Beyond Generative Decoding: Discriminative Hidden-State Readout from a Native Omni-Modal LLM for Multimodal Sentiment Analysis
Pith reviewed 2026-06-27 22:58 UTC · model grok-4.3
The pith
Discriminative readout from the final hidden state of an omni-modal LLM outperforms generative text decoding for continuous multimodal sentiment analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
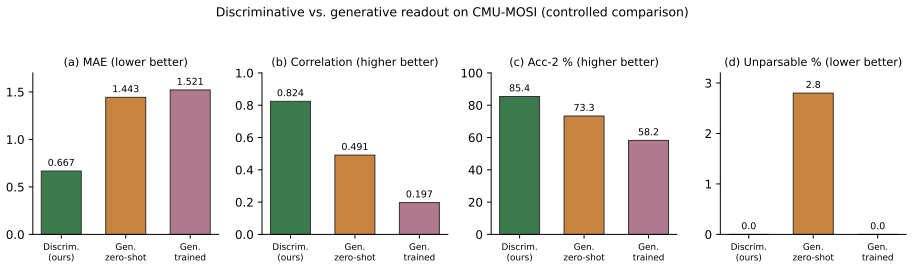
Mapping the final-layer hidden state of the last non-padding token directly to a continuous score via a regression head, after QLoRA adaptation of the native omni-modal LLM, yields MAE 0.551 and correlation 0.888 on CMU-MOSI plus MAE 0.506 and correlation 0.790 on CMU-MOSEI, while the generative readout alternative more than doubles the error and yields unparsable outputs.
What carries the argument
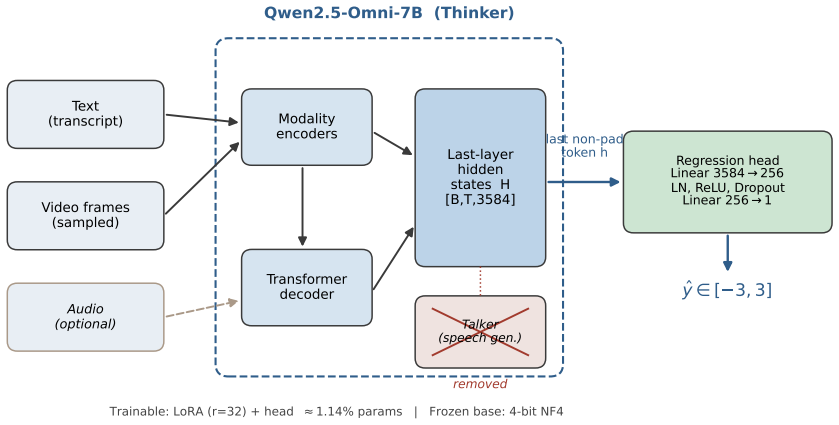
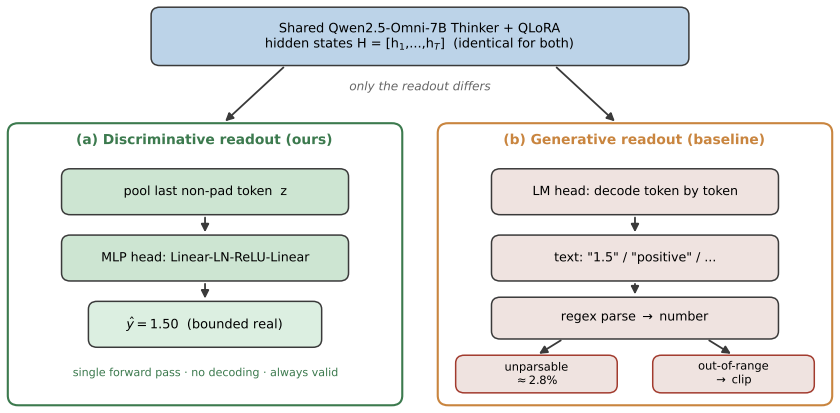
Discriminative hidden-state readout: a lightweight regression head applied to the final-layer hidden state of the last non-padding token in a single forward pass.
