Learning Predictive Control with Deep Koopman Operators for Autonomous Vehicle Motion Planning
Pith reviewed 2026-06-27 19:27 UTC · model grok-4.3
The pith
The LPC framework uses deep Koopman operators to produce closed-loop state-feedback policies for real-time autonomous vehicle motion planning under nonconvex constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The LPC framework yields a closed-loop state-feedback policy within each prediction interval through receding-horizon actor-critic learning, enabling efficient, safety-aware policy learning under nonconvex environmental constraints, by using a deep-Koopman-based predictor to lift the nonlinear and uncertain vehicle dynamics into an interpretable linear observable space in a data-driven manner and by embedding convex local surrogate representations of obstacles along with their potential-field functions.
What carries the argument
Deep-Koopman-based predictor that lifts nonlinear vehicle dynamics to a linear observable space, combined with receding-horizon actor-critic learning that directly embeds potential-field safety functions derived from convex obstacle surrogates.
If this is right
- Closed-loop policies are computed within each interval without solving full nonlinear optimizations at runtime.
- Nonconvex environmental constraints are handled through embedded convex surrogates and potential fields for safety.
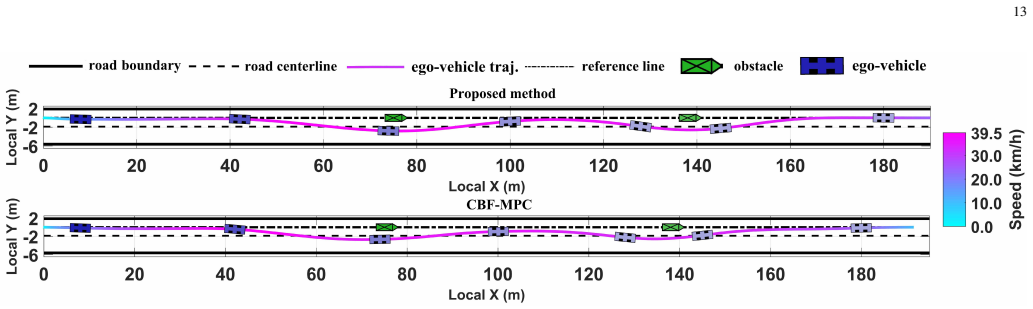
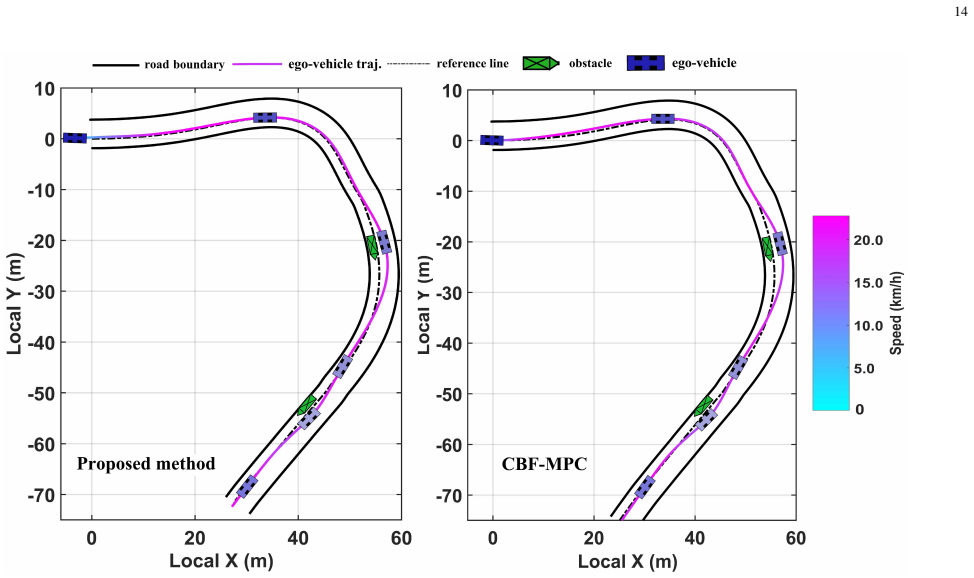
- The method achieves improved computational efficiency and driving comfort relative to CBF-MPC and LMPCC in obstacle-avoidance scenarios.
