miniReranker: Efficient Multimodal Reranking through Visual Cache Reuse and Interaction Sparsity
Pith reviewed 2026-06-27 11:34 UTC · model grok-4.3
The pith
A vision-first prompting format plus three sparsity interventions lets multimodal rerankers run at under 1 percent of dense-model runtime while keeping over 96 percent of original relevance accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that a vision-first formulation improves both cache reuse and relevance modeling, and that the combination of early exit, restricted cross-segment attention, and embedder-guided pruning reduces reranking runtime to less than 1 percent of the dense baseline under high-reuse conditions for a single query while retaining more than 96 percent of the dense model's performance.
What carries the argument
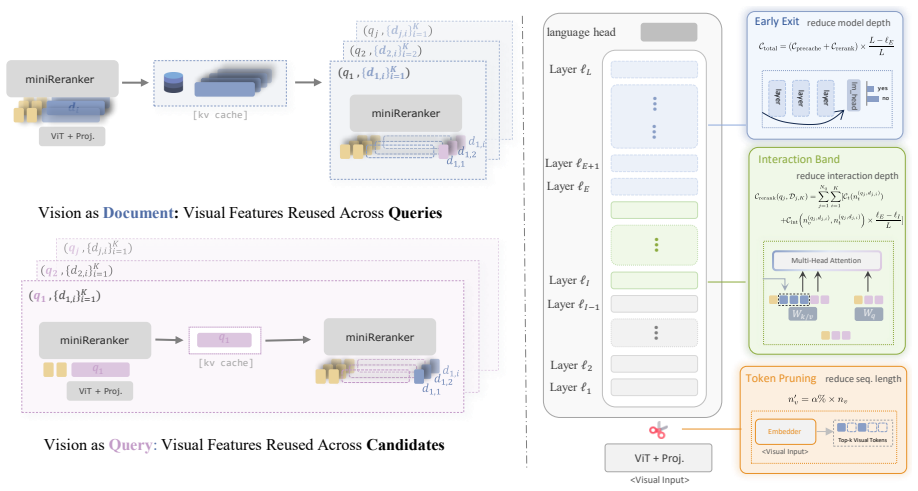
The vision-first prompt formulation together with early-exit, narrow interaction-band attention, and embedder-guided visual-token pruning.
If this is right
- Reranking latency becomes low enough for real-time use inside large-scale multimodal search pipelines.
- Visual tokens can be cached once per query and reused across many candidate documents.
- Model depth and attention cost scale independently of the number of documents being reranked.
- The same sparsity pattern can be applied to other point-wise MLLM scoring tasks.
Where Pith is reading between the lines
- The same cache-reuse pattern may extend to any task where one modality is fixed across many comparisons.
- Pruning guided by a lightweight embedder could be tested on non-visual modalities if an analogous cheap signal exists.
- Early-exit thresholds might be learned per layer rather than fixed, potentially recovering more accuracy at the same speed.
Load-bearing premise
The three sparsity interventions do not materially reduce the MLLM's ability to judge query-document relevance.
What would settle it
Measure NDCG or recall on a held-out multimodal retrieval set after applying all three sparsity methods; if accuracy falls below 96 percent of the dense baseline the central efficiency claim no longer holds.
