Towards Event-Robust Acoustic Scene Classification
Pith reviewed 2026-06-27 21:18 UTC · model grok-4.3
The pith
Existing acoustic scene classifiers lose substantial accuracy when unknown foreground events intrude on background recordings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
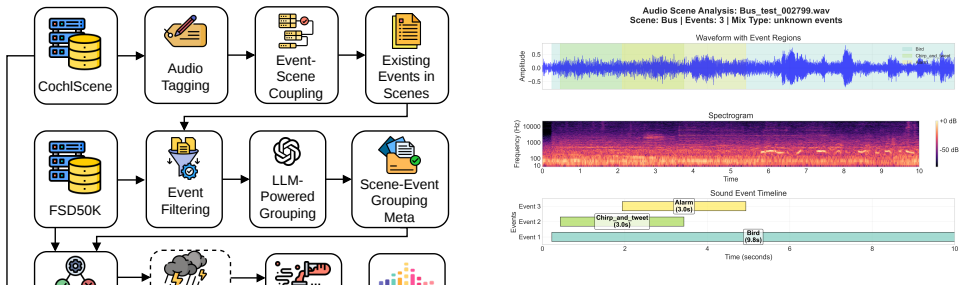
The Event-Shifted Acoustic Scene (ESAS) dataset is built by LLM-assisted injection of foreground sound events into background acoustic scenes, and evaluations on this benchmark establish that existing acoustic scene classification systems undergo significant performance degradation when confronted with event shifts.
What carries the argument
The ESAS dataset, formed through large language model guided insertion of foreground events into scene backgrounds, functions as the evaluation benchmark for robustness.
If this is right
- State-of-the-art acoustic scene classification models will exhibit reduced accuracy on data containing unexpected sound events.
- Research on acoustic scene classification will shift toward methods designed to handle event variations.
- The ESAS benchmark will serve as a standard for measuring and advancing robustness in future systems.
Where Pith is reading between the lines
- Training procedures that rely solely on clean scene data may require additional diversity mechanisms to reach stable performance outside controlled conditions.
- Event-shift effects observed here could appear in related audio tasks such as sound event detection or environmental sound tagging.
- Practical ASC deployments in variable settings may benefit from mechanisms that detect and adapt to novel foreground sounds during operation.
Load-bearing premise
Large language model injection of foreground events into background scenes produces audio that matches the diversity and unpredictability of actual real-world recordings.
What would settle it
Measure accuracy drops of the same models on a set of naturally recorded real-world scenes that contain unexpected foreground events; matching or larger drops than those seen on ESAS would support the central claim.
Figures
read the original abstract
This paper introduces the Event-Shifted Acoustic Scene (ESAS) dataset, a novel benchmark for evaluating the robustness of Acoustic Scene Classification (ASC) systems against unknown sound events. Existing ASC datasets typically contain recordings of clean and consistent audio, while real-world environments often include diverse and unexpected sound events. To bridge this gap, ESAS simulates real-world acoustic variability by injecting foreground sound events into background scenes with the assistance of large language models. In this work, we present the construction methodology, dataset statistics, and evaluation protocols. Furthermore, a comprehensive evaluation of state-of-the-art ASC systems is conducted using the ESAS benchmark. Experimental results reveal that existing ASC models suffer significant performance degradation when facing the event-shift challenge. The introduction of the ESAS dataset aims to drive future research toward event-robust ASC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Event-Shifted Acoustic Scene (ESAS) dataset, constructed via LLM-assisted injection of foreground sound events into background acoustic scenes to simulate real-world variability. It describes the construction methodology, dataset statistics, and evaluation protocols, then evaluates state-of-the-art ASC models on ESAS, reporting significant performance degradation that the authors attribute to an event-shift challenge, with the goal of spurring research on event-robust ASC.
Significance. If the LLM-assisted injection produces a faithful proxy for natural acoustic events (preserving mixing statistics, spectral properties, and unpredictability), the reported degradation would identify a meaningful robustness gap in existing ASC systems and supply a new benchmark for the field. The work's value would lie in shifting focus from clean-scene classification to handling unexpected foreground events.
major comments (2)
- [Construction methodology] Construction methodology (as summarized in the abstract): the claim that ESAS simulates real-world acoustic variability rests on LLM-assisted foreground injection, yet no quantitative validation is described (e.g., perceptual listening tests, comparison of spectro-temporal statistics against real recordings, or ablation on SNR/overlap parameters). This is load-bearing for the central claim, because degradation could arise from synthetic artifacts (discontinuities, level mismatches, or non-natural event distributions) rather than genuine event-shift robustness.
