ITME: Inference Tiered Memory Expansion with Disaggregated CXL-Hybrid Memories
Pith reviewed 2026-06-27 08:10 UTC · model grok-4.3
The pith
ITME adds CXL-hybrid remote memory to handle TB-scale KV caches in LLM inference beyond host limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
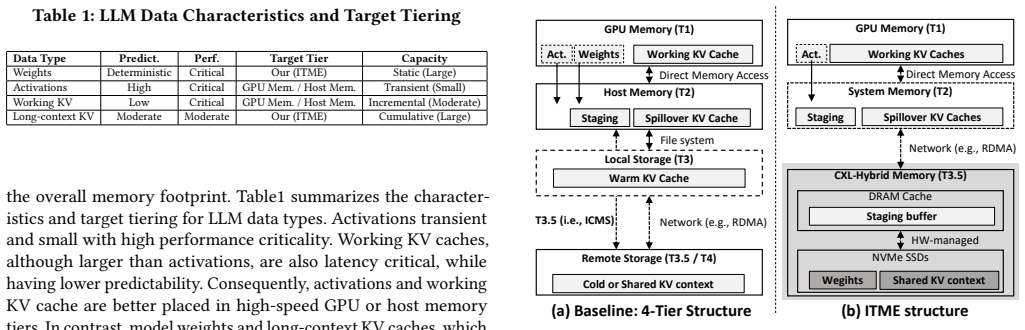
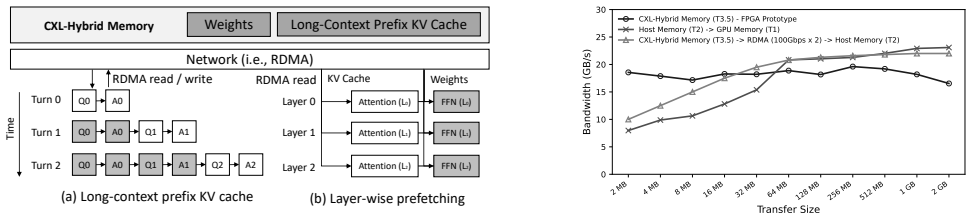
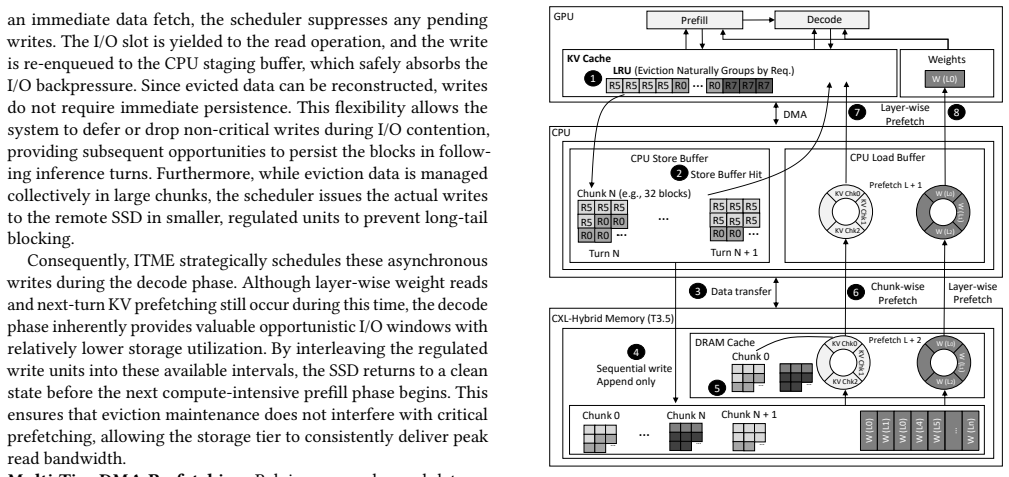
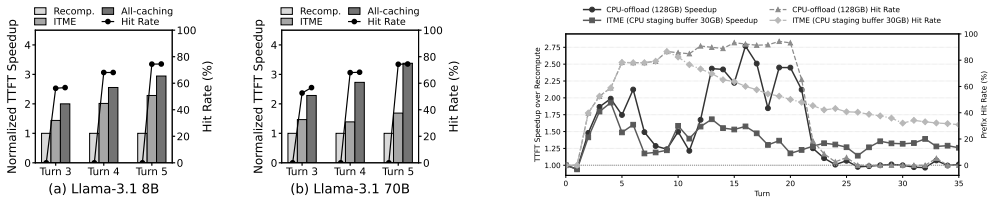
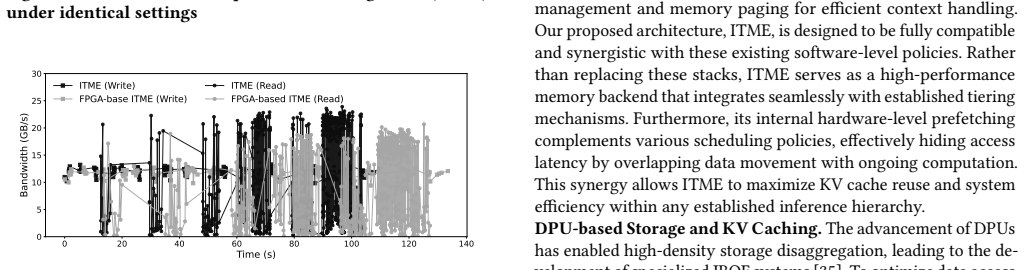
ITME leverages a CXL-hybrid memory to present a massive, TB-scale byte-addressable remote memory expansion that enables cost-efficient scaling and simplifies the software stack through direct byte-addressability. The key insight is that the deterministic access patterns of voluminous model weights and prefix caches enable the system to proactively manage data movement across the memory-storage hierarchy. Validation with SK Hynix CMM and PCIe Gen5 NVMe SSDs plus an FPGA prototype shows ITME enhances conventional CPU-offloading by accommodating large KV cache footprints beyond host memory limits, achieving up to a 35.7% throughput improvement.
What carries the argument
CXL-hybrid memory tier that supplies byte-addressable remote expansion and supports proactive data movement driven by deterministic access patterns.
If this is right
- Shared context layers can scale to TB-scale states across distributed clusters without heavy DPU software tuning.
- Direct byte-addressability reduces the need for specialized NVMe-oF target optimizations.
- Production hardware combinations like CMM and Gen5 SSDs become viable for cost-efficient expansion.
- FPGA prototypes confirm the architecture works at the hardware level for inference workloads.
Where Pith is reading between the lines
- The same tiered expansion could apply to other data-heavy serving systems that exhibit regular access sequences.
- Combining ITME with existing host memory managers might create hybrid local-remote policies that further cut latency.
- Wider adoption could shift cluster design away from pure flash offload toward memory-centric disaggregation for inference.
- Testing with varying context lengths would reveal how the proactive movement scales when KV cache sizes change dynamically.
Load-bearing premise
The access patterns of model weights and prefix caches are deterministic enough for the system to manage data movement proactively across tiers.
What would settle it
