The social consequences of AI delegation
Pith reviewed 2026-06-27 10:49 UTC · model grok-4.3
The pith
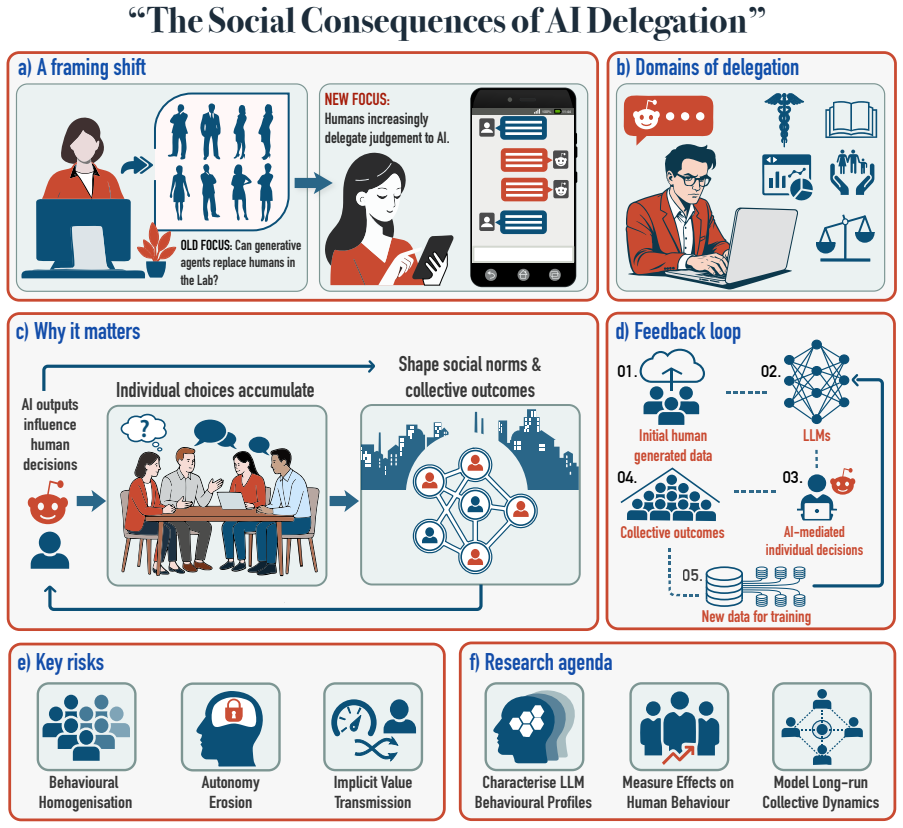
Humans are beginning to delegate their own deliberation to LLMs, turning these systems into functional social actors that shape decisions, norms, and collective dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The more consequential question is not simply whether researchers should use LLMs as human surrogates, but whether - and under what conditions - humans are beginning to use LLMs as surrogates for their own deliberation. Across domains including health, law, finance, education, and personal guidance, increasing numbers of people consult generative AI systems before, alongside, or instead of human experts, peers, or independent judgment. Although evidence for actual delegation remains uneven, this uncertainty makes the phenomenon an urgent social-scientific object of study. We argue for a research programme that treats LLMs as consequential social actors in a functional sense: systems whose ou
What carries the argument
LLMs treated as consequential social actors in a functional sense, where the mechanism is humans consulting these systems before, alongside, or instead of human experts or independent judgment, allowing AI outputs to influence decisions and norms.
If this is right
- Research attention must move beyond laboratory substitution of LLMs for humans to field studies of real-world delegation in health, law, finance, education, and personal guidance.
- Social norms around expertise and decision-making are expected to shift as AI outputs become routine inputs before or instead of human consultation.
- Collective dynamics such as opinion formation, consensus building, and group behavior may change when many individuals draw on the same LLM sources.
- The uneven nature of current evidence itself becomes a reason to prioritize systematic observation rather than wait for clearer patterns to emerge.
Where Pith is reading between the lines
- Frameworks developed for studying algorithmic influence on social media could be adapted to track how LLM outputs propagate through repeated human consultations.
- Questions of responsibility for downstream effects, such as biased or erroneous advice, may require new legal or ethical categories that treat the AI output as an intermediate social actor.
- Experimental designs could compare decision quality and diversity when groups deliberate with versus without access to LLM surrogates.
- The same delegation pattern might appear in other AI systems beyond language models, suggesting the research program could generalize to other generative tools.
