HiMem-WAM: Hierarchical Memory-Gated World Action Models for Robotic Manipulation
Pith reviewed 2026-06-27 13:07 UTC · model grok-4.3
The pith
HiMem-WAM adds hierarchical skill latents and boundary-triggered memory updates to world action models for better long-horizon robotic manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
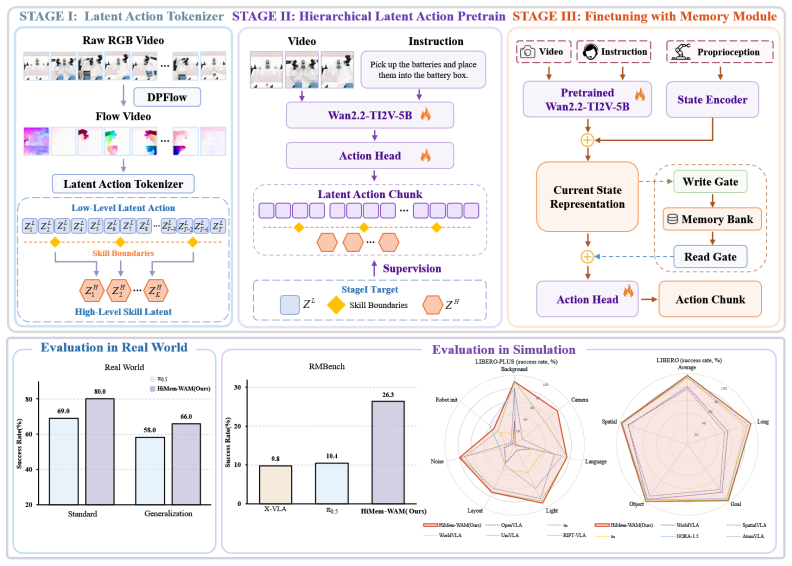
The paper establishes that jointly learning motion-centric latent actions and high-level skill latents, then routing memory writes through a boundary-aware gate at predicted skill transitions, supplies structured temporal abstraction and compact state representations that improve performance on long-horizon manipulation without test-time future video generation.
What carries the argument
Boundary-aware memory gate that writes compact task states at predicted skill transitions, within a hierarchical latent action framework.
If this is right
- Hierarchical latents increase robustness when the robot encounters deployment perturbations.
- The memory module delivers clear gains on memory-dependent long-horizon manipulation.
- Causal inference proceeds without test-time generation of future video or optical flow.
- The same architecture yields measurable improvements on the LIBERO, LIBERO-PLUS, RMBench and real-world task suites.
Where Pith is reading between the lines
- The same boundary-triggered update rule could be tested on sequential tasks outside manipulation, such as multi-step navigation or tool-use chains.
- Avoiding future video synthesis at inference time may reduce the compute budget needed for closed-loop robot control.
- The skill-transition predictor could be evaluated in environments where task boundaries are deliberately made less distinct.
Load-bearing premise
The boundary-aware memory gate can accurately predict skill transitions to write compact task states.
What would settle it
Ablating the memory gate produces no measurable drop in success rate on memory-dependent long-horizon tasks, or the gate's transition predictions show low correlation with actual skill boundaries observed in execution traces.
Figures



read the original abstract
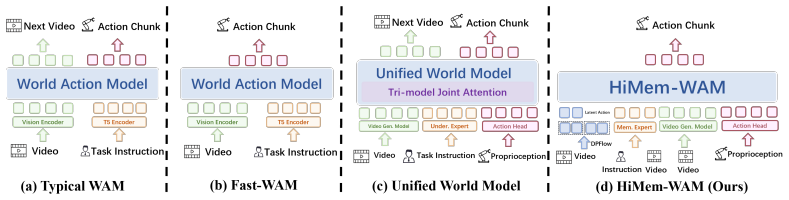
World Action Models (WAMs) have emerged as a new powerful paradigm for embodied intelligence, learning action-relevant visual dynamics that significantly enhance generalization and robustness. However, existing WAMs still struggle with task-relevant memory in long-horizon robotic manipulation. To address this, we present HiMem-WAM, a Hierarchical Memory-Gated WAM that integrates motion-centric latent actions, high-level skill latents, and boundary-triggered memory updates. Specifically, we develop a hierarchical latent action framework that jointly learns low-level motion and high-level skill latents, providing structured temporal abstraction. Meanwhile, a boundary-aware memory gate writes compact task states at predicted skill transitions, enabling causal inference without test-time generation of future video or optical flow estimation. Evaluated on LIBERO, LIBERO-PLUS, RMBench and real-world tasks, HiMem-WAM shows that hierarchical latents improve robustness under deployment perturbations, and the memory module substantially benefits memory-dependent long-horizon manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HiMem-WAM, a hierarchical memory-gated world action model for robotic manipulation. It proposes a hierarchical latent action framework combining low-level motion-centric latents and high-level skill latents, together with a boundary-aware memory gate that writes compact task states at predicted skill transitions. This is claimed to enable causal inference in long-horizon tasks without test-time future video generation or optical flow. Evaluations on LIBERO, LIBERO-PLUS, RMBench and real-world tasks are said to show that hierarchical latents improve robustness under perturbations and that the memory module substantially benefits memory-dependent manipulation.
