AI-Assisted Variance Reduction in Randomized Experiments
Pith reviewed 2026-06-27 17:18 UTC · model grok-4.3
The pith
Researchers can include AI predictions as ordinary covariates in regression adjustment to reduce variance in randomized experiments, with the estimator automatically reverting to the simple difference in means when the predictions add no in
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Including AI-generated predictions as covariates in ordinary least-squares regression adjustment reduces the variance of treatment-effect estimators in randomized experiments while preserving the do-no-harm property that the adjusted estimator equals the unadjusted difference-in-means estimator whenever the predictions are uninformative; the same guarantee does not hold for variants of prediction-powered inference.
What carries the argument
Regression adjustment that treats pre-determined AI predictions as fixed, exogenous covariates, delivering the do-no-harm reversion to the unadjusted estimator.
If this is right
- The adjusted estimator remains unbiased under the usual assumptions for regression adjustment in randomized experiments.
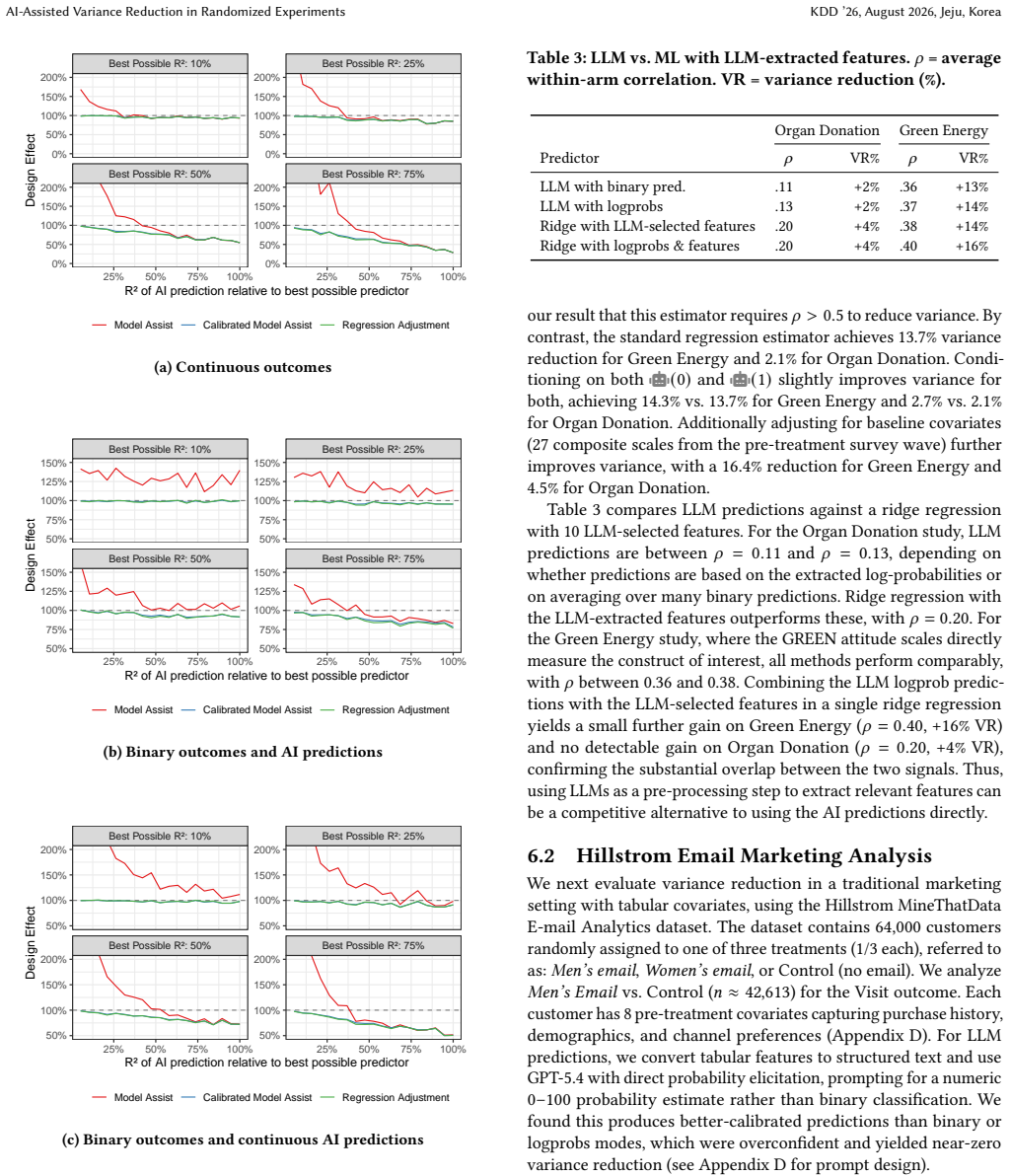
- Variance reduction is larger when the AI predictions are more accurate and when the study contains substantial unstructured inputs such as text.
