TSseek: Regular Expression-Based Similarity Search for Distributed Time Series Datasets
Pith reviewed 2026-06-27 14:10 UTC · model grok-4.3
The pith
TSseek maps time series to line segments and regex queries to rectangles for exact pattern search on distributed data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TSseek provides a regular-expression-powered search framework that maps time series objects to sequences of line segments preserving trend and value range, translates query constructs into bounding rectangles, and uses a distributed spatial index TSseek-X to support efficient exact matching for both whole-series and subsequence queries on distributed datasets.
What carries the argument
Mapping time series objects to line-segment sequences that retain slope direction and value range, paired with translation of regex constructs into bounding rectangles for use in a spatial index.
If this is right
- Regex queries on trends, value ranges, and wildcards become answerable exactly and at scale without forcing users to supply full example sequences.
- Both whole-matching and subsequence-matching workloads run on the same index structure with no accuracy loss relative to full scan.
- Distributed spatial indexing replaces the need for separate approximation pipelines such as PAA or SAX for pattern queries.
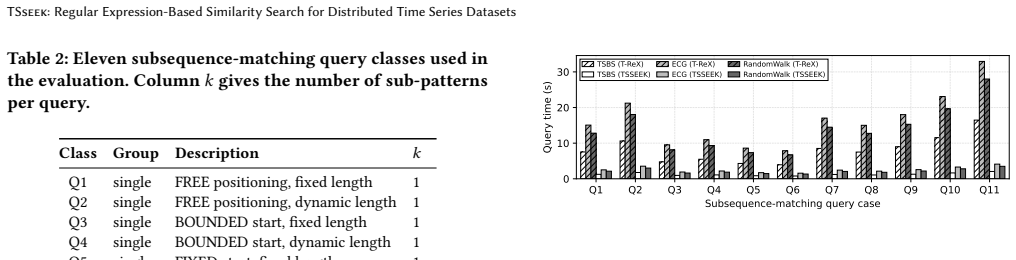
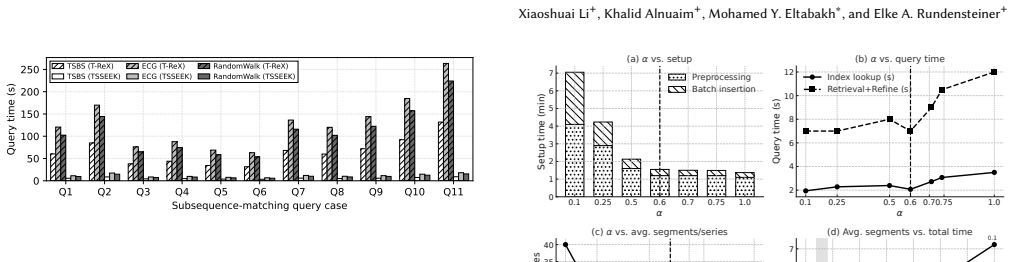
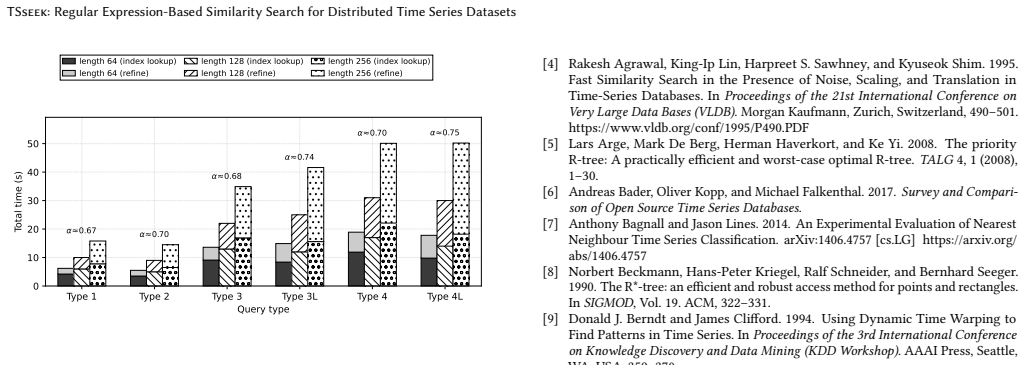
- Significant runtime reductions appear on subsequence workloads compared with prior subsequence engines while still returning exact results.
