SPA: A SQL-Plan-Aware Reinforcement Learning Framework for Query Rewriting with LLMs
Pith reviewed 2026-06-27 17:44 UTC · model grok-4.3
The pith
Physical execution plan feedback lets LLMs rewrite SQL queries to cut runtime more reliably than rules or text-only prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
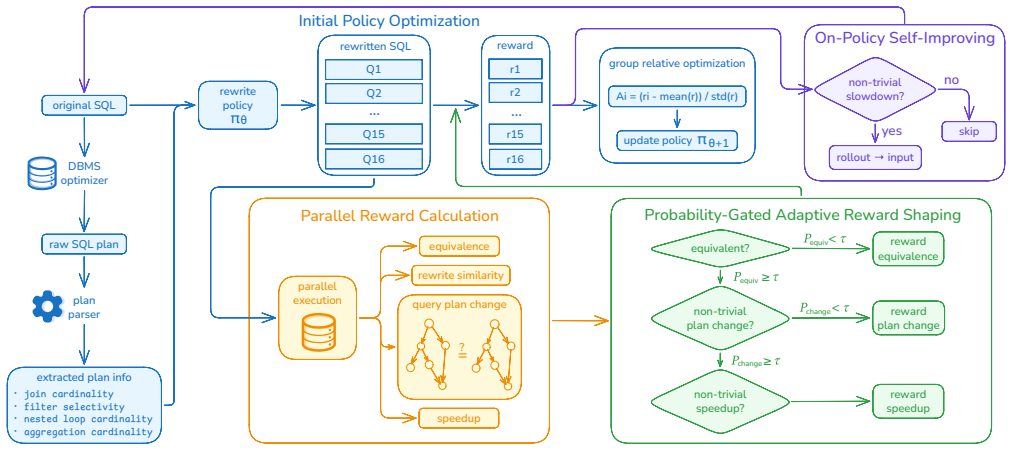
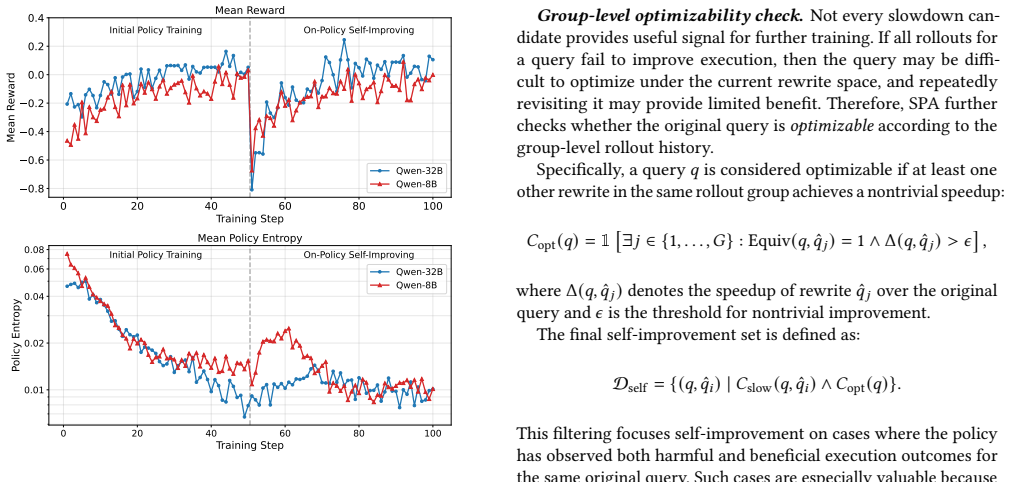
SPA formulates rewriting as a policy optimization problem and extends GRPO with rewards spanning semantic equivalence, textual rewrite distance, physical-plan divergence, and runtime speedup; Probability-Gated Adaptive Reward Shaping unlocks higher-level rewards only after a rollout group masters lower-level objectives, while on-policy self-improvement recycles slowdown rewrites as targeted signals, yielding superior end-to-end runtime on both IID and OOD workloads.
What carries the argument
Probability-Gated Adaptive Reward Shaping, a query-level curriculum that gates rewards according to mastery of lower-level objectives within each rollout group.
If this is right
- Fewer rewrites will compile to the same physical plan or produce slowdowns.
- Tail latencies improve because the policy avoids the worst-case rewrites.
- The same reward structure can be reused on new query sets without hand-crafted rules.
