEPDIFF : Speech separation based on denoising diffusion model
Chen, Bo and Wu, Chao and Zhao, Wenbin. SEPDIFF : Speech separation based on denoising diffusion model
-
[15]
Diffusion-Based Generative Speech Source Separation , booktitle = P_ICASSP, author =
-
[16]
Dong, Jinwei and Wang, Xinsheng and Mao, Qirong , booktitle=P_ICASSP, title=
-
[17]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle = P_ICLR, month = jan, year =
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle = P_ICLR, month = jan, year =
-
[18]
2023 , pages =
An Empirical Study on Speech Restoration Guided by Self-Supervised Speech Representation , booktitle = P_ICASSP, author =. 2023 , pages =
2023
-
[19]
Elucidating the
Karras, Tero and Aittala, Miika and Aila, Timo and Laine, Samuli , year =. Elucidating the
-
[20]
Pascual, Santiago and Bonafonte, Antonio and Serrà, Joan , month = jan, year =
-
[21]
Analyzing and
Karras, Tero and Laine, Samuli and Aittala, Miika and Hellsten, Janne and Lehtinen, Jaakko and Aila, Timo , year =. Analyzing and
-
[22]
Karras, Tero and Aittala, Miika and Laine, Samuli and Härkönen, Erik and Hellsten, Janne and Lehtinen, Jaakko and Aila, Timo , year =. Alias-
-
[23]
Lee, Sang-gil and Ping, Wei and Ginsburg, Boris and Catanzaro, Bryan and Yoon, Sungroh , month = may, year =
-
[24]
Ziyin, Liu and Hartwig, Tilman and Ueda, Masahito , month = dec, year =. Neural
-
[25]
, year =
Salimans, Tim and Kingma, Diederik P. , year =. Weight
-
[26]
Reverse-time diffusion equation models , volume =. Stoch. Process. their Appl. , author =. 1982 , pages =
1982
-
[27]
Deep clustering:
Hershey, John R and Chen, Zhuo and Le Roux, Jonathan and Watanabe, Shinji , month = mar, year =. Deep clustering:
-
[28]
IEEE/ACM Trans
Conv-. IEEE/ACM Trans. Audio Speech Lang. Process. , author =. 2019 , pages =
2019
-
[29]
Analysing
Lemercier, Jean-Marie and Richter, Julius and Welker, Simon and Gerkmann, Timo , month = jun, year =. Analysing
-
[30]
Chen, Nanxin and Zhang, Yu and Zen, Heiga and Weiss, Ron J and Norouzi, Mohammad and Chan, William , month = may, year =
-
[31]
Parallel and
Jayaram, Vivek and Thickstun, John , year =. Parallel and
-
[32]
Foley Sound Synthesis at the DCASE 2023 Challenge
Choi, Keunwoo and Im, Jaekwon and Heller, Laurie and McFee, Brian and Imoto, Keisuke and Okamoto, Yuki and Lagrange, Mathieu and Takamichi, Shinosuke. Foley Sound Synthesis at the DCASE 2023 Challenge. arXiv:2304.12521. 2023
-
[33]
Liu, Haohe and Chen, Zehua and Yuan, Yi and Mei, Xinhao and Liu, Xubo and Mandic, Danilo and Wang, Wenwu and Plumbley, Mark D , journal=
-
[34]
Text-to-Audio Generation using Instruction Tuned
Ghosal, Deepanway and Majumder, Navonil and Mehrish, Ambuj and Poria, Soujanya , journal=. Text-to-Audio Generation using Instruction Tuned
-
[35]
Sang-gil Lee and Wei Ping and Boris Ginsburg and Bryan Catanzaro and Sungroh Yoon , booktitle=P_ICLR, year=. Big
-
[36]
, year =
Bishop, Christopher M. , year =. Mixture
-
[37]
IEEE Trans
Evaluation of. IEEE Trans. Audio Speech Lang. Process. , author =. 2008 , pages =
2008
-
[38]
Zhang, Yongmao and Cong, Jian and Xue, Heyang and Xie, Lei and Zhu, Pengcheng and Bi, Mengxiao , month = may, year =
-
[39]
2017 , publisher =
Speech. 2017 , publisher =
2017
-
[40]