- Data-driven lifting allows the framework to operate without precise first-principles models of vehicle dynamics.
Where Pith is reading between the lines
- The linear lifted representation may permit direct application of linear control theory tools for stability or robustness analysis within the prediction horizon.
- The framework could extend to other robotic platforms that face nonlinear dynamics and nonconvex constraints, such as manipulators or drones.
- Embedding uncertainty estimates from the Koopman lifting step might further improve policy robustness in highly variable environments.
- The approach reduces dependence on online optimization solvers, potentially enabling deployment on lower-power embedded hardware.
Load-bearing premise
The deep-Koopman-based predictor can accurately lift the nonlinear and uncertain vehicle dynamics into an interpretable linear observable space in a data-driven manner.
What would settle it
A real-world driving test on the HongQi-EHS3 where the trained deep Koopman predictor produces a policy that collides with obstacles or violates constraints when vehicle dynamics differ from the training distribution.
Figures











read the original abstract
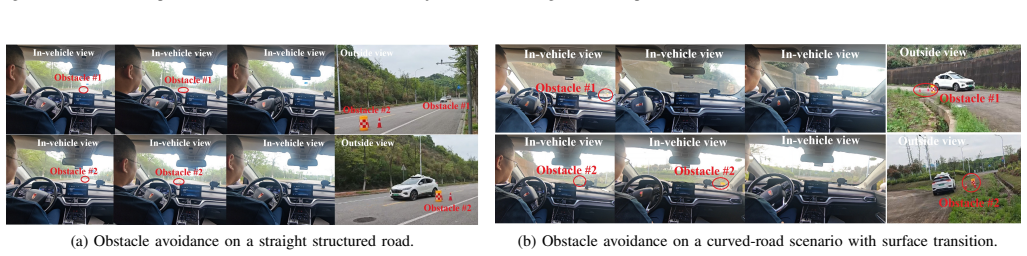
Model Predictive Control (MPC) is widely used for autonomous-vehicle (AV) motion planning, but its real-time applicability is often limited by the need for accurate models and online solution of nonlinear, nonconvex optimization problems in dynamic road environments. Actor-critic reinforcement learning offers a promising alternative for online policy generation, yet its policy-learning process often lacks explicit control-theoretic structure. This article proposes a learning predictive control (LPC) framework with deep Koopman operators for efficient real-time motion planning under nonconvex constraints. To address nonlinear and uncertain vehicle dynamics, a deep-Koopman-based predictor is used to lift the system into an interpretable linear observable space in a data-driven manner. Unlike traditional MPC, which computes open-loop control sequences, the proposed LPC framework yields a closed-loop state-feedback policy within each prediction interval through receding-horizon actor-critic learning. To ensure safety under nonconvex environmental constraints, LPC constructs convex local surrogate representations of obstacles and defines corresponding potential-field functions. These functions and their gradients are directly embedded into the actor-critic structure, enabling efficient, safety-aware policy learning. Extensive simulations and real-world experiments on the HongQi-EHS3 platform demonstrate favorable performance in diverse obstacle-avoidance scenarios in terms of safety, computational efficiency, and driving comfort, compared with benchmark methods such as CBF-MPC and LMPCC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Learning Predictive Control (LPC) framework that integrates deep Koopman operators to lift nonlinear and uncertain vehicle dynamics into a linear observable space, combined with receding-horizon actor-critic learning to generate closed-loop state-feedback policies for AV motion planning. Safety under nonconvex constraints is addressed by constructing convex local obstacle surrogates and embedding corresponding potential-field functions and gradients directly into the actor-critic structure. The approach is positioned as more efficient than traditional nonlinear MPC for real-time use, with claims of favorable performance in safety, computational efficiency, and comfort demonstrated via extensive simulations and real-world experiments on the HongQi-EHS3 platform against benchmarks including CBF-MPC and LMPCC.
