PALUTE: Processing-In-Memory Acceleration via Lookup Table for Edge LLM Inference
Pith reviewed 2026-06-27 15:06 UTC · model grok-4.3
The pith
PALUTE performs LLM inference on edge devices by running lookup tables directly inside monolithic 3D DRAM.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
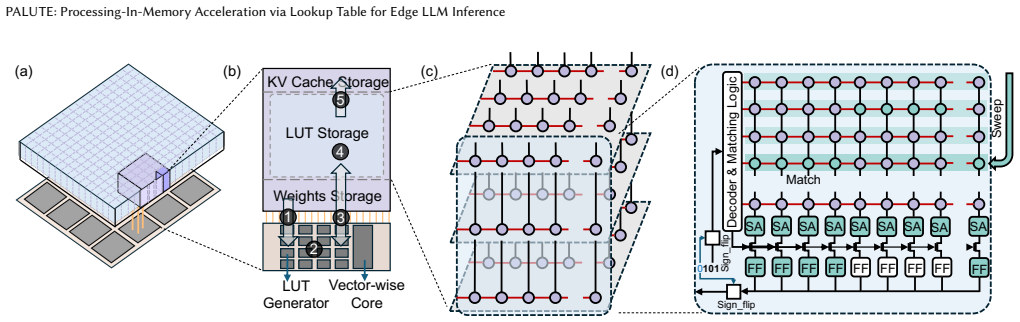
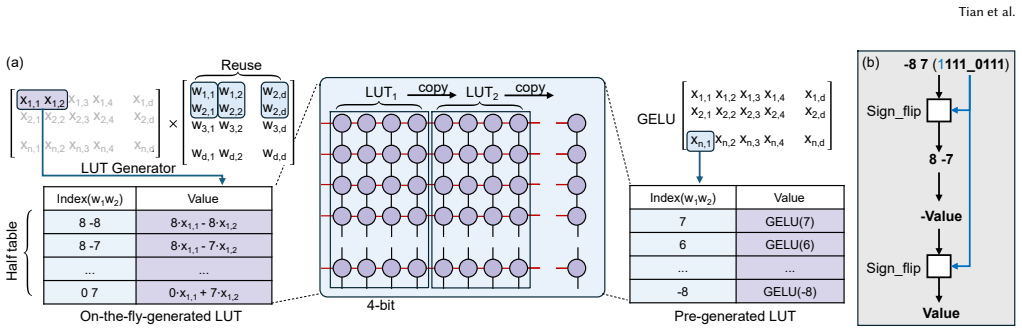
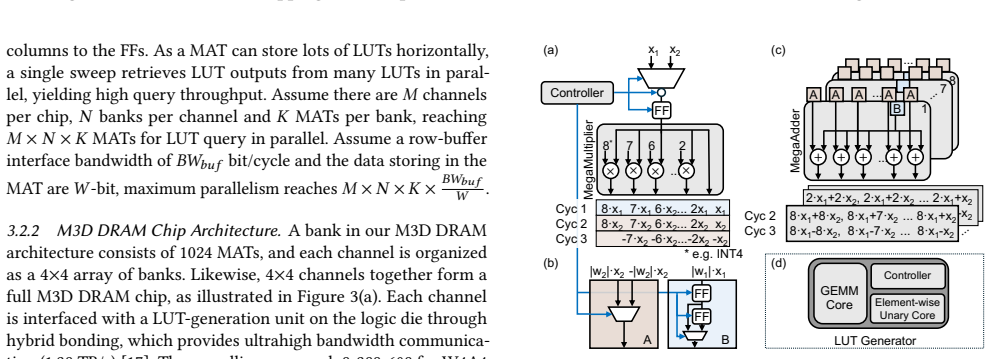
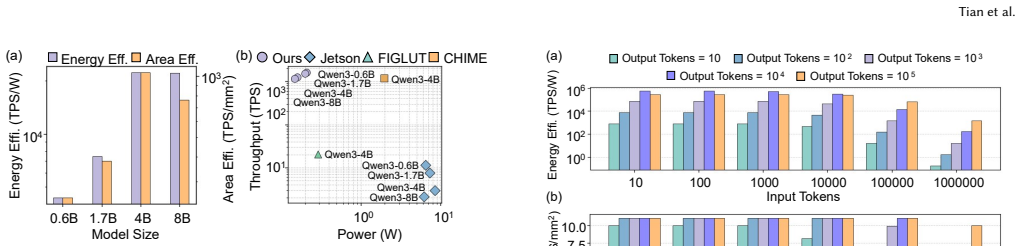
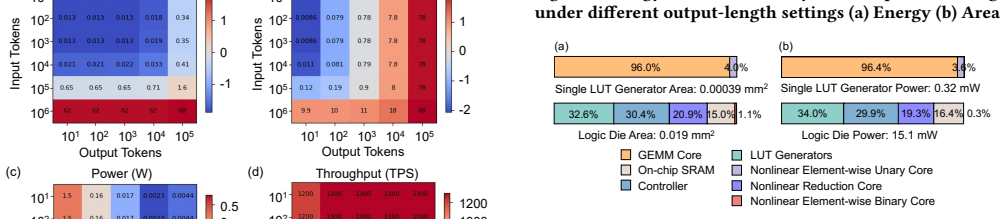
PALUTE is a lookup-table processing-in-memory accelerator built on monolithic 3D DRAM that executes in-DRAM LUT queries by exploiting the vertical organization of memory array tiles, supported by a near-memory LUT generator for GEMM and unary nonlinear operators plus system-level tiering and scheduling, delivering 1,264 TPS end-to-end at 0.16 W with 12.8× better energy efficiency than CHIME and 1.6× better than FIGLUT under W4A4 quantization on Qwen3-4B models.
What carries the argument
In-DRAM LUT queries that use the vertical stacking of M3D DRAM memory array tiles to deliver high parallelism at low area cost, paired with a near-memory LUT generator.
If this is right
- Dequantization and nonlinear operator costs no longer dominate quantized LLM inference latency.
- Edge systems can sustain higher token rates inside the same power envelope.
- Lookup-table methods become practical for real-time use once generation and query latency are brought inside memory.
- Data movement between memory tiers can be minimized through explicit tiering and scheduling policies.
Where Pith is reading between the lines
- The same vertical-tile lookup approach could be tested on other memory technologies that allow dense vertical access.
- If table generation cost scales with model size, hybrid schemes that cache only frequent operators may be needed for larger models.
- The reported area efficiency gain suggests the design could free silicon for additional on-chip buffers or sensors in edge packages.
Load-bearing premise
Cycle-accurate simulation and RTL synthesis will match the power, latency, and throughput of an actual fabricated chip without large unmodeled overheads.