- [Evaluation protocols] Evaluation protocols and experimental results (abstract): the headline finding of 'significant performance degradation' is presented without reported magnitudes, specific model identifiers, or controls that isolate event injection from other dataset factors. Without these, it is difficult to assess whether the drop supports the intended conclusion about event robustness.
minor comments (1)
- The abstract would benefit from explicit dataset statistics (number of scenes, event categories, SNR ranges) to allow readers to gauge scale and diversity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the ESAS dataset construction and evaluation. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Construction methodology] Construction methodology (as summarized in the abstract): the claim that ESAS simulates real-world acoustic variability rests on LLM-assisted foreground injection, yet no quantitative validation is described (e.g., perceptual listening tests, comparison of spectro-temporal statistics against real recordings, or ablation on SNR/overlap parameters). This is load-bearing for the central claim, because degradation could arise from synthetic artifacts (discontinuities, level mismatches, or non-natural event distributions) rather than genuine event-shift robustness.
Authors: We agree that the absence of quantitative validation (perceptual tests, spectro-temporal comparisons to real data, or explicit SNR/overlap ablations) is a limitation in the current manuscript. The construction section describes LLM-based event selection for contextual plausibility and mixing parameters drawn from existing ASC augmentation literature, but does not empirically confirm fidelity to natural event distributions. We will add an ablation study on SNR and overlap parameters plus a discussion of potential artifacts in the revised version; a small-scale listening test will be considered if resources allow. revision: yes
-
Referee: [Evaluation protocols] Evaluation protocols and experimental results (abstract): the headline finding of 'significant performance degradation' is presented without reported magnitudes, specific model identifiers, or controls that isolate event injection from other dataset factors. Without these, it is difficult to assess whether the drop supports the intended conclusion about event robustness.
Authors: The full manuscript reports specific state-of-the-art ASC models, exact accuracy drops, and protocols that compare original scenes against their event-injected counterparts. However, the abstract summarizes these findings at a high level without magnitudes or identifiers. We will revise the abstract to include key quantitative results and model names, and will add explicit text in the evaluation section confirming that the only difference between conditions is the injected events (same background recordings, same recording conditions). revision: partial
Circularity Check
No circularity: empirical evaluation on newly constructed benchmark
full rationale
The paper introduces the ESAS dataset via LLM-assisted foreground event injection into background scenes and reports measured performance degradation of existing ASC models on this benchmark. No equations, parameter fits, or derivations are present in the provided text. The central result is an external empirical measurement on the constructed data rather than a quantity that reduces to the construction method by definition or self-citation. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear. The work is self-contained as a dataset-plus-evaluation contribution against external model benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Acoustic Scene Classification (ASC) is a fundamental task in the field of computational sound scene analysis [1, 2]. ASC aims to recognize the environment in which an audio recording was captured, such as a park, airport, or metro station. While ASC models have achieved remarkable progress with the help of large-scale datasets [3, 4, 5] and d...
Pith/arXiv arXiv 2026
-
[2]
Event-Shifted Acoustic Scene Dataset The Event-Shifted Acoustic Scene (ESAS) dataset is developed to evaluate the robustness of ASC systems under the presence of unknown sound events. It combines background record- ings from CochlScene with foreground events from FSD50K. With the help of Large Language Model (LLM), we pro- duce polyphonic mixtures that si...
-
[3]
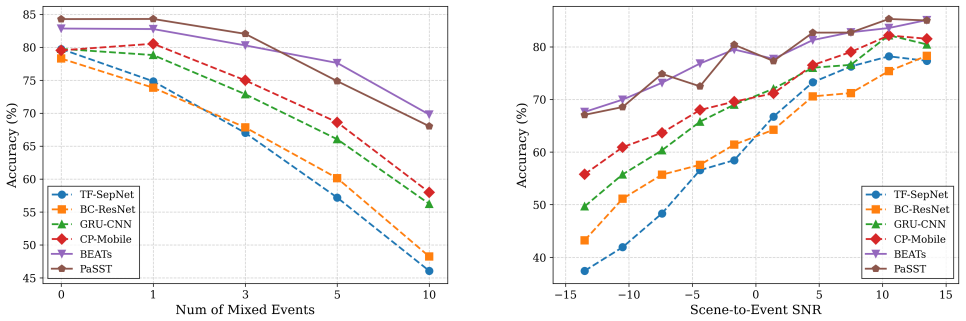
Experiment 3.1. Baselines To comprehensively evaluate the vulnerability of current methodologies under event-shift conditions, we benchmark the ESAS dataset against a diverse set of state-of-the-art ASC mod- els. Recognizing the dual necessity for both highly efficient and robust acoustic representation learning in real-world de- ployments, we selected ba...