Significance. If the deep Koopman lifting accurately captures relevant dynamics and uncertainties over prediction horizons, and if the experimental claims are substantiated with quantitative evidence, the work could provide a structured hybrid method that combines data-driven linearization with explicit safety constraints in policy learning, potentially improving real-time applicability for AV planning compared to pure MPC or RL approaches. The direct embedding of potential fields into the actor-critic is a constructive element that merits attention.
major comments (2)
- [Abstract] Abstract: The central claim that 'extensive simulations and real-world experiments demonstrate favorable performance' in safety, efficiency, and comfort is load-bearing for the paper's contribution, yet the abstract provides no quantitative metrics, error bars, specific comparison values, or statistical details to support superiority over CBF-MPC and LMPCC; this absence prevents verification that the data actually backs the claims.
- [Abstract] Abstract (deep-Koopman predictor description): The framework's reliance on the deep-Koopman-based predictor to 'lift the system into an interpretable linear observable space in a data-driven manner' for use inside the receding-horizon actor-critic is a load-bearing assumption for both efficiency and safety claims, but no validation details (e.g., prediction error over horizons, handling of tire forces or friction variation) are supplied to address potential error accumulation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of results and validation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'extensive simulations and real-world experiments demonstrate favorable performance' in safety, efficiency, and comfort is load-bearing for the paper's contribution, yet the abstract provides no quantitative metrics, error bars, specific comparison values, or statistical details to support superiority over CBF-MPC and LMPCC; this absence prevents verification that the data actually backs the claims.
Authors: We agree that the abstract would be strengthened by the inclusion of representative quantitative metrics. In the revised manuscript we will add concise highlights drawn from the simulation and experimental results (e.g., average computation time, safety-margin statistics, and comfort indices relative to CBF-MPC and LMPCC) while preserving the abstract's brevity. revision: yes
-
Referee: [Abstract] Abstract (deep-Koopman predictor description): The framework's reliance on the deep-Koopman-based predictor to 'lift the system into an interpretable linear observable space in a data-driven manner' for use inside the receding-horizon actor-critic is a load-bearing assumption for both efficiency and safety claims, but no validation details (e.g., prediction error over horizons, handling of tire forces or friction variation) are supplied to address potential error accumulation.
Authors: The manuscript contains closed-loop validation of the Koopman predictor through the overall planning performance; however, we acknowledge that explicit one-step and multi-step prediction-error statistics (including sensitivity to tire-force and friction variations) are not summarized in the abstract. We will add a short clause referencing these metrics from the experimental sections. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The abstract and description present a data-driven deep-Koopman lifting step followed by receding-horizon actor-critic policy learning and potential-field safety embedding. No equations, fitted parameters renamed as predictions, self-citations, or uniqueness theorems are supplied that would reduce any claimed result to its own inputs by construction. The method is described as relying on standard learning from data plus external benchmarks (CBF-MPC, LMPCC) and real-world experiments, making the chain self-contained against external validation rather than internally tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Receding-horizon reinforcement learning approach for kinodynamic motion planning of autonomous vehicles.IEEE Transactions on Intelligent Vehicles, 7(3):556–568, 2022
