RAMC: Remote Access Memory Channels over HPE Slingshot
Pith reviewed 2026-06-28 03:31 UTC · model grok-4.3
The pith
RAMC persistent channels deliver higher bandwidth than MPI on Slingshot networks while scaling to 19.6k processes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
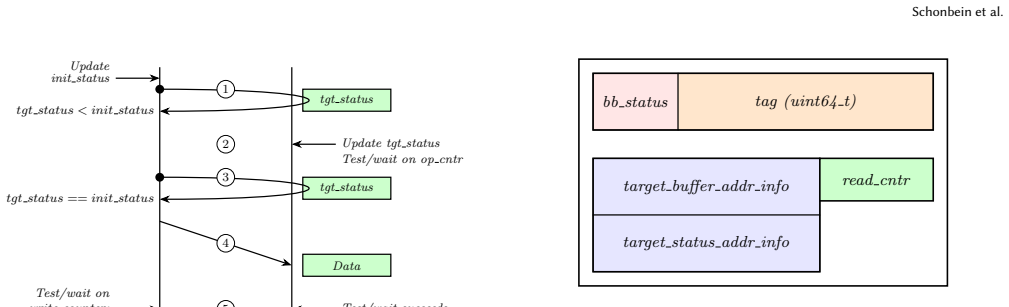
RAMC is a new explicit one-sided communication library based on the core concept of a persistent uni-directional communication channel that leverages Slingshot's unique memory region counters to enable efficient completion notification, addressing scalability and usability challenges in existing frameworks such as MPI RMA, OpenSHMEM, and PGAS models while outperforming Cray's proprietary MPI implementation in bandwidth for small-to-medium messages.
What carries the argument
Persistent uni-directional communication channel that uses Slingshot memory region counters for completion notification.
If this is right
- RAMC applications scale without difficulty to 19.6 thousand processes across 250 nodes.
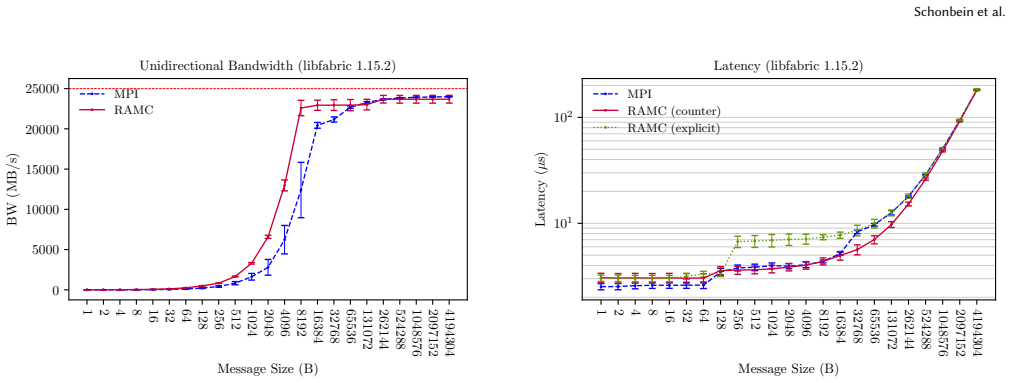
- Bandwidth increases of approximately 100-130% occur for 1B-4KiB messages versus Cray MPI under libfabric 1.15.2.
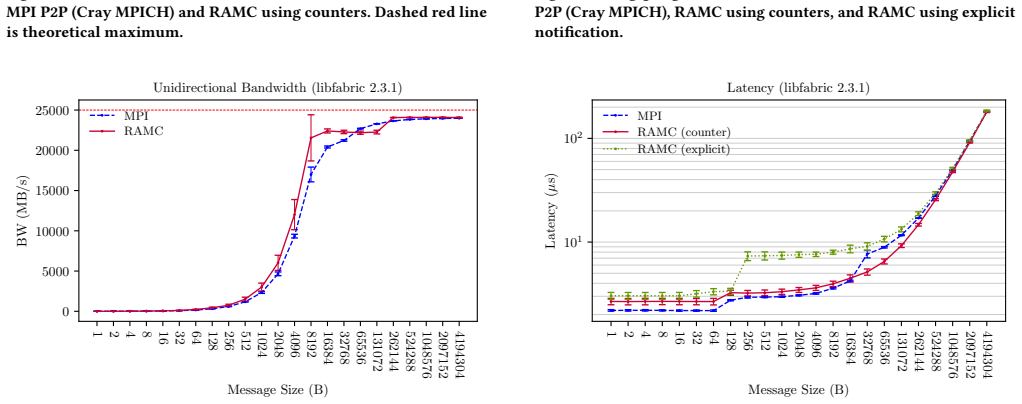
- Bandwidth increases of approximately 30-45% occur for the same message sizes under libfabric 2.3.1.
