Scaling Expert Feedback with Reflective Edit Propagation in Compositional Knowledge Bases
Pith reviewed 2026-06-28 04:05 UTC · model grok-4.3
The pith
A reflective agent infers the intent of one expert edit and propagates the correction across an entire knowledge base.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
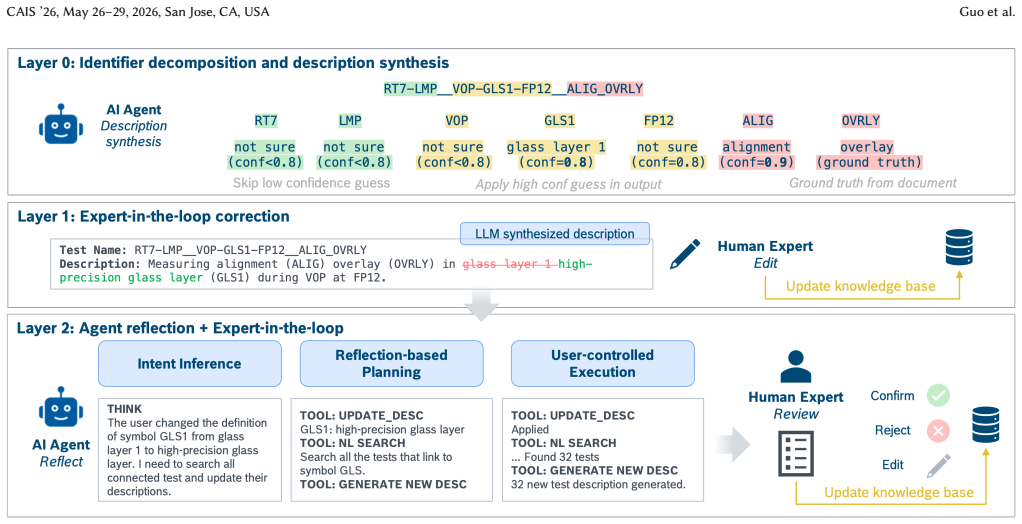
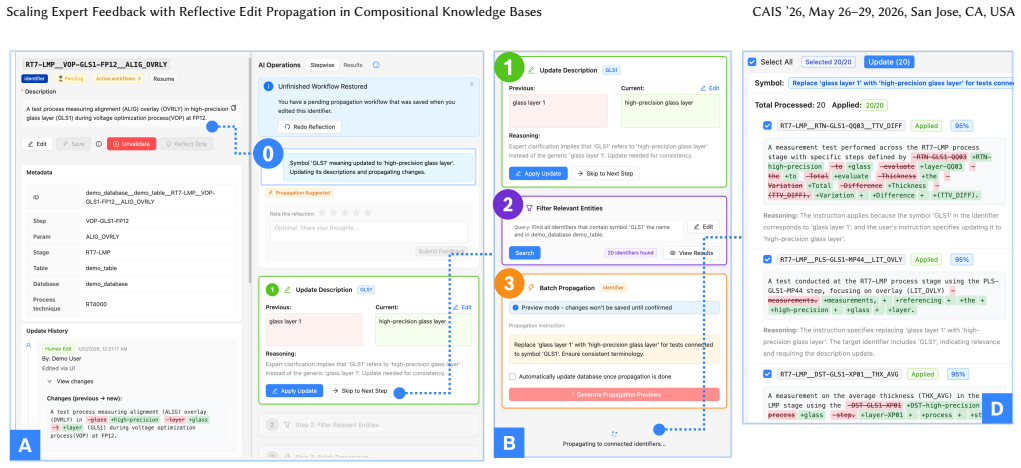
RAID transforms individual expert edits into systematic knowledge updates by using a reflective agent to infer the underlying semantic intent behind a single expert edit and propagates that correction across the entire KB through Intent Inference, Reflection-based Planning, and User Controlled Execution. Evaluation on a public dataset and a user study with subject matter experts on proprietary data shows the technical feasibility of capturing expert intent and scaling it.
What carries the argument
The RAID three-step architecture of Intent Inference, Reflection-based Planning, and User Controlled Execution, where a reflective agent infers semantic intent from an edit to drive propagation.
