Popcorn: A Configurable Benchmark for Visual Evidence in Multimodal Movie Recommendation
Pith reviewed 2026-06-27 14:40 UTC · model grok-4.3
The pith
A benchmark demonstrates that visual evidence sources for movie recommendation are not interchangeable, with thumbnail VLMs providing strong scalable signals while source and fusion choices alter accuracy, coverage, diversity, and calibrati
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
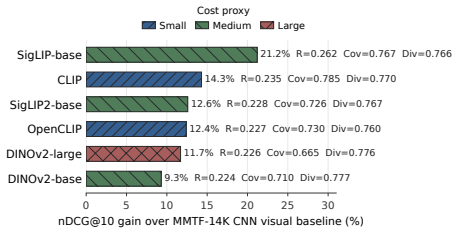
Popcorn standardizes modality assembly, fusion, splitting, evaluation, and LLM-augmented metadata through a single configuration contract that combines title-aligned full-movie/trailer embeddings with MovieLens-linked thumbnail features encoded by modern visual and vision-language models; experiments show thumbnail VLMs provide strong scalable item-side evidence while controlled trailer/full-movie comparisons establish that visual evidence sources are not interchangeable because source and fusion strategy affect ranking accuracy, coverage, diversity, and calibration.
What carries the argument
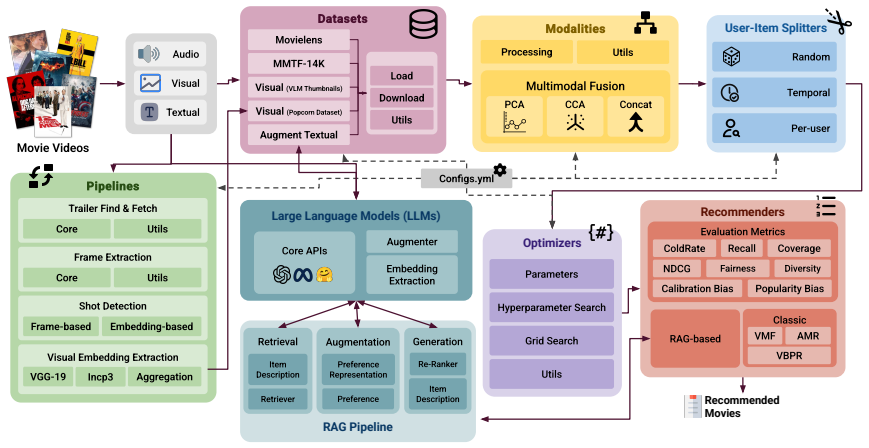
Popcorn, a configurable benchmark that standardizes modality assembly, fusion, splitting, evaluation, and LLM-augmented metadata through a single configuration contract combining title-aligned full-movie/trailer embeddings with MovieLens-linked thumbnail features.
If this is right
- Thumbnail VLMs can serve as strong and scalable item-side evidence in movie recommendation pipelines.
- Choice of visual source (thumbnail, trailer, or full movie) changes ranking accuracy.
- Fusion strategy between visual sources influences coverage, diversity, and calibration of recommendations.
- A single configuration contract enables reproducible comparisons of modality effects.
- Benchmarks relying on only one visual source may miss performance differences visible when sources are varied.
Where Pith is reading between the lines
- Recommendation pipelines may need modality-selection rules tuned to whether scalability or detail is the priority.
- Existing movie datasets that link only metadata to one visual source could systematically understate the impact of visual choice.
- Extending the benchmark to additional fusion methods or new visual encoders could reveal whether the observed non-interchangeability persists.
- Systems that treat all visual evidence as equivalent may produce mis-calibrated rankings on catalogs where thumbnail coverage differs from trailer availability.
Load-bearing premise
Title-aligned full-movie and trailer embeddings plus MovieLens-linked thumbnail features, when handled through one configuration contract, produce fair comparisons across modalities without hidden selection effects from linking or encoding.
What would settle it
A controlled experiment in which swapping visual sources or fusion strategies leaves ranking accuracy, coverage, diversity, and calibration unchanged across multiple linked datasets would falsify the non-interchangeability claim.