Significance. If the core claims hold after verification, the work would offer a structured temporal abstraction and memory mechanism for world action models that avoids expensive test-time prediction, potentially improving robustness in long-horizon embodied tasks.
major comments (2)
- [Abstract] Abstract: the headline result that 'the memory module substantially benefits memory-dependent long-horizon manipulation' rests on the untested assumption that the boundary-aware memory gate accurately predicts skill transitions; no precision, recall, or error-rate metrics on transition detection, nor any ablation isolating gate errors, are referenced.
- [Evaluation] Evaluation sections: without quantitative evidence on gate accuracy or failure cases when transitions are mispredicted, the attribution of robustness gains specifically to the memory module (as opposed to the hierarchical latents alone) cannot be separated from the correctness of the transition predictor.
minor comments (1)
- [Abstract] The abstract uses qualitative phrasing ('substantially benefits') without accompanying numbers; adding effect sizes or baseline comparisons would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for stronger evidence on the boundary-aware memory gate. We address each major comment below and will incorporate the suggested analyses in the revision.
read point-by-point responses
-
Referee: [Abstract] the headline result that 'the memory module substantially benefits memory-dependent long-horizon manipulation' rests on the untested assumption that the boundary-aware memory gate accurately predicts skill transitions; no precision, recall, or error-rate metrics on transition detection, nor any ablation isolating gate errors, are referenced.
Authors: We agree that the abstract claim would benefit from direct evidence on gate accuracy. In the revised manuscript we will report precision, recall, and F1 scores for skill-transition prediction on held-out sequences from LIBERO and RMBench, plus an ablation that measures performance drop when the gate is replaced by oracle transitions versus noisy predictions. This will clarify the contribution of the memory module independent of transition-prediction quality. revision: yes
-
Referee: [Evaluation] without quantitative evidence on gate accuracy or failure cases when transitions are mispredicted, the attribution of robustness gains specifically to the memory module (as opposed to the hierarchical latents alone) cannot be separated from the correctness of the transition predictor.
Authors: We acknowledge the separation of contributions is currently incomplete. The revision will add (i) a quantitative gate-accuracy table, (ii) failure-case analysis showing task success rates when the gate errs, and (iii) an explicit comparison of hierarchical-latents-only versus full HiMem-WAM under identical perturbation conditions. These additions will allow readers to isolate the memory module's effect. revision: yes
Circularity Check
No circularity: empirical model description with no derivation chain or equations
full rationale
The paper describes an architectural model (hierarchical latents + boundary-aware memory gate) and reports empirical results on LIBERO, RMBench, and real-world tasks. No equations, first-principles derivations, parameter-fitting steps presented as predictions, or self-citation load-bearing claims appear in the abstract or visible text. The central claims rest on benchmark evaluations rather than any reduction of outputs to inputs by construction, satisfying the criteria for a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption World Action Models learn action-relevant visual dynamics that enhance generalization and robustness.
