Data compression for fast dimension reduction and clustering of high-dimensional discrete data
Pith reviewed 2026-06-27 12:30 UTC · model grok-4.3
The pith
A scaled positional encoding compresses high-dimensional discrete data into low dimensions while keeping observations distinct and cluster centroids separable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the compression mapping is injective, ensuring distinct observations remain distinct; that under mild regularity conditions the compressed variables admit an approximate Gaussian representation; and that separation between cluster centroids is preserved, so that location-driven cluster structure remains identifiable after dimension reduction.
What carries the argument
The scaled positional encoding that defines the weighted sums producing the low-dimensional continuous representation of each discrete observation.
If this is right
- Distinct observations remain distinct after compression because the mapping is injective.
- Model-based clustering is justified in the compressed space by the approximate Gaussian representation.
- Location-driven cluster structure stays identifiable because centroid separation is preserved.
- The transformation applies stably to binary, categorical, and count-valued data.
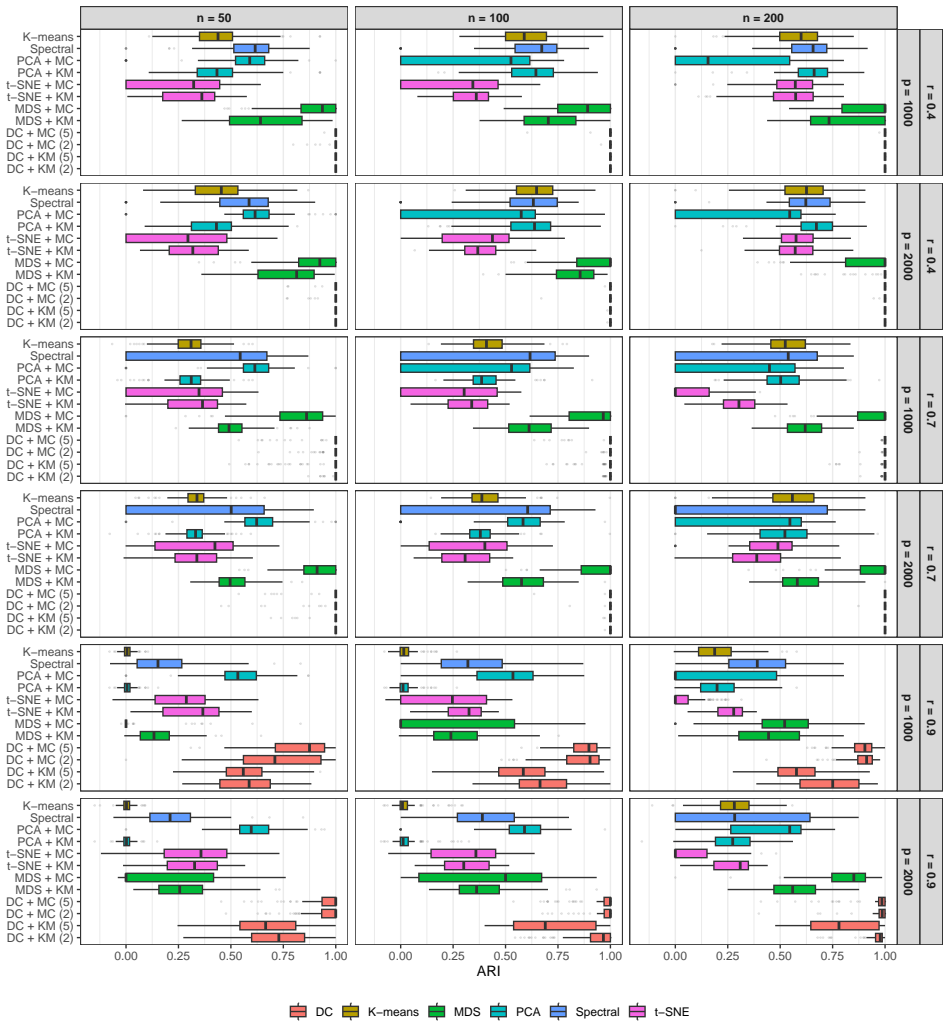
- Cluster recovery remains accurate in simulations while computation is substantially faster than standard dimension-reduction methods.
Where Pith is reading between the lines
- If the regularity conditions prove sensitive to extreme sparsity, the compression could be adapted by changing the scaling of the positional encoding for those regimes.
- The same injective compression might support other location-based tasks such as regression or outlier detection without needing new theory.
- Because the method is deterministic and parameter-light, it could serve as a preprocessing step before many existing discrete-data pipelines beyond clustering.
- Testing whether the approximate Gaussian property holds for count data with very heavy tails would clarify the practical scope of the mild conditions.
