Amortized Nonlinear Model Predictive Control
Pith reviewed 2026-06-28 00:12 UTC · model grok-4.3
The pith
For input-affine nonlinear systems the optimal first control move of nonlinear MPC can be approximated by solving a state-dependent quadratic program whose cost parameters are output by a neural network.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
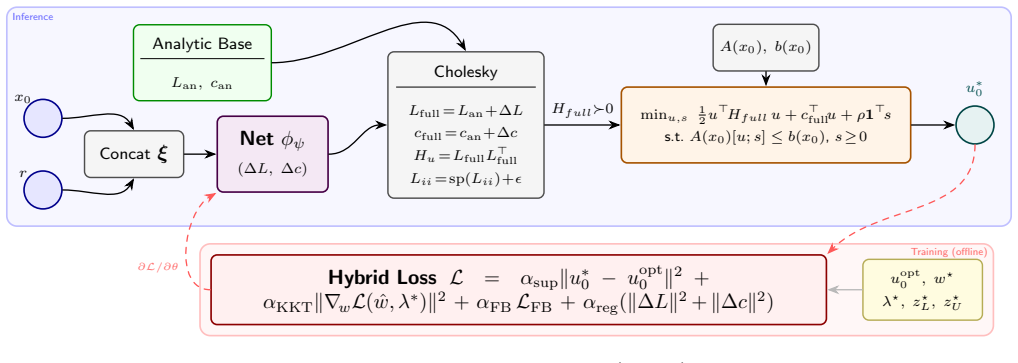
For the broad class of input-affine nonlinear systems the optimal control move obtained from a constrained nonlinear program can be closely approximated by a state-dependent quadratic program whose cost parameters depend on the current state and reference; these parameters are generated by a single-network residual-corrector architecture that starts from an analytic baseline and learns only the corrections needed to match the NLP solution, trained with a hybrid supervised and KKT-residual loss and solved via a differentiable interior-point layer.
What carries the argument
The single-network residual-corrector architecture that supplies state-dependent cost parameters to a quadratic program solved by a differentiable interior-point layer.
If this is right
- The first control action is guaranteed to satisfy the original constraints because the quadratic program is solved exactly.
- Computation time drops by orders of magnitude relative to repeated nonlinear-program solves.
- Comparable Cartesian end-effector tracking performance is obtained on the three-link robotic arm example.
- The approximation applies to any input-affine nonlinear system for which an NLP solver can generate training data.
Where Pith is reading between the lines
- The same residual-corrector idea could be tried on systems that are not strictly input-affine by first embedding them in a larger input-affine representation.
- If plant parameters drift, the network would require periodic retraining on new NLP data rather than online adaptation.
- The differentiable QP layer already present could be used to propagate gradients through longer horizons or to co-optimize other controller parameters.
Load-bearing premise
A neural network trained offline on NLP solutions can learn corrections to an analytic baseline such that the first move of the resulting quadratic program matches the nonlinear program solution closely enough for the intended applications.
What would settle it
On the three-link planar robotic arm, the end-effector tracking error or constraint violation rate produced by the learned quadratic program exceeds that of the full nonlinear program by more than a small margin.
