AuditFraudBench: Benchmarking Audit Judgment in Detecting Fraudulent Misstatements
Pith reviewed 2026-06-27 18:47 UTC · model grok-4.3
The pith
AuditFraudBench shows that LLMs still struggle to detect fraudulent misstatements by combining financial figures with disclosure framing and restatement evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
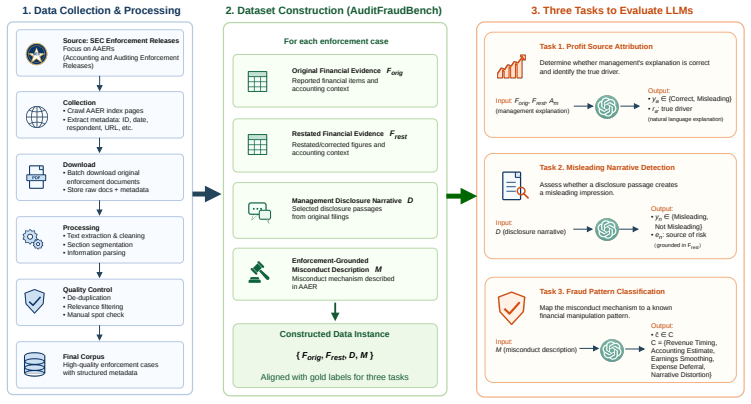
AuditFraudBench is constructed from authentic company filings and regulatory materials to create three tasks that require models to attribute reported profits to their actual sources, detect misleading narrative framing in MD&A disclosures, and classify misconduct into established fraud patterns using restatement evidence and AAERs; evaluations demonstrate that current LLMs cannot jointly reason over these elements.
What carries the argument
AuditFraudBench, an enforcement-grounded benchmark with three tasks built from original and restated filings plus AAERs.
Load-bearing premise
The three tasks built from filings and AAERs accurately represent the core challenges of professional audit judgment in spotting fraudulent misstatements.
What would settle it
A controlled experiment in which leading models achieve high accuracy across all three tasks when given the same original filings, restated filings, and AAER context without further training.
Figures
read the original abstract
Large language models (LLMs) have shown strong performance in financial analysis and surface-level factual error detection, yet their ability to identify fraudulent financial misinformation in audited corporate reporting remains underexplored. Existing financial and audit benchmarks mainly focus on factual verification, numerical reasoning, rule compliance, or audit workflows, but rarely evaluate misleading disclosure narratives or management explanations that obscure the true drivers of reported performance. We introduce AuditFraudBench, an enforcement-grounded benchmark constructed from authentic company filings and regulatory materials, including original and restated 10-K and 10-Q filings, structured financial statements, MD&A disclosures, and SEC Accounting and Auditing Enforcement Releases (AAERs). AuditFraudBench contains three tasks: Profit Source Attribution, Misleading Narrative Detection, and Fraud Pattern Classification, which evaluate whether models can identify the true source of reported performance, detect misleading disclosure framing, and classify misconduct mechanisms into known manipulation patterns. We evaluate GPT, DeepSeek, and Qwen series LLMs on the benchmark. Results show that both proprietary and open models still struggle to jointly reason over financial figures, disclosure framing, restatement evidence, and enforcement-grounded fraud mechanisms. AuditFraudBench provides a challenging testbed for audit-relevant, evidence-grounded evaluation of LLMs in financial reporting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AuditFraudBench, an enforcement-grounded benchmark for LLM evaluation on audit judgment in fraud detection. It is constructed from original and restated 10-K/10-Q filings, MD&A disclosures, and SEC AAERs, and comprises three tasks (Profit Source Attribution, Misleading Narrative Detection, Fraud Pattern Classification) that test joint reasoning over financial figures, disclosure framing, restatement evidence, and fraud mechanisms. Evaluations of GPT, DeepSeek, and Qwen series models are reported to show that current LLMs still struggle on these tasks.
