X4Val: Learning Neural Surrogates for Variance-Reduced Policy Evaluation
Pith reviewed 2026-06-28 05:43 UTC · model grok-4.3
The pith
X4Val learns a neural predictor from auxiliary data to cut variance in real-world robotic policy evaluation without paired samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
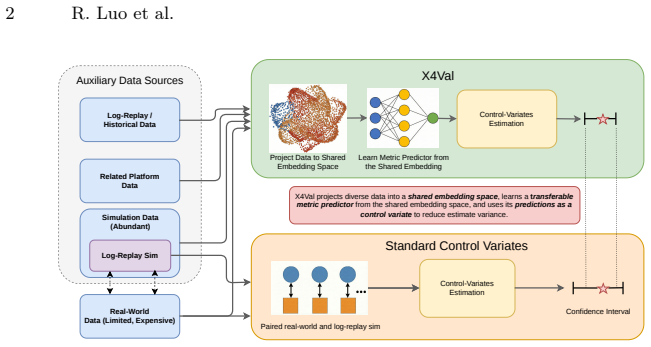
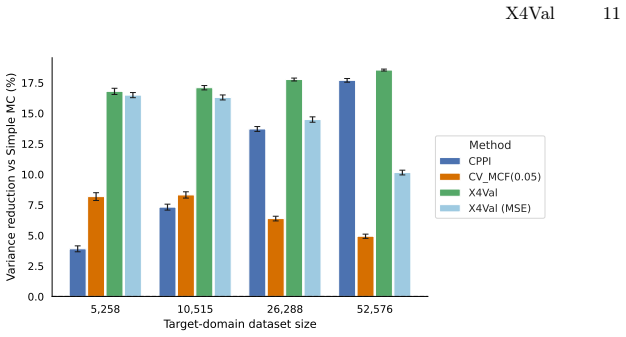
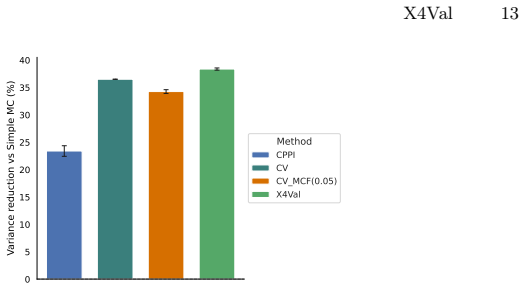
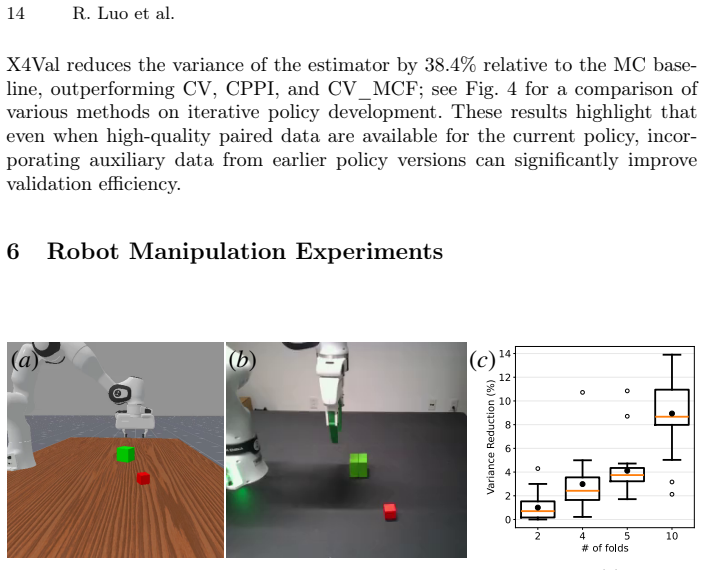
X4Val embeds samples from real and auxiliary domains into a shared representation space and learns a transferable predictor of real-world metrics; this learned predictor is then incorporated into a control-variates estimator, enabling variance reduction even when paired samples are unavailable. The framework supplies theoretical analysis and achieves up to 38.4 percent variance reduction with consistent gains over baselines on autonomous driving and real-world robot manipulation tasks.
What carries the argument
The neural surrogate predictor trained in a shared embedding space and inserted into the control-variates estimator.
If this is right
- Non-paired heterogeneous data sources become usable for high-confidence real-world metric estimation.
- Variance reduction reaches up to 38.4 percent on autonomous driving and robot manipulation tasks.
- Empirical results show consistent improvements over strong baselines.
- Theoretical analysis backs the variance reduction property of the estimator.
Where Pith is reading between the lines
- The shared embedding might support evaluation of policies in entirely new environments if the representation proves policy-invariant.
- The method could shorten iteration cycles in robotics by lowering the real-world data volume required per policy update.