Running the same LLM inference workload with deliberately randomized KV cache accesses and measuring whether throughput still improves or instead drops below the CPU-offloading baseline.
Figures




read the original abstract
The rapid shift toward agentic and long-context workloads in Large Language Models (LLMs) is pushing the industry beyond the capacity of individual servers toward disaggregated shared storage to handle TB-scale context states. This movement has led to the emergence of specialized shared context layers designed to externalize and share cumulative inference states across distributed clusters. While offloading to a data processing unit (DPU) within just-a-bunch-of-flash (JBOF) architectures accelerates NVMe-over-fabrics (NVMe-oF) target processing, the need for sophisticated software-level optimization and cost-efficiency burdens remain significant. Consequently, the ideal architecture for scaling this shared context infrastructure is still an active area of exploration. In this paper, we propose ITME (Inference Tiered Memory Expansion), which leverages a CXL-hybrid memory to present a massive, TB-scale byte-addressable remote memory expansion. This approach enables cost-efficient scaling and simplifies the software stack through direct byte-addressability, effectively addressing the challenges of shared context infrastructure. Our key insight is that the deterministic access patterns of voluminous model weights and prefix caches enable the system to proactively manage data movement across the memory-storage hierarchy. We validate ITME by evaluating its performance potential with production-grade SK Hynix CMM and PCIe Gen5 NVMe SSDs, while further demonstrating its functional feasibility through an FPGA-based hardware prototype. Overall, ITME enhances conventional CPU-offloading by providing additional remote memory expansion to accommodate large KV cache footprints beyond host memory limits, achieving up to a 35.7\% throughput improvement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ITME, a disaggregated architecture using CXL-hybrid memories (SK Hynix CMM + Gen5 NVMe) to provide TB-scale byte-addressable remote memory expansion for LLM inference. It targets large KV cache footprints beyond host DRAM limits by offloading from conventional CPU-based approaches, with the key insight that deterministic access patterns of model weights and prefix caches enable proactive tiered data movement. Functional feasibility is shown via an FPGA prototype, and hardware evaluation reports up to 35.7% throughput improvement.
