Graph Traversal on Tensor Cores: A BFS Framework for Modern GPUs
Pith reviewed 2026-06-28 03:59 UTC · model grok-4.3
The pith
BLEST reformulates BFS as bit-level sparse matrix-vector computation to run efficiently on GPU tensor cores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
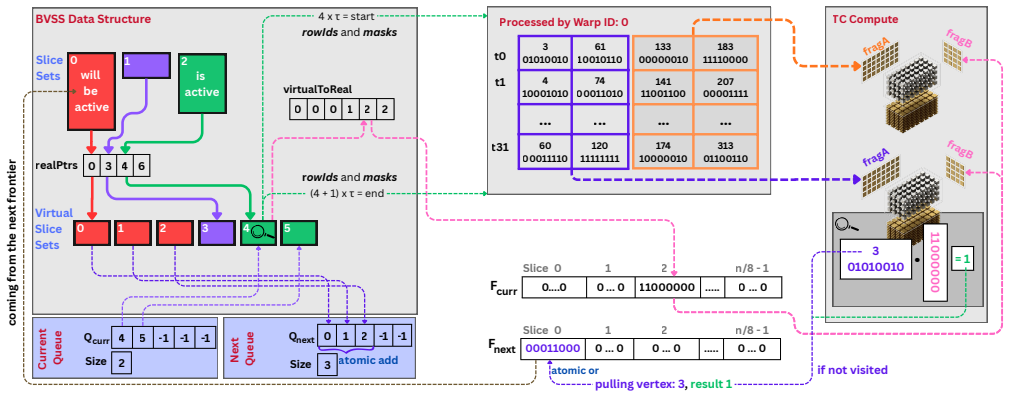
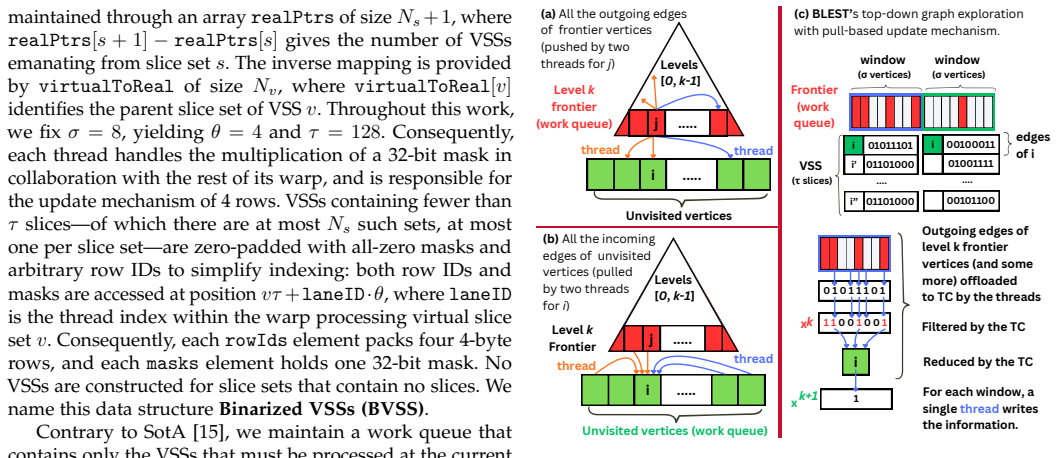
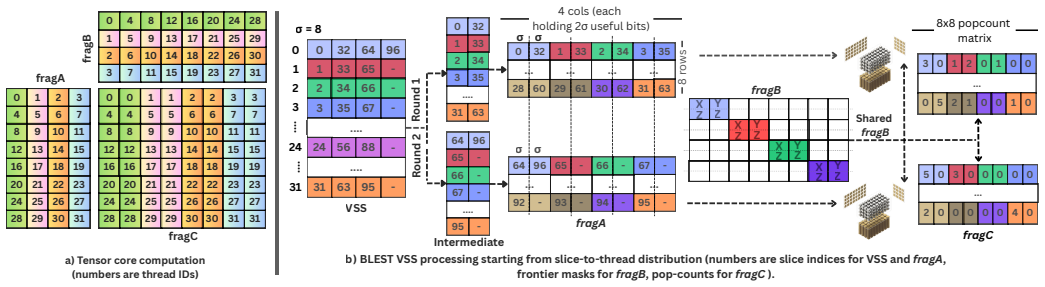
BLEST reformulates BFS as a bit-level sparse matrix-vector computation on tensor cores, using Binarized Virtual Slice Sets to partition work into balanced warp-level units that only process frontier-relevant graph regions, an optimized TC layout that maps neighbor checks to binary MMA instructions and reduces MMA calls by 8 times, and a lazy vertex-update scheme that avoids atomic and cache bottlenecks. The framework adds dynamic switching between tensor cores and CUDA cores when one becomes more efficient, extends naturally to multi-source BFS and closeness centrality, and includes a scalable reordering method that improves compression on scale-free graphs and locality on others. On real-wo
What carries the argument
Binarized Virtual Slice Sets (BVSS) together with the tensor-core layout that maps neighbor checks onto binary MMA instructions without wasted outputs.
If this is right
- BLEST sets a new performance baseline for single-source and multi-source BFS on modern GPUs.
- Exact closeness centrality becomes feasible for graphs with billions of edges using a few hundred GPUs.
- Dynamic switching between tensor cores and CUDA cores reduces total work when one unit type is clearly faster for a given frontier.