Significance. If the benchmark construction and labeling are shown to be reliable, the work would provide a useful, domain-specific testbed that moves beyond existing financial benchmarks focused on factual verification or numerical reasoning. It could help surface limitations in LLMs' handling of misleading narratives and enforcement-grounded patterns, supporting future research on AI assistance for professional auditing.
major comments (3)
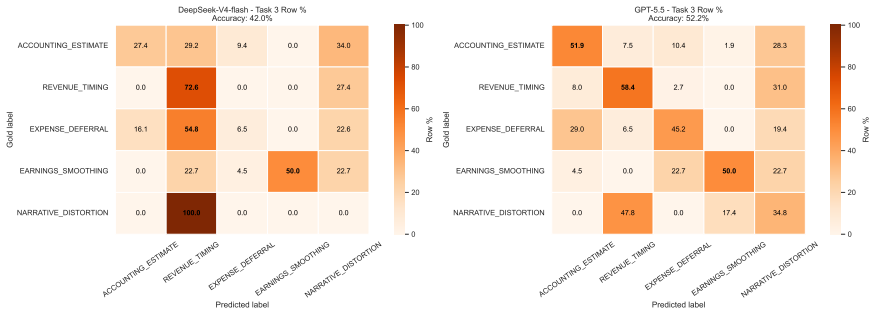
- [Abstract] Abstract: the central claim that 'results show that both proprietary and open models still struggle to jointly reason over financial figures, disclosure framing, restatement evidence, and enforcement-grounded fraud mechanisms' is stated without any quantitative performance scores, error analysis, or baseline comparisons, so the magnitude and nature of the reported struggle cannot be assessed from the provided description.
- [Benchmark construction (tasks and data)] Benchmark construction (tasks and data): the three tasks are described as constructed from original/restated filings plus AAERs, yet no details are supplied on how ground-truth labels were created, validated, or checked for inter-annotator agreement; this information is load-bearing for the claim that the tasks accurately capture core challenges of professional audit judgment.
- [Evaluation protocol] Evaluation protocol: the manuscript supplies no information on exact prompting strategies, few-shot settings, or how model outputs were scored against the enforcement-grounded labels, preventing replication or assessment of whether the headline result is robust.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments, which highlight important areas for clarification in our manuscript. We address each major comment below and will make revisions accordingly to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'results show that both proprietary and open models still struggle to jointly reason over financial figures, disclosure framing, restatement evidence, and enforcement-grounded fraud mechanisms' is stated without any quantitative performance scores, error analysis, or baseline comparisons, so the magnitude and nature of the reported struggle cannot be assessed from the provided description.
Authors: We agree that the abstract, as a high-level summary, does not include specific quantitative metrics. The detailed results, including performance scores for each model and task, error analyses, and comparisons, are presented in the Experiments and Results sections of the full manuscript. To improve the abstract's informativeness, we will revise it to incorporate key quantitative findings, such as the accuracy rates achieved by the evaluated models on the three tasks. revision: yes
-
Referee: [Benchmark construction (tasks and data)] Benchmark construction (tasks and data): the three tasks are described as constructed from original/restated filings plus AAERs, yet no details are supplied on how ground-truth labels were created, validated, or checked for inter-annotator agreement; this information is load-bearing for the claim that the tasks accurately capture core challenges of professional audit judgment.
Authors: The ground-truth labels in AuditFraudBench are derived directly from official SEC Accounting and Auditing Enforcement Releases (AAERs) and the corresponding original and restated filings, making them enforcement-grounded rather than subjectively annotated. We will add a new subsection in the benchmark construction section detailing the label extraction process from AAERs, including how specific fraud mechanisms and restatement evidence were mapped to task labels. Since the labels originate from regulatory enforcement actions, inter-annotator agreement is not applicable in the traditional sense; however, we will describe any cross-verification steps performed during dataset curation. revision: yes
-
Referee: [Evaluation protocol] Evaluation protocol: the manuscript supplies no information on exact prompting strategies, few-shot settings, or how model outputs were scored against the enforcement-grounded labels, preventing replication or assessment of whether the headline result is robust.