Significance. If the performance results hold under detailed scrutiny, ITME could meaningfully advance cost-efficient scaling of shared context layers for long-context and agentic LLM workloads by simplifying the software stack through direct byte-addressability. The combination of production-grade hardware components and an FPGA prototype provides a concrete feasibility demonstration that strengthens the architecture's practicality.
major comments (2)
- [Evaluation section] Evaluation section (hardware results): the central claim of a 35.7% throughput improvement is load-bearing for the paper's contribution, yet the abstract (and by extension the reported evaluation) supplies no baselines, workload details, error bars, or exclusion criteria, preventing verification of the gain's robustness or attribution to the CXL-hybrid tiering.
- [§3] §3 (key insight and architecture): the claim that deterministic access patterns of voluminous model weights and prefix caches enable proactive data movement across the memory-storage hierarchy is presented as the enabling insight, but lacks concrete quantification or prototype measurements showing how this determinism is exploited versus reactive baselines.
minor comments (2)
- Clarify the exact CXL protocol version, coherence model, and latency/bandwidth assumptions used in the FPGA prototype versus the SK Hynix CMM evaluation.
- Add a table or figure comparing ITME against at least one standard CPU-offload baseline and one pure NVMe-oF configuration to make the 35.7% figure interpretable.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, agreeing where revisions are warranted to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section (hardware results): the central claim of a 35.7% throughput improvement is load-bearing for the paper's contribution, yet the abstract (and by extension the reported evaluation) supplies no baselines, workload details, error bars, or exclusion criteria, preventing verification of the gain's robustness or attribution to the CXL-hybrid tiering.
Authors: We agree that the abstract is too concise to include these elements and that the evaluation section would benefit from greater explicitness. The full manuscript does compare against conventional CPU-offloading as the primary baseline and describes the workloads, but we will revise both the abstract and §Evaluation to add error bars, explicit workload parameters, exclusion criteria, and clearer attribution of gains to the tiered CXL-hybrid mechanism. revision: yes
-
Referee: [§3] §3 (key insight and architecture): the claim that deterministic access patterns of voluminous model weights and prefix caches enable proactive data movement across the memory-storage hierarchy is presented as the enabling insight, but lacks concrete quantification or prototype measurements showing how this determinism is exploited versus reactive baselines.
Authors: The architecture in §3 relies on the deterministic patterns to drive proactive movement, and the FPGA prototype validates overall functionality. However, we acknowledge that direct quantitative comparison to reactive baselines is not currently reported. We will add prototype measurements contrasting proactive versus reactive policies to quantify the benefit of exploiting determinism. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a systems/architecture proposal for ITME, a CXL-hybrid memory expansion for LLM KV cache offloading. Its central claims rest on a hardware prototype (SK Hynix CMM + Gen5 NVMe + FPGA) and measured throughput gains rather than any mathematical derivation chain. The abstract and description contain no equations, fitted parameters, self-definitional constructs, uniqueness theorems, or self-citations that could reduce a prediction to its inputs by construction. The key insight about deterministic access patterns is presented as an empirical observation enabling the design, not as a fitted or renamed result. The derivation is therefore self-contained against external hardware benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aguilera, Emmanuel Amaro, Nadav Amit, Erika Hunhoff, Anil Yelam, and Greg Zellweger
Marcos K. Aguilera, Emmanuel Amaro, Nadav Amit, Erika Hunhoff, Anil Yelam, and Greg Zellweger. 2023. Memory Disaggregation: Why Now and What Are the Challenges.ACM SIGOPS Operating Systems Review57, 1 (2023), 38–46. https://doi.org/10.1145/3606557.3606563
-
[2]
Del Mundo, Mohammad Rastegari, and Mehrdad Farajtabar
Keivan Alizadeh, Iman Mirzadeh, Dmitry Belenko, Karen Khatamifard, Minsik Cho, Carlo C. Del Mundo, Mohammad Rastegari, and Mehrdad Farajtabar. 2023. LLM in a Flash: Efficient Large Language Model Inference with Limited Memory. arXiv preprint arXiv:2312.11514(2023)
arXiv 2023
-
[3]
Altera. 2026. Agilex 7 FPGA and SoC FPGA I-Series Overview. https://www. altera.com/products/fpga/agilex/7/i-series
2026
-
[4]
Reza Yazdani Aminabadi, Samyam Rajbhandari, Minjia Zhang, Ammar Ahmad Awan, Cheng Li, Du Li, Elton Zheng, Jeff Rasley, Shaden Smith, Olatunji Ruwase, and Yuxiong He. 2022. DeepSpeed-Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale. InProceedings of the International Conference for High Performance Computing, Networking,...