- The graph reordering method improves both compression ratios on scale-free graphs and cache locality on others.
- The same bit-level sparse matrix formulation can be reused for other traversal-based graph kernels.
Where Pith is reading between the lines
- Similar tensor-core mappings could be explored for other sparse linear-algebra kernels that dominate graph analytics libraries.
- The 8 times reduction in MMA calls suggests that future GPUs with wider tensor units would amplify the reported speedups.
- The lazy-update and BVSS ideas might transfer to CPU vector units or to accelerators that support low-precision matrix operations.
- Testing the same framework on graphs generated from different degree distributions would reveal how sensitive the speedups are to graph structure.
Load-bearing premise
The BVSS partitioning, TC layout, and lazy-update scheme maintain their efficiency advantage without hidden overheads dominating on the full range of graphs tested.
What would settle it
A set of graphs or GPU hardware where the measured runtime of BLEST exceeds that of Gunrock or GSWITCH by more than 20 percent despite using the same number of GPUs.
Figures
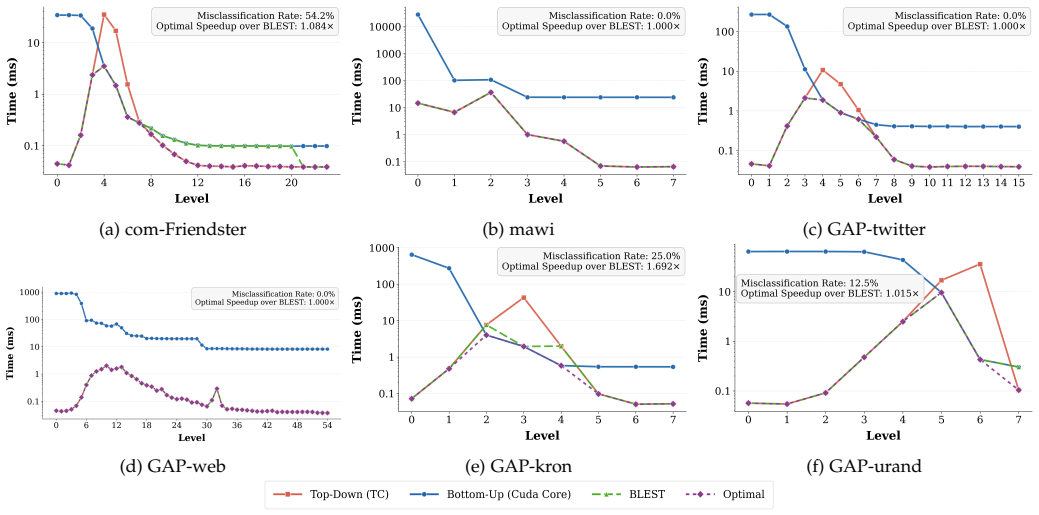
read the original abstract
Modern GPUs have Tensor Cores (TCs) capable of extremely high-throughput matrix operations, yet graph algorithms remain difficult to accelerate because of their irregular and data-dependent execution patterns. This work presents BLEST, a TC-accelerated framework that reformulates Breadth-First Search (BFS) as a bit-level sparse matrix-vector computation while addressing the load imbalance, memory inefficiency, and synchronization overheads that limit prior approaches. BLEST introduces Binarized Virtual Slice Sets (BVSS), a graph representation that partitions work into balanced warp-level units and schedules only frontier-relevant regions of the graph. It further employs an optimized TC layout that maps neighbour checks onto binary MMA instructions without wasted outputs, reducing the number of required MMA calls by 8$\times$ compared with prior layouts. To mitigate atomic and cache bottlenecks, BLEST incorporates a lazy vertex-update scheme. We revisit the switching terminology for BFS and propose a mechanism that dynamically transitions from TCs to CUDA cores when it becomes more efficient. We also extend BLEST to multi-source BFS and closeness centrality workloads. Finally, we introduce a scalable graph reordering method that improves compression for scale-free-like graphs, while using RCM to improve locality for others. Across a broad set of real-world graphs, BLEST achieves average speedups of 22.0$\times$, 7.7$\times$, 8.1$\times$, and 5.9$\times$ over GAP, Gunrock, GSWITCH, and BerryBees, respectively, establishing a new BFS baseline on GPUs. Thanks to its high performance, BLEST can compute the exact closeness centralities of 65.6M vertices in a social network with 3.6B edges in an hour using 100 H100 GPUs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