Figures






read the original abstract
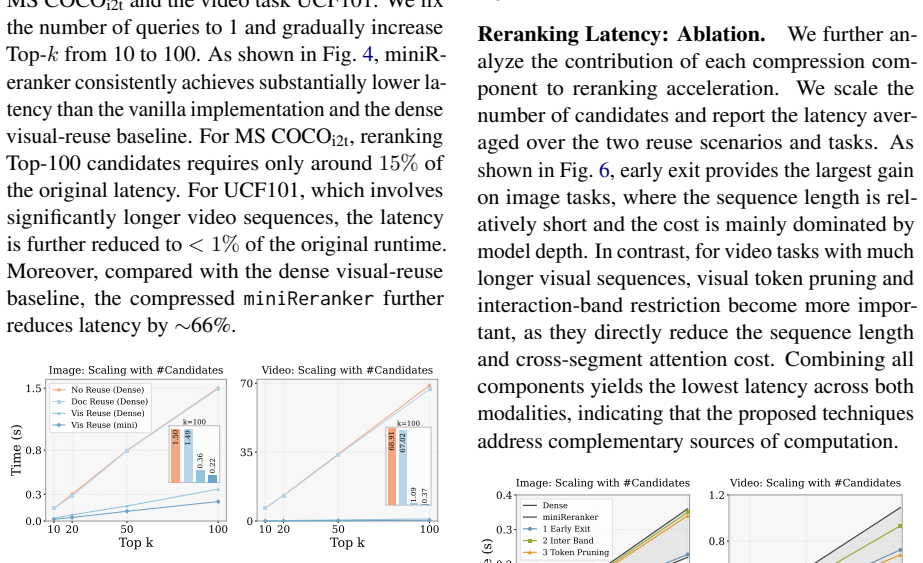
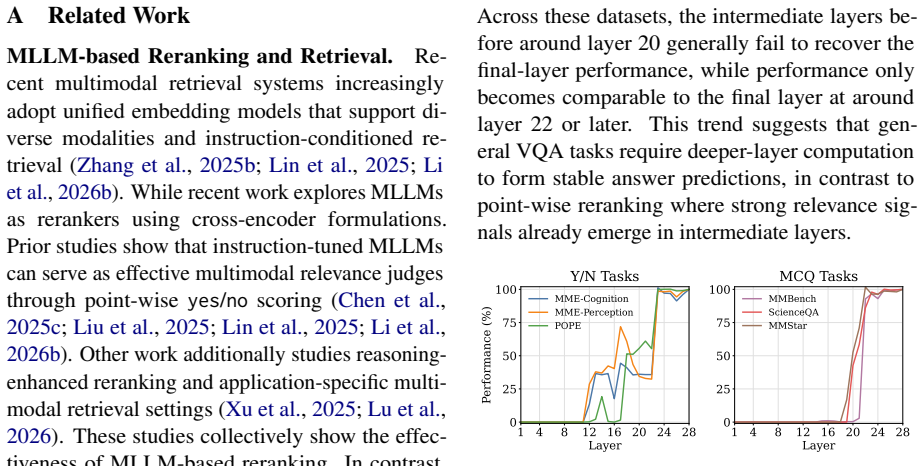
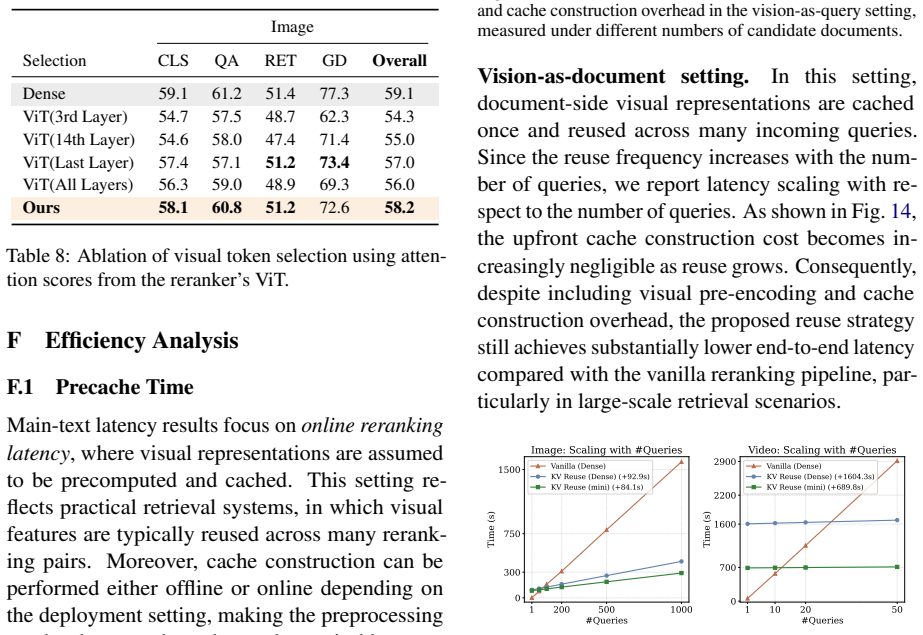
Multimodal large language models (MLLMs) have recently shown strong potential as point-wise rerankers by directly modeling query--document relevance through next-token prediction. However, point-wise reranking suffers from substantial repeated computation across query--document pairs, while the causal structure of transformers allows only prefix segments to be reused via pre-caching. To address the misalignment of existing query-first and document-first formats with both VQA-style prompting and computation-aware reuse, we propose a $\textit{vision-first}$ formulation that improves both cache reuse efficiency and reranking performance. However, the remaining cost is still considerable and stems from three main sources: (1) $\textit{model depth}$, for which we reduce active parameters via early exit; (2) $\textit{cross-segment attention}$, which we restrict to a narrow interaction band across a few layers; and (3) $\textit{visual tokens}$, where we reduce the number of tokens via embedder-guided pruning. Together, these designs form miniReranker, which reduces reranking runtime to <1% of the dense implementation under high-reuse settings for a single query, while preserving >96% of the dense model performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes miniReranker for efficient point-wise multimodal reranking with MLLMs. It introduces a vision-first prompting formulation to improve KV-cache reuse over query-first or document-first formats, then applies three sparsity interventions—early exit to reduce active model depth, a narrow interaction band to limit cross-segment attention in selected layers, and embedder-guided pruning to reduce visual tokens. The central claim is that these changes together reduce reranking runtime to <1% of a dense baseline under high-reuse single-query settings while retaining >96% of the dense model's relevance performance.
