A Comparative Study of Pre-trained Speech Encoders and Training Objectives for Large-Scale Indic Spoken Language Identification
Pith reviewed 2026-06-27 15:10 UTC · model grok-4.3
The pith
Frozen FastConformer reaches over 90% macro accuracy on out-of-domain Indic language identification benchmarks without adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The frozen FastConformer encoder achieves over 90% macro accuracy on FLEURS and Kathbath without any task-specific adaptation, substantially outperforming Whisper on out-of-domain benchmarks, while HSM consistently outperforms CE and CE+SupCon for both encoders across all benchmarks, with the largest gains on out-of-domain test sets. CE+SupCon degrades FastConformer's cross-corpus generalization, suggesting that the contrastive objective over-specializes representations to in-domain conditions.
What carries the argument
Pre-trained speech encoders (Whisper and FastConformer) used in frozen or fine-tuned mode with a linear classifier and different training objectives (CE, CE+SupCon, HSM) evaluated in cross-corpus settings for 42-language Indic LID.
If this is right
- Fine-tuned Whisper yields stronger in-domain performance but weaker out-of-domain results compared to frozen FastConformer.
- CE+SupCon degrades FastConformer's cross-corpus generalization by over-specializing representations to in-domain conditions.
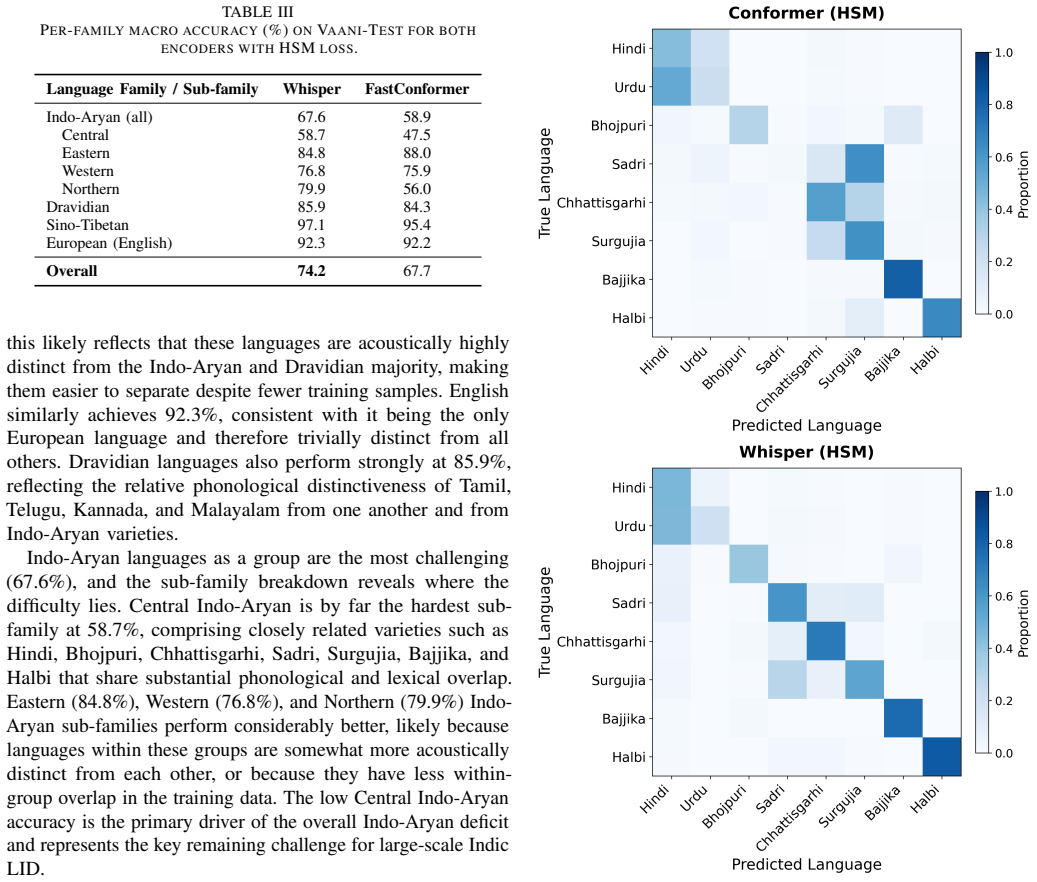
- Central Indo-Aryan varieties are the hardest to discriminate, dominated by Hindi-Urdu and Sadri-Chhattisgarhi-Surgujia confusion pairs.
- HSM provides the largest gains on out-of-domain test sets for both encoders.
- Models generalize from Vaani training to FLEURS and Kathbath, showing domain differences are bridgeable with appropriate objectives.