- Similar surrogate-augmented control-variates setups might apply to other domains that rely on abundant but non-representative auxiliary data, such as simulation-heavy engineering validation.
Load-bearing premise
The predictor learned from auxiliary domains must remain accurate and unbiased enough when plugged into the control-variates estimator for the target real metric.
What would settle it
Collect a large held-out set of real-world samples, compute the estimator variance both with and without the learned predictor, and check whether the reduction matches or exceeds the reported levels or whether predictor bias nullifies the gain.
Figures

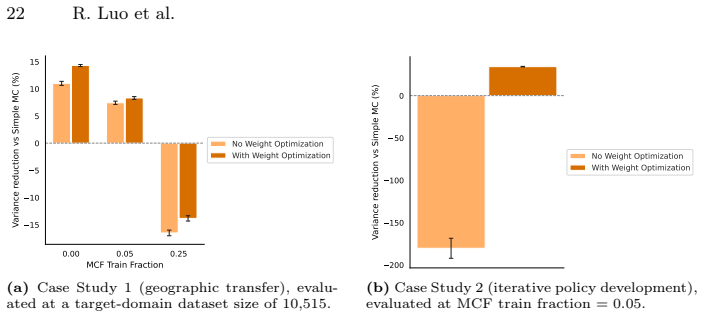
read the original abstract
Rigorous evaluation of learning-based robotic systems is an essential prerequisite for deployment. However, real-world test data is expensive to gather; moreover, in a typical iterative development context, data gathered from the latest policy is necessarily limited in scale. This motivates evaluation methodologies that make use of heterogeneous data sources, including simulation, historical policy logs, and data collected from related platforms or environments. While such auxiliary data are abundant and inexpensive, they are generally not directly representative of real-world outcomes -- for example, performance in simulation may differ substantially from performance in the real world -- making their principled use for high-confidence performance estimation challenging. In this paper, we introduce X4Val, a general framework for variance-reduced real-world metric estimation in the presence of non-paired, multi-domain data. X4Val embeds samples from real and auxiliary domains into a shared representation space and learns a transferable predictor of real-world metrics; this learned predictor is then incorporated into a control-variates estimator, enabling variance reduction even when paired samples are unavailable. We provide theoretical analysis and empirical evaluations on autonomous driving and real-world robot manipulation tasks, domains across which X4Val achieves up to 38.4% variance reduction and demonstrates consistent improvements over strong baselines. These results show that non-paired, heterogeneous data can be leveraged to substantially improve the sample efficiency of rigorous robotic system validation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces X4Val, a framework for variance-reduced real-world metric estimation in robotics using non-paired multi-domain data. Samples from real and auxiliary domains (e.g., simulation, historical logs) are embedded into a shared representation space; a transferable neural predictor of the target real-world metric is learned from this space and then plugged into a control-variates estimator. The method is supported by theoretical analysis and evaluated on autonomous driving and real-world robot manipulation tasks, where it reports up to 38.4% variance reduction over strong baselines while remaining consistent across domains.
Significance. If the unbiasedness of the control-variates estimator is preserved under domain shift, the approach would meaningfully improve sample efficiency for rigorous policy evaluation in robotics, where real-world data collection is costly and auxiliary data sources are abundant but non-representative. The explicit use of learned surrogates inside control variates, together with the reported empirical gains, would constitute a practical advance over standard Monte-Carlo or paired-sample methods.
major comments (1)
- [Theoretical Analysis] The central claim that the estimator remains unbiased (and therefore that reported variance reductions are meaningful for high-confidence estimation) rests on the learned predictor satisfying E[P(real)] = E[M] (or a known offset) after transfer from auxiliary domains. The skeptic note correctly identifies this as the least secure assumption; the theoretical analysis section must therefore contain an explicit derivation or bound showing that any residual domain gap does not introduce a non-zero bias term in the control-variates estimator E[M - β(P - E[P])]. Without such a derivation or a sensitivity analysis, the variance-reduction numbers alone do not establish that the estimator is suitable for rigorous validation.
minor comments (2)
- [Introduction] The abstract and introduction would benefit from a short statement clarifying whether the control-variates coefficient β is estimated from the same data or held out, as this choice directly affects both bias and variance.
- [Experiments] Figure captions should explicitly state the number of independent runs and whether error bars represent standard error or standard deviation.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for emphasizing the need to rigorously address potential bias under domain shift. We respond to the major comment below and will revise the manuscript to include the requested derivation and sensitivity analysis.
read point-by-point responses
-
Referee: [Theoretical Analysis] The central claim that the estimator remains unbiased (and therefore that reported variance reductions are meaningful for high-confidence estimation) rests on the learned predictor satisfying E[P(real)] = E[M] (or a known offset) after transfer from auxiliary domains. The skeptic note correctly identifies this as the least secure assumption; the theoretical analysis section must therefore contain an explicit derivation or bound showing that any residual domain gap does not introduce a non-zero bias term in the control-variates estimator E[M - β(P - E[P])]. Without such a derivation or a sensitivity analysis, the variance-reduction numbers alone do not establish that the estimator is suitable for rigorous validation.