Significance. If the reported efficiency and accuracy numbers are reproducible, the work would address a practical bottleneck in deploying MLLM rerankers at scale by exploiting cache reuse and structured sparsity rather than model compression or distillation. The vision-first reformulation and the three targeted sparsity mechanisms are concrete engineering contributions that could be adopted in production retrieval pipelines.
major comments (2)
- [Abstract] Abstract: the manuscript states concrete runtime (<1% of dense) and accuracy (>96% retention) figures yet supplies no experimental section, datasets, baselines, number of queries/documents, hardware, or statistical details; without these the central claim cannot be evaluated.
- No equations, derivations, or complexity analysis appear in the provided text; the efficiency claims rest entirely on unreported empirical measurements, leaving open whether the reported gains are parameter-free or depend on specific hyper-parameter choices for the interaction band and pruning thresholds.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to ensure all claims are fully supported and evaluable.
read point-by-point responses
-
Referee: [Abstract] Abstract: the manuscript states concrete runtime (<1% of dense) and accuracy (>96% retention) figures yet supplies no experimental section, datasets, baselines, number of queries/documents, hardware, or statistical details; without these the central claim cannot be evaluated.
Authors: We agree that the provided manuscript text (limited to the abstract) does not include an experimental section or supporting details. The full submission will be revised to incorporate a dedicated Experiments section reporting the specific datasets, baselines, query/document counts, hardware platform, and statistical measures (including variance across runs) that underpin the <1% runtime and >96% retention figures. revision: yes
-
Referee: [—] No equations, derivations, or complexity analysis appear in the provided text; the efficiency claims rest entirely on unreported empirical measurements, leaving open whether the reported gains are parameter-free or depend on specific hyper-parameter choices for the interaction band and pruning thresholds.