Load-bearing premise
The mild regularity conditions that justify the approximate Gaussian representation and the preservation of centroid separation must actually hold for the data being compressed.
What would settle it
Finding two distinct high-dimensional discrete observations that map to the exact same compressed vector, or a dataset of known clusters whose centroids become inseparable after compression while satisfying the stated regularity conditions, would disprove the core theoretical properties.
Figures
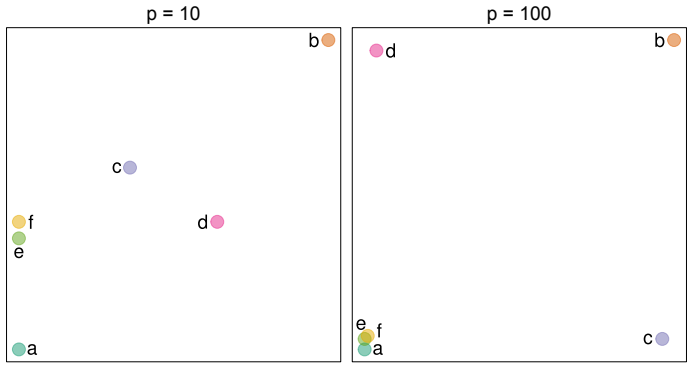
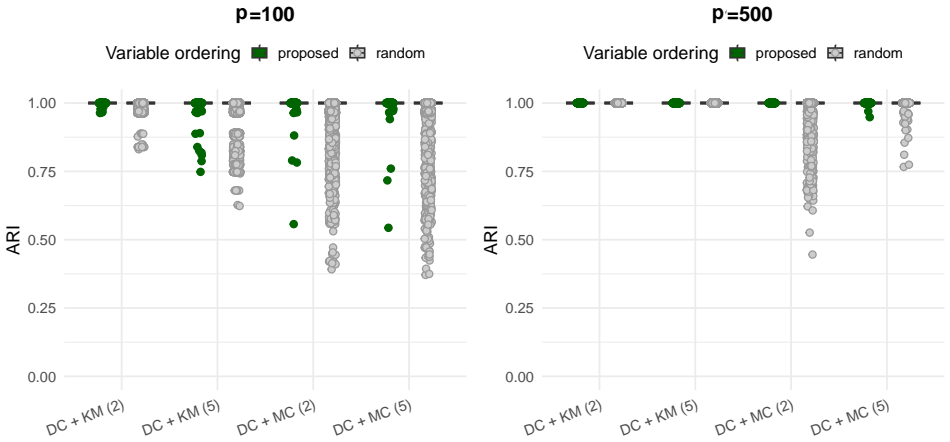

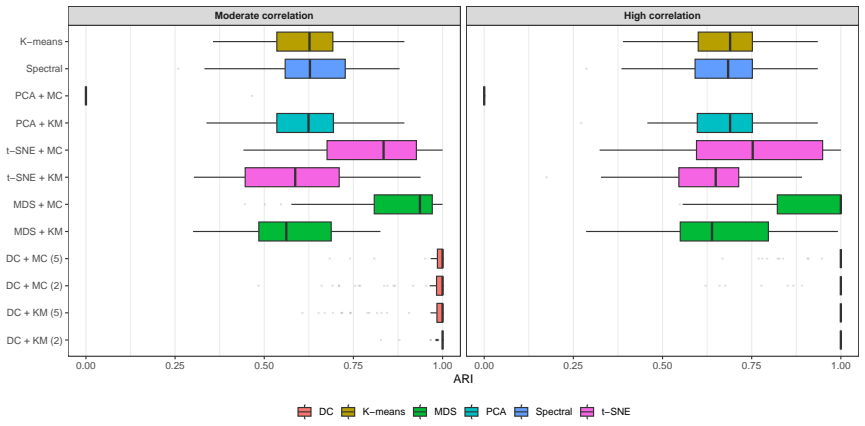
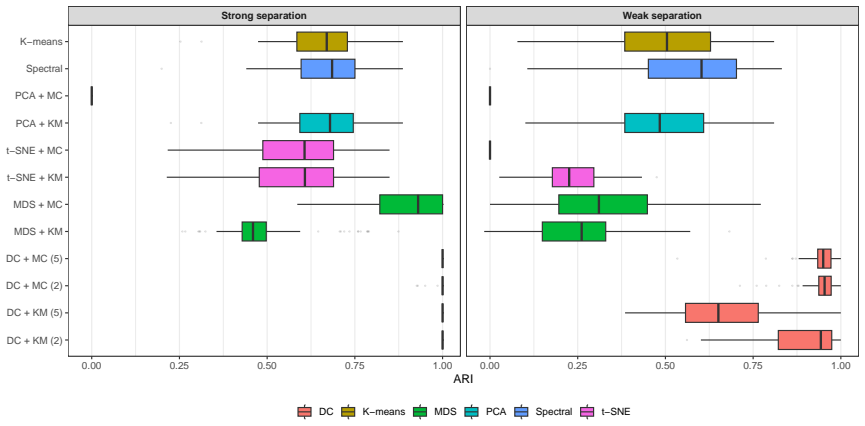
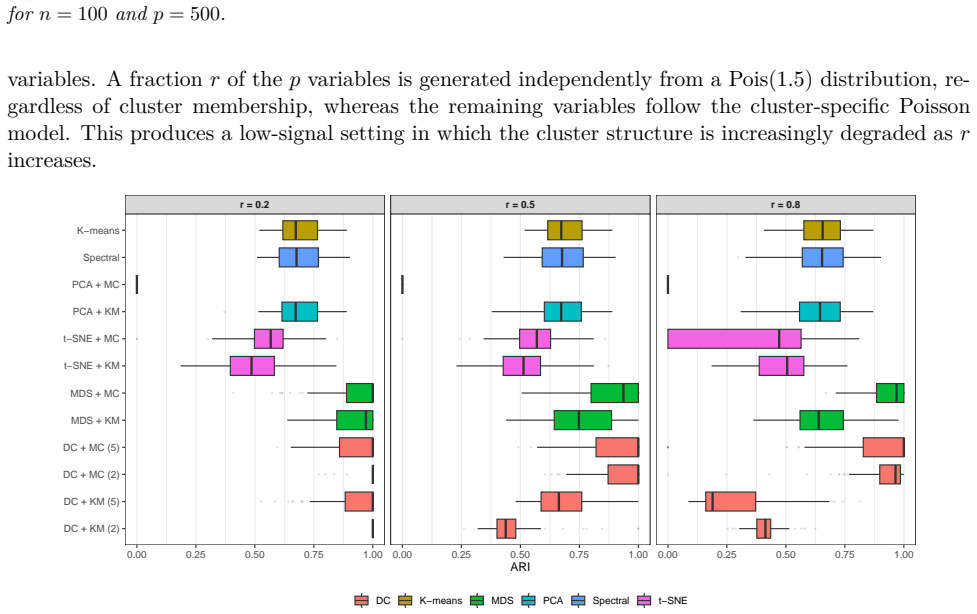
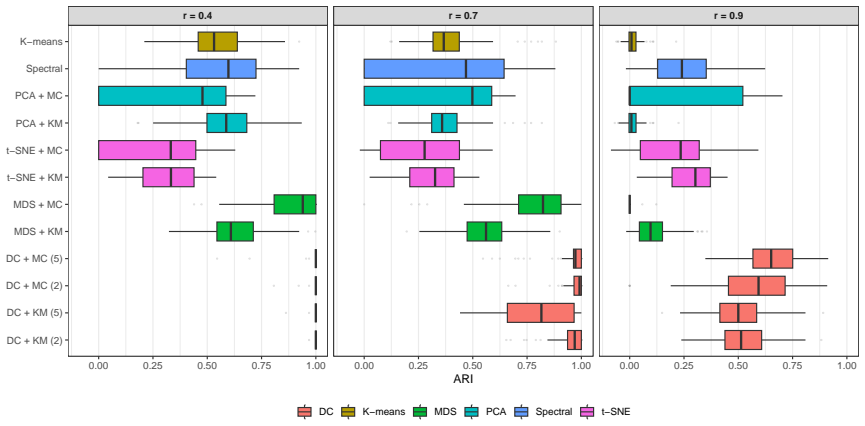
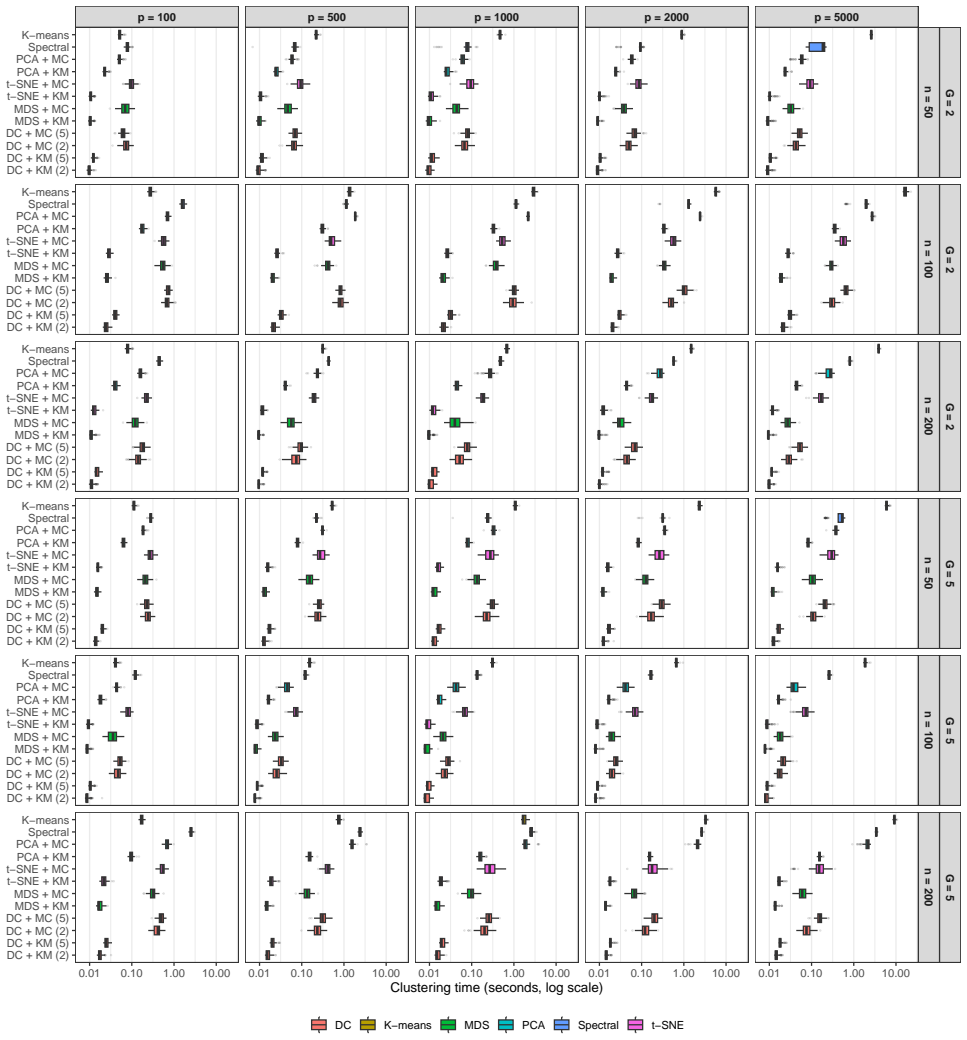
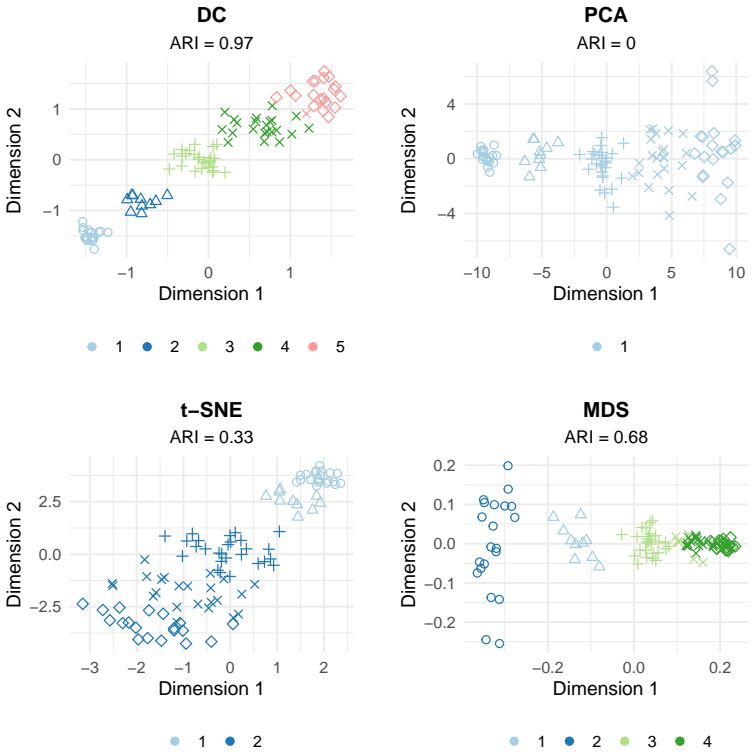
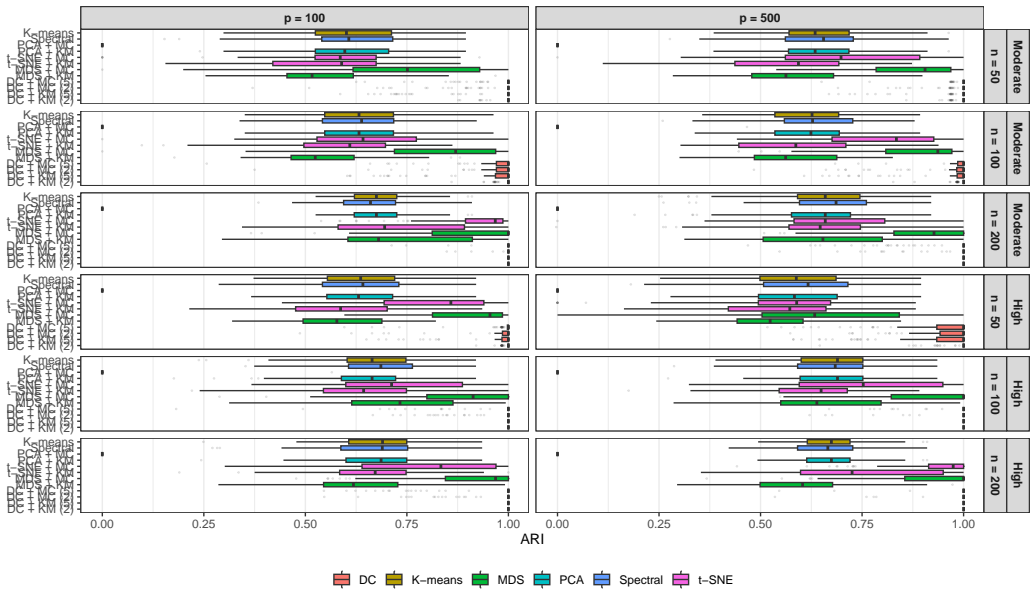
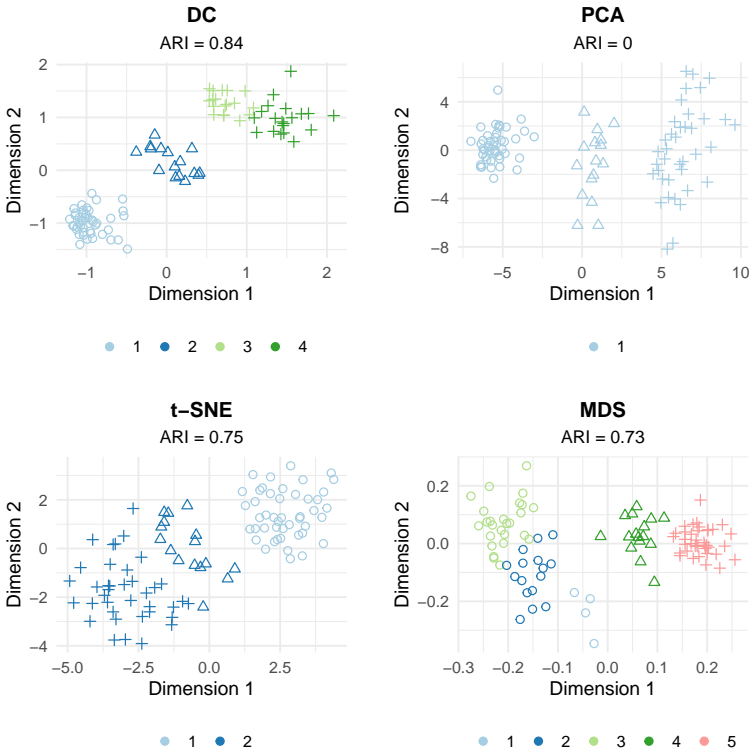
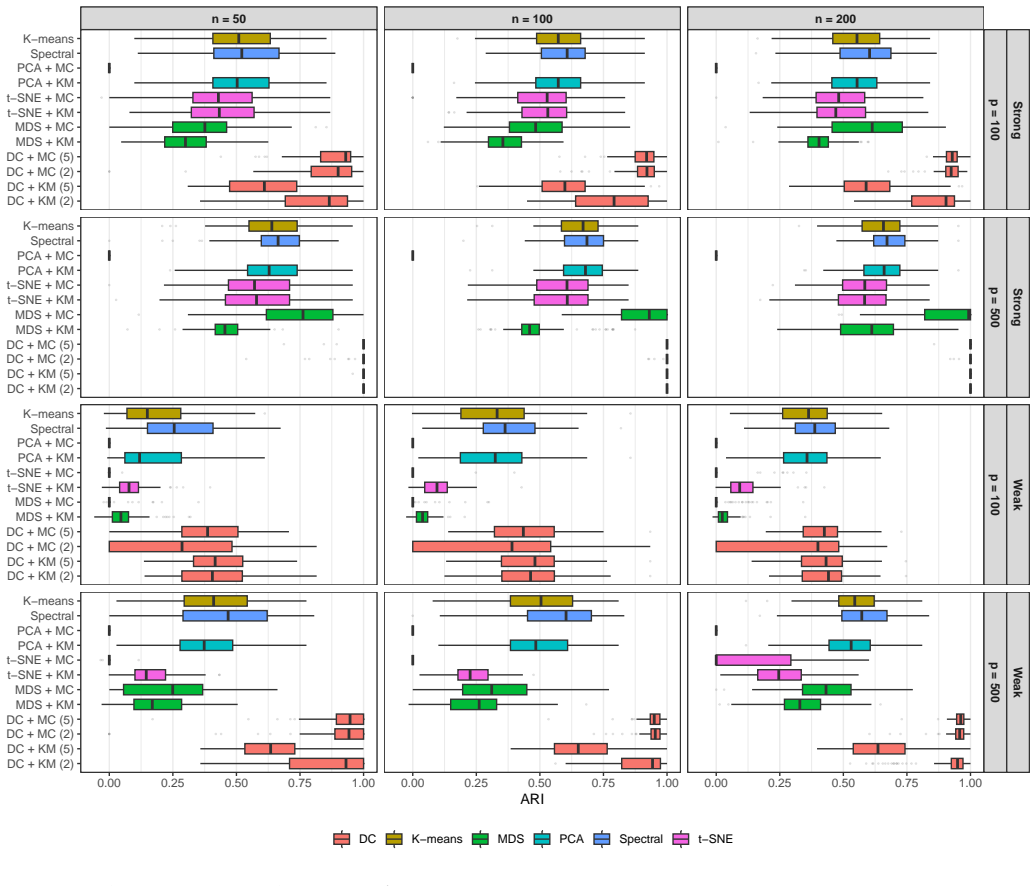