Xinglong Zhang, Yan Jiang, Yang Lu, and Xin Xu. Receding-horizon reinforcement learning approach for kinodynamic motion planning of autonomous vehicles.IEEE Transactions on Intelligent Vehicles, 7(3):556–568, 2022
2022
-
[2]
The convex feasible set algorithm for real time optimization in motion planning
Changliu Liu, Chung-Yen Lin, and Masayoshi Tomizuka. The convex feasible set algorithm for real time optimization in motion planning. SIAM Journal on Control and optimization, 56(4):2712–2733, 2018
2018
-
[3]
A survey of the state- of-the-art localization techniques and their potentials for autonomous vehicle applications.IEEE Internet of Things Journal, 5:829–846, 2018
Sampo Kuutti, Saber Fallah, Konstantinos Katsaros, Mehrdad Dianati, Francis Mccullough, and Alexandros Mouzakitis. A survey of the state- of-the-art localization techniques and their potentials for autonomous vehicle applications.IEEE Internet of Things Journal, 5:829–846, 2018
2018
-
[4]
Autonomous driving motion planning with constrained iterative lqr.IEEE Transactions on Intelligent Vehicles, 4(2):244–254, 2019
Jianyu Chen, Wei Zhan, and Masayoshi Tomizuka. Autonomous driving motion planning with constrained iterative lqr.IEEE Transactions on Intelligent Vehicles, 4(2):244–254, 2019
2019
-
[5]
Safety-critical model predictive control with discrete-time control barrier function
Jun Zeng, Bike Zhang, and Koushil Sreenath. Safety-critical model predictive control with discrete-time control barrier function. In2021 American Control Conference (ACC), pages 3882–3889. IEEE, 2021
2021
-
[6]
Model predictive contouring control for collision avoidance in unstructured dy- namic environments.IEEE Robotics and Automation Letters, 4(4):4459– 4466, 2019
Bruno Brito, Boaz Floor, Laura Ferranti, and Javier Alonso-Mora. Model predictive contouring control for collision avoidance in unstructured dy- namic environments.IEEE Robotics and Automation Letters, 4(4):4459– 4466, 2019
2019
-
[7]
Multi-kernel online reinforcement learning for path tracking control of intelligent vehicles.IEEE Transactions on Systems, Man, and Cybernetics: Systems, 51(11):6962–6975, 2020
Jiahang Liu, Zhenhua Huang, Xin Xu, Xinglong Zhang, Shiliang Sun, and Dazi Li. Multi-kernel online reinforcement learning for path tracking control of intelligent vehicles.IEEE Transactions on Systems, Man, and Cybernetics: Systems, 51(11):6962–6975, 2020
2020
-
[8]
Lateral control for autonomous land vehicles via dual heuristic programming
Zhenhua Huang, Chuanqiang Lian, Xin Xu, and Jian Wang. Lateral control for autonomous land vehicles via dual heuristic programming. International Journal of Robotics and Automation, 31(6), 2016
2016
-
[9]
Xinglong Zhang, Jiahang Liu, Xin Xu, Shuyou Yu, and Hong Chen. Robust learning-based predictive control for discrete-time nonlinear sys- tems with unknown dynamics and state constraints.IEEE Transactions on Systems, Man, and Cybernetics: Systems, 52(12):7314–7327, 2022
2022
-
[10]
Functional nonlinear model predictive control based on adaptive dynamic program- ming.IEEE transactions on Cybernetics, 49(12):4206–4218, 2018
Lu Dong, Jun Yan, Xin Yuan, Haibo He, and Changyin Sun. Functional nonlinear model predictive control based on adaptive dynamic program- ming.IEEE transactions on Cybernetics, 49(12):4206–4218, 2018
2018
-
[11]
Linear predictors for nonlinear dynamical systems: Koopman operator meets model predictive control.Automatica, 93:149–160, 2018
Milan Korda and Igor Mezi ´c. Linear predictors for nonlinear dynamical systems: Koopman operator meets model predictive control.Automatica, 93:149–160, 2018
2018
-
[12]
Koopman operator applications in signalized traffic systems.IEEE Transactions on Intelligent Transportation Systems, 23(4):3214–3225, 2020
Esther Ling, Liyuan Zheng, Lillian J Ratliff, and Samuel Coogan. Koopman operator applications in signalized traffic systems.IEEE Transactions on Intelligent Transportation Systems, 23(4):3214–3225, 2020
2020
-
[13]