Figures
read the original abstract
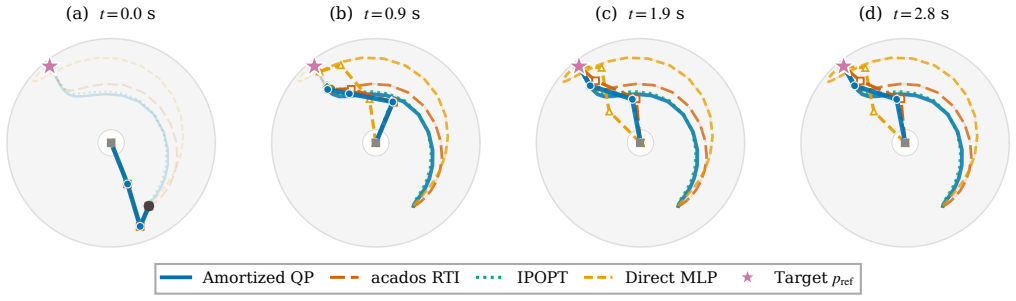
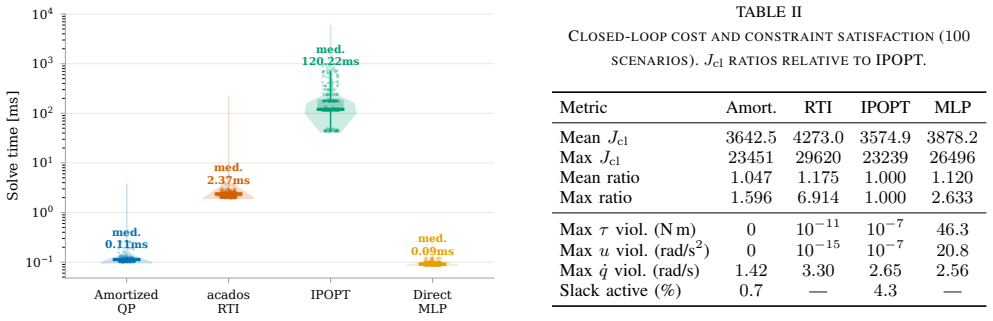
Nonlinear Model Predictive Control requires solving a constrained nonlinear program (NLP) in real-time at every sampling instant, a computational bottleneck that limits deployment on resource-constrained hardware or at high sampling rates. We address this challenge for the broad class of input-affine nonlinear systems to show that the optimal control move can be approximated by a state-dependent quadratic program (QP) whose cost parameters depend on the current state and reference. We propose a single-network residual-corrector architecture: a state-dependent analytic baseline provides initial QP parameters, and the network learns only the corrections needed to match the full NLP solution; the QP is solved by a differentiable interior-point layer, guaranteeing constraint satisfaction for the first control action. The network is trained offline on data generated by an NLP solver using a hybrid loss that combines supervised imitation and KKT-residual penalties. We validate the approach on a three-link planar robotic arm with Cartesian end-effector tracking, demonstrating orders-of-magnitude speedup over the NLP solver while maintaining comparable tracking performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that for the broad class of input-affine nonlinear systems, the first optimal control action from an NMPC problem can be recovered by solving a state-dependent QP whose cost parameters are produced by a single residual-corrector neural network (analytic baseline plus learned corrections). The network is trained offline on NLP-generated data using a hybrid supervised imitation plus KKT-residual loss; the QP is solved via a differentiable interior-point layer to enforce feasibility. Validation on a three-link planar arm Cartesian-tracking task is reported to yield orders-of-magnitude speedup over direct NLP solution while preserving comparable tracking performance.
Significance. If the residual-corrector architecture generalizes, the method would offer a practical route to real-time NMPC on embedded hardware by amortizing the nonlinear solve into a fast QP whose parameters are state-dependent. The combination of an analytic baseline, differentiable optimization layer for constraint satisfaction, and hybrid loss is a constructive strength that could be reused in other control settings.
major comments (2)
- [Abstract] Abstract and validation results: the central claim that the approach works for the 'broad class of input-affine nonlinear systems' is load-bearing yet supported only by a single 3-link planar arm Cartesian-tracking example. No additional plants (underactuated, non-minimum-phase, or higher-dimensional input-affine systems) are tested, so there is no evidence that the learned correction map remains effective when the underlying NLP KKT conditions change structure.
- [Abstract] Abstract: the statements of 'orders-of-magnitude speedup' and 'comparable tracking performance' are presented without any quantitative metrics, error tables, or timing comparisons in the provided description, leaving the empirical support for the QP approximation unquantified.
minor comments (1)
- The description of the differentiable interior-point layer would benefit from an explicit citation or one-sentence recap of its constraint-handling properties to improve self-contained readability.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment point-by-point below, with planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract and validation results: the central claim that the approach works for the 'broad class of input-affine nonlinear systems' is load-bearing yet supported only by a single 3-link planar arm Cartesian-tracking example. No additional plants (underactuated, non-minimum-phase, or higher-dimensional input-affine systems) are tested, so there is no evidence that the learned correction map remains effective when the underlying NLP KKT conditions change structure.
