AudioProcessBench: Benchmark for Identifying Process Errors in Audio-Grounded Reasoning
Pith reviewed 2026-06-27 18:06 UTC · model grok-4.3
The pith
AudioProcessBench supplies annotated reasoning traces from six models to test whether verifiers can spot step-level process errors in audio tasks and improve final answer selection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
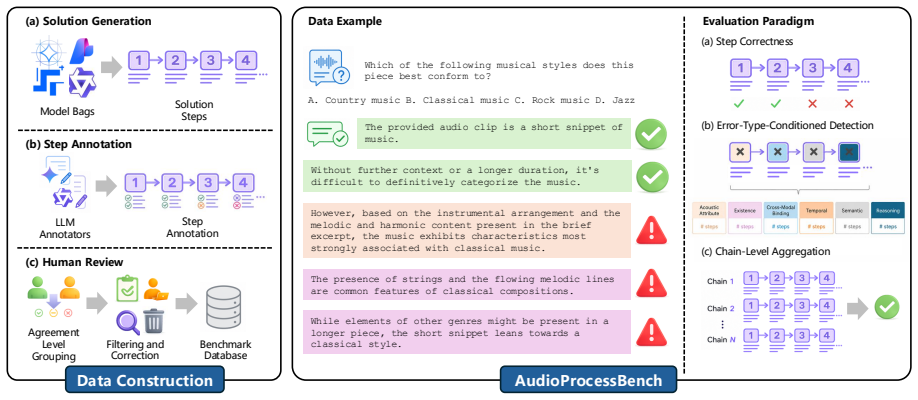
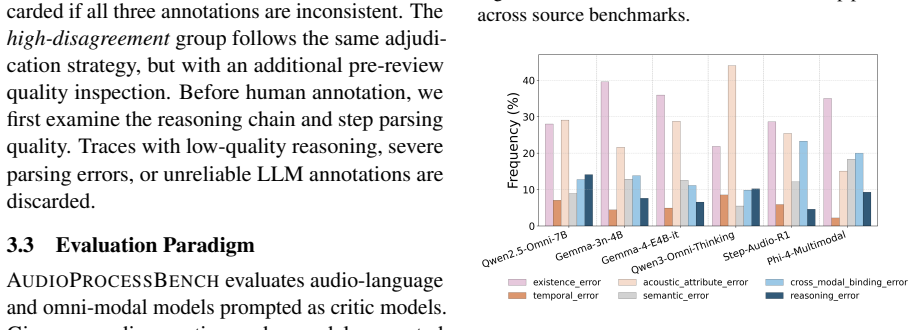
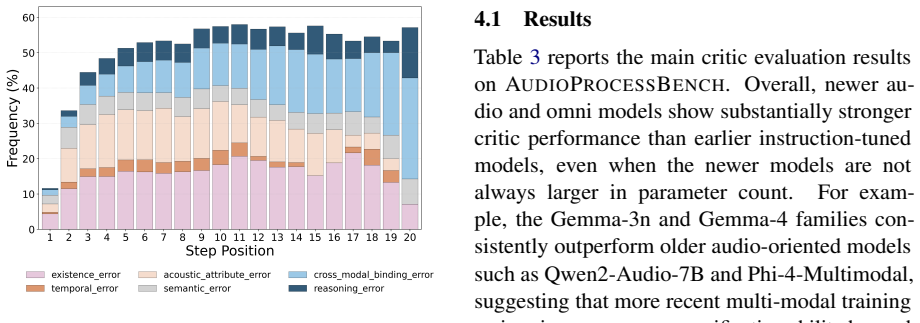
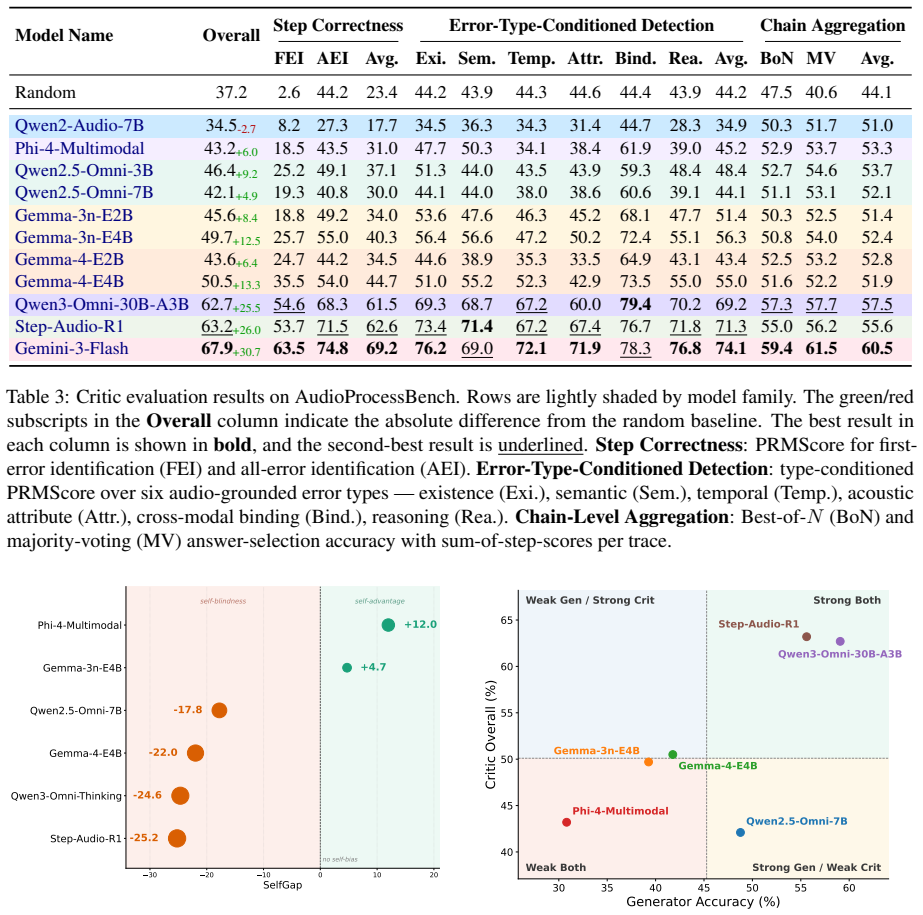
AudioProcessBench contains diverse reasoning traces generated by six audio and omni language models, with each trace segmented into steps and annotated for binary correctness plus fine-grained error types, supporting evaluation under step correctness identification, error-type-conditioned detection, and chain-level aggregation to select or combine traces for the same question.
What carries the argument
AudioProcessBench benchmark, built from segmented and annotated reasoning traces, evaluated through three paradigms that separately test error detection, type-specific diagnosis, and answer improvement via verification.
If this is right
- Models can be measured for their capacity to detect process errors during audio reasoning.
- Differences in verifier performance across audio-specific error types can be diagnosed directly.
- Process verification can be checked for whether it produces better answer selection than using raw traces alone.
Where Pith is reading between the lines
- The annotation method could be applied to build similar process benchmarks for other sensory modalities beyond audio.
- Verifiers improved via this benchmark might be integrated into training loops to create more reliable audio-language models.
- The error-type taxonomy may reveal systematic gaps that point to needed changes in how models generate audio reasoning steps.
Load-bearing premise
The reasoning traces produced by the six models represent real audio reasoning well enough, and the binary labels plus error-type annotations are accurate and consistent enough to act as ground truth.
What would settle it
If verifiers trained or tested on AudioProcessBench show no gain in selecting correct final answers compared with models that skip process verification, the claim that step-level error identification improves audio reasoning would not hold.
