BiEAR: A Human Auditory-Inspired Adaptive Binaural Front-end for Multi-Speaker Localisation and Distance Estimation
Pith reviewed 2026-06-27 21:20 UTC · model grok-4.3
The pith
A neural controller adapts binaural filter selectivity during inference to improve multi-speaker localisation accuracy and room robustness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BiEAR uses a neural controller to adaptively adjust the frequency selectivity of a binaural auditory filterbank during inference, yielding time-frequency adaptive representations for the ears that enable improved multi-speaker localisation and distance estimation in anechoic and real-room environments compared with fixed binaural front-ends.
What carries the argument
The neural controller that adjusts the frequency selectivity of the binaural auditory filterbank in response to acoustic conditions during inference.
If this is right
- Localisation accuracy rises for multiple simultaneous speakers in both anechoic and reverberant rooms.
- Performance holds up better when test speakers or rooms differ from those seen in training.
- The system learns to weight informative frequency bands more heavily as conditions change over time.
Where Pith is reading between the lines
- The same controller could be tested on other binaural tasks such as source separation or speech enhancement without major redesign.
- If the adaptation proves causal, hybrid systems might combine this front-end with existing deep models to reduce retraining costs across environments.
- Extending the controller to handle moving sources or rapidly varying noise would test whether the biological analogy scales to more dynamic scenes.
Load-bearing premise
The neural controller's adjustments to frequency selectivity during inference cause the reported performance gains rather than other differences in the overall pipeline or training procedure.
What would settle it
An ablation experiment that keeps the full pipeline and training identical but disables the neural controller's ability to adjust filter selectivity at inference time, then measures whether localisation accuracy and robustness to new speakers and rooms remain unchanged.
Figures

read the original abstract
We present BiEAR, a human auditory-inspired adaptive binaural front-end for multi-speaker localisation and distance estimation. Inspired by medial olivocochlear (MOC) feedback in human hearing, BiEAR uses a neural controller to adaptively adjust the frequency selectivity of a binaural auditory filterbank during inference. This yields time-frequency adaptive representations for ears, enabling the model to respond to changing acoustic conditions. We evaluate BiEAR on multi-speaker localisation and distance estimation in anechoic and real-room environments. Results show that the adaptive front-end improves localisation accuracy and robustness to unseen speakers and rooms compared with commonly used fixed binaural front-ends. Visualisation and analysis of learned filter adaptations show that BiEAR emphasises informative frequency bands over time. These findings suggest that adaptive, biologically inspired binaural front-ends can improve machine hearing robustness in complex acoustic scenes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BiEAR, a binaural front-end inspired by medial olivocochlear feedback that employs a neural controller to dynamically adjust the frequency selectivity of an auditory filterbank at inference time. This produces time-frequency adaptive representations claimed to improve multi-speaker localisation and distance estimation in anechoic and real-room conditions, with reported gains in accuracy and robustness to unseen speakers/rooms over standard fixed binaural front-ends. Visualisations of the learned adaptations are included to support the biological inspiration.
Significance. If the adaptive mechanism can be shown to be causally responsible for the gains, the approach would offer a concrete example of biologically motivated dynamic processing that could enhance robustness in machine hearing systems operating under varying acoustic conditions.
major comments (2)
- [Evaluation / Experiments] The central claim attributes performance improvements to the neural controller's inference-time adjustments, yet the manuscript provides no ablation that isolates this component (e.g., by replacing the adaptive controller with a static or time-averaged equivalent while holding filterbank design, training procedure, loss, and localisation head fixed). Comparisons are only to 'commonly used fixed binaural front-ends,' which may differ in multiple uncontrolled ways.
- [Abstract] The abstract asserts quantitative gains in localisation accuracy and robustness but supplies no numerical results, error bars, statistical tests, or architecture details for the neural controller. The full manuscript must include these to substantiate the claims.
minor comments (2)
- [Method] Clarify the exact architecture and training objective of the neural controller; the current description leaves its parameter count and update rule underspecified.
