Beyond Greedy Chunking: SLO-Aware Sliding-Window Scheduling for LLM Inference
Pith reviewed 2026-06-27 23:47 UTC · model grok-4.3
The pith
SlidingServe raises LLM inference service capacity by up to 30 percent while cutting SLO violations 16 to 53 percent under heavy load.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
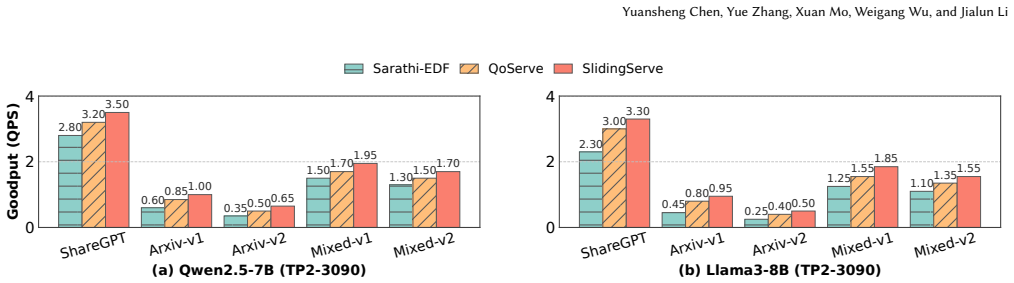
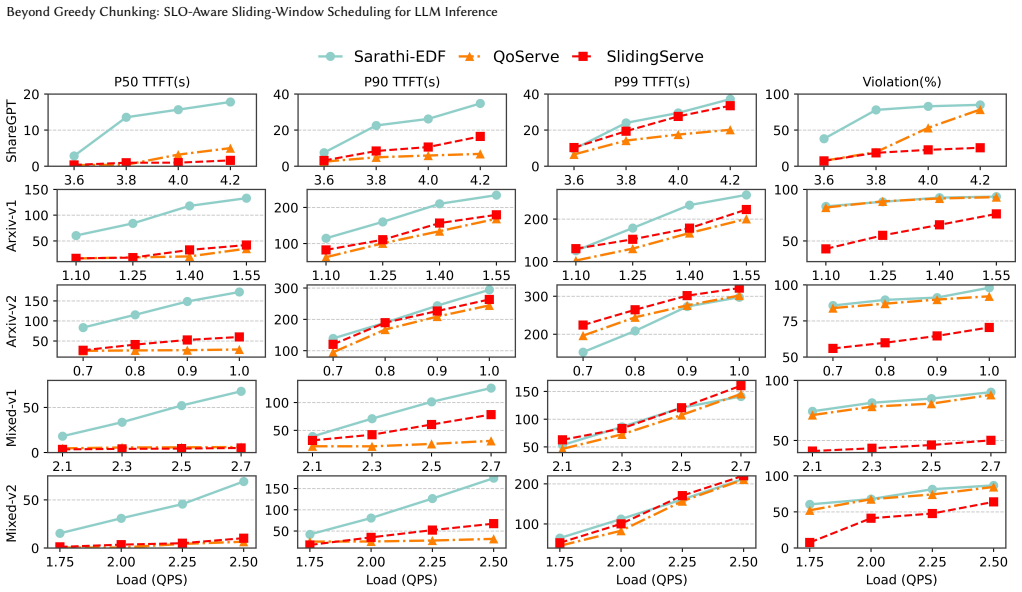
SlidingServe improves service capacity by up to 30% compared to advanced scheduling systems under various load conditions, and further reduces the rate of SLO violation by 16%-53% under heavy-load inference mode, by combining a lightweight batch latency predictor with SlidingChunker for dynamic chunking, Multi-Level Priority Sorter for request ordering, and BatchConstructor for dynamic-programming selection of safe request sets.