Where Pith is reading between the lines
- The same segment-to-rectangle reduction might apply directly to other ordered sequence data such as event logs or sensor streams that exhibit trends.
- Extending the rectangle bounds to capture uncertainty intervals could support queries over noisy or incomplete time series without changing the core index.
- Because the index is spatial, multi-variate extensions become possible by treating each dimension as an additional coordinate axis inside the same rectangles.
Load-bearing premise
The line-segment approximation and rectangle translation preserve enough information that the spatial index can return exact matches with neither false negatives nor false positives.
What would settle it
Run a set of regex queries on a labeled dataset where every true match is known in advance; if the index ever misses a true match or returns a non-match, the exactness guarantee fails.
Figures




read the original abstract
Similarity search is a fundamental operation in time series analysis. Most existing techniques, however, require users to supply a precise sequence of values (typically an entire time series object) as the query input. This rigid requirement limits real-world applications, where users instead want to express patterns, trends, or value ranges. Flexible, pattern-based search has been explored in text retrieval and complex event processing, but remains underexplored for large-scale distributed time series. To close this gap, we propose TSseek, a regular-expression-powered search framework for distributed time series datasets. TSseek's query language enables users to compose patterns encompassing trends, value ranges, and wildcard segments. We show that conventional approximation techniques (e.g., PAA and SAX) and their index structures are ill-suited for such queries because they cannot operate on regular-expression query constructs. In TSseek, we map the time series objects and the query constructs into the same space by approximating time series objects as sequences of line segments that retain both trend (slope direction) and value range, and translating query constructs into bounding rectangles. To support efficient processing, we build TSseek-X, a distributed spatial index over the time series segments. TSseek supports two fundamental query types, namely whole-matching queries (over entire series) and subsequence-matching queries (over arbitrary windows within a series). Across benchmark and real-world datasets, full-scan, model-based, and SAX-based baselines all sacrifice either accuracy or speed, whereas TSseek returns exact answers efficiently. Also, for subsequence workloads, it achieves significant speedups over state-of-the-art subsequence matching engines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TSseek, a regular-expression-based search framework for distributed time series datasets. Time series are approximated as sequences of line segments retaining slope direction and value range; regex constructs are translated to bounding rectangles. These are indexed in the distributed spatial index TSseek-X to support exact whole-matching and subsequence-matching queries. Experiments on benchmark and real-world datasets claim that TSseek returns exact answers while outperforming full-scan, model-based, SAX-based, and state-of-the-art subsequence-matching baselines in accuracy or speed.
Significance. If the line-segment approximation and rectangle translation are shown to be conservative filters that guarantee no false negatives, the work would enable flexible pattern, trend, and range queries on large-scale time series, addressing a limitation of existing similarity search methods that require exact sequence inputs.
major comments (2)
- [Abstract and §3] Abstract and §3 (mapping and query translation): the central claim of exact answers requires that every true match produces at least one segment whose rectangle intersects the query region. No invariant, completeness argument, or proof is supplied showing that the chosen segment granularity and rectangle construction are complete for all supported regex operators (including wildcards), so false negatives remain possible before post-filtering.
- [Experimental evaluation] Experimental evaluation (results tables): the reported exactness and speedups rest on the unverified filter property above. Without reported checks for missed matches, error-bound measurements, or controls that would detect false negatives on the tested datasets, the performance claims cannot be assessed as sound.
minor comments (2)
- [§3] Clarify the precise definition of line-segment parameters (number of segments, slope discretization) and how they interact with the spatial index construction.