Physically analyzable ai-based nonlinear platoon dynamics modeling during traffic oscillation: A koopman approach.IEEE Transactions on Intelligent Transportation Systems, 2025
Kexin Tian, Haotian Shi, Yang Zhou, and Sixu Li. Physically analyzable ai-based nonlinear platoon dynamics modeling during traffic oscillation: A koopman approach.IEEE Transactions on Intelligent Transportation Systems, 2025
2025
-
[14]
Differential high order control barrier function- based safe reinforcement learning.IEEE Robotics and Automation Letters, 2025
Xiangyu Kong, Yuanqing Xia, Zhongqi Sun, Di-Hua Zhai, Yunshan Deng, and Sihua Zhang. Differential high order control barrier function- based safe reinforcement learning.IEEE Robotics and Automation Letters, 2025
2025
-
[15]
Cbf-based hierar- chical quadratic programs with guaranteed feasibility for safety-critical systems.IEEE Transactions on Automation Science and Engineering, 22:23687–23699, 2025
Junjun Xie, Liang Hu, Yunzhe Tan, and Jun Yang. Cbf-based hierar- chical quadratic programs with guaranteed feasibility for safety-critical systems.IEEE Transactions on Automation Science and Engineering, 22:23687–23699, 2025
2025
-
[16]
Safe and fast tracking on a robot manipulator: Robust MPC and neural network control.IEEE Robotics and Automation Letters, 5(2):3050–3057, 2020
Jakob Nubert, Jonas K ¨ohler, Vincent Berenz, Klaus L ¨utjens, and J ¨org Raisch. Safe and fast tracking on a robot manipulator: Robust MPC and neural network control.IEEE Robotics and Automation Letters, 5(2):3050–3057, 2020
2020
-
[17]
MPC-based haptic shared steering system: A driver modeling approach for symbiotic driving
Ander M Lazcano, Tianyi Niu, Xabier C Akutain, Mercedes Delgado, Oihana Otaegui, Unai Jauregi, and et al. MPC-based haptic shared steering system: A driver modeling approach for symbiotic driving. IEEE/ASME Transactions on Mechatronics, 26(3):1201–1211, 2021
2021
-
[18]
A potential field-based model predictive path-planning con- troller for autonomous road vehicles.IEEE Transactions on Intelligent Transportation Systems, 18(5):1255–1267, 2016
Yadollah Rasekhipour, Amir Khajepour, Shih-Ken Chen, and Bakhtiar Litkouhi. A potential field-based model predictive path-planning con- troller for autonomous road vehicles.IEEE Transactions on Intelligent Transportation Systems, 18(5):1255–1267, 2016
2016
-
[19]
Lateral vehicle trajectory optimization using constrained linear time-varying MPC
Benjamin Gutjahr, Lutz Gr ¨oll, and Moritz Werling. Lateral vehicle trajectory optimization using constrained linear time-varying MPC. IEEE Transactions on Intelligent Transportation Systems, 18(6):1586– 1595, 2016
2016
-
[20]
Path planning and tracking for vehicle collision avoidance based on model predictive control with multiconstraints.IEEE Transactions on Vehicular Technology, 66(2):952–964, 2016
Jie Ji, Amir Khajepour, Wael William Melek, and Yanjun Huang. Path planning and tracking for vehicle collision avoidance based on model predictive control with multiconstraints.IEEE Transactions on Vehicular Technology, 66(2):952–964, 2016
2016
-
[21]
Qianxiao Li, Felix Dietrich, Erik M Bollt, and Ioannis G Kevrekidis. Ex- tended dynamic mode decomposition with dictionary learning: A data- driven adaptive spectral decomposition of the Koopman operator.Chaos: An Interdisciplinary Journal of Nonlinear Science, 27(10):103111, 2017
2017
-
[22]
Witherden, and Mykel J
Jeremy Morton, Freddie D. Witherden, and Mykel J. Kochenderfer. Deep variational koopman models: Inferring koopman observations for uncertainty-aware dynamics modeling and control. InProceedings of the 28th International Joint Conference on Artificial Intelligence (IJCAI), IJCAI’19, page 3173–3179. AAAI Press, 2019. 15
2019
-
[23]
Joglekar et al
A. Joglekar et al. Data-driven modeling and experimental validation of autonomous vehicles using koopman operator. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 9442–9447, Detroit, MI, USA, 2023
2023
-
[24]
Deep koopman traffic modeling for freeway ramp metering.IEEE Transactions on Intelligent Transportation Systems, 24(6):6001–6013, 2023
