When More Cores Hurts: The Vector Database Scaling Paradox in HPC
Pith reviewed 2026-06-27 15:17 UTC · model grok-4.3
The pith
Scaling vector databases to more cores on HPC systems can reduce query throughput by up to 30.67%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
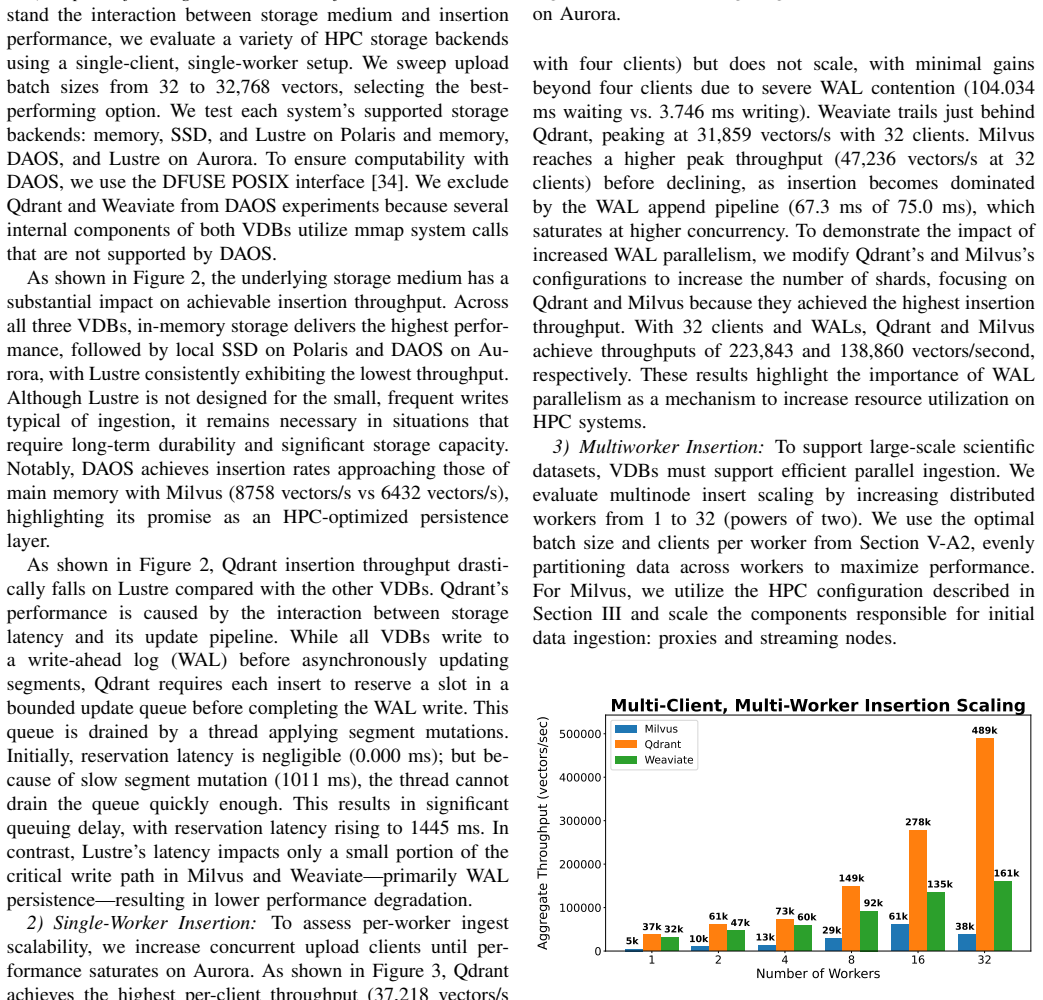
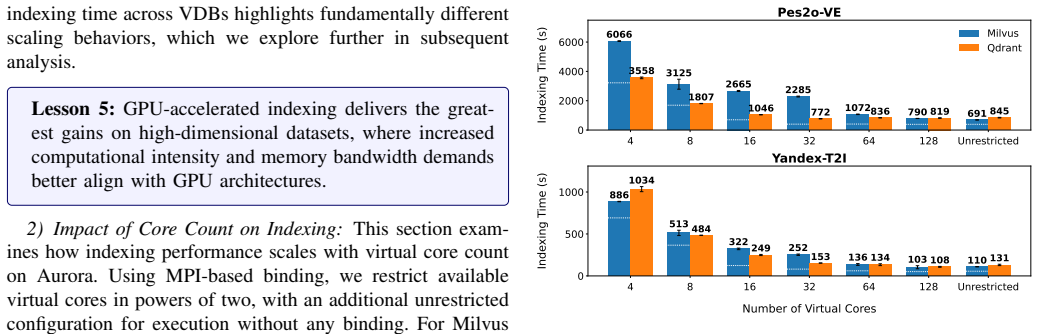
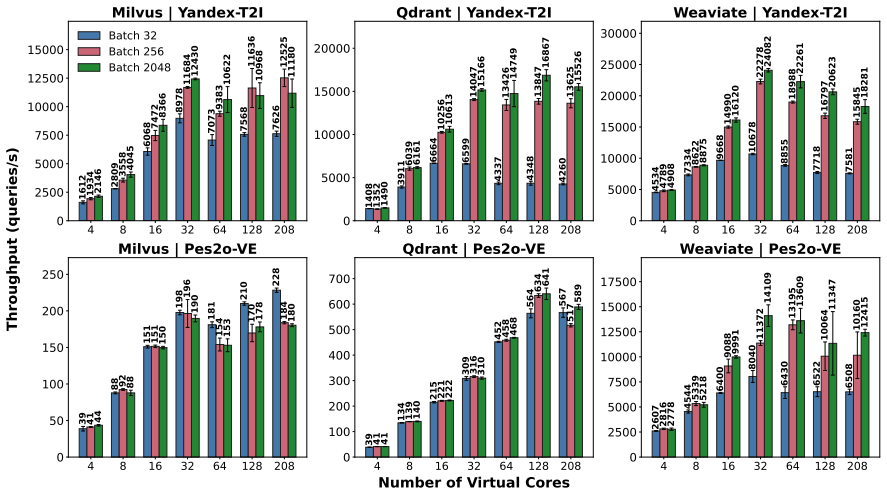
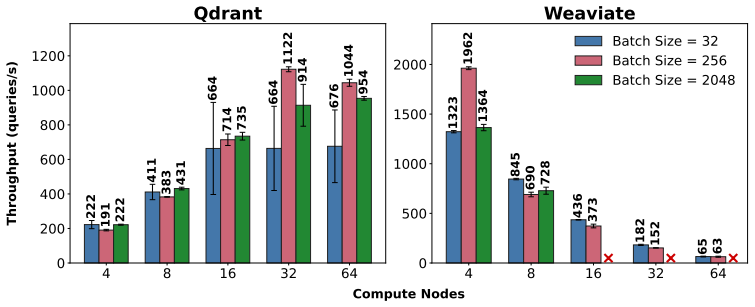
When Qdrant, Milvus, and Weaviate are run on production supercomputers with mixed read/write and write-then-read workloads, workload traits limit latency gains, extra cores cut query throughput by as much as 30.67 percent, and moving from 16 to 256 workers yields only a 5.46 times improvement. This scaling paradox reveals the basic mismatch between cloud-oriented vector database designs and HPC hardware.
What carries the argument
The scaling paradox, measured as sublinear or negative throughput change when increasing distributed workers on HPC nodes.
If this is right
- Cloud vector database designs require HPC-specific adaptations to avoid throughput loss with added cores.
- Workload patterns such as mixed read/write operations constrain how much latency improves at scale.
- New vector database architectures must account for HPC interconnects and node memory hierarchies.
- Scientific applications relying on vector search will face performance ceilings until the mismatch is addressed.
Where Pith is reading between the lines
- The same core-count penalty may appear when other cloud data services are moved to tightly coupled HPC networks.
- Targeted changes to sharding or indexing that reduce cross-node traffic could be tested directly on the reported hardware.
Load-bearing premise
The chosen workload patterns, benchmarks, multimodal embeddings, and scientific dataset represent the demands of emerging scientific AI workloads on HPC systems.