What would settle it
Fabricate the PALUTE design, run end-to-end inference on Qwen3-4B under W4A4, and measure whether real throughput reaches 1,264 TPS at 0.16 W and whether energy and area gains match the simulated multiples over CHIME, FIGLUT, and PIMPAL.
Figures
read the original abstract
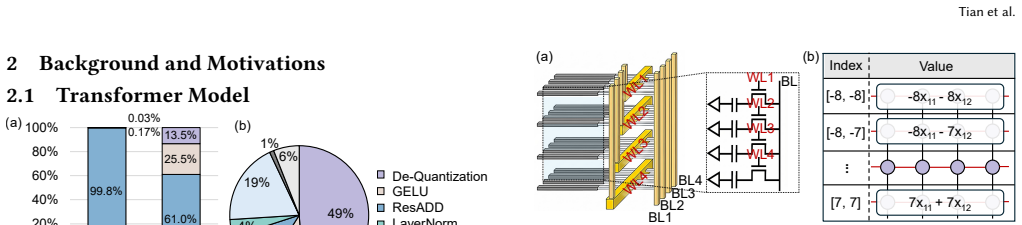
Large language models are increasingly deployed on edge devices with tight power and area budgets. While mixed-precision GEMM reduces arithmetic complexity, quantized inference is often dominated by dequantization and nonlinear operators. Lookup Table (LUT)-based method mitigates these costs by precomputing outputs and replacing repeated arithmetic with table lookups, but existing designs incur significant capacity and lookup-latency overheads. This paper presents PALUTE, a LUT-based Processing-In-Memory accelerator built on Monolithic 3D DRAM for efficient edge LLM inference. PALUTE enables in-DRAM LUT queries that exploit the vertical organization of M3D DRAM memory array tiles to achieve high parallelism with low area overhead. A near-memory LUT generator supports low-latency LUT generation for both GEMM and element-wise unary nonlinear operators, while a system-level tiering and scheduling strategy minimizes data movement across memory tiers. Evaluation using cycle-accurate simulation and RTL synthesis shows that PALUTE achieves 1,264 TPS end-to-end throughput at 0.16 W, improving energy efficiency by 12.8$\times$ over CHIME and 1.6$\times$ over FIGLUT, improving area efficiency by 2.0$\times$ over PIMPAL under W4A4 across Qwen3-4B models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PALUTE, a LUT-based processing-in-memory accelerator on monolithic 3D DRAM for edge LLM inference. It exploits vertical M3D DRAM tile organization for in-DRAM lookups, includes a near-memory LUT generator for GEMM and nonlinear operators, and uses tiered scheduling to minimize data movement. Cycle-accurate simulation and RTL synthesis results claim 1,264 TPS end-to-end throughput at 0.16 W, with 12.8× energy efficiency over CHIME, 1.6× over FIGLUT, and 2.0× area efficiency over PIMPAL under W4A4 for Qwen3-4B models.