Authors: We acknowledge the lack of detailed evaluation protocol information in the current manuscript. In the revised version, we will expand the 'Experiments' section to include the exact prompting templates used, the number of few-shot examples (if any), the decoding parameters, and the precise method for scoring model outputs against the ground-truth labels, such as exact match or semantic similarity metrics. This will enable full replication of our results. revision: yes
Circularity Check
No significant circularity
full rationale
The paper constructs an empirical benchmark (AuditFraudBench) from external regulatory filings and AAERs, then reports direct LLM performance on three defined tasks. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the provided text. The central claims rest on data construction and evaluation rather than any derivation that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[3]
arXiv e-prints , pages=
FinRule-Bench: A Benchmark for Joint Reasoning over Financial Tables and Principles , author=. arXiv e-prints , pages=
-
[6]
Companion Proceedings of the ACM on Web Conference 2025 , pages=
Fin-fact: a benchmark dataset for multimodal financial fact-checking and explanation generation , author=. Companion Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[8]
Brainae Journal of Business, Sciences and Technology , volume=
Uncovering hidden financial risks: The tactics companies use to manipulate reporting and appear more profitable than they really are , author=. Brainae Journal of Business, Sciences and Technology , volume=
-
[10]
Contemporary topics in finance: A collection of literature surveys , pages=
Financial fraud: A literature review , author=. Contemporary topics in finance: A collection of literature surveys , pages=. 2019 , publisher=
2019
-
[11]
2010 , publisher=
Financial Shenanigans Third Edition , author=. 2010 , publisher=
2010
-
[12]
Merkl-Davies and D
D.M. Merkl-Davies and D. Merkl-Davies and N. Brennan. Discretionary Disclosure Strategies in Corporate Narratives: Incremental Information or Impression Management?. Journal of Accounting Literature. 2007
2007
-
[13]
2025 , url =
Introducing GPT-4.1 , author =. 2025 , url =
2025
-
[14]
Text summarization branches out , pages=
Rouge: A package for automatic evaluation of summaries , author=. Text summarization branches out , pages=
-
[15]
arXiv preprint arXiv:1904.09675 , year=
Bertscore: Evaluating text generation with bert , author=. arXiv preprint arXiv:1904.09675 , year=
Pith/arXiv arXiv 1904
-
[16]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
FinDVer: Explainable claim verification over long and hybrid-content financial documents , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[18]
2025 , eprint=
MultiFinBen: Benchmarking Large Language Models for Multilingual and Multimodal Financial Application , author=. 2025 , eprint=
2025
-
[20]
2026 , eprint=
Herculean: An Agentic Benchmark for Financial Intelligence , author=. 2026 , eprint=
2026
-
[21]
Mbonigaba Celestin. 2015. Uncovering hidden financial risks: The tactics companies use to manipulate reporting and appear more profitable than they really are. Brainae Journal of Business, Sciences and Technology, 1(2):527--537
2015
-
[22]
Junzhe Jiang, Chang Yang, Aixin Cui, Sihan Jin, Ruiyu Wang, Bo Li, Xiao Huang, Dongning Sun, and Xinrun Wang. 2025. Finmaster: A holistic benchmark for mastering full-pipeline financial workflows with llms. arXiv preprint arXiv:2505.13533
arXiv 2025
-
[23]
Yuechen Jiang, Zhiwei Liu, Yupeng Cao, Yueru He, Ziyang Xu, Chen Xu, Zhiyang Deng, Prayag Tiwari, Xi Chen, Alejandro Lopez-Lira, and 1 others. 2026. All that glisters is not gold: A benchmark for reference-free counterfactual financial misinformation detection. arXiv preprint arXiv:2601.04160
arXiv 2026
-
[24]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, pages 74--81
2004
-
[25]
Zhiwei Liu, Yupen Cao, Yuechen Jiang, Mohsinul Kabir, Polydoros Giannouris, Chen Xu, Ziyang Xu, Tianlei Zhu, Tariquzzaman Faisal, Triantafillos Papadopoulos, and 1 others. 2026. Same claim, different judgment: Benchmarking scenario-induced bias in multilingual financial misinformation detection. arXiv preprint arXiv:2601.05403
Pith/arXiv arXiv 2026
-
[26]
Merkl-Davies, D
D.M. Merkl-Davies, D. Merkl-Davies, and N. Brennan. 2007. Discretionary disclosure strategies in corporate narratives: Incremental information or impression management? Journal of Accounting Literature, 26:116--196
2007
-
[27]
Yuqi Nie, Yaxuan Kong, Xiaowen Dong, John M Mulvey, H Vincent Poor, Qingsong Wen, and Stefan Zohren. 2024. A survey of large language models for financial applications: Progress, prospects and challenges. arXiv preprint arXiv:2406.11903
arXiv 2024
-
[28]
OpenAI . 2025. https://openai.com/index/gpt-4-1/ Introducing gpt-4.1 . Official OpenAI announcement for the GPT-4.1 model family
2025
-
[29]
Xueqing Peng, Lingfei Qian, Yan Wang, Ruoyu Xiang, Yueru He, Yang Ren, Mingyang Jiang, Vincent Jim Zhang, Yuqing Guo, Jeff Zhao, Huan He, Yi Han, Yun Feng, Yuechen Jiang, Yupeng Cao, Haohang Li, Yangyang Yu, Xiaoyu Wang, Penglei Gao, and 28 others. 2025. https://arxiv.org/abs/2506.14028 Multifinben: Benchmarking large language models for multilingual and ...