- On-policy recycling of slowdowns increases sample efficiency over pure off-policy methods.
Where Pith is reading between the lines
- The curriculum may transfer to other sparse-reward LLM tasks that admit measurable execution feedback, such as code optimization.
- If plan differences can be estimated from cost models instead of full execution, training cost could drop while preserving most of the signal.
- Engine-specific plan features learned during training may require periodic re-calibration when the underlying optimizer changes.
Load-bearing premise
Physical execution plans and runtime measurements can be obtained reliably and at acceptable cost to provide unbiased training signals that generalize beyond the specific workloads and database engine used during training.
What would settle it
Train the model on one database engine, then evaluate the resulting policy on a different engine where the same physical-plan and runtime signals were never observed during training; if the performance gap over baselines disappears, the claim is falsified.
Figures




read the original abstract
SQL query rewriting is a well-established technique for improving database performance without schema or index changes, yet finding effective rewrites for modern analytical workloads remains difficult: rule-based methods are limited to predefined transformations, while LLM-based approaches often produce rewrites that are semantically valid but compile to equivalent physical plans or degrade runtime performance. We present SPA, a SQL-Plan-Aware reinforcement learning framework that trains LLMs to rewrite queries using physical execution feedback. SPA formulates rewriting as a policy optimization problem and extends GRPO with rewards spanning semantic equivalence, textual rewrite distance, physical-plan divergence, and runtime speedup. To handle reward sparsity across query difficulty, SPA introduces Probability-Gated Adaptive Reward Shaping, a query-level curriculum that unlocks higher-level rewards only once a rollout group achieves sufficient mastery of lower-level objectives, and further improves sample efficiency through on-policy self-improvement by recycling slowdown rewrites from the current policy as targeted training signals. On both IID and OOD workloads, SPA outperforms rule-based and strong LLM baselines in end-to-end runtime, substantially reduces harmful slowdown rewrites, and yields strong tail-latency gains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SPA, a SQL-Plan-Aware reinforcement learning framework for training LLMs to rewrite queries. It formulates the task as policy optimization by extending GRPO with rewards for semantic equivalence, textual rewrite distance, physical-plan divergence, and runtime speedup. SPA adds Probability-Gated Adaptive Reward Shaping as a query-level curriculum to address reward sparsity and uses on-policy self-improvement by recycling slowdown rewrites. The central empirical claim is that SPA outperforms rule-based and strong LLM baselines on both IID and OOD workloads in end-to-end runtime, substantially reduces harmful slowdown rewrites, and yields strong tail-latency gains.
Significance. If the claimed gains hold under rigorous evaluation, the work would provide a concrete mechanism for incorporating physical execution feedback into LLM-based query rewriting, addressing a known limitation of purely semantic or rule-based approaches. The adaptive curriculum and self-improvement components target practical RL challenges in this setting and could influence future systems that combine learned rewriters with DBMS execution signals.
major comments (2)
- [Abstract] Abstract: The OOD generalization claim (runtime and tail-latency gains) is central, yet the text supplies no description of whether OOD workloads involve different database engines, optimizers, or hardware. Because the reward components explicitly depend on physical-plan divergence and measured runtime, engine-specific biases in these signals constitute a load-bearing risk to the generalization part of the claim; no cross-engine validation or variance analysis is mentioned.
- [Abstract] Abstract: No experimental details are provided on workload sizes, statistical significance testing, baseline implementations, variance of runtime measurements, or safeguards against reward hacking. These omissions prevent verification of the reported outperformance and reduction in harmful rewrites, directly affecting soundness assessment of the central empirical result.
minor comments (1)
- [Abstract] The acronym GRPO is introduced without expansion or citation; a brief definition or reference would improve readability for readers unfamiliar with the base method.
Simulated Author's Rebuttal
Thank you for the review. We address the two major comments point by point below and will revise the abstract and related sections for greater clarity on the OOD setup and experimental details.
read point-by-point responses
-
Referee: The OOD generalization claim (runtime and tail-latency gains) is central, yet the text supplies no description of whether OOD workloads involve different database engines, optimizers, or hardware. Because the reward components explicitly depend on physical-plan divergence and measured runtime, engine-specific biases in these signals constitute a load-bearing risk to the generalization part of the claim; no cross-engine validation or variance analysis is mentioned.
