Mixture-of-Experts Transformer for Automatic Modulation Recognition
Pith reviewed 2026-06-27 15:55 UTC · model grok-4.3
The pith
Mixture-of-experts transformer with input-dependent gating outperforms static multi-scale methods on I/Q modulation signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
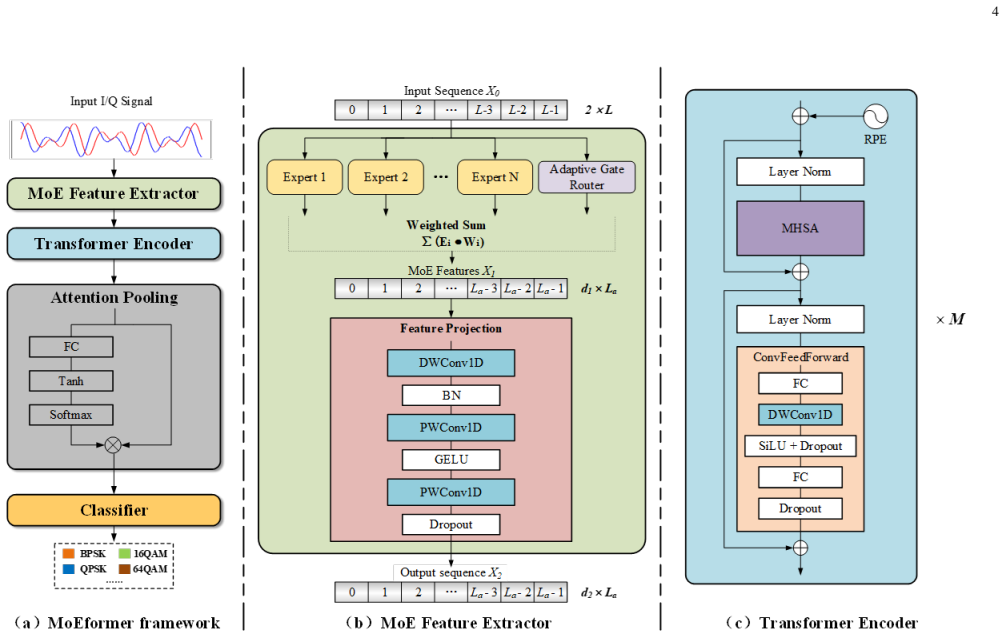
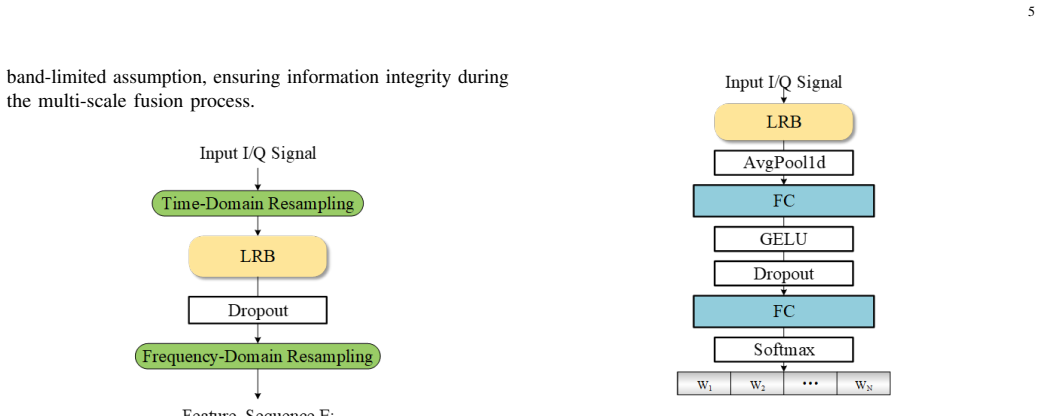
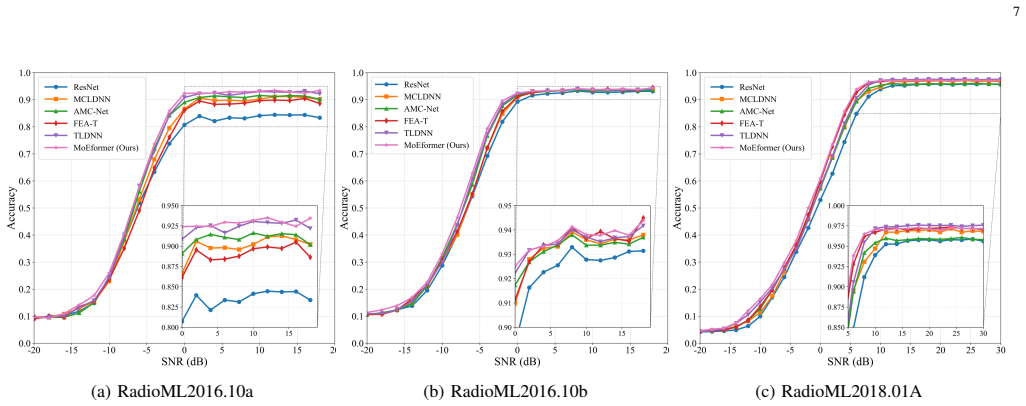
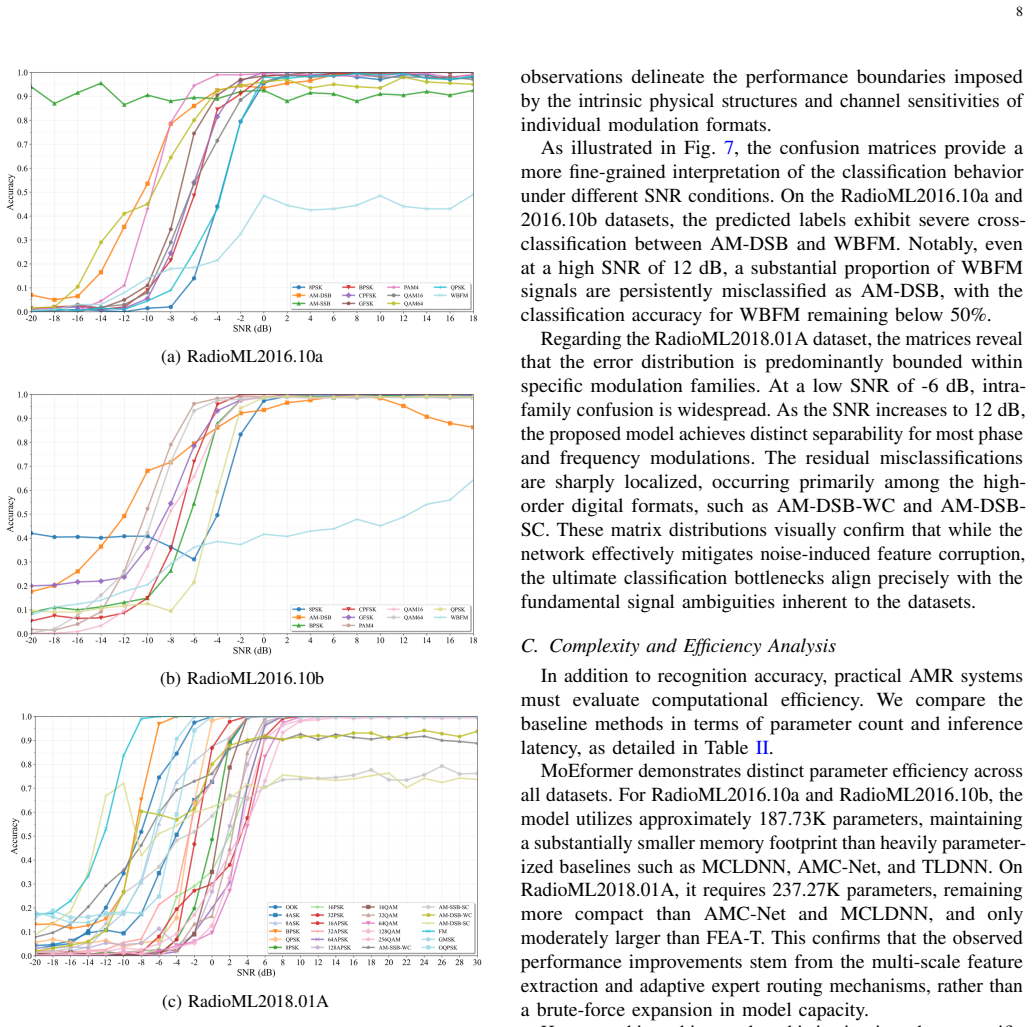
MoEformer is an adaptive Multi-Scale Mixture-of-Experts Transformer network that directly processes I/Q signals to preserve their temporal and phase structures. It constructs multi-scale expert views through temporal resampling, employs an input-dependent gating mechanism for dynamic expert fusion, and integrates Rotary Position Embeddings within Transformer encoders to capture both local and global temporal dependencies, achieving superior average recognition accuracies of 63.74 percent, 66.24 percent, and 64.22 percent on RadioML2016.10a, RadioML2016.10b, and RadioML2018.01A respectively.
What carries the argument
Input-dependent gating mechanism that dynamically selects and fuses multi-scale expert views produced by temporal resampling inside a RoPE-equipped Transformer encoder.
If this is right
- Higher recognition accuracy than competitive baselines on the three evaluated RadioML benchmarks.
- Direct I/Q processing that retains original temporal and phase information without intermediate transformations.
- Improved ability to handle dynamic temporal variations compared with static multi-scale fusion.
- A practical balance between recognition performance and overall model complexity.
Where Pith is reading between the lines
- The same resampling-plus-gating pattern could be tested on other time-series classification problems that involve variable-scale patterns.
- If the gate learns to ignore certain experts for particular signal classes, the architecture might be pruned for lower inference cost without retraining.
- Deployment on edge devices would require measuring whether the added gating computation offsets the accuracy gain under strict latency constraints.