What would settle it
A follow-up run on the same hardware and workloads that achieves near-linear throughput gains up to 256 workers would falsify the paradox.
Figures


read the original abstract
Vector databases have been designed and optimized for cloud environments; however, emerging scientific AI workloads (e.g., molecular search, meteorological trajectory detection, and literature-driven hypothesis generation) demand efficient, scalable execution on HPC systems. We present a large-scale evaluation of three state-of-the-art vector databases -- Qdrant, Milvus, and Weaviate -- on two production supercomputers, scaling to 256 distributed workers across 64 compute nodes. We evaluate representative workload patterns -- mixed read/write and write-then-read -- using popular benchmarks, multimodal embeddings, and a novel real-world scientific dataset. Our results reveal that workload characteristics can limit latency reduction, additional cores can reduce query throughput by up to 30.67%, and scaling from 16 to 256 workers (16x) only yields a 5.46x improvement. This scaling paradox exposes the fundamental mismatch between cloud-oriented designs and HPC systems, highlighting the need for new, HPC-aware vector database designs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates three vector databases (Qdrant, Milvus, Weaviate) on two production supercomputers, scaling to 256 distributed workers across 64 nodes. Using mixed read/write and write-then-read workload patterns with popular benchmarks, multimodal embeddings, and a novel real-world scientific dataset, it reports that additional cores can reduce query throughput by up to 30.67% and that scaling from 16 to 256 workers yields only a 5.46x improvement, concluding that this scaling paradox exposes a fundamental mismatch between cloud-oriented vector database designs and HPC systems for emerging scientific AI workloads.