- [§3] Add a short table or pseudocode summarizing the regex-to-rectangle translation rules for each supported operator.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on the completeness of our filter and the experimental validation. We address each major comment below and will revise the manuscript to incorporate a formal argument and additional verification.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (mapping and query translation): the central claim of exact answers requires that every true match produces at least one segment whose rectangle intersects the query region. No invariant, completeness argument, or proof is supplied showing that the chosen segment granularity and rectangle construction are complete for all supported regex operators (including wildcards), so false negatives remain possible before post-filtering.
Authors: We agree that a formal completeness argument is required to support the claim of exact answers. In the revised version we will add a dedicated subsection to §3 that states the invariant (every true match must intersect at least one query rectangle) and supplies a proof sketch covering all supported regex operators, including wildcards. The argument will show that the chosen line-segment granularity and rectangle construction are conservative and therefore produce no false negatives prior to post-filtering. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation (results tables): the reported exactness and speedups rest on the unverified filter property above. Without reported checks for missed matches, error-bound measurements, or controls that would detect false negatives on the tested datasets, the performance claims cannot be assessed as sound.
Authors: We acknowledge that the current experimental section does not explicitly verify the absence of false negatives. In the revision we will extend the evaluation with additional controls that enumerate all true matches via full scan on the benchmark and real-world datasets, then confirm that TSseek reports every such match. We will also report the measured false-negative rate (expected to be zero) alongside the existing timing and accuracy results. revision: yes
Circularity Check
No circularity; new mapping and index construction evaluated against external baselines
full rationale
The paper presents TSseek as a novel framework that maps time series to line-segment sequences and regex constructs to bounding rectangles, then builds a distributed spatial index (TSseek-X) for exact whole- and subsequence-matching queries. No equations, fitted parameters, self-citations, or uniqueness theorems are invoked in the provided text that would reduce any claimed result to an input by construction. Performance claims rest on direct comparisons to independent baselines (full-scan, SAX, model-based, and subsequence engines), satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Approximating time series as sequences of line segments that retain both trend (slope direction) and value range, combined with translating query constructs into bounding rectangles, enables exact matching via spatial indexing.
Reference graph
Works this paper leans on
-
[1]
A Large-scale 12-Lead Electrocardiogram Database for Arrhythmia Study, version 1.0
2022. A Large-scale 12-Lead Electrocardiogram Database for Arrhythmia Study, version 1.0. https://physionet.org/content/ecg-arrhythmia/1.0.0/
