Data Architectures and their Technical Requirements (DATER)
Pith reviewed 2026-06-27 17:23 UTC · model grok-4.3
The pith
The DATER framework supplies a shared set of technical requirement dimensions for describing and comparing data architectures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
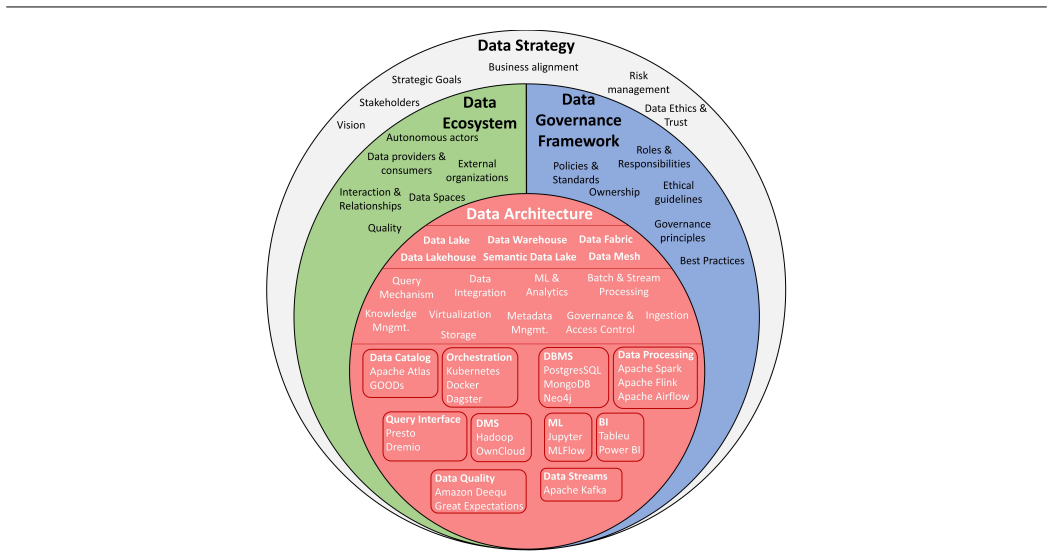
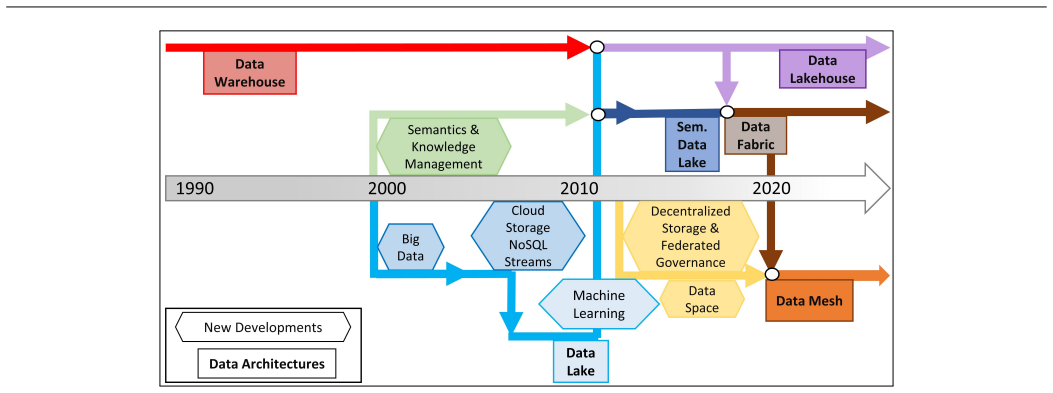
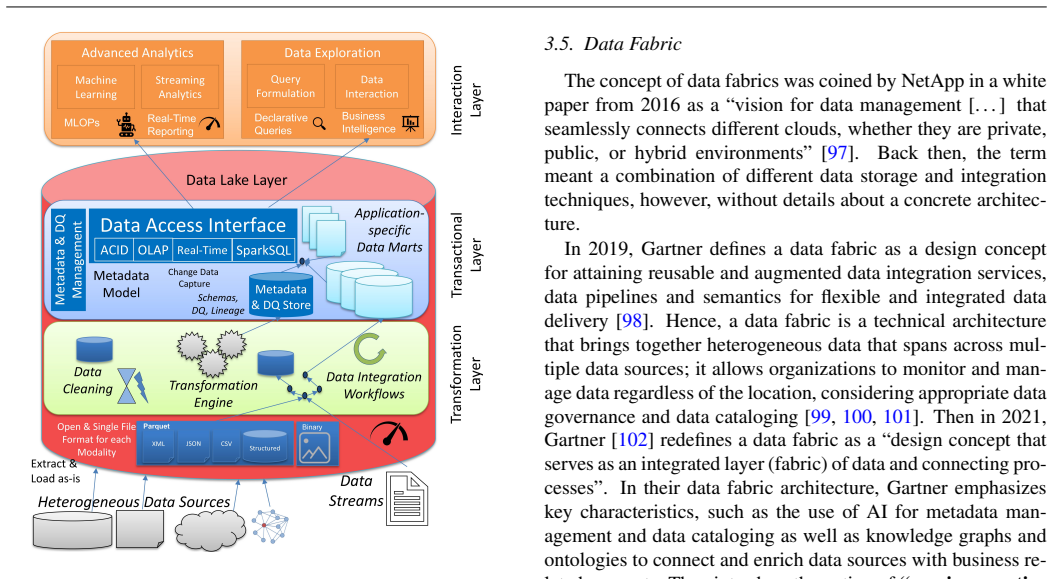
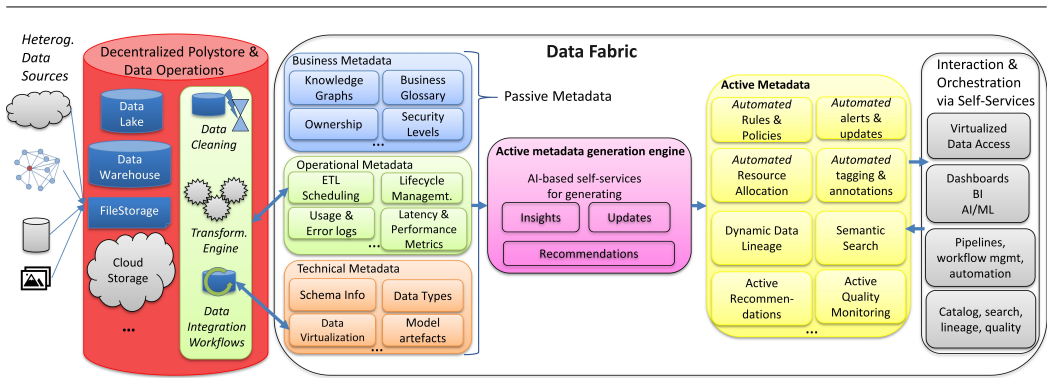
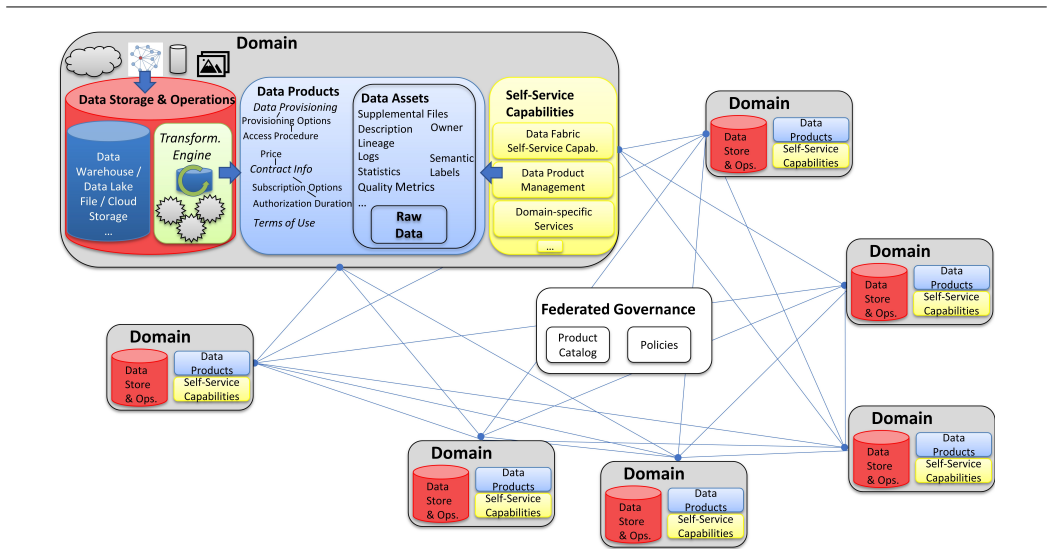
DATER is introduced as a conceptual framework consisting of dimensions that capture essential technical requirements; the six architectures—data warehouse, semantic data lake, data lake, data lakehouse, data fabric, and data mesh—are then described by historical context and defining features before their conformance to each DATER dimension is assessed.
What carries the argument
The DATER framework, a set of technical-requirement dimensions used to evaluate conformance of data architectures.
If this is right
- Organizations gain a common language for matching data architectures to specific technical needs.
- Overlaps between architectures such as data lakes and data meshes become visible through shared dimension scores.
- Strengths and gaps of each architecture are highlighted for particular use cases.
- Researchers obtain a structured basis for extending or refining architecture comparisons.
Where Pith is reading between the lines
- The same dimensions could be tested on hybrid or future architectures not covered in the original six.
- DATER might serve as a starting point for adding non-technical criteria such as organizational governance.
- Standardized scoring templates derived from the dimensions could support repeatable architecture audits.
Load-bearing premise
The chosen DATER dimensions capture the essential technical requirements completely and without subjective weighting that would alter the conformance results for the six architectures.
What would settle it
Independent teams applying the DATER dimensions to the same architecture and arriving at materially different conformance scores would show the framework fails to produce consistent evaluations.
