Natural Language Access Control (NLAC): From Help Desk Requests to Structured Policies
Pith reviewed 2026-06-27 23:04 UTC · model grok-4.3
The pith
By selecting relevant network components with embedding similarity, LLMs translate natural language requests into access policies at up to 98.7% accuracy in large networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
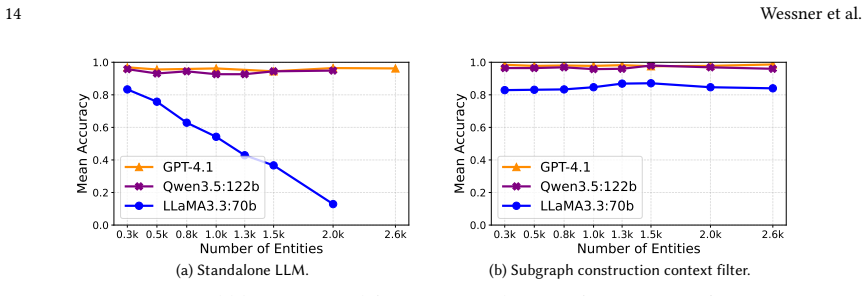
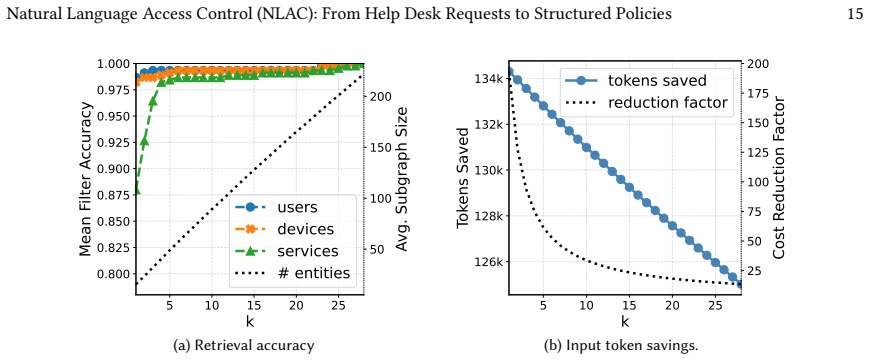
The authors show that an NLAC architecture using LLMs achieves high accuracy in translating user requests to policies when relevant network components are identified via embedding similarity to form compact subgraphs, reaching 98.7% accuracy in large networks with constant resource requirements, compared to degradation below 20% without this step.
What carries the argument
Embedding similarity to construct compact subgraphs of the network that are then provided to the LLM for policy generation.
If this is right
- Accuracy holds or improves as network size increases.
- Inference time and costs remain constant independent of network scale.
- Top models show complementary errors, enabling potential multi-model systems for higher accuracy.
- NLACBench serves as a standard for evaluating intent-to-policy translation systems.
Where Pith is reading between the lines
- Natural language interfaces could replace much of the manual configuration work in network security.
- The subgraph method might generalize to other tasks where LLMs interact with large graphs or databases.
- Further gains could come from fine-tuning embeddings specifically for policy relevance rather than general text similarity.
Load-bearing premise
Embedding similarity reliably identifies all network components required to generate the correct access policy for a given request.
What would settle it
A counterexample request where the embedding-selected subgraph omits a node or edge that changes the correct policy output from what the full network would yield.