- [Results] Ensure all tables reporting localisation and distance errors include baseline comparisons with identical downstream heads and training protocols.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will revise the manuscript to incorporate the suggested improvements, thereby strengthening the evidence for our claims.
read point-by-point responses
-
Referee: [Evaluation / Experiments] The central claim attributes performance improvements to the neural controller's inference-time adjustments, yet the manuscript provides no ablation that isolates this component (e.g., by replacing the adaptive controller with a static or time-averaged equivalent while holding filterbank design, training procedure, loss, and localisation head fixed). Comparisons are only to 'commonly used fixed binaural front-ends,' which may differ in multiple uncontrolled ways.
Authors: We agree that an ablation isolating the inference-time adaptive controller is necessary to causally attribute the gains. In the revised manuscript, we will add this experiment: a static-controller variant (with time-averaged or fixed parameters) will be trained and evaluated under identical conditions to the full BiEAR model, holding the filterbank, loss, and localisation head fixed. This will directly address the concern about uncontrolled differences in the existing comparisons to fixed front-ends. revision: yes
-
Referee: [Abstract] The abstract asserts quantitative gains in localisation accuracy and robustness but supplies no numerical results, error bars, statistical tests, or architecture details for the neural controller. The full manuscript must include these to substantiate the claims.
Authors: We will revise the abstract to include key quantitative results (e.g., specific accuracy improvements with error bars), mention statistical significance where applicable, and provide concise architecture details for the neural controller. The full manuscript already reports these elements in the experiments section; the abstract update will ensure the claims are substantiated at the outset. revision: yes
Circularity Check
No circularity: empirical neural model with no derivations or self-referential reductions
full rationale
The paper describes an architecture (neural controller adjusting filterbank selectivity) and reports empirical results on localisation/distance tasks versus fixed baselines. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. All claims rest on experimental comparisons rather than any chain that reduces by construction to its own inputs. This is the common case of a self-contained engineering proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Binaural sound source localisation and distance detection sup- port many machine-hearing applications, including binaural speech enhancement [1, 2], acoustic scene analysis [3–5], and speaker tracking for robotics [6–8]. In computational auditory scene analysis (CASA) [9], achieving human-like localisation and distance perception remains chal...
-
[2]
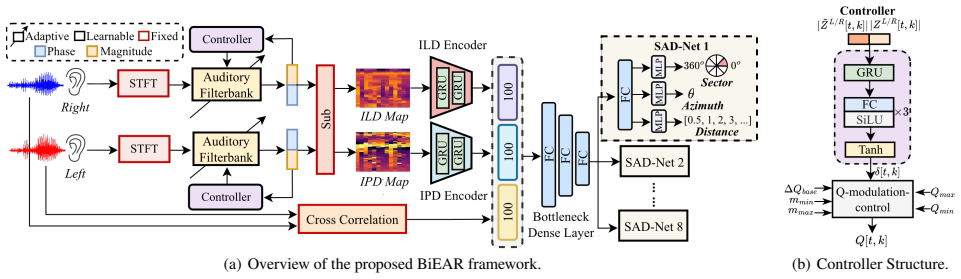
Model Overview An overview of BiEAR is shown in Fig
BiEAR 2.1. Model Overview An overview of BiEAR is shown in Fig. 2(a). Following prior work [12, 15], we uniformly partition the azimuth range [0◦,360 ◦)into eight45 ◦ sectors. Accordingly, BiEAR com- prises eight sector-wise SAD-Nets for joint source detection, arXiv:2606.06795v1 [eess.AS] 5 Jun 2026 (a) Overview of the proposed BiEAR framework. (b) Contr...
Pith/arXiv arXiv 2026
-
[3]
Data Preparation An anechoic binaural speech dataset was generated following the DeepEar protocol [15]
Experimental Setups 3.1. Data Preparation An anechoic binaural speech dataset was generated following the DeepEar protocol [15]. Clean monaural utterances were drawn from TIMIT [30], clipped or zero-padded to 1 second, and spatialized by convolving with anechoic binaural room im- pulse responses (BRIRs). Multi-speaker mixtures were cre- ated by independen...