Significance. If the reported efficiency numbers hold under realistic conditions, the work would advance PIM techniques for quantized edge inference by addressing dequantization and nonlinearity overheads via low-overhead in-DRAM LUTs. The vertical stacking exploitation and near-memory generation are distinctive elements that could influence future edge accelerator designs.
major comments (1)
- [Evaluation] Evaluation (cycle-accurate simulation and RTL synthesis results): The headline metrics (1,264 TPS at 0.16 W and the 12.8×/1.6×/2.0× efficiency gains) rest entirely on simulation without post-layout extraction, thermal coupling analysis between M3D tiers, or process-variation modeling. This is load-bearing for the central claim because unmodeled effects that increase effective lookup latency or static power by more than ~15 % would invalidate the comparisons to CHIME, FIGLUT, and PIMPAL.
minor comments (1)
- [Abstract] Abstract: no error bars, confidence intervals, or explicit modeling assumptions are stated for the reported throughput and power figures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our evaluation methodology. We address the single major comment point-by-point below.
read point-by-point responses
-
Referee: [Evaluation] Evaluation (cycle-accurate simulation and RTL synthesis results): The headline metrics (1,264 TPS at 0.16 W and the 12.8×/1.6×/2.0× efficiency gains) rest entirely on simulation without post-layout extraction, thermal coupling analysis between M3D tiers, or process-variation modeling. This is load-bearing for the central claim because unmodeled effects that increase effective lookup latency or static power by more than ~15 % would invalidate the comparisons to CHIME, FIGLUT, and PIMPAL.
Authors: We agree that post-layout extraction, thermal coupling analysis, and process-variation modeling would strengthen the absolute accuracy of the reported numbers. Our evaluation follows the standard methodology in the PIM and accelerator architecture literature (cycle-accurate simulation + RTL synthesis), which is used by the baseline works we compare against (CHIME, FIGLUT, PIMPAL). All comparisons are therefore performed under consistent modeling assumptions. We acknowledge that unmodeled physical effects could shift absolute values; however, the relative gains arise primarily from architectural differences (in-DRAM LUT organization, near-memory generation, and tiered scheduling) that are captured at the cycle-accurate level. In the revised manuscript we will add a new subsection under Evaluation that (1) explicitly states the modeling assumptions and their consistency with prior work, (2) provides a sensitivity analysis showing how ±15 % variations in lookup latency or static power would affect the reported speedups, and (3) discusses why full post-layout/thermal analysis is left for future tape-out studies. We believe this revision directly addresses the concern while preserving the core claims. revision: partial
Circularity Check
No circularity; results are direct outputs of cycle-accurate simulation and RTL synthesis.
full rationale
The paper reports throughput, power, and efficiency numbers exclusively from cycle-accurate simulation plus RTL synthesis of the PALUTE design on M3D DRAM. No equations, fitted parameters, or first-principles derivations appear in the abstract or description; the central claims are empirical evaluation outputs rather than predictions that reduce to inputs by construction. No self-citation chains or ansatzes are invoked to justify the performance figures. The evaluation methodology is therefore self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Monolithic 3D DRAM vertical organization enables high-parallelism low-overhead LUT queries
invented entities (1)
-
PALUTE accelerator architecture
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L. Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. 2024. QuaRot: outlier-free 4-bit inference in rotated LLMs. InProceedings of the 38th International Conference on Neural Information Processing Systems (NeurIPS)
2024
-
[2]
Kazi Asifuzzaman, Narasinga Miniskar, Aaron Young, Frank Liu, and Jeffrey Vetter. 2022. A survey on processing-in-memory techniques: Advances and challenges.Memories - Materials, Devices, Circuits and Systems4 (12 2022), 100022. doi:10.1016/j.memori.2022.100022
-
[3]
Amirali Boroumand, Saugata Ghose, Youngsok Kim, Rachata Ausavarungnirun, Eric Shiu, Rahul Thakur, Daehyun Kim, Aki Kuusela, Allan Knies, Parthasarathy Ranganathan, and Onur Mutlu. 2018. Google Workloads for Consumer Devices: Mitigating Data Movement Bottlenecks. InProceedings of the Twenty-Third In- ternational Conference on Architectural Support for Prog...