- RAMC retains dynamic flexibility that partitioned MPI communication sacrifices.
- Small message latencies remain an area identified for further improvement.
Where Pith is reading between the lines
- Channel-based designs like RAMC could be ported to other RDMA networks that expose similar completion counters.
- Avoiding collective operations for window creation may benefit codes with irregular or dynamic communication patterns.
- Production workloads with different message size distributions or synchronization needs could yield different relative performance.
- The explicit channel model might complement or replace parts of implicit PGAS implementations without requiring full language changes.
Load-bearing premise
The chosen microbenchmarks and heat diffusion application represent production workloads and the observed bandwidth differences come from the RAMC design rather than unstated implementation or measurement differences.
What would settle it
Running the identical microbenchmarks on the same Slingshot hardware with the same libfabric versions and measurement methodology but finding no bandwidth advantage for RAMC over MPI would falsify the performance claim.
Figures



read the original abstract
In this paper, we present Remote Access Memory Channels (RAMC), an explicit one-sided communication library designed to leverage the capabilities of HPE Cray Slingshot network hardware. Existing one-sided communication frameworks, such as MPI RMA and OpenSHMEM, rely on monolithic shared memory models that introduce scalability and usability challenges. These frameworks often assume symmetric memory regions or require blocking collective operations for window creation, which can mismatch user communication needs and hinder performance. Implicit models, such as PGAS and UPC, aim to simplify programming by treating local and remote memory as a unified region but ultimately rely on explicit mechanisms to implement data movement. MPI's recently-introduced partitioned communication API offers a persistent point-to-point interface but sacrifices the dynamic flexibility of RDMA. RAMC is designed to address these limitations. Based on the core concept of a persistent uni-directional communication channel, RAMC leverages Slingshot's unique memory region counters to enable efficient completion notification. Experiments with a RAMC-based heat diffusion code demonstrate RAMC has no difficulty scaling to 19.6 thousand processes across 250 nodes, and microbenchmark studies across multiple libfabric versions show RAMC can outperform Cray's proprietary MPI implementation (e.g., increases in bandwidth ranging from approx. 100%-130% for 1B-4KiB messages under libfabric 1.15.2, and from approx. 30%-45% under libfabric 2.3.1) while identifying additional areas for improvement, such as small message latencies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Remote Access Memory Channels (RAMC), an explicit one-sided communication library for HPE Cray Slingshot networks. RAMC is built around persistent uni-directional channels that exploit Slingshot memory-region counters for completion notification. It positions RAMC as addressing limitations in MPI RMA, OpenSHMEM, PGAS, and MPI partitioned communication. The central empirical claims are that a RAMC-based heat-diffusion code scales without difficulty to 19.6k processes on 250 nodes and that microbenchmarks show RAMC delivering 100-130% higher bandwidth than Cray MPI for 1B-4KiB messages under libfabric 1.15.2 (and 30-45% under 2.3.1).
Significance. If the performance and scaling claims are substantiated with adequate experimental controls, RAMC would represent a practical middle ground between fully explicit RDMA and monolithic shared-memory models for Slingshot-class hardware. The work could inform future one-sided library design and provide a concrete alternative for workloads that benefit from persistent uni-directional channels.
major comments (2)
- [Abstract] Abstract: the headline bandwidth claims (100-130% and 30-45% improvements for 1B-4KiB messages) are load-bearing for the contribution, yet the manuscript supplies no description of the experimental controls, baseline MPI configuration, completion-notification paths, timing methodology, or whether identical Slingshot memory-region counter usage was enforced between RAMC and Cray MPI. Without these details the attribution of gains to the persistent-channel abstraction cannot be verified.