2022
-
[2]
2024. POSIX.1-2024 – Portable Operating System Interface (Base Specifications, Issue 8), Regular Expressions. https://pubs.opengroup.org/onlinepubs/97999197 99/
arXiv 2024
-
[3]
Rakesh Agrawal, Christos Faloutsos, and Arun Swami. 1993. Efficient Similarity Search in Sequence Databases. InProc. Foundations of Data Organization and Algorithms (FODO) (LNCS, Vol. 730). Springer, 69–84
1993
-
[4]
Sawhney, and Kyuseok Shim
Rakesh Agrawal, King-Ip Lin, Harpreet S. Sawhney, and Kyuseok Shim. 1995. Fast Similarity Search in the Presence of Noise, Scaling, and Translation in Time-Series Databases. InProceedings of the 21st International Conference on Very Large Data Bases (VLDB). Morgan Kaufmann, Zurich, Switzerland, 490–501. https://www.vldb.org/conf/1995/P490.PDF
1995
-
[5]
Lars Arge, Mark De Berg, Herman Haverkort, and Ke Yi. 2008. The priority R-tree: A practically efficient and worst-case optimal R-tree.TALG4, 1 (2008), 1–30
2008
-
[6]
2017.Survey and Compari- son of Open Source Time Series Databases
Andreas Bader, Oliver Kopp, and Michael Falkenthal. 2017.Survey and Compari- son of Open Source Time Series Databases
2017
-
[7]
Anthony Bagnall and Jason Lines. 2014. An Experimental Evaluation of Nearest Neighbour Time Series Classification. arXiv:1406.4757 [cs.LG] https://arxiv.org/ abs/1406.4757
Pith/arXiv arXiv 2014
-
[8]
Norbert Beckmann, Hans-Peter Kriegel, Ralf Schneider, and Bernhard Seeger
-
[9]
InSIGMOD, Vol
The R*-tree: an efficient and robust access method for points and rectangles. InSIGMOD, Vol. 19. ACM, 322–331
-
[10]
Berndt and James Clifford
Donald J. Berndt and James Clifford. 1994. Using Dynamic Time Warping to Find Patterns in Time Series. InProceedings of the 3rd International Conference on Knowledge Discovery and Data Mining (KDD Workshop). AAAI Press, Seattle, WA, USA, 359–370
1994
-
[11]
Siddhartha Bhandari, Neil Bergmann, Raja Jurdak, and Branislav Kusy. 2017. Time Series Data Analysis of Wireless Sensor Network Measurements of Temperature. Sensors17 (05 2017), 1221. doi:10.3390/s17061221
-
[12]
Alessandro Camerra, Themis Palpanas, Jin Shieh, and Eamonn Keogh. 2010. iSAX 2.0: Indexing and Mining One Billion Time Series. In2010 IEEE International Conference on Data Mining (ICDM). 58–67. doi:10.1109/ICDM.2010.124
-
[13]
A. Chakraborti, M. Patriarca, and M. S. Santhanam. [n. d.].Financial Time-series Analysis: a Brief Overview. Springer Milan, 51–67. doi:10.1007/978-88-470-0665- 2_4
-
[14]
Kin-Pong Chan and Ada Wai-Chee Fu. 1999. Efficient time series matching by wavelets. InICDE. IEEE, 126–133
1999
-
[15]
Georgios Chatzigeorgakidis, Dimitrios Skoutas, Kostas Patroumpas, Themis Palpanas, Spiros Athanasiou, and Spiros Skiadopoulos. 2021. Twin Subsequence Search in Time Series. arXiv:2104.06874 [cs.DS] https://arxiv.org/abs/2104.06874
arXiv 2021
-
[16]
Chia-Shang James Chu. 1995. Time Series Segmentation: A Sliding Window Approach.Information Sciences85, 1–3 (1995), 147–173. doi:10.1016/0020- 0255(95)00021-G
-
[17]
Charles L. A. Clarke and Gordon V. Cormack. 1997. On the Use of Regular Expressions for Searching Text.ACM Trans. Program. Lang. Syst.19, 3 (1997), 413–426. doi:10.1145/256167.256174
-
[18]
Cook, Göksel Mısırlı, and Zhong Fan
Andrew A. Cook, Göksel Mısırlı, and Zhong Fan. 2020. Anomaly Detection for IoT Time-Series Data: A Survey.IEEE Internet of Things Journal7, 7 (2020), 6481–6494. doi:10.1109/JIOT.2019.2958185