- No specialized estimators are required; standard regression software suffices.
- Discrete LLM outputs can be converted to continuous scores for use as covariates, and LLMs can also be used to create auxiliary features from unstructured data.
Where Pith is reading between the lines
- The same adjustment could be applied using predictions from any source that is fixed before randomization, not only generative AI.
- Routine inclusion of such predictions would lower the sample sizes needed to detect effects of a given size in text-rich domains.
- The approach invites direct comparison of variance reduction across different types of unstructured data inputs within the same experiment.
Load-bearing premise
The AI predictions must be fixed before treatment assignment occurs and can be treated as ordinary exogenous covariates without introducing bias.
What would settle it
An experiment in which adding the AI predictions either increases the variance of the treatment-effect estimator relative to the unadjusted estimator or produces a point estimate that differs from the unadjusted estimator when the predictions carry no information about the outcome.
Figures
read the original abstract
Generative AI and large language models can produce realistic predictions of human behavior from rich, unstructured inputs with little to no task-specific training data. Recent work uses these ``digital twin'' predictions to supplement human responses in surveys and experiments. We study the special case of using AI-generated predictions to reduce variance in randomized experiments. We argue that doing so requires no new estimators and that researchers can simply include AI predictions as covariates in standard regression adjustment, analogous to adjusting for a prognostic score. A benefit of this approach is a ``do no harm'' property whereby the adjusted estimator reverts to the unadjusted difference in means when predictions are uninformative. Other methods, such as variants of prediction-powered inference, do not have this guarantee. We provide implementation guidance, including how to obtain continuous scores from discrete LLM outputs and how to use LLMs to featurize unstructured inputs as auxiliary covariates. We demonstrate these ideas in simulations and three empirical applications: a survey mega-study, an email marketing A/B test, and a large-scale technology platform experiment. Overall, efficiency gains are real if modest, with greater benefits in studies that contain substantial text and other unstructured data. We also confirm the do no harm property empirically. Given these gains and limited costs, we recommend adjusting for AI-generated predictions as a regular empirical practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that AI-generated predictions (e.g., from LLMs) can be used as covariates in standard OLS regression adjustment for estimating average treatment effects in randomized experiments, requiring no new estimators. It emphasizes a 'do no harm' property in which the adjusted estimator reverts to the unadjusted difference-in-means estimator when the predictions are uninformative. The approach is positioned as analogous to prognostic score adjustment, with implementation guidance on handling discrete LLM outputs and featurizing unstructured inputs. Efficiency gains are demonstrated via simulations and three empirical applications (survey mega-study, email marketing A/B test, large-scale tech platform experiment), with greater benefits when unstructured data are present; the do-no-harm property is also confirmed empirically.