Figures
read the original abstract
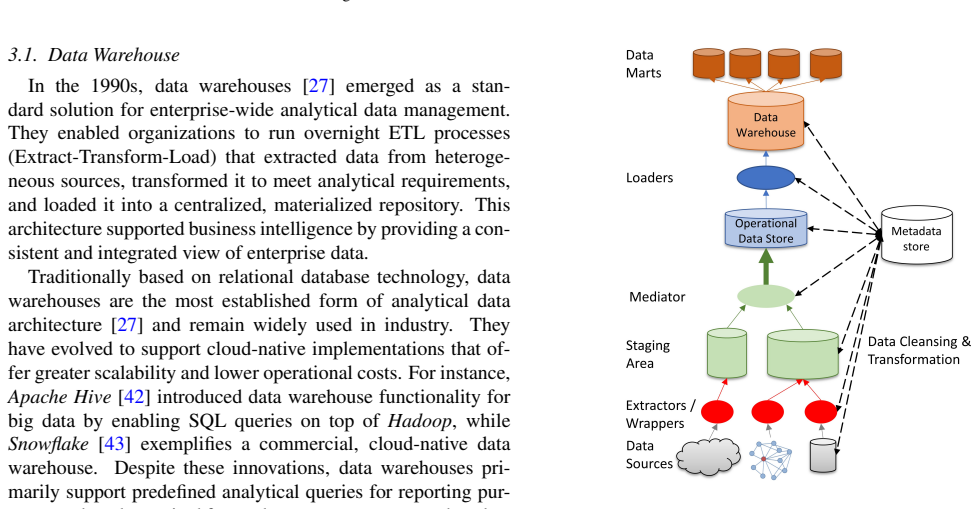
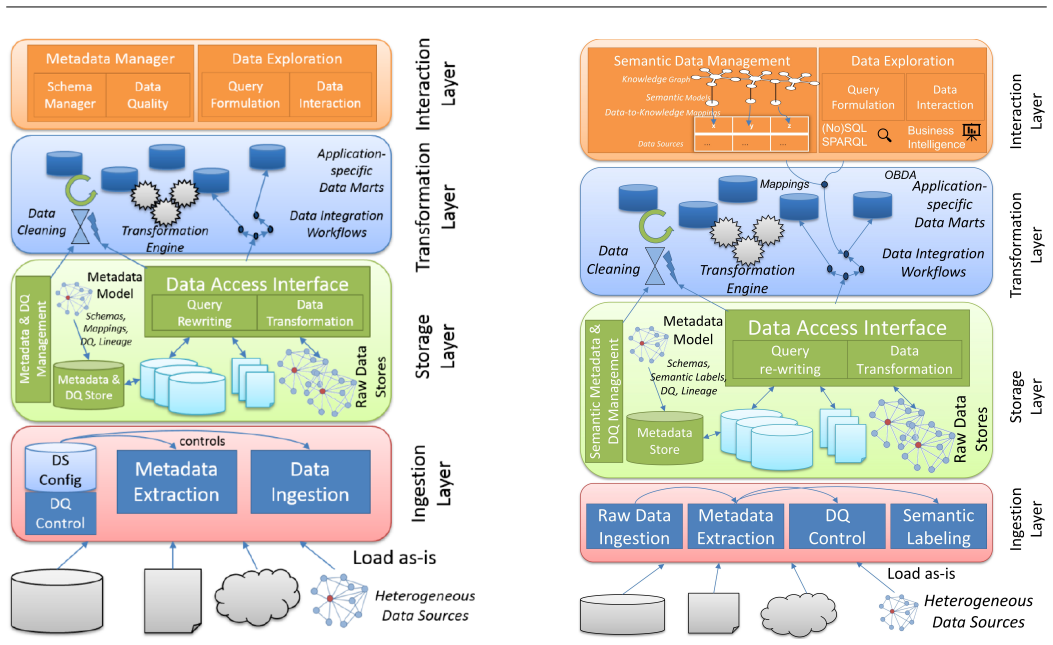
Modern organizations generate and consume massive volumes of heterogeneous data at high speed. This requires a continuous development of new techniques for more efficient and reliable data management. Designing appropriate data architectures has therefore become a strategic necessity, as they shape how data is integrated, governed, and made available for analytics and decisionmaking. This paper introduces a conceptual framework - Data Architectures and their Technical Requirements (DATER) - to systematically describe and evaluate data architectures based on technical requirements. Six modern architectures are examined: data warehouse, (semantic) data lake, data lakehouse, data fabric, and data mesh. Each is analyzed by historical context, defining features, and conformance to DATER dimensions. The study supports researchers and practitioners in navigating architectural paradigms, clarifying overlaps, and highlighting strengths, limitations, and use-case suitability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Data Architectures and their Technical Requirements (DATER) conceptual framework to systematically describe and evaluate data architectures based on technical requirements. It examines six architectures—data warehouse, (semantic) data lake, data lakehouse, data fabric, and data mesh—by their historical context, defining features, and conformance to DATER dimensions, with the goal of clarifying overlaps and use-case suitability.