If this is right
- The full 7B model including video and audio processing trains with 10-21 GB peak memory on a single consumer GPU.
- Modality ablations indicate a text-dominant regime on CMU-MOSI.
- The discriminative method exhibits strong stability across multiple random seeds.
- Generative readout incurs higher latency and 2.8 percent zero-shot unparsable outputs.
Where Pith is reading between the lines
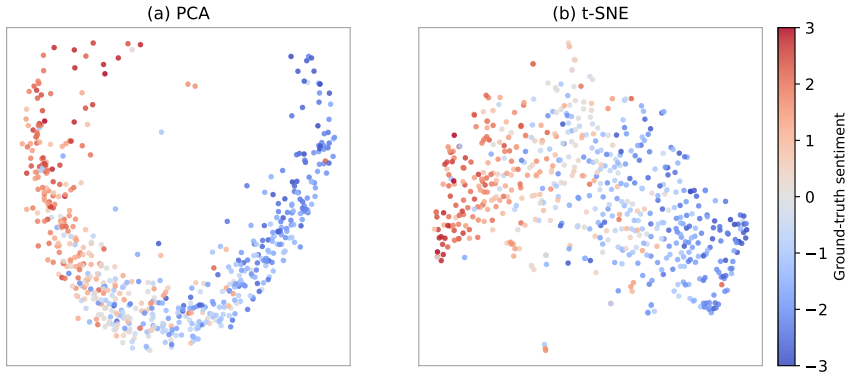
- The performance gap suggests that hidden states retain continuous-valued information more directly than autoregressive text generation for regression targets.
- The single-forward-pass design may generalize to other multimodal continuous prediction tasks where discrete decoding introduces quantization noise.
- Low parameter count and consumer-GPU feasibility could enable on-device multimodal affect monitoring without cloud offload.
Load-bearing premise
The final-layer hidden state of the last non-padding token already encodes a representation sufficient for accurate continuous regression after only LoRA adaptation.
What would settle it
If the generative readout, after identical supervised training on the same data and backbone, matches or beats the reported MAE without producing unparsable or out-of-range outputs, the claimed advantage of the discriminative method would not hold.
Figures
read the original abstract
Multimodal sentiment analysis (MSA) infers human affect from language, acoustic, and visual signals. Recent methods increasingly adapt large multimodal models (LMMs) via generative readout: prompting the model to emit a sentiment score as a text string. While convenient, this ties continuous regression to discrete autoregressive decoding, incurring unmeasured costs. We revisit this readout mechanism and propose a discriminative formulation built on the Thinker module of a native omni-modal LLM (Qwen2.5-Omni-7B). Instead of text decoding, we map the final-layer hidden state of the last non-padding token to a continuous score via a lightweight regression head in a single forward pass. Using 4-bit quantization and low-rank adaptation (QLoRA), the entire 7B pipeline -- including video and audio processing -- trains on a single consumer GPU (RTX 5090, 32 GB) with 10-21 GB peak memory and 1.14% trainable parameters. Through a controlled comparison fixing the backbone, data, and LoRA configuration, we isolate the impact of the readout. On CMU-MOSI and CMU-MOSEI, our discriminative readout reaches state-of-the-art accuracy without task-specific feature engineering (MOSI: MAE 0.551, Corr 0.888; MOSEI: MAE 0.506, Corr 0.790) and exhibits strong multi-seed stability. In contrast, the generative readout -- even after equivalent supervised training -- more than doubles the mean absolute error, yields unparsable or out-of-range outputs (2.8% zero-shot), and suffers from higher latency. Modality ablations reveal a text-dominant regime on CMU-MOSI. Our findings indicate that how an LMM is read out is as consequential as how it is trained, demonstrating that a discriminative readout offers a more accurate, efficient, and reliable alternative for continuous MSA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that replacing generative text decoding with a discriminative readout—mapping the final-layer hidden state of the last non-padding token in Qwen2.5-Omni-7B through a lightweight regression head—yields state-of-the-art continuous sentiment scores on CMU-MOSI (MAE 0.551, Corr 0.888) and CMU-MOSEI (MAE 0.506, Corr 0.790). A controlled comparison (identical backbone, data, and QLoRA configuration) shows the generative baseline more than doubles MAE, produces unparsable outputs, and incurs higher latency, while the discriminative approach trains the full 7B pipeline on a single consumer GPU with 1.14% trainable parameters.