Chuanye Gu, Tao Zhou, and Changzhi Wu. Deep koopman traffic modeling for freeway ramp metering.IEEE Transactions on Intelligent Transportation Systems, 24(6):6001–6013, 2023
2023
-
[25]
Transformers for modeling physical systems.Neural Networks, 146:272–289, 2022
Nicholas Geneva and Nicholas Zabaras. Transformers for modeling physical systems.Neural Networks, 146:272–289, 2022
2022
-
[26]
Characterization of groundwater contamination: A transformer-based deep learning model.Advances in Water Resources, 164:104217, 2022
Tao Bai and Pejman Tahmasebi. Characterization of groundwater contamination: A transformer-based deep learning model.Advances in Water Resources, 164:104217, 2022
2022
-
[27]
Deepkoco: Efficient latent planning with a task-relevant koopman rep- resentation
Bas van der Heijden, Laura Ferranti, Jens Kober, and Robert Babu ˇska. Deepkoco: Efficient latent planning with a task-relevant koopman rep- resentation. In2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), page 183–189. IEEE Press, 2021
2021
-
[28]
Near- optimal rapid MPC using neural networks: A primal-dual policy learn- ing framework.IEEE Transactions on Control Systems Technology, 29(5):2102–2114, 2020
Xiaojing Zhang, Monimoy Bujarbaruah, and Francesco Borrelli. Near- optimal rapid MPC using neural networks: A primal-dual policy learn- ing framework.IEEE Transactions on Control Systems Technology, 29(5):2102–2114, 2020
2020
-
[29]
Autonomous driving using linear model predictive control with a Koopman operator based bilinear vehicle model.IFAC-PapersOnLine, 55(24):254–259, 2022
Siyuan Yu, Congkai Shen, and Tulga Ersal. Autonomous driving using linear model predictive control with a Koopman operator based bilinear vehicle model.IFAC-PapersOnLine, 55(24):254–259, 2022
2022
-
[30]
A review of end-to-end autonomous driving in urban environments.IEEE Access, 10:75296–75311, 2022
Daniel Coelho and Miguel Oliveira. A review of end-to-end autonomous driving in urban environments.IEEE Access, 10:75296–75311, 2022
2022
-
[31]
Deep reinforcement learning for autonomous driving: A survey.IEEE Transactions on Intelligent Transportation Systems, 23(6):4909–4926, 2021
B Ravi Kiran, Ibrahim Sobh, Victor Talpaert, Patrick Mannion, Ahmad A Al Sallab, Senthil Yogamani, and Patrick P ´erez. Deep reinforcement learning for autonomous driving: A survey.IEEE Transactions on Intelligent Transportation Systems, 23(6):4909–4926, 2021
2021
-
[32]
Real- time drift-driving control for an autonomous vehicle: Learning from nonlinear model predictive control via a deep neural network.Electron- ics, 11(17):2651, 2022
Taekgyu Lee, Dongyoon Seo, Jinyoung Lee, and Yeonsik Kang. Real- time drift-driving control for an autonomous vehicle: Learning from nonlinear model predictive control via a deep neural network.Electron- ics, 11(17):2651, 2022
2022
-
[33]
Accept synthetic objects as real: End-to-end training of attentive deep visuomotor policies for manipulation in clutter
Pooya Abolghasemi and Ladislau B ¨ol¨oni. Accept synthetic objects as real: End-to-end training of attentive deep visuomotor policies for manipulation in clutter. In2020 IEEE International Conference on Robotics and Automation (ICRA), pages 6506–6512. IEEE, 2020
2020
-
[34]
End-to-end steering controller with cnn-based closed-loop feedback for autonomous vehicles
Junekyo Jhung, Il Bae, Jaeyoung Moon, Taewoo Kim, Jincheol Kim, and Shiho Kim. End-to-end steering controller with cnn-based closed-loop feedback for autonomous vehicles. In2018 IEEE Intelligent Vehicles Symposium (IV), pages 617–622. IEEE, 2018
2018
-
[35]
Mixgail: Autonomous driving using demonstrations with mixed qualities
Gunmin Lee, Dohyeong Kim, Wooseok Oh, Kyungjae Lee, and Songh- wai Oh. Mixgail: Autonomous driving using demonstrations with mixed qualities. In2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5425–5430. IEEE, 2020
2020
-
[37]
arXiv preprint arXiv:2307.07162
Daocheng Fu, Xin Li, Licheng Wen, Min Dou, Pinlong Cai, Botian Shi, and Yu Qiao. Drive as you speak: Enabling human-like interaction with large language models in autonomous vehicles.arXiv preprint arXiv:2307.07162, 2023