invented entities (2)
-
Hierarchical latent action framework
no independent evidence
-
Boundary-aware memory gate
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[2]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, et al. Openvla: An open-source vision-language-action model. In8th Annual Conference on Robot Learning, 2024
2024
-
[3]
Ghosh, H
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, C. Xu, J. Luo, et al. Octo: An open-source generalist robot policy. InProceedings of Robotics: Science and Systems, Delft, Netherlands, 2024
2024
-
[4]
H. Wu, Y . Jing, C. Cheang, G. Chen, J. Xu, X. Li, M. Liu, H. Li, and T. Kong. Unleashing large-scale video generative pre-training for visual robot manipulation.ICLR, 2024
2024
-
[5]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation. InThe Thirteenth International Conference on Learning Representations, 2024
2024
-
[6]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[7]
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, et al.π0.5: a vision-language-action model with open-world general- ization.arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[8]
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, et al. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model.arXiv preprint arXiv:2510.10274, 2025
Pith/arXiv arXiv 2025
-
[9]
W. Song, J. Chen, X. Sun, H. Lei, Y . Qin, W. Zhao, P. Ding, H. Zhao, T. Wang, P. Hou, et al. Rethinking the practicality of vision-language-action model: A comprehensive benchmark and an improved baseline.arXiv preprint arXiv:2602.22663, 2026
arXiv 2026
-
[10]
Y . Du, S. Yang, B. Dai, H. Dai, O. Nachum, J. Tenenbaum, D. Schuurmans, and P. Abbeel. Learning universal policies via text-guided video generation. InAdvances in Neural Informa- tion Processing Systems, volume 36, pages 9156–9172, 2023
2023
-
[11]
S. Zhou, Y . Du, J. Chen, Y . Li, D.-Y . Yeung, and C. Gan. Robodreamer: Learning composi- tional world models for robot imagination. InInternational Conference on Machine Learning, pages 61885–61896, 2024
2024
-
[12]
Y . Feng, H. Tan, X. Mao, C. Xiang, G. Liu, S. Huang, H. Su, and J. Zhu. Vidar: Embodied video diffusion model for generalist manipulation.arXiv preprint arXiv:2507.12898, 2025
Pith/arXiv arXiv 2025
-
[13]
Q. Lv, W. Kong, H. Li, J. Zeng, Z. Qiu, D. Qu, H. Song, Q. Chen, X. Deng, and J. Pang. F1: A vision-language-action model bridging understanding and generation to actions.arXiv preprint arXiv:2509.06951, 2025
Pith/arXiv arXiv 2025
-
[14]
C. Zhu, R. Yu, S. Feng, B. Burchfiel, P. Shah, and A. Gupta. Unified world models: Cou- pling video and action diffusion for pretraining on large robotic datasets.arXiv preprint arXiv:2504.02792, 2025
Pith/arXiv arXiv 2025
-
[15]
H. Bi, H. Tan, S. Xie, Z. Wang, S. Huang, H. Liu, R. Zhao, Y . Feng, C. Xiang, Y . Rong, H. Zhao, H. Liu, Z. Su, L. Ma, H. Su, and J. Zhu. Motus: A unified latent action world model. arXiv preprint arXiv:2512.13030, 2025
Pith/arXiv arXiv 2025
-
[16]
J. Cen, C. Yu, H. Yuan, Y . Jiang, S. Huang, J. Guo, X. Li, Y . Song, H. Luo, F. Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025. 9
Pith/arXiv arXiv 2025
-
[17]
T. Yuan, Z. Dong, Y . Liu, and H. Zhao. Fast-wam: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026
Pith/arXiv arXiv 2026
-
[18]
M. Team, C. Xiang, F. Bao, H. Liu, H. Tan, H. Bi, J. Li, J. Liu, J. Pang, K. Jing, et al. Mo- tubrain: An advanced world action model for robot control.arXiv preprint arXiv:2604.27792, 2026
Pith/arXiv arXiv 2026
-
[19]
L. Li, Q. Zhang, Y . Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhu, Y . Shen, and Y . Xu. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