-
[4]
By evaluating various state-of-the-art models, we exposed a critical vulnerability in current ASC methods
Conclusion In this paper, we introduced the Event-Shifted Acoustic Scene (ESAS) dataset, a new benchmark designed to evaluate the robustness of Acoustic Scene Classification (ASC) systems against unexpected foreground sounds. By evaluating various state-of-the-art models, we exposed a critical vulnerability in current ASC methods. Experimental results rev...
-
[5]
Acknowledgments This work was supported by the Jiangsu Provincial Major Sci- ence and Technology Project (BG2024027)
-
[6]
Generative AI Use Disclosure As detailed in the methodology section, OpenAI’s GPT-4 was used to guide the semantic scene-event grouping during the con- struction of the ESAS dataset
-
[7]
Acoustic scene classification: Classifying environments from the sounds they produce,
D. Barchiesi, D. Giannoulis, D. Stowell, and M. D. Plumbley, “Acoustic scene classification: Classifying environments from the sounds they produce,”IEEE Signal Processing Magazine, vol. 32, no. 3, pp. 16–34, 2015
2015
-
[8]
Virtanen, M
T. Virtanen, M. D. Plumbley, and D. Ellis,Computational analysis of sound scenes and events. Springer, 2018, vol. 9
2018
-
[9]
A multi-device dataset for urban acoustic scene classification,
A. Mesaros, T. Heittola, and T. Virtanen, “A multi-device dataset for urban acoustic scene classification,” inProceedings of the De- tection and Classification of Acoustic Scenes and Events 2018 Workshop (DCASE2018), November 2018, pp. 9–13
2018
-
[10]
Cochlscene: Acquisition of acoustic scene data using crowdsourcing,
I.-Y . Jeong and J. Park, “Cochlscene: Acquisition of acoustic scene data using crowdsourcing,” in2022 Asia-Pacific Signal and Information Processing Association Annual Summit and Confer- ence (APSIPA ASC). IEEE, 2022, pp. 17–21
2022
-
[11]
J. Bai, M. Wang, H. Liu, H. Yin, Y . Jia, S. Huang, Y . Du, D. Zhang, D. Shi, W.-S. Ganet al., “Description on ieee icme 2024 grand challenge: Semi-supervised acoustic scene classifica- tion under domain shift,”arXiv preprint arXiv:2402.02694, 2024
arXiv 2024
-
[12]
Receptive field regularization techniques for audio classification and tagging with deep convolutional neural networks,
K. Koutini, H. Eghbal-zadeh, and G. Widmer, “Receptive field regularization techniques for audio classification and tagging with deep convolutional neural networks,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 1987–2000, 2021
1987
-
[13]
TF-SepNet: An efficient 1D kernel design in CNNs for low-complexity acoustic scene classification,
Y . Cai, P. Zhang, and S. Li, “TF-SepNet: An efficient 1D kernel design in CNNs for low-complexity acoustic scene classification,” in2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 821–825
2024
-
[14]
Distilling the knowledge of transformers and CNNs with CP-mobile,
F. Schmid, T. Morocutti, S. Masoudian, K. Koutini, and G. Wid- mer, “Distilling the knowledge of transformers and CNNs with CP-mobile,” inProceedings of the 8th Detection and Classification of Acoustic Scenes and Events 2023 Workshop (DCASE2023), Tampere, Finland, September 2023, pp. 161–165
2023
-
[15]
Multiview embeddings for sound- scape classification,
D. V . Devalraju and P. Rajan, “Multiview embeddings for sound- scape classification,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 1197–1206, 2022
2022
-
[16]
The apsipa asc 2025 grand challenge on city and time-aware semi-supervised acoustic scene classification: Summary and results,
J. Bai, M. Wang, H. Liu, B. Xiang, Y . Liu, J. Chen, D. Shi, M. D. Plumbley, S. Rahardja, and W.-S. Gan, “The apsipa asc 2025 grand challenge on city and time-aware semi-supervised acoustic scene classification: Summary and results,” in2025 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC). IEEE, 2025, pp...
