Defeat the Heap: Zero-Copy Data Movement in AXI4MLIR
Pith reviewed 2026-06-27 11:08 UTC · model grok-4.3
The pith
Allocating MLIR buffers directly in DMA-mapped memory removes a redundant staging copy and halves main memory data movement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
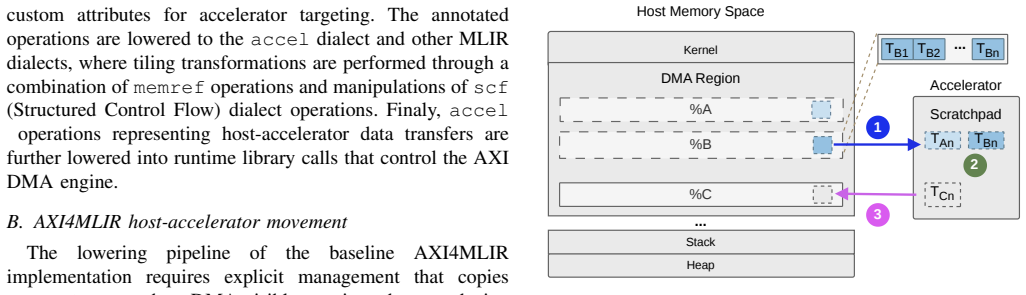
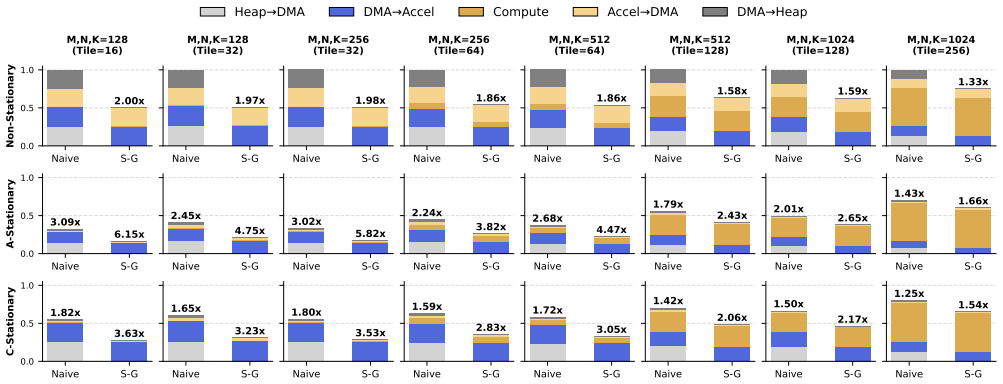
This work identifies the copy from heap-allocated memory buffers into contiguous DMA-mapped buffers as a redundant staging operation during host to accelerator transfers in AXI4MLIR. The optimization extends the accel dialect and implements lowering support that allocates buffers directly within DMA-mapped memory, omitting the staging copy. Evaluation with a configurable matrix-matrix multiplication accelerator shows the zero-copy scheme reduces main memory data movement by up to 2x and increases overall accelerator utilization.
What carries the argument
The lowering support added to the accel dialect that allocates buffers directly within DMA-mapped memory regions instead of using heap buffers followed by a copy.
If this is right
- Main memory data movement is reduced by up to 2x.
- Overall accelerator utilization increases as transfers take less time.
- The redundant staging copy between heap and DMA buffers is eliminated for host-accelerator transfers.
- The change applies to linear algebra kernels running on custom hardware accelerators.
Where Pith is reading between the lines
- The same direct-allocation pattern could be added to other MLIR dialects that generate accelerator driver code.
- Runtime systems would need to guarantee safe DMA-mapped regions for the allocation change to remain zero-overhead.
- The reduction in data movement could compound with other optimizations such as tiling or prefetching.
Load-bearing premise
Buffers can be allocated directly inside DMA-mapped memory regions without violating hardware constraints, OS policies, or introducing new overheads that offset the removed copy.
What would settle it
Measure the volume of main memory data transfers during matrix-matrix multiplication before and after switching to direct DMA-mapped buffer allocation.