Figures






read the original abstract
Large audio-language models (LALMs) increasingly use explicit reasoning traces for complex audio understanding, yet the evaluation of reasoning quality remains underexplored. Although process-level benchmarks for process reward models (PRMs) have advanced reasoning evaluation in text and multi-modal domains, comparable evaluation for audio reasoning remains limited. In this paper, we present AudioProcessBench, a comprehensive benchmark for step-level process error identification in audio reasoning. AudioProcessBench contains diverse reasoning traces generated by 6 audio and omni language models. Each trace is segmented into discrete reasoning steps and annotated with binary step correctness and fine-grained error types. Our benchmark evaluates models under three complementary paradigms: (1) step correctness identification, (2) error-type-conditioned detection for diagnosing audio-specific verifier capacities, and (3) chain-level aggregation, where verifiers select or aggregate among multiple reasoning traces for the same question. This design enables a systematic analysis of whether current models can detect process errors, whether their weaknesses differ across audio-specific error types, and whether process verification translates into improved answer selection. AudioProcessBench provides a testbed for future research on audio reasoning verifiers, process reward models, and reliable omni-modal reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AudioProcessBench, a benchmark for identifying process errors in audio-grounded reasoning. It contains reasoning traces from six audio and omni-language models, segmented into steps and annotated with binary correctness labels plus fine-grained error types. The benchmark supports three evaluation paradigms: step-level correctness identification, error-type-conditioned detection, and chain-level aggregation to select or combine traces for improved answer selection.
Significance. If the annotations are reliable, the benchmark would fill a clear gap by enabling systematic diagnosis of verifier performance on audio-specific errors and testing whether process verification improves final outputs. This provides a concrete testbed for audio process reward models and omni-modal reasoning research.
major comments (1)
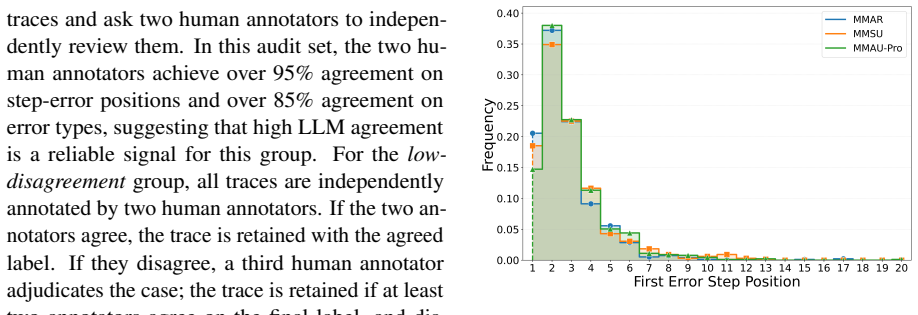
- [Abstract / benchmark construction] Abstract and benchmark construction section: the manuscript describes the three evaluation paradigms and states that traces are annotated with binary step correctness and fine-grained error types, yet supplies no annotation protocol, number of annotators, inter-annotator agreement statistics, or validation procedure for audio-specific categories such as acoustic misinterpretation or temporal misalignment. Because all three paradigms treat these labels as ground truth, the absence of reliability evidence is load-bearing for the central claim of diagnostic utility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on annotation reliability, which is critical for the benchmark's utility. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / benchmark construction] Abstract and benchmark construction section: the manuscript describes the three evaluation paradigms and states that traces are annotated with binary step correctness and fine-grained error types, yet supplies no annotation protocol, number of annotators, inter-annotator agreement statistics, or validation procedure for audio-specific categories such as acoustic misinterpretation or temporal misalignment. Because all three paradigms treat these labels as ground truth, the absence of reliability evidence is load-bearing for the central claim of diagnostic utility.
Authors: We agree that the absence of annotation details weakens the claims. In the revised manuscript we will add a new subsection under benchmark construction that specifies: (1) the full annotation protocol (step segmentation rules, error taxonomy definitions, and audio-specific guidelines), (2) the number of annotators and their qualifications, (3) inter-annotator agreement statistics, and (4) the validation procedure used for categories such as acoustic misinterpretation and temporal misalignment, including example annotations. This will directly support the ground-truth status of the labels across all three evaluation paradigms. revision: yes
Circularity Check
No circularity: benchmark construction is self-contained
full rationale
This is a benchmark paper introducing AudioProcessBench with human-annotated reasoning traces from six models, evaluated under three paradigms (step correctness, error-type detection, chain aggregation). No equations, fitted parameters, or derivations are present that could reduce to inputs by construction. The central claims rest on the creation and use of the dataset itself rather than any self-referential prediction or uniqueness theorem. Annotation reliability is an external validity concern, not a circularity issue within the reported framework.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human or expert annotations of step correctness and error types provide reliable ground truth for audio reasoning evaluation.