Authors: We agree that the abstract does not explicitly define the OOD workloads. In the experimental setup, OOD refers to queries from shifted distributions executed on the same engine, optimizer, and hardware; the rewards are computed from that system's execution signals. The framework itself is not tied to a specific engine, but we acknowledge the risk of environment-specific biases and the absence of cross-engine experiments. We will revise the abstract to state the OOD definition and scope of generalization, and we will add explicit reporting of runtime variance in the results section. revision: yes
-
Referee: No experimental details are provided on workload sizes, statistical significance testing, baseline implementations, variance of runtime measurements, or safeguards against reward hacking. These omissions prevent verification of the reported outperformance and reduction in harmful rewrites, directly affecting soundness assessment of the central empirical result.
Authors: We accept that the abstract omits these parameters. The manuscript body specifies workload sizes, describes the rule-based and LLM baselines, reports runtime measurements, and incorporates semantic-equivalence and plan-divergence checks as safeguards against reward hacking. We will revise the abstract to reference these elements concisely and will ensure the experimental section highlights statistical testing and variance where performed. If additional tables or text are needed for full transparency, we will incorporate them. revision: yes
Circularity Check
No circularity: empirical RL framework with external runtime signals
full rationale
The paper describes a reinforcement learning setup that trains an LLM policy using rewards computed from independent measurements (semantic equivalence checks, plan divergence via the DBMS optimizer, and actual runtime speedup on executed queries). These signals are obtained from the database engine and are not defined in terms of the policy's own outputs or fitted parameters. No equations, derivations, or predictions appear that reduce to inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The IID/OOD evaluation uses held-out workloads, so reported gains are not forced by the training procedure itself. This is standard empirical RL work and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Physical execution plans and runtimes supply unbiased, generalizable feedback for training query-rewriting policies.
Reference graph
Works this paper leans on
-
[1]
Edmon Begoli, Jesús Camacho-Rodríguez, Julian Hyde, Michael J. Mior, and Daniel Lemire. 2018. Apache Calcite: A Foundational Framework for Optimized Query Processing Over Heterogeneous Data Sources. InProceedings of the 2018 In- ternational Conference on Management of Data, SIGMOD Conference 2018, Houston, TX, USA, June 10-15, 2018, Gautam Das, Christophe...
-
[2]
Surajit Chaudhuri. 1998. An overview of query optimization in relational systems. InProceedings of the Seventeenth ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems(Seattle, Washington, USA)(PODS ’98). Association for Computing Machinery, New York, NY, USA, 34–43. https://doi.org/10.1145/ 275487.275492
arXiv 1998
-
[3]
Kaiwen Chen, Yueting Chen, Nick Koudas, and Xiaohui Yu. 2025. Reliable Text- to-SQL with Adaptive Abstention.Proc. ACM Manag. Data3, 1 (2025), 69:1–69:30. https://doi.org/10.1145/3709719
-
[5]
https://doi.org/ 10.48550/ARXIV.2502.12918 arXiv:2502.12918
Query Rewriting via LLMs.CoRRabs/2502.12918 (2025). https://doi.org/ 10.48550/ARXIV.2502.12918 arXiv:2502.12918
-
[6]
Haritsa, and Harish Doraiswamy
Sriram Dharwada, Himanshu Devrani, Jayant R. Haritsa, and Harish Doraiswamy
-
[7]
LITHE: A Query Rewrite Advisor using LLMs. InProceedings 29th Inter- national Conference on Extending Database Technology, EDBT 2026, Tampere, Finland, March 24-27, 2026, Wolfgang Lehner, Vanessa Braganholo, Kostas Ste- fanidis, Zheying Zhang, Alexander Krause, and João Felipe Nicolaci Pimentel (Eds.). OpenProceedings.org, 233–246. https://doi.org/10.4878...