If this is right
- One expert edit can update multiple related entries without separate reviews for each.
- Expert workload for maintaining LLM-drafted knowledge bases decreases while preserving technical accuracy.
- User-controlled execution lets experts approve or adjust the planned propagations before they take effect.
- Evaluations confirm the system captures intent on both public and proprietary data.
Where Pith is reading between the lines
- The same intent-inference step could extend to other structured data curation tasks beyond identifier dictionaries.
- If generalization holds, organizations might maintain knowledge bases in near real time as experts make occasional corrections.
- Further tests on entries with ambiguous intent would clarify where the propagation step breaks down.
Load-bearing premise
The reflective agent can accurately infer the semantic intent from a single expert edit so the inferred intent generalizes correctly to other entries without introducing new errors.
What would settle it
Run RAID on a set of held-out expert edits and measure how often the propagated changes match independent expert judgments on those same entries; high mismatch rates would disprove reliable propagation.
Figures
read the original abstract
Domain-specific knowledge bases (KBs) encode vertical expertise and proprietary information that organizations depend on, but curating them at scale is a persistent challenge. Although Large Language Models (LLMs) can draft initial entries efficiently, technical accuracy still requires human expert validation, and reviewing entries one by one at scale is impractical. We present Reflective Agent for Identifier Dictionary (RAID), a novel system that transforms individual expert edits into systematic knowledge updates. Unlike traditional "correct-and-save" paradigms, RAID utilizes a reflective agent to infer the underlying semantic intent behind a single expert edit and propagates that correction across the entire KB through a three-step architecture: Intent Inference, Reflection-based Planning, and User Controlled Execution. We evaluated the reflection and propagation performance on a public dataset and conducted a user study with subject matter experts with proprietary data. The evaluation shows RAID's technical feasibility in capturing expert intent and its potential to scale specialized expertise across industrial knowledge bases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents RAID, a system for scaling expert feedback in domain-specific knowledge bases. It uses a reflective agent to infer the underlying semantic intent from a single expert edit and propagates the correction across the KB via a three-step architecture: Intent Inference, Reflection-based Planning, and User Controlled Execution. The authors report an evaluation of reflection and propagation performance on a public dataset along with a user study involving subject matter experts and proprietary data, claiming to demonstrate technical feasibility in capturing expert intent.
Significance. If the reflective propagation mechanism proves reliable, the approach could meaningfully address the scalability challenge of curating large vertical knowledge bases by converting isolated expert corrections into systematic updates. The three-step architecture offers a structured way to generalize edits beyond simple string replacement. However, the complete absence of any quantitative metrics, baselines, or error analysis in the manuscript prevents assessment of whether the claimed feasibility holds.
major comments (1)
- [Abstract] Abstract: The statement that 'the evaluation shows RAID's technical feasibility in capturing expert intent' is load-bearing for the central claim yet is unsupported by any reported metrics, baselines, results, error analysis, or dataset details from either the public dataset evaluation or the user study.
Simulated Author's Rebuttal
We thank the referee for the careful review and the identification of a key issue in how the abstract presents our evaluation results. We address the comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The statement that 'the evaluation shows RAID's technical feasibility in capturing expert intent' is load-bearing for the central claim yet is unsupported by any reported metrics, baselines, results, error analysis, or dataset details from either the public dataset evaluation or the user study.