Significance. If the empirical gap holds under full verification, the work establishes that readout choice is load-bearing for regression accuracy in native omni-modal LLMs and supplies a practical, low-resource alternative to generative decoding. The explicit isolation of readout mechanism, multi-seed stability, and modality ablations constitute reproducible evidence that can be directly tested by other groups.
major comments (2)
- [Methods / Experimental Setup] Methods (data splits, preprocessing, and error bars): the abstract and controlled-comparison claim rest on specific numeric gaps, yet the visible text supplies neither the exact train/val/test partitions, any preprocessing steps beyond standard dataset usage, nor per-seed standard deviations; without these the reported SOTA margins cannot be independently reproduced or checked for post-hoc selection.
- [Abstract and Discriminative Readout section] Hidden-state readout claim (abstract and § on discriminative formulation): the assertion that the final-layer state “already encodes a representation sufficient for accurate continuous regression after only LoRA adaptation” is not directly tested; the performance advantage could arise from the regression head learning to extract affect features that remain entangled with next-token prediction signals, rather than from the state being regression-ready by itself. A simple probe (e.g., zero-shot linear regression on frozen hidden states or representation similarity to affect labels) would falsify or support this.
minor comments (2)
- [Results] The generative baseline reports 2.8% zero-shot unparsable outputs; the exact parsing rule and post-processing applied to both readouts should be stated explicitly so the comparison is fully reproducible.
- [Ablation studies] Modality-ablation table: clarify whether the text-dominant regime on MOSI is measured with the same regression head or with generative decoding, as this affects interpretation of the ablation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that enhance reproducibility and provide additional empirical support for our claims.
read point-by-point responses
-
Referee: [Methods / Experimental Setup] Methods (data splits, preprocessing, and error bars): the abstract and controlled-comparison claim rest on specific numeric gaps, yet the visible text supplies neither the exact train/val/test partitions, any preprocessing steps beyond standard dataset usage, nor per-seed standard deviations; without these the reported SOTA margins cannot be independently reproduced or checked for post-hoc selection.
Authors: We agree that explicit documentation is required for reproducibility. In the revised manuscript we will: (1) state the precise train/val/test partitions used for CMU-MOSI and CMU-MOSEI (standard splits with exact sample counts and any custom filtering), (2) detail all preprocessing steps for text, audio, and video modalities, and (3) report all metrics as mean ± standard deviation across five independent random seeds. These additions will allow independent verification and address concerns about post-hoc selection. revision: yes
-
Referee: [Abstract and Discriminative Readout section] Hidden-state readout claim (abstract and § on discriminative formulation): the assertion that the final-layer state “already encodes a representation sufficient for accurate continuous regression after only LoRA adaptation” is not directly tested; the performance advantage could arise from the regression head learning to extract affect features that remain entangled with next-token prediction signals, rather than from the state being regression-ready by itself. A simple probe (e.g., zero-shot linear regression on frozen hidden states or representation similarity to affect labels) would falsify or support this.