Load-bearing premise
Dynamic selection of experts according to each input will adapt more effectively to changing temporal patterns in modulation signals than any fixed multi-scale fusion rule.
What would settle it
A controlled experiment on the same three RadioML datasets in which the input-dependent gate is replaced by a static average of the same experts and accuracy does not decrease would show that the gating step is not required.
Figures

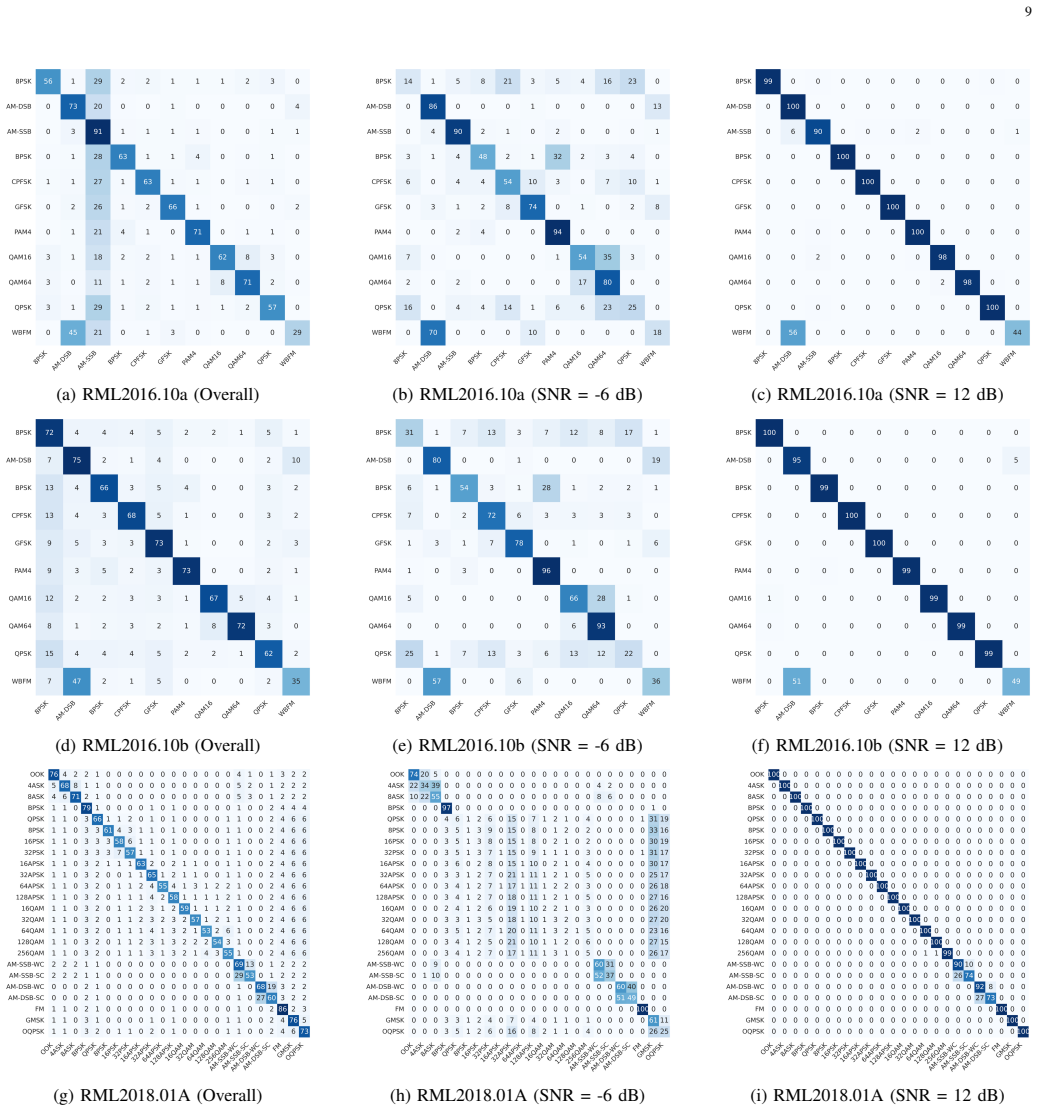

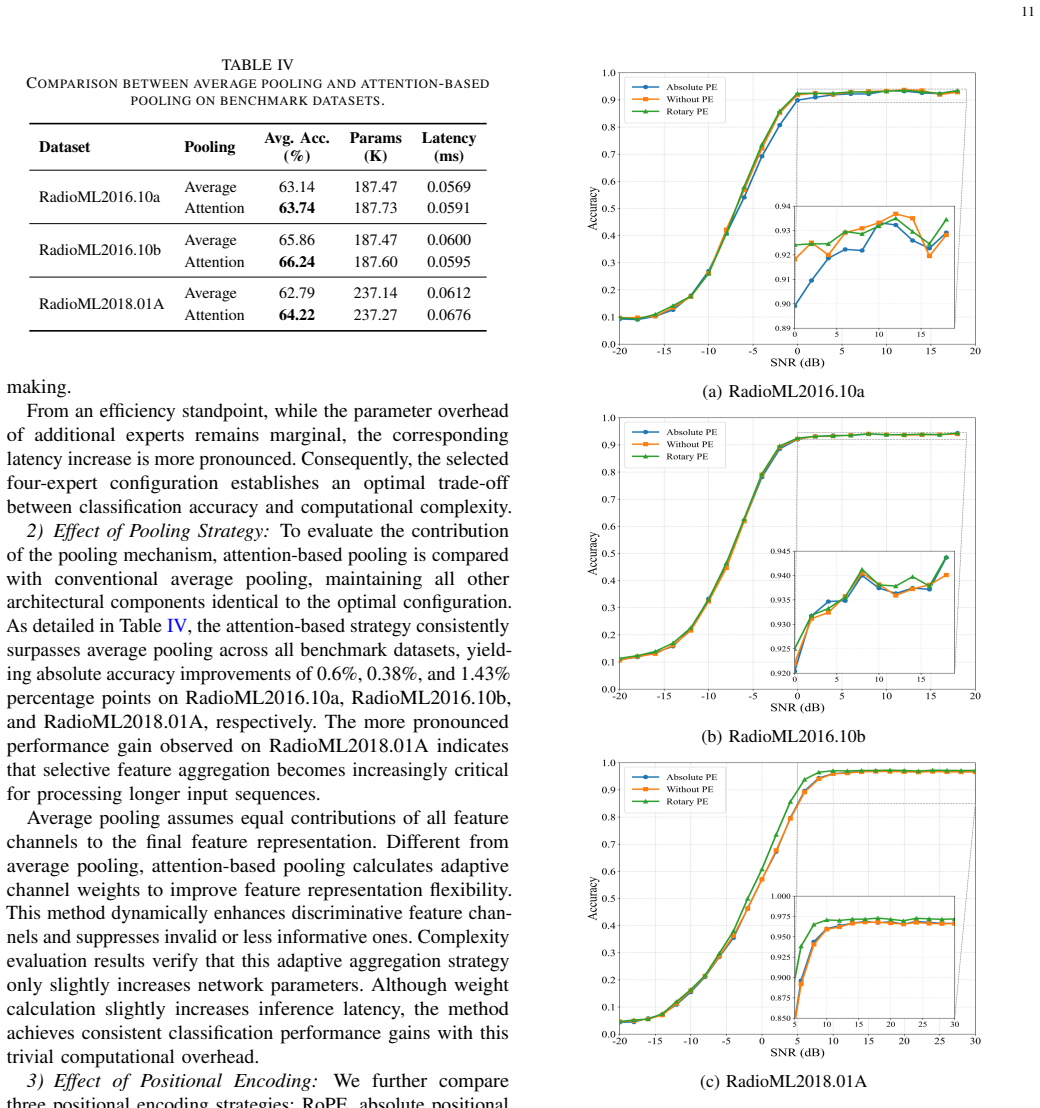
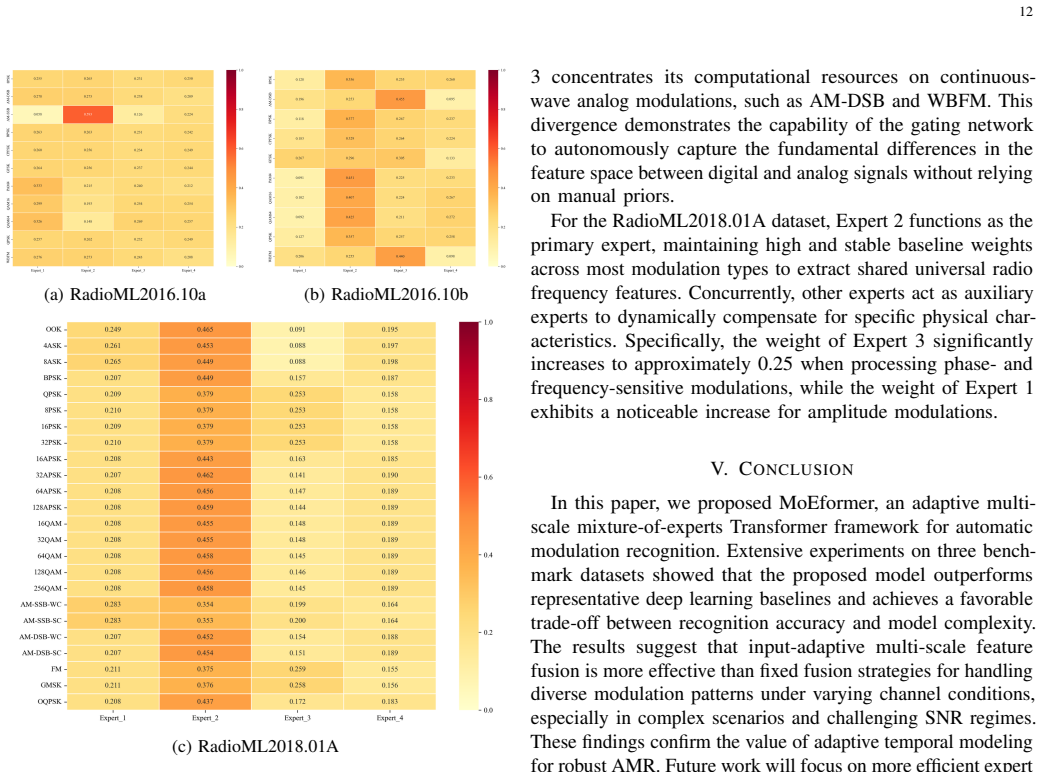
read the original abstract
Automatic Modulation Recognition (AMR) is a key enabling technology for cognitive radio and intelligent spectrum management in next-generation wireless systems. However, current deep learning-based AMR methods predominantly rely on static multi-scale fusion strategies, which lack the flexibility to adapt to the highly dynamic temporal variations of modulation signals. To address this limitation, we propose MoEformer, an adaptive Multi-Scale Mixture-of-Experts Transformer network that directly processes I/Q signals to preserve their temporal and phase structures. Specifically, MoEformer constructs multi scale expert views through temporal resampling, employs an input-dependent gating mechanism for dynamic expert fusion, and integrates Rotary Position Embeddings (RoPE) within Transformer encoders to capture both local and global tem poral dependencies. Comprehensive evaluations on three widely adopted benchmarks (RadioML2016.10a, RadioML2016.10b, and RadioML2018.01A) demonstrate that MoEformer outperforms the competitive baselines, achieving superior average recognition accuracies of 63.74%, 66.24%, and 64.22%, respectively. In addition, the proposed method strikes an optimal trade-off between recognition performance and model