-
[8]
Bailu Ding, Surajit Chaudhuri, Johannes Gehrke, and Vivek R. Narasayya. 2021. DSB: A Decision Support Benchmark for Workload-Driven and Traditional Database Systems.Proc. VLDB Endow.14, 13 (2021), 3376–3388. https://doi.org/ 10.14778/3484224.3484234
-
[9]
Narasayya, and Surajit Chaudhuri
Bailu Ding, Vivek R. Narasayya, and Surajit Chaudhuri. 2024. Extensible Query Optimizers in Practice.Found. Trends Databases14, 3-4 (2024), 186–402. https: //doi.org/10.1561/1900000077
-
[10]
Rui Dong, Jie Liu, Yuxuan Zhu, Cong Yan, Barzan Mozafari, and Xinyu Wang
-
[11]
VLDB Endow.16, 11 (2023), 3151–3164
SlabCity: Whole-Query Optimization using Program Synthesis.Proc. VLDB Endow.16, 11 (2023), 3151–3164. https://doi.org/10.14778/3611479.3611515
-
[12]
Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou. 2024. Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation.Proc. VLDB Endow.17, 5 (2024), 1132–1145. https: //doi.org/10.14778/3641204.3641221
-
[13]
1987.Rule-Based Query Optimization in Extensible Database Systems
Goetz Graefe. 1987.Rule-Based Query Optimization in Extensible Database Systems. Ph.D. Dissertation. Univ. of Wisconsin-Madison
1987
-
[14]
Laura M. Haas. 1999. Review - Access Path Selection in a Relational Database Management System.ACM SIGMOD Digit. Rev.1 (1999). https://dblp.org/db/ journals/dr/Haas99a.html
1999
-
[15]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net. https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[16]
Viktor Leis, Andrey Gubichev, Atanas Mirchev, Peter Boncz, Alfons Kemper, and Thomas Neumann. 2015. How Good Are Query Optimizers, Really?Proc. VLDB Endow.9, 3 (2015), 204–215. https://doi.org/10.14778/2850583.2850594
-
[17]
Viktor Leis, Andrey Gubichev, Atanas Mirchev, Peter Boncz, Alfons Kemper, and Thomas Neumann. 2025. Still Asking: How Good Are Query Optimizers, Really? Proc. VLDB Endow.18, 12 (2025), 5531–5536. https://doi.org/10.14778/3750601. 3760521
-
[18]
Levy, Inderpal Singh Mumick, and Yehoshua Sagiv
Alon Y. Levy, Inderpal Singh Mumick, and Yehoshua Sagiv. 1994. Query Optimiza- tion by Predicate Move-Around. InVLDB’94, Proceedings of 20th International Conference on Very Large Data Bases, September 12-15, 1994, Santiago de Chile, Chile, Jorge B. Bocca, Matthias Jarke, and Carlo Zaniolo (Eds.). Morgan Kaufmann, 96–107. http://www.vldb.org/conf/1994/P096.PDF
1994
-
[19]
Guoliang Li, Xuanhe Zhou, Shifu Li, and Bo Gao. 2019. QTune: a query-aware database tuning system with deep reinforcement learning.Proc. VLDB Endow. 12, 12 (Aug. 2019), 2118–2130. https://doi.org/10.14778/3352063.3352129
-
[20]
Jiahui Li, Tongwang Wu, Yuren Mao, Yunjun Gao, Yajie Feng, and Huaizhong Liu
-
[21]
VLDB Endow.19, 3 (2025), 292–305
SQL-Factory: A Multi-Agent Framework for High-Quality and Large-Scale SQL Generation.Proc. VLDB Endow.19, 3 (2025), 292–305. https://www.vldb. org/pvldb/vol19/p292-gao.pdf
2025
-
[22]
Zhaodonghui Li, Haitao Yuan, Huiming Wang, Gao Cong, and Lidong Bing
-
[23]
LLM-R2: A Large Language Model Enhanced Rule-Based Rewrite System for Boosting Query Efficiency.Proc. VLDB Endow.18, 1 (Sept. 2024), 53–65. https://doi.org/10.14778/3696435.3696440
-
[24]
Hanwen Liu, Qihan Zhang, Ryan Marcus, and Ibrahim Sabek. 2025. SEFRQO: A Self-Evolving Fine-Tuned RAG-Based Query Optimizer.Proc. ACM Manag. Data 3, 6 (2025), 1–27. https://doi.org/10.1145/3769826
-
[25]
Jie Liu and Barzan Mozafari. 2026. GenRewrite: Query Rewriting via Large Language Models.Proceedings of the ACM on Management of Data4, 1 (SIGMOD (2026), 1–26
2026
-
[26]
Ryan Marcus, Parimarjan Negi, Hongzi Mao, Nesime Tatbul, Mohammad Al- izadeh, and Tim Kraska. 2021. Bao: Making Learned Query Optimization Practical. InSIGMOD ’21: International Conference on Management of Data, Virtual Event, China, June 20-25, 2021, Guoliang Li, Zhanhuai Li, Stratos Idreos, and Divesh Srivastava (Eds.). ACM, 1275–1288. https://doi.org/1...