Authors: The residual-corrector architecture and hybrid loss are derived directly from the KKT stationarity conditions that arise for any input-affine nonlinear system; the QP structure follows from the affine dependence of the dynamics on the control. The three-link arm is a standard, fully coupled nonlinear benchmark within this class. We agree that additional plants would provide stronger empirical support. We will therefore revise the abstract to qualify the claim as applying to input-affine systems and add a dedicated paragraph in the discussion section on structural assumptions and potential limitations for other system classes. revision: partial
-
Referee: [Abstract] Abstract: the statements of 'orders-of-magnitude speedup' and 'comparable tracking performance' are presented without any quantitative metrics, error tables, or timing comparisons in the provided description, leaving the empirical support for the QP approximation unquantified.
Authors: The abstract is a high-level summary; the full manuscript reports concrete timing benchmarks (NLP vs. QP solve times) and tracking-error tables in the experimental evaluation. To make the abstract self-contained, we will insert specific quantitative statements such as 'achieving >100x speedup with Cartesian tracking error within 2% of the NLP baseline'. revision: yes
Circularity Check
No circularity: approximation learned from external NLP data via standard hybrid loss
full rationale
The paper's central claim is an empirical approximation of NLP solutions for input-affine systems via a residual-corrector network trained offline on solver-generated data. The analytic baseline plus learned corrections, differentiable IP layer for QP solving, and hybrid supervised+KKT loss are standard architectural and training choices that do not reduce the output to the inputs by definition or self-citation. No load-bearing step equates a 'prediction' to a fitted parameter or renames a known result. The single 3-link arm validation is an empirical demonstration, not a derivation that collapses into its own assumptions.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network weights
axioms (2)
- domain assumption Systems are input-affine nonlinear
- domain assumption Differentiable interior-point layer guarantees first-action constraint satisfaction
invented entities (1)
-
residual-corrector network
no independent evidence
Reference graph
Works this paper leans on
-
[1]
J. B. Rawlings, D. Q. Mayne, and M. Diehl,Model Predictive Control: Theory, Computation, and Design, 2nd ed. Nob Hill Publishing, 2017
2017
-
[2]
qpoases: A parametric active-set algorithm for quadratic program- ming,
H. J. Ferreau, C. Kirches, A. Potschka, H. G. Bock, and M. Diehl, “qpoases: A parametric active-set algorithm for quadratic program- ming,”Mathematical Programming Computation, vol. 6, no. 4, pp. 327–363, 2014. TABLE II CLOSED-LOOP COST AND CONSTRAINT SATISFACTION(100 SCENARIOS).J cl RATIOS RELATIVE TOIPOPT. Metric Amort. RTI IPOPT MLP MeanJ cl 3642.5 427...