Authors: We appreciate this point. While our controlled comparison (identical backbone, data, and QLoRA) isolates the readout mechanism and shows a large gap favoring the discriminative head, it does not directly test whether the final hidden state is already regression-ready prior to head training. We will add the suggested zero-shot linear probe on frozen (no LoRA) hidden states, together with a representation-similarity analysis to affect labels, and report the results. If the probe performance is substantially lower, we will revise the claim wording to reflect that the advantage arises from the combination of LoRA-adapted states and the regression head. revision: yes
Circularity Check
No circularity; empirical comparison on external backbone
full rationale
The paper reports controlled empirical results comparing generative vs. discriminative readout on the fixed external Qwen2.5-Omni-7B backbone with QLoRA. No equations, derivations, or predictions are presented that reduce to fitted inputs by construction, and no self-citation chains or ansatzes are invoked as load-bearing premises. The performance claims rest on standard train/test splits and reported metrics rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- regression head weights
Reference graph
Works this paper leans on
-
[1]
Multimodal sentiment intensity analysis in videos: Facial gestures and verbal messages,
A. Zadeh, R. Zellers, E. Pincus, and L.-P. Morency, “Multimodal sentiment intensity analysis in videos: Facial gestures and verbal messages,”IEEE Intell. Syst., vol. 31, no. 6, pp. 82–88, 2016
2016
-
[2]
Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph,
A. Bagher Zadeh, P. P. Liang, S. Poria, E. Cambria, and L.-P. Morency, “Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph,” inProc. ACL, 2018, pp. 2236–2246
2018
-
[3]
A review of affective computing: From unimodal analysis to multimodal fusion,
S. Poria, E. Cambria, R. Bajpai, and A. Hussain, “A review of affective computing: From unimodal analysis to multimodal fusion,”Inf. Fusion, vol. 37, pp. 98–125, 2017
2017
-
[4]
Multimodal machine learning: A survey and taxonomy,
T. Baltrušaitis, C. Ahuja, and L.-P. Morency, “Multimodal machine learning: A survey and taxonomy,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 41, no. 2, pp. 423–443, 2019
2019
-
[5]
Tensor fusion network for multimodal sentiment analysis,
A. Zadeh, M. Chen, S. Poria, E. Cambria, and L.-P. Morency, “Tensor fusion network for multimodal sentiment analysis,” inProc. EMNLP, 2017, pp. 1103–1114
2017
-
[6]
Efficient low-rank multimodal fusion with modality-specific factors,
Z. Liu, Y. Shen, V. B. Lakshminarasimhan, P. P. Liang, A. Zadeh, and L.-P. Morency, “Efficient low-rank multimodal fusion with modality-specific factors,” inProc. ACL, 2018, pp. 2247–2256
2018
-
[7]
Memory fusion network for multi-view sequential learning,
A. Zadeh, P. P. Liang, N. Mazumder, S. Poria, E. Cambria, and L.-P. Morency, “Memory fusion network for multi-view sequential learning,” inProc. AAAI, 2018, pp. 5634–5641
2018
-
[8]
Multimodal transformer for unaligned multimodal language sequences,
Y.-H. H. Tsai, S. Bai, P. P. Liang, J. Z. Kolter, L.-P. Morency, and R. Salakhutdinov, “Multimodal transformer for unaligned multimodal language sequences,” inProc. ACL, 2019, pp. 6558–6569
2019
-
[9]
MISA: Modality-invariant and -specific represen- tations for multimodal sentiment analysis,
D. Hazarika, R. Zimmermann, and S. Poria, “MISA: Modality-invariant and -specific represen- tations for multimodal sentiment analysis,” inProc. ACM MM, 2020, pp. 1122–1131
2020
-
[10]
BERT: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” inProc. NAACL-HLT, 2019, pp. 4171–4186