Significance. If the reported scaling behaviors hold under representative conditions, the work is significant for identifying concrete performance limitations when deploying vector databases on HPC platforms for scientific applications such as molecular search and trajectory detection. The large-scale empirical measurements on production systems provide practical evidence that could motivate development of HPC-aware vector database architectures.
major comments (3)
- [Abstract and §4 (Results)] Abstract and §4 (Results): The headline quantitative claims (throughput reduction of up to 30.67% and 5.46x speedup from 16x workers) are stated without error bars, number of experimental repetitions, statistical tests, or variance measures. This directly affects verifiability of the central empirical claim that additional cores hurt performance.
- [§3 (Workloads and Dataset)] §3 (Workloads and Dataset): The conclusion of a fundamental cloud-HPC mismatch rests on the assertion that the chosen mixed read/write and write-then-read patterns, benchmarks, multimodal embeddings, and novel scientific dataset are representative of emerging scientific AI workloads. No quantitative validation, access-pattern comparison, or justification against real tasks (e.g., molecular search or hypothesis generation) is provided, leaving the representativeness assumption untested.
- [§2 (Experimental Setup)] §2 (Experimental Setup): Hardware configuration details, node specifications, network topology, and exclusion criteria for the two supercomputers are not supplied, preventing independent assessment or reproduction of the scaling measurements.
minor comments (2)
- [Abstract] Abstract: The two production supercomputers are not named; early identification would improve clarity.
- Figure captions and tables: Axis labels and legends should explicitly state whether throughput is normalized or absolute to avoid ambiguity in interpreting the negative scaling results.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help improve the clarity and reproducibility of our work. We address each major point below.
read point-by-point responses
-
Referee: [Abstract and §4 (Results)] The headline quantitative claims (throughput reduction of up to 30.67% and 5.46x speedup from 16x workers) are stated without error bars, number of experimental repetitions, statistical tests, or variance measures. This directly affects verifiability of the central empirical claim that additional cores hurt performance.
Authors: We agree that including statistical measures would enhance verifiability. Although the experiments were repeated to ensure reliability, variance was not reported. In the revised manuscript, we will include error bars representing standard deviation, specify the number of repetitions (typically 5 per configuration), and note any statistical considerations in §4. revision: yes
-
Referee: [§3 (Workloads and Dataset)] The conclusion of a fundamental cloud-HPC mismatch rests on the assertion that the chosen mixed read/write and write-then-read patterns, benchmarks, multimodal embeddings, and novel scientific dataset are representative of emerging scientific AI workloads. No quantitative validation, access-pattern comparison, or justification against real tasks (e.g., molecular search or hypothesis generation) is provided, leaving the representativeness assumption untested.
Authors: The workload patterns were derived from standard vector database benchmarks and extended with a novel dataset from scientific applications. We will revise §3 to provide additional justification, including references to similar access patterns in molecular search literature, while acknowledging that a full quantitative validation against all possible scientific tasks is beyond the scope of this study. revision: partial
-
Referee: [§2 (Experimental Setup)] Hardware configuration details, node specifications, network topology, and exclusion criteria for the two supercomputers are not supplied, preventing independent assessment or reproduction of the scaling measurements.
Authors: We will expand §2 with comprehensive details on the hardware configurations of both supercomputers, including node specifications (CPU, memory, accelerators if any), network topology (e.g., InfiniBand), and any node selection criteria used during experiments. revision: yes
Circularity Check
No circularity: purely empirical measurement study
full rationale
The paper reports direct measurements of query throughput, latency, and scaling on production supercomputers using chosen benchmarks and workloads. No equations, derivations, fitted parameters, or predictions are present that could reduce results to inputs by construction. Claims rest on observed data from the evaluation rather than any self-referential modeling or self-citation chains. This is the expected outcome for an empirical scaling study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The evaluated workload patterns and datasets accurately reflect demands of scientific AI workloads on HPC systems.
Reference graph
Works this paper leans on
-
[1]
Efficient Estimation of Word Representations in Vector Space
T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” 2013. [Online]. Available: https://doi.org/10.48550/arXiv.1301.3781
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1301.3781 2013
-
[2]
GloVe: Global vectors for word representation,
J. Pennington, R. Socher, and C. Manning, “GloVe: Global vectors for word representation,” inProceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), A. Moschitti, B. Pang, and W. Daelemans, Eds. Doha, Qatar: Association for Computational Linguistics, Oct. 2014, pp. 1532–1543. [Online]. Available: https://doi.org/10....
-
[3]
Q. Hu, X. Li, Z. Li, and Y . Zhang, “Generative AI of pinecone vector retrieval and retrieval-augmented generation architecture: Financial data-driven intelligent customer recommendation system,” inProceedings of the 2025 2nd International Conference on Digital Economy and Computer Science, ser. DECS ’25. New York, NY , USA: Association for Computing Mach...