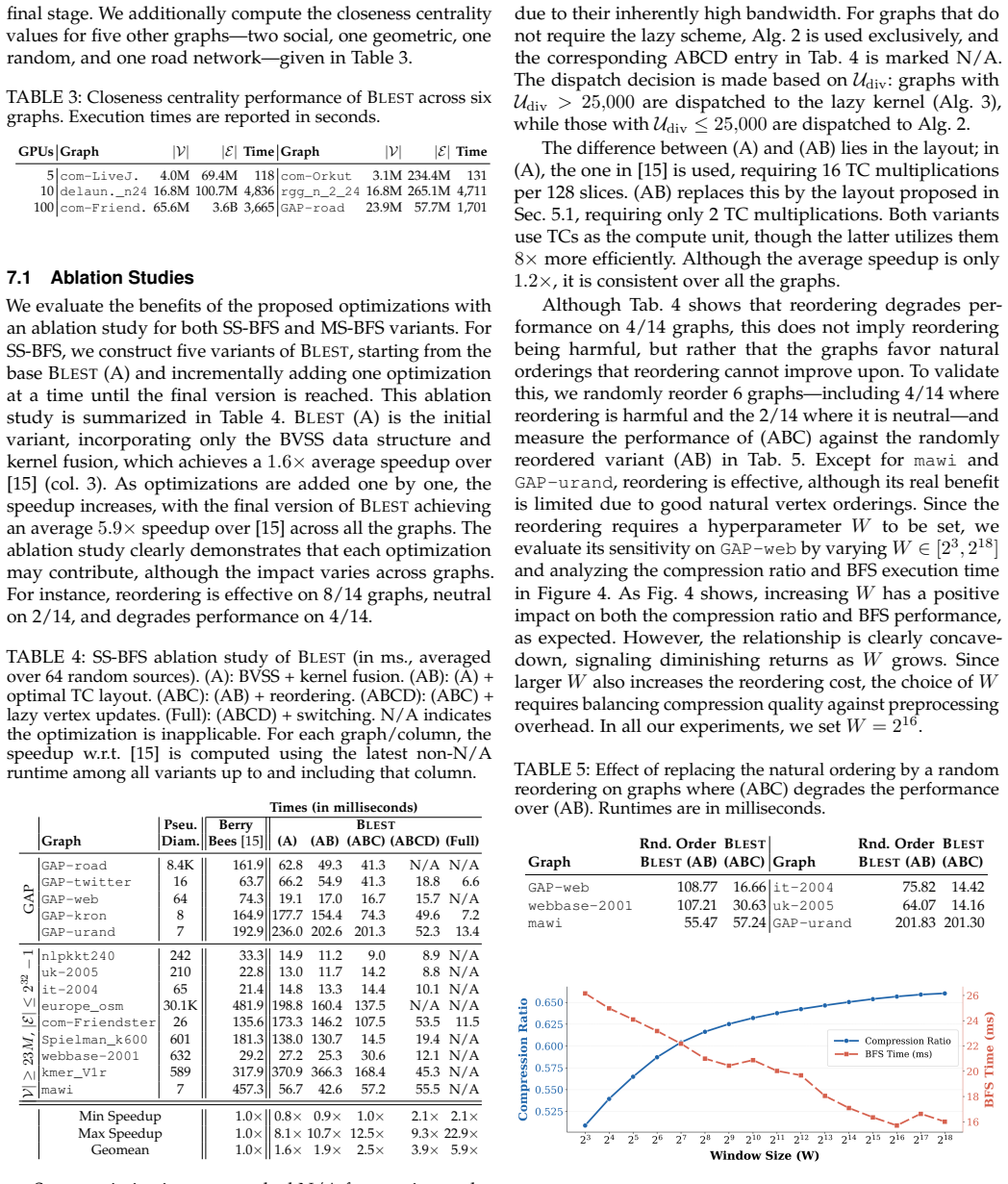
Summary. The paper presents BLEST, a TC-accelerated BFS framework for modern GPUs that reformulates graph traversal as bit-level sparse matrix-vector multiplication. It introduces Binarized Virtual Slice Sets (BVSS) for balanced warp-level partitioning and frontier-relevant scheduling, an optimized TC layout mapping neighbor checks to binary MMA instructions (reducing MMA calls by 8×), a lazy vertex-update scheme to reduce atomic/cache pressure, a dynamic TC-to-CUDA switching mechanism, extensions to multi-source BFS and closeness centrality, and a scalable graph reordering method (RCM for locality, custom for scale-free graphs). The central empirical claim is average speedups of 22.0×, 7.7×, 8.1×, and 5.9× over GAP, Gunrock, GSWITCH, and BerryBees across real-world graphs, plus a demonstration of exact closeness centrality on a 3.6B-edge graph using 100 H100 GPUs in one hour.
Significance. If the reported speedups and overhead measurements hold under the evaluated conditions, the work is significant for establishing a new high-performance baseline for GPU BFS and for showing how Tensor Cores can be applied to irregular graph workloads without hidden overheads dominating. Credit is due for the directly measured 8× MMA reduction, the dynamic switching mechanism presented as measured, and the multi-source/centrality extensions that follow the same framework without additional leaps.
minor comments (3)
- [Abstract] Abstract: the phrase 'we revisit the switching terminology for BFS' is introduced without defining the new terminology or contrasting it explicitly with prior usage, which would clarify the contribution.
- [Abstract] Abstract: average speedups are stated without the number of graphs, per-graph range, or any indication of variance, making it harder to assess robustness of the cross-system comparison.
- The description of the BVSS partitioning and TC layout would benefit from a small illustrative diagram or pseudocode snippet showing how the 8× MMA reduction is achieved, as the textual description alone leaves the mapping from neighbor checks to binary MMA outputs somewhat abstract.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report contains no specific major comments to address point by point.