complexity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MoEformer, an adaptive Multi-Scale Mixture-of-Experts Transformer for Automatic Modulation Recognition that processes raw I/Q signals. It constructs multi-scale expert views via temporal resampling, uses an input-dependent gating network for dynamic expert selection, and incorporates Rotary Position Embeddings (RoPE) inside Transformer encoders to model local and global temporal dependencies. On the RadioML2016.10a, RadioML2016.10b, and RadioML2018.01A benchmarks the method is reported to achieve average accuracies of 63.74%, 66.24%, and 64.22% respectively, outperforming competitive baselines while maintaining a favorable accuracy-complexity trade-off.
Significance. If the empirical superiority can be shown to be statistically reliable, the combination of input-dependent MoE routing with explicit temporal resampling offers a principled way to handle non-stationary modulation signals without relying on hand-crafted multi-scale fusion. The preservation of raw I/Q phase structure and the use of RoPE are technically sound design choices that align with the physics of the problem.
major comments (2)
- [Abstract / Experiments] Abstract and experimental section: the central claim of outperformance rests on three scalar average accuracies (63.74%, 66.24%, 64.22%) reported without standard deviations, number of independent runs, confidence intervals, or hypothesis tests. In AMR, where training stochasticity and data ordering materially affect results, point estimates alone do not establish that the observed margins are outside normal experimental variation.
- [§3 (Method)] Method description (gating and resampling): the paper asserts that the input-dependent gating plus temporal resampling adapts more effectively to dynamic temporal variations than static multi-scale strategies, yet provides no ablation that isolates the contribution of the gating network versus the resampling operation or versus a standard multi-head attention baseline with the same resampling.
minor comments (2)
- [Abstract] Abstract contains the typographical error 'tem poral' (should be 'temporal').
- [§4 (Experiments)] Training protocol, optimizer settings, learning-rate schedule, batch size, and exact baseline re-implementations are not described at a level that permits reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and describe the changes planned for the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and experimental section: the central claim of outperformance rests on three scalar average accuracies (63.74%, 66.24%, 64.22%) reported without standard deviations, number of independent runs, confidence intervals, or hypothesis tests. In AMR, where training stochasticity and data ordering materially affect results, point estimates alone do not establish that the observed margins are outside normal experimental variation.
Authors: We agree that point estimates alone are insufficient to demonstrate statistical reliability. In the revised manuscript we will rerun all experiments with at least five independent random seeds, report mean accuracy together with standard deviation and 95% confidence intervals for each method, and include paired statistical tests (e.g., t-tests) to assess whether the observed margins exceed experimental variation. revision: yes
-
Referee: [§3 (Method)] Method description (gating and resampling): the paper asserts that the input-dependent gating plus temporal resampling adapts more effectively to dynamic temporal variations than static multi-scale strategies, yet provides no ablation that isolates the contribution of the gating network versus the resampling operation or versus a standard multi-head attention baseline with the same resampling.