-
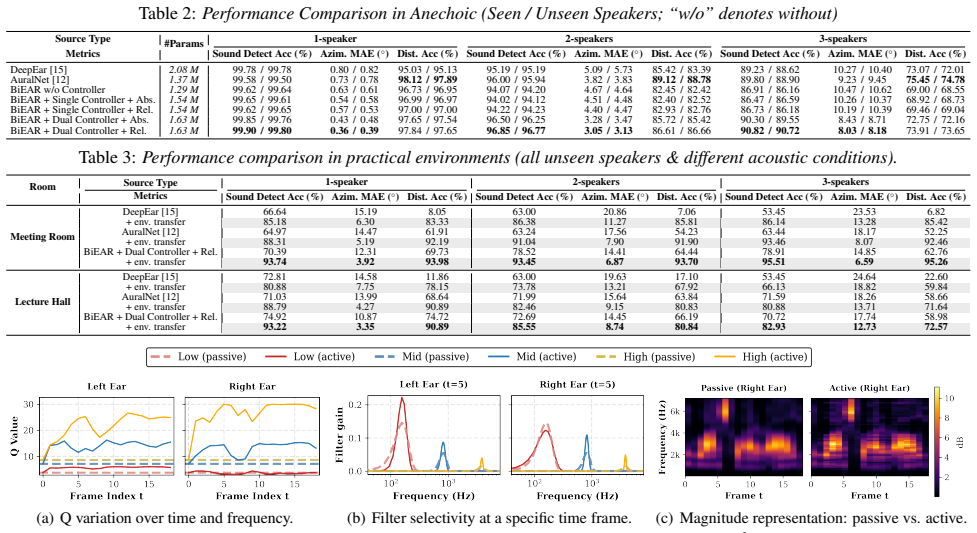
[4]
Passive” is w/o controller; “Active
Results and Discussions 4.1. Anechoic Environments Table 2 summarizes the performance of the baselines and BiEAR variants trained onAnechoic-train, validated on Anechoic-val, and evaluated onAnechoic-testand the speaker disjoint setAnechoic-test-unseen-spkunder one-, two-, and three-speaker mixtures. We report sound detection accuracy, azimuth mean absolu...
-
[5]
MOC inspired neural feedback regulates filterbank Q-factors, enabling time-frequency adaptive, ear- specific modulation
Conclusion In this work, we propose BiEAR, a human auditory-inspired adaptive binaural front-end for multi-speaker localisation and distance estimation. MOC inspired neural feedback regulates filterbank Q-factors, enabling time-frequency adaptive, ear- specific modulation. Across anechoic and real room conditions with unseen speakers and environments, BiE...
-
[6]
The authors would also like to thank UNSW, Sydney, Australia, for providing PhD scholarship support
Acknowledgments This work was funded by ARC Discovery Grant DP210101228. The authors would also like to thank UNSW, Sydney, Australia, for providing PhD scholarship support
-
[7]
Multi-channel conversational speaker separation via neural diarization,
H. Taherian and D. Wang, “Multi-channel conversational speaker separation via neural diarization,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 2467–2476, 2024
2024
-
[8]
Binaural Speech Separation of Moving Speakers With Preserved Spatial Cues,
C. Han, Y . Luo, and N. Mesgarani, “Binaural Speech Separation of Moving Speakers With Preserved Spatial Cues,” inInterspeech 2021, 2021, pp. 3505–3509
2021
-
[9]
Multi-target doa estimation with an audio-visual fusion mechanism,
X. Qian, M. Madhavi, Z. Pan, J. Wang, and H. Li, “Multi-target doa estimation with an audio-visual fusion mechanism,” inProc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 4280–4284
2021
-
[10]
Sound event localization and detection of overlapping sources using con- volutional recurrent neural networks,
S. Adavanne, A. Politis, J. Nikunen, and T. Virtanen, “Sound event localization and detection of overlapping sources using con- volutional recurrent neural networks,”IEEE Journal of Selected Topics in Signal Processing, vol. 13, no. 1, pp. 34–48, 2019
2019
-
[11]
DeepASA: An object-oriented multi-purpose network for auditory scene analysis,
D. Lee, Y . Kwon, and J.-W. Choi, “DeepASA: An object-oriented multi-purpose network for auditory scene analysis,” inAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[12]
Glmb 3d speaker tracking with video-assisted multi-channel audio opti- mization functions,
X. Qian, Z. Pan, Q. Zhang, K. Chen, and S. Lin, “Glmb 3d speaker tracking with video-assisted multi-channel audio opti- mization functions,” inProc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 8100–8104
2024
-
[13]
Binaural sound source distance estimation and localization for a moving listener,
D. A. Krause, G. Garc ´ıa-Barrios, A. Politis, and A. Mesaros, “Binaural sound source distance estimation and localization for a moving listener,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 996–1011, 2024
2024
-
[14]
IPDnet: A universal direct- path IPD estimation network for sound source localization,
Y . Wang, B. Yang, and X. Li, “IPDnet: A universal direct- path IPD estimation network for sound source localization,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 32, pp. 5051–5064, 2024
2024
-
[15]
Fundamentals of computational audi- tory scene analysis,
D. Wang and G. J. Brown, “Fundamentals of computational audi- tory scene analysis,” inComputational Auditory Scene Analysis: Principles, Algorithms, and Applications, 2006, pp. 1–44