-
[4]
A curriculum recommendation system using a vector database for challenge-based learning,
O. B. Akhiiezer, O. A. Haluza, L. M. Lyubchyk, and V . Y . Sokol, “A curriculum recommendation system using a vector database for challenge-based learning,” inJournal of Physics Conference Series, ser. Journal of Physics Conference Series, vol. 3105. IOP, Sep. 2025, p. 012023. [Online]. Available: https://doi.org/10.1088/1742-6596/3105/1/012023
-
[5]
SMURF: federated multimodal retrieval for scientific data via embedding alignment,
S. Y . Oh, A. Khan, I. Foster, and K. Chard, “SMURF: federated multimodal retrieval for scientific data via embedding alignment,” in 2025 IEEE International Conference on eScience (eScience), 2025, pp. 452–459, https://doi.org/10.1109/eScience65000.2025.00091
-
[6]
B. Sarmah, B. Hall, R. Rao, S. Patel, S. Pasquali, and D. Mehta, “HybridRAG: integrating knowledge graphs and vector retrieval augmented generation for efficient information extraction,” 2024. [Online]. Available: https://doi.org/10.1145/3677052.3698671
-
[7]
A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models,
W. Fan, Y . Ding, L. Ning, S. Wang, H. Li, D. Yin, T.-S. Chua, and Q. Li, “A survey on RAG meeting LLMs: Towards retrieval- augmented large language models,” 2024. [Online]. Available: https://doi.org/10.1145/3637528.3671470
-
[8]
MemGPT: Towards LLMs as operating systems,
C. Packer, S. Wooders, K. Lin, V . Fang, S. G. Patil, I. Stoica, and J. E. Gonzalez, “MemGPT: Towards LLMs as operating systems,”
-
[9]
MemGPT: Towards LLMs as Operating Systems
[Online]. Available: https://doi.org/10.48550/arXiv.2310.08560
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.08560
-
[10]
MAGMA: A Multi-Graph based Agentic Memory Architecture for AI Agents
D. Jiang, Y . Li, G. Li, and B. Li, “MAGMA: a multi-graph based agentic memory architecture for AI agents,” 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2601.03236
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.03236 2026
-
[11]
MemoryBank: Enhancing Large Language Models with Long-Term Memory
W. Zhong, L. Guo, Q. Gao, H. Ye, and Y . Wang, “MemoryBank: Enhancing large language models with long-term memory,” 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2305.10250 11ChatGPT [104] was used to improve the grammar and phrasing of this work
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.10250 2023
-
[12]
A-MEM: Agentic Memory for LLM Agents
W. Xu, Z. Liang, K. Mei, H. Gao, J. Tan, and Y . Zhang, “A-mem: Agentic memory for LLM agents,” inAdvances in Neural Information Processing Systems, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2502.12110
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.12110 2025
-
[13]
Multi-modal foundation model for cosmological simulation data,
B. Xia, N. Ramachandra, A. I. Wells, S. Habib, and J. Wise, “Multi-modal foundation model for cosmological simulation data,”
-
[14]
Available: https://doi.org/10.48550/arXiv.2510.07684
[Online]. Available: https://doi.org/10.48550/arXiv.2510.07684
-
[15]
TRAKNN: efficient trajectory aware spatiotemporal kNN for rare meteorological trajectory detection,
G. Coulaud and D. Faranda, “TRAKNN: efficient trajectory aware spatiotemporal kNN for rare meteorological trajectory detection,”
-
[16]
Available: https://doi.org/10.48550/arXiv.2603.02059
[Online]. Available: https://doi.org/10.48550/arXiv.2603.02059
-
[17]
Dual retrieving and ranking medical large language model with retrieval augmented generation,
Q. Yang, H. Zuo, R. Su, H. Su, T. Zeng, H. Zhou, R. Wang, J. Chen, Y . Lin, Z. Chen, and T. Tan, “Dual retrieving and ranking medical large language model with retrieval augmented generation,”Scientific Reports, vol. 15, 05 2025. [Online]. Available: https://doi.org/10.1038/s41598-025-00724-w
-
[18]
Exploring distributed vector databases performance on HPC platforms: A study with Qdrant,
S. Ockerman, A. Gueroudji, S. Y . Oh, R. Underwood, N. Chia, K. Chard, R. Ross, and S. Venkataraman, “Exploring distributed vector databases performance on HPC platforms: A study with Qdrant,”
-
[19]
Available: https://doi.org/10.1145/3731599.3767404
[Online]. Available: https://doi.org/10.1145/3731599.3767404
-
[20]
A foundational multimodal vision language ai assistant for human pathology,
M. Y . Lu, B. Chen, D. F. K. Williamson, R. J. Chen, K. Ikamura, G. Gerber, I. Liang, L. P. Le, T. Ding, A. V . Parwani, and F. Mahmood, “A foundational multimodal vision language ai assistant for human pathology,” 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2312.07814
-
[21]
Automating literature screening and curation with applications to computational neuroscience,
Z. Ji, S. Guo, Y . Qiao, and R. A. McDougal, “Automating literature screening and curation with applications to computational neuroscience,”Journal of the American Medical Informatics Association, vol. 31, no. 7, pp. 1463–1470, 05 2024. [Online]. Available: https://doi.org/10.1093/jamia/ocae097
-
[22]
V . Eyring, S. Bony, G. A. Meehl, C. A. Senior, B. Stevens, R. J. Stouf- fer, and K. E. Taylor, “Overview of the coupled model intercompar- ison project phase 6 (CMIP6) experimental design and organization,” Geoscientific Model Development, vol. 9, no. 5, pp. 1937–1958, 2016, https://doi.org/10.5194/gmd-9-1937-2016
-
[23]
S. Fairley, E. Lowy-Gallego, E. Perry, and P. Flicek, “The International Genome Sample Resource (IGSR) collection of open human genomic variation resources,”Nucleic Acids Research, vol. 48, no. D1, pp. D941–D947, 10 2019. [Online]. Available: https://doi.org/10.1093/nar/gkz836
-
[24]
F. Cappello, R. Underwood, Y . Alexeev, A. Baker, E. Bozda ˘g, M. Burtscher, K. Chard, S. Di, K. G. Felker, P. C. O’Grady, H. Guo, Y . Huang, P. Jiang, S. Jin, P. Johansson, S. Li, X. Liang, E. Lindahl, P. Lindstrom, Z. Luki ´c, M. Lundborg, D. Lykov, M. Nagaso, K. Sato, A. Singh, S. W. Son, S. Song, W. Tang, D. Tao, J. Tian, K. Yoshii, and K. Zhao, “What...