Authors: We concur that targeted ablations would strengthen the methodological claims. The revised version will add an ablation table that compares (i) the full MoEformer, (ii) a fixed-gating variant, (iii) a single-scale (no-resampling) variant, and (iv) a standard Transformer encoder that receives the same resampled inputs but uses conventional multi-head attention. These results will isolate the incremental benefit of input-dependent routing and of the resampling step. revision: yes
Circularity Check
No significant circularity; empirical results only
full rationale
The manuscript proposes MoEformer as an architecture for AMR and reports empirical accuracies on RadioML benchmarks. No derivation chain, equations, or first-principles predictions exist that could reduce to inputs by construction. Claims rest on experimental outcomes rather than fitted parameters renamed as predictions or self-citation load-bearing theorems. This is the normal case for an applied neural-network paper with no mathematical reduction steps.
Axiom & Free-Parameter Ledger
invented entities (1)
-
MoEformer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Deep learning at the physical layer: System challenges and applications to 5g and beyond,
F. Restuccia and T. Melodia, “Deep learning at the physical layer: System challenges and applications to 5g and beyond,”IEEE Communications Magazine, vol. 58, no. 10, pp. 58–64, 2020
2020
-
[2]
Signal identification for multiple-antenna wireless systems: Achievements and challenges,
Y . A. Eldemerdash, O. A. Dobre, and M. ¨Oner, “Signal identification for multiple-antenna wireless systems: Achievements and challenges,”IEEE Commun. Surveys Tuts., vol. 18, no. 3, pp. 1524–1551, 2016
2016
-
[3]
Shared spectrum monitoring using deep learning,
F. A. Bhatti, M. J. Khan, and A. Selim, “Shared spectrum monitoring using deep learning,”IEEE Trans. Cogn. Commun. Netw., vol. 7, no. 4, pp. 1172–1185, 2021
2021
-
[4]
End-to-end learning from spectrum data: A deep learning approach for wireless signal identification in spectrum monitoring applications,
M. Kulin, T. Kazaz, I. Moerman, and E. De Poorter, “End-to-end learning from spectrum data: A deep learning approach for wireless signal identification in spectrum monitoring applications,”IEEE Access, vol. 6, pp. 18 484–18 501, 2018
2018
-
[5]
Survey of automatic modulation classification techniques: Classical approaches and new trends,
O. A. Dobre, A. Abdi, Y . Bar-Ness, and W. Su, “Survey of automatic modulation classification techniques: Classical approaches and new trends,”IET Commun., vol. 1, no. 2, pp. 137–156, 2007
2007
-
[6]
Maximum-likelihood classification of digital amplitude-phase modulated signals in flat fading non-Gaussian channels,
V . G. Chavali and C. R. Da Silva, “Maximum-likelihood classification of digital amplitude-phase modulated signals in flat fading non-Gaussian channels,”IEEE Trans. Commun., vol. 59, no. 8, pp. 2051–2056, Aug. 2011
2051
-
[7]
Algorithms for automatic modulation recognition of communication signals,
A. K. Nandi and E. E. Azzouz, “Algorithms for automatic modulation recognition of communication signals,”IEEE Trans. Commun., vol. 46, no. 4, pp. 431–436, Apr. 1998
1998
-
[8]
Learning to short-time Fourier transform in spectrum sensing,
L. Zhou, Z. Sun, and W. Wang, “Learning to short-time Fourier transform in spectrum sensing,”Phys. Commun., vol. 25, pp. 420–425, 2017
2017
-
[9]
Automatic modulation recognition using deep learning architectures,
M. Zhang, Y . Zeng, Z. Han, and Y . Gong, “Automatic modulation recognition using deep learning architectures,” inProc. IEEE 19th Int. Workshop Signal Process. Adv. Wireless Commun. (SPAWC), 2018, pp. 1–5
2018
-
[10]
Automatic modulation recognition of digital signals using wavelet features and SVM,
C. Park, J. Choi, S. Nah, W. Jang, and D. Y . Kim, “Automatic modulation recognition of digital signals using wavelet features and SVM,” inProc. 10th Int. Conf. Adv. Commun. Technol., 2008, pp. 387–390. 13
2008
-
[11]
A survey of modulation classification using deep learning: Signal representation and data preprocessing,
S. Peng, S. Sun, and Y .-D. Yao, “A survey of modulation classification using deep learning: Signal representation and data preprocessing,”IEEE Trans. Neural Netw. Learn. Syst., vol. 33, no. 12, pp. 7020–7038, Dec. 2022
2022
-
[12]
An introduction to deep learning for the physical layer,
T. O’Shea and J. Hoydis, “An introduction to deep learning for the physical layer,”IEEE Trans. Cogn. Commun. Netw., vol. 3, no. 4, pp. 563–575, Dec. 2017
2017
-
[13]
Radio machine learning dataset generation with GNU radio,
T. J. O’Shea and N. West, “Radio machine learning dataset generation with GNU radio,” inProc. GNU Radio Conf., 2016, pp. 1–6
2016
-