Figures

read the original abstract
Movies are long-form audiovisual works, yet recommender benchmarks often rely on trailers, thumbnails, or metadata. These sources differ in semantics and scalability: full movies preserve consumption-level evidence, trailers concentrate promotional highlights, and thumbnails provide sparse but catalog-scale visual signals. We present Popcorn, a configurable benchmark for visual evidence in multimodal movie recommendation, combining title-aligned full-movie/trailer embeddings with MovieLens-linked thumbnail features encoded by modern visual and vision-language models. Popcorn standardizes modality assembly, fusion, splitting, evaluation, and LLM-augmented metadata through a single configuration contract. Experiments show that thumbnail VLMs provide strong, scalable item-side evidence, while controlled trailer/full-movie comparisons show that visual evidence sources are not interchangeable: the choice of source and fusion strategy affects ranking accuracy, coverage, diversity, and calibration. The framework is available at https://github.com/RecSys-lab/Popcorn.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Popcorn, a configurable benchmark for visual evidence in multimodal movie recommendation. It combines title-aligned full-movie/trailer embeddings with MovieLens-linked thumbnail features encoded by modern VLMs, standardizes modality assembly, fusion, splitting, evaluation, and LLM-augmented metadata through a single configuration contract, and reports experiments showing that thumbnail VLMs provide strong scalable item-side evidence while visual evidence sources are not interchangeable (source and fusion strategy affect ranking accuracy, coverage, diversity, and calibration). The framework is released at https://github.com/RecSys-lab/Popcorn.
Significance. If the non-interchangeability result holds after addressing coverage issues, the work supplies a valuable open, reproducible benchmark for multimodal movie recommendation research, with explicit credit for the GitHub repository and configuration contract that enables controlled comparisons across visual sources.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the central claim that controlled trailer/full-movie vs. thumbnail comparisons demonstrate non-interchangeability rests on the assumption that title-aligned embeddings plus MovieLens-linked thumbnail features yield fair modality assembly; however, trailer and full-movie availability is unlikely to be uniform across the MovieLens item set and may correlate with popularity, release date, or genre, yet the single configuration contract standardizes fusion/splitting but does not report or correct for balanced coverage or encoding mismatches between VLMs.
- [§3] §3 (Dataset and Configuration): no details are given on how missing modality coverage is handled or whether item subsets are restricted to those with complete visual sources; without this, the reported effects on ranking accuracy, coverage, diversity, and calibration cannot be isolated from selection effects.
minor comments (2)
- [Methods] The abstract states experimental outcomes but the methods section should explicitly list data splits, statistical tests, and number of runs to allow verification of the non-interchangeability claim.
- Notation for the configuration contract (e.g., how fusion strategies are parameterized) should be clarified with a small example table to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important considerations for ensuring fair and reproducible comparisons in multimodal benchmarks. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central claim that controlled trailer/full-movie vs. thumbnail comparisons demonstrate non-interchangeability rests on the assumption that title-aligned embeddings plus MovieLens-linked thumbnail features yield fair modality assembly; however, trailer and full-movie availability is unlikely to be uniform across the MovieLens item set and may correlate with popularity, release date, or genre, yet the single configuration contract standardizes fusion/splitting but does not report or correct for balanced coverage or encoding mismatches between VLMs.
Authors: We agree that non-uniform availability of trailers and full movies could introduce selection effects correlated with item popularity or other attributes, and that the manuscript should explicitly address this for the non-interchangeability claim. The configuration contract is intended to support controlled experiments by allowing users to define item subsets with complete modality coverage. In the reported experiments, comparisons were performed on the intersection of available sources to enable direct evaluation. To address the concern, we will revise the manuscript to report coverage statistics, detail how subsets are constructed, and clarify that results reflect comparable items rather than the full MovieLens catalog. revision: yes
-
Referee: [§3] §3 (Dataset and Configuration): no details are given on how missing modality coverage is handled or whether item subsets are restricted to those with complete visual sources; without this, the reported effects on ranking accuracy, coverage, diversity, and calibration cannot be isolated from selection effects.
Authors: We concur that explicit details on coverage handling are required to isolate the reported effects from potential selection biases. While the framework supports restricting experiments to items with complete visual sources through its configuration contract, the current manuscript does not provide coverage rates or subset definitions. We will update §3 to include these details, such as the proportion of MovieLens items possessing each visual source and the exact subset criteria used in experiments. revision: yes
Circularity Check
Empirical benchmark paper with no derivations or load-bearing self-references
full rationale
The paper presents Popcorn as a configurable benchmark for multimodal movie recommendation, standardizing modality assembly and reporting empirical results on thumbnail VLMs versus trailer/full-movie sources. No equations, derivations, fitted parameters, or predictions appear in the provided text. Claims rest on experimental comparisons under a single configuration contract rather than any self-definitional reduction, fitted-input renaming, or self-citation chain. The work is self-contained as an empirical introduction with external reproducibility via the linked GitHub repository.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption MovieLens dataset provides reliable item-side metadata and links for thumbnail features.