Where Pith is reading between the lines
- The robustness of frozen FastConformer suggests its representations capture language-specific features that transfer across recording conditions and speaker groups.
- Hierarchical softmax may be particularly useful when classes have natural groupings, as in language families, potentially extending to other hierarchical classification tasks.
- The fact that contrastive training hurts out-of-domain performance points to a need for objectives that balance specificity and generality in representation learning.
- Per-family confusion patterns could guide targeted data collection or model improvements for low-resource Indic varieties.
Load-bearing premise
The cross-corpus test sets FLEURS and Kathbath differ from Vaani primarily in domain rather than in unmeasured factors such as microphone type, speaker demographics, or recording environment.
What would settle it
Evaluate the frozen FastConformer on an additional out-of-domain Indic speech dataset collected under different acoustic conditions; if macro accuracy falls substantially below 90 percent the generalization claim would be weakened.
Figures
read the original abstract
Spoken language identification (LID) for Indian languages is a challenging problem due to the large number of languages, significant phonetic overlap among related varieties, and the scarcity of labeled data for many low-resource languages. In this work, we present a systematic comparative study of two pre-trained speech encoders -- Whisper and FastConformer -- combined with a linear classifier for large-scale Indic LID spanning 42 languages across four linguistic families. We evaluate both encoders in frozen (linear probing) and fine-tuned settings, and compare three training objectives: cross-entropy (CE), supervised contrastive loss with cross entropy (CE + supCon), and hierarchical softmax (HSM). Models are trained on the Vaani dataset and evaluated in a cross-corpus setting on Vaani-Test (held-out), FLEURS, and Kathbath, providing insights into domain generalization. The frozen FastConformer encoder achieves over 90\% macro accuracy on FLEURS and Kathbath without any task-specific adaptation, substantially outperforming Whisper on out-of-domain benchmarks, while fine-tuned Whisper yields stronger in-domain performance. HSM consistently outperforms CE and CE+SupCon for both encoders across all benchmarks, with the largest gains on out-of-domain test sets. CE+SupCon degrades FastConformer's cross-corpus generalization, suggesting that the contrastive objective over-specializes representations to in-domain conditions. Per-family analysis shows that Central Indo-Aryan varieties are the hardest to discriminate, with Hindi--Urdu and the Sadri--Chhattisgarhi--Surgujia cluster being the dominant confusion pairs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a comparative study of two pre-trained speech encoders, Whisper and FastConformer, combined with a linear classifier for spoken language identification across 42 Indic languages from four families. Models are trained on the Vaani dataset using three objectives: cross-entropy (CE), CE with supervised contrastive loss, and hierarchical softmax (HSM). Evaluation is performed on held-out Vaani-Test as well as cross-corpus on FLEURS and Kathbath in both frozen and fine-tuned settings. Main claims include the frozen FastConformer achieving over 90% macro accuracy on out-of-domain benchmarks outperforming Whisper, HSM outperforming other objectives especially out-of-domain, and specific confusion patterns in Central Indo-Aryan languages.
Significance. Should the results prove robust upon addressing the evidentiary gaps, this study offers practical guidance on selecting encoders and objectives for large-scale Indic LID systems. The finding that frozen encoders can generalize well and that HSM provides benefits for related languages has potential impact on low-resource speech applications. The cross-corpus setup strengthens the assessment of generalization capabilities.
major comments (3)
- [Abstract] The reported performance figures (e.g., over 90% macro accuracy for frozen FastConformer on FLEURS and Kathbath) are given as point estimates without error bars, results from multiple random seeds, or statistical tests to establish significant differences between encoders and objectives. This makes the claims of consistent outperformance and largest gains on out-of-domain sets only moderately supported.
- [Cross-corpus evaluation] The conclusion that HSM yields the largest gains on out-of-domain test sets and that CE+SupCon degrades generalization treats the differences between Vaani and the test corpora (FLEURS, Kathbath) as purely domain-related. Without analysis or discussion of potential mismatches in acoustic conditions, microphone types, SNR, or speaker demographics, the generalization and objective-ranking claims risk being confounded by unmeasured factors.
- [Experimental setup] The manuscript provides no details on data split construction for Vaani-Test, hyperparameter tuning, optimizer settings, or the precise formulation and implementation of the HSM and linear probe, all of which are load-bearing for reproducing and validating the accuracy numbers and the superiority claims.
minor comments (1)
- [Abstract] It would be helpful to specify the exact number of languages per family or provide a reference to the language list to contextualize the per-family confusion analysis.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where additional evidence and details would strengthen the manuscript. We address each major comment below and outline proposed revisions.
read point-by-point responses
-
Referee: [Abstract] The reported performance figures (e.g., over 90% macro accuracy for frozen FastConformer on FLEURS and Kathbath) are given as point estimates without error bars, results from multiple random seeds, or statistical tests to establish significant differences between encoders and objectives. This makes the claims of consistent outperformance and largest gains on out-of-domain sets only moderately supported.