Authors: We agree that the abstract claim is insufficiently supported as written. The manuscript body contains descriptions of the public dataset evaluation and user study, but these sections do not include the quantitative metrics, baselines, or error analysis needed to substantiate the abstract statement. We will revise the abstract to remove or qualify the unsupported claim and will add a concise summary of key results (including metrics and dataset details) to the abstract in the revised manuscript. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes a systems architecture (RAID) with a three-step process for intent inference and edit propagation, supported by evaluations on a public dataset and a user study with experts. No mathematical derivations, equations, fitted parameters, or self-citations appear in the provided abstract or description that reduce any claim to its own inputs by construction. The central claims rest on empirical feasibility demonstrations rather than any self-referential or definitional loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sri Rosa Anjelia, Dana Indra Sensuse, and Sofian Lusa. 2025. AI agents for organizational knowledge retrieval and sharing: A Systematic Literature Review. International Journal of Advances in Data and Information Systems6, 3 (23 Dec. 2025), 824–839. doi:10.59395/ijadis.v6i3.1462
-
[2]
Tyler Bikaun, Michael Stewart, and Wei Liu. 2024. CleanGraph: Human-in-the- loop knowledge graph refinement and completion.arXiv [cs.AI](6 May 2024). arXiv:2405.03932 [cs.AI]
arXiv 2024
-
[3]
Zana Buçinca, Maja Barbara Malaya, and Krzysztof Z Gajos. 2021. To Trust or to Think: Cognitive Forcing Functions Can Reduce Overreliance on AI in AI-assisted Decision-making.Proceedings of the ACM on Human-Computer Interaction5, CSCW1 (22 April 2021), 1–21. doi:10.1145/3449287
work page internal anchor Pith review doi:10.1145/3449287 2021
-
[4]
Roi Cohen, Eden Biran, Ori Yoran, Amir Globerson, and Mor Geva. 2024. Eval- uating the ripple effects of knowledge editing in language models.Transac- tions of the Association for Computational Linguistics12 (9 April 2024), 283–298. doi:10.1162/tacl_a_00644
-
[5]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2024. From local to global: A graph RAG approach to query-focused summarization.arXiv [cs.CL](24 April 2024). arXiv:2404.16130 [cs.CL]
Pith/arXiv arXiv 2024
-
[6]
Huan-Ang Gao, Jiayi Geng, Wenyue Hua, Mengkang Hu, Xinzhe Juan, Hongzhang Liu, Shilong Liu, Jiahao Qiu, Xuan Qi, Yiran Wu, Hongru Wang, Han Xiao, Yuhang Zhou, Shaokun Zhang, Jiayi Zhang, Jinyu Xiang, Yixiong Fang, Qiwen CAIS ’26, May 26–29, 2026, San Jose, CA, USA Guo et al. Zhao, Dongrui Liu, Qihan Ren, Cheng Qian, Zhenhailong Wang, Minda Hu, Huazheng Wa...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.21046 2026
-
[7]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. 2023. Retrieval-Augmented Gen- eration for large Language Models: A survey.arXiv [cs.CL](18 Dec. 2023). arXiv:2312.10997 [cs.CL]
Pith/arXiv arXiv 2023
-
[8]
Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, Senjie Jin, Jiejun Tan, Yanbin Yin, Jiongnan Liu, Zeyu Zhang, Zhongxiang Sun, Yutao Zhu, Hao Sun, Boci Peng, Zhenrong Cheng, Xuanbo Fan, Jiaxin Guo, Xinlei Yu, Zhenhong Zhou, Zewen Hu, Jiahao Huo, Junhao Wang, Yuwei Niu, Yu Wang, Zhe...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.13564 2026