Significance. If the DATER dimensions form a complete and unbiased basis, the framework offers a structured conceptual tool for researchers and practitioners to compare data architecture paradigms without reliance on fitted parameters or mathematical derivations. The absence of invented entities or ad-hoc axioms in the presentation supports its role as an independent contribution.
major comments (2)
- [DATER dimensions definition section] The section defining the DATER dimensions provides no derivation method (e.g., from requirements engineering literature, ISO 8000, or NIST guidelines), no empirical survey basis, and no inter-rater validation. This is load-bearing for the central claim, as subjective selection could introduce omissions (such as fine-grained consistency models, multi-tenancy isolation, or energy efficiency) or uneven weighting that directly alters the conformance assessments for the six architectures.
- [Conformance analysis for the six architectures] In the conformance analysis sections for each architecture, the qualitative scoring lacks explicit criteria, weighting scheme, or cross-check against external references. This undermines the reported strengths, limitations, and use-case suitability, as the evaluations rest on unvalidated dimension application.
minor comments (2)
- [Abstract] The abstract lists five items under 'six modern architectures' (data warehouse, (semantic) data lake, data lakehouse, data fabric, and data mesh); clarify whether semantic data lake is treated as distinct from data lake.
- [References] Add references to standard data management guidelines (e.g., ISO 8000, NIST) to ground the framework choice.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify the presentation of our conceptual framework. We address each major comment below.
read point-by-point responses
-
Referee: [DATER dimensions definition section] The section defining the DATER dimensions provides no derivation method (e.g., from requirements engineering literature, ISO 8000, or NIST guidelines), no empirical survey basis, and no inter-rater validation. This is load-bearing for the central claim, as subjective selection could introduce omissions (such as fine-grained consistency models, multi-tenancy isolation, or energy efficiency) or uneven weighting that directly alters the conformance assessments for the six architectures.
Authors: We agree that an explicit derivation strengthens the framework. The dimensions were synthesized from recurring technical requirements in data management literature (e.g., scalability, consistency, governance). We will revise the section to include a derivation subsection referencing requirements engineering practices and ISO 8000 for data quality. We will also discuss why certain aspects (e.g., energy efficiency) were treated as secondary rather than core dimensions. Inter-rater validation will be noted as a limitation for future empirical work, as the current contribution is conceptual. revision: yes
-
Referee: [Conformance analysis for the six architectures] In the conformance analysis sections for each architecture, the qualitative scoring lacks explicit criteria, weighting scheme, or cross-check against external references. This undermines the reported strengths, limitations, and use-case suitability, as the evaluations rest on unvalidated dimension application.
Authors: We acknowledge the value of explicit criteria. We will add a methods subsection defining conformance levels (full/partial/none) based on each architecture's documented features, with equal weighting applied across dimensions. Cross-references to existing literature surveys and case studies will be incorporated to support the assessments. These additions will improve reproducibility without changing the qualitative conclusions. revision: yes
Circularity Check
DATER is a self-contained conceptual framework with no derivation chain or reductions to inputs
full rationale
The paper presents DATER as an original conceptual framework for evaluating data architectures. No equations, fitted parameters, predictions, or first-principles derivations are described. The dimensions are introduced as part of the contribution itself rather than derived from prior results by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are referenced in the provided text. The analysis of the six architectures proceeds by direct conformance assessment to the defined dimensions, without reducing to any fitted or self-referential inputs. This meets the criteria for an independent contribution; no circular steps exist.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