What carries the argument
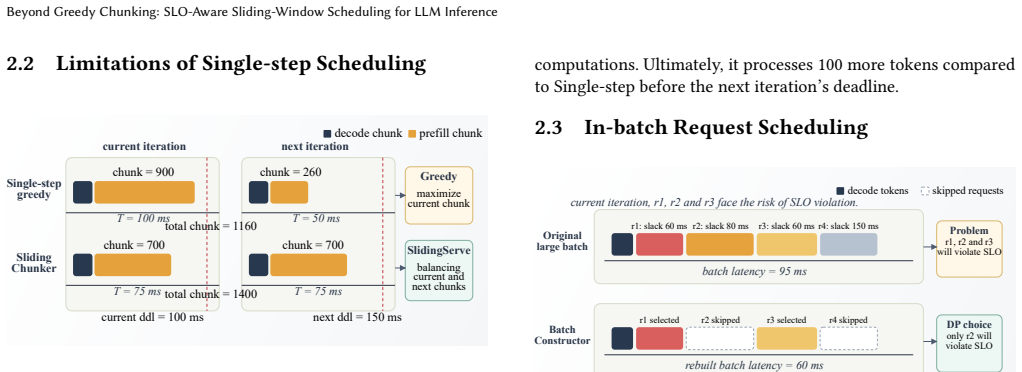
SlidingChunker, which merges information from the current and next iteration to perform dynamic chunking guided by the batch latency predictor.
If this is right
- Dynamic chunking that looks one iteration ahead raises overall throughput while preserving per-request latency bounds.
- Multi-level priority ordering can balance fairness and efficiency without separate fairness mechanisms.
- Dynamic programming selection of requests inside a batch reduces SLO violations for the highest-priority requests when contention is high.
- The system maintains strict QoS differentiation across requests even when resource contention is severe.
- Service capacity scales with load without proportional growth in violation rates.
Where Pith is reading between the lines
- The same predictor-plus-sliding-window pattern could be tested on non-LLM workloads that also require strict per-request latency targets.
- Replacing the current predictor with a more accurate but still lightweight model would be a direct next experiment to quantify how much of the gain depends on prediction quality.
- Evaluating the approach on models larger than those used in the paper would test whether the chunking and selection overheads remain acceptable.
Load-bearing premise
The lightweight batch latency predictor supplies accurate enough estimates of batch execution times for dynamic chunking and priority decisions to succeed without large scheduling errors.
What would settle it
Measure the difference between predicted and actual batch execution times on a production LLM workload and check whether prediction errors above a few percent cause the claimed capacity gains or SLO reductions to disappear.
Figures

read the original abstract
With the rapid growth of interactive applications in large language model (LLM) online services, maintaining high system throughput while ensuring user-perceived latency has become a key issue in inference scheduling. Existing LLM service systems rely on coarse-grained output constraints, making it difficult to effectively handle resource contention among multiple requests, resulting in low resource utilization efficiency and limited support for fine-grained quality of service (QoS) differentiation. We present SlidingServe, a sliding-window-driven SLO-Aware scheduling system for online LLM inference. SlidingServe designed a lightweight batch latency predictor to estimate the execution time of a batch. Based on this, SlidingServe uses SlidingChunker to combine information from the current iteration and the next iteration to achieve dynamic chunking and improve the overall system throughput while maintaining strict QoS guarantees. SlidingServe introduces Multi-Level Priority Sorter to sort candidate requests in order to balance fairness and efficiency. Additionally, when multiple requests within the same batch are at risk of SLO violating,SlidingServe introduces BatchConstructor, which uses dynamic programming to select the set of requests to execute in the current round, mitigating the SLO violation risk of critical requests.Our evaluation demonstrates that SlidingServe can improve service capacity by up to 30% compared to advanced scheduling systems under various load conditions, and further reduces the rate of SLO violation by 16%-53% under heavy-load inference mode.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SlidingServe, a sliding-window-driven SLO-aware scheduler for online LLM inference. It introduces a lightweight batch latency predictor to estimate batch execution times, SlidingChunker for dynamic chunking that incorporates current and next-iteration information, a Multi-Level Priority Sorter to balance fairness and efficiency, and BatchConstructor (a DP-based selector) to mitigate SLO violations when multiple requests are at risk. The evaluation claims up to 30% higher service capacity versus advanced baselines under varied loads and 16-53% lower SLO violation rates under heavy load.