Figures


read the original abstract
As custom hardware accelerators become increasingly central to machine learning workloads, efficient data transfer is critical for maximizing accelerator performance on linear algebra kernels. AXI4MLIR, an extension of the Multi-Level Intermediate Representation (MLIR) compiler framework for automated generation of host-accelerator driver code, incurs significant runtime overhead due to non-zero-copy CPU-accelerator data movement. During transfers from the host to the accelerator, data is copied from heap-allocated memory buffers into contiguous Direct Memory Access (DMA)-mapped buffers. This work identifies this copy as a redundant staging operation and eliminates it through zero-copy data movement. The optimization extends accel, an MLIR dialect introduced by AXI4MLIR, and implements lowering support that allocates buffers directly within DMA-mapped memory, thereby omitting the staging copy. We evaluate the proposed scheme using a configurable matrix-matrix multiplication accelerator and show that the zero-copy optimization reduces main memory data movement by up to 2x, increasing overall accelerator utilization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper describes an extension to AXI4MLIR that eliminates a redundant heap-to-DMA staging copy during host-accelerator transfers by extending the accel dialect and its lowering pass to allocate MLIR buffers directly inside DMA-mapped regions. It evaluates the change on a configurable matrix-matrix multiplication accelerator and reports that the optimization reduces main-memory data movement by up to 2x while increasing accelerator utilization.
Significance. A verified zero-copy path that removes a staging copy without new overheads would be a useful, incremental improvement for MLIR-based accelerator flows that rely on DMA. The approach is conceptually straightforward and targets a known source of overhead, but the manuscript supplies no experimental details, baselines, or verification of the three necessary conditions (DMA-region allocation feasibility, OS cost parity, and absence of new coherence/TLB traffic), so the practical significance cannot yet be assessed.
major comments (2)
- [Abstract / Evaluation] Abstract and evaluation description: the headline claim of 'up to 2x' reduction in main-memory data movement is stated without any workload description, matrix sizes, baseline (non-zero-copy) measurements, error bars, or even the number of runs, so the quantitative result cannot be reproduced or verified from the text.
- [Implementation / Lowering] Lowering pass and allocation strategy: the central assumption that arbitrary-sized, arbitrarily-aligned buffers can be placed directly in DMA-mapped regions without padding, extra copies, or new TLB/cache/coherence costs is load-bearing for the net 2x win, yet the manuscript provides no evidence or measurement that any of these conditions were checked.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive criticism. We agree that the current manuscript lacks sufficient experimental detail and verification of key assumptions. We will revise the paper to include the requested information and measurements. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation description: the headline claim of 'up to 2x' reduction in main-memory data movement is stated without any workload description, matrix sizes, baseline (non-zero-copy) measurements, error bars, or even the number of runs, so the quantitative result cannot be reproduced or verified from the text.
Authors: We agree that the abstract and evaluation sections do not provide enough detail for reproducibility. In the revised manuscript we will expand the evaluation section to describe the workloads (matrix-multiplication kernels), report the exact matrix dimensions tested, include the non-zero-copy baseline numbers, add error bars from multiple runs, and state the number of repetitions performed. These additions will make the 'up to 2x' claim verifiable from the text. revision: yes
-
Referee: [Implementation / Lowering] Lowering pass and allocation strategy: the central assumption that arbitrary-sized, arbitrarily-aligned buffers can be placed directly in DMA-mapped regions without padding, extra copies, or new TLB/cache/coherence costs is load-bearing for the net 2x win, yet the manuscript provides no evidence or measurement that any of these conditions were checked.