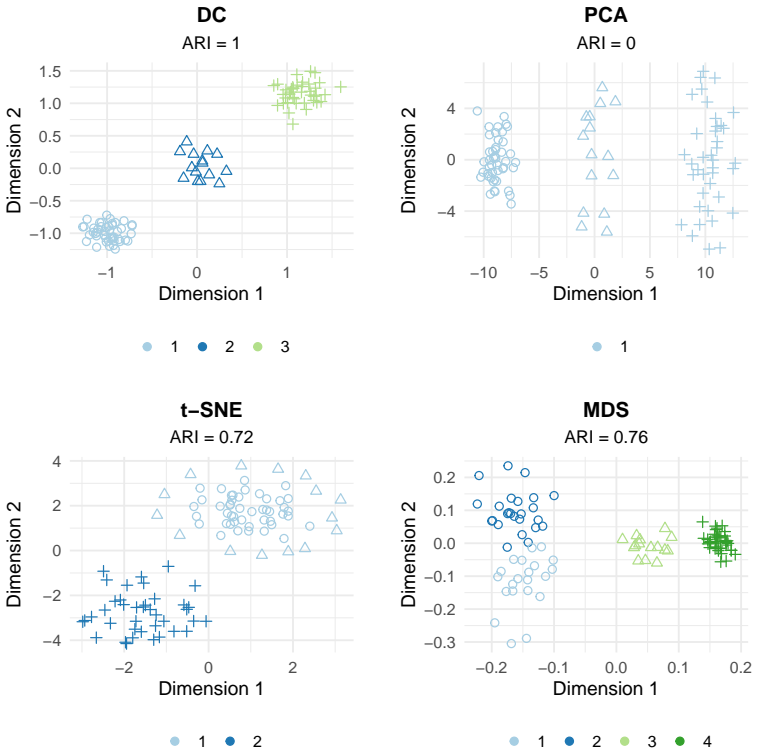
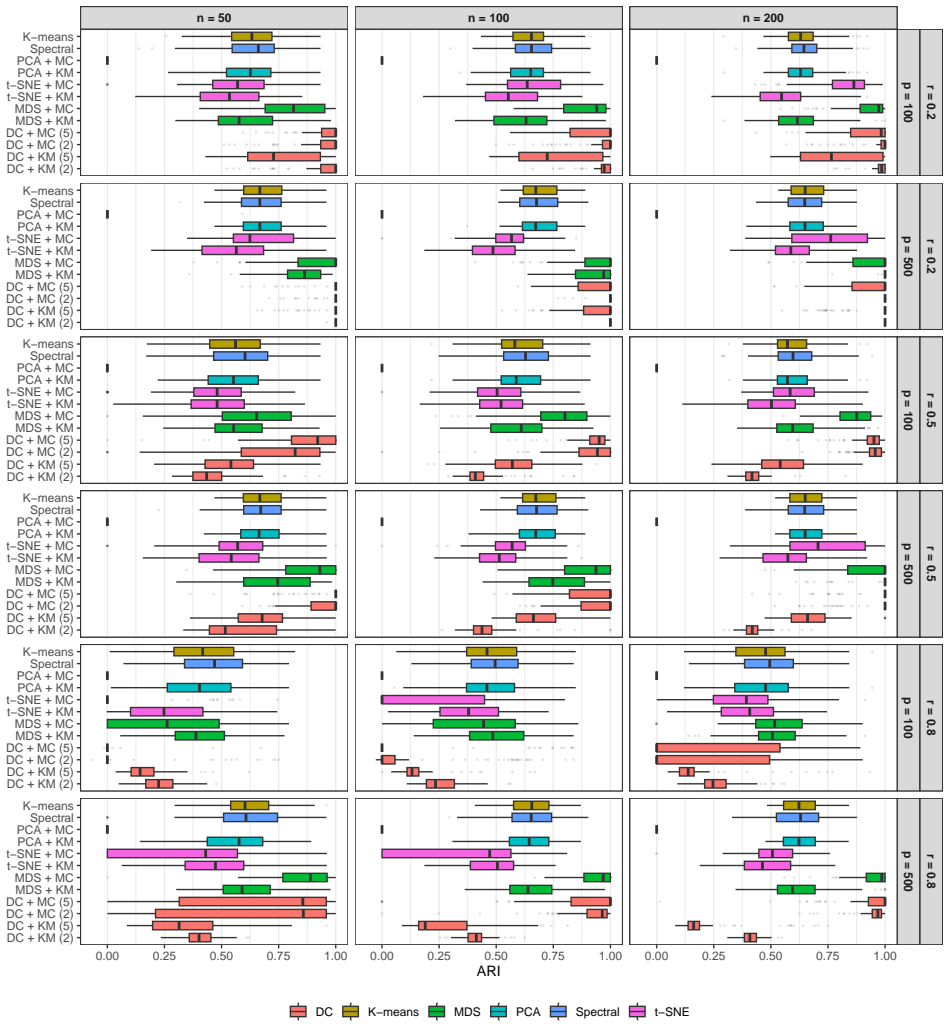
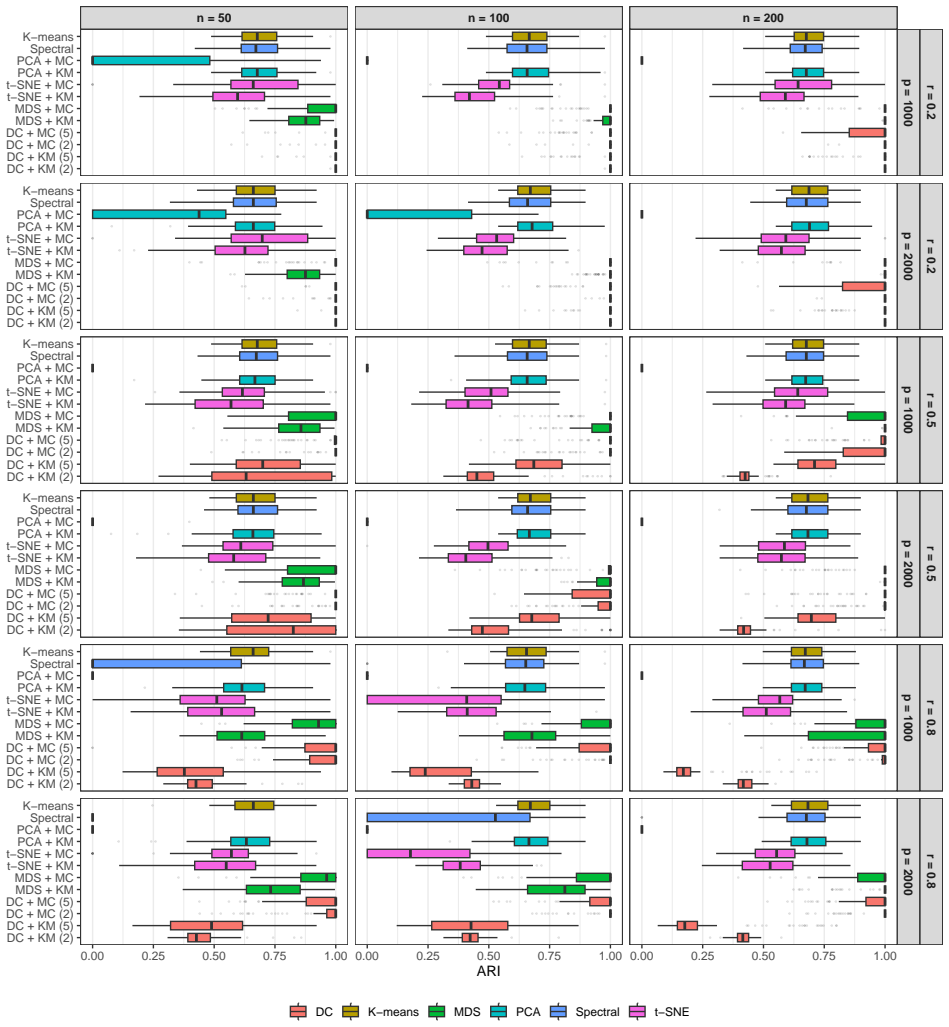
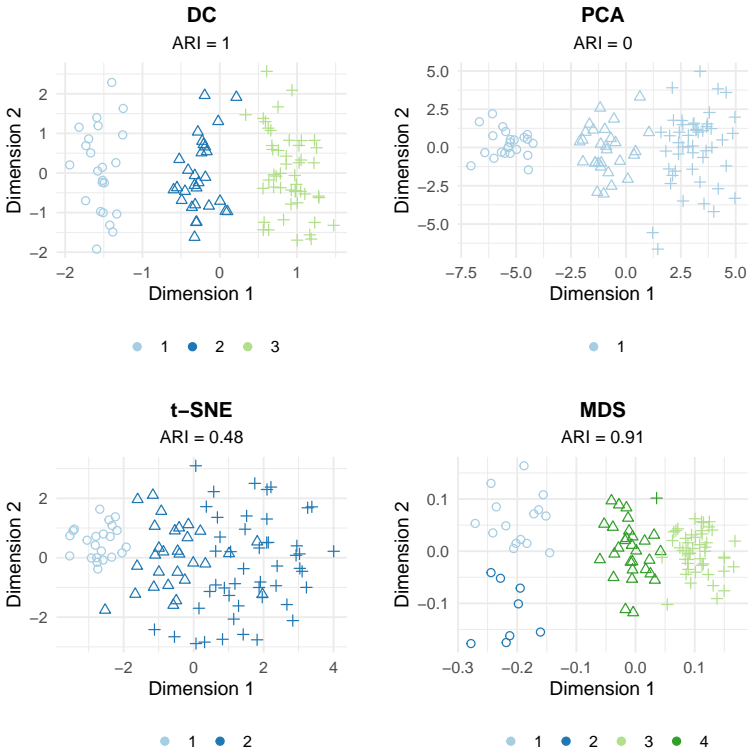
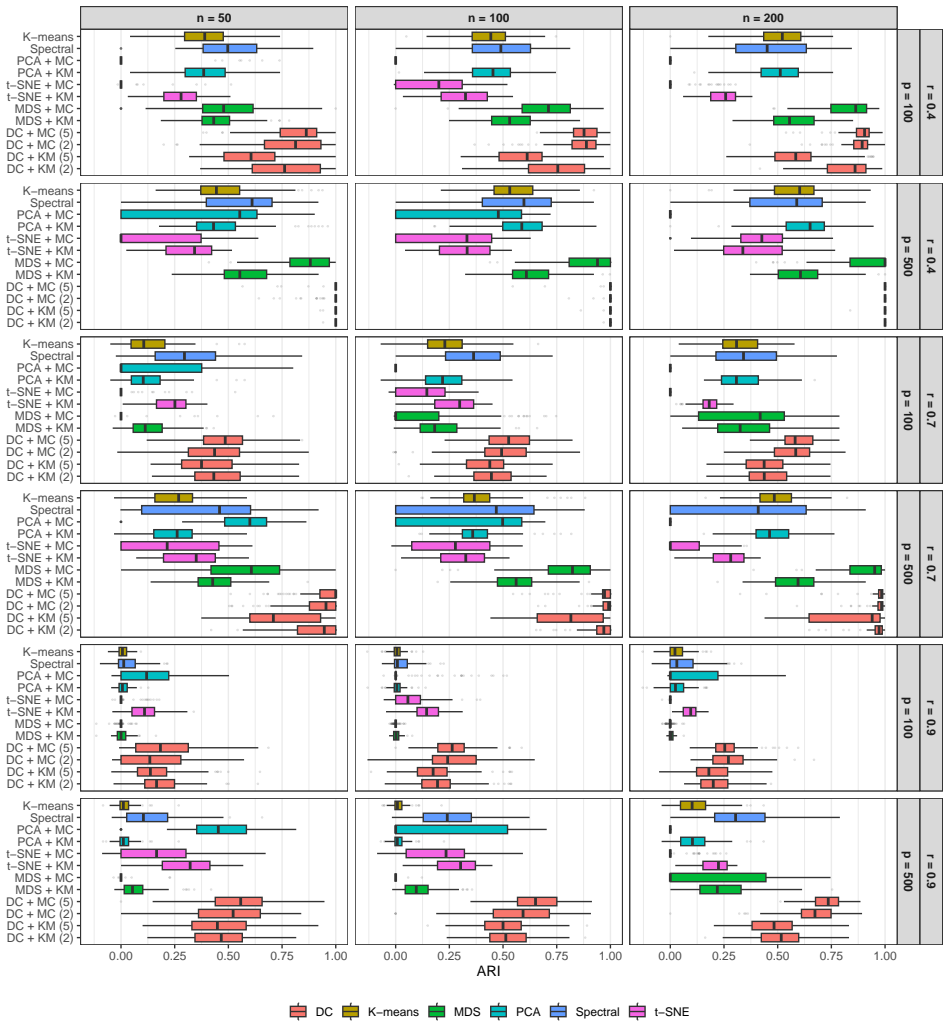
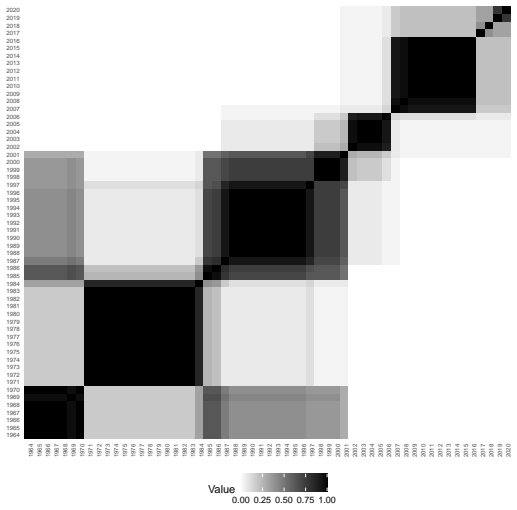
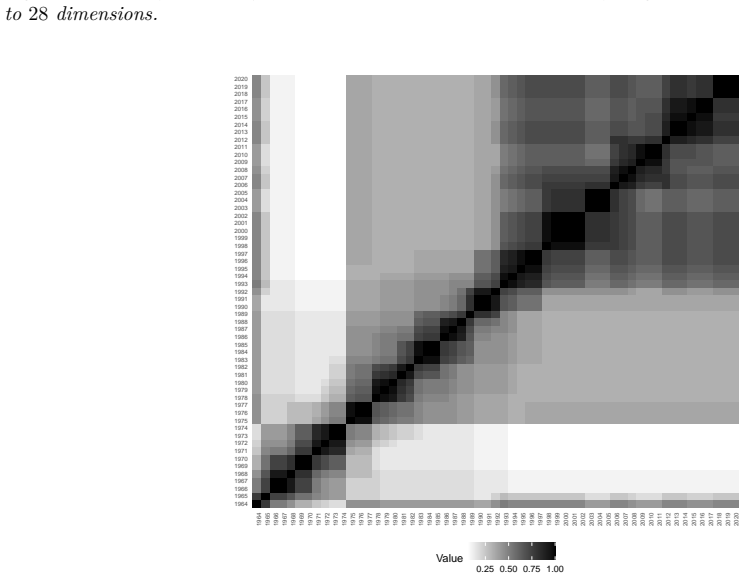
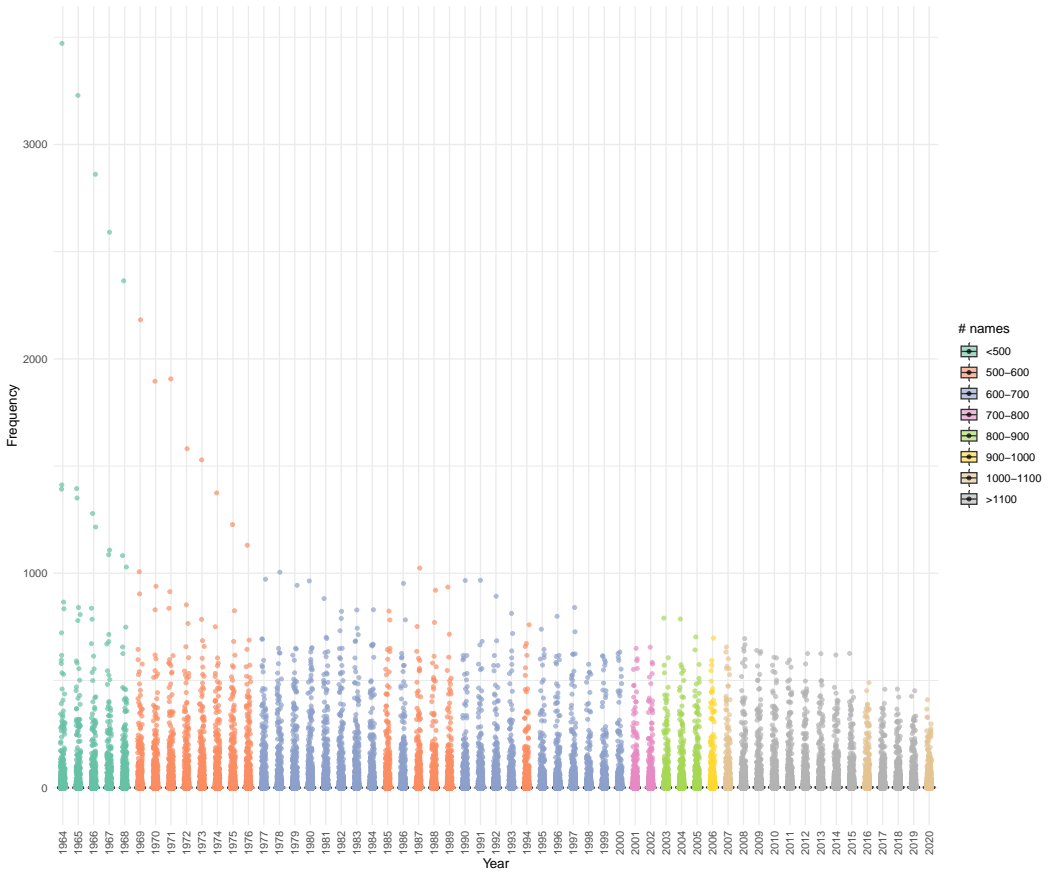



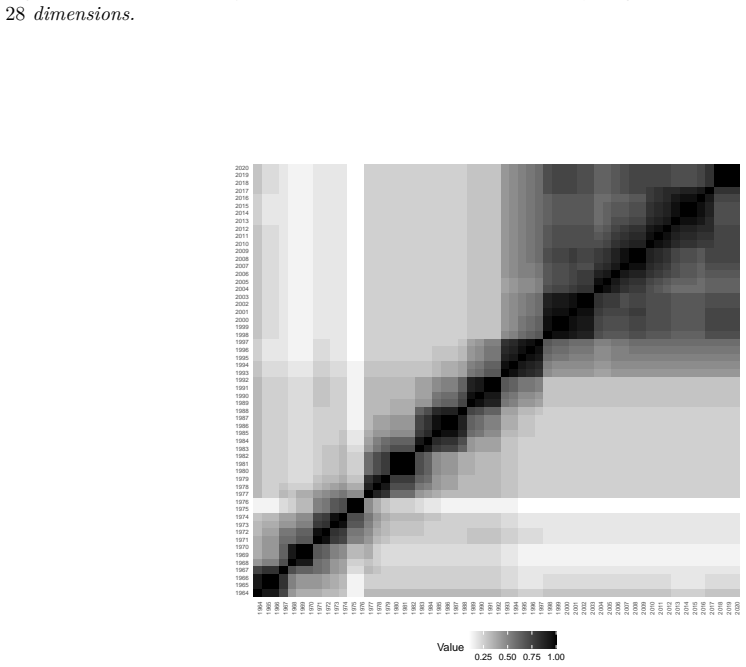
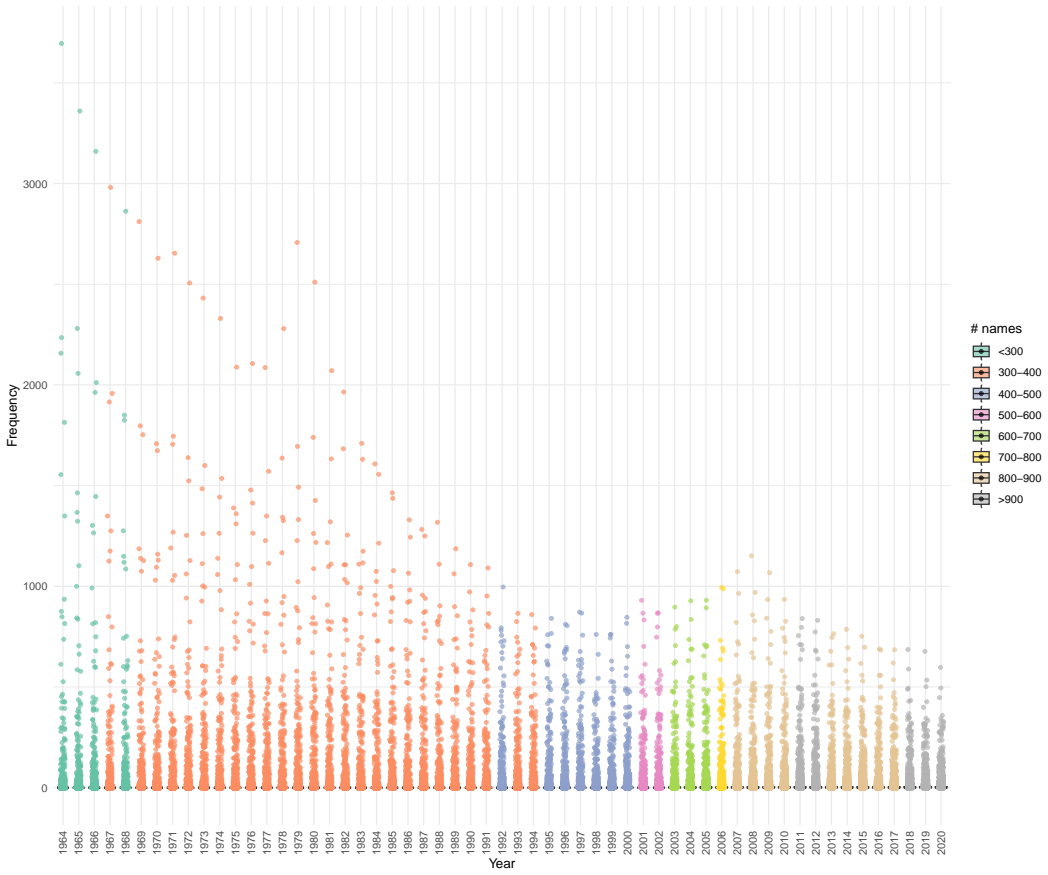



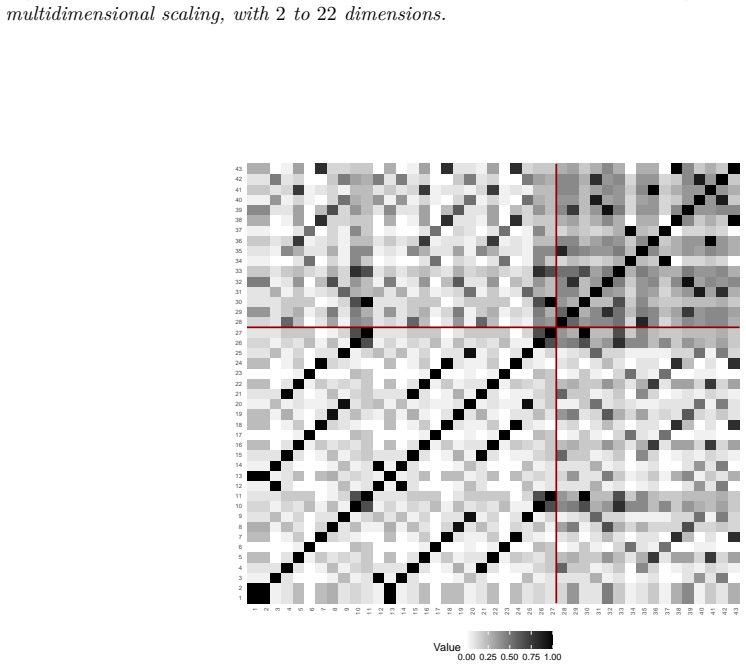
read the original abstract
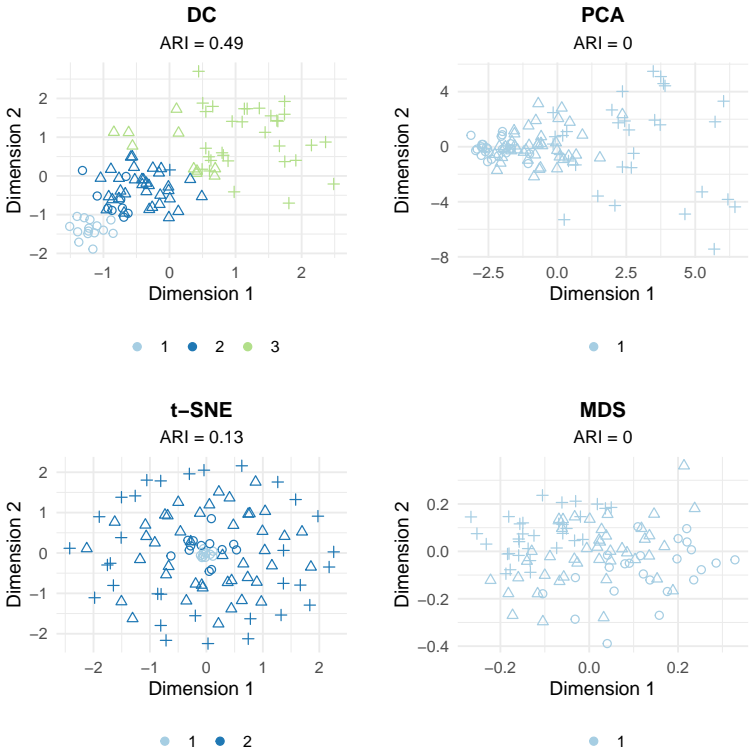
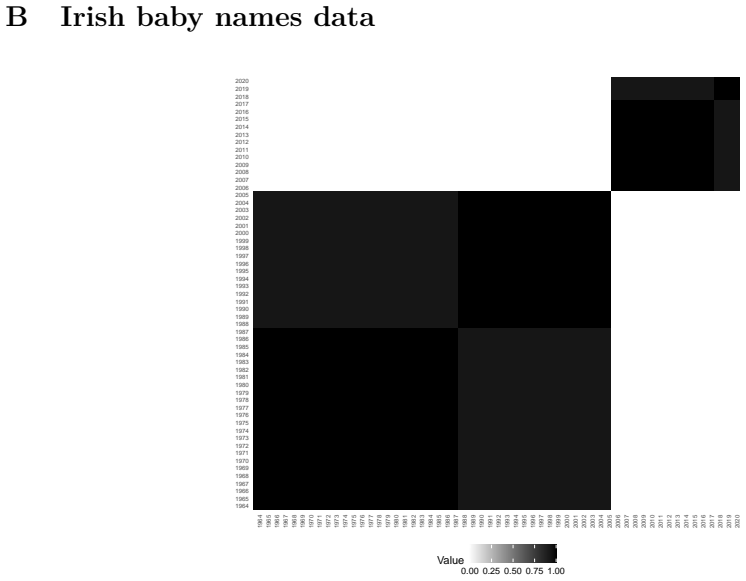
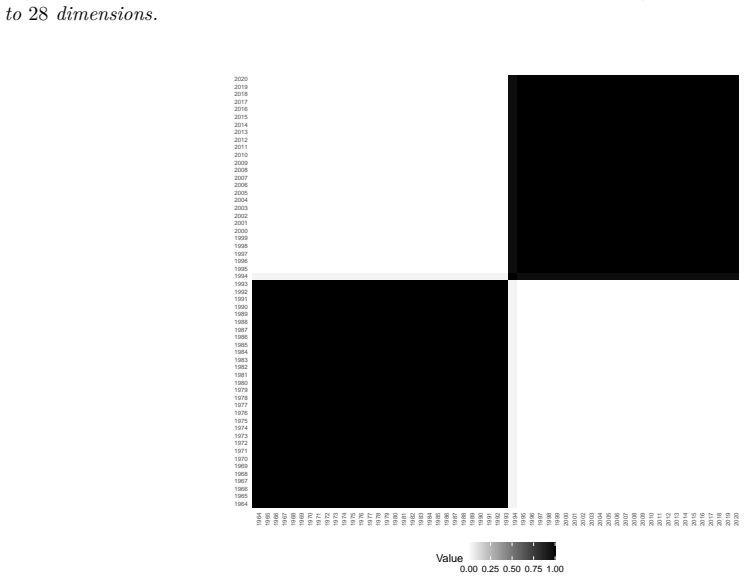
High-dimensional discrete data arise in many contemporary applications, including genomics, microbiome research, survey studies, and digital behavioral analysis. Clustering such data remains challenging because existing methods are often computationally demanding, sensitive to sparsity and discreteness, or designed for specific data types. We propose a deterministic dimension-reduction framework for clustering