Circularity Check
No significant circularity; empirical claims rest on external baselines
full rationale
The paper presents an empirical GPU BFS implementation (BLEST) whose central claims are measured speedups against named external systems (GAP, Gunrock, GSWITCH, BerryBees). No equations, fitted parameters, or self-citation chains are used to derive performance numbers; the reported reductions in MMA calls, dynamic switching, and BVSS partitioning are presented as directly implemented and measured quantities. The multi-source and centrality extensions follow the same framework without additional self-referential steps. Because the argument structure is self-contained against external benchmarks and contains no load-bearing self-definitional or fitted-input reductions, the derivation chain exhibits no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Determining the diameter of small world networks,
F. W. Takes and W. A. Kosters, “Determining the diameter of small world networks,” inProc. 20th ACM Int. Conf. on Information and Knowledge Management (CIKM’11). New York, NY, USA: ACM, 2011, pp. 1191–1196
2011
-
[2]
Breadth-first search-based single- phase algorithms for bridge detection in wireless sensor networks,
V . K. Akram and O. Dagdeviren, “Breadth-first search-based single- phase algorithms for bridge detection in wireless sensor networks,” Sensors, vol. 13, no. 7, pp. 8786–8813, 2013
2013
-
[3]
BFSMpR: A BFS graph based recommendation system using MapReduce,
V . Pandey and P . Bonde, “BFSMpR: A BFS graph based recommendation system using MapReduce,”Int. J. on Recent and Innovation Trends in Comp. and Communication, vol. 5, no. 6, pp. 445–449, 2017. [Online]. Available: https://ijritcc.org/index.php/ ijritcc/article/view/794
2017
-
[4]
Parallel breadth-first search LTL model checking,
J. Barnat, L. Brim, and J. Chaloupka, “Parallel breadth-first search LTL model checking,” inProc. 18th IEEE Int. Conf. on Automated Software Eng. (ASE’03). Montreal, Canada: IEEE, 2003, pp. 106–115
2003
-
[5]
A work-efficient parallel breadth- first search algorithm (or how to cope with the nondeterminism of reducers),
C. E. Leiserson and T. B. Schardl, “A work-efficient parallel breadth- first search algorithm (or how to cope with the nondeterminism of reducers),” inProc. 22nd ACM Symp. on Parallelism in Algorithms and Archs. (SP AA’10). Santorini, Greece: ACM, 2010, pp. 303–314
2010
-
[6]
Direction-optimizing breadth-first search,
S. Beamer, K. Asanovi´c, and D. Patterson, “Direction-optimizing breadth-first search,” inProc. 2012 ACM/IEEE Int. Conference for High Perf. Comp., Netw., Storage and Analysis (SC’12). Salt Lake City, UT, USA: IEEE Computer Society, 2012, pp. 1–10
2012
-
[7]
Theoretically efficient parallel graph algorithms can be fast and scalable,
L. Dhulipala, G. E. Blelloch, and J. Shun, “Theoretically efficient parallel graph algorithms can be fast and scalable,”ACM Trans. Parallel Comp., vol. 8, no. 1, pp. 4:1–4:70, 2021
2021
-
[8]
Ligra: A lightweight graph processing framework for shared memory,
J. Shun and G. E. Blelloch, “Ligra: A lightweight graph processing framework for shared memory,” inProc. 18th ACM SIGPLAN Symp. on Principles and Practice of Parallel Programming (PPoPP’13). Shenzhen, China: ACM, 2013, pp. 135–146
2013
-
[9]
High-performance and scalable GPU graph traversal,
D. Merrill, M. Garland, and A. Grimshaw, “High-performance and scalable GPU graph traversal,”ACM Trans. Parallel Comp., vol. 1, no. 2, pp. 14:1–14:30, 2015
2015
-
[10]
Gunrock: GPU graph analytics,
Y. Wang, Y. Pan, A. Davidson, Y. Wu, C. Yang, L. Wang, M. Osama, C. Yuan, W. Liu, A. T. Riffel, and J. D. Owens, “Gunrock: GPU graph analytics,”ACM Trans. Par. Comp., vol. 4, no. 1, pp. 3:1–3:49, 2017
2017
-
[11]
A pattern based algorithmic autotuner for graph processing on GPUs,
K. Meng, J. Li, G. Tan, and N. Sun, “A pattern based algorithmic autotuner for graph processing on GPUs,” inProc. 24th ACM SIGPLAN Symp. on Principles and Practice of Parallel Programming (PPoPP’19). Washington, DC, USA: ACM, 2019, pp. 201–213
2019
-
[12]
Parallel breadth-first search on dist. memory systems,
A. Buluc ¸and K. Madduri, “Parallel breadth-first search on dist. memory systems,” inProc. 2011 ACM/IEEE Int. Conference for High Perf. Comp., Netw., Storage and Analysis (SC’11). New York, NY, USA: ACM, 2011, pp. 65:1–65:12
2011
-
[13]