2022
-
[5]
Mustafa Rafique, and Sudharshan Vazhkudai
Moiz Arif, Kevin Assogba, M. Mustafa Rafique, and Sudharshan Vazhkudai. 2022. Exploiting CXL-based Memory for Distributed Deep Learning. InProceedings of the 51st International Conference on Parallel Processing. ACM, 19:1–19:11
2022
-
[6]
Yihua Cheng, Yuhan Liu, Jiayi Yao, Yuwei An, Xiaokun Chen, Shaoting Feng, Yuyang Huang, Samuel Shen, Kuntai Du, and Junchen Jiang. 2025. LMCache: An Efficient KV Cache Layer for Enterprise-Scale LLM Inference.arXiv preprint arXiv:2510.09665(2025)
arXiv 2025
-
[7]
Pouya Esmaili-Dokht, Francesco Sgherzi, Valéria Soldera Girelli, Isaac Boixaderas, Mariana Carmin, Alireza Monemi, Adrià Armejach, Estanislao Mercadal, German Llort, Petar Radojkovic, Miquel Moretó, Judit Giménez, Xavier Martorell, Eduard Ayguadé, Jesús Labarta, Emanuele Confalonieri, Rishabh Dubey, and Jason Ad- lard. 2024. A Mess of Memory System Benchm...
-
[8]
Yehonatan Fridman, Suprasad Mutalik Desai, Navneet Singh, Thomas Willhalm, and Gal Oren. 2023. CXL Memory as Persistent Memory for Disaggregated HPC: A Practical Approach. InProceedings of the SC ’23 Workshops of The International Conference on High Performance Computing, Network, Storage, and Analysis. ACM, 983–994. https://doi.org/10.1145/3624062.3624175
-
[9]
Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou Yu, and Pengfei Zuo. 2024. Cost-Efficient Large Language Model Serving for Multi-turn Conversations with CachedAttention. InarXiv preprint arXiv:2403.19708v3
arXiv 2024
-
[10]
Goumas, Zeshan Chishti, and Nandita Vijaykumar
Christina Giannoula, Kailong Huang, Jonathan Tang, Nectarios Koziris, Geor- gios I. Goumas, Zeshan Chishti, and Nandita Vijaykumar. 2023. DaeMon: Archi- tectural Support for Efficient Data Movement in Fully Disaggregated Systems. Proceedings of the ACM on Measurement and Analysis of Computing Systems7, 1 (2023), 16:1–16:36. https://doi.org/10.1145/3579445
-
[11]
Donghyun Gouk, Miryeong Kwon, Hanyeoreum Bae, Sangwon Lee, and My- oungsoo Jung. 2023. Memory Pooling With CXL.IEEE Micro43, 2 (2023), 48–57. https://doi.org/10.1109/MM.2023.3237491
-
[12]
Donghyun Gouk, Sangwon Lee, Miryeong Kwon, and Myoungsoo Jung. 2022. Direct Access, High-Performance Memory Disaggregation with DirectCXL. In 2022 USENIX Annual Technical Conference (USENIX ATC 22). USENIX Association, Carlsbad, CA, 287–294. https://www.usenix.org/conference/atc22/presentation/ gouk
2022
-
[13]
Z. Guo, H. Zhang, C. Zhao, Y. Bai, M. Swift, and M. Liu. 2023. LEED: A Low- Power, Fast Persistent Key-Value Store on SmartNIC JBOFs. InProceedings of the ACM SIGCOMM 2023 Conference. 1012–1027
2023
-
[14]
Xiao-Yu Hu, Evangelos Eleftheriou, Robert Haas, Ilias Iliadis, and Roman Pletka
-
[15]
InProceed- ings of SYSTOR 2009: The Israeli Experimental Systems Conference (SYSTOR ’09)
Write Amplification Analysis in Flash-Based Solid State Drives. InProceed- ings of SYSTOR 2009: The Israeli Experimental Systems Conference (SYSTOR ’09). ACM, 10:1–10:9. https://doi.org/10.1145/1534530.1534544
-
[16]
Intel. 2016. Introduction to the Storage Performance Development Kit (SPDK). https://www.intel.com/content/www/us/en/developer/articles/tool/ introduction-to-the-storage-performance-development-kit-spdk.html
2016
-
[17]
Juhyun Jang, Donghyun Gouk, Miryeong Kwon, Sangwon Han, Myoungsoo Kim, and Myoungsoo Jung. 2023. CXL-ANNS: Software-Hardware Collaborative Memory Disaggregation and Computation. InProceedings of the 2023 USENIX Annual Technical Conference (ATC)