-
[19]
Gianpaolo Cugola and Alessandro Margara. 2015. The Complex Event Processing Paradigm. InData Management in Pervasive Systems, Francesco Colace, Massimo De Santo, Vincenzo Moscato, Antonio Picariello, Fabio A. Schreiber, and Letizia Tanca (Eds.). Springer International Publishing, Cham, 113–133. doi:10.1007/978- 3-319-20062-0_6
-
[20]
Hui Ding, Goce Trajcevski, Peter Scheuermann, Xiaoyue Wang, and Eamonn Keogh. 2008. Querying and Mining of Time Series Data: Experimental Com- parison of Representations and Distance Measures.Proceedings of the VLDB Endowment1, 2 (2008), 1542–1552. doi:10.14778/1454159.1454226
-
[21]
Ranganathan, and Yannis Manolopoulos
Christos Faloutsos, M. Ranganathan, and Yannis Manolopoulos. 1994. Fast sub- sequence matching in time-series databases. InProceedings of the 1994 ACM SIGMOD International Conference on Management of Data(Minneapolis, Min- nesota, USA)(SIGMOD ’94). Association for Computing Machinery, New York, NY, USA, 419–429. doi:10.1145/191839.191925
-
[22]
Navid Mohammadi Foumani, Chang Wei Tan, Geoffrey I Webb, Hamid Rezatofighi, and Mahsa Salehi. 2024. Series2Vec: similarity-based self-supervised representation learning for time series classification.Data Mining and Knowledge Discovery38, 4 (2024), 2520–2544. doi:10.1007/s10618-024-01043-w
-
[23]
Jeffrey E. F. Friedl. 2006.Mastering Regular Expressions(3rd ed.). O’Reilly
2006
-
[24]
Tak-chung Fu, Fu-lai Chung, Robert Luk, and Chak-man Ng. 2007. Stock time series pattern matching: Template-based vs. rule-based approaches.Eng. Appl. Artif. Intell.20, 3 (April 2007), 347–364. doi:10.1016/j.engappai.2006.07.003
-
[25]
A. L. Goldberger, L. A. N. Amaral, L. Glass, J. M. Hausdorff, P. C. Ivanov, R. G. Mark, J. E. Mietus, G. B. Moody, C. K. Peng, and H. E. Stanley. 2000. PhysioBank, PhysioToolkit, and PhysioNet: Components of a New Research Resource for Complex Physiologic Signals.Circulation101, 23 (2000), e215–e220. doi:10.1161/ 01.cir.101.23.e215 PMID: 10851218
2000
-
[26]
Antonin Guttman. 1984. R-trees: A dynamic index structure for spatial searching. InProceedings of the 1984 ACM SIGMOD international conference on Management of data. 47–57
1984
-
[27]
Sylvain Hallé. 2017. From Complex Event Processing to Simple Event Processing. arXiv:1702.08051 [cs.DB] https://arxiv.org/abs/1702.08051
Pith/arXiv arXiv 2017
-
[28]
Chaochen Hu, Zihan Sun, Chao Li, Yong Zhang, and Chunxiao Xing. 2023. Survey of Time Series Data Generation in IoT.Sensors23 (2023). doi:10.3390/s23156976 Xiaoshuai Li+, Khalid Alnuaim +, Mohamed Y. Eltabakh ∗, and Elke A. Rundensteiner +
-
[29]
Silu Huang, Erkang Zhu, Surajit Chaudhuri, and Leonhard Spiegelberg. 2023. T-Rex: Optimizing Pattern Search on Time Series.Proc. ACM Manag. Data1, 2, Article 130 (June 2023), 26 pages. doi:10.1145/3589275
-
[30]
Hassan Ismail Fawaz, Germain Forestier, Jonathan Weber, Lhassane Idoumghar, and Pierre-Alain Muller. 2019. Deep Learning for Time Series Classification: A Review.Data Mining and Knowledge Discovery33, 4 (2019), 917–963. doi:10.100 7/s10618-019-00619-1
2019
-
[31]
1993.Hilbert R-tree: An improved R-tree using fractals
Ibrahim Kamel and Christos Faloutsos. 1993.Hilbert R-tree: An improved R-tree using fractals. Technical Report
1993
-
[32]
Eamonn Keogh, Kaushik Chakrabarti, Michael Pazzani, and Sharad Mehrotra
-
[33]
Dimensionality reduction for fast similarity search in large time series databases.KAIS3 (2001), 263–286