Load-bearing premise
The use of LLMs as substitutes for human deliberation is happening at a scale large enough to produce measurable effects on social norms and collective dynamics, even though current evidence for that scale is uneven.
What would settle it
Large-scale surveys or usage logs across health, law, finance, and education showing that most people still rely on human experts or independent judgment rather than LLM outputs for consequential decisions.
Figures
read the original abstract
A substantial body of recent work has debated whether large language models (LLMs) can serve as substitutes for human participants in behavioural research. This debate, however, captures only one direction of a rapidly changing relationship. The more consequential question is not simply whether researchers should use LLMs as human surrogates, but whether - and under what conditions - humans are beginning to use LLMs as surrogates for their own deliberation. Across domains including health, law, finance, education, and personal guidance, increasing numbers of people consult generative AI systems before, alongside, or instead of human experts, peers, or independent judgment. Although evidence for actual delegation remains uneven, this uncertainty makes the phenomenon an urgent social-scientific object of study. We argue for a research programme that treats LLMs as consequential social actors in a functional sense: systems whose outputs shape human decisions, social norms, and collective dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that the ongoing debate over using LLMs as substitutes for human participants in behavioral research addresses only one direction of the human-AI relationship. The more consequential direction, it claims, is humans delegating their own deliberation to LLMs across domains such as health, law, finance, education, and personal guidance. Although evidence for such delegation remains uneven, the authors treat this uncertainty as motivation for a dedicated research program that treats LLMs as consequential social actors in a functional sense—systems whose outputs shape human decisions, social norms, and collective dynamics.
Significance. If the described delegation phenomenon occurs at meaningful scale, the proposed research program could open productive lines of inquiry at the intersection of social science and AI studies by shifting attention from LLMs as research tools to LLMs as influences on real-world social processes. The manuscript's honesty about the current data gap is a strength, as it frames the call for study around an acknowledged uncertainty rather than overstated claims. As a position statement without new empirical results or formal models, its value lies in its potential to stimulate targeted investigations rather than in any tested proposition.
minor comments (2)
- The abstract and framing would benefit from one or two concrete examples of observed or hypothesized delegation (e.g., specific use cases in health or finance) to illustrate the functional social-actor claim without requiring new data.
- A short section outlining example research questions or methodological approaches for the proposed program would make the call more actionable for readers while remaining consistent with the position-piece format.
Simulated Author's Rebuttal
We thank the referee for their constructive and positive assessment of the manuscript. We appreciate the recognition that the paper's value lies in framing a call for study around an acknowledged uncertainty rather than overstated claims, and that this honesty is a strength. The referee's summary accurately captures the manuscript's central argument regarding the shift from LLMs as research tools to LLMs as influences on real-world social processes.
Circularity Check
No circularity: position paper with no derivations or fitted inputs
full rationale
The paper is a conceptual position statement advocating a research program on LLMs as social actors. It contains no equations, parameters, derivations, or empirical fits. The abstract explicitly flags that 'evidence for actual delegation remains uneven' and uses this uncertainty to motivate study rather than asserting a quantified claim that could reduce to its own inputs. No self-citation chains, self-definitional loops, or renamed known results appear in the provided text. The central claim is functional and argumentative, remaining self-contained without internal reduction to fitted quantities or prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