Reference graph
Works this paper leans on
-
[1]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Let’s verify step by step. InInternational Conference on Learning Representations, volume 2024, pages 39578–39601. Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingx- uan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, and 1 others. 2025. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Step-audio-r1 technical report.arXiv preprint arXiv:2511.15848, 2025
Step-audio-r1 technical report.arXiv preprint arXiv:2511.15848. Weiyun Wang, Zhangwei Gao, Lianjie Chen, Zhe Chen, Jinguo Zhu, Xiangyu Zhao, Yangzhou Liu, Yue Cao, Shenglong Ye, Xizhou Zhu, and 1 others. 2025. Visu- alprm: An effective process reward model for multi- modal reasoning.arXiv preprint arXiv:2503.10291. 10 Xumeng Wen, Zihan Liu, Shun Zheng, Sh...
-
[3]
Reward models in deep reinforcement learn- ing: A survey.arXiv preprint arXiv:2506.15421. Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. 2025. Processbench: Iden- tifying process errors in mathematical reasoning. In Proceedings of the 63rd Annual Meeting of the As- sociation for Comp...
-
[4]
Do NOT paraphrase, summarize, translate, reorder, or insert any word, character, or punctuation
PRESERVE THE ORIGINAL TEXT EXACTLY. Do NOT paraphrase, summarize, translate, reorder, or insert any word, character, or punctuation. Each output step must be a verbatim contiguous substring of the input reasoning trace
-
[5]
The concatenation of all steps (joined by single space or newline) must reconstruct the original reasoning trace (allowing only inter-step whitespace)
-
[6]
Step boundaries are decided by natural reasoning flow: one perceptual claim, one inference, one knowledge lookup, one conclusion, etc
-
[7]
steps": [
Don’t over-split (every step does real work) or under-split (a step spans multiple distinct reasoning moves). GRANULARITY GUIDANCE: - Aim for 5–12 steps for most reasoning traces; up to 20 only for genuinely very long reasoning (>4000 chars). - Numbered bullets (1., 2., 3.) and bullet markers (-, *) are NOT automatic step boundaries — group consecutive bu...
-
[8]
Label the step as exactly one of: ‘correct’, ‘existence_error’, ‘temporal_error’, ‘acoustic_attribute_error’, ‘semantic_error’, ‘cross_modal_binding_error’, ‘reasoning_error’
-
[9]
Justify the label in a 2–4 sentence ‘analysis’ citing specific audio evidence or logical structure
-
[10]
step_id”: <int>, “step_text
After labeling all steps, populate ‘first_error_step’ and ‘final_answer_correct’. You must label every step exactly once, in the order provided. Do not skip, merge, split, re-order, or invent steps. The set of ‘step_id’ values in your output must equal the set of ‘step_id’ values in <solver_segmented_steps> – no more, no less. # 2. Step-correctness criter...
-
[11]
Listen to the entire audio clip end-to-end at least once
-
[12]
Read the question and ground-truth answer to understand the task framing, without using the ground truth to retro-justify step labels
-
[13]
Read the pre-segmented steps in order to understand the chain’s trajectory and endpoints
-
[14]
For each step: re-listen to relevant audio spans, decide whether the step contains an objectively incorrect and load-bearing claim, apply the precedence rule, determine whether the step is a fresh error or propagation, and write the analysis
-
[15]
Populate ‘first_error_step’ with the smallest non-correct step id, or null if all steps are correct
-
[16]
Set ‘final_answer_correct’ by comparing the solver’s effective answer to the ground truth semantically
-
[17]
step_id": <int>,
Output the complete JSON object and nothing else. Begin now. Figure 9: Prompt template for step-level audio reasoning verification and error-type annotation (Part 2). 17 You are an expert audio reasoning critic. Your task is to analyze problem-solving steps and provide structured assessments in JSON format. For each step, emit a numerical ‘score‘∈[-1, +1]...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.