-
[27]
Ryan Marcus, Parimarjan Negi, Hongzi Mao, Chi Zhang, Mohammad Alizadeh, Tim Kraska, Olga Papaemmanouil, and Nesime Tatbul. 2019. Neo: A Learned Query Optimizer.Proc. VLDB Endow.12, 11 (2019), 1705–1718. https://doi.org/ 10.14778/3342263.3342644
-
[28]
Muralikrishna
M. Muralikrishna. 1992. Improved Unnesting Algorithms for Join Aggregate SQL Queries. In18th International Conference on Very Large Data Bases, August 23-27, 1992, Vancouver, Canada, Proceedings, Li-Yan Yuan (Ed.). Morgan Kaufmann, 91–102. http://www.vldb.org/conf/1992/P091.PDF
1992
-
[29]
Raghunath Othayoth Nambiar and Meikel Poess. 2006. The Making of TPC-DS. InProceedings of the 32nd International Conference on Very Large Data Bases, Seoul, Korea, September 12-15, 2006, Umeshwar Dayal, Kyu-Young Whang, David B. Lomet, Gustavo Alonso, Guy M. Lohman, Martin L. Kersten, Sang Kyun Cha, and Young-Kuk Kim (Eds.). ACM, 1049–1058. http://dl.acm....
2006
-
[30]
OpenAI. 2024. GPT-4o System Card.CoRRabs/2410.21276 (2024). https://doi. org/10.48550/ARXIV.2410.21276 arXiv:2410.21276
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.21276 2024
-
[31]
OpenAI. 2026. GPT-5.4 Thinking System Card. https://deploymentsafety.openai. com/gpt-5-4-thinking/gpt-5-4-thinking.pdf
2026
-
[32]
Malinga Perera, Bastian Oetomo, Benjamin I
R. Malinga Perera, Bastian Oetomo, Benjamin I. P. Rubinstein, and Renata Borovica-Gajic. 2021. DBA bandits: Self-driving index tuning under ad-hoc, analytical workloads with safety guarantees. In37th IEEE International Confer- ence on Data Engineering, ICDE 2021, Chania, Greece, April 19-22, 2021. IEEE, 600–611. https://doi.org/10.1109/ICDE51399.2021.00058
-
[33]
Meikel Poess and Chris Floyd. 2000. New TPC benchmarks for decision support and web commerce.SIGMOD Rec.29, 4 (Dec. 2000), 64–71. https://doi.org/10. 1145/369275.369291
arXiv 2000
-
[34]
Tobias Schmidt, Viktor Leis, Peter Boncz, and Thomas Neumann. 2025. SQLStorm: Taking Database Benchmarking into the LLM Era.Proc. VLDB Endow.18, 11 (2025), 4144–4157. https://doi.org/10.14778/3749646.3749683
-
[35]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.CoRRabs/2402.03300 (2024). https://doi.org/10.48550/ARXIV.2402.03300 arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
-
[36]
Yuyang Song, Hanxu Yan, Jiale Lao, Yibo Wang, Yufei Li, Yuanchun Zhou, Jianguo Wang, and Mingjie Tang. 2025. QUITE: A Query Rewrite System Beyond Rules with LLM Agents.CoRRabs/2506.07675 (2025). https://doi.org/10.48550/ARXIV. 2506.07675 arXiv:2506.07675
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[37]
Zhaoyan Sun, Xuanhe Zhou, Guoliang Li, Xiang Yu, Jianhua Feng, and Yong Zhang. 2025. R-Bot: An LLM-based Query Rewrite System.Proc. VLDB Endow. 18, 12 (2025), 5031–5044. https://doi.org/10.14778/3750601.3750625
-
[38]
Gemini Team. 2025. Gemini 2.5: Pushing the Frontier with Advanced Rea- soning, Multimodality, Long Context, and Next Generation Agentic Capabili- ties.CoRRabs/2507.06261 (2025). https://doi.org/10.48550/ARXIV.2507.06261 arXiv:2507.06261
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.06261 2025
-
[39]
Qwen Team. 2025. Qwen3 Technical Report.CoRRabs/2505.09388 (2025). https: //doi.org/10.48550/ARXIV.2505.09388 arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[40]
Immanuel Trummer, Junxiong Wang, Ziyun Wei, Deepak Maram, Samuel Mose- ley, Saehan Jo, Joseph Antonakakis, and Ankush Rayabhari. 2021. SkinnerDB: Regret-bounded Query Evaluation via Reinforcement Learning.ACM Trans. Database Syst.46, 3 (2021), 9:1–9:45. https://doi.org/10.1145/3464389
-
[41]
Junxiong Wang, Immanuel Trummer, and Debabrota Basu. 2021. UDO: Universal Database Optimization using Reinforcement Learning.Proc. VLDB Endow.14, 13 (2021), 3402–3414. https://doi.org/10.14778/3484224.3484236
-
[42]
Zhaoguo Wang, Zhou Zhou, Yicun Yang, Haoran Ding, Gansen Hu, Ding Ding, Chuzhe Tang, Haibo Chen, and Jinyang Li. 2022. WeTune: Automatic Discovery and Verification of Query Rewrite Rules. InSIGMOD ’22: International Conference on Management of Data, Philadelphia, PA, USA, June 12 - 17, 2022, Zachary G. Ives, Angela Bonifati, and Amr El Abbadi (Eds.). ACM,...