2001
-
[34]
Eamonn Keogh, Selina Chu, David Hart, and Michael Pazzani. 2004. Segmenting Time Series: A Survey and Novel Approach. InData Mining in Time Series Databases. World Scientific, 1–22. doi:10.1142/9789812565402_0001
-
[35]
Eamonn Keogh and Chotirat Ann Ratanamahatana. 2005. Exact indexing of dynamic time warping.Knowledge and Information Systems7, 3 (2005), 358–386. doi:10.1007/s10115-004-0154-9
-
[36]
Keogh, Kaushik Chakrabarti, Sharad Mehrotra, and Michael J
Eamonn J. Keogh, Kaushik Chakrabarti, Sharad Mehrotra, and Michael J. Pazzani
-
[37]
Locally Adaptive Dimensionality Reduction for Indexing Large Time Series Databases. InProceedings of the 2001 ACM SIGMOD International Conference on Management of Data, Sharad Mehrotra and Timos K. Sellis (Eds.). ACM, 151–162. doi:10.1145/375663.375680
-
[38]
Eamonn J. Keogh, Selina Chu, David M. Hart, and Michael J. Pazzani. 2001. An Online Algorithm for Segmenting Time Series. InProc. IEEE Int. Conf. on Data Mining (ICDM). 289–296. doi:10.1109/ICDM.2001.989531
-
[39]
Jessica Lin, Eamonn Keogh, and Stefano Lonardi. 2005. Visualizing and Dis- covering Non-Trivial Patterns in Large Time Series Databases.Information Visualization4, 2 (2005), 61–82
2005
-
[40]
Jessica Lin, Eamonn Keogh, Li Wei, and Stefano Lonardi. 2007. Experiencing SAX: a novel symbolic representation of time series.Data Mining and knowledge discovery15 (2007), 107–144
2007
-
[41]
Michele Linardi and Themis Palpanas. 2020. Scalable Data Series Subsequence Matching with ULISSE. arXiv:2009.10373 [cs.DB] https://arxiv.org/abs/2009.103 73
arXiv 2020
-
[42]
Shuhan Liu, Yuan Tian, Zikun Deng, Weiwei Cui, Haidong Zhang, Di Weng, and Yingcai Wu. 2025. Relation-Driven Query of Multiple Time Series.IEEE Transactions on Visualization and Computer Graphics31, 8 (2025), 4210–4225. doi:10.1109/TVCG.2024.3397554
-
[43]
David C. Luckham. 2002.The Power of Events: An Introduction to Complex Event Processing in Distributed Enterprise Systems. Addison-Wesley
2002
-
[44]
Yu. A. Malkov and D. A. Yashunin. 2018. Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs. arXiv:1603.09320 [cs.DS] https://arxiv.org/abs/1603.09320
Pith/arXiv arXiv 2018
-
[45]
Konstantinos Mamouras and Agnishom Chattopadhyay. 2024. Efficient Matching of Regular Expressions with Lookaround Assertions.Proc. ACM Program. Lang. 8, POPL, Article 92 (Jan. 2024), 31 pages. doi:10.1145/3632934
-
[46]
Gautier Marti, Sébastien Andler, Frank Nielsen, and Philippe Donnat. 2016. Clus- tering Financial Time Series: How Long is Enough? arXiv:1603.04017 [stat.ML] https://arxiv.org/abs/1603.04017
Pith/arXiv arXiv 2016
-
[47]
M. L. Micó, J. Oncina, and E. Vidal. 1994. A new version of the nearest-neighbour approximating and eliminating search algorithm (AESA) with linear preprocess- ing time and memory requirements.Pattern Recognition Letters15, 1 (1994), 9–17. doi:10.1016/0167-8655(94)90095-7
-
[48]
Yang-Sae Moon, Kyu-Young Whang, and Woong-Kee Loh. 2001. Duality-Based Subsequence Matching in Time-Series Databases. InProceedings of the 17th International Conference on Data Engineering, April 2-6, 2001, Heidelberg, Germany, Dimitrios Georgakopoulos and Alexander Buchmann (Eds.). IEEE Computer Society, 263–272. doi:10.1109/ICDE.2001.914837
-
[49]