Figures




read the original abstract
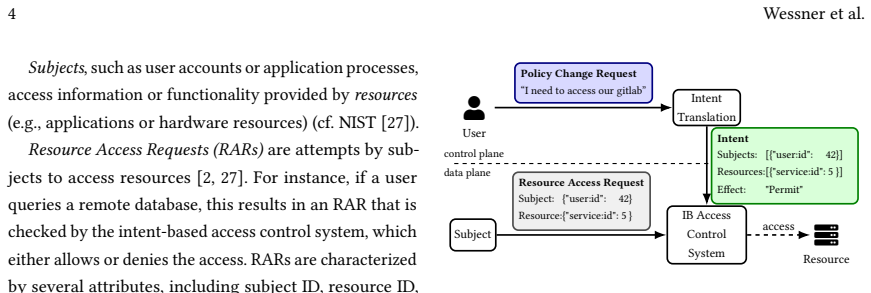
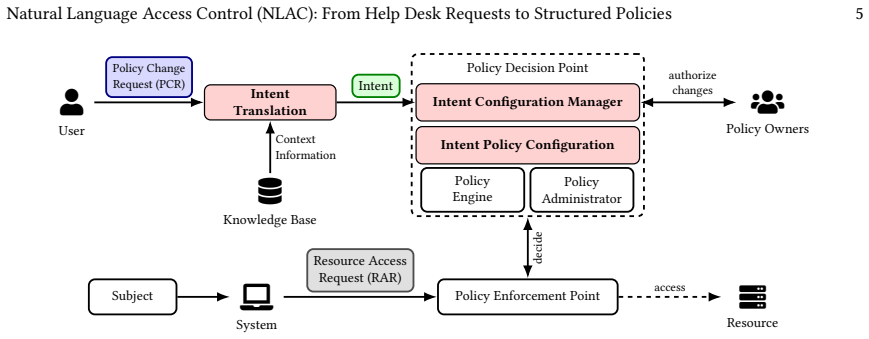
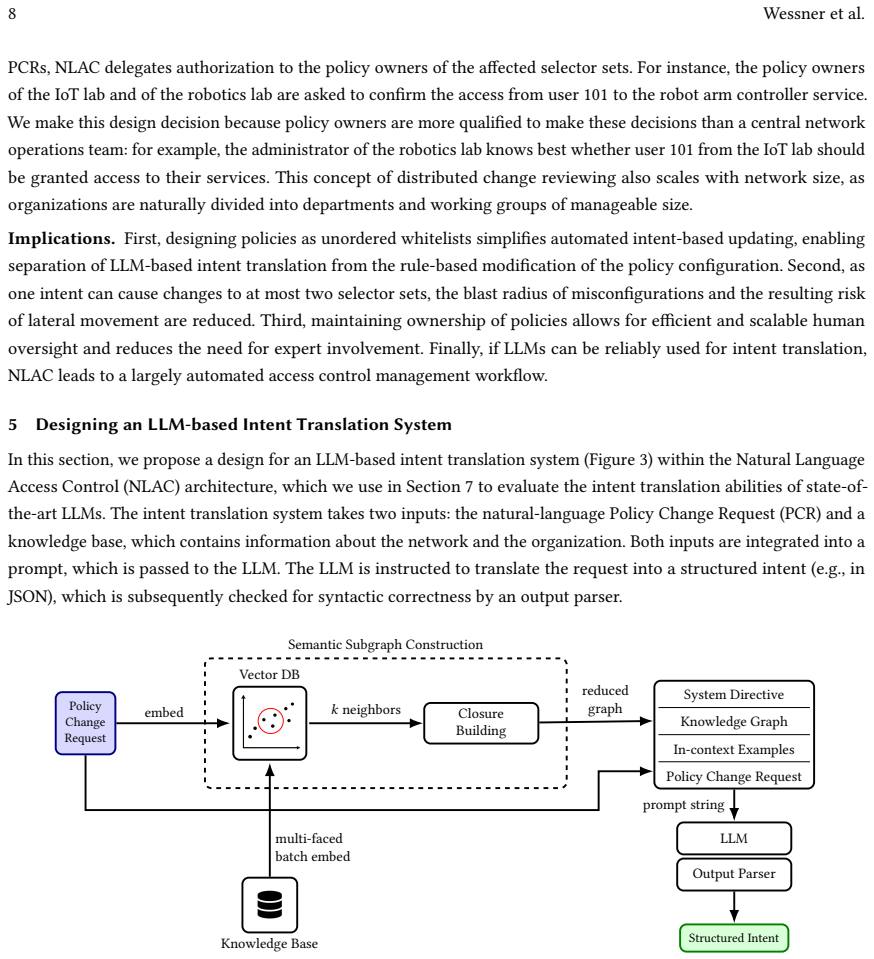
Configuring network access control policies in large, complex networks is error-prone and requires significant expert effort. LLMs offer a promising interface for expressing such policies in natural language, but their capability for translating user requests into access policies, and the system architectures best suited to leverage LLMs, remain underexplored. We present an architecture for natural-language access control (NLAC) that uses LLMs to translate user requests into access policies, and introduce NLACBench, a benchmark for evaluating LLM-based intent translation systems in large-scale networks. Our evaluation across multiple state-of-the-art models shows that top-performing LLMs achieve up to 96.9% accuracy in small-network settings, but performance degrades substantially (below 20% for some models) as network size increases. To address this limitation, we identify relevant network components via embedding similarity and construct compact subgraphs that are passed to the LLM. This approach enables scaling to larger networks with up to 98.7% accuracy, while simultaneously reducing inference time, hardware requirements, and operating costs to a constant resource budget. Finally, a case study indicates that top-performing models exhibit largely complementary error patterns, suggesting that intent translation accuracy may be further improved through multi-LLM architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an architecture called Natural Language Access Control (NLAC) in which LLMs translate natural-language help-desk requests into structured network access-control policies. It introduces the NLACBench benchmark for evaluating such systems on large-scale networks. Experiments show that leading LLMs reach up to 96.9 % accuracy on small networks but drop below 20 % for some models as network size grows; an embedding-similarity subgraph construction technique is proposed that restores accuracy to 98.7 % on larger instances while keeping inference cost constant. A case study indicates that the best models exhibit largely complementary errors, suggesting possible gains from multi-LLM ensembles.