Reddy, Chandan K A and Gopal, Vishak and Cutler, Ross , year =
-
[41]
Le Roux, J and Wisdom, S and Erdogan, Hakan and Hershey, John R , year =
-
[42]
2013 , pages =
Speech enhancement based on deep denoising autoencoder , booktitle = P_INTERSPEECH, author =. 2013 , pages =
2013
-
[43]
1988 , pages =
Noise reduction using connectionist models , booktitle = P_ICASSP, author =. 1988 , pages =
1988
-
[44]
Kong, Jungil and Kim, Jaehyeon and Bae, Jaekyoung , booktitle = P_NeurIPS, pages =
-
[45]
Generative Adversarial Nets , booktitle = P_NIPS, author =
-
[46]
Mao, Xudong and Li, Qing and Xie, Haoran and Lau, Raymond Y. K. and Wang, Zhen and Paul Smolley, Stephen , year =. Least
-
[47]
Andreev, Pavel and Alanov, Aibek and Ivanov, Oleg and Vetrov, Dmitry , year =
-
[48]
Lee, Sangho and Chung, Jiwan and Yu, Youngjae and Kim, Gunhee and Breuel, Thomas and Chechik, Gal and Song, Yale , booktitle=
-
[49]
Gemmeke, Jort F and Ellis, Daniel PW and Freedman, Dylan and Jansen, Aren and Lawrence, Wade and Moore, R Channing and Plakal, Manoj and Ritter, Marvin , booktitle=
-
[50]
Scaling Instruction-Finetuned Language Models
Scaling Instruction-Finetuned Language Models , journal =. doi:10.48550/ARXIV.2210.11416 , author =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.11416
-
[51]
A udio C aps: Generating Captions for Audios in The Wild
Kim, Chris Dongjoo and Kim, Byeongchang and Lee, Hyunmin and Kim, Gunhee. A udio C aps: Generating Captions for Audios in The Wild. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019
2019
-
[52]
Denoising diffusion probabilistic models , author=
-
[53]
Denoising Diffusion Implicit Models , author=
-
[54]
Augmented Bridge Matching
De Bortoli, Valentin and Liu, Guan-Horng and Chen, Tianrong and Theodorou, Evangelos A and Nie, Weilie. Augmented Bridge Matching. arXiv [cs.LG]
-
[55]
Diffusion S chr \"o dinger Bridge with applications to score-based generative modeling
De Bortoli, Valentin and Thornton, James and Heng, Jeremy and Doucet, Arnaud. Diffusion S chr \"o dinger Bridge with applications to score-based generative modeling
-
[56]
Neural Diffusion Processes
Dutordoir, Vincent and Saul, Alan and Ghahramani, Zoubin and Simpson, Fergus. Neural Diffusion Processes
-
[57]
NeurIPS Workshop on Deep Generative Models and Downstream Applications , year=
Classifier-Free Diffusion Guidance , author=. NeurIPS Workshop on Deep Generative Models and Downstream Applications , year=
-
[58]
ICASSP , author =
Proc. ICASSP , author =. 2017 , pages =
2017
-
[59]
Journal of Multivariate Analysis , author =
The. Journal of Multivariate Analysis , author =. 1982 , pages =
1982
-
[60]
The Journal of Chemical Physics , author =
Equation of State Calculations by Fast Computing Machines , volume =. The Journal of Chemical Physics , author =. 1953 , pages =
1953
-
[61]
Synthesising knocking sound effects using conditional
Barahona-R. Synthesising knocking sound effects using conditional. Proc. 17th Sound and Music Computing Conference , month=jun, year=
-
[62]
Analysis and Re-Synthesis of Natural Cricket Sounds Assessing the Perceptual Relevance of Idiosyncratic Parameters , booktitle =
Oliveira, Marco and Almeida, Vitor and Silva, Jo. Analysis and Re-Synthesis of Natural Cricket Sounds Assessing the Perceptual Relevance of Idiosyncratic Parameters , booktitle =. 2023 , pages =
