Answer Set Programming for Egg Extraction and More
Pith reviewed 2026-06-27 11:03 UTC · model grok-4.3
The pith
A naive ASP encoding for e-graph term extraction matches the efficiency of optimized ILP methods and finds additional optimal solutions on complex instances.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A naive ASP encoding for e-graph extraction achieves efficiency on par with well-optimized ILP-based DAG extraction and discovers several extra optimal extractions on complex instances.
What carries the argument
ASP encoding that directly models e-graph terms and the extraction objective as answer-set constraints.
If this is right
- ASP can serve as a practical alternative to ILP for exact optimal extraction from e-graphs.
- The approach opens the possibility of treating ASP as a more powerful Datalog layer on top of egg.
- Combined egg-plus-ASP systems could support richer reasoning over equality saturation results than current Datalog integrations allow.
Where Pith is reading between the lines
- If the scaling assumption holds, ASP extraction could be embedded directly inside existing equality-saturation loops without external solver calls.
- The extra optima found on complex instances suggest that ASP may expose different trade-offs between extraction cost and solution quality that ILP encodings miss.
- A practical next step would be to measure wall-clock extraction time on representative compiler IRs rather than on synthetic benchmark graphs.
Load-bearing premise
The chosen ASP solver and encoding will continue to scale to the sizes of e-graphs encountered in real compiler workloads without requiring solver-specific tuning or additional heuristics.
What would settle it
Running the same naive ASP encoding on e-graphs drawn from production compiler workloads that exceed the size and complexity of the extraction-gym suite and measuring whether solution times remain competitive without any changes to the encoding or solver configuration.
Figures
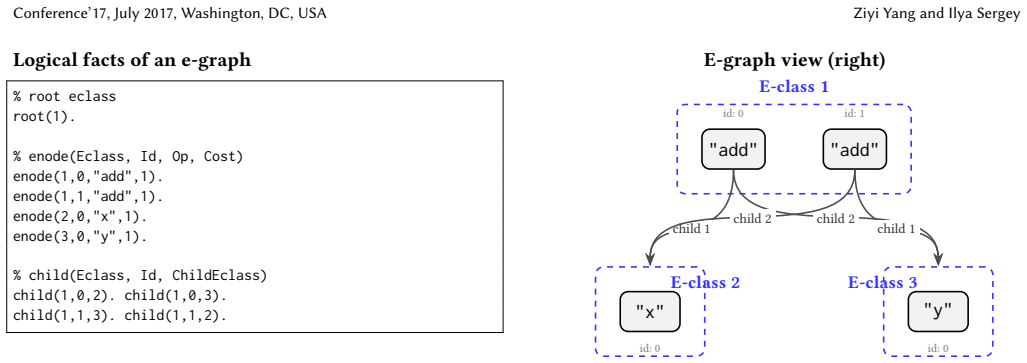

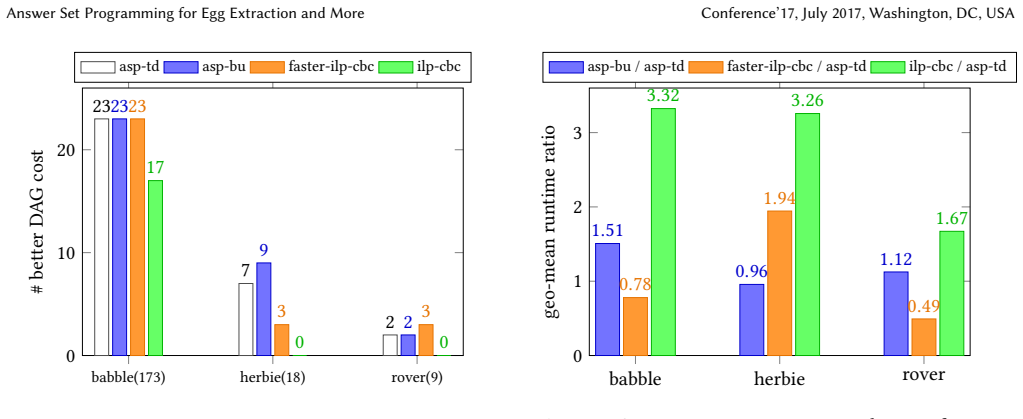
read the original abstract
Three years ago, Philip Zucker posted an attempt to use answer set programming (ASP) for term extraction from e-graphs Although the task is NP-hard and ASP offers a natural modelling of e-graph terms, the initial attempt did not yield convincing results. From the aspect of practical ASP users, we first pinpoint the way to make ASP work and work well on the task of e-graph extraction. The initial results show the na\"ive ASP encoding is comparable on efficiency to the well-optimised ILP-based exact DAG extraction in the extraction-gym, and find several extra optimal extraction on the complex instances. This leads us to a further agenda: with the "better together of egg+Datalog", is there a better "better together" by having ASP as a more powerful Datalog? We discuss the potential benefit from each other.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a naive ASP encoding for optimal term extraction from e-graphs achieves efficiency comparable to the well-optimized ILP baseline in the extraction-gym, recovers additional optimal solutions on complex instances, and motivates a broader agenda of using ASP as a more expressive Datalog layer alongside egg for compiler workloads.
Significance. If the empirical comparability holds and the approach scales, the work would supply a declarative, solver-based alternative to ILP extraction that could simplify encoding of complex cost functions and enable tighter integration between e-graph rewriting and logic programming in program optimizers.
major comments (3)
- [§4] §4 (Experimental Results): The central claim of comparability to ILP and discovery of extra optima is stated without any table of per-instance runtimes, costs, benchmark names, or e-graph sizes, so the evidence cannot be assessed or reproduced.