Significance. If the central assumptions hold, the result offers a low-cost, immediately implementable way to improve precision in RCTs by leveraging generative AI on rich inputs, without introducing bias or requiring custom inference procedures. The explicit 'do no harm' guarantee and empirical verification distinguish it from alternatives like prediction-powered inference. Credit is due for grounding the contribution in standard econometric tools rather than claiming novel estimators, and for providing concrete guidance plus multi-application evidence.
major comments (2)
- [Methods / prediction generation and exogeneity discussion] The unbiasedness and do-no-harm property (abstract and methods) rest on the assumption that AI predictions are strictly pre-determined, fixed before treatment assignment, and exogenous to the assignment mechanism. The manuscript must specify how the full prediction pipeline (prompt construction, input featurization from unstructured data, any fine-tuning or shared training data) is isolated from post-randomization information or features correlated with outcomes; without this, the exogeneity claim is load-bearing and unverified.
- [Simulations and empirical applications] Simulation design and empirical robustness (simulation section and § on applications): the abstract and main text provide insufficient detail on data exclusion rules, exact procedure for generating AI predictions within the simulations, and sensitivity checks to alternative prompt or featurization choices. This undermines verification of the claimed efficiency gains and do-no-harm confirmation.
minor comments (2)
- [Methods] Clarify notation for the regression adjustment estimator (likely Eq. in methods) to explicitly show the 'do no harm' reversion when the AI covariate coefficient is zero or the covariate is uninformative.
- [Results / tables] Figure or table presenting efficiency gains across applications could include a column for the unadjusted estimator variance to make the incremental benefit transparent.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and recommendation for minor revision. We address each major comment below and will incorporate clarifications and additional details into the revised manuscript.
read point-by-point responses
-
Referee: The unbiasedness and do-no-harm property (abstract and methods) rest on the assumption that AI predictions are strictly pre-determined, fixed before treatment assignment, and exogenous to the assignment mechanism. The manuscript must specify how the full prediction pipeline (prompt construction, input featurization from unstructured data, any fine-tuning or shared training data) is isolated from post-randomization information or features correlated with outcomes; without this, the exogeneity claim is load-bearing and unverified.
Authors: We agree that the exogeneity assumption is central and that the manuscript would benefit from greater specificity on how the prediction pipeline is isolated from post-randomization information. In the revision we will expand the methods section to explicitly state that all AI predictions are generated exclusively from pre-randomization inputs and baseline covariates, with the entire pipeline (prompt engineering, featurization of unstructured data, and any model calls) completed prior to treatment assignment. We will also add practical guidance on avoiding leakage, noting that our applications rely on off-the-shelf models without fine-tuning or shared post-randomization data. revision: yes
-
Referee: Simulation design and empirical robustness (simulation section and § on applications): the abstract and main text provide insufficient detail on data exclusion rules, exact procedure for generating AI predictions within the simulations, and sensitivity checks to alternative prompt or featurization choices. This undermines verification of the claimed efficiency gains and do-no-harm confirmation.