2006
-
[16]
Identifying the human-machine differ- ences in complex binaural scenes: what can be learned from our auditory system,
C. Spille and B. T. Meyer, “Identifying the human-machine differ- ences in complex binaural scenes: what can be learned from our auditory system,” inInterspeech 2014, 2014, pp. 626–630
2014
-
[17]
End-to- end binaural sound localisation from the raw waveform,
P. Vecchiotti, N. Ma, S. Squartini, and G. J. Brown, “End-to- end binaural sound localisation from the raw waveform,” inProc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, May 2019, pp. 451–455
2019
-
[18]
Auralnet: Hierarchical attention-based 3d binaural localization of overlapping speakers,
L. Fu, Y . Liu, Z. Liu, Z. Yang, Z.-Q. Wang, Y . Li, and H. Kong, “Auralnet: Hierarchical attention-based 3d binaural localization of overlapping speakers,” inInterspeech 2025, 2025, pp. 938–942
2025
-
[19]
Bast- mamba: Binaural audio spectrogram mamba transformer for bin- aural sound localization,
S. Kuang, J. Shi, K. van der Heijden, and S. Mehrkanoon, “Bast- mamba: Binaural audio spectrogram mamba transformer for bin- aural sound localization,”Neurocomputing, vol. 650, p. 130804, 2025
2025
-
[20]
Framewise multi- ple sound source localization and counting using binaural spatial audio signals,
L. Wang, Z. Jiao, Q. Zhao, J. Zhu, and Y . Fu, “Framewise multi- ple sound source localization and counting using binaural spatial audio signals,” inProc. IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[21]
DeepEar: Sound localization with bin- aural microphones,
Q. Yang and Y . Zheng, “DeepEar: Sound localization with bin- aural microphones,”IEEE Transactions on Mobile Computing, vol. 23, no. 1, pp. 359–375, 2024
2024
-
[22]
F. Jazaeri, H. Kamkar-Parsi, F. Grondin, and M. Bouchard, “Multi-speaker doa estimation in binaural hearing aids us- ing deep learning and speaker count fusion,”arXiv preprint arXiv:2509.21382, 2025
Pith/arXiv arXiv 2025
-
[23]
Auditory cortex- inspired spectral attention modulation for binaural sound local- ization in hrtf mismatch,
W. Phokhinanan, N. Obin, and S. Argentieri, “Auditory cortex- inspired spectral attention modulation for binaural sound local- ization in hrtf mismatch,” inProc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 8656–8660
2024
-
[24]
Binaural localization model for speech in noise,
V . Tokala, E. Grinstein, R. Brooks, M. Brookes, S. Doclo, J. Jensen, and P. A. Naylor, “Binaural localization model for speech in noise,” inProc. 11th Convention of the European Acous- tics Association (EAA), Jun 2025, pp. 1–5
2025
-
[25]
Learning deep direct-path rel- ative transfer function for binaural sound source localization,
B. Yang, H. Liu, and X. Li, “Learning deep direct-path rel- ative transfer function for binaural sound source localization,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 29, pp. 3491–3503, Oct 2021
2021
-
[26]
Olivocochlear efferents: Their action, effects, mea- surement and uses, and the impact of the new conception of cochlear mechanical responses,
J. J. Guinan, “Olivocochlear efferents: Their action, effects, mea- surement and uses, and the impact of the new conception of cochlear mechanical responses,”Hearing Research, vol. 362, pp. 38–47, 2018
2018
-
[27]
Mechanisms of sound localization in mammals,
B. Grothe, M. Pecka, and D. McAlpine, “Mechanisms of sound localization in mammals,”Physiological Reviews, vol. 90, no. 3, pp. 983–1012, 2010
2010
-
[28]
Sound localization: Jeffress and be- yond,
G. Ashida and C. E. Carr, “Sound localization: Jeffress and be- yond,”Current Opinion in Neurobiology, vol. 21, no. 5, pp. 745– 751, 2011
2011
-
[29]
Auditory efferents facilitate sound localization in noise in humans,