2023
-
[18]
Shine Kim, Jonghyun Bae, Hakbeom Jang, Wenjing Jin, Jeonghun Gong, Se- ungyeon Lee, Tae Jun Ham, and Jae W. Lee. 2019. Practical Erase Suspen- sion for Modern Low-latency SSDs. In2019 USENIX Annual Technical Con- ference (USENIX ATC 19). USENIX Association, Renton, WA, 813–820. https: //www.usenix.org/conference/atc19/presentation/kim-shine
2019
-
[19]
KIOXIA. 2024. KIOXIA CD8P-R NVMe Solid-State Drive. Product specification
2024
-
[20]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. arXiv preprint arXiv:2309.06180(2023)
Pith/arXiv arXiv 2023
-
[21]
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. 2024. InfiniGen: Efficient Generative Inference of Large Language Models with Dynamic KV Cache Management. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association, Santa Clara, CA, 155–172. https://www.usenix.org/conference/osdi24/presentation/lee
2024
-
[22]
Hasan Al Maruf and Mosharaf Chowdhury. 2023. TPP: Transparent Page Place- ment for CXL-Enabled Tiered-Memory. InProceedings of the 28th ACM Inter- national Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS)
2023
-
[23]
J. Min, M. Liu, T. Chugh, C. Zhao, A. Wei, I. H. Doh, and A. Krishnamurthy. 2021. Gimbal: Enabling Multi-Tenant Storage Disaggregation on SmartNIC JBOFs. In Proceedings of the 2021 ACM SIGCOMM 2021 Conference. 106–122
2021
-
[24]
Jidong Min, Ming Liu, Tushar Chugh, Chris Zhao, Andrew Wel, In Hwan Doh, and Arvind Krishnamurthy. 2021. Gimbal: Enabling Multi-tenant Storage Disag- gregation on SmartNIC JBOFs. InProceedings of the 2021 ACM SIGCOMM 2021 Conference. 106–122
2021
-
[25]
NVIDIA. 2021. NVIDIA BlueField Networking Platform. https://www.nvidia. com/en-us/networking/products/data-processing-unit/. Accessed: 2026-03-30
2021
-
[26]
NVIDIA. 2024. Chelsio T7 DPU Furthers Expansive Ethernet Storage Networking, Empowering Open, ROI-Enhanced Enterprise Storage Platforms. https://www. chelsio.com/wp-content/uploads/resources/pr-chelsio-t7-jbof.pdf. Accessed: 2026-03-30
2024
-
[27]
NVIDIA. 2026. CUDA Programming Guide: Page-Locked Host Memory. https://docs.nvidia.com/cuda/cuda-programming-guide/02- basics/understanding-memory.html. CUDA Programming Guide v13.2, Section 2.4.3, accessed 2026-04-06
2026
-
[28]
NVIDIA. 2026. Introducing NVIDIA BlueField-4-Powered CMX Context Memory Storage Platform for the Next Frontier of AI.NVIDIA Technical Blog(2026). https://developer.nvidia.com/blog/introducing-nvidia-bluefield-4-powered- inference-context-memory-storage-platform-for-the-next-frontier-of-ai/
2026
-
[29]
NVM Express. 2017. Accelerating NVMe™over Fabrics with Hardware Of- floads at 100Gb/s and Beyond. https://nvmexpress.org/wp-content/uploads/ Accelerating-NVMe-over-Fabrics-with-Hardware-Offloads.pdf
2017
-
[30]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. 2025. Mooncake: Trading More Storage for Less Computation — A KVCache-Centric Architecture for Serving LLM Chatbots. InProceedings of the USENIX Conference on File and Storage Technologies
2025
-
[31]
Jiacheng Shen, Pengfei Zuo, Xuchuan Luo, Yuxuan Su, Jiazhen Gu, Hao Feng, Yangzhou Zhou, and Michael R. Lyu. 2023. Ditto: An elastic and adaptive memory- disaggregated caching system. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP). 675–691
2023
-
[32]
Fu, Zhiqiang Xie, Beidi Chen, Clark Barrett, Joseph E
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Daniel Y. Fu, Zhiqiang Xie, Beidi Chen, Clark Barrett, Joseph E. Gonzalez, and Ion Stoica