Authors: We acknowledge that the current description of the simulation design and prediction-generation procedure lacks sufficient granularity for full replicability and robustness verification. In the revised manuscript we will add an appendix (or expanded methods subsection) that details the exact data exclusion rules applied, the precise prompts and featurization steps used to generate AI predictions in the simulations, and the procedure for obtaining continuous scores from discrete outputs. We will also include sensitivity checks across alternative prompts and featurization choices to confirm that the reported efficiency gains and do-no-harm property are not sensitive to these implementation decisions. revision: yes
Circularity Check
No circularity; applies standard regression adjustment to pre-treatment covariates
full rationale
The paper's central claim is that AI predictions can be used as covariates in ordinary regression adjustment for ATE estimation in RCTs, inheriting the known unbiasedness and do-no-harm properties of that estimator when the covariate is fixed before randomization. This is a direct application of textbook results on covariate adjustment under randomization (no new derivation or fitted parameters are introduced). The abstract and description contain no self-citations that bear the load of the main result, no redefinition of quantities in terms of themselves, and no renaming of known patterns as novel. The exogeneity of the AI predictions is stated as an assumption rather than derived, so it does not create circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption OLS regression adjustment is valid for estimating treatment effects when covariates are pre-treatment and fixed before randomization
Reference graph
Works this paper leans on
-
[1]
Digital twin generators for disease modeling.arXiv preprint arXiv:2405.01488, 2024
Nameyeh Alam, Jake Basilico, Daniele Bertolini, Satish Casie Chetty, Heather D’Angelo, Ryan Douglas, Charles K Fisher, Franklin Fuller, Melissa Gomes, Rishabh Gupta, et al. Digital twin generators for disease modeling.arXiv preprint arXiv:2405.01488, 2024
arXiv 2024
-
[2]
Prediction-powered inference.Science, 382(6671):669–674, 2023
Anastasios N Angelopoulos, Stephen Bates, Clara Fannjiang, Michael I Jordan, and Tijana Zrnic. Prediction-powered inference.Science, 382(6671):669–674, 2023
2023
-
[3]
Lisa P Argyle, Ethan C Busby, Nancy Fulda, Joshua R Gubler, Christopher Rytting, and David Wingate. Out of one, many: Using language models to simulate human samples.Political Analysis, 31(3):337–351, 2023. doi: 10.1017/pan.2023.2
-
[4]
Meshi Bashari, Yonghoon Lee, Roy Maor Lotan, Edgar Dobriban, and Yaniv Romano. Statistical inference leveraging synthetic data with distribution-free guarantees.arXiv preprint arXiv:2509.20345, 2025
Pith/arXiv arXiv 2025
-
[5]
Inference for regression with variables generated by AI or machine learning
Laura Battaglia, Timothy Christensen, Stephen Hansen, and Szymon Sacher. Inference for regression with variables generated by AI or machine learning. arXiv preprint arXiv:2402.15585, 2024
arXiv 2024
-
[6]
Using GPT for market research
James Brand, Ayelet Israeli, and Donald Ngwe. Using GPT for market research. SSRN working paper, 2023. Harvard Business School Marketing Unit Working Paper 23-062
2023
-
[7]
The mixed subjects de- sign: Treating large language models as potentially informative observations
David Broska, Michael Howes, and Austin van Loon. The mixed subjects de- sign: Treating large language models as potentially informative observations. Sociological Methods & Research, 54(3):1074–1109, 2025
2025
-
[8]
Lipton, Rachel Leah Childers, and Bryan Wilder
Yewon Byun, Shantanu Gupta, Zachary C. Lipton, Rachel Leah Childers, and Bryan Wilder. Valid inference with imperfect synthetic data. InAdvances in Neural Information Processing Systems, 2025. NeurIPS 2025
2025
-
[9]
Exact bias correction for linear adjustment of randomized controlled trials.Econometrica, 92(5):1503–1519, 2024
Haoge Chang, Joel A Middleton, and P M Aronow. Exact bias correction for linear adjustment of randomized controlled trials.Econometrica, 92(5):1503–1519, 2024
2024
-
[10]
Cohen and Colin B