Significance. If the predictor accuracy and experimental results hold, the work could improve fine-grained QoS differentiation and resource utilization in multi-tenant LLM serving, moving beyond coarse output constraints.
major comments (2)
- [Abstract] Abstract: the quantitative claims (30% capacity gain, 16-53% SLO reduction) are presented without any description of experimental setup, workload traces, baselines, number of runs, or statistical significance, making it impossible to evaluate whether the reported improvements are load-bearing or reproducible.
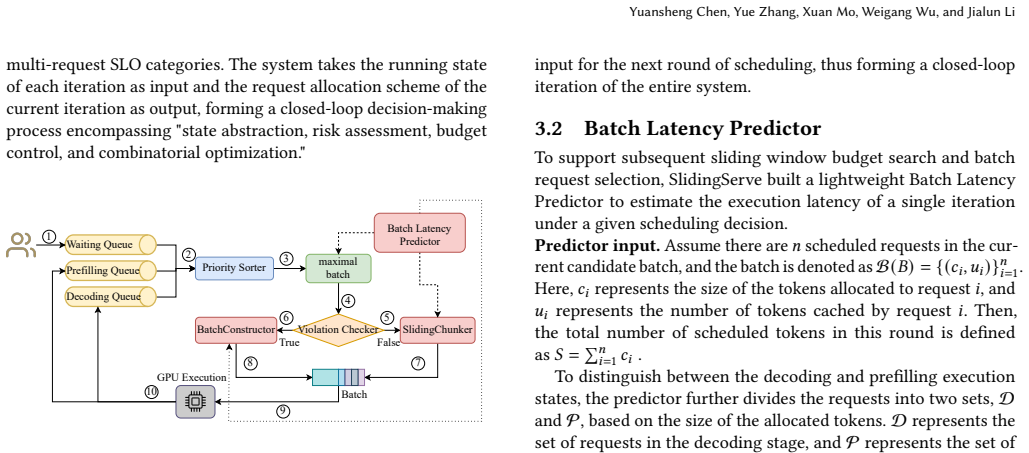
- [System Design (lightweight batch latency predictor)] Batch latency predictor description (system overview): all downstream components (SlidingChunker dynamic boundaries, priority ordering, and BatchConstructor DP selection) depend on accurate execution-time estimates, yet the manuscript supplies no training data/procedure, no accuracy metrics (MAPE, max error, or per-batch error distribution), and no sensitivity analysis. If prediction error exceeds a few percent, the claimed gains become unreliable.
minor comments (1)
- [BatchConstructor] Notation for the DP objective and constraints in BatchConstructor should be defined explicitly with symbols before use.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments correctly identify gaps in the current manuscript. We will revise the abstract and add a dedicated subsection on the batch latency predictor (including training details, accuracy metrics, and sensitivity analysis) to make the quantitative claims and system design fully evaluable.
read point-by-point responses
-
Referee: [Abstract] Abstract: the quantitative claims (30% capacity gain, 16-53% SLO reduction) are presented without any description of experimental setup, workload traces, baselines, number of runs, or statistical significance, making it impossible to evaluate whether the reported improvements are load-bearing or reproducible.
Authors: We agree that the abstract as written does not provide sufficient context for the reported gains. In the revised version we will expand the abstract (within length limits) to briefly state the workload traces, primary baselines, evaluation methodology (including number of runs), and note that improvements are reported as averages with observed ranges across load conditions. Full experimental details remain in Section 5. revision: yes
-
Referee: [System Design (lightweight batch latency predictor)] Batch latency predictor description (system overview): all downstream components (SlidingChunker dynamic boundaries, priority ordering, and BatchConstructor DP selection) depend on accurate execution-time estimates, yet the manuscript supplies no training data/procedure, no accuracy metrics (MAPE, max error, or per-batch error distribution), and no sensitivity analysis. If prediction error exceeds a few percent, the claimed gains become unreliable.