- [Abstract] Abstract (heat-diffusion scaling result): the claim that RAMC “has no difficulty scaling to 19.6 thousand processes across 250 nodes” is presented without error bars, run-to-run variability, baseline MPI scaling data on the same platform, or discussion of potential confounds such as network configuration or collective overheads. This information is required to support the scalability assertion.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. The two major comments both correctly identify that the abstract and main text lack sufficient experimental detail to support the central performance and scaling claims. We agree that these details are necessary for verification and will make the requested revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline bandwidth claims (100-130% and 30-45% improvements for 1B-4KiB messages) are load-bearing for the contribution, yet the manuscript supplies no description of the experimental controls, baseline MPI configuration, completion-notification paths, timing methodology, or whether identical Slingshot memory-region counter usage was enforced between RAMC and Cray MPI. Without these details the attribution of gains to the persistent-channel abstraction cannot be verified.
Authors: We agree that the manuscript does not currently supply the requested experimental controls. The performance numbers are central to the contribution, and without them the attribution cannot be independently verified. We will add a dedicated experimental methodology subsection that describes the Cray MPI baseline configuration, the libfabric versions tested, the timing methodology, completion-notification paths, and explicit confirmation that memory-region counter usage was matched between RAMC and the MPI baseline. The revised text will also clarify how the persistent-channel design produces the observed gains. revision: yes
-
Referee: [Abstract] Abstract (heat-diffusion scaling result): the claim that RAMC “has no difficulty scaling to 19.6 thousand processes across 250 nodes” is presented without error bars, run-to-run variability, baseline MPI scaling data on the same platform, or discussion of potential confounds such as network configuration or collective overheads. This information is required to support the scalability assertion.
Authors: The referee is correct that the scaling claim lacks the supporting statistical and comparative information needed to substantiate it. We will revise the results section to include error bars on all scaling plots, report run-to-run variability, add direct MPI scaling curves measured on the identical platform and network configuration, and discuss potential confounds including network settings and any collective operations. These additions will be referenced from the abstract. revision: yes
Circularity Check
No circularity; experimental claims rest on direct benchmarks
full rationale
The paper introduces RAMC as a new one-sided library and supports its claims solely via microbenchmark bandwidth/latency numbers and a heat-diffusion scaling run at 19.6k processes. No equations, fitted parameters, predictions, or self-citation chains appear in the abstract or described content. All load-bearing statements are empirical comparisons to MPI under stated libfabric versions; these do not reduce to the inputs by construction. This is the expected non-finding for a systems paper whose central contribution is implementation and measurement rather than derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
OSU Micro-Benchmarks (OMB) 7.5
2024. OSU Micro-Benchmarks (OMB) 7.5. Online. https://mvapich.cse.ohio- state.edu/benchmarks/ Accessed: 2025
2024
-
[2]
Barrett, Ron Brightwell, Ryan E
Brian W. Barrett, Ron Brightwell, Ryan E. Grant, Whit Schonbein, Scott Hemmert, Kevin Pedretti, Keith Underwood, Rolf Riesen, Mathieu Barbe, Luiz H. Suraty Filho, Alexandre Ratchov, and Arthur B. Maccabe. 2022.The Portals 4.3 Network Programming Interface. Technical Report SAND2022-8810. Sandia National Laboratories, Albuquerque, New Mexico. https://www.s...