- domain assumption Modern visual and vision-language models produce comparable embeddings across different movie visual sources.
Reference graph
Works this paper leans on
-
[1]
M. Attimonelli, D. Danese, A. Di Fazio, D. Malitesta, C. Pomo, and T. Di Noia. Ducho meets elliot: Large-scale benchmarks for multimodal recommendation.arXiv preprint arXiv:2409.15857, 2024
-
[2]
Attimonelli, D
M. Attimonelli, D. Danese, D. Malitesta, C. Pomo, G. Gassi, and T. Di Noia. Ducho 2.0: Towards a more up-to-date unified framework for the extraction of multimodal features in recommendation. In Companion Proceedings of the ACM on Web Conference 2024, pages 1075–1078, 2024
2024
-
[3]
Cherti, R
M. Cherti, R. Beaumont, R. Wightman, M. Wortsman, G. Ilharco, C. Gordon, C. Schuhmann, L. Schmidt, and J. Jitsev. Reproducible scaling laws for contrastive language-image learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2818–2829, 2023
2023
-
[4]
Deldjoo, M
Y. Deldjoo, M. G. Constantin, B. Ionescu, M. Schedl, and P. Cremonesi. Mmtf-14k: a multifaceted movie trailer feature dataset for recommendation and retrieval. InProceedings of the 9th ACM Multimedia Systems Conference, pages 450–455, 2018
2018
-
[5]
Deldjoo, M
Y. Deldjoo, M. Schedl, P. Cremonesi, and G. Pasi. Recommender systems leveraging multimedia content.ACM Computing Surveys (CSUR), 53(5):1–38, 2021
2021
-
[6]
F. M. Harper and J. A. Konstan. The movielens datasets: History and context.Acm transactions on interactive intelligent systems (tiis), 5(4):1–19, 2015
2015
-
[7]
He and J
R. He and J. McAuley. Vbpr: visual bayesian personalized ranking from implicit feedback. In Proceedings of the AAAI conference on artificial intelligence, volume 30, 2016
2016
- [8]
- [9]
- [10]
-
[11]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. Vo, M. Szafraniec, V. Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
C. Park, D. Kim, J. Oh, and H. Yu. Do” also-viewed” products help user rating prediction? In Proceedings of the 26th international conference on world wide web, pages 1113–1122, 2017
2017
-
[13]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[14]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[15]
Szegedy, V
C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2818–2826, 2016. 7
2016
-
[16]
J. Tang, X. Du, X. He, F. Yuan, Q. Tian, and T.-S. Chua. Adversarial training towards robust multimedia recommender system.IEEE Transactions on Knowledge and Data Engineering, 32(5):855– 867, 2019
2019
-
[17]
J. Tian, Z. Wang, J. Zhao, and Z. Ding. Mmrec: Llm based multi-modal recommender system. In 2024 19th International Workshop on Semantic and Social Media Adaptation & Personalization (SMAP), pages 105–110. IEEE, 2024
2024
-
[18]
A. Tourani, F. Nazary, and Y. Deldjoo. Rag-visualrec: An open resource for vision-and text-enhanced retrieval-augmented generation in recommendation.arXiv preprint arXiv:2506.20817, 2025
work page internal anchor Pith review arXiv 2025
-
[19]
M. Tschannen, A. Gritsenko, X. Wang, M. F. Naeem, I. Alabdulmohsin, N. Parthasarathy, T. Evans, L. Beyer, Y. Xia, B. Mustafa, et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
W. Wei, C. Huang, L. Xia, and C. Zhang. Multi-modal self-supervised learning for recommendation. InProceedings of the ACM Web Conference 2023, pages 790–800, 2023
2023
-
[21]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11975–11986, 2023
2023
-
[22]
X. Zhou. Mmrec: Simplifying multimodal recommendation. InProceedings of the 5th ACM International Conference on Multimedia in Asia Workshops, pages 1–2, 2023. 8
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.