Cristina Morariu and Theodor Borangiu. 2018. Time series forecasting for dynamic scheduling of manufacturing processes. In2018 IEEE International Conference on Automation, Quality and Testing, Robotics (AQTR). 1–6. doi:10.110 9/AQTR.2018.8402748
arXiv 2018
-
[50]
Taisei Nogami and Tachio Terauchi. 2023. On the Expressive Power of Regular Expressions with Backreferences. arXiv:2307.08531 [cs.FL] https://arxiv.org/ab s/2307.08531
arXiv 2023
-
[51]
Themis Palpanas. 2015. Data Series Management: The Road to Big Sequence Analytics.ACM SIGMOD Record44, 2 (2015), 47–52
2015
-
[52]
John Paparrizos and Luis Gravano. 2015. k-Shape: Efficient and Accurate Clus- tering of Time Series. InProceedings of the 2015 ACM SIGMOD International Conference on Management of Data(Melbourne, Victoria, Australia)(SIGMOD ’15). Association for Computing Machinery, New York, NY, USA, 1855–1870. doi:10.1145/2723372.2737793
-
[53]
Botao Peng. 2020. Data Series Indexing Gone Parallel. In2020 IEEE 36th Interna- tional Conference on Data Engineering (ICDE). 2059–2063. doi:10.1109/ICDE4830 7.2020.00244
-
[54]
2024.perlre — Perl Regular Expressions
Perl Community. 2024.perlre — Perl Regular Expressions. https://perldoc.perl.o rg/perlre Perl documentation
2024
-
[55]
PostGIS Development Team. 2024. PostGIS Documentation. https://postgis.net/ documentation Accessed: 2024-04-17
2024
-
[56]
Thanawin Rakthanmanon, Bilson Campana, Abdullah Mueen, Gustavo Batista, Brandon Westover, Qiang Zhu, Jesin Zakaria, and Eamonn Keogh. 2012. Search- ing and Mining Trillions of Time Series Subsequences under Dynamic Time Warping. InProceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 262–270. doi:10.1145/23395...
-
[57]
Bala Ravikumar. 1998. Parallel algorithms for finite automata problems. In Advances in Randomized Parallel Computing. Springer, 209–239
1998
-
[58]
Mustafizur Rahman, and Raihanul Islam
Asif Salekin, Md. Mustafizur Rahman, and Raihanul Islam. 2012. Composite pattern matching in time series. In2012 15th International Conference on Computer and Information Technology (ICCIT). IEEE, 173–178. doi:10.1109/ICCITechn.2012 .6509784
-
[59]
Nicholas I. Sapankevych and Ravi Sankar. 2009. Time series prediction using support vector machines: a survey.Comp. Intell. Mag.4, 2 (May 2009), 24–38. doi:10.1109/MCI.2009.932254
-
[60]
Jeffrey D. Scargle, Jay P. Norris, Brad Jackson, and James Chiang. 2013. STUDIES IN ASTRONOMICAL TIME SERIES ANALYSIS. VI. BAYESIAN BLOCK REPRE- SENTATIONS.The Astrophysical Journal764, 2 (Feb. 2013), 167. doi:10.1088/0004- 637x/764/2/167
-
[61]
Eli Sherman, Hitinder Gurm, Ulysses Balis, Scott Owens, and Jenna Wiens
-
[62]
arXiv:1811.12520 [cs.LG] https://arxiv.org/abs/1811.12520
Leveraging Clinical Time-Series Data for Prediction: A Cautionary Tale. arXiv:1811.12520 [cs.LG] https://arxiv.org/abs/1811.12520
-
[63]
Jin Shieh and Eamonn Keogh. 2008. iSAX: indexing and mining terabyte sized time series. InProceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining(Las Vegas, Nevada, USA)(KDD ’08). Association for Computing Machinery, New York, NY, USA, 623–631. doi:10.114 5/1401890.1401966
arXiv 2008
-
[64]
Shumway and D.S
R.H. Shumway and D.S. Stoffer. 2010.Time Series Analysis and Its Applications: With R Examples. Springer New York. https://books.google.com/books?id=db S5IQ8P5gYC
2010
-
[65]
Tomáš Skopal, Jaroslav Pokorný, and Václav Snášel. 2004. PM-tree: Pivoting Metric Tree for Similarity Search in Multimedia Databases. InProceedings of ADBIS (Local Proceedings). 803–815