I., and Kalai, A
Aher, G., Arriaga, R. I., and Kalai, A. T. (2023). Using large language models to simulate multiple humans and replicate human subject studies. In Proceedings of the 40th International Conference on Machine Learning, pages 337--371
2023
-
[2]
R., Shah, J
Anderson, B. R., Shah, J. H., and Kreminski, M. (2024). Homogenization effects of large language models on human creative ideation. In Proceedings of the 16th Conference on Creativity & Cognition (C&C '24), pages 413--425. Association for Computing Machinery
2024
-
[3]
P., Busby, E
Argyle, L. P., Busby, E. C., Fulda, N., Gubler, J. R., Rytting, C., and Wingate, D. (2023). Out of one, many: Using language models to simulate human samples. Political Analysis, 31(3):337--351
2023
-
[4]
J., Lin, M
Ayo-Ajibola, O., Davis, R. J., Lin, M. E., Riddell, J., and Kravitz, R. L. (2024). Characterizing the adoption and experiences of users of artificial intelligence--generated health information in the United States : Cross-sectional questionnaire study. Journal of Medical Internet Research, 26:e55138
2024
-
[5]
M., Gebru, T., McMillan-Major, A., and Shmitchell, S
Bender, E. M., Gebru, T., McMillan-Major, A., and Shmitchell, S. (2021). On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, pages 610--623
2021
-
[6]
A., Aditi, E., Altman, R., Arora, S., Artetxe, M., et al
Bommasani, R., Hudson, D. A., Aditi, E., Altman, R., Arora, S., Artetxe, M., et al. (2021). On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258
Pith/arXiv arXiv 2021
-
[7]
F., Nussberger, A.-M., Czaplicka, A., Acerbi, A., Griffiths, T
Brinkmann, L., Baumann, F., Bonnefon, J.-F., Derex, M., M\" u ller, T. F., Nussberger, A.-M., Czaplicka, A., Acerbi, A., Griffiths, T. L., Henrich, J., Leibo, J. Z., McElreath, R., Oudeyer, P.-Y., Stray, J., and Rahwan, I. (2023). Machine culture. Nature Human Behaviour, 7(11):1855--1868
2023
-
[8]
Carr, N. (2011). The Shallows: What the Internet Is Doing to Our Brains. W. W. Norton
2011
-
[9]
H., Monahan, A
Choi, J. H., Monahan, A. B., and Schwarcz, D. (2024). Lawyering in the age of artificial intelligence. Minnesota Law Review, 109(1):147--218
2024
-
[10]
and Chalmers, D
Clark, A. and Chalmers, D. (1998). The extended mind. Analysis, 58(1):7--19
1998
-
[11]
Carlini, N., Chien, S., Nasr, M., Song, S., Terzis, A., and Tramer, F
Desai, A. P., Mallya, G. S., Luqman, M., Ravi, T., Kota, N., and Yadav, P. (2024). Opportunities and challenges of generative- AI in finance. In 2024 IEEE International Conference on Big Data (BigData), pages 4913--4920. doi:10.1109/BigData62323.2024.10825658
-
[12]
J., Simmons, J
Dietvorst, B. J., Simmons, J. P., and Massey, C. (2015). Algorithm aversion: People erroneously avoid algorithms after seeing them err. Journal of Experimental Psychology: General, 144(1):114--126
2015
-
[13]
Doshi, A. R. and Hauser, O. P. (2024). Generative AI enhances individual creativity but reduces the collective diversity of novel content. Science Advances, 10(28):eadn5290
2024
-
[14]
Durmus, E., Nguyen, K., Liao, T. I., Schiefer, N., Askell, A., Bakhtin, A., Chen, C., Hatfield-Dodds, Z., Hernandez, D., Joseph, N., Lovitt, L., McCandlish, S., Sikder, O., Tamkin, A., Thamkul, J., Kaplan, J., Clark, J., and Ganguli, D. (2024). Towards measuring the representation of subjective global opinions in language models. arXiv preprint arXiv:2306.16388
Pith/arXiv arXiv 2024
-
[15]
Eisenstein, E. L. (1980). The Printing Press as an Agent of Change. Cambridge University Press
1980
-
[16]
Geng, M., Trotta, R., Nanni, F., and Bizer, C. (2025). The impact of large language models in academia: From writing to speaking. In Findings of the Association for Computational Linguistics: ACL 2025, pages 19303--19319
2025
-
[17]
a m\" a l\
H\" a m\" a l\" a inen, P., Tavast, M., and Kunnari, A. (2023). Evaluating large language models in generating synthetic HCI research data: a case study. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, pages 1--19
2023
-
[18]
How Gen Z uses gen AI --- and why it worries them
Harvard Business Review/Gallup/Walton Family Foundation (2026). How Gen Z uses gen AI --- and why it worries them. (https://hbr.org/2026/01/how-gen-z-uses-gen-ai-and-why-it-worries-them) Harvard Business Review, January 2026
2026
-
[19]
Hutchins, E. (1995). Cognition in the Wild. MIT Press