high-dimensional discrete observations. The method compresses each observation into a low-dimensional continuous representation through weighted sums defined by a scaled positional encoding, yielding a numerically stable transformation applicable to binary, categorical, and count-valued data. We establish several theoretical properties of the proposed compression. The mapping is injective, ensuring that distinct observations remain distinct after compression. Under mild regularity conditions, the compressed variables admit an approximate Gaussian representation, providing a theoretical basis for model-based clustering in the compressed space. We further show that separation between cluster centroids is preserved under compression, implying that location-driven cluster structure remains identifiable after dimension reduction. Extensive simulation studies demonstrate accurate cluster recovery across a wide range of realistic settings. The proposed approach is also computationally efficient, providing substantial speed improvements over commonly used dimension-reduction techniques often used in conjunction with clustering. Applications to Irish baby-name records and microbiome data further illustrate its practical utility. The proposed framework offers a scalable, computationally efficient, and broadly applicable approach to clustering high-dimensional discrete data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a deterministic compression framework for high-dimensional discrete data (binary, categorical, count) that maps each observation to a low-dimensional continuous vector via weighted sums with a scaled positional encoding. It claims the mapping is injective, that the compressed variables admit an approximate Gaussian representation under mild regularity conditions (providing justification for model-based clustering), and that separation between cluster centroids is preserved. Simulation studies and applications to Irish baby-name records and microbiome data are used to illustrate performance and computational efficiency.