-
[33]
InProceedings of the 40th International Conference on Machine Learning (ICML)
FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU. InProceedings of the 40th International Conference on Machine Learning (ICML)
-
[34]
SK hynix. 2024. SK hynix CXL Memory Module. Product documentation
2024
-
[35]
Yixin Song, Zeyu Mi, Haotong Xie, and Haibo Chen. 2023. PowerInfer: Fast Large Language Model Serving with a Consumer-Grade GPU.arXiv preprint arXiv:2312.12456(2023)
arXiv 2023
-
[36]
Xun Sun, Mingxing Zhang, Yingdi Shan, Kang Chen, Jinlei Jiang, and Yongwei Wu. 2025. Scalio: Scaling up DPU-based JBOF Key-value Store with NVMe-oF Target Offload. In19th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’25). USENIX Association
2025
-
[37]
Super Micro Computer, Inc. 2024. Petascale JBOF All-Flash Array for AI Data Pipeline Acceleration. https://www.supermicro.org.cn/en/products/jbof
2024
-
[38]
Supermicro. 2024. Petascale JBOF All-Flash Array for AI Data Pipeline Accelera- tion. https://www.supermicro.org.cn/en/products/jbof. Accessed: 2026-03-30
2024
-
[39]
TechPowerUp. 2024. SK Hynix Platinum P51 2 TB Specs. https://www. techpowerup.com/ssd-specs/sk-hynix-platinum-p51-2-tb.d1968. Accessed: 2026-04-06
2024
-
[40]
Shin-Yeh Tsai, Yizhou Shan, and Yiying Zhang. 2020. Disaggregating Persistent Memory and Controlling Them Remotely: An Exploration of Passive Disaggre- gated Key-Value Stores. In2020 USENIX Annual Technical Conference (USENIX ATC 20). USENIX Association, 33–48. https://www.usenix.org/conference/atc20/ presentation/tsai
2020
-
[41]
Xi Wang, Jie Liu, Jianbo Wu, Shuangyan Yang, Jie Ren, Bhanu Shankar, and Dong Li. 2024. Exploring and Evaluating Real-World CXL: Use Cases and System Adoption.arXiv preprint arXiv:2405.14209(2024)
arXiv 2024
-
[42]
Jingsen Xu, Yu Qiu, Yuan Chen, Yang Wang, Wei Lin, Yi Lin, Shuai Zhao, Yan Liu, Yu Wang, and Wenguang Chen. 2024. Performance Characterization of SmartNIC NVMe-over-Fabrics Target Offloading. InProceedings of the 17th ACM International Systems and Storage Conference. 14–24
2024
-
[43]
Lingfan Yu, Jinkun Lin, and Jinyang Li. 2023. Stateful Large Language Model Serving with Pensieve.arXiv preprint arXiv:2312.05516(2023)
arXiv 2023
-
[44]
Jianping Zeng, Shuyi Pei, Da Zhang, Yuchen Zhou, Amir Beygi, Xuebin Yao, Ramdas Kachare, Tong Zhang, Zongwang Li, Marie Nguyen, Rekha Pitchumani, 12 Yang Soek Ki, and Changhee Jung. 2025. Performance Characterizations and Usage Guidelines of Samsung CXL Memory Module Hybrid Prototype.arXiv preprint arXiv:2503.22017(2025)
arXiv 2025
-
[45]
L. Zhan, K. Lu, Y. Xiong, J. Wan, and Z. Yang. 2024. TrickleKV: A High- Performance Key-Value Store on Disaggregated Storage with Low Network Traffic.IEEE Access(2024)
2024
-
[46]
Ming Zhang, Yu Hua, Pengfei Zuo, and Limin Liu. 2022. FORD: Fast one-sided RDMA-based distributed transactions for disaggregated persistent memory. In Proceedings of the 20th USENIX Conference on File and Storage Technologies (FAST 22). 51–68
2022
-
[47]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving. arXiv:2401.09670 [cs.DC]
arXiv 2024
-
[48]
Yuchen Zhou, Jianping Zeng, and Changhee Jung. 2024. LightWSP: Whole- System Persistence on the Cheap. In2024 57th IEEE/ACM International Sym- posium on Microarchitecture (MICRO). IEEE, 215–230. https://doi.org/10.1109/ MICRO61859.2024.00025 13
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.