data in management and decision engineering
A. Tzanetos, G. Dounias, Introduction to the special issue “data in management and decision engineering”, Data in Brief 55 (2024) 110711
2024
-
[2]
Muller, A reference architecture primer, Eindhoven Univ
G. Muller, A reference architecture primer, Eindhoven Univ. of Techn., Eindhoven, White paper (2008) 24
2008
-
[3]
Gröger, There is no ai without data, Communications of the ACM 64 (11) (2021) 98–108
C. Gröger, There is no ai without data, Communications of the ACM 64 (11) (2021) 98–108
2021
-
[4]
A. P. Sheth, J. A. Larson, Federated database systems for managing distributed, heterogeneous, and autonomous databases, ACM Comput. Surv. 22 (3) (1990) 183–236. doi:10.1145/96602.96604. URLhttps://doi.org/10.1145/96602.96604
-
[5]
G. M. Sang, L. Xu, P. de Vrieze, A reference architec- ture for big data systems, in: 2016 10th International Conference on Software, Knowledge, Information Man- agement and Applications (SKIMA), 2016, pp. 370–375. doi:10.1109/SKIMA.2016.7916249
-
[6]
G. M. Sang, L. Xu, P. De Vrieze, Simplifying big data analytics systems with a reference architecture, in: Col- laboration in a Data-Rich World: 18th IFIP WG 5.5 Working Conference on Virtual Enterprises, PRO-VE 2017, Vicenza, Italy, September 18-20, 2017, Proceed- ings 18, Springer, 2017, pp. 242–249
2017
-
[7]
Van den Hoven, Data architecture: Blueprints for data., Information systems management 20 (1) (2003)
J. Van den Hoven, Data architecture: Blueprints for data., Information systems management 20 (1) (2003)
2003
-
[8]
Badampudi, C
D. Badampudi, C. Wohlin, K. Petersen, Experiences from using snowballing and database searches in sys- tematic literature studies, in: Proceedings of the 19th in- ternational conference on evaluation and assessment in software engineering, 2015, pp. 1–10
2015
-
[9]
Otto, The evolution of data spaces, in: Designing data spaces: The ecosystem approach to competitive advan- tage, Springer International Publishing Cham, 2022, pp
B. Otto, The evolution of data spaces, in: Designing data spaces: The ecosystem approach to competitive advan- tage, Springer International Publishing Cham, 2022, pp. 3–15
2022
-
[10]
Gessler, M
J. Gessler, M. R. Cencic, C. Metzner, H. Wieker, K. Lin- dow, W. H. Schulz, Business models and organizational roles of data spaces: A framework for sustainable value creation, Data in Brief (2025) 111795
2025
-
[11]
Lin, The lambda and the kappa, IEEE Internet Com- puting 21 (05) (2017) 60–66
J. Lin, The lambda and the kappa, IEEE Internet Com- puting 21 (05) (2017) 60–66
2017
-
[12]
Linstedt, M
D. Linstedt, M. Olschimke, Building a scalable data warehouse with data vault 2.0, Morgan Kaufmann, 2015
2015
-
[13]
W. H. Inmon, D. Linstedt, Data architecture: a primer for the data scientist: big data, data warehouse and data vault, Morgan Kaufmann, 2014
2014
-
[14]
M. Kiran, P. Murphy, I. Monga, J. Dugan, S. S. Baveja, Lambda architecture for cost-effective batch and speed big data processing, in: 2015 IEEE International Con- ference on Big Data (Big Data), 2015, pp. 2785–2792. doi:10.1109/BigData.2015.7364082
-
[15]
Hoseini, A
S. Hoseini, A. Ali, H. Shaker, C. Quix, Sedar: A seman- tic data reservoir for heterogeneous datasets, in: Pro- ceedings of the 32nd ACM International Conference on Information and Knowledge Management, 2023, pp. 5056–5060
2023
-
[16]
rep., Federal Ministry for Economic Affairs and Energy (BMWi), D-11019 Berlin, Germany (Oct
Plattform Industrie 4.0, Project gaia-x: A federated data infrastructure as the cradle of a vibrant european ecosys- tem, Tech. rep., Federal Ministry for Economic Affairs and Energy (BMWi), D-11019 Berlin, Germany (Oct. 2019)
2019
-
[17]
Venugopal, R
S. Venugopal, R. Buyya, K. Ramamohanarao, A tax- onomy of data grids for distributed data sharing, man- agement, and processing, ACM Computing Surveys (CSUR) 38 (1) (2006) 3–es
2006
-
[18]
Ataei, A
P. Ataei, A. Litchfield, The state of big data reference ar- chitectures: A systematic literature review, IEEE Access 10 (2022) 113789–113807
2022
-
[19]
Giebler, C