- [§6] §6 (Discussion): The manuscript pivots to an integration agenda for real compiler e-graphs, yet provides no scaling experiments, instance-size analysis, or argument addressing whether the naive encoding remains competitive when e-node counts grow by the factors typical in production workloads.
- [§3] §3 (ASP Encoding): The paper describes the encoding as 'naive' yet offers no formal definition or listing of the rules, making it impossible to judge whether hidden solver-specific tuning or modeling choices explain the reported performance.
minor comments (2)
- [Abstract] Abstract: The LaTeX rendering of 'na"ive' should be corrected to 'naive'.
- The manuscript would benefit from an explicit list of the extraction-gym instances used and a pointer to the ASP source files for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve transparency and completeness of the presented evidence.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Results): The central claim of comparability to ILP and discovery of extra optima is stated without any table of per-instance runtimes, costs, benchmark names, or e-graph sizes, so the evidence cannot be assessed or reproduced.
Authors: We agree that the experimental results section would benefit from greater detail. In the revised manuscript we will add one or more tables reporting, for each benchmark instance, the benchmark name, e-graph size (number of e-classes and e-nodes), runtime for both the ASP and ILP solvers, the cost of the extracted term, and whether the ASP encoding recovered an additional optimum. This will make the comparability claim and the discovery of extra optima directly verifiable. revision: yes
-
Referee: [§6] §6 (Discussion): The manuscript pivots to an integration agenda for real compiler e-graphs, yet provides no scaling experiments, instance-size analysis, or argument addressing whether the naive encoding remains competitive when e-node counts grow by the factors typical in production workloads.
Authors: The discussion section is prospective and does not contain scaling experiments on production-scale e-graphs. We will revise §6 to include a qualitative scaling argument based on the known complexity of the extraction problem and the performance characteristics of modern ASP solvers, together with references to observed e-graph sizes in the compiler literature. We acknowledge that new empirical scaling studies lie outside the scope of the present work, which focused on the extraction-gym suite; this limitation will be stated explicitly. revision: partial
-
Referee: [§3] §3 (ASP Encoding): The paper describes the encoding as 'naive' yet offers no formal definition or listing of the rules, making it impossible to judge whether hidden solver-specific tuning or modeling choices explain the reported performance.
Authors: We will expand §3 to present the complete set of ASP rules in a formal listing. The revised section will show the exact encoding used, making clear that it relies on standard Clingo features without undisclosed solver-specific tuning. revision: yes
Circularity Check
No circularity: empirical head-to-head on external extraction-gym baseline
full rationale
The paper's central claim is an empirical observation that a naive ASP encoding performs comparably to an existing ILP solver on the extraction-gym benchmark suite and recovers additional optima on some instances. This rests on running off-the-shelf solvers against an independently maintained external benchmark collection rather than any derivation, fitted parameter, or self-referential definition. No equations, ansatzes, uniqueness theorems, or self-citations appear as load-bearing steps in the provided text. The forward-looking discussion of ASP+Datalog integration with egg is presented as an open agenda, not as a derived result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Answer Set Programming for E-Graph DAG Extraction
Philip Zucker. Answer Set Programming for E-Graph DAG Extraction
-
[2]
Amir Kafshdar Goharshady and Chun Kit Lam and Lionel Parreaux , title =. Proc. 2024 , url =. doi:10.1145/3689801 , timestamp =
-
[3]
2011 , url =
Michael Stepp , title =. 2011 , url =
2011
-
[4]
Jiaqi Yin and Zhan Song and Chen Chen and Yaohui Cai and Zhiru Zhang and Cunxi Yu , title =. 2025 , url =. doi:10.1109/ICCAD66269.2025.11240719 , timestamp =
-
[5]
Glenn Sun and Yihong Zhang and Haobin Ni , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2408.17042 , eprinttype =. 2408.17042 , timestamp =
-
[6]
EGRAPHS 2023 workshop , year=
Improving term extraction with acyclic constraints , author=. EGRAPHS 2023 workshop , year=
2023
-
[7]
Unsatisfiability-based optimization in clasp , booktitle =
Benjamin Andres and Benjamin Kaufmann and Oliver Matheis and Torsten Schaub , editor =. Unsatisfiability-based optimization in clasp , booktitle =. 2012 , url =. doi:10.4230/LIPICS.ICLP.2012.211 , timestamp =
-
[8]
doi:10.2200/S00457ED1V01Y201211AIM019 , isbn =
Martin Gebser and Roland Kaminski and Benjamin Kaufmann and Torsten Schaub , title =. doi:10.2200/S00457ED1V01Y201211AIM019 , isbn =
-
[9]
Roland Kaminski and Javier Romero and Torsten Schaub and Philipp Wanko , title =. Theory Pract. Log. Program. , volume =. 2023 , url =. doi:10.1017/S1471068421000508 , timestamp =
-
[10]
Theory and Practice of Logic Programming , publisher=
Martin Gebser and Roland Kaminski and Benjamin Kaufmann and Torsten Schaub , title =. Theory Pract. Log. Program. , timestamp =. doi:10.1017/S1471068418000054 , number =
-
[11]
Martin Gebser and Benjamin Kaufmann and Torsten Schaub , title =. Theory Pract. Log. Program. , volume =. 2012 , url =. doi:10.1017/S1471068412000166 , timestamp =
-
[12]
Yihong Zhang and Yisu Remy Wang and Oliver Flatt and David Cao and Philip Zucker and Eli Rosenthal and Zachary Tatlock and Max Willsey , title =. Proc. 2023 , url =. doi:10.1145/3591239 , timestamp =
-
[13]
Guided Equality Saturation , journal =
Thomas Koehler and Andr. Guided Equality Saturation , journal =. 2024 , url =. doi:10.1145/3632900 , timestamp =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.