Traversing trillions of edges in real time: Graph exploration on large-scale parallel machines,
F. Checconi and F. Petrini, “Traversing trillions of edges in real time: Graph exploration on large-scale parallel machines,” inProc. 28th IEEE Int. Parallel and Dist. Processing Symp. (IPDPS’14). Phoenix, AZ, USA: IEEE, 2014, pp. 425–434
2014
-
[14]
Mathematical foundations of the GraphBLAS,
J. Kepner, P . Aaltonen, D. Bader, A. Buluc ¸, F. Franchetti, J. Gilbert, D. Hutchison, M. Kumar, A. Lumsdaine, H. Meyerhenke, S. McMil- lan, C. Yang, J. D. Owens, M. Zalewski, T. Mattson, and J. Moreira, “Mathematical foundations of the GraphBLAS,” inProc. 2016 IEEE High Perf. Extreme Comp. Conference (HPEC’16). Waltham, MA, USA: IEEE, 2016, pp. 1–9
2016
-
[15]
BerryBees: Breadth first search by bit-tensor- cores,
Y. Niu and M. Casas, “BerryBees: Breadth first search by bit-tensor- cores,” inProc. 30th ACM SIGPLAN Annual Symp. on Principles and Practice of Parallel Programming (PPoPP’25). New York, NY, USA: ACM, 2025, pp. 339–354
2025
-
[16]
W. Liu and A. H. Sherman, “Comparative analysis of the Cuthill–McKee and the reverse Cuthill–McKee ordering algorithms for sparse matrices,”SIAM Journal on Numerical Analysis, vol. 13, no. 2, pp. 198–213, 1976. [Online]. Available: https://doi.org/10.1137/0713020
-
[17]
S. Beamer, K. Asanovi´c, and D. Patterson, “The GAP benchmark suite,”CoRR, vol. abs/1508.03619, 2015. [Online]. Available: https://arxiv.org/abs/1508.03619
Pith/arXiv arXiv 2015
-
[18]
Bitmap-based sparse matrix-vector mul- tiplication with tensor cores,
Y. Chen and J. X. Yu, “Bitmap-based sparse matrix-vector mul- tiplication with tensor cores,” inProc. 53rd Int. Conf. on Parallel Processing, ser. ICPP ’24. Sweden: ACM, Aug. 2024, pp. 1135–1144
2024
-
[19]
DASP: Specific dense matrix multiply- accumulate units accelerated general sparse matrix-vector mul- tiplication,
Y. Lu and W. Liu, “DASP: Specific dense matrix multiply- accumulate units accelerated general sparse matrix-vector mul- tiplication,” inProc. Int. Conf. for High Perf. Comp., Netw., Storage and Analysis, ser. SC ’23. Denver, CO, USA: ACM, Nov. 2023
2023
-
[20]
DTC-SpMM: Bridging the gap in accelerating general sparse matrix multiplication with tensor cores,
R. Fan, W. Wang, and X. Chu, “DTC-SpMM: Bridging the gap in accelerating general sparse matrix multiplication with tensor cores,” inProc. 29th ACM Int. Conf. on Architectural Support for Programming Languages and Operating Systems, Volume 3, ser. ASPLOS ’24. La Jolla, CA, USA: ACM, Apr. 2024, pp. 253–267
2024
-
[21]
High performance unstructured SpMM computation using tensor cores,
P . Okanovic, G. Kwasniewski, P . S. Labini, M. Besta, F. Vella, and T. Hoefler, “High performance unstructured SpMM computation using tensor cores,” inProc. Int. Conf. for High Perf. Comp., Netw., Storage and Analysis, ser. SC ’24. Atlanta, GA, USA: IEEE, Nov. 2024, pp. 154:1–154:14
2024
-
[22]
Acc-SpMM: Accelerating general-purpose sparse matrix-matrix multiplication with GPU tensor cores,
H. Zhao, S. Li, J. Wang, C. Zhou, J. Wang, Z. Xin, S. Li, Z. Liang, Z. Pan, F. Liu, Y. Zeng, Y. Wang, and X. Chi, “Acc-SpMM: Accelerating general-purpose sparse matrix-matrix multiplication with GPU tensor cores,” inProc. 30th ACM SIGPLAN Annual Symp. on Principles and Practice of Parallel Programming, ser. PPoPP ’25. Las Vegas, NV , USA: ACM, Mar. 2025, ...
2025
-
[23]
BRP- SpMM: Block-row partition based sparse matrix multiplication with tensor and CUDA cores,
Y. Dong, W. Jiang, X. Shen, H. Guo, Z. Shao, and H. Jin, “BRP- SpMM: Block-row partition based sparse matrix multiplication with tensor and CUDA cores,” inProc. 39th Int. Parallel and Dist. Proc. Symp. (IPDPS ’25). Milan, Italy: IEEE, May 2025, pp. 901–912
2025
-
[24]
cuTeSpMM: Accelerating sparse-dense matrix mul- tiplication using GPU tensor cores,
L. Xiang, O. Asudeh, G. Sabin, A. Sukumaran-Rajam, and P . Sa- dayappan, “cuTeSpMM: Accelerating sparse-dense matrix mul- tiplication using GPU tensor cores,”CoRR, vol. abs/2504.06443, 2025
arXiv 2025
-
[25]
FlashSparse: Minimiz- ing computation redundancy for fast sparse matrix multiplications on tensor cores,
J. Shi, S. Li, Y. Xu, R. Fu, X. Wang, and T. Wu, “FlashSparse: Minimiz- ing computation redundancy for fast sparse matrix multiplications on tensor cores,” inProc. 30th ACM SIGPLAN Annual Symp. on Principles and Practice of Parallel Programming, ser. PPoPP ’25. Las Vegas, NV , USA: ACM, Mar. 2025, pp. 312–325