-
[9]
National Library of Medicine. [n. d.]. RxTerms. https://lhncbc.nlm.nih.gov/MOR/ RxTerms/. Accessed: 2026-3-13
2026
-
[10]
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G Patil, Ion Stoica, and Joseph E Gonzalez. 2023. MemGPT: Towards LLMs as operating systems. arXiv [cs.AI](12 Oct. 2023). arXiv:2310.08560 [cs.AI] doi:10.48550/arXiv.2310. 08560
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310 2023
-
[11]
Joon Sung Park, Joseph C O’Brien, Carrie J Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2023. Generative Agents: Interactive Simulacra of Human Behavior.arXiv [cs.HC](7 April 2023). arXiv:2304.03442 [cs.HC]
Pith/arXiv arXiv 2023
-
[12]
Ben Shneiderman. 2020. Human-Centered Artificial Intelligence: Reliable, Safe & Trustworthy.International Journal of Human–Computer Interaction36, 6 (2 April 2020), 495–504. arXiv:2002.04087 doi:10.1080/10447318.2020.1741118
-
[13]
Annalisa Szymanski, Noah Ziems, Heather A Eicher-Miller, Toby Jia-Jun Li, Meng Jiang, and Ronald A Metoyer. 2025. Limitations of the LLM-as-a-judge approach for evaluating LLM outputs in expert knowledge tasks. InProceedings of the 30th International Conference on Intelligent User Interfaces. ACM, New York, NY, USA, 952–966. doi:10.1145/3708359.3712091
-
[14]
Stefani Tsaneva, Danilo Dessì, Francesco Osborne, and Marta Sabou. 2025. Knowl- edge graph validation by integrating LLMs and human-in-the-loop.Information Processing & Management62, 5 (Sept. 2025), 104145. doi:10.1016/j.ipm.2025.104145
-
[15]
Shih-Ying Yeh, Yueh-Feng Ku, Ko-Wei Huang, and Buu-Khang Tu. 2026. Ko- hakuRAG: A simple RAG framework with hierarchical document indexing.arXiv [cs.CL](8 March 2026). arXiv:2603.07612 [cs.CL] doi:10.48550/arXiv.2603.07612
-
[16]
Rui Yu, Tianyi Wang, Ruixia Liu, and Yinglong Wang. 2026. SF-RAG: Structure- fidelity retrieval-augmented generation for academic question answering.arXiv [cs.IR](18 March 2026). arXiv:2602.13647 [cs.IR] doi:10.48550/arXiv.2602.13647
-
[17]
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. 2024. ExpeL: LLM agents are experiential learners.Proceedings of the AAAI Conference on Artificial Intelligence38, 17 (24 March 2024), 19632–19642. doi:10.1609/aaai.v38i17.29936
-
[18]
Zihao Zhao, Yuchen Yang, Yijiang Li, and Yinzhi Cao. 2024. RIPPLECOT: Ampli- fying ripple effect of knowledge editing in language models via chain-of-thought in-context learning.arXiv [cs.CL](3 Oct. 2024). arXiv:2410.03122 [cs.CL]
arXiv 2024
-
[19]
Knowledge graph-guided retrieval augmented generation
Xiangrong Zhu, Yuexiang Xie, Yi Liu, Yaliang Li, and Wei Hu. 2025. Knowl- edge graph-guided retrieval augmented generation. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Com- putational Linguistics: Human Language Technologies (Volume 1: Long Papers). Association for Computational Linguistics, Stroudsbu...
-
[20]
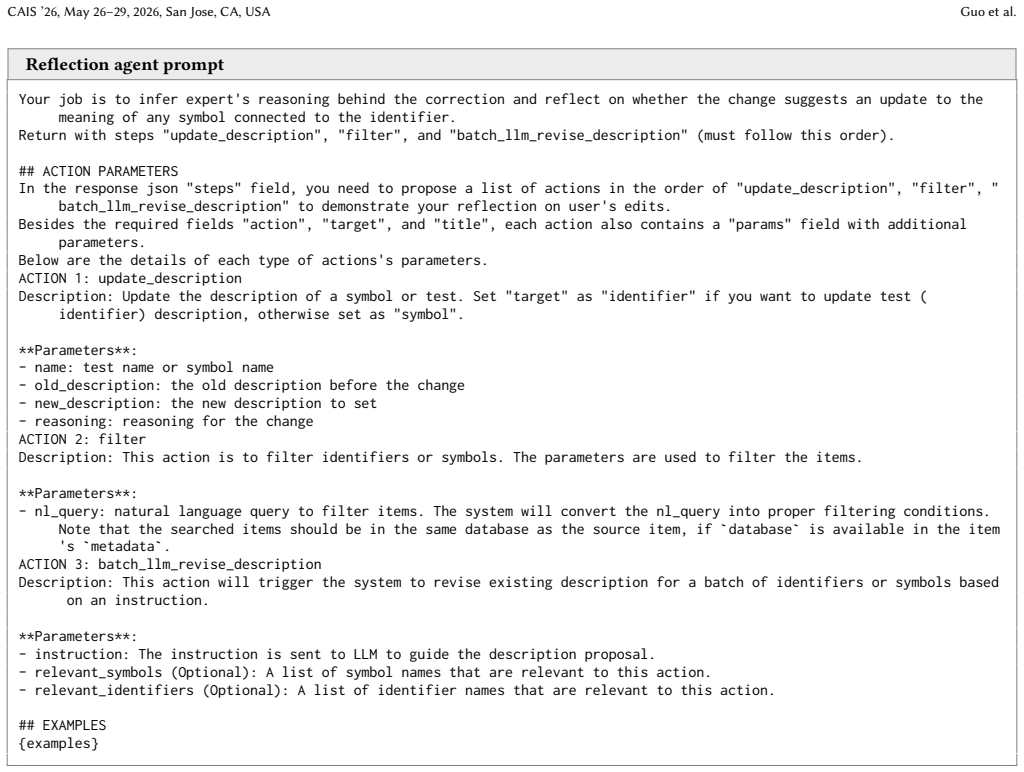
**Identify the core difference**: What specific pharmacological fact was changed? Was it the mechanism of action, therapeutic class, clinical distinction, dose form characterization, or route description?