Authors: We agree that the unbiasedness claim requires explicit handling of residual domain gap after transfer. Section 3 derives that the control-variates estimator E[M - β(P - E[P])] is unbiased whenever E[P] = E[M] holds in the target (real) domain; the analysis treats the learned predictor as satisfying this equality after embedding into the shared space. However, the current write-up does not provide a quantitative bound on the bias that would arise if transfer is imperfect. In the revision we will add (i) a derivation bounding the absolute bias |E[M - β(P - E[P])]| by the product of the control-variate coefficient and an integral probability metric (e.g., Wasserstein-1) between the embedded real and auxiliary distributions, and (ii) a sensitivity study in the experimental section that injects controlled domain discrepancies and reports both the resulting bias and the observed variance reduction. These additions will make the theoretical guarantees and empirical claims directly comparable. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The provided abstract and description present X4Val as a new framework that learns a transferable neural predictor from multi-domain embeddings and plugs it into a standard control-variates estimator. No equations, self-citations, or fitted quantities are shown that reduce the claimed variance reduction to a tautology or to inputs by construction. The method relies on independent statistical theory (control variates) and standard supervised learning, with the domain-transfer assumption stated explicitly rather than smuggled in via prior self-work. This is the common honest case of a self-contained proposal against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Science382(6671), 669–674 (2023)
Angelopoulos, A.N., Bates, S., Fannjiang, C., Jordan, M.I., Zrnic, T.: Prediction- powered inference. Science382(6671), 669–674 (2023)
2023
-
[2]
arXiv preprint arXiv:2311.01453 (2023)
Angelopoulos, A.N., Duchi, J.C., Zrnic, T.: Ppi++: Efficient prediction-powered inference. arXiv preprint arXiv:2311.01453 (2023)
Pith/arXiv arXiv 2023
-
[3]
arXiv preprint arXiv:2510.04354 (2025)
Badithela, A., Snyder, D., Zha, L., Mikhail, J., O’Kelly, M., Dixit, A., Majumdar, A.: Reliable and scalable robot policy evaluation with imperfect simulators. arXiv preprint arXiv:2510.04354 (2025)
arXiv 2025
-
[4]
arXiv preprint arXiv:2403.07008 (2024)
Boyeau, P., Angelopoulos, A.N., Yosef, N., Malik, J., Jordan, M.I.: Autoeval done right: Using synthetic data for model evaluation. arXiv preprint arXiv:2403.07008 (2024)
Pith/arXiv arXiv 2024
-
[5]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., Beijbom, O.: nuscenes: A multimodal dataset for autonomous driving. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11621–11631 (2020)
2020
-
[6]
Journal of Personalized Medicine13(2023)
Chato, L., Regentova, E.E.: Survey of transfer learning approaches in the machine learning of digital health sensing data. Journal of Personalized Medicine13(2023)
2023
-
[7]
The International Journal of Robotics Research44(10-11), 1684–1704 (2025)
Chi,C.,Xu,Z.,Feng,S.,Cousineau,E.,Du,Y.,Burchfiel,B.,Tedrake,R.,Song,S.: Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research44(10-11), 1684–1704 (2025)
2025
-
[8]
In: North American Chapter of the Association for Computational Linguistics (2019)
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: Pre-training of deep bidi- rectional transformers for language understanding. In: North American Chapter of the Association for Computational Linguistics (2019)
2019
-
[9]
Advances in Neural Information Process- ing Systems36, 7730–7742 (2023)
Gulino, C., Fu, J., Luo, W., Tucker, G., Bronstein, E., Lu, Y., Harb, J., Pan, X., Wang, Y., Chen, X., et al.: Waymax: An accelerated, data-driven simulator for large-scale autonomous driving research. Advances in Neural Information Process- ing Systems36, 7730–7742 (2023)
2023
-
[10]
arXiv preprint arXiv:2008.12037 (2020)
Iakovleva, E., Verbeek, J.J., Karteek, A.: Meta-learning with shared amortized variational inference. arXiv preprint arXiv:2008.12037 (2020)
arXiv 2008
-
[11]
arXiv preprint arXiv:2201.05867 (2022)
Jiang, J., Shu, Y., Wang, J., Long, M.: Transferability in deep learning: A survey. arXiv preprint arXiv:2201.05867 (2022)