-
[25]
Learned protein embeddings for machine learning,
K. K. Yang, Z. Wu, C. N. Bedbrook, and F. H. Arnold, “Learned protein embeddings for machine learning,”Bioinformatics, vol. 34, no. 15, pp. 2642–2648, 03 2018. [Online]. Available: https://doi.org/10.1093/bioinformatics/bty178
-
[26]
Y . S. Ko, J. Parkinson, and W. Wang, “Scalable embedding fusion with protein language models: insights from benchmarking text-integrated representations,”Briefings in Bioinformatics, vol. 27, no. 1, p. bbag014, 01 2026. [Online]. Available: https://doi.org/10.1093/bib/bbag014
-
[27]
When protein structure embedding meets large language models,
S. Ali, P. Chourasia, and M. Patterson, “When protein structure embedding meets large language models,”Genes, vol. 15, no. 1, 2024. [Online]. Available: https://doi.org/10.3390/genes15010025
-
[28]
Milvus: A purpose-built vector data management system,
J. Wang, X. Yi, R. Guo, H. Jin, P. Xu, S. Li, X. Wang, X. Guo, C. Li, X. Xu, K. Yu, Y . Yuan, Y . Zou, J. Long, Y . Cai, Z. Li, Z. Zhang, Y . Mo, J. Gu, R. Jiang, Y . Wei, and C. Xie, “Milvus: A purpose-built vector data management system,” inProceedings of the 2021 International Conference on Management of Data, ser. SIGMOD ’21. New York, NY , USA: Assoc...
-
[29]
[Online]
Vespa Team, “Vespa,” 2026. [Online]. Available: https://vespa.ai/
2026
-
[30]
[Online]
Qdrant Team, “Qdrant,” 2026. [Online]. Available: https://qdrant.tech/
2026
-
[31]
[Online]
Vald Team, “Vald,” 2026. [Online]. Available: https://vald.vdaas.org/
2026
-
[32]
Weaviate,
Weaviate Team, “Weaviate,” 2026. [Online]. Available: https: //weaviate.io/
2026
-
[33]
Billion-scale similarity search with GPUs
J. Johnson, M. Douze, and H. J ´egou, “Billion-scale similarity search with GPUs,” 2017, https://doi.org/10.48550/arXiv.1702.08734
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1702.08734 2017
-
[34]
Cloud-native vector search: A comprehensive performance analysis,
Z. Li, W. Ding, S. Huang, Z. Wang, Y . Lin, K. Wu, Y . Park, and J. Chen, “Cloud-native vector search: A comprehensive performance analysis,”
-
[35]
Available: https://doi.org/10.48550/arXiv.2511.14748
[Online]. Available: https://doi.org/10.48550/arXiv.2511.14748
-
[36]
Evaluating the cloud for capability class leadership workloads,
J. R. Lange and et al., “Evaluating the cloud for capability class leadership workloads,” Oak Ridge National Laboratory, Technical Report ORNL/TM-2023/3083, September 2023. [Online]. Available: https://doi.org/10.2172/2000306
-
[37]
Usability evaluation of cloud for HPC applications,
V . Sochat, D. Milroy, A. Sarkar, A. Marathe, and T. Patki, “Usability evaluation of cloud for HPC applications,” 2025. [Online]. Available: https://doi.org/10.1145/3731599.3767353
-
[38]
A performance comparison of hpc workloads on traditional and cloud-based HPC clusters,
V . Munhoz, A. Bonfils, M. Castro, and O. Mendizabal, “A performance comparison of hpc workloads on traditional and cloud-based HPC clusters,” in2023 International Symposium on Computer Architecture and High Performance Computing Workshops (SBAC-PADW), 2023, pp. 108–114, https://doi.org/10.1109/SBAC-PADW60351.2023.00026
-
[39]
Ceems: A resource manager agnostic en- ergy and emissions monitoring stack,
R. Latham, R. B. Ross, P. Carns, S. Snyder, K. Harms, K. Velusamy, P. Coffman, and G. McPheeters, “Initial experiences with DAOS object storage on Aurora,” inProceedings of the SC ’24 Workshops of the International Conference on High Performance Computing, Network, Storage, and Analysis, ser. SC- W ’24. IEEE Press, 2025, pp. 1304–1310. [Online]. Available...