-
[38]
Model-free deep reinforcement learning for urban autonomous driving
Jianyu Chen, Bodi Yuan, and Masayoshi Tomizuka. Model-free deep reinforcement learning for urban autonomous driving. In2019 IEEE Intelligent Transportation Systems Conference (ITSC), pages 2765–2771. IEEE, 2019
2019
-
[39]
Uncertainty-aware model-based reinforcement learning: Methodology and application in autonomous driving.IEEE Transactions on Intelligent Vehicles, 8(1):194–203, 2022
Jingda Wu, Zhiyu Huang, and Chen Lv. Uncertainty-aware model-based reinforcement learning: Methodology and application in autonomous driving.IEEE Transactions on Intelligent Vehicles, 8(1):194–203, 2022
2022
-
[40]
Interpretable end-to-end urban autonomous driving with latent deep reinforcement learning.IEEE Transactions on Intelligent Transportation Systems, 2021
Jianyu Chen, Shengbo Eben Li, and Masayoshi Tomizuka. Interpretable end-to-end urban autonomous driving with latent deep reinforcement learning.IEEE Transactions on Intelligent Transportation Systems, 2021
2021
-
[41]
Self-learning cruise control using kernel-based least squares policy iter- ation.IEEE Transactions on Control Systems Technology, 22(3):1078– 1087, 2013
Jian Wang, Xin Xu, Daxue Liu, Zhenping Sun, and Qingyang Chen. Self-learning cruise control using kernel-based least squares policy iter- ation.IEEE Transactions on Control Systems Technology, 22(3):1078– 1087, 2013
2013
-
[42]
An approxi- mate dynamic programming approach for path following control of an autonomous vehicle
Kun Zhao, Jian Wang, Xin Xu, and Zhenhua Huang. An approxi- mate dynamic programming approach for path following control of an autonomous vehicle. InProceeding of the 11th World Congress on Intelligent Control and Automation (WCICA), pages 1998–2004. IEEE, 2014
1998
-
[43]
Parameterized batch reinforcement learning for longitudinal control of autonomous land vehicles.IEEE Transactions on Systems, Man, and Cybernetics: Systems, 49(4):730–741, 2019
Zhenhua Huang, Xin Xu, Haibo He, Jun Tan, and Zhenping Sun. Parameterized batch reinforcement learning for longitudinal control of autonomous land vehicles.IEEE Transactions on Systems, Man, and Cybernetics: Systems, 49(4):730–741, 2019
2019
-
[44]
Learning-based predictive control for discrete-time nonlinear systems with stochastic disturbances.IEEE Transactions on Neural Networks and Learning Systems, 29(12):6202–6213, 2018
Xin Xu, Hong Chen, Chuanqiang Lian, and Dazi Li. Learning-based predictive control for discrete-time nonlinear systems with stochastic disturbances.IEEE Transactions on Neural Networks and Learning Systems, 29(12):6202–6213, 2018
2018
-
[45]
Deep neural networks with Koopman operators for modeling and control of autonomous vehicles.IEEE Transactions on Intelligent Vehicles, 8(1):135–146, 2023
Yongqian Xiao, Xinglong Zhang, Xin Xu, Xueqing Liu, and Jiahang Liu. Deep neural networks with Koopman operators for modeling and control of autonomous vehicles.IEEE Transactions on Intelligent Vehicles, 8(1):135–146, 2023
2023
-
[46]
Model-based safe reinforcement learning with time-varying constraints: Applications to intelligent vehicles.IEEE Transactions on Industrial Electronics, 71(10):12744–12753, 2024
Xinglong Zhang, Yaoqian Peng, Biao Luo, Wei Pan, Xin Xu, and Haibin Xie. Model-based safe reinforcement learning with time-varying constraints: Applications to intelligent vehicles.IEEE Transactions on Industrial Electronics, 71(10):12744–12753, 2024
2024
-
[47]
Toward scalable multirobot control: Fast policy learning in distributed mpc.IEEE Transactions on Robotics, 41:1491– 1512, 2025
Xinglong Zhang, Wei Pan, Cong Li, Xin Xu, Xiangke Wang, Ronghua Zhang, and Dewen Hu. Toward scalable multirobot control: Fast policy learning in distributed mpc.IEEE Transactions on Robotics, 41:1491– 1512, 2025. APPENDIX A. Learning Convergence in Each Prediction Interval In the following, we analyze the convergence of the policy learning procedure in ea...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.