Authors: The observation is accurate: the current manuscript does not include training data, procedure, accuracy metrics, or sensitivity analysis for the predictor. We will add a new subsection (likely 3.2) that describes the training dataset and procedure, reports MAPE and per-batch error distributions on held-out batches, and presents a sensitivity study showing how SLO violation rates and throughput change under injected prediction errors of 5-20%. This will directly address the reliability concern for the downstream components. revision: yes
Circularity Check
No circularity: claims rest on empirical evaluation of an independently described scheduler
full rationale
The paper presents SlidingServe as a system design (SlidingChunker, Multi-Level Priority Sorter, BatchConstructor DP, and a lightweight batch latency predictor) whose performance claims are obtained from direct evaluation under load conditions. No equations, fitted parameters, or self-citations are shown to define the reported capacity gains or SLO-violation reductions; the abstract and description treat these as measured outcomes rather than quantities derived by construction from the inputs. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2020.Towards a human-like open-domain chatbot
Daniel Adiwardana, Minh-Thang Luong, David R So, Jamie Hall, Noah Fiedel, Romal Thoppilan, Zi Yang, Apoorv Kulshreshtha, Gaurav Nemade, Yifeng Lu, et al. 2020.Towards a human-like open-domain chatbot. arXiv:2001.09977
-
[2]
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. Taming {Throughput-Latency} tradeoff in {LLM} inference with {Sarathi-Serve}. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). pages 117–134,2024
2024
-
[3]
SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills
Amey Agrawal, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S Gulavani, and Ramachandran Ramjee. 2023.Sarathi: Efficient llm inference by piggybacking decodes with chunked prefills. arXiv:2308.16369
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Yu Ding, Jingxuan Zhao, Zhengong Cai, Kai Shi, Fansong Zeng, and Boweiy Yang. 2025. Adaptoserve: An Efficient System for Supporting Adaptive Chunked- Prefills in LLM Inference. In2025 IEEE International Conference on High Perfor- mance Computing and Communications (HPCC). 1–9
2025
-
[5]
Jiangsu Du, Hongbin Zhang, Taosheng Wei, Zhenyi Zheng, Kaiyi Wu, Zhiguang Chen, and Yutong Lu. 2025.Ecoserve: Enabling cost-effective llm serving with proactive intra-and inter-instance orchestration. arXiv:2504.18154
-
[6]
Jingqi Feng, Yukai Huang, Rui Zhang, Sicheng Liang, Ming Yan, and Jie Wu
-
[7]
InProceedings of the 52nd Annual International Symposium on Computer Architecture
Windserve: Efficient phase-disaggregated llm serving with stream-based dynamic scheduling. InProceedings of the 52nd Annual International Symposium on Computer Architecture. 1283–1295
-
[8]
Shihong Gao, Xin Zhang, Yanyan Shen, and Lei Chen. 2025. Apt-serve: Adaptive request scheduling on hybrid cache for scalable llm inference serving.Proceedings of the ACM on Management of Data3, 3 (2025), 1–28
2025
-
[9]
Kanishk Goel, Jayashree Mohan, Nipun Kwatra, Ravi Shreyas Anupindi, and Ramachandran Ramjee. 2026. QoServe: Breaking the Silos of LLM Inference Serving. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 1492–1507
2026
-
[10]
2024.Deepspeed-fastgen: High-throughput text generation for llms via mii and deepspeed-inference
Connor Holmes, Masahiro Tanaka, Michael Wyatt, Ammar Ahmad Awan, Jeff Rasley, Samyam Rajbhandari, Reza Yazdani Aminabadi, Heyang Qin, Arash Bakhtiari, Lev Kurilenko, et al. 2024.Deepspeed-fastgen: High-throughput text generation for llms via mii and deepspeed-inference. arXiv:2401.08671
-
[11]
Ke Hong, Xiuhong Li, Lufang Chen, Qiuli Mao, Guohao Dai, Xuefei Ning, Shengen Yan, Yun Liang, and Yu Wang. 2025. Sola: Optimizing slo attainment for large language model serving with state-aware scheduling.Proceedings of Machine Learning and Systems7 (2025)