C. Giebler, C. Gröger, E. Hoos, R. Eichler, H. Schwarz, B. Mitschang, The data lake architecture framework, in: BTW 2021, Gesellschaft für Informatik, Bonn, 2021, pp. 351–370
2021
-
[20]
Geisler, M.-E
S. Geisler, M.-E. Vidal, C. Cappiello, B. F. Lóscio, A. Gal, M. Jarke, M. Lenzerini, P. Missier, B. Otto, E. Paja, et al., Knowledge-driven data ecosystems toward 19/25 Preprint submitted to arXiv data transparency, ACM Journal of Data and Information Quality (JDIQ) 14 (1) (2021) 1–12
2021
-
[21]
K. M. Endris, P. D. Rohde, M. Vidal, S. Auer, Ontario: Federated query processing against a semantic data lake, in: Proc. DEXA, V ol. 11706 of LNCS, Springer, 2019, pp. 379–395.doi:10.1007/978-3-030-27615-7\ _{2}{9}
-
[22]
R. Hai, S. Geisler, C. Quix, Constance: An intelligent data lake system, in: Proc. SIGMOD, 2016
2016
-
[23]
D. A. M. Association, et al., DAMA-DMBOK: Data management body of knowledge, Technics Publications, LLC, 2017
2017
-
[24]
M. I. S. Oliveira, B. F. Lóscio, What is a data ecosys- tem?, in: Proceedings of the 19th Annual International Conference on Digital Government Research: Gover- nance in the Data Age, dg.o ’18, ACM, New York, NY , USA, 2018.doi:10.1145/3209281.3209335. URLhttps://doi.org/10.1145/3209281. 3209335
-
[25]
C. J. Date, An introduction to database systems, Pearson Education India, 1977
1977
-
[26]
Fathy, W
N. Fathy, W. Gad, N. Badr, A unified access to hetero- geneous big data through ontology-based semantic inte- gration, in: 2019 Ninth International Conference on In- telligent Computing and Information Systems (ICICIS), IEEE, 2019, pp. 387–392
2019
-
[27]
W. H. Inmon, Building the data warehouse, John wiley & sons, 2005
2005
-
[28]
S. Decker, S. Melnik, F. van Harmelen, D. Fensel, M. C. A. Klein, J. Broekstra, M. Erdmann, I. Horrocks, The semantic web: The roles of XML and RDF, IEEE Internet Comput. 4 (5) (2000) 63–74.doi:10.1109/ 4236.877487. URLhttps://doi.org/10.1109/4236.877487
-
[29]
Laney, et al., 3d data management: Controlling data volume, velocity and variety, META group research note 6 (70) (2001) 1
D. Laney, et al., 3d data management: Controlling data volume, velocity and variety, META group research note 6 (70) (2001) 1
2001
-
[30]
A. Moniruzzaman, S. A. Hossain, Nosql database: New era of databases for big data analytics-classification, characteristics and comparison, arXiv preprint arXiv:1307.0191 (2013)
Pith/arXiv arXiv 2013
-
[31]
Armbrust, A
M. Armbrust, A. Fox, R. Griffith, A. D. Joseph, R. Katz, A. Konwinski, G. Lee, D. Patterson, A. Rabkin, I. Stoica, et al., A view of cloud computing, Communications of the ACM 53 (4) (2010) 50–58
2010
-
[32]
Golab, M
L. Golab, M. T. Ozsu, Data stream management, Springer Nature, 2022
2022
-
[33]
Krizhevsky, I
A. Krizhevsky, I. Sutskever, G. E. Hinton, Imagenet classification with deep convolutional neural networks, Advances in neural information processing systems 25 (2012)
2012
-
[34]
K. Simonyan, A. Zisserman, Very deep convolu- tional networks for large-scale image recognition, arXiv preprint arXiv:1409.1556 (2014)
Pith/arXiv arXiv 2014
-
[35]
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learn- ing for image recognition, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[36]
I. M. Putrama, P. Martinek, Heterogeneous data inte- gration: Challenges and opportunities, Data in Brief 56 (2024) 110853
2024
-
[37]
Dixon, Pentaho, hadoop, and data lakes|james dixon’s blog, [Online; accessed 22-Oct-2024] (2010)
J. Dixon, Pentaho, hadoop, and data lakes|james dixon’s blog, [Online; accessed 22-Oct-2024] (2010). URLhttps://jamesdixon.wordpress.com/2010/ 10/14/pentaho-hadoop-and-data-lakes/
2024
-
[38]
tcs.2020.02.014,doi:10.1016/J.TCS.2020.02.014
S. Hoseini, J. Theissen-Lipp, C. Quix, A sur- vey on semantic data management as intersection of ontology-based data access, semantic modeling and data lakes, Journal of Web Semantics 81 (2024) 100819.doi:https://doi.org/10.1016/j. websem.2024.100819
work page doi:10.1016/j 2024
-
[39]
Dehghani, Data Mesh: Delivering Data-Driven Value at Scale, O’Reilly Media, Sebastopol, CA, 2022
Z. Dehghani, Data Mesh: Delivering Data-Driven Value at Scale, O’Reilly Media, Sebastopol, CA, 2022. URLhttps://www.oreilly.com/library/view/ data-mesh/9781492092346/
arXiv 2022
-
[40]
Zaidi, E
E. Zaidi, E. Thoo, G. De Simoni, M. Beyer, Data fab- rics add augmented intelligence to modernize your data integration, With Eric Thoo. Gartner Grou 17 (2019)