Authors: We acknowledge the absence of equations and complexity analysis in the current text. We will add a dedicated Analysis section that formally defines the vision-first prompting, early-exit criterion, narrow interaction band, and embedder-guided pruning, derives the resulting complexity reductions, and explicitly states the hyper-parameter values chosen for the interaction band width and pruning thresholds. We will also include a sensitivity study showing how runtime and relevance vary with these choices. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical engineering design paper focused on practical optimizations (vision-first formulation, early exit, narrow interaction band, embedder-guided pruning) for multimodal reranking efficiency. No equations, derivations, or mathematical claims are present in the provided abstract or description. There are no load-bearing steps that reduce predictions to inputs by construction, no fitted parameters presented as independent predictions, and no self-citation chains invoked to justify uniqueness theorems or ansatzes. The central claims rest on design choices and reported empirical performance metrics rather than any self-referential logic, making the work self-contained against external benchmarks with no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2023 , eprint=
Attention Is All You Need , author=. 2023 , eprint=
2023
-
[2]
Zhanpeng Chen and Chengjin Xu and Yiyan Qi and Jian Guo , year=
-
[3]
2020 , eprint=
Passage Re-ranking with BERT , author=. 2020 , eprint=
2020
-
[4]
2023 , eprint=
UniIR: Training and Benchmarking Universal Multimodal Information Retrievers , author=. 2023 , eprint=
2023
-
[5]
2021 , eprint=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. 2021 , eprint=
2021
-
[6]
2019 , eprint=
Multi-Stage Document Ranking with BERT , author=. 2019 , eprint=
2019
-
[7]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Liu, Nelson F. and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy. Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00638
-
[8]
2024 , eprint=
Efficient Streaming Language Models with Attention Sinks , author=. 2024 , eprint=
2024
-
[9]
arXiv preprint arXiv:2511.21631 , year=
Qwen3-VL Technical Report , author=. arXiv preprint arXiv:2511.21631 , year=
-
[10]
2024 , eprint=
Improved Baselines with Visual Instruction Tuning , author=. 2024 , eprint=
2024
-
[11]
2024 , eprint=
An Image is Worth 1/2 Tokens After Layer 2: Plug-and-Play Inference Acceleration for Large Vision-Language Models , author=. 2024 , eprint=
2024
-
[12]
2022 , eprint=
Flamingo: a Visual Language Model for Few-Shot Learning , author=. 2022 , eprint=
2022
-
[13]
2023 , eprint=
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning , author=. 2023 , eprint=
2023
-
[14]
2024 , eprint=
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks , author=. 2024 , eprint=
2024
-
[15]
2024 , eprint=
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution , author=. 2024 , eprint=
2024
-
[16]
From Data to Model: A Survey of the Compression Lifecycle in MLLMs , url=
Wu, Hao and Tong, Junlong and Wang, Xudong and Tan, Yang and Zeng, Changyu and Antsiferova, Anastasia and Shen, Xiaoyu , year=. From Data to Model: A Survey of the Compression Lifecycle in MLLMs , url=. doi:10.36227/techrxiv.177220375.55495124/v1 , publisher=
-
[17]
2021 , eprint=
Learning Transferable Visual Models From Natural Language Supervision , author=. 2021 , eprint=
2021
-
[18]
2024 , eprint=
Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting , author=. 2024 , eprint=
2024
-
[19]
Cao, Zhe and Qin, Tao and Liu, Tie-Yan and Tsai, Ming-Feng and Li, Hang , title =. 2007 , isbn =. doi:10.1145/1273496.1273513 , booktitle =
-
[20]
Xia, Fen and Liu, Tie-Yan and Wang, Jue and Zhang, Wensheng and Li, Hang , title =. 2008 , isbn =. doi:10.1145/1390156.1390306 , booktitle =
-
[21]
2025 , eprint=
Supervised Fine-Tuning or Contrastive Learning? Towards Better Multimodal LLM Reranking , author=. 2025 , eprint=
2025
-
[22]
2026 , eprint=
Qwen3-VL-Embedding and Qwen3-VL-Reranker: A Unified Framework for State-of-the-Art Multimodal Retrieval and Ranking , author=. 2026 , eprint=