2019
-
[11]
Integrating multimodal information in large pretrained transformers,
W.Rahman, M.K.Hasan, S.Lee, A.Zadeh, C.Mao, L.-P.Morency, andE.Hoque, “Integrating multimodal information in large pretrained transformers,” inProc. ACL, 2020, pp. 2359–2369. 16
2020
-
[12]
Learning modality-specific representations with self- supervised multi-task learning for multimodal sentiment analysis,
W. Yu, H. Xu, Z. Yuan, and J. Wu, “Learning modality-specific representations with self- supervised multi-task learning for multimodal sentiment analysis,” inProc. AAAI, vol. 35, no. 12, 2021, pp. 10790–10797
2021
-
[13]
Improving multimodal fusion with hierarchical mutual infor- mation maximization for multimodal sentiment analysis,
W. Han, H. Chen, and S. Poria, “Improving multimodal fusion with hierarchical mutual infor- mation maximization for multimodal sentiment analysis,” inProc. EMNLP, 2021, pp. 9180– 9192
2021
-
[14]
UniMSE: Towards unified multimodal sentiment analysis and emotion recognition,
G. Hu, T.-E. Lin, Y. Zhao, G. Lu, Y. Wu, and Y. Li, “UniMSE: Towards unified multimodal sentiment analysis and emotion recognition,” inProc. EMNLP, 2022, pp. 7837–7851
2022
-
[15]
Self-adaptive context and modal-interaction modeling for multimodal sentiment analysis,
H. Yang, X. Gao, J. Wu, T. Gan, N. Ding, F. Jiang, and L. Nie, “Self-adaptive context and modal-interaction modeling for multimodal sentiment analysis,” inFindings of ACL, 2022
2022
-
[16]
ConFEDE: Contrastive feature decomposition for multimodal sentiment analysis,
J. Yang, Y. Yu, D. Niu, W. Guo, and Y. Xu, “ConFEDE: Contrastive feature decomposition for multimodal sentiment analysis,” inProc. ACL, 2023, pp. 7617–7630
2023
-
[17]
Decoupled multimodal distilling for emotion recognition,
Y. Li, Y. Wang, and Z. Cui, “Decoupled multimodal distilling for emotion recognition,” inProc. IEEE/CVF CVPR, 2023, pp. 6631–6640
2023
-
[18]
Learning language-guided adaptive hyper-modality representation for multimodal sentiment analysis,
Y. Zhang, M. Chen, J. Shen, and C. Wang, “Learning language-guided adaptive hyper-modality representation for multimodal sentiment analysis,” inProc. EMNLP, 2023, pp. 756–767
2023
-
[19]
TETFN: A text enhanced transformer fusion network for multimodal sentiment analysis,
D. Wang, X. Guo, Y. Tian, J. Liu, L. He, and X. Luo, “TETFN: A text enhanced transformer fusion network for multimodal sentiment analysis,”Pattern Recognit., vol. 136, p. 109259, 2023
2023
-
[20]
M-SENA: An integrated platform for multimodal sentiment analysis,
H. Mao, Z. Yuan, H. Xu, W. Yu, Y. Liu, and K. Gao, “M-SENA: An integrated platform for multimodal sentiment analysis,” inProc. ACL Syst. Demonstrations, 2022, pp. 204–213
2022
-
[21]
DeepFilterNet: A low com- plexity speech enhancement framework for full-band audio based on deep filtering,
H. Schröter, A. N. Escalante-B., T. Rosenkranz, and A. Maier, “DeepFilterNet: A low com- plexity speech enhancement framework for full-band audio based on deep filtering,” inProc. IEEE ICASSP, 2022, pp. 7407–7411
2022
-
[22]
MSAmba: Exploring multimodal sentiment analysis with state space models,
X. He, H. Liang, B. Peng, W. Xie, M. H. Khan, S. Song, and Z. Yu, “MSAmba: Exploring multimodal sentiment analysis with state space models,” inProc. AAAI, 2025, pp. 1309–1317
2025
-
[23]
Modality-enhanced multimodal integrated fusion attention model for sentiment anal- ysis (MEMMI),
G. Feng, “Modality-enhanced multimodal integrated fusion attention model for sentiment anal- ysis (MEMMI),”Appl. Sci., vol. 15, no. 19, p. 10825, 2025
2025
-
[24]
DecAlign: Hierarchical cross-modal alignment for multimodal sentiment analysis,