2018
-
[4]
Yanru Chen, Runyang Tian, Yue Pan, Zheyu Li, Weihong Xu, and Tajana Rosing
-
[5]
CHIME: Chiplet-based Heterogeneous Near-Memory Acceleration for Edge Multimodal LLM Inference. arXiv:2601.19908 [cs.AR]
-
[6]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
-
[7]
InAdvances in Neural Information Processing Systems (NeurIPS)
FLASHATTENTION: fast and memory-efficient exact attention with IO- awareness. InAdvances in Neural Information Processing Systems (NeurIPS)
-
[8]
Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdh- ery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, and Pete Florence. 2023. PaLM-E: an e...
2023
-
[9]
Kim, Geraldo F
Joao Dinis Ferreira, Gabriel Falcao, Juan Gomez-Luna, Mohammed Alser, Lois Orosa, Mohammad Sadrosadati, Jeremie S. Kim, Geraldo F. Oliveira, Taha Shahroodi, Anant Nori, and Onur Mutlu. 2022. pLUTo: Enabling Massively Parallel Computation in DRAM via Lookup Tables. In2022 IEEE/ACM Interna- tional Symposium on Microarchitecture (MICRO). 900–919
2022
-
[10]
Amir Gholami, Sehoon Kim, Zhen Dong, Zhewei Yao, Michael W. Mahoney, and Kurt Keutzer. 2021. A Survey of Quantization Methods for Efficient Neural Network Inference. arXiv:2103.13630 [cs.CV] https://arxiv.org/abs/2103.13630
-
[11]
Philip Wong, and Shimeng Yu
Po-Kai Hsu, Janak Sharda, Xiangjin Wu, H.-S. Philip Wong, and Shimeng Yu
-
[12]
Monolithic 3D Stackable DRAM.IEEE Nanotechnology Magazine19, 2 (2025), 7–16
2025
-
[13]
Andrei Ivanov, Nikoli Dryden, Tal Ben-Nun, Shigang Li, and Torsten Hoefler
-
[14]
Data Movement Is All You Need: A Case Study on Optimizing Transformers. arXiv:2007.00072 [cs.LG]
-
[15]
Yoonho Jang, Hyeongjun Cho, Yesin Ryu, Jungrae Kim, and Seokin Hong. 2025. PIMPAL: Accelerating LLM Inference on Edge Devices via In-DRAM Arithmetic Lookup. InProceedings of the 62nd Annual ACM/IEEE Design Automation Confer- ence (DAC)
2025
-
[16]
Mahoney, and Kurt Keutzer
Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, and Kurt Keutzer
-
[17]
I-BERT: Integer-only BERT Quantization.International Conference on Machine Learning (ICML)(2021)
2021
-
[18]
Mahoney, Yakun Sophia Shao, and Amir Gholami
Sehoon Kim, Coleman Hooper, Thanakul Wattanawong, Minwoo Kang, Ruohan Yan, Hasan Genc, Grace Dinh, Qijing Huang, Kurt Keutzer, Michael W. Mahoney, Yakun Sophia Shao, and Amir Gholami. 2023. Full Stack Optimization of Trans- former Inference. InArchitecture and System Support for Transformer Models (ASSYST @ ISCA)
2023
-
[19]
Donghyuk Lee, Gennady Pekhimenko, Samira Khan, Saugata Ghose, and Onur Mutlu. 2016. Simultaneous Multi-Layer Access: Improving 3D-Stacked Memory Bandwidth at Low Cost.ACM Transactions on Architecture and Code Optimization 12, 4 (2016)
2016
- [20]
-
[21]
Onur Mutlu, Saugata Ghose, Juan Gómez-Luna, and Rachata Ausavarungnirun
-
[22]
InGreat Lakes Symposium on VLSI (GLSVLSI)
Processing Data Where It Makes Sense in Modern Computing Systems: Enabling In-Memory Computation. InGreat Lakes Symposium on VLSI (GLSVLSI). 5–6
-
[23]
Dimin Niu, Shuangchen Li, Yuhao Wang, Wei Han, Zhe Zhang, Yijin Guan, Tianchan Guan, Fei Sun, Fei Xue, Lide Duan, Yuanwei Fang, Hongzhong Zheng, Xiping Jiang, Song Wang, Fengguo Zuo, Yubing Wang, Bing Yu, Qiwei Ren, and Yuan Xie. 2022. 184QPS/W 64Mb/mm2 3D Logic-to-DRAM Hybrid Bonding with Process-Near-Memory Engine for Recommendation System. InIEEE Inter...