2025
-
[17]
Towards joint sound scene and polyphonic sound event recognition,
H. L. Bear, I. Nolasco, and E. Benetos, “Towards joint sound scene and polyphonic sound event recognition,” inProceedings of the Conference of the International Speech Communication As- sociation (INTERSPEECH). ISCA, 2019, pp. 4594–4598
2019
-
[18]
Joint analysis of sound events and acoustic scenes using multitask learning,
N. Tonami, K. Imoto, R. Yamanishi, and Y . Yamashita, “Joint analysis of sound events and acoustic scenes using multitask learning,”IEICE TRANSACTIONS on Information and Systems, vol. 104, no. 2, pp. 294–301, 2021
2021
-
[19]
Cooperative scene-event modelling for acoustic scene classification,
Y . Hou, B. Kang, A. Mitchell, W. Wang, J. Kang, and D. Bot- teldooren, “Cooperative scene-event modelling for acoustic scene classification,”IEEE/ACM transactions on audio, speech, and language processing, vol. 32, pp. 68–82, 2023
2023
-
[20]
Acoustic scene clas- sification across cities and devices via feature disentanglement,
Y . Tan, H. Ai, S. Li, and M. D. Plumbley, “Acoustic scene clas- sification across cities and devices via feature disentanglement,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 32, pp. 1286–1297, 2024
2024
-
[21]
Acoustic scene classifi- cation in DCASE 2020 challenge: Generalization across devices and low complexity solutions,
T. Heittola, A. Mesaros, and T. Virtanen, “Acoustic scene classifi- cation in DCASE 2020 challenge: Generalization across devices and low complexity solutions,” inProceedings of the Detection and Classification of Acoustic Scenes and Events 2020 Workshop (DCASE2020), 2020, pp. 56–60
2020
-
[22]
P. Zhang, Y . Liu, R. Sang, Z. Li, Y . Cai, Y . Tan, and S. Li, “Ddsc: Dynamic dual-signal curriculum for data-efficient acous- tic scene classification under domain shift,”arXiv preprint arXiv:2510.17345, 2025
arXiv 2025
-
[23]
Fsd50k: an open dataset of human-labeled sound events,
E. Fonseca, X. Favory, J. Pons, F. Font, and X. Serra, “Fsd50k: an open dataset of human-labeled sound events,”IEEE/ACM Trans- actions on Audio, Speech, and Language Processing, vol. 30, pp. 829–852, 2021
2021
-
[24]
BEATs: Audio pre-training with acoustic to- kenizers,
S. Chen, Y . Wu, C. Wang, S. Liu, D. Tompkins, Z. Chen, W. Che, X. Yu, and F. Wei, “BEATs: Audio pre-training with acoustic to- kenizers,” inProceedings of the 40th International Conference on Machine Learning (ICML). PMLR, 2023, pp. 5178–5193
2023
-
[25]
Broadcasted Residual Learning for Efficient Keyword Spotting,
B. Kim, S. Chang, J. Lee, and D. Sung, “Broadcasted Residual Learning for Efficient Keyword Spotting,” inProceedings of the Conference of the International Speech Communication Associa- tion (INTERSPEECH). ISCA, 2021, pp. 4538–4542
2021
-
[26]
Sntl-ntu dcase25 submission: Acoustic scene classification using CNN-GRU model without knowledge distillation,
E.-L. Tan, J. W. Yeow, S. Peksi, H. Li, Z. Yang, and W.-S. Gan, “Sntl-ntu dcase25 submission: Acoustic scene classification using CNN-GRU model without knowledge distillation,” DCASE2025 Challenge, Tech. Rep., May 2025
2025
-
[27]
Leveraging self-supervised audio representations for data-efficient acoustic scene classification,
Y . Cai, S. Li, and X. Shao, “Leveraging self-supervised audio representations for data-efficient acoustic scene classification,” inProceedings of the Detection and Classification of Acoustic Scenes and Events 2024 Workshop (DCASE2024), October 2024, pp. 21–25
2024
-
[28]
Effi- cient training of audio transformers with patchout,
K. Koutini, J. Schl ¨uter, H. Eghbal-zadeh, and G. Widmer, “Effi- cient training of audio transformers with patchout,” inProceed- ings of the Conference of the International Speech Communica- tion Association (INTERSPEECH). ISCA, 2022, pp. 2753–2757
2022
-
[29]
Knowl- edge distillation from transformers for low-complexity acous- tic scene classification,
F. Schmid, S. Masoudian, K. Koutini, and G. Widmer, “Knowl- edge distillation from transformers for low-complexity acous- tic scene classification,” inProceedings of the Detection and Classification of Acoustic Scenes and Events 2022 Workshop (DCASE2022), 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.