2023
-
[63]
Sound event detection in domestic environments with weakly labeled data and soundscape synthesis , booktitle =
Turpault, Nicolas and Serizel, Romain and Shah, Ankit Parag and Salamon, Justin , month = oct, year =. Sound event detection in domestic environments with weakly labeled data and soundscape synthesis , booktitle =
-
[64]
Multimedia , author =
IEEE Trans. Multimedia , author =. 2021 , pages =
2021
-
[65]
Computer Music Journal , author =
Digital Synthesis of Plucked-String and Drum Timbres , volume =. Computer Music Journal , author =. 1983 , pages =
1983
-
[66]
2021 , note =
A Survey on Neural Speech Synthesis , author =. 2021 , note =
2021
-
[67]
2023 , pages =
Hernandez-Olivan, Carlos and Beltr\'. 2023 , pages =
2023
-
[68]
Agostinelli, Andrea and Denk, Timo I. and Borsos, Zalán and Engel, Jesse and Verzetti, Mauro and Caillon, Antoine and Huang, Qingqing and Jansen, Aren and Roberts, Adam and Tagliasacchi, Marco and Sharifi, Matt and Zeghidour, Neil and Frank, Christian , month = jan, year =
-
[69]
Pasini, Marco and Schlüter, Jan , booktitle = P_ISMIR, year =. Musika!
-
[70]
Evaluation Metrics for Generative Speech Enhancement Methods: Issues and Perspectives , booktitle =
Pirklbauer, Jan and Sach, Marvin and Fluyt, Kristoff , month = sep, year =. Evaluation Metrics for Generative Speech Enhancement Methods: Issues and Perspectives , booktitle =
-
[71]
Pauletto, Sandra , year =
-
[72]
When hybrid sound effects are better than real recordings , volume =. Proc. Meet. Acoust. , author =. 2022 , pages =
2022
-
[73]
Neural. Proc. AAAI Conf. Artif. Intell. Interact. Digit. Entertain. , author =. 2022 , pages =
2022
-
[74]
Li, Sipan and Zhang, Luwen and Dong, Chenyu and Xue, Haiwei and Wu, Zhiyong and Sun, Lifa and Li, Kun and Meng, Helen , editor =. Man-. 2023 , pages =
2023
-
[75]
and Wang, Wenwu , month = oct, year =
Liu, Xubo and Iqbal, Turab and Zhao, Jinzheng and Huang, Qiushi and Plumbley, Mark D. and Wang, Wenwu , month = oct, year =. Conditional Sound Generation Using Neural Discrete Time-Frequency Representation Learning , booktitle =
-
[76]
Full-Band General Audio Synthesis with Score-Based Diffusion , booktitle =
Pascual, Santiago and Bhattacharya, Gautam and Yeh, Chunghsin and Pons, Jordi and Serrà, Joan , month = jun, year =. Full-Band General Audio Synthesis with Score-Based Diffusion , booktitle =
-
[77]
High Fidelity Speech Enhancement with Band-split
Yu, Jianwei and Chen, Hangting and Luo, Yi and Gu, Rongzhi and Weng, Chao , year =. High Fidelity Speech Enhancement with Band-split
-
[78]
Mel-Band RoFormer for Music Source Separation
Wang, Ju-Chiang and Lu, Wei-Tsung and Won, Minz. Mel-Band RoFormer for Music Source Separation
-
[79]
TF -locoformer: Transformer with local modeling by convolution for speech separation and enhancement
Saijo, Kohei and Wichern, Gordon and Germain, François G and Pan, Zexu and Roux, Jonathan Le. TF -locoformer: Transformer with local modeling by convolution for speech separation and enhancement
-
[80]
Miipher: A robust speech restoration model integrating self-supervised speech and text representations , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.