C. Qian, S. Xing, S. Li, Y. Zhao, and Z. Tu, “DecAlign: Hierarchical cross-modal alignment for multimodal sentiment analysis,” inProc. ICLR, 2026
2026
-
[25]
Multimodal multi-loss fusion network for sentiment analysis,
Z. Wu, Z. Gong, J. Koo, and J. Hirschberg, “Multimodal multi-loss fusion network for sentiment analysis,” inProc. NAACL, 2024, pp. 3588–3602
2024
-
[26]
Large language models meet text-centric multi- modal sentiment analysis: A survey,
J. Yang, Y. Yu, D. Niu, W. Guo, and Y. Xu, “Large language models meet text-centric multi- modal sentiment analysis: A survey,”Sci. China Inf. Sci., 2025, doi:10.1007/s11432-024-4593-8
-
[27]
J. Achiam et al., “GPT-4 technical report,” arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[28]
Qwen2.5-Omni technical report,
J. Xu et al. (Qwen Team), “Qwen2.5-Omni technical report,” arXiv:2503.20215, 2025
Pith/arXiv arXiv 2025
-
[29]
J. Qiao et al., “A unified framework for emotion recognition and sentiment analysis via expert- guided multimodal fusion with large language models,” arXiv:2601.07565, 2026. 17
arXiv 2026
-
[30]
Multimodal large language model with LoRA fine-tuning for multimodal sentiment analysis,
J. Mu, W. Wang, W. Liu, T. Yan, et al., “Multimodal large language model with LoRA fine-tuning for multimodal sentiment analysis,”ACM Trans. Intell. Syst. Technol., 2025, doi:10.1145/3709147
-
[31]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” inProc. ICLR, 2022
2022
-
[32]
QLoRA: Efficient finetuning of quantized LLMs,
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “QLoRA: Efficient finetuning of quantized LLMs,” inProc. NeurIPS, 2023
2023
-
[33]
Visualizing data using t-SNE,
L. van der Maaten and G. Hinton, “Visualizing data using t-SNE,”J. Mach. Learn. Res., vol. 9, pp. 2579–2605, 2008
2008
-
[34]
Affective computing in the era of large language models: A survey from the NLP perspective,
Y. Wang, Y. Li, P. Liang, et al., “Affective computing in the era of large language models: A survey from the NLP perspective,”arXiv:2408.04638, 2024
arXiv 2024
-
[35]
EmoLLMs: A series of emotional large language models and annotation tools for comprehensive affective analysis,
Z. Liu, K. Yang, Q. Xie, T. Zhang, and S. Ananiadou, “EmoLLMs: A series of emotional large language models and annotation tools for comprehensive affective analysis,” inProc. ACM SIGKDD, 2024, pp. 5487–5496
2024
-
[36]
Emotion-LLaMA: Multimodal emotion recognition and reasoning with instruction tuning,
Z. Cheng, Z.-Q. Cheng, J.-Y. He, K. Wang, Y. Lin, Z. Lian, X. Peng, and A. Hauptmann, “Emotion-LLaMA: Multimodal emotion recognition and reasoning with instruction tuning,” in Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 37, 2024, pp. 110805–110853
2024
-
[37]
Probing hidden states for calibrated, alignment-resistant predictions in large language models,
J. Berkowitz, S. Kivelson, A. Srinivasan, U. Gisladottir, K. K. Tsang, J. M. Acitores Cortina, A. Kuchi, J. Patock, R. Czarny, and N. P. Tatonetti, “Probing hidden states for calibrated, alignment-resistant predictions in large language models,”arXiv preprint, 2025
2025
-
[38]
Large language models encode semantics and alignment in linearly separable representations,
B. Saglam, P. Kassianik, B. Nelson, S. Weerawardhena, Y. Singer, and A. Karbasi, “Large language models encode semantics and alignment in linearly separable representations,” arXiv:2507.09709, 2025
arXiv 2025
-
[39]
Fine-tuning causal LLMs for text classification: Embedding-based vs. instruction-based approaches,
A. Yousefiramandi and C. Cooney, “Fine-tuning causal LLMs for text classification: Embedding-based vs. instruction-based approaches,”arXiv:2512.12677, 2025. 18
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.