-
[40]
AI and HPC applications on leadership computing platforms: Performance and scalability studies,
J. Kwack, C. Bertoni, U. Unnikrishnan, R. Balin, K. Hossain, Y . Ghadar, T. J. Williams, A. Bagusetty, M. Thavappiragasam, V . Hatanp ¨a¨a, A. Vasan, J. Tramm, and S. Parker, “AI and HPC applications on leadership computing platforms: Performance and scalability studies,” in2025 IEEE International Parallel and Distributed Processing Symposium (IPDPS), 202...
-
[41]
Polaris and acceptance testing
B. Homerding, B. Lenard, C. Blackworth, C. Holohan, A. Kulyavtsev, G. McPheeters, E. Pershy, P. Rich, D. Waldron, M. Zhang, K. Harms, T. Leggett, and W. Allcock, “Polaris and acceptance testing.” CUG, 2023, https://cug.org/proceedings/cug2023 proceedings/includes/files/ pap109s2-file1.pdf
2023
-
[42]
DAOS: A scale-out high performance storage stack for storage class memory,
Z. Liang, J. Lombardi, M. Chaarawi, and M. Hennecke, “DAOS: A scale-out high performance storage stack for storage class memory,” inSupercomputing Frontiers: 6th Asian Conference, SCFA 2020, Singapore, February 24–27, 2020, Proceedings. Berlin, Heidelberg: Springer-Verlag, 2020, pp. 40–54. [Online]. Available: https://doi.org/10.1007/978-3-030-48842-0 3
-
[43]
Efficient indexing of billion-scale datasets of deep descriptors,
A. B. Yandex and V . Lempitsky, “Efficient indexing of billion-scale datasets of deep descriptors,” in2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 2055–2063. [Online]. Available: https://doi.org/10.1109/CVPR.2016.226
-
[44]
Product quantization for nearest neighbor search,
H. J ´egou, M. Douze, and C. Schmid, “Product quantization for nearest neighbor search,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 33, no. 1, pp. 117–128, 2011. [Online]. Available: https://doi.org/10.1109/TPAMI.2010.57
-
[45]
dbpedia-entities- openai-1m,
Kumar Shivendu and Nirant Kasliwal, “dbpedia-entities- openai-1m,” 2023, https://huggingface.co/datasets/KShivendu/ dbpedia-entities-openai-1M
2023
-
[46]
MOFA: discovering materials for carbon capture with a GenAI- and simulation-based workflow,
X. Yan, N. Hudson, H. Park, D. Grzenda, J. G. Pauloski, M. Schwarting, H. Pan, H. Harb, S. Foreman, C. Knight, T. Gibbs, K. Chard, S. Chaudhuri, E. Tajkhorshid, I. Foster, M. Moosavi, L. Ward, and E. A. Huerta, “MOFA: discovering materials for carbon capture with a GenAI- and simulation-based workflow,” 2025. [Online]. Available: https://doi.org/10.48550/...