2025
-
[26]
Groot: Graph-centric row reordering with tree for sparse matrix multiplications on tensor cores,
Y. Chen, J. Xie, S. Teng, W. Zeng, and J. X. Yu, “Groot: Graph-centric row reordering with tree for sparse matrix multiplications on tensor cores,” inProc. 20th European Conf. on Comp. Sys., ser. EuroSys ’25. Rotterdam, Netherlands: ACM, Apr. 2025, pp. 803–817
2025
-
[27]
FastSpMM: Leveraging tensor cores for sparse matrix multiplication,
G. Li, Y. Liu, W. Luo, R. Fu, X. Wang, and T. Wu, “FastSpMM: Leveraging tensor cores for sparse matrix multiplication,” inProc. 22nd ACM Int. Conf. on Comp. Frontiers, ser. CF ’25. ACM, 2025, pp. 195–204
2025
-
[28]
Voltrix: Sparse matrix-matrix multiplication on tensor cores withs asynchronous and balanced kernel optimization,
Y. Xia, W. Wang, D. Yang, X. Zhou, and D. Cheng, “Voltrix: Sparse matrix-matrix multiplication on tensor cores withs asynchronous and balanced kernel optimization,” in2025 USENIX Annual Tech. Conf., ser. USENIX ATC ’25. Boston, MA, USA: USENIX Assoc., Jul. 2025, pp. 699–714
2025
-
[29]
Jigsaw: Accelerating SpMM with vector sparsity on sparse tensor core,
K. Zhang, X. Liu, H. Yang, T. Feng, X. Yang, Y. Liu, Z. Luan, and D. Qian, “Jigsaw: Accelerating SpMM with vector sparsity on sparse tensor core,” inProc. 53rd Int. Conf. on Parallel Processing, ser. ICPP ’24. Gotland, Sweden: ACM, Aug. 2024, pp. 1124–1134
2024
-
[30]
HR-SpMM: Adap- tive row partitioning and hybrid kernel design for sparse matrix multiplication,
Q. Wang, Y. Wang, Y. Luo, R. Luo, and P . Tang, “HR-SpMM: Adap- tive row partitioning and hybrid kernel design for sparse matrix multiplication,” inProc. 39th ACM Int. Conf. on Supercomputing, ser. ICS ’25. Salt Lake City, UT, USA: ACM, Jun. 2025, pp. 161–172
2025
-
[31]
NM-SpMM: Accelerating matrix multiplication using N:M sparsity with GPGPU,
C. Ma, D. Wu, Z. Deng, J. Chen, X. Huang, J. Meng, W. Zhu, B. Wang, A. C. Zhou, P . Chen, M. Deng, Y. Wei, S. Feng, and Y. Pan, “NM-SpMM: Accelerating matrix multiplication using N:M sparsity with GPGPU,” inProc. 39th IEEE Int. Parallel and Dist. Processing Symp., ser. IPDPS ’25. Milan, Italy: IEEE, Jun. 2025, pp. 926–937
2025
-
[32]
HC-SpMM: Accelerating sparse matrix-matrix multiplication for graphs with hybrid GPU cores,
Z. Li, X. Ke, Y. Zhu, Y. Gao, and Y. Tu, “HC-SpMM: Accelerating sparse matrix-matrix multiplication for graphs with hybrid GPU cores,” inProc. 2025 IEEE 41st Int. Conf. on Data Eng. (ICDE). Hong Kong, China: IEEE, May 2025. [Online]. Available: https://ieeexplore.ieee.org/document/11112857
arXiv 2025
-
[33]
RSH-SpMM: A row-structured hybrid kernel for sparse matrix-matrix multiplication on GPUs,
A. Li, J. Sun, H. Li, W. Ji, and G. Sun, “RSH-SpMM: A row-structured hybrid kernel for sparse matrix-matrix multiplication on GPUs,” February 2026. [Online]. Available: https://arxiv.org/abs/2603.08734
arXiv 2026
-
[34]
Bridging the gap between unstructured SpMM and structured sparse tensor cores,
Y. Dong, Z. Shen, W. Jiang, Z. Liu, Y. Xu, B. He, R. Zheng, and H. Jin, “Bridging the gap between unstructured SpMM and structured sparse tensor cores,” inProc. Int. Conf. for High Perf. Comp., Netw., Storage and Analysis (SC ’25). New York, NY, USA: ACM, 2025, pp. 645–660. [Online]. Available: https://dl.acm.org/doi/10.1145/3712285.3759849
-
[35]
ToT: Triangle counting on tensor cores,
Y. Chen and J. X. Yu, “ToT: Triangle counting on tensor cores,”IEEE Trans. Parallel and Dist. Systems, vol. 36, no. 12, pp. 2679–2692, 2025
2025
-
[36]
Efficient quantized sparse matrix operations on tensor cores,
S. Li, K. Osawa, and T. Hoefler, “Efficient quantized sparse matrix operations on tensor cores,” inProc. Int. Conf. for High Perf. Comp., Netw., Storage and Analysis, ser. SC ’22. Dallas, TX, USA: IEEE, Nov. 2022, pp. 1–15. Preprint submitted to IEEE Transactions on Parallel and Distributed Systems
2022
-
[37]
Neo: Towards efficient fully homomorphic encryption acceleration using tensor cores,
D. Jiao, X. Deng, Z. Wang, S. Fan, Y. Chen, D. Meng, R. Hou, and M. Zhang, “Neo: Towards efficient fully homomorphic encryption acceleration using tensor cores,” inProc. 52nd Int. Symp. on Comp. Arch., ser. ISCA ’25. Tokyo, Japan: ACM, Jun. 2025, pp. 107–121
2025
-
[38]
EPIClear: Exploiting domain-specific features for epistasis detection acceleration on tensor cores,