2022
-
[24]
2022.Jetson Orin NX Series Datasheet
NVIDIA Corporation. 2022.Jetson Orin NX Series Datasheet. Technical Report
2022
-
[25]
Yue Pan, Zihan Xia, Po-Kai Hsu, Lanxiang Hu, Hyungyo Kim, Janak Sharda, Minx- uan Zhou, Nam Sung Kim, Shimeng Yu, Tajana Rosing, and Mingu Kang. 2025. Stratum: System-Hardware Co-Design with Tiered Monolithic 3D-Stackable DRAM for Efficient MoE Serving. InProceedings of the 58th IEEE/ACM Interna- tional Symposium on Microarchitecture (MICRO). 1–17
2025
-
[26]
Gunho Park, Hyeokjun Kwon, Jiwoo Kim, Jeongin Bae, Baeseong Park, Dongsoo Lee, and Youngjoo Lee. 2025. FIGLUT: An Energy-Efficient Accelerator Design for FP-INT GEMM Using Look-Up Tables. InIEEE International Symposium on High Performance Computer Architecture (HPCA). 1098–1111
2025
-
[27]
Guanqiao Qu, Qiyuan Chen, Wei Wei, Zheng Lin, Xianhao Chen, and Kaibin Huang. 2025. Mobile Edge Intelligence for Large Language Models: A Contem- porary Survey.IEEE Communications Surveys & TutorialsPP (01 2025), 1–1. doi:10.1109/COMST.2025.3527641
-
[28]
Tao Tu, Shekoofeh Azizi, Danny Driess, Mike Schaekermann, Mohamed Amin, Pi- Chuan Chang, Andrew Carroll, Chuck Lau, Ryutaro Tanno, Sofia Ira Ktena, Basil Mustafa, Aakanksha Chowdhery, Yun Liu, Simon Kornblith, David Fleet, Philip Mansfield, Sushant Prakash, Renee Wong, Sunny Virmani, and Vivek Natarajan
-
[29]
Towards generalist biomedical AI.arXiv preprint arXiv:2307.14334, 2023
Towards Generalist Biomedical AI. doi:10.48550/arXiv.2307.14334
-
[30]
Jianyu Wei, Shijie Cao, Ting Cao, Lingxiao Ma, Lei Wang, Yanyong Zhang, and Mao Yang. 2025. T-MAC: CPU Renaissance via Table Lookup for Low-Bit LLM Deployment on Edge. InProceedings of the Twentieth European Conference on Computer Systems(Rotterdam, Netherlands)(EuroSys ’25). Association for Computing Machinery, New York, NY, USA, 278–292
2025
-
[31]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Zhiheng Yue, Yang Wang, Chao Li, Shaojun Wei, Yang Hu, and Shouyi Yin
-
[33]
InProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture (MICRO)
3D-PATH: A Hierarchy LUT Processing-in-memory Accelerator with Thermal-aware Hybrid Bonding Integration. InProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture (MICRO). 78–93
-
[34]
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. 2023. A Survey of Large Language Models. http://arxiv.org/abs/2303.18223 arX...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Yilong Zhao, Chien-Yu Lin, Kan Zhu, Zihao Ye, Lequn Chen, Size Zheng, Luis Ceze, Arvind Krishnamurthy, Tianqi Chen, and Baris Kasikci. 2024. Atom: Low-Bit Quantization for Efficient and Accurate LLM Serving. InProceedings of Machine Learning and Systems (MLSys), Vol. 6. 196–209
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.