2025
-
[12]
HuggingFace. 2025. arxiv_summarization_postprocess. https://huggingface.co/ datasets/whu9/arxiv_summarization_postprocess
2025
-
[13]
HuggingFace. 2025. ShareGPT_Vicuna_unfiltered. https://huggingface.co/ datasets/anon8231489123/ShareGPT_Vicuna_unfiltered
2025
-
[14]
Shashwat Jaiswal, Kunal Jain, Yogesh Simmhan, Anjaly Parayil, Ankur Mallick, Rujia Wang, Renee St Amant, Chetan Bansal, Victor Ruhle, Anoop Kulkarni, et al
-
[15]
SageServe: Optimizing LLM Serving on Cloud Data Centers with Forecast Aware Auto-Scaling.Proceedings of the ACM on Measurement and Analysis of Computing Systems9, 3 (2025), 1–24
2025
-
[16]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2026. A survey on large language models for code generation.ACM Transactions on Software Engineering and Methodology35, 2 (2026), 1–72
2026
-
[17]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the ACM Symposium on Operating Systems Principles(SOSP). pages 611–626,2023
2023
-
[18]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). 118–132
2024
-
[19]
Uwe Peters and Benjamin Chin-Yee. 2025. Generalization bias in large language model summarization of scientific research.Royal Society Open Science12, 4 (2025), pages 241776
2025
-
[20]
Saurabh Pujar, Luca Buratti, Xiaojie Guo, Nicolas Dupuis, Burn Lewis, Sahil Suneja, Atin Sood, Ganesh Nalawade, Matt Jones, Alessandro Morari, et al. 2023. Automated code generation for information technology tasks in yaml through large language models. InProceedings of the 60th ACM/IEEE Design Automation Conference (DAC). pages 1–4,2023
2023
-
[21]
2024.ConServe: Fine-Grained GPU Harvesting for LLM Online and Offline Co-Serving
Yifan Qiao, Shu Anzai, Shan Yu, Haoran Ma, Shuo Yang, Yang Wang, Miryung Kim, Yongji Wu, Yang Zhou, Jiarong Xing, et al. 2024.ConServe: Fine-Grained GPU Harvesting for LLM Online and Offline Co-Serving. arXiv:2410.01228
-
[22]
Partha Pratim Ray. 2023. ChatGPT: A comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope.Internet of Things and Cyber-Physical Systems3 (2023), pages 121–154
2023
-
[23]
2020.Recipes for building an open-domain chatbot
Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M Smith, et al. 2020.Recipes for building an open-domain chatbot. arXiv:2004.13637 Beyond Greedy Chunking: SLO-Aware Sliding-Window Scheduling for LLM Inference
-
[24]
2025.Hygen: Efficient llm serving via elastic online-offline request co-location
Ting Sun, Penghan Wang, and Fan Lai. 2025.Hygen: Efficient llm serving via elastic online-offline request co-location. arXiv:2501.14808
-
[25]
Vaidya, F
N. Vaidya, F. Oh, and N. Comly. 2023. Optimizing inference on large language models with NVIDIA TensorRT-LLM, now publicly available. https://github. com/NVIDIA/TensorRT-LLM
2023
-
[26]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. Orca: A distributed serving system for transformer-based generative models. InProceedings of the USENIX Symposium on Operating Systems Design and Implementation (OSDI). pages 521–538,2022
2022
-
[27]
2024.Planning with large language models for code generation
Shun Zhang, Zhenfang Chen, Yikang Shen, Mingyu Ding, Joshua B Tenenbaum, and Chuang Gan. 2024.Planning with large language models for code generation. arXiv:2303.05510
-
[28]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al . 2024. Sglang: Efficient execution of structured language model programs.Advances in neural information processing systems37 (2024), 62557–62583
2024
-
[29]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. 2024. {DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 193–210
2024
-
[30]
2025.PolyServe: Efficient Multi-SLO Serving at Scale
Kan Zhu, Haiyang Shi, Le Xu, Jiaxin Shan, Arvind Krishnamurthy, Baris Kasikci, and Liguang Xie. 2025.PolyServe: Efficient Multi-SLO Serving at Scale. arXiv:2507.17769
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.