Pith/arXiv arXiv 2026
-
[20]
R. Wang, Y . Zhang, J. Lin, K. Luo, J. Wang, Z. Wang, and X. Qi. When to trust imagination: Adaptive action execution for world action models.arXiv preprint arXiv:2605.06222, 2026
Pith/arXiv arXiv 2026
-
[21]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.arXiv preprint arXiv:2306.03310, 2023
Pith/arXiv arXiv 2023
-
[22]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, J. Fu, J. Gong, and X. Qiu. Libero-plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626, 2025
Pith/arXiv arXiv 2025
-
[23]
T. Chen, Y . Wang, M. Li, Y . Qin, H. Shi, Z. Li, Y . Hu, Y . Zhang, K. Wang, Y . Chen, et al. Rm- bench: Memory-dependent robotic manipulation benchmark with insights into policy design. arXiv preprint arXiv:2603.01229, 2026
arXiv 2026
-
[24]
T. Zhao et al. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
Pith/arXiv arXiv 2023
-
[25]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, page 02783649241273668, 2023
2023
-
[26]
Q. Li, Y . Liang, Z. Wang, L. Luo, X. Chen, M. Liao, F. Wei, Y . Deng, S. Xu, Y . Zhang, et al. CogACT: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
Pith/arXiv arXiv 2024
-
[27]
H. Li, S. Yang, Y . Chen, Y . Tian, X. Yang, X. Chen, H. Wang, T. Wang, F. Zhao, D. Lin, et al. Cronusvla: Towards efficient and robust manipulation via multi-frame vision-language-action modeling.arXiv preprint arXiv:2506.19816, 2025
arXiv 2025
-
[28]
H. Shi, B. Xie, Y . Liu, L. Sun, F. Liu, T. Wang, E. Zhou, H. Fan, X. Zhang, and G. Huang. Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic ma- nipulation.arXiv preprint arXiv:2508.19236, 2025
Pith/arXiv arXiv 2025
-
[29]
A. Sridhar, J. Pan, S. Sharma, and C. Finn. Memer: Scaling up memory for robot control via experience retrieval.arXiv preprint arXiv:2510.20328, 2025
arXiv 2025
-
[30]
H. Fang, M. Grotz, W. Pumacay, Y . R. Wang, D. Fox, R. Krishna, and J. Duan. SAM2Act: In- tegrating visual foundation model with a memory architecture for robotic manipulation.arXiv preprint arXiv:2501.18564, 2025
arXiv 2025
-
[31]
Morimitsu, X
H. Morimitsu, X. Zhu, R. M. Cesar-Jr., X. Ji, and X.-C. Yin. DPFlow: Adaptive optical flow estimation with a dual-pyramid framework. InThe IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[32]
X. Sun, Z. Xu, C. Cao, Z. Liu, Y . Sun, J. Pang, R. Zhang, Z. Yang, K. Pang, D. He, et al. Atomvla: Scalable post-training for robotic manipulation via predictive latent world models. arXiv preprint arXiv:2603.08519, 2026. 10 Supplementary Material This supplementary material provides additional details on the implementation and evaluation of HiMem-W AM. ...
arXiv 2026
-
[33]
Receive current RGB observationso t, proprioceptionp t, instructionℓ, and memory bankM t
-
[34]
Computex t =E θ(ot, pt, ℓ)and retrievec m t fromM t
-
[35]
Form˜xt =x t +α r t Wmcm t
-
[36]
Use the Qwen3-VL-4B-Instruct planner to predictˆzh t and ˆbt
-
[37]
Use the executor to generate ˆZl t:t+K−1
-
[38]
Decode ˆat:t+K−1 =D act(ˆZl t:t+K−1 ,˜xt)
-
[39]
This procedure uses only current observations and stored memory, preserving the standard causal interface of action-chunking robot policies
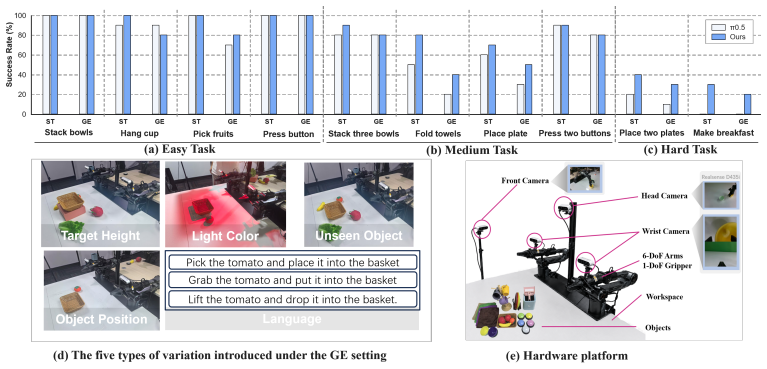
Ifα w t > η, writeγ t into the memory bank. This procedure uses only current observations and stored memory, preserving the standard causal interface of action-chunking robot policies. 15 B Real-World Setting Details B.1 Generalization Setting We provide the HiMem-W AM definition of theGEsetting used in our real-world evaluation. De- pending on the task, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.