arXiv 2022
-
[12]
In: International conference on machine learning
Jiang, N., Li, L.: Doubly robust off-policy value evaluation for reinforcement learn- ing. In: International conference on machine learning. pp. 652–661. PMLR (2016)
2016
-
[13]
In: Conference on Robot Learning (2023)
Katdare, P., Jiang, N., Driggs-Campbell, K.: Marginalized importance sampling for off-environment policy evaluation. In: Conference on Robot Learning (2023)
2023
-
[14]
Levine, S., Kumar, A., Tucker, G., Fu, J.: Offline reinforcement learning: Tutorial, review,andperspectivesonopenproblems.arXivpreprintarXiv:2005.01643(2020) X4Val 17
Pith/arXiv arXiv 2005
-
[15]
In: Proceedings of the Conference on Robot Learning (CoRL) (2025)
Luo, R., Yang, H., Watson, M., Sharma, A., Veer, S., Schmerling, E., Pavone, M.: Sim2val: Leveraging correlation across test platforms for variance-reduced metric estimation. In: Proceedings of the Conference on Robot Learning (CoRL) (2025)
2025
-
[16]
arXiv preprint arXiv:2507.20068 (2025)
Mandyam, A., Meng, J., Gao, G., Sun, J., Schwager, M., Engelhardt, B.E., Brun- skill, E.: Perry: Policy evaluation with confidence intervals using auxiliary data. arXiv preprint arXiv:2507.20068 (2025)
Pith/arXiv arXiv 2025
-
[17]
arXiv preprint arXiv:2107.14483 (2021)
Mu, T., Ling, Z., Xiang, F., Yang, D., Li, X., Tao, S., Huang, Z., Jia, Z., Su, H.: Maniskill: Generalizable manipulation skill benchmark with large-scale demonstra- tions. arXiv preprint arXiv:2107.14483 (2021)
arXiv 2021
-
[18]
Niu, H., Hu, J., Zhou, G., Zhan, X.: A comprehensive survey of cross-domain policy transfer for embodied agents. ArXivabs/2402.04580(2024)
arXiv 2024
-
[19]
NVIDIA, Cao, Y., de Lutio, R., Fidler, S., Cobo, G.G., Gojcic, Z., Igl, M., Ivanovic, B.,Karkus,P.,Esturo,J.M.,Pavone,M.,Smith,A.,Tanimura,E.,Tyszkiewicz,M., Watson, M., Wu, Q., Zhang, L.: Alpasim: A modular, lightweight, and data-driven research simulator for autonomous driving (October 2025),https://github.com/ NVlabs/alpasim
2025
-
[20]
NVIDIA Corporation: PhysicalAI-Autonomous-Vehicles dataset (October 2025), https://huggingface.co/datasets/nvidia/PhysicalAI-Autonomous-Vehicles
2025
-
[21]
arXiv preprint arXiv:2304.07193 (2023)
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
Pith/arXiv arXiv 2023
-
[22]
domains/mc/(2013)
Owen, A.B.: Monte Carlo theory, methods and examples.https://artowen.su. domains/mc/(2013)
2013
-
[23]
In: ICML
Precup, D., Sutton, R.S., Singh, S.: Eligibility traces for off-policy policy evalua- tion. In: ICML. vol. 2000, pp. 759–766. Citeseer (2000)
2000
-
[24]
In: International Confer- ence on Learning Representations (2018)
Ravi, S., Beatson, A.: Amortized bayesian meta-learning. In: International Confer- ence on Learning Representations (2018)
2018
-
[25]
In: International Conference on Artificial Neural Networks (2018)
Tan, C., Sun, F., Kong, T., Zhang, W., Yang, C., Liu, C.: A survey on deep transfer learning. In: International Conference on Artificial Neural Networks (2018)
2018
-
[26]
Yosinski, J., Clune, J., Bengio, Y., Lipson, H.: How transferable are features in deep neural networks? ArXivabs/1411.1792(2014)
Pith/arXiv arXiv 2014
-
[27]
Zaheer, M., Kottur, S., Ravanbakhsh, S., Póczos, B., Salakhutdinov, R., Smola, A.: Deep sets (2017)
2017
-
[28]
arXiv preprint arXiv:2508.14285 (2025)
Zhang, L., Snell, J., Griffiths, T.: Amortized bayesian meta-learning for low-rank adaptation of large language models. arXiv preprint arXiv:2508.14285 (2025)
arXiv 2025
-
[29]
arXiv preprint arXiv:2502.10563 (2025)
Zhou, Z., Song, Y., Zanette, A.: Accelerating unbiased llm evaluation via synthetic feedback. arXiv preprint arXiv:2502.10563 (2025)
arXiv 2025
-
[30]
Proceedings of the National Academy of Sciences of the United States of America121(2024) 18 R
Zrnic, T., Candès, E.J.: Cross-prediction-powered inference. Proceedings of the National Academy of Sciences of the United States of America121(2024) 18 R. Luo et al. A Cross-Fitted Estimator and Confidence Intervals This section gives the full cross-fitted version of the estimator described in Sec- tion 4. Cross-fitting allows all labeled target-domain s...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.