-
[47]
Osprey: Production-ready agentic AI for safety-critical control systems,
T. Hellert, J. Montenegro, and A. Sulc, “Osprey: Production-ready agentic AI for safety-critical control systems,” 2025. [Online]. Available: https://doi.org/10.1063/5.0306302
-
[48]
The Role of Local Intrinsic Dimensionality in Benchmarking Nearest Neighbor Search
M. Aum ¨uller and M. Ceccarello, “The role of local intrinsic dimensionality in benchmarking nearest neighbor search,” 2019. [Online]. Available: https://doi.org/10.48550/arXiv.1907.07387
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1907.07387 2019
-
[49]
On the correlation be- tween local intrinsic dimensionality and outlierness,
M. E. Houle, E. Schubert, and A. Zimek, “On the correlation be- tween local intrinsic dimensionality and outlierness,” inSimilarity Search and Applications: 11th International Conference, SISAP 2018, Lima, Peru, October 7–9, 2018, Proceedings. Berlin, Heidelberg: Springer-Verlag, 2018, pp. 177–191, https://dl.acm.org/doi/10.1007/ 978-3-030-02224-2 14
2018
-
[50]
O. P. Elliott and J. Clark, “The impacts of data, ordering, and intrinsic dimensionality on recall in hierarchical navigable small worlds,” in Proceedings of the 2024 ACM SIGIR International Conference on Theory of Information Retrieval, ser. ICTIR ’24. ACM, Aug. 2024, p. 25–33. [Online]. Available: https://doi.org/10.1145/3664190.3672512
-
[51]
The Lustre Storage Architecture
P. Braam, “The Lustre storage architecture,” 2019. [Online]. Available: https://doi.org/10.48550/arXiv.1903.01955
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1903.01955 2019
-
[52]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Y . Zhang, M. Li, D. Long, X. Zhang, H. Lin, B. Yang, P. Xie, A. Yang, D. Liu, J. Lin, F. Huang, and J. Zhou, “Qwen3 embedding: Advancing text embedding and reranking through foundation models,”arXiv preprint arXiv:2506.05176, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2506.05176
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.05176 2025
-
[53]
NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models
C. Lee, R. Roy, M. Xu, J. Raiman, M. Shoeybi, B. Catanzaro, and W. Ping, “NV-Embed: Improved techniques for training LLMs as generalist embedding models,” 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2405.17428
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.17428 2025
-
[54]
Scalable nearest neighbor algorithms for high dimensional data,
M. Muja and D. G. Lowe, “Scalable nearest neighbor algorithms for high dimensional data,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 36, pp. 2227–2240, 2014. [Online]. Available: https://doi.org/10.1109/TPAMI.2014.2321376
-
[55]
Similarity search in high dimensions via hashing,
A. Gionis, P. Indyk, and R. Motwani, “Similarity search in high dimensions via hashing,” inProceedings of the 25th International Conference on Very Large Data Bases, ser. VLDB ’99. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 1999, p. 518–529. [Online]. Available: https://dl.acm.org/doi/10.5555/645925.671516
-
[56]
Data structures and algorithms for nearest neighbor search in general metric spaces,
P. N. Yianilos, “Data structures and algorithms for nearest neighbor search in general metric spaces,” inProceedings of the Fourth Annual ACM-SIAM Symposium on Discrete Algorithms, ser. SODA ’93. USA: Society for Industrial and Applied Mathematics, 1993, pp. 311–321. [Online]. Available: https://dl.acm.org/doi/10.5555/313559.313789
-
[57]
Approximate nearest neighbors: towards removing the curse of dimensionality,
P. Indyk and R. Motwani, “Approximate nearest neighbors: towards removing the curse of dimensionality,” inProceedings of the Thirtieth Annual ACM Symposium on Theory of Computing, ser. STOC ’98. New York, NY , USA: Association for Computing Machinery, 1998, pp. 604–613. [Online]. Available: https://doi.org/10.1145/276698.276876
-
[58]
Multidimensional binary search trees used for associative searching,
J. L. Bentley, “Multidimensional binary search trees used for associative searching,”Commun. ACM, vol. 18, no. 9, pp. 509–517, Sep. 1975. [Online]. Available: https://doi.org/10.1145/361002.361007
-
[59]
R-trees: a dynamic index structure for spatial searching,
A. Guttman, “R-trees: a dynamic index structure for spatial searching,” inProceedings of the 1984 ACM SIGMOD International Conference on Management of Data, ser. SIGMOD ’84. New York, NY , USA: Association for Computing Machinery, 1984, pp. 47–57. [Online]. Available: https://doi.org/10.1145/602259.602266
-
[60]
Efficient in-memory inverted indexes: Theory and practice,
J. Mackenzie, S. MacAvaney, A. Mallia, and M. Siedlaczek, “Efficient in-memory inverted indexes: Theory and practice,” inProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, ser. SIGIR ’25. New York, NY , USA: Association for Computing Machinery, 2025, pp. 4102–4105. [Online]. Available: https://...