arXiv 2025
-
[30]
Xueqing Peng, Zhuohan Xie, Yupeng Cao, Haohang Li, Lingfei Qian, Yan Wang, Vincent Jim Zhang, Huan He, Xuguang Ai, Linhai Ma, Ruoyu Xiang, Yueru He, Yi Han, Shuyao Wang, Yuqing Guo, Mingyang Jiang, Yilun Zhao, Youzhong Dong, Xiaoyu Wang, and 44 others. 2026. https://arxiv.org/abs/2605.14355 Herculean: An agentic benchmark for financial intelligence . Prep...
Pith/arXiv arXiv 2026
-
[31]
Aman Rangapur, Haoran Wang, Ling Jian, and Kai Shu. 2025. Fin-fact: a benchmark dataset for multimodal financial fact-checking and explanation generation. In Companion Proceedings of the ACM on Web Conference 2025, pages 785--788
2025
-
[32]
Arjan Reurink. 2019. Financial fraud: A literature review. Contemporary topics in finance: A collection of literature surveys, pages 79--115
2019
-
[33]
Howard M Schilit and Jeremy Perler. 2010. Financial Shenanigans Third Edition. McGraw-Hill
2010
-
[34]
Rishab Sharma, Iman Saberi, Elham Alipour, Jie JW Wu, and Fatemeh Fard. 2025. Fiscal: Financial synthetic claim-document augmented learning for efficient fact-checking. arXiv preprint arXiv:2511.19671
arXiv 2025
-
[35]
Arun Vignesh Malarkkan, Manan Roy Choudhury, Guangwei Zhang, Vivek Gupta, Qingyun Wang, Yanjie Fu, and Denghui Zhang. 2026. Finrule-bench: A benchmark for joint reasoning over financial tables and principles. arXiv e-prints, pages arXiv--2603
2026
-
[36]
Rushi Wang, Jiateng Liu, Weijie Zhao, Shenglan Li, and Denghui Zhang. 2025 a . Automating financial statement audits with large language models. arXiv preprint arXiv:2506.17282
arXiv 2025
-
[37]
Yan Wang, Keyi Wang, Shanshan Yang, Jaisal Patel, Jeff Zhao, Fengran Mo, Xueqing Peng, Lingfei Qian, Jimin Huang, Guojun Xiong, and 1 others. 2025 b . Finauditing: A financial taxonomy-structured multi-document benchmark for evaluating llms. arXiv preprint arXiv:2510.08886
Pith/arXiv arXiv 2025
-
[38]
Qianqian Xie, Weiguang Han, Zhengyu Chen, Ruoyu Xiang, Xiao Zhang, Yueru He, Mengxi Xiao, Dong Li, Yongfu Dai, Duanyu Feng, Yijing Xu, Haoqiang Kang, Ziyan Kuang, Chenhan Yuan, Kailai Yang, Zheheng Luo, Tianlin Zhang, Zhiwei Liu, Guojun Xiong, and 15 others. 2024. https://doi.org/10.52202/079017-3033 Finben: A holistic financial benchmark for large langua...
-
[39]
Yilun Zhao, Yitao Long, Tintin Jiang, Chengye Wang, Weiyuan Chen, Hongjun Liu, Xiangru Tang, Yiming Zhang, Chen Zhao, and Arman Cohan. 2024. Findver: Explainable claim verification over long and hybrid-content financial documents. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 14739--14752
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.