Significance. If the reported accuracies prove reproducible, the work could materially reduce the expert effort required to configure access-control policies in complex networks and could establish NLACBench as a reference evaluation resource. The subgraph technique directly tackles the practical scaling barrier that currently limits LLM use on large topologies, and the complementary-error observation supplies a concrete direction for ensemble methods. These elements together address a real operational pain point in network management.
major comments (3)
- [Abstract] Abstract: concrete accuracy figures (96.9 % and 98.7 %) are stated without any definition of the accuracy metric, without error bars, without dataset-construction or exclusion criteria, and without a full description of the evaluation protocol. These omissions render the numerical claims uninterpretable and non-reproducible.
- [Subgraph construction paragraph] Subgraph construction paragraph: the scaling claim rests on the assumption that vector-similarity selection never omits a device, interface, or ACL entry whose absence would alter the ground-truth allow/deny decision. No completeness guarantee, threshold analysis, or post-hoc verification is supplied; if even a modest fraction of test cases suffer such omissions, the 98.7 % figure is an artifact of the test distribution rather than evidence of architectural robustness.
- [Evaluation] Evaluation description: the reported degradation below 20 % for some models on larger networks cannot be assessed without knowing how ground-truth policies are generated, how test requests are sampled, or what constitutes a correct structured-policy output. These details are load-bearing for any claim about scaling behavior.
minor comments (1)
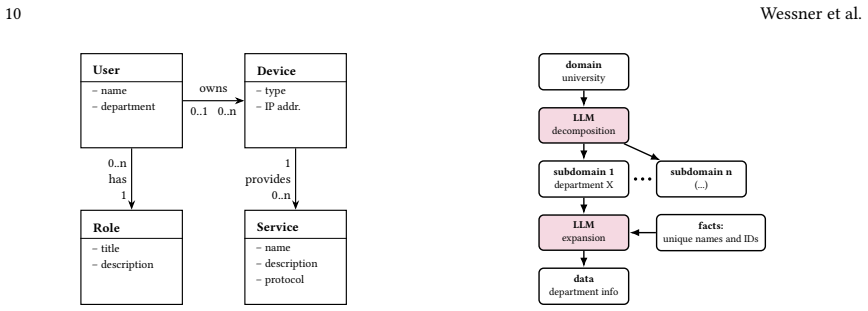
- [Abstract] The introduction of NLACBench would benefit from an explicit statement of its size, topology distribution, and labeling procedure even if full details appear later in the paper.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. The comments highlight important gaps in clarity and reproducibility that we will address. We respond point-by-point below and will incorporate the requested details into the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: concrete accuracy figures (96.9 % and 98.7 %) are stated without any definition of the accuracy metric, without error bars, without dataset-construction or exclusion criteria, and without a full description of the evaluation protocol. These omissions render the numerical claims uninterpretable and non-reproducible.