G. And ´eol, A. Guillaume, C. Micheyl, S. Savel, L. Pellieux, and A. Moulin, “Auditory efferents facilitate sound localization in noise in humans,”Journal of Neuroscience, vol. 31, no. 18, pp. 6759–6763, May 2011
2011
-
[30]
Adap- tive per-channel energy normalization front-end for robust au- dio signal processing,
H. Meng, V . Sethu, E. Ambikairajah, Q. Zhang, and H. Li, “Adap- tive per-channel energy normalization front-end for robust au- dio signal processing,” inProc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2026, pp. 14 757–14 761
2026
-
[31]
Should audio front-ends be adaptive? comparing learnable and adaptive front-ends,
Q. Zhang, B. Wickramasinghe, E. Ambikairajah, V . Sethu, and H. Li, “Should audio front-ends be adaptive? comparing learnable and adaptive front-ends,”IEEE Transactions on Audio, Speech and Language Processing, vol. 33, pp. 998–1010, 2025
2025
-
[32]
DNN controlled adaptive front-end for replay attack detection systems,
B. Wickramasinghe, E. Ambikairajah, V . Sethu, J. Epps, H. Li, and T. Dang, “DNN controlled adaptive front-end for replay attack detection systems,”Speech Communication, vol. 154, p. 102973, 2023
2023
-
[33]
LEAF: A learnable frontend for audio classi- fication,
N. Zeghidour, O. Teboul, F. de Chaumont Quitry, and M. Tagliasacchi, “LEAF: A learnable frontend for audio classi- fication,” inProc. International Conference on Learning Repre- sentations (ICLR), 2021
2021
-
[34]
Derivation of auditory fil- ter shapes from notched-noise data,
B. R. Glasberg and B. C. Moore, “Derivation of auditory fil- ter shapes from notched-noise data,”Hearing Research, vol. 47, no. 1, pp. 103–138, 1990
1990
-
[35]
Extension of a binaural cross-correlation model by contralateral inhibition. i. simulation of lateralization for sta- tionary signals,
W. Lindemann, “Extension of a binaural cross-correlation model by contralateral inhibition. i. simulation of lateralization for sta- tionary signals,”The Journal of the Acoustical Society of America, vol. 80, no. 6, pp. 1608–1622, Dec. 1986
1986
-
[36]
DARPA TIMIT acoustic-phonetic continuous speech corpus CD-ROM,
J. S. Garofolo, L. F. Lamel, W. M. Fisher, J. G. Fiscus, and D. S. Pallett, “DARPA TIMIT acoustic-phonetic continuous speech corpus CD-ROM,” National Institute of Standards and Technol- ogy (NIST), NASA STI/Recon Technical Report 93-27403, 1993
1993
-
[37]
A free database of head- related impulse response measurements in the horizontal plane with multiple distances,
H. Wierstorf, M. Geier, and S. Spors, “A free database of head- related impulse response measurements in the horizontal plane with multiple distances,” inProceedings of the 130th Audio Engi- neering Society Convention. Audio Engineering Society, 2011
2011
-
[38]
H. Wierstorf, M. Geier, A. Raake, and S. Spors, “A free database of head-related impulse response measurements in the horizontal plane with multiple distances,” Jun. 2016. [Online]. Available: https://doi.org/10.5281/zenodo.55418
-
[39]
https://doi.org/10.5281/zenodo
H. Wierstorf and M. Geier, “Binaural room impulse responses recorded with KEMAR in a small meeting room,” Zenodo, Oct. 2016. [Online]. Available: https://doi.org/10.5281/zenodo. 160751
-
[40]
Binaural room impulse responses recorded with KEMAR in a mid-size lecture hall,
——, “Binaural room impulse responses recorded with KEMAR in a mid-size lecture hall,” Zenodo, Oct. 2016. [Online]. Available: https://doi.org/10.5281/zenodo.160749
-
[41]
Adam: A method for stochastic op- timization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic op- timization,” inProceedings of the International Conference on Learning Representations (ICLR), 2015
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.