2019
-
[41]
Armbrust, A
M. Armbrust, A. Ghodsi, R. Xin, M. Zaharia, Lake- house: a new generation of open platforms that unify data warehousing and advanced analytics, in: Proceed- ings of CIDR, V ol. 8, 2021, p. 28
2021
-
[42]
Y . Huai, A. Chauhan, A. Gates, G. Hagleitner, E. N. Han- son, O. O’Malley, J. Pandey, Y . Yuan, R. Lee, X. Zhang, Major technical advancements in apache hive, in: Pro- ceedings of the 2014 ACM SIGMOD international con- ference on Management of data, 2014, pp. 1235–1246
2014
-
[43]
M. Hentschel, J. Dees, F. Funke, M. Heimel, I. Oukid, Building a data management system for the cloud: Lessons learned and future direc- tions, Datenbank-Spektrum 25 (1) (2025) 17–28. doi:10.1007/S13222-025-00494-9. URLhttps://doi.org/10.1007/ s13222-025-00494-9
-
[44]
Chaudhuri, U
S. Chaudhuri, U. Dayal, An overview of data warehous- ing and olap technology, ACM Sigmod record 26 (1) (1997) 65–74. 20/25 Preprint submitted to arXiv
1997
-
[45]
Bose, Advanced analytics: opportunities and chal- lenges, Industrial Management & Data Systems 109 (2) (2009) 155–172
R. Bose, Advanced analytics: opportunities and chal- lenges, Industrial Management & Data Systems 109 (2) (2009) 155–172
2009
-
[46]
A. A. Harby, F. Zulkernine, Data lakehouse: A sur- vey and experimental study, Information Systems (2024) 102460
2024
-
[47]
Jarke, M
M. Jarke, M. A. Jeusfeld, C. Quix, P. Vassiliadis, Architecture and Quality in Data Warehouses: An Extended Repository Approach, Information Systems 24 (3) (1999) 229–253
1999
-
[48]
Kimball, M
R. Kimball, M. Ross, The data warehouse toolkit: The definitive guide to dimensional modeling, John Wiley & Sons, 2013
2013
-
[49]
Davoudian, L
A. Davoudian, L. Chen, M. Liu, A survey on nosql stores, ACM Computing Surveys (CSUR) 51 (2) (2018) 1–43
2018
-
[50]
Jarke, M
M. Jarke, M. Lenzerini, Y . Vassiliou, P. Vassiliadis (Eds.), Fundamentals of Data Warehouses, 2nd Edition, Springer-Verlag, 2003
2003
-
[51]
C. Quix, R. Hai, Data lake, in: Encyclopedia of Big Data Technologies, Springer, 2019.doi:10.1007/ 978-3-319-63962-8\_{7}{-}{1}
2019
-
[52]
Sawadogo, J
P. Sawadogo, J. Darmont, On data lake architectures and metadata management, JJIS (2021)
2021
-
[53]
E. Scholly, P. Sawadogo, P. Liu, J. A. Espinosa-Oviedo, C. Favre, S. Loudcher, J. Darmont, C. Noûs, Coining goldmedal: a new contribution to data lake generic meta- data modeling, arXiv preprint arXiv:2103.13155 (2021)
arXiv 2021
-
[54]
Y . Zhao, I. Megdiche, F. Ravat, Data lake ingestion man- agement, arXiv preprint arXiv:2107.02885 (2021)
arXiv 2021
-
[55]
Farid, A
M. Farid, A. Roatis, I. F. Ilyas, H.-F. Hoffmann, X. Chu, Clams: Bringing quality to data lakes, in: Proc. SIG- MOD, 2016
2016
-
[56]
S. Galhotra, U. Khurana, Semantic search over struc- tured data, in: Proceedings of the 29th ACM Interna- tional Conference on Information & Knowledge Man- agement, Association for Computing Machinery, New York, NY , USA, 2020, p. 3381–3384.doi:10.1145/ 3340531.3417426
arXiv 2020
-
[57]
Dibowski, S
H. Dibowski, S. Schmid, Y . Svetashova, C. A. Henson, T. Tran, Using semantic technologies to manage a data lake: Data catalog, provenance and access control, in: SSWS@ISWC, 2020. URLhttps://api.semanticscholar.org/ CorpusID:229357020
2020
-
[58]
R. Eichler, C. Giebler, C. Gröger, H. Schwarz, B. Mitschang, Modeling metadata in data lakes - A generic model, Data Knowl. Eng. 136 (2021) 101931. doi:10.1016/J.DATAK.2021.101931. URLhttps://doi.org/10.1016/j.datak.2021. 101931
-
[59]
Nambiar, D
A. Nambiar, D. Mundra, An overview of data warehouse and data lake in modern enterprise data management, Big data and cognitive computing 6 (4) (2022) 132
2022
-
[60]
Ramakrishnan, B
R. Ramakrishnan, B. Sridharan, J. R. Douceur, P. Kas- turi, B. Krishnamachari-Sampath, K. Krishnamoorthy, P. Li, M. Manu, S. Michaylov, R. Ramos, et al., Azure data lake store: a hyperscale distributed file service for big data analytics, in: Proceedings of the 2017 ACM In- ternational Conference on Management of Data, 2017, pp. 51–63
2017
-
[61]
A. Y . Halevy, F. Korn, N. F. Noy, C. Olston, N. Polyzotis, S. Roy, S. E. Whang, Managing google’s data lake: an overview of the goods system, IEEE Data Eng. Bull. (2016). URLhttp://sites.computer.org/debull/ A16sept/p5.pdf
2016
-
[62]
Azzabi, Z