Authors: We agree that the abstract must be self-contained. In the revision we will add a concise definition of accuracy (exact match between generated and ground-truth structured policies on allow/deny decisions), note that results include standard deviations across runs (with error bars shown in the main figures), briefly summarize NLACBench construction and sampling, and direct readers to Section 4 for the full protocol. This will make the numerical claims interpretable without lengthening the abstract excessively. revision: yes
-
Referee: [Subgraph construction paragraph] Subgraph construction paragraph: the scaling claim rests on the assumption that vector-similarity selection never omits a device, interface, or ACL entry whose absence would alter the ground-truth allow/deny decision. No completeness guarantee, threshold analysis, or post-hoc verification is supplied; if even a modest fraction of test cases suffer such omissions, the 98.7 % figure is an artifact of the test distribution rather than evidence of architectural robustness.
Authors: The concern is valid; our current text does not supply a formal completeness argument or post-hoc checks. We will add (1) the exact similarity threshold and embedding model used, (2) a sensitivity analysis varying the threshold and reporting accuracy impact, and (3) a manual verification on 100 random large-network cases confirming that omitted elements never changed the ground-truth decision for the given request. If any omissions are found we will report them and adjust the claim accordingly. revision: yes
-
Referee: [Evaluation] Evaluation description: the reported degradation below 20 % for some models on larger networks cannot be assessed without knowing how ground-truth policies are generated, how test requests are sampled, or what constitutes a correct structured-policy output. These details are load-bearing for any claim about scaling behavior.
Authors: We will expand Section 4 with the missing details: ground-truth policies are produced by network experts following the NLACBench specification; requests are sampled stratified by network size and request complexity; correctness is defined as exact equivalence of the resulting allow/deny matrix for the requested flow. We will also include pseudocode for the evaluation pipeline and the precise criteria used to label a policy output as correct or incorrect. revision: yes
Circularity Check
No significant circularity; purely empirical evaluation on new benchmark
full rationale
The paper introduces NLACBench and reports direct empirical accuracies from LLM evaluations (up to 96.9% on small networks, 98.7% with subgraph method on larger ones). No equations, derivations, or load-bearing self-citations exist. The subgraph construction via embedding similarity is presented as an engineering heuristic whose effectiveness is measured by accuracy on held-out cases, not derived from or equivalent to its inputs by construction. This matches the default expectation of a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can translate natural language requests into correct structured access policies when supplied with relevant network context
invented entities (1)
-
NLACBench
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Muhammad Asif, Talha Ahmed Khan, and Wang-Cheol Song. 2025. Evaluating Large Language Models for Optimized Intent Translation and Contradiction Detection Using KNN in IBN.IEEE Access(2025), 20316–20327. https://doi.org/10.1109/ACCESS.2025.3534880
-
[2]
Leonard Bradatsch, Oleksandr Miroshkin, and Frank Kargl. 2023. ZTSFC: A Service Function Chaining-Enabled Zero Trust Architecture.IEEE Access11 (2023), 125307–125327. https://doi.org/10.1109/access.2023.3330706
-
[3]