[14]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Las Vegas, NV , USA, 2016, pp. 770–778
2016
-
[15]
Deep architectures for modulation recognition,
N. E. West and T. J. O’Shea, “Deep architectures for modulation recognition,” inProc. IEEE Int. Symp. Dyn. Spectr. Access Netw. (DySPAN), Baltimore, MD, USA, 2017, pp. 1–6
2017
-
[16]
Automatic modulation classification: A deep learning enabled approach,
F. Meng, P. Chen, L. Wu, and X. Wang, “Automatic modulation classification: A deep learning enabled approach,”IEEE Trans. Veh. Technol., vol. 67, no. 11, pp. 10 760–10 772, Nov. 2018
2018
-
[17]
Over-the-air deep learning based radio signal classification,
T. J. O’Shea, T. Roy, and T. C. Clancy, “Over-the-air deep learning based radio signal classification,”IEEE J. Sel. Topics Signal Process., vol. 12, no. 1, pp. 168–179, Feb. 2018
2018
-
[18]
Convolutional radio modulation recognition networks,
T. J. O’Shea, J. Corgan, and T. C. Clancy, “Convolutional radio modulation recognition networks,” inProc. Eng. Appl. Neural Netw. (EANN), Aberdeen, U.K., 2016, pp. 213–226
2016
-
[19]
Data-driven deep learning for automatic modulation recognition in cognitive radios,
Y . Wang, M. Liu, J. Yang, and G. Gui, “Data-driven deep learning for automatic modulation recognition in cognitive radios,”IEEE Transactions on Vehicular Technology, vol. 68, no. 4, pp. 4074–4077, 2019
2019
-
[20]
ImageNet classification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2012, pp. 1097–1105
2012
-
[21]
Going deeper with convolutions,
C. Szegedyet al., “Going deeper with convolutions,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2015, pp. 1–9
2015
-
[22]
Modulation classification based on signal constellation diagrams and deep learning,
S. Penget al., “Modulation classification based on signal constellation diagrams and deep learning,”IEEE Trans. Neural Netw. Learn. Syst., vol. 30, no. 3, pp. 718–727, Mar. 2019
2019
-
[23]
Modulation recognition using signal enhancement and multistage attention mechanism,
S. Lin, Y . Zeng, and Y . Gong, “Modulation recognition using signal enhancement and multistage attention mechanism,”IEEE Trans. Wireless Commun., vol. 21, no. 11, pp. 9921–9935, Nov. 2022
2022
-
[24]
Augmenting radio signals with wavelet transform for deep learning-based modulation recognition,
T. Chen, S. Zheng, K. Qiu, L. Zhang, Q. Xuan, and X. Yang, “Augmenting radio signals with wavelet transform for deep learning-based modulation recognition,”IEEE Trans. Cogn. Commun. Netw., vol. 10, no. 6, pp. 2029–2044, Dec. 2024
2029
-
[25]
Understanding the effective receptive field in deep convolutional neural networks,
W. Luo, Y . Li, R. Urtasun, and R. Zemel, “Understanding the effective receptive field in deep convolutional neural networks,” inProceedings of the 30th International Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 2016, pp. 4905–4913
2016
-
[26]
A spatio temporal multi-channel learning framework for automatic modulation recognition,
J. Xu, C. Luo, G. Parr, and Y . Luo, “A spatio temporal multi-channel learning framework for automatic modulation recognition,” inProc. IEEE Wireless Commun. Lett., vol. 9, no. 10, Oct. 2020, pp. 1629–1632
2020
-
[27]
Automatic modulation classification using recurrent neural networks,
D. Hong, Z. Zhang, and X. Xu, “Automatic modulation classification using recurrent neural networks,” inProc. IEEE Int. Conf. Comput. Commun. (ICCC), 2017, pp. 695–700
2017
-
[28]
Deep learning models for wireless signal classification with distributed low-cost spectrum sensors,
S. Rajendran, W. Meert, D. Giustiniano, V . Lenders, and S. Pollin, “Deep learning models for wireless signal classification with distributed low-cost spectrum sensors,”IEEE Trans. Cogn. Commun. Netw., vol. 4, no. 3, pp. 433–445, Sep. 2018
2018
-
[29]
A comprehensive survey on pretrained foundation models: A history from bert to chatgpt,
C. Z. at al, “A comprehensive survey on pretrained foundation models: A history from bert to chatgpt,” 2023, arXiv:2302.09419
-
[30]
SpeechBERT: Cross-modal pre-trained language model for end-to-end spoken question answering,
Y . S. Chuang, C. L. Liu, and H. Y . Lee, “SpeechBERT: Cross-modal pre-trained language model for end-to-end spoken question answering,” inProc. Interspeech, 2020, pp. 4168–4172
2020
-
[31]
An image is worth 16×16 words: Transformers for image recognition at scale,
A. Dosovitskiyet al., “An image is worth 16×16 words: Transformers for image recognition at scale,” inProc. Int. Conf. Learn. Represent. (ICLR), 2021, pp. 1–22
2021
-
[32]
Attention is all you need,
A. Vaswaniet al., “Attention is all you need,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2017, pp. 6000–6010
2017
-
[33]
Automatic modulation classification using convolutional neural network with features fusion of SPWVD and BJD,