1995
-
[20]
and Raghavan, M
Kleinberg, J. and Raghavan, M. (2021). Algorithmic monoculture and social welfare. Proceedings of the National Academy of Sciences, 118(22):e2018340118
2021
-
[21]
and Thelwall, M
Kousha, K. and Thelwall, M. (2026). How much are LLMs changing the language of academic papers after ChatGPT? A multi-database and full text analysis. Scientometrics
2026
-
[22]
Laestadius, L., Bishop, A., Gonzalez, M., Illen c \' i k, D., and Campos-Castillo, C. (2024). Too human and not human enough: A grounded theory analysis of mental health harms from intimate human--AI relationships. New Media & Society, 26(10):5923--5941
2024
-
[23]
M., Minson, J
Logg, J. M., Minson, J. A., and Moore, D. A. (2019). Algorithm appreciation: People prefer algorithmic to human judgment. Organizational Behavior and Human Decision Processes, 151:90--103
2019
-
[24]
Maples, B., Cerit, M., Vishwanath, A., and Pea, R. (2024). Loneliness and suicide mitigation for students using GPT-3-enabled chatbots. npj Mental Health Research, 3:4
2024
-
[25]
Page, S. E. (2007). The Difference: How the Power of Diversity Creates Better Groups, Firms, Schools, and Societies. Princeton University Press
2007
-
[26]
and He, H
Padmakumar, V. and He, H. (2024). Does writing with language models reduce content diversity? In The Twelfth International Conference on Learning Representations (ICLR)
2024
-
[27]
and Riley, V
Parasuraman, R. and Riley, V. (1997). Humans and automation: Use, misuse, disuse, abuse. Human Factors, 39(2):230--253
1997
-
[28]
Parsons, T. (1937). The Structure of Social Action. McGraw-Hill
1937
-
[29]
Teens, social media and AI chatbots 2025 (https://www.pewresearch.org/internet/2025/12/09/teens-social-media-and-ai-chatbots-2025/)
Pew Research Center (2025). Teens, social media and AI chatbots 2025 (https://www.pewresearch.org/internet/2025/12/09/teens-social-media-and-ai-chatbots-2025/). Technical report, Pew Research Center, December 2025
2025
-
[30]
and Nass, C
Reeves, B. and Nass, C. (1996). The Media Equation: How People Treat Computers, Television, and New Media Like Real People and Places. Cambridge University Press
1996
-
[31]
H., Gallotti, R., and West, R
Salvi, F., Ribeiro, M. H., Gallotti, R., and West, R. (2025). On the conversational persuasiveness of GPT-4 Nature Human Behaviour, 9:1645--1653
2025
-
[32]
Santurkar, S., Durmus, E., Ladd, F., Lee, E., Liang, P., and Hashimoto, T. (2023). Whose opinions do language models reflect? In Proceedings of the 40th International Conference on Machine Learning, pages 29971--30004
2023
-
[33]
Seabrooke, T., Schneiders, E., Dowthwaite, L., Krook, J., Leesakul, N., Clos, J., Maior, H., and Fischer, J. (2024). A survey of lay people's willingness to generate legal advice using large language models. In Proceedings of the Second International Symposium on Trustworthy Autonomous Systems (TAS '24). Association for Computing Machinery
2024
-
[34]
and Choudhury, A
Shahsavar, Y. and Choudhury, A. (2023). User intentions to use ChatGPT for self-diagnosis and health-related purposes: Cross-sectional survey study. JMIR Human Factors, 10:e47564
2023
-
[35]
Shumailov, I., Shumaylov, Z., Zhao, Y., Gal, Y., Papernot, N., and Anderson, R. (2024). AI models collapse when trained on recursively generated data. Nature, 631:755--759
2024
-
[36]
Slocum, S., Parker-Sartori, A., and Hadfield-Menell, D. (2025). Diverse preference learning for capabilities and alignment. In The Thirteenth International Conference on Learning Representations
2025
-
[37]
Sparrow, B., Liu, J., and Wegner, D. M. (2011). Google effects on memory: Cognitive consequences of having information at our fingertips. Science, 333(6043):776--778
2011
-
[38]
Teixeira, A. S., Shergill, S. S., Laban, G. (2026) Human–AI interactions reshape the self and our social networks. Nat Mach Intell. https://doi.org/10.1038/s42256-026-01248-2
-
[39]
Weidinger, L., Mellor, J., Rauh, M., Griffin, C., Uesato, J., Huang, P.-S., Cheng, M., Glaese, M., Balle, B., Kasirzadeh, A., et al. (2021). Ethical and social risks of harm from language models. arXiv preprint arXiv:2112.04359
Pith/arXiv arXiv 2021
-
[40]
Yakura, H., Lopez-Lopez, E., Brinkmann, L., Serna, I., Gupta, P., and Rahwan, I. (2024). Empirical evidence of large language model's influence on human spoken communication. arXiv preprint arXiv:2409.01754
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.