-
[61]
Near-optimal hashing algorithms for approximate nearest neighbor in high dimensions,
A. Andoni and P. Indyk, “Near-optimal hashing algorithms for approximate nearest neighbor in high dimensions,”Commun. ACM, vol. 51, no. 1, pp. 117–122, Jan. 2008. [Online]. Available: https://doi.org/10.1145/1327452.1327494
-
[62]
A survey on locality sensitive hashing algorithms and their applications,
O. Jafari, P. Maurya, P. Nagarkar, K. M. Islam, and C. Crushev, “A survey on locality sensitive hashing algorithms and their applications,”
-
[63]
Available: https://doi.org/10.48550/arXiv.2102.08942
[Online]. Available: https://doi.org/10.48550/arXiv.2102.08942
-
[64]
Diskann: Fast accurate billion-point nearest neighbor search on a single node,
S. J. Subramanya, Devvrit, R. Kadekodi, R. Krishaswamy, and H. V . Simhadri, “Diskann: Fast accurate billion-point nearest neighbor search on a single node,” inNeurIPS 2019, November 2019. [Online]. Available: https://dl.acm.org/doi/abs/10.5555/3454287.3455520
-
[65]
Fast approximate nearest neighbor search with the navigating spreading-out graph,
C. Fu, C. Xiang, C. Wang, and D. Cai, “Fast approximate nearest neighbor search with the navigating spreading-out graph,” 2025. [Online]. Available: https://doi.org/10.14778/3303753.3303754
-
[66]
CAGRA: highly parallel graph construction and approximate nearest neighbor search for GPUs,
H. Ootomo, A. Naruse, C. Nolet, R. Wang, T. Feher, and Y . Wang, “CAGRA: highly parallel graph construction and approximate nearest neighbor search for GPUs,” 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2308.15136
-
[67]
Y . A. Malkov and D. A. Yashunin, “Efficient and robust approxi- mate nearest neighbor search using hierarchical navigable small world graphs,” 2018, https://doi.org/10.48550/arXiv.1603.09320
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1603.09320 2018
-
[68]
Rapidsai/raft: RAFT contains fundamental widely-used algorithms and primitives for data science, graph and machine learning
Rapidsai, “Rapidsai/raft: RAFT contains fundamental widely-used algorithms and primitives for data science, graph and machine learning.” 2022. [Online]. Available: https://github.com/rapidsai/raft
2022
-
[69]
Chord: A scalable peer-to-peer lookup service for internet applications,
I. Stoica, R. Morris, D. Karger, M. F. Kaashoek, and H. Balakrishnan, “Chord: A scalable peer-to-peer lookup service for internet applications,” inProceedings of the 2001 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, ser. SIGCOMM ’01. New York, NY , USA: Association for Computing Machinery, 2001, pp. 1...
-
[70]
A. Cuzzocrea, “Vector databases for modelling, managing and querying big scientific data: Models, issues, paradigms,” inProceedings of the 37th International Conference on Scalable Scientific Data Manage- ment, ser. SSDBM ’25. New York, NY , USA: Association for Com- puting Machinery, 2025, https://doi.org/10.1145/3733723.3742469
-
[71]
Vector database management systems: Fundamental concepts, use-cases, and current challenges,
T. Taipalus, “Vector database management systems: Fundamental concepts, use-cases, and current challenges,”Cognitive Systems Research, vol. 85, p. 101216, 2024. [Online]. Available: https: //doi.org/10.48550/arXiv.2309.11322
-
[72]
J. J. Pan, J. Wang, and G. Li, “Survey of vector database management systems,” 2023. [Online]. Available: https://doi.org/10.48550/arXiv. 2310.14021
work page internal anchor Pith review doi:10.48550/arxiv 2023
-
[73]
A comprehensive survey on vector database: Storage and retrieval technique, challenge,
Y . Han, C. Liu, and P. Wang, “A comprehensive survey on vector database: Storage and retrieval technique, challenge,”arXiv preprint arXiv:2310.11703, 2023. [Online]. Available: https://doi.org/10.48550/ arXiv.2310.11703
arXiv 2023
-
[74]
Towards understanding systems trade-offs in retrieval-augmented generation model inference,
M. Shen, M. Umar, K. Maeng, G. E. Suh, and U. Gupta, “Towards understanding systems trade-offs in retrieval-augmented generation model inference,” 2024. [Online]. Available: https: //doi.org/10.48550/arXiv.2412.11854
-
[75]
A comprehensive survey and experimental comparison of graph-based approximate nearest neighbor search,
M. Wang, X. Xu, Q. Yue, and Y . Wang, “A comprehensive survey and experimental comparison of graph-based approximate nearest neighbor search,”Proc. VLDB Endow., vol. 14, no. 11, p. 1964–1978, Jul
1964
-
[76]
Available: https://doi.org/10.14778/3476249.3476255
[Online]. Available: https://doi.org/10.14778/3476249.3476255
-
[77]
ANN-Benchmarks: a benchmarking tool for approximate nearest neighbor algorithms,
M. Aum ¨uller, E. Bernhardsson, and A. Faithfull, “ANN-Benchmarks: a benchmarking tool for approximate nearest neighbor algorithms,”
-
[78]
ANN-Benchmarks: A Benchmarking Tool for Approximate Nearest Neighbor Algorithms
[Online]. Available: https://doi.org/10.48550/arXiv.1807.05614
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1807.05614
-
[79]
On- tology generation using large language models
G. Pandit, M. Roder, and A.-C. Ngonga Ngomo, “Evaluating approximate nearest neighbour search systems on knowledge graph embeddings,” inThe Semantic Web: 22nd European Semantic Web Conference, ESWC 2025, Portoroz, Slovenia, June 1–5, 2025, Proceed- ings, Part I. Berlin, Heidelberg: Springer-Verlag, 2025, pp. 59–76. [Online]. Available: https://doi.org/10....
-
[80]
RAGPerf: An end-to-end benchmarking framework for retrieval-augmented generation systems,
S. Li, Y . Zhou, Y . Xu, K. Chen, D. Waddington, S. Sundararaman, H. Franke, and J. Huang, “RAGPerf: An end-to-end benchmarking framework for retrieval-augmented generation systems,” 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2603.10765
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.