-
[43]
Xiangjin Xie, Guangwei Xu, Lingyan Zhao, and Ruijie Guo. 2025. OpenSearch- SQL: Enhancing Text-to-SQL with Dynamic Few-shot and Consistency Align- ment.Proc. ACM Manag. Data3, 3 (2025), 194:1–194:24. https://doi.org/10.1145/ 3725331
2025
-
[44]
Dongjie Xu, Yue Cui, Weijie Shi, Qingzhi Ma, Hanghui Guo, Jiaming Li, Yao Zhao, Ruiyuan Zhang, Shimin Di, Jia Zhu, Kai Zheng, and Jiajie Xu. 2025. E3-Rewrite: Learning to Rewrite SQL for Executability, Equivalence,and Effi- ciency.CoRRabs/2508.09023 (2025). https://doi.org/10.48550/ARXIV.2508.09023 arXiv:2508.09023
-
[45]
Yicun Yang, Zhaoguo Wang, Yu Xia, Zhuoran Wei, Haoran Ding, Ruzica Piskac, Haibo Chen, and Jinyang Li. 2025. Automated Validating and Fixing of Text-to- SQL Translation with Execution Consistency.Proc. ACM Manag. Data3, 3 (2025), 134:1–134:28. https://doi.org/10.1145/3725271 13
-
[46]
Zongheng Yang, Wei-Lin Chiang, Sifei Luan, Gautam Mittal, Michael Luo, and Ion Stoica. 2022. Balsa: Learning a Query Optimizer Without Expert Demonstrations. InSIGMOD ’22: International Conference on Management of Data, Philadelphia, PA, USA, June 12 - 17, 2022, Zachary G. Ives, Angela Bonifati, and Amr El Abbadi (Eds.). ACM, 931–944. https://doi.org/10.1...
-
[47]
Xiang Yu, Guoliang Li, Chengliang Chai, and Nan Tang. 2020. Reinforcement Learning with Tree-LSTM for Join Order Selection. In36th IEEE International Conference on Data Engineering, ICDE 2020, Dallas, TX, USA, April 20-24, 2020. IEEE, 1297–1308. https://doi.org/10.1109/ICDE48307.2020.00116
-
[48]
Ji Zhang, Yu Liu, Ke Zhou, Guoliang Li, Zhili Xiao, Bin Cheng, Jiashu Xing, Yangtao Wang, Tianheng Cheng, Li Liu, Minwei Ran, and Zekang Li. 2019. An End-to-End Automatic Cloud Database Tuning System Using Deep Reinforce- ment Learning. InProceedings of the 2019 International Conference on Management of Data(Amsterdam, Netherlands)(SIGMOD ’19). Associatio...
-
[49]
Yuxin Zhang, Meihao Fan, Ju Fan, Mingyang Yi, Yuyu Luo, Jian Tan, and Guoliang Li. 2025. Reward-SQL: Boosting Text-to-SQL via Stepwise Reasoning and Process- Supervised Rewards.CoRRabs/2505.04671 (2025). https://doi.org/10.48550/ ARXIV.2505.04671 arXiv:2505.04671
arXiv 2025
-
[50]
Xuanhe Zhou, Guoliang Li, Chengliang Chai, and Jianhua Feng. 2021. A Learned Query Rewrite System using Monte Carlo Tree Search.Proc. VLDB Endow.15, 1 (2021), 46–58. https://doi.org/10.14778/3485450.3485456 14
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.