2022
-
[3]
In: European Conference on Com- puter Vision
Brian W. Barrett, Ron Brightwell, K. Scott Hemmert, Kyle B. Wheeler, and Keith D. Underwood. 2011. Using Triggered Operations to Offload Rendezvous Messages. InRecent Advances in the Message Passing Interface (Lecture Notes in Computer Science). Springer, Berlin, Heidelberg, 120–129. https://doi.org/10.1007/978-3- 642-24449-0_15
-
[4]
Roberto Belli and Torsten Hoefler. 2015. Notified Access: Extending Remote Memory Access Programming Models for Producer-Consumer Synchronization. In2015 IEEE International Parallel and Distributed Processing Symposium. 871–881. https://doi.org/10.1109/IPDPS.2015.30
-
[5]
Bridges, Derek Schafer, Jack Lange, James B
Patrick G. Bridges, Derek Schafer, Jack Lange, James B. White III, Anthony Skjel- lum, Evan Suggs, Thomas Hines, Purushotham Bangalore, Matthew G. F. Dosanjh, and Whit Schonbein. 2026. Co-Design and Evaluation of a CPU-Free MPI GPU Communication Abstraction and Implementation. arXiv:2602.15356 [cs.DC] https://arxiv.org/abs/2602.15356
-
[6]
Castain, Joshua Hursey, Aurelien Bouteiller, and David Solt
Ralph H. Castain, Joshua Hursey, Aurelien Bouteiller, and David Solt. 2018. PMIx: Process management for exascale environments.Parallel Comput.79 (Nov. 2018), 9–29. https://doi.org/10.1016/j.parco.2018.08.002
-
[7]
Matthew GF Dosanjh, Andrew Worley, Derek Schafer, Prema Soundararajan, Sheikh Ghafoor, Anthony Skjellum, Purushotham V Bangalore, and Ryan E Grant
-
[8]
Implementation and evaluation of MPI 4.0 partitioned communication libraries.Parallel Comput.108 (2021), 102827
2021
-
[9]
Ferreira, Patrick Bridges, and Ron Brightwell
Kurt B. Ferreira, Patrick Bridges, and Ron Brightwell. 2008. Characterizing application sensitivity to OS interference using kernel-level noise injection. In Proceedings of the 2008 ACM/IEEE Conference on Supercomputing(Austin, Texas) (SC ’08). IEEE Press, Article 19, 12 pages
2008
-
[10]
1997.MPI: A Message-Passing Interface Stan- dard Version 2.0
Message Passing Interface Forum. 1997.MPI: A Message-Passing Interface Stan- dard Version 2.0. https://www.mpi-forum.org/docs/mpi-2.0/mpi20-report.pdf
1997
-
[11]
Thomas Gillis, Ken Raffenetti, Hui Zhou, Yanfei Guo, and Rajeev Thakur. 2023. Quantifying the performance benefits of partitioned communication in mpi. In Proceedings of the 52nd International Conference on Parallel Processing. 285–294
2023
-
[12]
Ryan E Grant, Matthew GF Dosanjh, Michael J Levenhagen, Ron Brightwell, and Anthony Skjellum. 2019. Finepoints: Partitioned multithreaded MPI communi- cation. InInternational Conference on High Performance Computing. Springer, 330–350
2019
-
[13]
Scott Hemmert, Brian Barrett, and Keith D
K. Scott Hemmert, Brian Barrett, and Keith D. Underwood. 2010. Using Triggered Operations to Offload Collective Communication Operations. InRecent Advances in the Message Passing Interface (Lecture Notes in Computer Science). Springer, Berlin, Heidelberg, 249–256. https://doi.org/10.1007/978-3-642-15646-5_26
-
[14]
Nathan Hjelm, Matthew GF Dosanjh, Ryan E Grant, Taylor Groves, Patrick Bridges, and Dorian Arnold. 2018. Improving MPI multi-threaded RMA com- munication performance. InProceedings of the 47th International Conference on Parallel Processing. 1–11. RAMC: Remote Access Memory Channels over HPE Slingshot
2018
-
[15]
Chung-Hsing Hsu, Neena Imam, Akhil Langer, Sreeram Potluri, and Chris J Newburn. 2020. An initial assessment of nvshmem for high performance com- puting. In2020 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW). IEEE, 1–10
2020
-
[16]
Panda, Darius Buntinas, Rajeev Thakur, and William D
Weihang Jiang, Jiuxing Liu, Hyun-Wook Jin, Dhabaleswar K. Panda, Darius Buntinas, Rajeev Thakur, and William D. Gropp. 2004. Efficient Implementation of MPI-2 Passive One-Sided Communication on InfiniBand Clusters. InRecent Advances in Parallel Virtual Machine and Message Passing Interface, Dieter Kran- zlmüller, Péter Kacsuk, and Jack Dongarra (Eds.). Sp...