Peter L. Cohen and Colin B. Fogarty. No-harm calibration for generalized Oaxaca–Blinder estimators.Biometrika, 111(1):331–338, 2024. doi: 10.1093/ biomet/asad036
2024
-
[11]
Jamie Cummins. The threat of analytic flexibility in using large language models to simulate human data: A call to attention.arXiv preprint arXiv:2509.13397, 2025
Pith/arXiv arXiv 2025
-
[12]
Piersilvio De Bartolomeis, Javier Abad, Guanbo Wang, Konstantin Donhauser, Raymond M. Duch, Fanny Yang, and Issa J. Dahabreh. Efficient Randomized Experiments Using Foundation Models, February 2025. URL http://arxiv.org/abs/ 2502.04262. arXiv:2502.04262 [cs]
arXiv 2025
-
[13]
A review of generalizability and transportability
Irina Degtiar and Sherri Rose. A review of generalizability and transportability. Annual Review of Statistics and Its Application, 10(1):501–524, 2023
2023
-
[14]
Improving the sensitivity of online controlled experiments by utilizing pre-experiment data
Alex Deng, Ya Xu, Ron Kohavi, and Toby Walker. Improving the sensitivity of online controlled experiments by utilizing pre-experiment data. InProceedings of the Sixth ACM International Conference on Web Search and Data Mining, pages 123–132. ACM, 2013. doi: 10.1145/2433396.2433413
-
[15]
Alex Deng, Luke Hagar, Nathaniel Stevens, Tatiana Xifara, Lo-Hua Yuan, and Amit Gandhi. From augmentation to decomposition: A new look at CUPED in 2023.arXiv preprint arXiv:2312.02935, 2023. doi: 10.48550/arXiv.2312.02935
-
[16]
Chapman and Hall/CRC, 2024
Peng Ding.A first course in causal inference. Chapman and Hall/CRC, 2024
2024
-
[17]
Naoki Egami, Musashi Hinck, Brandon Stewart, and Hanying Wei. Using im- perfect surrogates for downstream inference: Design-based supervised learning for social science applications of large language models.Advances in Neural Information Processing Systems, 36:68589–68601, 2023
2023
-
[18]
Chris Engh and P. M. Aronow. Using LLMs to directly guess conditional expecta- tions can improve efficiency in causal estimation.arXiv preprint arXiv:2510.09684, 2025
arXiv 2025
-
[19]
David A Freedman. On regression adjustments in experiments with several treatments.The Annals of Applied Statistics, 2(1):176–196, 2008. doi: 10.1214/07- AOAS143
work page doi:10.1214/07- 2008
-
[20]
George Gui and Seungwoo Kim. Leveraging LLMs to improve experimental design: A generative stratification approach.arXiv preprint arXiv:2509.25709, 2025
arXiv 2025
-
[21]
The generalized Oaxaca-Blinder estimator
Kevin Guo and Guillaume Basse. The generalized Oaxaca-Blinder estimator. Journal of the American Statistical Association, 118(541):524–536, 2023. doi: 10. 1080/01621459.2021.1941053
arXiv 2023
-
[22]
Wenxuan Guo, JungHo Lee, and Panos Toulis. ML-assisted randomization tests for detecting treatment effects in A/B experiments.arXiv preprint arXiv:2501.07722, 2025
arXiv 2025
-
[23]
Machine learning for variance reduction in online experiments,
Yongyi Guo, Dominic Coey, Mikael Konutgan, Wenting Li, Chris Schoener, and Matt Goldman. Machine learning for variance reduction in online experiments,
-
[24]
URL https://arxiv.org/abs/2106.07263
-
[25]
The prognostic analogue of the propensity score.Biometrika, 95 (2):481–488, 2008
Ben B Hansen. The prognostic analogue of the propensity score.Biometrika, 95 (2):481–488, 2008
2008
-
[26]
Tabpfn: A transformer that solves small tabular classification problems in a second
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. Tabpfn: A transformer that solves small tabular classification problems in a second. InInternational Conference on Learning Representations, 2023
2023
-
[27]
John J Horton. Large language models as simulated economic agents: What can we learn from homo silicus?arXiv preprint arXiv:2301.07543, 2023
arXiv 2023
-
[28]
Cambridge University Press, 2015
Guido W Imbens and Donald B Rubin.Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction. Cambridge University Press, 2015
2015
-
[29]
Lihua Lei and Peng Ding. Regression adjustment in completely randomized experiments with a diverging number of covariates.Biometrika, 108(4):815–828, KDD ’26, August 2026, Jeju, Korea David Arbour, Eli Ben-Michael, Avi Feller, Apoorva Lal, and Lo-Hua Yuan 2021
2026
-
[30]