2014
-
[3]
ODYS QP Solver,
G. Cimini, A. Bemporad, and D. Bernardini, “ODYS QP Solver,” ODYS S.r.l. (https://odys.it/qp), Sep. 2017
2017
-
[4]
Hpipm: a high-performance quadratic programming framework for model predictive control,
G. Frison and M. Diehl, “Hpipm: a high-performance quadratic programming framework for model predictive control,”IFAC- PapersOnLine, vol. 53, no. 2, pp. 6563–6569, 2020
2020
-
[5]
The ex- plicit linear quadratic regulator for constrained systems,
A. Bemporad, M. Morari, V . Dua, and E. N. Pistikopoulos, “The ex- plicit linear quadratic regulator for constrained systems,”Automatica, vol. 38, no. 1, pp. 3–20, 2002
2002
-
[6]
A real-time iteration scheme for nonlinear optimization in optimal feedback control,
M. Diehl, H. G. Bock, and J. P. Schl ¨oder, “A real-time iteration scheme for nonlinear optimization in optimal feedback control,”SIAM Journal on Control and Optimization, vol. 43, no. 5, pp. 1714–1736, 2005
2005
-
[7]
From linear to nonlinear MPC: Bridging the gap via the real-time iteration,
S. Gros, M. Zanon, R. Quirynen, A. Bemporad, and M. Diehl, “From linear to nonlinear MPC: Bridging the gap via the real-time iteration,” International Journal of Control, vol. 93, no. 1, pp. 62–80, 2020
2020
-
[8]
Tutorial on amortized optimization,
B. Amos, “Tutorial on amortized optimization,”Foundations and Trends in Machine Learning, vol. 16, no. 5, pp. 592–732, 2023
2023
-
[9]
Learning Lyapunov terminal costs from data for complexity reduction in nonlinear model predictive control,
S. Abdufattokhov, M. Zanon, and A. Bemporad, “Learning Lyapunov terminal costs from data for complexity reduction in nonlinear model predictive control,”Int. Journal of Robust and Nonlinear Control, vol. 34, no. 13, pp. 8676–8691, 2024
2024
-
[10]
Learning Parametric Convex Functions,
M. Schaller, A. Bemporad, and S. Boyd, “Learning Parametric Convex Functions,” 2025, http://arxiv.org/abs/2506.04183
-
[11]
A predictive safety filter for learning-based control of constrained nonlinear dynamical systems,
K. P. Wabersich and M. N. Zeilinger, “A predictive safety filter for learning-based control of constrained nonlinear dynamical systems,” Automatica, vol. 129, p. 109597, 2021
2021
-
[12]
Learning to warm-start fixed-point optimization algorithms,
R. Sambharya, G. Hall, B. Amos, and B. Stellato, “Learning to warm-start fixed-point optimization algorithms,”J. Mach. Learn. Res., vol. 25, no. 1, Jan. 2024
2024
-
[13]
OptNet: Differentiable optimization as a layer in neural networks,
B. Amos and J. Z. Kolter, “OptNet: Differentiable optimization as a layer in neural networks,” inProc. International Conference on Machine Learning (ICML), 2017, pp. 136–145
2017
-
[14]
On the implementation of an interior- point filter line-search algorithm for large-scale nonlinear program- ming,
A. W ¨achter and L. T. Biegler, “On the implementation of an interior- point filter line-search algorithm for large-scale nonlinear program- ming,”Mathematical programming, vol. 106, no. 1, pp. 25–57, 2006
2006
-
[15]
A special Newton-type optimization method,
A. Fischer, “A special Newton-type optimization method,”Optimiza- tion, vol. 24, no. 3–4, pp. 269–284, 1992
1992
-
[16]
Self-supervised learning of iterative solvers for constrained optimization,
L. L ¨uken and S. Lucia, “Self-supervised learning of iterative solvers for constrained optimization,” 2025. [Online]. Available: https://arxiv.org/abs/2409.08066
-
[17]
On the differentiability of the primal- dual interior-point method,
K. Tracy and Z. Manchester, “On the differentiability of the primal- dual interior-point method,” 2024
2024
-
[18]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimiza- tion,”arXiv preprint 1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[19]
JAX: composable transformations of Python+NumPy programs,
J. Bradbury, R. Frostig, P. Hawkins, M. J. Johnson, C. Leary, D. Maclaurin, G. Necula, A. Paszke, J. VanderPlas, S. Wanderman- Milne, and Q. Zhang, “JAX: composable transformations of Python+NumPy programs,” 2018. [Online]. Available: http://github. com/jax-ml/jax
2018
-
[20]
acados – a modular open-source framework for fast embedded optimal control,
R. Verschueren, G. Frison, D. Kouzoupis, J. Frey, N. v. Duijkeren, A. Zanelli, B. Novoselnik, T. Albin, R. Quirynen, and M. Diehl, “acados – a modular open-source framework for fast embedded optimal control,”Mathematical Programming Computation, vol. 14, no. 1, pp. 147–183, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.