2004
-
[17]
Jithin Jose, Sreeram Potluri, Hari Subramoni, Xiaoyi Lu, Khaled Hamidouche, Karl Schulz, Hari Sundar, and Dhabaleswar K Panda. 2014. Designing scalable out- of-core sorting with hybrid MPI+ PGAS programming models. InProceedings of the 8th International Conference on Partitioned Global Address Space Programming Models. 1–9
2014
-
[18]
Ferreira, Patrick Widener, Patrick G
Scott Levy, Kurt B. Ferreira, Patrick Widener, Patrick G. Bridges, and Oscar H. Mondragon. 2016. How I Learned to Stop Worrying and Love In Situ Analytics: Leveraging Latent Synchronization in MPI Collective Algorithms. InProceedings of the 23rd European MPI Users’ Group Meeting(Edinburgh, United Kingdom)(Eu- roMPI ’16). Association for Computing Machiner...
-
[19]
Scott Levy, Whit Schonbein, and Craig Ulmer. 2024. Leveraging High- Performance Data Transfer to Offload Data Management Tasks to SmartNICs. In 2024 IEEE International Conference on Cluster Computing (CLUSTER). 346–356. https://doi.org/10.1109/CLUSTER59578.2024.00037
-
[20]
Edgar A. León, Joseph Glenski, Mark Stock, Kim McMahon, William Loewe, Clark Snyder, Larry Kaplan, Srinath Vadlamani, Timothy I. Mattox, Trent D’Hooge, Brian Behlendorf, Nathan Hanford, Ramesh Pankajakshan, and Matthew L. Leininger. 2025. Breaking the System Noise Barrier at Exascale. InProceed- ings of the International Conference for High Performance Co...
-
[21]
W. Pepper Marts, Donald A. Kruse, Matthew G. F. Dosanjh, Whit Schonbein, Scott Levy, and Patrick G. Bridges. 2024. CMB: A Configurable Messaging Benchmark to Explore Fine-Grained Communication. In2024 IEEE 24th Inter- national Symposium on Cluster, Cloud and Internet Computing (CCGrid). 28–38. https://doi.org/10.1109/CCGrid59990.2024.00013
-
[22]
2012.MPI: A Message-Passing Interface Stan- dard Version 3.0
Message Passing Interface Forum. 2012.MPI: A Message-Passing Interface Stan- dard Version 3.0. https://www.mpi-forum.org/docs/mpi-3.0/mpi30-report.pdf
2012
-
[23]
2021.MPI: A Message-Passing Interface Stan- dard Version 4.0
Message Passing Interface Forum. 2021.MPI: A Message-Passing Interface Stan- dard Version 4.0. https://www.mpi-forum.org/docs/mpi-4.0/mpi40-report.pdf
2021
- [24]
-
[25]
Poole, Oscar Hernandez, Jeffery A
Stephen W. Poole, Oscar Hernandez, Jeffery A. Kuehn, Galen M. Shipman, An- thony Curtis, and Karl Feind. 2011.OpenSHMEM - Toward a Unified RMA Model. Springer US, Boston, MA, 1379–1391. https://doi.org/10.1007/978-0-387-09766- 4_490
-
[26]
Yıltan Hassan Temuçin, Whit Schonbein, Scott Levy, Amirhossein Sojoodi, Ryan E Grant, and Ahmad Afsahi. 2024. Design and Implementation of MPI- Native GPU-Initiated MPI Partitioned Communication. InSC24-W: Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 436–447
2024
-
[27]
K. D. Underwood, J. Coffman, R. Larsen, K. S. Hemmert, B. W. Barrett, R. Brightwell, and M. Levenhagen. 2011. Enabling Flexible Collective Communica- tion Offload with Triggered Operations. In2011 IEEE 19th Annual Symposium on High Performance Interconnects. 35–42. https://doi.org/10.1109/HOTI.2011.15
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.