Rerandomization and regression adjustment.Journal of the Royal Statistical Society Series B: Statistical Methodology, 82(1):241–268, 2020
Xinran Li and Peng Ding. Rerandomization and regression adjustment.Journal of the Royal Statistical Society Series B: Statistical Methodology, 82(1):241–268, 2020
2020
-
[31]
Optimizing language models for human preferences is a causal inference problem
Victoria Lin, Eli Ben-Michael, and Louis-Philippe Morency. Optimizing language models for human preferences is a causal inference problem. InProceedings of the Fortieth Conference on Uncertainty in Artificial Intelligence, volume 244 ofUAI ’24, pages 2250–2270, Barcelona, Spain, 2024. JMLR.org
2024
-
[32]
Agnostic notes on regression adjustments to experimental data: Reexamining Freedman’s critique.The Annals of Applied Statistics, 7(1):295–318,
Winston Lin. Agnostic notes on regression adjustments to experimental data: Reexamining Freedman’s critique.The Annals of Applied Statistics, 7(1):295–318,
-
[33]
doi: 10.1214/12-AOAS583
-
[34]
Estimation based on nearest neighbor matching: from density ratio to average treatment effect.Econometrica, 91(6): 2187–2217, 2023
Zhexiao Lin, Peng Ding, and Fang Han. Estimation based on nearest neighbor matching: from density ratio to average treatment effect.Econometrica, 91(6): 2187–2217, 2023
2023
-
[35]
Large language models: An applied econometric framework.arXiv preprint arXiv:2412.07031, 2024
Jens Ludwig, Sendhil Mullainathan, and Ashesh Rambachan. Large language models: An applied econometric framework.arXiv preprint arXiv:2412.07031, 2024
arXiv 2024
-
[36]
Daniel Molitor and Samantha Gold. Anytime-valid inference in adaptive experi- ments: Covariate adjustment and balanced power.arXiv preprint arXiv:2506.20523, 2025
arXiv 2025
-
[37]
Digital Twins as Funhouse Mirrors: Five Key Distortions
Tianyi Peng, George Gui, Melanie Brucks, Daniel J Merlau, Grace Jiarui Fan, Malek Ben Sliman, Eric J Johnson, Abdullah Althenayyan, Silvia Bellezza, Dante Donati, et al. Digital twins as funhouse mirrors: Five key distortions.arXiv preprint arXiv:2509.19088, 2025. doi: 10.48550/arXiv.2509.19088
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.19088 2025
-
[38]
Prediction-powered inference for clinical trials: application to linear covariate adjustment.BMC Medical Research Methodology, 25(1):204, 2025
Pierre-Emmanuel Poulet, Maylis Tran, Sophie Tezenas du Montcel, Bruno Dubois, Stanley Durrleman, Bruno Jedynak, and Alzheimer’s Disease Neuroimaging Initiative. Prediction-powered inference for clinical trials: application to linear covariate adjustment.BMC Medical Research Methodology, 25(1):204, 2025
2025
-
[39]
Xinrui Ruan, Xinwei Ma, Yingfei Wang, Waverly Wei, and Jingshen Wang. Can language models boost the power of randomized experiments without statistical bias?arXiv preprint arXiv:2510.05545, 2025
arXiv 2025
-
[40]
Autopersuade: A framework for evaluating and explaining persuasive arguments
Till Raphael Saenger, Musashi Hinck, Justin Grimmer, and Brandon M Stewart. Autopersuade: A framework for evaluating and explaining persuasive arguments. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 16325–16342, 2024
2024
-
[41]
Springer Science & Business Media, 2003
Carl-Erik Särndal, Bengt Swensson, and Jan Wretman.Model assisted survey sampling. Springer Science & Business Media, 2003
2003
-
[42]
Is regression adjustment supported by the neyman model for causal inference?Journal of Statistical Planning and Inference, 140(1):246–259, 2010
Peter Z Schochet. Is regression adjustment supported by the neyman model for causal inference?Journal of Statistical Planning and Inference, 140(1):246–259, 2010
2010
-
[43]
Increasing the efficiency of random- ized trial estimates via linear adjustment for a prognostic score.The International Journal of Biostatistics, 18(2):329–356, 2022
Alejandro Schuler, David Walsh, Diana Hall, Jon Walsh, Charles Fisher, Criti- cal Path for Alzheimer’s Disease, Alzheimer’s Disease Neuroimaging Initiative, and Alzheimer’s Disease Cooperative Study. Increasing the efficiency of random- ized trial estimates via linear adjustment for a prognostic score.The International Journal of Biostatistics, 18(2):329–...