-
[21]
**Attribute the change to a symbol**: Which component symbol (ingredient, dose form, or route) in the connected symbols most likely corresponds to the changed part of the description? Use the CONNECTED SYMBOLS section to identify the source
-
[22]
**Assess semantic impact**: Use the criteria below to classify the change
-
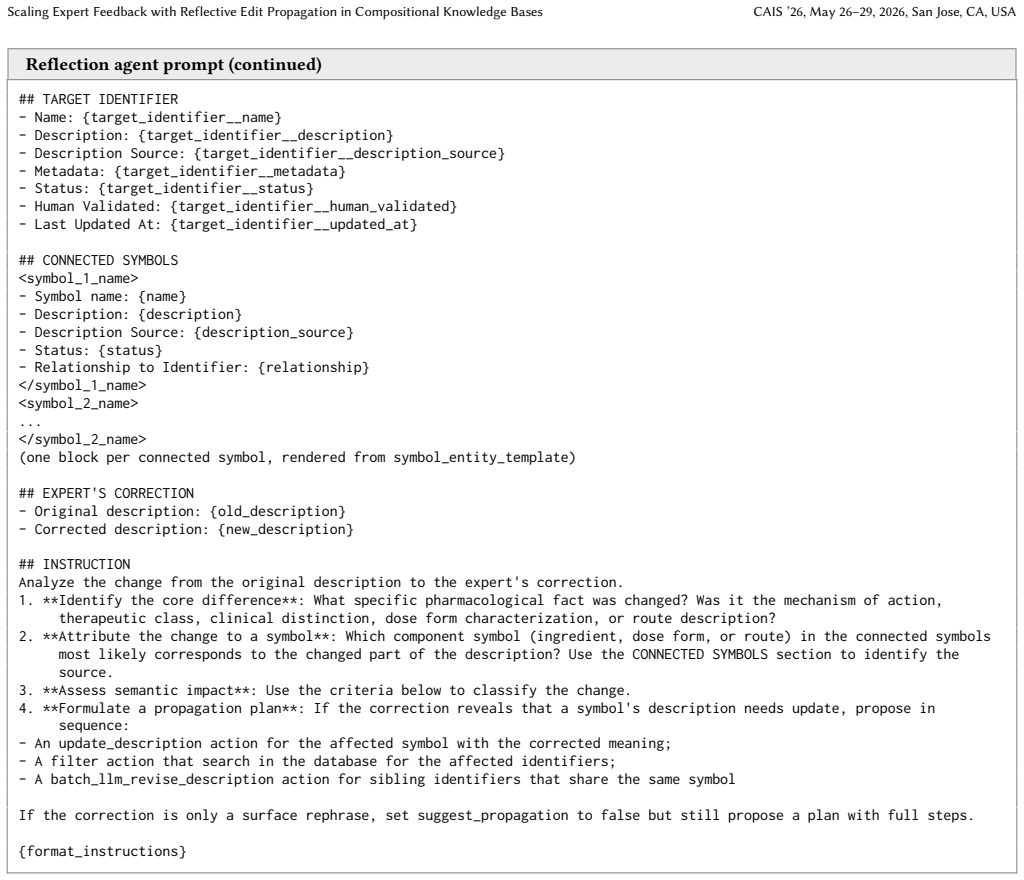
[23]
{format_instructions} Figure 4: Reflection agent prompt template (continued)
**Formulate a propagation plan**: If the correction reveals that a symbol's description needs update, propose in sequence: - An update_description action for the affected symbol with the corrected meaning; - A filter action that search in the database for the affected identifiers; - A batch_llm_revise_description action for sibling identifiers that share ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.