R. Nobre, M. Gra c ¸a, L. Sousa, and A. Ilic, “EPIClear: Exploiting domain-specific features for epistasis detection acceleration on tensor cores,” inProc. 39th ACM Int. Conf. on Supercomputing, ser. ICS ’25. Salt Lake City, UT, USA: ACM, Jun. 2025, pp. 293–307
2025
-
[39]
TC-GNN: Bridging sparse GNN computation and dense tensor cores on GPUs,
Y. Wang, B. Feng, Z. Wang, G. Huang, and Y. Ding, “TC-GNN: Bridging sparse GNN computation and dense tensor cores on GPUs,” in2023 USENIX Annual Tech. Conf., ser. ATC ’23. Boston, MA, USA: USENIX Assoc., Jul. 2023, pp. 149–164
2023
-
[40]
Accelerating GNNs on GPU sparse tensor cores through N:M sparsity-oriented graph reordering,
J.-A. Chen, H.-H. Sung, R. Zhang, A. Li, and X. Shen, “Accelerating GNNs on GPU sparse tensor cores through N:M sparsity-oriented graph reordering,” inProc. 30th ACM SIGPLAN Annual Symp. on Principles and Practice of Parallel Programming, ser. PPoPP ’25. Las Vegas, NV , USA: ACM, Mar. 2025, pp. 16–28
2025
-
[41]
Tensor core-adapted sparse matrix multiplication for accelerating sparse deep neural networks,
Y. Han, I. Kim, J. Kim, and G. E. Moon, “Tensor core-adapted sparse matrix multiplication for accelerating sparse deep neural networks,” Electronics, vol. 13, no. 20, p. 3981, 2024
2024
-
[42]
VENOM: A vectorized N:M format for unleashing the power of sparse tensor cores,
R. L. Castro, A. Ivanov, D. Andrade, T. Ben-Nun, B. B. Fraguela, and T. Hoefler, “VENOM: A vectorized N:M format for unleashing the power of sparse tensor cores,” inProc. Int. Conf. for High Perf. Comp., Netw., Storage and Analysis, ser. SC ’23. Denver, CO, USA: ACM, Nov. 2023
2023
-
[43]
SparseTIR: Composable abstractions for sparse compilation in deep learning,
Z. Ye, R. Lai, J. Shao, T. Chen, and L. Ceze, “SparseTIR: Composable abstractions for sparse compilation in deep learning,” inProc. 28th ACM Int. Conf. on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’23), Volume 3. Vancouver, BC, Canada: ACM, March 2023, pp. 660–678. [Online]. Available: https://dl.acm.org/doi/10.1145/358...
-
[44]
SparTA: Deep-learning model sparsity via Tensor-with-Sparsity-Attribute,
N. Zheng, B. Lin, Q. Zhang, L. Ma, Y. Yang, F. Yang, Y. Wang, M. Yang, and L. Zhou, “SparTA: Deep-learning model sparsity via Tensor-with-Sparsity-Attribute,” in16th USENIX Symp. on Operating Systems Design and Implementation (OSDI ’22). Carlsbad, CA, USA: USENIX Assoc., July 2022, pp. 213–232
2022
-
[45]
Coruscant: Co- designing GPU kernel and sparse tensor core to advocate unstruc- tured sparsity in efficient LLM inference,
D. Joo, H. Hosseini, R. Hadidi, and B. Asgari, “Coruscant: Co- designing GPU kernel and sparse tensor core to advocate unstruc- tured sparsity in efficient LLM inference,” inProc. 58th IEEE/ACM Int. Symp. on Microarchitecture, ser. MICRO ’25. Seoul, South Korea: ACM, Oct. 2025
2025
-
[46]
GeneralSparse: Bridging the gap in SpMM for pruned large language model inference on GPUs,
Y. Wang, X. Guo, J. Xiao, D. Chen, and G. Tan, “GeneralSparse: Bridging the gap in SpMM for pruned large language model inference on GPUs,” in2025 USENIX Annual Tech. Conf., ser. USENIX ATC ’25. Boston, MA, USA: USENIX Assoc., Jul. 2025, pp. 417–432
2025
-
[47]
H. Xia, Z. Zheng, Y. Li, D. Zhuang, Z. Zhou, X. Qiu, Y. Li, W. Lin, and S. L. Song, “Flash-LLM: Enabling cost-effective and highly-efficient large generative model inference with unstructured sparsity,”Proc. VLDB Endowment, vol. 17, no. 2, pp. 211–224, 2023. [Online]. Available: https://dl.acm.org/doi/10.14778/3626292.3626303
-
[48]
SpInfer: Leveraging low-level sparsity for efficient large language model inference on GPUs,
R. Fan, X. Yu, P . Dong, Z. Li, G. Gong, Q. Wang, W. Wang, and X. Chu, “SpInfer: Leveraging low-level sparsity for efficient large language model inference on GPUs,” in Proc. 20th European Conf. on Computer Systems (EuroSys ’25). Rotterdam, Netherlands: ACM, March 2025. [Online]. Available: https://dl.acm.org/doi/10.1145/3689031.3717481
-
[49]
ConvStencil: Transform stencil computation to matrix multiplication on tensor cores,
Y. Chen, K. Li, Y. Wang, D. Bai, L. Wang, L. Ma, L. Yuan, Y. Zhang, T. Cao, and M. Yang, “ConvStencil: Transform stencil computation to matrix multiplication on tensor cores,” inProc. 29th ACM SIGPLAN Annual Symp. on Principles and Practice of Parallel Programming, ser. PPoPP ’24. Edinburgh, United Kingdom: ACM, Mar. 2024, pp. 333–347