Significance. If the injectivity, approximate-Gaussian, and centroid-separation results hold once the regularity conditions are stated explicitly, the method would supply a fast, broadly applicable preprocessing step that enables standard Gaussian-mixture clustering on compressed discrete data while preserving location-driven structure. This could be practically significant for large-scale genomics and microbiome analyses where existing dimension-reduction-plus-clustering pipelines are computationally heavy.
major comments (2)
- [Abstract / theoretical properties] Abstract and theoretical-properties section: the claims that 'under mild regularity conditions, the compressed variables admit an approximate Gaussian representation' and that 'separation between cluster centroids is preserved' are load-bearing for the clustering justification, yet the precise statement of those conditions (moment requirements, lower bounds on cell probabilities, dependence on sparsity or ambient dimension, etc.) is not supplied. Without an explicit theorem or set of assumptions, it is impossible to verify whether the conditions hold for the sparse discrete data the method targets.
- [Theoretical properties] Theoretical-properties section (likely around the injectivity and Gaussian claims): the manuscript must supply the derivation steps or regularity-condition statements that convert the deterministic weighted-sum construction into the stated approximate-Gaussian and centroid-preservation results; the current abstract supplies none.
minor comments (1)
- [Abstract] Abstract: the phrase 'extensive simulation studies demonstrate accurate cluster recovery across a wide range of realistic settings' would benefit from a one-sentence indication of the range of dimensions, sparsity levels, and cluster-separation regimes examined.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for explicit theoretical details. We will revise the manuscript to address these points by adding formal statements of conditions and derivations.
read point-by-point responses
-
Referee: [Abstract / theoretical properties] Abstract and theoretical-properties section: the claims that 'under mild regularity conditions, the compressed variables admit an approximate Gaussian representation' and that 'separation between cluster centroids is preserved' are load-bearing for the clustering justification, yet the precise statement of those conditions (moment requirements, lower bounds on cell probabilities, dependence on sparsity or ambient dimension, etc.) is not supplied. Without an explicit theorem or set of assumptions, it is impossible to verify whether the conditions hold for the sparse discrete data the method targets.
Authors: We agree that explicit statements of the regularity conditions are required. In the revised manuscript we will add a dedicated theorem specifying the assumptions, including moment bounds, minimum cell-probability thresholds, and their dependence on sparsity and ambient dimension. This will allow direct verification for the sparse discrete data targeted by the method. revision: yes
-
Referee: [Theoretical properties] Theoretical-properties section (likely around the injectivity and Gaussian claims): the manuscript must supply the derivation steps or regularity-condition statements that convert the deterministic weighted-sum construction into the stated approximate-Gaussian and centroid-preservation results; the current abstract supplies none.
Authors: We will include the derivation steps in the theoretical-properties section of the revision. These will detail how the scaled positional encoding and weighted sums yield the approximate-Gaussian property and centroid separation under the stated conditions. The abstract will be updated to reference the new theorem explicitly. revision: yes
Circularity Check
No circularity; properties derived directly from deterministic mapping definition
full rationale
The paper defines a deterministic compression via weighted sums with scaled positional encoding. It then states that the mapping is injective, that compressed variables admit an approximate Gaussian representation under mild regularity conditions, and that cluster-centroid separation is preserved. These are presented as mathematical consequences of the construction itself rather than reductions to fitted parameters, self-citations, or renamings. No load-bearing self-citation chains, ansatzes smuggled via prior work, or predictions that equal their inputs by construction appear in the abstract or context. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bioinformatics , volume =
Chen, Guanhua and Wang, Xinyue and Sun, Qiang and Tang, Zheng-Zheng , title =. Bioinformatics , volume =. 2025 , month =
2025
-
[2]
Polynomials and Polynomial Inequalities , series =
Peter Borwein and Tam. Polynomials and Polynomial Inequalities , series =. 1995 , isbn =
1995
-
[3]
William Feller , title =
-
[4]
Shannon , title =
Claude E. Shannon , title =. Bell System Technical Journal , volume =
-
[5]
Serge Lang , title =
-
[6]
Ingwer Borg and Patrick J. F. Groenen , title =. 2005 , isbn =
2005
-
[7]
Journal of Machine Learning Research , volume =
Laurens van der Maaten and Geoffrey Hinton , title =. Journal of Machine Learning Research , volume =. 2008 , issn =
2008
-
[8]
Statistics and Computing , volume =
Ulrike von Luxburg , title =. Statistics and Computing , volume =. 2007 , doi =
2007
-
[9]
Jolliffe , title =
Ian T. Jolliffe , title =. 2002 , isbn =
2002
-
[10]
Bishop , title =
Christopher M. Bishop , title =. 2006 , isbn =
2006
-
[11]
The Gut Microbiota of Rural Papua New Guineans: Composition, Diversity Patterns, and Ecological Processes , journal =
Mart. The Gut Microbiota of Rural Papua New Guineans: Composition, Diversity Patterns, and Ecological Processes , journal =. 2015 , doi =
2015
-
[12]
Irish Babies' Names , year =
-
[13]
and Scrucca, L
Casa, A. and Scrucca, L. and Menardi, G. , title =. Advances in Data Analysis and Classification , volume =. 2021 , doi =
2021
-
[14]
and Brodley, C.E
Fern, X.Z. and Brodley, C.E. , title =. Proceedings of the 20th international conference on machine learning , volume =. 2003 , doi =
2003
-
[15]
and Candela, M
Schnorr, S.L. and Candela, M. and Rampelli, S. and Centanni, M. and Consolandi, C. and Basaglia, G. and Turroni, S. and Biagi, E. and Peano, C. and Severgnini, M. and others , title =. Nature Communications , volume =. 2014 , doi =
2014
-
[16]
and Zhang, L
Shi, Y. and Zhang, L. and Peterson, C.B. and others , title =. Microbiome , volume =. 2022 , doi =
2022
-
[17]
and Chen, Z
Wang, C. and Chen, Z. and Xi, R. , title =. Annals of Applied Statistics , volume =. 2025 , doi =
2025
-
[18]
2026 , note =
vegan: Community Ecology Package , author =. 2026 , note =
2026
-
[19]
Journal of classification , volume=
Comparing partitions , author=. Journal of classification , volume=. 1985 , publisher=
1985
-
[20]
2024 , note =
kernlab: Kernel-Based Machine Learning Lab , author =. 2024 , note =
2024
-
[21]
kernlab -- An
Alexandros Karatzoglou and Alex Smola and Kurt Hornik and Achim Zeileis , journal =. kernlab -- An. 2004 , volume =
2004
-
[22]
Krijthe , year =
Jesse H. Krijthe , year =
-
[23]
Journal of Open Source Software , year =
simstudy: Illuminating research methods through data generation , author =. Journal of Open Source Software , year =
-
[24]
An extensive comparative study of cluster validity indices , journal =. 2013 , issn =. doi:https://doi.org/10.1016/j.patcog.2012.07.021 , url =
-
[25]
Clustering with the Average Silhouette Width , journal =. 2021 , issn =. doi:https://doi.org/10.1016/j.csda.2021.107190 , url =
-
[26]
Lausser, Ludwig and Schmid, Florian and Schirra, Lyn-Rouven and Wilhelm, Adalbert F. X. and Kestler, Hans A. , title=. Advances in Data Analysis and Classification , year=. doi:10.1007/s11634-016-0277-3 , url=
-
[27]
Priebe and Youngser Park and David J
Congyuan Yang and Carey E. Priebe and Youngser Park and David J. Marchette , title =. Journal of Computational and Graphical Statistics , volume =. 2021 , publisher =
2021
-
[28]
, title =
MacQueen, James B. , title =. Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability , volume =. 1967 , publisher =
1967
-
[29]
, title =
Lloyd, Stuart P. , title =. IEEE Transactions on Information Theory , volume =. 1982 , doi =
1982
-
[30]
, title =