2022
-
[44]
Yulin Shao, Liangbo Lyu, Menggang Yu, and Bingkai Wang. Benchmarking covariate-adjustment strategies for randomized clinical trials.arXiv preprint arXiv:2602.00434, 2026
Pith/arXiv arXiv 2026
-
[45]
Kluger, Harsh Parikh, and Tian Gu
Yilin Song, Dan M. Kluger, Harsh Parikh, and Tian Gu. Demystifying prediction powered inference.arXiv preprint arXiv:2601.20819, 2026
arXiv 2026
-
[46]
Model-assisted analyses of cluster-randomized ex- periments.Journal of the Royal Statistical Society Series B: Statistical Methodology, 83(5):994–1015, 2021
Fangzhou Su and Peng Ding. Model-assisted analyses of cluster-randomized ex- periments.Journal of the Royal Statistical Society Series B: Statistical Methodology, 83(5):994–1015, 2021
2021
-
[47]
Calibeating prediction-powered inference.arXiv preprint arXiv:2604.21260, 2026
Lars van der Laan and Mark van der Laan. Calibeating prediction-powered inference.arXiv preprint arXiv:2604.21260, 2026
Pith/arXiv arXiv 2026
-
[48]
Causal inference: A statistical learning approach, 2024
Stefan Wager. Causal inference: A statistical learning approach, 2024. A Derivations of Estimator Properties This appendix provides additional details on the bias and variance results summarized in Table 1. Throughout, we define 𝜅(𝑧, 𝑧 ′)= Var(♂robot(𝑧′))/Var(𝑌(𝑧)) as the ratio of prediction variance to out- come variance. Digital twin estimator.The digit...
2024
-
[49]
(♂robot(1)− ♂robotobs 1 )−( ˆ𝛽0−𝛽 ∗
-
[50]
You are an AI assistant. Your task is to answer the ‘New Survey Question’ as if you are the person described in the ‘Persona Profile’
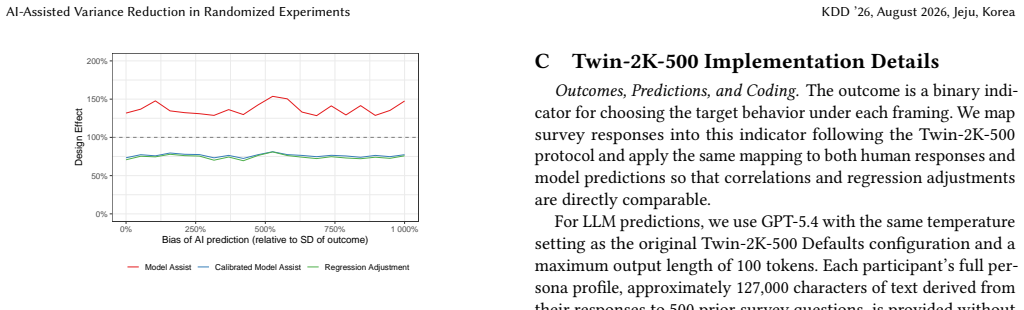
(♂robot(0)− ♂robotobs 0 )=𝑂 𝑝 (1/𝑛). B Additional simulations Varying prediction bias.The simulations in Section 5 fix the AI- prediction bias parameter𝑏= 0. Here we vary𝑏 from 0 to 1 (in units of the outcome standard deviation) to illustrate how each estimator responds to systematic over- or under-prediction by the AI. Figure 2 reports the design effect ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.