Authors: We agree that reporting variability and statistical significance would provide stronger support for the outperformance claims. In the revised manuscript, we will include results averaged over multiple random seeds with standard deviations and apply appropriate statistical tests (such as McNemar's test) to evaluate differences between encoders and objectives. revision: yes
-
Referee: [Cross-corpus evaluation] The conclusion that HSM yields the largest gains on out-of-domain test sets and that CE+SupCon degrades generalization treats the differences between Vaani and the test corpora (FLEURS, Kathbath) as purely domain-related. Without analysis or discussion of potential mismatches in acoustic conditions, microphone types, SNR, or speaker demographics, the generalization and objective-ranking claims risk being confounded by unmeasured factors.
Authors: We acknowledge that unmeasured mismatches could influence results and that the current discussion focuses primarily on domain generalization. In revision, we will add a paragraph summarizing documented differences in recording conditions, microphones, and speaker demographics across Vaani, FLEURS, and Kathbath to better contextualize the findings. revision: partial
-
Referee: [Experimental setup] The manuscript provides no details on data split construction for Vaani-Test, hyperparameter tuning, optimizer settings, or the precise formulation and implementation of the HSM and linear probe, all of which are load-bearing for reproducing and validating the accuracy numbers and the superiority claims.
Authors: We agree these implementation details are necessary for reproducibility. The revised version will expand the experimental setup section to specify Vaani-Test split construction, hyperparameter tuning procedure, optimizer and learning rate choices, and the exact formulation and code-level implementation of hierarchical softmax and the linear probe. revision: yes
Circularity Check
No circularity; purely empirical comparisons on held-out data.
full rationale
The paper reports accuracy metrics from training linear probes or fine-tuning on Vaani and evaluating on Vaani-Test, FLEURS, and Kathbath. No equations, derivations, or first-principles claims exist that could reduce to fitted inputs or self-citations by construction. All load-bearing statements are direct empirical observations (e.g., 'frozen FastConformer encoder achieves over 90% macro accuracy'). The cross-corpus design is a standard held-out evaluation and does not involve any self-referential definitions or renamed predictions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard i.i.d. sampling and label correctness assumptions hold for the Vaani, FLEURS, and Kathbath corpora.
Reference graph
Works this paper leans on
-
[1]
R. C. Nigam,Language Handbook on Mother Tongues in Census of India, 1971. New Delhi: Office of the Registrar General, India (Ministry of Home Affairs), 1972, accessed: 2025-07-22. [Online]. Available: https://language.census.gov.in/eLanguageDivision_VirtualPath/ eArchive/pdf/28.pdf
1971
-
[2]
Official indian languages,
GoI, “Official indian languages,” https://rajbhasha.gov.in/en/ languages-included-eighth-schedule-indian-constitution, accessed: 2025-07-22
2025
-
[3]
C. P. Masica,The Indo-Aryan Languages. Cambridge University Press, 1991
1991
-
[4]
India as a linguistic area revisited,
A. Abbi, “India as a linguistic area revisited,”Language Sciences, vol. 28, no. 6, pp. 617–633, 2006
2006
-
[5]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inProceedings of the International Conference on Machine Learning (ICML), 2023
2023
-
[6]
Conformer: Convolution-augmented transformer for speech recognition,
A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y . Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, R. Panget al., “Conformer: Convolution-augmented transformer for speech recognition,” inProceedings of Interspeech, 2020
2020
-
[7]
Indian language identification using deep learning,
S. Godbole, V . Jadhav, and G. Birajdar, “Indian language identification using deep learning,”ITM Web of Conferences, vol. 32, p. 01010, 01 2020
2020
-
[8]
Deep learning for spoken language identification: Can we visualize speech signal patterns?