2004
-
[66]
Ken Thompson. 1968. Regular Expression Search Algorithm.Commun. ACM11, 6 (1968), 419–422
1968
-
[67]
Timescale. [n. d.]. Time Series Benchmark Suite (TSBS). GitHub repository. [Online]. Available: https://github.com/timescale/tsbs. Accessed: Oct. 10, 2025
2025
-
[68]
Ryota TOMODA and Hisashi Koga. 2025. Section Min-Hash Approximating Time Series Search based on Dynamic Time Warping.IEICE Transactions on Information and Systems(01 2025). doi:10.1587/transinf.2024DAP0004
-
[69]
McGrail, Peng Wang, Diaohan Luo, Jun Yuan, Jianmin Wang, and Jiaguang Sun
Chen Wang, Xiangdong Huang, Jialin Qiao, Tian Jiang, Lei Rui, Jinrui Zhang, Rong Kang, Julian Feinauer, Kevin A. McGrail, Peng Wang, Diaohan Luo, Jun Yuan, Jianmin Wang, and Jiaguang Sun. 2020. Apache IoTDB: Time-series Database for Internet of Things.Proceedings of the VLDB Endowment13, 12 (2020), 2901–2904. doi:10.14778/3415478.3415504
-
[70]
Mengzhao Wang, Xiaoliang Xu, Qiang Yue, and Yuxiang Wang. 2021. A com- prehensive survey and experimental comparison of graph-based approximate nearest neighbor search.Proc. VLDB Endow.14, 11 (July 2021), 1964–1978. doi:10.14778/3476249.3476255
-
[71]
Qitong Wang and Themis Palpanas. 2021. Deep Learning Embeddings for Data Series Similarity Search. InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). Association for Computing Machinery, New York, NY, USA, 1708–1716. doi:10.1145/3447548.3467317
-
[72]
Will Wang, Ina Chen, Leeor Hershkovich, Jiamu Yang, Ayush Shetty, Geetika Singh, Yihang Jiang, Aditya Kotla, Jason Shang, Rushil Yerrabelli, Ali Roghanizad, Md Shandhi, and Jessilyn Dunn. 2022. A Systematic Review of Time Series Classification Techniques Used in Biomedical Applications.Sensors22 (10 2022),
2022
-
[73]
doi:10.3390/s22208016
-
[74]
Eugene Wu, Philippe Cudre-Mauroux, and Samuel Madden. 2009. Demonstration of the TrajStore System.PVLDB2 (08 2009), 1554–1557. doi:10.14778/1687553.1 687589
-
[75]
Huanmei Wu, Betty Salzberg, Gregory C Sharp, Steve B Jiang, Hiroki Shirato, and David Kaeli. 2005. Subsequence matching on structured time series data. In Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data(Baltimore, Maryland)(SIGMOD ’05). Association for Computing Machinery, New York, NY, USA, 682–693. doi:10.1145/1066157.1066235
-
[76]
Jiaye Wu, Peng Wang, Ningting Pan, Chen Wang, Wei Wang, and Jianmin Wang
-
[77]
In2019 IEEE 35th International Conference on Data Engineering (ICDE)
KV-Match: A Subsequence Matching Approach Supporting Normalization and Time Warping. In2019 IEEE 35th International Conference on Data Engineering (ICDE). 866–877. doi:10.1109/ICDE.2019.00082
-
[78]
Djamel Edine Yagoubi, Reza Akbarinia, Florent Masseglia, and Themis Palpanas
-
[79]
In2017 IEEE International Conference on Data Mining (ICDM)
DPiSAX: Massively Distributed Partitioned iSAX. In2017 IEEE International Conference on Data Mining (ICDM). 1135–1140. doi:10.1109/ICDM.2017.151
-
[80]
Data structures and algorithms for nearest neighbor search in general metric spaces,
Peter N. Yianilos. 1993. Data Structures and Algorithms for Nearest Neighbor Search in General Metric Spaces. InProceedings of the 4th Annual ACM-SIAM Symposium on Discrete Algorithms (SODA). 311–321. doi:10.1145/313559.313789 TSseek: Regular Expression-Based Similarity Search for Distributed Time Series Datasets
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.