Authors: We acknowledge that the manuscript does not present explicit measurements confirming the absence of padding, extra copies, or new TLB/cache/coherence traffic. In the revision we will add a dedicated subsection that reports (1) the DMA-region allocation strategy and its feasibility for the tested sizes, (2) measured OS allocation cost parity, and (3) hardware performance-counter data showing no measurable increase in TLB misses or coherence traffic on the evaluated platform. If any of these conditions require additional platform-specific caveats, they will be stated explicitly. revision: yes
Circularity Check
No circularity: empirical implementation change with direct measurement
full rationale
The paper presents an engineering optimization that removes a heap-to-DMA staging copy by allocating buffers directly in DMA-mapped regions. The central claim (up to 2x reduction in memory movement) is supported by runtime measurements on a matrix-multiplication accelerator, not by any derivation, fitted parameters, or self-referential equations. No load-bearing self-citations, uniqueness theorems, or ansatzes appear in the provided text. The result is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption DMA-mapped memory regions can be allocated directly from the compiler without additional runtime cost or hardware incompatibility
Reference graph
Works this paper leans on
-
[1]
Hirac: A hier- archical accelerator with sorting-based packing for spgemms in dnn applications,
H. Shabani, A. Singh, B. Youhana, and X. Guo, “Hirac: A hier- archical accelerator with sorting-based packing for spgemms in dnn applications,” inIEEE International Symposium on High-Performance Computer Architecture, ser. HPCA’23, 2023, pp. 247–258
2023
-
[2]
Inca: Input-stationary dataflow at outside-the- box thinking about deep learning accelerators,
B. Kim, S. Li, and H. Li, “Inca: Input-stationary dataflow at outside-the- box thinking about deep learning accelerators,” inIEEE International Symposium on High-Performance Computer Architecture, ser. HPCA’23, 2023, pp. 29–41
2023
-
[3]
Mp-rec: Hardware-software co-design to enable multi-path recommendation,
S. Hsia, U. Gupta, B. Acun, N. Ardalani, P. Zhong, G.-Y . Wei, D. Brooks, and C.-J. Wu, “Mp-rec: Hardware-software co-design to enable multi-path recommendation,” inProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, ser. ASPLOS 2023, 2023, p. 449–465
2023
-
[4]
Flexagon: A multi-dataflow sparse-sparse matrix multiplication accelerator for efficient dnn processing,
F. Muñoz Martínez, R. Garg, M. Pellauer, J. L. Abellán, M. E. Aca- cio, and T. Krishna, “Flexagon: A multi-dataflow sparse-sparse matrix multiplication accelerator for efficient dnn processing,” inProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, ser. ASPLOS’23, 2023, p. 252–265
2023
-
[5]
AXI4MLIR: User-Driven Auto- matic Host Code Generation for Custom AXI-Based Accelerators,
N. B. Agostini, J. Haris, P. Gibson, M. Jayaweera, N. Rubin, A. Tumeo, J. L. Abellán, J. Cano, and D. Kaeli, “AXI4MLIR: User-Driven Auto- matic Host Code Generation for Custom AXI-Based Accelerators,” in Proceedings of the 2024 IEEE/ACM International Symposium on Code Generation and Optimization, ser. CGO ’24, 2024, p. 143–157
2024
-
[6]
MLIR: Scaling Compiler Infrastructure for Domain Specific Computation,
C. Lattner, M. Amini, U. Bondhugula, A. Cohen, A. Davis, J. Pienaar, R. Riddle, T. Shpeisman, N. Vasilache, and O. Zinenko, “MLIR: Scaling Compiler Infrastructure for Domain Specific Computation,” in IEEE/ACM International Symposium on Code Generation and Optimiza- tion, ser. CGO’21, 2021, pp. 2–14
2021
-
[7]
’linalg’ Dialect,
M. Developers, “’linalg’ Dialect,” 2020, online accessed on 11-04-2023. [Online]. Available: https://mlir.llvm.org/docs/Dialects/Linalg/
2020
-
[8]
Data Transfer Optimizations for Host-CPU and Accelerators in AXI4MLIR,
J. Haris, N. B. Agostini, A. Tumeo, D. Kaeli, and J. Cano, “Data Transfer Optimizations for Host-CPU and Accelerators in AXI4MLIR,”
-
[9]
Available: https://arxiv.org/abs/2402.19184
[Online]. Available: https://arxiv.org/abs/2402.19184
-
[10]
Eyeriss: a spatial architecture for energy-efficient dataflow for convolutional neural networks,
Y .-H. Chen, J. Emer, and V . Sze, “Eyeriss: a spatial architecture for energy-efficient dataflow for convolutional neural networks,” in Proceedings of the 43rd International Symposium on Computer Architecture, ser. ISCA ’16. New York, USA: IEEE Press, 2016, p. 367–379. [Online]. Available: https://doi.org/10.1109/ISCA.2016.40
-
[11]
DLAS: A Conceptual Model for Across-Stack Deep Learning Acceleration,
P. Gibson, J. Cano, E. Crowley, A. Storkey, and M. O’boyle, “DLAS: A Conceptual Model for Across-Stack Deep Learning Acceleration,”ACM Transactions on Architecture and Code Optimization, 2025
2025
-
[12]
Mlir-based ai engine toolchain and iron api,
Xilinx/AMD, “Mlir-based ai engine toolchain and iron api,” https: //github.com/Xilinx/mlir-aie, 2025, accessed on December 5, 2025
2025
-
[13]
Compiler-driven simulation of reconfigurable hardware accelerators,
Z. Li, Y . Ye, S. Neuendorffer, and A. Sampso, “Compiler-driven simulation of reconfigurable hardware accelerators,” 2022. [Online]. Available: https://arxiv.org/abs/2202.00739
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.