Ye Cheng, Minghui Xu, Yue Zhang, Kun Li, Hao Wu, Yechao Zhang, Shaoyong Guo, Wangjie Qiu, Dongxiao Yu, and Xiuzhen Cheng. 2025. Say What You Mean: Natural Language Access Control with Large Language Models for Internet of Things.arXiv preprint arXiv: 2505.23835(2025)
arXiv 2025
-
[4]
Wenlong Ding, Jianqiang Li, Zhixiong Niu, et al. 2024. Poster: Automating Network Configuration with Natural Language Intents. InSIGCOMM Conference: Posters and Demos(Sydney, NSW, Australia). ACM, 19–21. https://doi.org/10.1145/3672202.3673721
-
[5]
Aaron Elliott and Scott Knight. 2010. Role Explosion: Acknowledging the Problem. Royal Military College, Kingston, Ontario, Canada
2010
-
[6]
Ahlam Fuad, Azza H. Ahmed, Michael A. Riegler, et al. 2024. An Intent-based Networks Framework based on Large Language Models. InInternational Conference on Network Softwarization (NetSoft). IEEE, 7–12. https://doi.org/10.1109/NetSoft60951.2024.10588879
-
[7]
João Vitor A. Garcês, Nicollas R. De Oliveira, João André C. Watanabe, et al. 2024. Intent-Based Management for Open RAN: Intelligent Network Configuration Automation via Chatbot. InInternational Conference on Cloud Networking (CloudNet). IEEE, 1–9. https://doi.org/10.1109/CloudNet62 863.2024.10815823
-
[8]
Carlos Gómez-Rodríguez and Paul Williams. 2023. A Confederacy of Models: a Comprehensive Evaluation of LLMs on Creative Writing. InFindings of the Association for Computational Linguistics: EMNLP. ACL, 14504–14528. https://doi.org/10.18653/v1/2023.findings-emnlp.966
-
[9]
Peyman Hosseini, Ignacio Castro, Iacopo Ghinassi, and Matthew Purver. 2025. Efficient Solutions for an Intriguing Failure of LLMs: Long Context Window Does Not Mean LLMs Can Analyze Long Sequences Flawlessly. InProceedings of the 31st international conference on computational linguistics. 1880–1891
2025
-
[10]
Vincent C. Hu, D. Richard Kuhn, David F. Ferraiolo, and Jeffrey Voas. 2015. Attribute-Based Access Control.Computer48, 2 (2015), 85–88
2015
-
[11]
Jacobs, Ricardo J
Arthur S. Jacobs, Ricardo J. Pfitscher, Rafael H. Ribeiro, et al. 2021. Hey, Lumi! Using Natural Language for Intent-Based Network Management. In Annual Technical Conference (ATC). USENIX Association, 625–639
2021
-
[12]
Jacobs, Ricardo J
Arthur S. Jacobs, Ricardo J. Pfitscher, Rafael H. Ribeiro, et al. 2021. Lumi Dataset. https://github.com/lumichatbot/webhook/blob/master/res/dataset. Accessed: 2026-01-26
2021
-
[13]
Sherifdeen Lawal, Xingmeng Zhao, Anthony Rios, Ram Krishnan, and David Ferraiolo. 2024. Translating Natural Language Specifications into Access Control Policies by Leveraging Large Language Models. In2024 IEEE 6th International Conference on Trust, Privacy and Security in Intelligent Systems, and Applications (TPS-ISA). 361–370. https://doi.org/10.1109/TP...
-
[14]
LDAP. 2026. Lightweight Directory Access Protocol (LDAP). https://ldap.com/. Accessed: 2026-05-26
2026
-
[15]
Aris Leivadeas and Matthias Falkner. 2023. A Survey on Intent-Based Networking.IEEE Communications Surveys & Tutorials25, 1 (2023), 625–655. https://doi.org/10.1109/comst.2022.3215919
-
[16]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InAdvances in Neural Information Processing Systems, Vol. 33. Curran Associates, Inc., 9459–9474
2020
-
[17]
Haoran Li, Qingxiu Dong, Zhengyang Tang, et al. 2024. Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models. arXiv preprint arXiv:2402.13064(2024). https://doi.org/10.48550/arXiv.2402.13064
-
[18]
Jiaqi Li, Mengmeng Wang, Zilong Zheng, and Muhan Zhang. 2024. LooGLE: Can Long-Context Language Models Understand Long Contexts?. In Annual Meeting of the Association for Computational Linguistics (ACL). ACL, 16304–16333. https://doi.org/10.18653/v1/2024.acl-long.859
-
[19]
Samuel Lin, Jiawei Zhou, and Minlan Yu. 2025. An LLM-based Agentic Framework for Accessible NetworkControl.SIGMETRICS Perform. Eval. Rev. 53, 2 (2025). https://doi.org/10.1145/3764944.3764949 18 Wessner et al