H. Mukherjee, S. Ghosh, S. Sen, O. Sk, K. Santosh, S. Phadikar, and K. Roy, “Deep learning for spoken language identification: Can we visualize speech signal patterns?”Neural Computing and Applications, vol. 31, 12 2019
2019
-
[9]
An overview of indian spoken language recognition from machine learning perspective,
S. Dey, M. Sahidullah, and G. Saha, “An overview of indian spoken language recognition from machine learning perspective,” ACM Transactions on Asian and Low-Resource Language Information Processing, vol. 21, pp. 1 – 45, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:247319584
2022
-
[10]
Self-Supervised Phonotactic Representations for Language Identification,
G. Ramesh, C. S. Kumar, and K. S. R. Murty, “Self-Supervised Phonotactic Representations for Language Identification,” inInterspeech 2021, 2021, pp. 1514–1518
2021
-
[11]
Cross-corpora language recognition: A preliminary investigation with indian languages,
S. Dey, G. Saha, and M. Sahidullah, “Cross-corpora language recognition: A preliminary investigation with indian languages,”2021 29th European Signal Processing Conference (EUSIPCO), pp. 546–550, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:234357575
2021
-
[12]
Cross-corpora spoken language identification with domain diversification and generalization,
S. Dey, M. Sahidullah, and G. Saha, “Cross-corpora spoken language identification with domain diversification and generalization,”ArXiv, vol. abs/2302.05110, 2023. [Online]. Available: https://api.semanticscholar. org/CorpusID:256808424
-
[13]
Spoken language identification in unseen target domain using within-sample similarity loss,
M. H, S. Kapoor, D. A. Dinesh, and P. Rajan, “Spoken language identification in unseen target domain using within-sample similarity loss,” inICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 7223–7227
2021
-
[14]
A unified approach to multilingual automatic speech recognition with improved language identification for indic languages,
A. Shrivastavaet al., “A unified approach to multilingual automatic speech recognition with improved language identification for indic languages,” inProceedings of Interspeech, 2024
2024
-
[15]
VAANI: Capturing the language landscape for an inclusive digital India
S. Pulikodan, A. Singh, A. Basu, N. Desai, P. K. J, P. D. Bhat, R. Dharmaraju, R. Gupta, S. Udupa, S. Kumar, S. Sharma, V . Sanka, D. Tewari, H. Dhand, A. Kamat, S. Singh, S. Vashishth, P. Talukdar, R. Acharya, and P. K. Ghosh, “Vaani: Capturing the language landscape for an inclusive digital india,” 2026. [Online]. Available: https://arxiv.org/abs/2603.28714
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Self-attention encoding and pooling for speaker recognition,
P. Safari, M. India, and J. Hernando, “Self-attention encoding and pooling for speaker recognition,” 10 2020, pp. 941–945
2020
-
[17]
Supervised contrastive learning,
P. Khosla, P. Teterwak, C. Wang, A. Sarna, Y . Tian, P. Isola, A. Maschinot, C. Liu, and D. Krishnan, “Supervised contrastive learning,” inAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[18]
Hierarchical probabilistic neural network language model,
F. Morin and Y . Bengio, “Hierarchical probabilistic neural network language model,” inProceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), 2005
2005
-
[19]
Fleurs: Few-shot learning evaluation of universal representations of speech,
A. Conneau, M. Ma, S. Khanuja, Y . Zhang, V . Axelrod, S. Dalmia, J. Riesa, C. Rivera, and A. Bapna, “Fleurs: Few-shot learning evaluation of universal representations of speech,” inIEEE Spoken Language Technology Workshop (SLT), 2023
2023
-
[20]
Towards building asr systems for the next billion users,
T. Javed, S. Doddapaneni, A. Raman, K. Bhogale, G. Ramesh, A. Kunchukuttan, P. Kumar, and M. Khapra, “Towards building asr systems for the next billion users,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, pp. 10 813–10 821, 06 2022
2022
-
[21]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” in International Conference on Learning Representations (ICLR), 2019
2019
-
[22]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” in Proceedings of NAACL-HLT, 2019
2019
-
[23]
Scaling speech technology to 1,000+ languages,
V . Pratap, A. Tjandra, B. Shi, P. Tomasello, A. Babu, S. Kundu, W.-N. Wanget al., “Scaling speech technology to 1,000+ languages,”arXiv preprint arXiv:2305.13516, 2023
-
[24]
V oxLingua107: A dataset for spoken language recognition,
J. Valk and T. Alumäe, “V oxLingua107: A dataset for spoken language recognition,” inProceedings of the IEEE Spoken Language Technology Workshop (SLT), 2021
2021
-
[25]
ECAPA-TDNN: Emphasized channel attention, propagation and aggregation in tdnn- based speaker verification,
B. Desplanques, J. Thienpondt, and K. Demuynck, “ECAPA-TDNN: Emphasized channel attention, propagation and aggregation in tdnn- based speaker verification,” inProceedings of Interspeech, 2020, pp. 3830–3834. VIII. APPENDIX A. Languages We consider 42 languages organized into a hierarchical taxonomy spanning multiple language families. The languages were c...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.