S. Azzabi, Z. Alfughi, A. Ouda, Data lakes: A survey of concepts and architectures, Computers 13 (7) (2024) 183
2024
-
[63]
R. Hai, C. Koutras, C. Quix, M. Jarke, Data lakes: A survey of functions and systems, IEEE TKDE 35 (12) (2023) 12571–12590
2023
-
[64]
Nargesian, E
F. Nargesian, E. Zhu, R. J. Miller, K. Q. Pu, P. C. Aro- cena, Data lake management: challenges and opportuni- ties, Proc. VLDB Endow. 12 (12) (2019) 1986–1989
2019
-
[65]
Gartner, Gartner says beware of the data lake fallacy, [Online; accessed 29-Jun-2025] (2014)
I. Gartner, Gartner says beware of the data lake fallacy, [Online; accessed 29-Jun-2025] (2014). URLhttps://www.gartner.com/ en/newsroom/press-releases/ 2014-07-28-gartner-says-beware-of-the-data-lake-fallacy
2025
-
[66]
Dixon, Data lakes revisited, [Online; accessed 22-Oct- 2024] (2014)
J. Dixon, Data lakes revisited, [Online; accessed 22-Oct- 2024] (2014). URLhttps://jamesdixon.wordpress.com/2014/ 09/25/data-lakes-revisited/
2024
-
[67]
M. Jarke, C. Quix, On warehouses, lakes, and spaces: The changing role of conceptual modeling for data integration, in: J. Cabot, C. Gómez, O. Pastor, M. Sancho, E. Teniente (Eds.), Conceptual Mod- eling Perspectives, Springer, 2017, pp. 231–245. doi:10.1007/978-3-319-67271-7\_16. URLhttps://doi.org/10.1007/ 978-3-319-67271-7_16
-
[68]
Hoseini, M
S. Hoseini, M. Ibbels, C. Quix, Enhancing machine learning capabilities in data lakes with automl and llms, in: European Conference on Advances in Databases and Information Systems, Springer, 2024, pp. 184–198. 21/25 Preprint submitted to arXiv
2024
-
[69]
Bacco, A
M. Bacco, A. Kocian, S. Chessa, A. Crivello, P. Barsoc- chi, What are data spaces? systematic survey and future outlook, Data in Brief 57 (2024) 110969
2024
-
[70]
C. Quix, R. Hai, I. Vatov, Metadata extraction and man- agement in data lakes with GEMMS, Complex Syst. In- formatics Model. Q. (2016)
2016
-
[71]
P. N. Sawadogo, E. Scholly, C. Favre, E. Ferey, S. Loud- cher, J. Darmont, Metadata systems for data lakes: mod- els and features, in: European conference on advances in databases and information systems, Springer, 2019, pp. 440–451
2019
-
[72]
Eichler, C
R. Eichler, C. Giebler, C. Gröger, H. Schwarz, B. Mitschang, Handle-a generic metadata model for data lakes, in: International Conference on Big Data Analyt- ics and Knowledge Discovery, Springer, 2020, pp. 73– 88
2020
-
[73]
Ouellette, A
P. Ouellette, A. Sciortino, F. Nargesian, B. G. Bashardoost, E. Zhu, K. Q. Pu, R. J. Miller, Ronin: data lake exploration, Proceedings of the VLDB Endowment 14 (12) (2021)
2021
-
[74]
N. W. Paton, J. Chen, Z. Wu, Dataset discovery and ex- ploration: A survey, ACM Computing Surveys 56 (4) (2023) 1–37
2023
-
[75]
M. N. Mami, D. Graux, S. Scerri, H. Jabeen, S. Auer, J. Lehmann, Squerall: Virtual ontology-based access to heterogeneous and large data sources, in: C. Ghi- dini, O. Hartig, M. Maleshkova, V . Svátek, I. F. Cruz, A. Hogan, J. Song, M. Lefrançois, F. Gandon (Eds.), The Semantic Web - ISWC 2019 - 18th International Seman- tic Web Conference, Auckland, New ...
2019
-
[76]
Bagozi, D
A. Bagozi, D. Bianchini, V . D. Antonellis, M. Garda, M. Melchiori, Personalised exploration graphs on se- mantic data lakes, in: Proc. OTM Conf., V ol. 11877 of LNCS, Springer, 2019, pp. 22–39.doi:10.1007/ 978-3-030-33246-4\_2
2019
-
[77]
Sharma, Architecting Data Lakes—Data Manage- ment Architectures for Advanced Business Use Cases, 2nd Edition, O’Reilly Media, Sebastopol, CA, USA, 2018
B. Sharma, Architecting Data Lakes—Data Manage- ment Architectures for Advanced Business Use Cases, 2nd Edition, O’Reilly Media, Sebastopol, CA, USA, 2018
2018
-
[78]
Patel, G
P. Patel, G. Wood, A. Diaz, Data lake governance best practices, Dzone Guide Big Data—Data Sci. Adv. Anal. 4 (2017) 6–7
2017
-
[79]
Ravat, Y
F. Ravat, Y . Zhao, Data lakes: Trends and perspectives, in: Database and Expert Systems Applications: 30th In- ternational Conference, DEXA 2019, Linz, Austria, Au- gust 26–29, 2019, Proceedings, Part I 30, Springer, 2019, pp. 304–313
2019
-
[80]
Madsen, How to Build an Enterprise Data Lake: Important Considerations before Jumping, Third Nature Inc., San Mateo, CA, USA, 2015
M. Madsen, How to Build an Enterprise Data Lake: Important Considerations before Jumping, Third Nature Inc., San Mateo, CA, USA, 2015
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.