-
[20]
Jianmin Liu, Li Chen, Dan Li, et al. 2025. CEGS: Configuration Example Generalizing Synthesizer. InSymposium on Networked Systems Design and Implementation (NSDI). USENIX Association, 1327–1347
2025
-
[21]
Lin Long, Rui Wang, Ruixuan Xiao, Junbo Zhao, Xiao Ding, Gang Chen, and Haobo Wang. 2024. On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey. InFindings of the Association for Computational Linguistics: ACL. ACL, 11065–11082. https://doi.org/10.18653/v 1/2024.findings-acl.658
work page doi:10.18653/v 2024
-
[22]
Khang Mai, Nakul Ghate, Jongmin Lee, and Razvan Beuran. 2025. LLM-Based Fine-Grained ABAC Policy Generation. In11th International Conference on Information Systems Security and Privacy - Volume 2: ICISSP. INSTICC, SciTePress, 204–212. https://doi.org/10.5220/0013225500003899
-
[23]
NetBox Labs. 2025. NetBox. https://github.com/netbox-community/netbox. Accessed: 2025-10-31
2025
-
[24]
Oasis. 2013. eXtensible Access Control Markup Language (XACML) Version 3.0. https://docs.oasis-open.org/xacml/3.0/xacml-3.0-core-spec-os- en.html. OASIS Standard
2013
-
[25]
OpenAI. 2025. OpenAI API Pricing. https://openai.com/api/pricing/. Accessed: 2025-11-12; input and output tokens are billed per million tokens
2025
-
[26]
Maria Teresa Paratore, Eda Marchetti, and Antonello Calabrò. 2025. From Plain English to XACML Policies: An AI-Based Pipeline Approach. In13th International Conference on Model-Based Software and Systems Engineering - MODELSW ARD. SciTePress, 85–96. https://doi.org/10.5220/0013357200 003896
-
[27]
Scott Rose, Oliver Borchert, Stu Mitchell, and Connelly Sean. 2020. Zero Trust Architecture.NIST Special Publication800-207 (2020). https: //doi.org/10.6028/nist.sp.800-207
-
[28]
Ravi S. Sandhu. 1998. Role-based Access Control. Vol. 46. Elsevier
1998
-
[29]
Daniel Servos and Sylvia L. Osborn. 2017. Current Research and Open Problems in Attribute-Based Access Control.ACM Computing Surveys(2017)
2017
-
[30]
Pratik Sonune, Ritwik Rai, Shamik Sural, Vijayalakshmi Atluri, and Ashish Kundu. 2025. LMN: A Tool for Generating Machine Enforceable Policies from Natural Language Access Control Rules using LLMs.arXiv preprint arXiv:2502.12460(2025)
arXiv 2025
-
[31]
Ashish Vaswani, Noam Shazeer, Niki Parmar, et al. 2017. Attention is All you Need. InAdvances in Neural Information Processing Systems (NIPS), Vol. 30. Curran Associates, Inc
2017
-
[32]
Adarsh Vatsa, Pratyush Patel, and William Eiers. 2025. Synthesizing Access Control Policies Using Large Language Models. In2025 IEEE/ACM International Workshop on Natural Language-Based Software Engineering (NLBSE). 13–16. https://doi.org/10.1109/NLBSE66842.2025.00008
-
[33]
Fanqi Wan, Xinting Huang, Tao Yang, Xiaojun Quan, Wei Bi, and Shuming Shi. 2023. Explore-Instruct: Enhancing Domain-Specific Instruction Coverage through Active Exploration. InConference on Empirical Methods in Natural Language Processing (EMNLP). ACL, 9435–9454. https: //doi.org/10.18653/v1/2023.emnlp-main.587
-
[34]
Changjie Wang, Mariano Scazzariello, Alireza Farshin, et al. 2024. NetConfEval: Can LLMs Facilitate Network Configuration?SIGCOMM Computer Communication Review2, CoNEXT2, Article 7 (June 2024), 25 pages. https://doi.org/10.1145/3656296
-
[35]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought Prompting Elicits Reasoning in Large Language Models. 35 (2022), 24824–24837
2022
-
[36]
Robot Arm Controller
Wessner, Jonas. 2026. NLAC Artifacts Repository. released upon publication. Natural Language Access Control (NLAC): From Help Desk Requests to Structured Policies 19 A Ethical Considerations We provide a stakeholder-based ethics analysis of the potential impacts of our work. Network Operations Teams.Our work can reduce the workload of network operations t...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.