Z. Zhang, C. Wang, C. Gan, S. Sun, and M. Wang, “Automatic modulation classification using convolutional neural network with features fusion of SPWVD and BJD,”IEEE Trans. Signal Inf. Process. Netw., vol. 5, no. 3, pp. 469–478, Sep. 2019
2019
-
[34]
A spatiotemporal multi- stream learning framework based on attention mechanism for automatic modulation recognition,
X. Wang, D. Liu, Y . Zhang, Y . Li, and S. Wu, “A spatiotemporal multi- stream learning framework based on attention mechanism for automatic modulation recognition,”Digital Signal Process., vol. 130, p. 103703, 2022
2022
-
[35]
A novel lstm architecture for automatic modulation recognition: Comparative analysis with conventional machine learning and rnn-based approaches,
S. Ansari, S. Mahmoud, S. Majzoub, E. Almajali, A. Jarndal, and T. Bonny, “A novel lstm architecture for automatic modulation recognition: Comparative analysis with conventional machine learning and rnn-based approaches,”IEEE Access, vol. 13, pp. 72 526–72 543, 2025
2025
-
[36]
MCformer: A transformer based deep neural network for automatic modulation classification,
S. Hamidi-Rad and S. Jain, “MCformer: A transformer based deep neural network for automatic modulation classification,” inProc. IEEE Global Commun. Conf. (GLOBECOM), Madrid, Spain, 2021, pp. 1–6
2021
-
[37]
MST: A multi-scale transformer framework with cross-scale token fusion for automatic modulation recognition,
J. Zhang, S. An, F. Meng, and Q. Liu, “MST: A multi-scale transformer framework with cross-scale token fusion for automatic modulation recognition,”IEEE Wireless Communications Letters, vol. 14, no. 12, pp. 4112–4116, 2025
2025
-
[38]
Automatic modulation classification using CNN-LSTM based dual-stream structure,
Z. Zhang, H. Luo, C. Wang, C. Gan, and Y . Xiang, “Automatic modulation classification using CNN-LSTM based dual-stream structure,”IEEE Transactions on Vehicular Technology, vol. 69, no. 11, pp. 13 521–13 531, 2020
2020
-
[39]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,”J. Mach. Learn. Res., vol. 23, no. 120, pp. 1–39, 2022
2022
-
[40]
A comprehensive survey of mixture-of-experts: Algorithms, theory, and applications
S. Mu and S. Lin, “A comprehensive survey of mixture-of-experts: Algorithms, theory, and applications,”arXiv preprint arXiv:2503.07137, 2026
-
[41]
A survey on mixture of experts in large language models,
W. Cai, J. Jiang, F. Wang, J. Tang, S. Kim, and J. Huang, “A survey on mixture of experts in large language models,”IEEE Transactions on Knowledge and Data Engineering, pp. 1–20, 2025
2025
-
[42]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,” inProc. Int. Conf. Learn. Represent. (ICLR), Toulon, France, 2017
2017
-
[43]
RoFormer: Enhanced Transformer with Rotary Position Embedding
J. Su, Y . Lu, S. Pan, A. Murtadha, B. Wen, and Y . Liu, “Roformer: Enhanced transformer with rotary position embedding,”arXiv preprint, vol. arXiv:2104.09864, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[44]
Xception: Deep learning with depthwise separable convo- lutions,
F. Chollet, “Xception: Deep learning with depthwise separable convo- lutions,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Honolulu, HI, USA, 2017, pp. 1251–1258
2017
-
[45]
Batch normalization: Accelerating deep network training by reducing internal covariate shift,
S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” inProc. Int. Conf. Mach. Learn. (ICML), Lille, France, 2015, pp. 448–456
2015
-
[46]
Gaussian Error Linear Units (GELUs)
D. Hendrycks and K. Gimpel, “Gaussian error linear units (gelus),”arXiv preprint, vol. arXiv:1606.08415, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[47]
AMC-Net: An effective network for automatic modulation classification,
J. Zhang, T. Wang, Z. Feng, and S. Yang, “AMC-Net: An effective network for automatic modulation classification,” inProc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP), 2023, pp. 1–5
2023
-
[48]
Abandon locality: Frame- wise embedding aided transformer for automatic modulation recognition,
Y . Chen, B. Dong, C. Liu, W. Xiong, and S. Li, “Abandon locality: Frame- wise embedding aided transformer for automatic modulation recognition,” IEEE Commun. Lett., vol. 27, no. 1, pp. 327–331, Jan. 2023
2023
-
[49]
Enhancing automatic modulation recognition through robust global feature extraction,
Y . Qu, Z. Lu, R. Zeng, J. Wang, and J. Wang, “Enhancing automatic modulation recognition through robust global feature extraction,”arXiv preprint, vol. arXiv:2401.01056, 2024
-
[50]
Visualizing data using t-sne,
L. van der Maaten and G. Hinton, “Visualizing data using t-sne,”J. Mach. Learn. Res., vol. 9, no. 86, pp. 2579–2605, 2008
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.