2024
-
[50]
Accelerating reduction and scan using tensor core units,
A. Dakkak, C. Li, J. Xiong, I. Gelado, and W. mei W. Hwu, “Accelerating reduction and scan using tensor core units,” inProc. ACM Int. Conf. on Supercomputing, ser. ICS ’19. Phoenix, AZ, USA: ACM, Jun. 2019, pp. 46–57
2019
-
[51]
[Online]
Parallel Thread Execution ISA, NVIDIA Corporation, 2025, PTX ISA Version 9.1, online documentation. [Online]. Available: https://docs.nvidia.com/cuda/parallel-thread-execution/
2025
-
[52]
To push or to pull: On reducing communication and synchronization in graph computations,
M. Besta, M. Podstawski, L. Groner, E. Solomonik, and T. Hoefler, “To push or to pull: On reducing communication and synchronization in graph computations,” inProc. 26th Int. Symp. on High-Performance Parallel and Dist. Comp., ser. HPDC ’17. New York, NY, USA: ACM, 2017, p. 93–104. [Online]. Available: https://doi.org/10.1145/3078597.3078616
-
[53]
The distribution of the flora in the alpine zone. I,
P . Jaccard, “The distribution of the flora in the alpine zone. I,” New Phytologist, vol. 11, no. 2, pp. 37–50, 1912. [Online]. Available: https://doi.org/10.1111/j.1469-8137.1912.tb05611.x
-
[54]
M. Harris. (2017, may) Cooperative groups: Flexible CUDA thread programming. NVIDIA Dev. Blog, acc.: 2025-12. [Online]. Available: https://developer.nvidia.com/blog/cooperative-groups/
2017
-
[55]
NVIDIA Nsight Compute,
NVIDIA Corporation, “NVIDIA Nsight Compute,” https:// developer.nvidia.com/nsight-compute, 2024, version 2024.3, ac- cessed: 2026
2024
-
[56]
Regularizing graph centrality computations,
A. E. Sarıy ¨uce, E. Saule, K. Kaya, and ¨U. V . C ¸ataly ¨urek, “Regularizing graph centrality computations,”Journal of Parallel and Distributed Computing, vol. 76, pp. 106–119, 2015. [Online]. Available: https://doi.org/10.1016/j.jpdc.2014.07.006
-
[57]
A faster algorithm for betweenness centrality*,
U. Brandes, “A faster algorithm for betweenness centrality*,”The Journal of Math. Soc., vol. 25, no. 2, pp. 163–177, 2001. [Online]. Available: https://doi.org/10.1080/0022250X.2001.9990249
-
[58]
The university of florida sparse matrix collection,
T. A. Davis and Y. Hu, “The University of Florida sparse matrix collection,”ACM Trans. Mathematical Software, vol. 38, no. 1, pp. 1:1–1:25, 2011. [Online]. Available: https://doi.org/10.1145/2049662.2049663
-
[59]
iBFS: Concurrent breadth-first search on GPUs,
H. Liu, H. H. Huang, and Y. Hu, “iBFS: Concurrent breadth-first search on GPUs,” inProceedings of the 2016 International Conference on Management of Data, ser. SIGMOD ’16. San Francisco, California, USA: ACM, 2016, pp. 403–416. [Online]. Available: https://doi.org/10.1145/2882903.2882959
-
[60]
The more the merrier: Efficient multi-source graph traversal,
M. Then, M. Kaufmann, F. Chirigati, T.-A. Hoang-Vu, K. Pham, A. Kemper, T. Neumann, and H. T. Vo, “The more the merrier: Efficient multi-source graph traversal,”Proceedings of the VLDB Endowment, vol. 8, no. 4, pp. 449–460, 2014. [Online]. Available: https://www.vldb.org/pvldb/vol8/p449-then.pdf
2014
-
[61]
Computing classic closeness centrality, at scale,
E. Cohen, D. Delling, T. Pajor, and R. F. Werneck, “Computing classic closeness centrality, at scale,” inProc. 2nd ACM Conf. on Online Social Networks (COSN 2014). ACM, 2014, pp. 37–50
2014
-
[62]
Computing top-k closeness centrality faster in unweighted graphs,
E. Bergamini, M. Borassi, P . Crescenzi, A. Marino, and H. Meyer- henke, “Computing top-k closeness centrality faster in unweighted graphs,”ACM Transactions on Knowledge Discovery from Data, vol. 13, no. 5, pp. 53:1–53:40, 2019
2019
-
[63]
The combinatorial BLAS: Design, implementation, and app
A. Bulu c ¸and J. R. Gilbert, “The combinatorial BLAS: Design, implementation, and app.”The Int. J. of High Perf. Comp. App., vol. 25, no. 4, pp. 496–509, 2011. [Online]. Available: https://doi.org/10.1177/1094342011403516
-
[64]
Graphblast: A high-perf. linear algebra-based graph framework on the GPU,
C. Yang, A. Bulu c ¸, and J. D. Owens, “Graphblast: A high-perf. linear algebra-based graph framework on the GPU,”ACM Trans. on Mathematical Software, vol. 48, no. 1, pp. 1:1–1:51, 2022. [Online]. Available: https://doi.org/10.1145/3466795 Deniz Elbekis an undergraduate student in Computer Science and Engineering at Sabanci University. His areas of resear...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.