Rousseeuw, Peter J. , title =. Journal of Computational and Applied Mathematics , volume =. 1987 , doi =
1987
-
[31]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =
Tibshirani, Robert and Walther, Guenther and Hastie, Trevor , title =. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =. 2001 , month =. doi:10.1111/1467-9868.00293 , url =
-
[32]
Brendan and Raftery, Adrian E
Bouveyron, Charles and Celeux, Gilles and Murphy, T. Brendan and Raftery, Adrian E. , year=. Model-Based Clustering and Classification for Data Science: With Applications in R , publisher=
-
[33]
https://doi.org/10.1201/9781003277965
Luca Scrucca and Chris Fraley and T. Brendan Murphy and Adrian E. Raftery , publisher =. Model-Based Clustering, Classification, and Density Estimation Using. doi:10.1201/9781003277965 , year =
-
[34]
2026 , url =
R: A Language and Environment for Statistical Computing , author =. 2026 , url =
2026
-
[35]
McLachlan and Suren Rathnayake
McLachlan, Geoffrey J. and Rathnayake, Suren , title =. WIREs Data Mining and Knowledge Discovery , volume =. doi:https://doi.org/10.1002/widm.1135 , url =. https://wires.onlinelibrary.wiley.com/doi/pdf/10.1002/widm.1135 , year =
-
[36]
Journal of the American Statistical Association , volume =
Chris Fraley and Adrian E Raftery , title =. Journal of the American Statistical Association , volume =. 2002 , publisher =
2002
-
[37]
Journal of Classification , year=
Anderlucci, Laura and Fortunato, Francesca and Montanari, Angela , title=. Journal of Classification , year=. doi:10.1007/s00357-021-09403-7 , url=
-
[38]
Payne, Andrea and Silva, Anjali and Rothstein, Steven J. and McNicholas, Paul D. and Subedi, Sanjeena , title=. Statistics and Computing , year=. doi:10.1007/s11222-025-10720-9 , url=
-
[39]
Journal of Classification , year=
Tu, Wangshu and Subedi, Sanjeena , title=. Journal of Classification , year=
-
[40]
Fang, Yuan and Subedi, Sanjeena , title=. Scientific Reports , year=. doi:10.1038/s41598-023-41318-8 , url=
-
[41]
Computational Statistics & Data Analysis , volume =. 2014 , issn =. doi:https://doi.org/10.1016/j.csda.2012.12.008 , url =
-
[42]
Journal of Machine Learning Research , year =
Dapeng Yao and Fangzheng Xie and Yanxun Xu , title =. Journal of Machine Learning Research , year =
-
[43]
Gallivan and Adrian Barbu , title =
Yijia Zhou and Kyle A. Gallivan and Adrian Barbu , title =. Journal of Computational and Graphical Statistics , volume =. 2025 , publisher =
2025
-
[44]
Clarke and Jennifer L
Saeid Amiri and Bertrand S. Clarke and Jennifer L. Clarke , title =. Journal of Computational and Graphical Statistics , volume =. 2018 , publisher =
2018
-
[45]
Journal of Nonparametric Statistics , volume =
Yong Wang and Reza Modarres , title =. Journal of Nonparametric Statistics , volume =. 2025 , publisher =
2025
-
[46]
Journal of the American Statistical Association , volume =
Xiaoxia Champon and Ana-Maria Staicu and Anthony Weishampel and Chathura Jayalah and William Rand , title =. Journal of the American Statistical Association , volume =
-
[47]
Journal of the American Statistical Association , volume =
Zhiyi Tian and Jiaming Xu and Jen Tang , title =. Journal of the American Statistical Association , volume =. 2024 , publisher =
2024
-
[48]
Journal of the American Statistical Association , volume =
Raffaele Argiento and Edoardo Filippi-Mazzola and Lucia Paci , title =. Journal of the American Statistical Association , volume =. 2025 , publisher =
2025
-
[49]
Biometrika , volume =
Ghilotti, L and Beraha, M and Guglielmi, A , title =. Biometrika , volume =. 2025 , month =
2025
-
[50]
Bioinformatics Advances , volume =
Rao, Jackie and Kirk, Paul D W , title =. Bioinformatics Advances , volume =. 2025 , month =
2025
-
[51]
Papastamoulis, Panagiotis and Rattray, Magnus , title =. The R Journal , year =. doi:10.32614/RJ-2017-022 , volume =
-
[52]
2009 , issn =
Discrete data clustering using finite mixture models , journal =. 2009 , issn =
2009
-
[53]
2025 , author =
Review of Post-Clustering Inference Methods , journal =. 2025 , author =
2025
-
[54]
and Hemanth, Duraisamy Jude and Sethi, Jasleen K
Mittal, Mamta and Goyal, Lalit M. and Hemanth, Duraisamy Jude and Sethi, Jasleen K. , title =. WIREs Data Mining and Knowledge Discovery , volume =
-
[55]
Advances in Data Analysis and Classification , year=
Mori, Matteo and Anderlucci, Laura , title=. Advances in Data Analysis and Classification , year=
-
[56]
Advances in Data Analysis and Classification , year=
Papastamoulis, Panagiotis , title=. Advances in Data Analysis and Classification , year=
-
[57]
Model based clustering of high-dimensional binary data , journal =. 2015 , issn =. doi:https://doi.org/10.1016/j.csda.2014.12.009 , url =
-
[58]
van den Heuvel , title =
Alberto Brini and Abu Manju and Edwin R. van den Heuvel , title =. Communications in Statistics - Simulation and Computation , volume =. 2025 , publisher =
2025
-
[59]
Statistics and Computing , year=
Failli, Dalila and Marino, Maria Francesca and Arpino, Bruno , title=. Statistics and Computing , year=
-
[60]
Gormley, Isobel Claire and Murphy, Thomas Brendan and Raftery, Adrian E. Model-Based Clustering. Annual Review of Statistics and Its Application. 2023. doi:https://doi.org/10.1146/annurev-statistics-033121-115326
-
[61]
Wade, S. , title =. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume =. 2023 , month =. doi:10.1098/rsta.2022.0149 , url =
-
[62]
Dunson , title =
Noirrit Kiran Chandra and Antonio Canale and David B. Dunson , title =. Journal of Machine Learning Research , year =
-
[63]
Chen and Daniela M
Yiqun T. Chen and Daniela M. Witten , title =. Journal of Machine Learning Research , year =
-
[64]
Tony Cai and Rong Ma , title =
T. Tony Cai and Rong Ma , title =. Journal of Machine Learning Research , year =
-
[65]
A simple method for screening variables before clustering microarray data , journal =. 2009 , issn =. doi:https://doi.org/10.1016/j.csda.2009.02.001 , url =
-
[66]
Classification of social media users with generalized functional data analysis , journal =
Anthony Weishampel and Ana-Maria Staicu and William Rand , keywords =. Classification of social media users with generalized functional data analysis , journal =. 2023 , issn =. doi:https://doi.org/10.1016/j.csda.2022.107647 , url =
-
[67]
and Andrews, Tallulah S
Kiselev, Vladimir Yu. and Andrews, Tallulah S. and Hemberg, Martin , title =. Nature Reviews Genetics , volume =. 2019 , doi =
2019
-
[68]
and Street, Kelly and Irizarry, Rafael A
Grabski, Isabella N. and Street, Kelly and Irizarry, Rafael A. , title =. Nature Methods , volume =. 2023 , doi =
2023
-
[69]
and Bowen, Natasha K
Weller, Bridget E. and Bowen, Natasha K. and Faubert, Sarah J. , title =. Journal of Black Psychology , volume =. 2020 , doi =
2020
-
[70]
Engineering Applications of Artificial Intelligence , volume =
A comprehensive survey of clustering algorithms:. Engineering Applications of Artificial Intelligence , volume =. 2022 , issn =. doi:https://doi.org/10.1016/j.engappai.2022.104743 , url =
-
[71]
Journal of the American Statistical Association , volume =
Zhongyuan Lyu and Ling Chen and Yuqi Gu , title =. Journal of the American Statistical Association , volume =. 2025 , publisher =
2025
-
[72]
Categorical data clustering: 25 years beyond K-modes , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.eswa.2025.126608 , url =
-
[73]
Spectral Clustering with Likelihood Refinement for High-Dimensional Latent Class Recovery , volume=. Psychometrika , author=. 2026 , pages=. doi:10.1017/psy.2026.10095 , number=
-
[74]
A Tensor-. Psychometrika , author=. 2023 , pages=. doi:10.1007/s11336-022-09887-1 , number=
-
[75]
Data Mining and Knowledge Discovery , year=
Huang, Zhexue , title=. Data Mining and Knowledge Discovery , year=
-
[76]
Rock: A robust clustering algorithm for categorical attributes , journal =. 2000 , issn =. doi:https://doi.org/10.1016/S0306-4379(00)00022-3 , url =
-
[77]
and Sevcik, Kenneth C
Andritsos, Periklis and Tsaparas, Panayiotis and Miller, Ren \'e e J. and Sevcik, Kenneth C. LIMBO: Scalable Clustering of Categorical Data. Advances in Database Technology - EDBT 2004. 2004
2004
-
[78]
Statistics Surveys , volume=
Variable selection methods for model-based clustering , author=. Statistics Surveys , volume=. 2018 , publisher=
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.