2026
-
[23]
2025 , eprint=
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , author=. 2025 , eprint=
2025
-
[24]
Chen, Zhanpeng and Xu, Chengjin and Qi, Yiyan and Jiang, Xuhui and Guo, Jian. VLM Is a Strong Reranker: Advancing Multimodal Retrieval-augmented Generation via Knowledge-enhanced Reranking and Noise-injected Training. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.432
-
[25]
arXiv preprint arXiv:2506.12364 , year=
Mm-r5: Multimodal reasoning-enhanced reranker via reinforcement learning for document retrieval , author=. arXiv preprint arXiv:2506.12364 , year=
-
[26]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
LamRA: Large Multimodal Model as Your Advanced Retrieval Assistant , author=. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=. 2025 , organization=
2025
-
[27]
2025 , url=
Sheng-Chieh Lin and Chankyu Lee and Mohammad Shoeybi and Jimmy Lin and Bryan Catanzaro and Wei Ping , booktitle=. 2025 , url=
2025
-
[28]
2026 , eprint=
Beyond Global Similarity: Towards Fine-Grained, Multi-Condition Multimodal Retrieval , author=. 2026 , eprint=
2026
-
[29]
2025 , eprint=
The Evolution of Reranking Models in Information Retrieval: From Heuristic Methods to Large Language Models , author=. 2025 , eprint=
2025
-
[30]
2025 , eprint=
Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval-Augmented Generation , author=. 2025 , eprint=
2025
-
[31]
TechRxiv , volume =
Yinxin Zhou and Qin Luo and Bin Feng and Bang Wang , title =. TechRxiv , volume =. 2025 , doi =
2025
-
[32]
Bridging Modalities: Improving Universal Multimodal Retrieval by Multimodal Large Language Models , year=
Zhang, Xin and Zhang, Yanzhao and Xie, Wen and Li, Mingxin and Dai, Ziqi and Long, Dingkun and Xie, Pengjun and Zhang, Meishan and Li, Wenjie and Zhang, Min , booktitle=. Bridging Modalities: Improving Universal Multimodal Retrieval by Multimodal Large Language Models , year=
-
[33]
Towards Text-Image Interleaved Retrieval
Zhang, Xin and Dai, Ziqi and Li, Yongqi and Zhang, Yanzhao and Long, Dingkun and Xie, Pengjun and Zhang, Meishan and Yu, Jun and Li, Wenjie and Zhang, Min. Towards Text-Image Interleaved Retrieval. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.214
-
[34]
2020 , eprint=
ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT , author=. 2020 , eprint=
2020
-
[35]
2025 , eprint=
VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks , author=. 2025 , eprint=
2025
-
[36]
2025 , eprint=
VLM2Vec-V2: Advancing Multimodal Embedding for Videos, Images, and Visual Documents , author=. 2025 , eprint=
2025
-
[37]
2026 , eprint=
ViDoRe V3: A Comprehensive Evaluation of Retrieval Augmented Generation in Complex Real-World Scenarios , author=. 2026 , eprint=
2026
-
[38]
2025 , eprint=
jina-embeddings-v4: Universal Embeddings for Multimodal Multilingual Retrieval , author=. 2025 , eprint=
2025
-
[39]
2024 , eprint=
MMBench: Is Your Multi-modal Model an All-around Player? , author=. 2024 , eprint=
2024
-
[40]
2023 , eprint=
Evaluating Object Hallucination in Large Vision-Language Models , author=. 2023 , eprint=
2023
-
[41]
2025 , eprint=
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models , author=. 2025 , eprint=
2025
-
[42]
2022 , eprint=
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering , author=. 2022 , eprint=
2022
-
[43]
2024 , eprint=
Are We on the Right Way for Evaluating Large Vision-Language Models? , author=. 2024 , eprint=
2024
-
[44]
2019 , eprint=
GQA: A New Dataset for Real-World Visual Reasoning and Compositional Question Answering , author=. 2019 , eprint=
2019
-
[45]
2019 , eprint=
Towards VQA Models That Can Read , author=. 2019 , eprint=
2019
-
[46]
arXiv preprint arXiv:2404.01258 , year=
Direct Preference Optimization of Video Large Multimodal Models from Language Model Reward , author=. arXiv preprint arXiv:2404.01258 , year=
-
[47]
2024 , eprint=
ColPali: Efficient Document Retrieval with Vision Language Models , author=. 2024 , eprint=
2024
-
[48]
2025 , eprint=
VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents , author=. 2025 , eprint=
2025
-
[49]
2024 , eprint=
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models , author=. 2024 , eprint=
2024
-
[50]
2025 , eprint=
Do Language Models Use Their Depth Efficiently? , author=. 2025 , eprint=
2025
-
[51]
2026 , eprint=
The Curse of Depth in Large Language Models , author=. 2026 , eprint=
2026
-
[52]
2025 , eprint=
Layer by Layer: Uncovering Hidden Representations in Language Models , author=. 2025 , eprint=
2025
-
[53]
2025 , eprint=
The Remarkable Robustness of LLMs: Stages of Inference? , author=. 2025 , eprint=
2025
-
[54]
2024 , eprint=
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models , author=. 2024 , eprint=
2024
-
[55]
2026 , eprint=
ViCA: Efficient Multimodal LLMs with Vision-Only Cross-Attention , author=. 2026 , eprint=
2026
-
[56]
2026 , eprint=
Prefill-as-a-Service: KVCache of Next-Generation Models Could Go Cross-Datacenter , author=. 2026 , eprint=
2026
-
[57]
HiDrop: Hierarchical Vision Token Reduction in
Hao Wu and Yingqi Fan and Dai Jinyang and Junlong Tong and Yunpu Ma and Xiaoyu Shen , booktitle=. HiDrop: Hierarchical Vision Token Reduction in. 2026 , url=
2026
-
[58]
Lin, Junyan and Chen, Haoran and Zhu, Dawei and Shen, Xiaoyu. To Preserve or To Compress: An In-Depth Study of Connector Selection in Multimodal Large Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.325
-
[59]
2026 , eprint=
What Do Visual Tokens Really Encode? Uncovering Sparsity and Redundancy in Multimodal Large Language Models , author=. 2026 , eprint=
2026
-
[60]
Yingqi Fan and Anhao Zhao and Jinlan Fu and Junlong Tong and Hui Su and Yijie Pan and Wei Zhang and Xiaoyu Shen , year=. 2510.17205 , archivePrefix=
-
[61]
2021 , journal=
A Mathematical Framework for Transformer Circuits , author=. 2021 , journal=
2021
-
[62]
2020 , url =
nostalgebraist , title =. 2020 , url =
2020
-
[63]
Proceedings of the ACM Web Conference 2026 , pages=
LongRanker: Efficient One-Pass Document Reranking with Long-Context Large Language Models , author=. Proceedings of the ACM Web Conference 2026 , pages=
2026
-
[64]
2026 , eprint=
Very Efficient Listwise Multimodal Reranking for Long Documents , author=. 2026 , eprint=
2026
-
[65]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Scalable In-context Ranking with Generative Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[66]
The Thirteenth International Conference on Learning Representations , year=
Attention in Large Language Models Yields Efficient Zero-Shot Re-Rankers , author=. The Thirteenth International Conference on Learning Representations , year=
-
[67]
Query-Focused Retrieval Heads Improve Long-Context Reasoning and Re-ranking
Zhang, Wuwei and Yin, Fangcong and Yen, Howard and Chen, Danqi and Ye, Xi. Query-Focused Retrieval Heads Improve Long-Context Reasoning and Re-ranking. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1214
-
[68]
2025 , eprint=
HyperRAG: Enhancing Quality-Efficiency Tradeoffs in Retrieval-Augmented Generation with Reranker KV-Cache Reuse , author=. 2025 , eprint=
2025
-
[69]
2025 , eprint=
Reranking with Compressed Document Representation , author=. 2025 , eprint=
2025
-
[70]
2026 , eprint=
Efficient Long-Document Reranking via Block-Level Embeddings and Top-k Interaction Refinement , author=. 2026 , eprint=
2026
-
[71]
2025 , eprint=
RankLLM: A Python Package for Reranking with LLMs , author=. 2025 , eprint=
2025
-
[72]
2025 , eprint=
Rank-R1: Enhancing Reasoning in LLM-based Document Rerankers via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[73]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[74]
2024 , eprint=
A Stitch in Time Saves Nine: Small VLM is a Precise Guidance for Accelerating Large VLMs , author=. 2024 , eprint=
2024
-
[75]
2025 , eprint=
PACT: Pruning and Clustering-Based Token Reduction for Faster Visual Language Models , author=. 2025 , eprint=
2025
-
[76]
Jiang, Pengfei and Li, Hanjun and Zhao, Linglan and Chao, Fei and Yan, Ke and Ding, Shouhong and Ji, Rongrong , year=. VISA: Group-wise Visual Token Selection and Aggregation via Graph Summarization for Efficient MLLMs Inference , url=. doi:10.1145/3746027.3755792 , booktitle=
-
[77]
2025 , eprint=
See What You Are Told: Visual Attention Sink in Large Multimodal Models , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.