Revisiting the ABCs of Working with AI: A Replication with Radiologists
Pith reviewed 2026-06-27 07:25 UTC · model grok-4.3
The pith
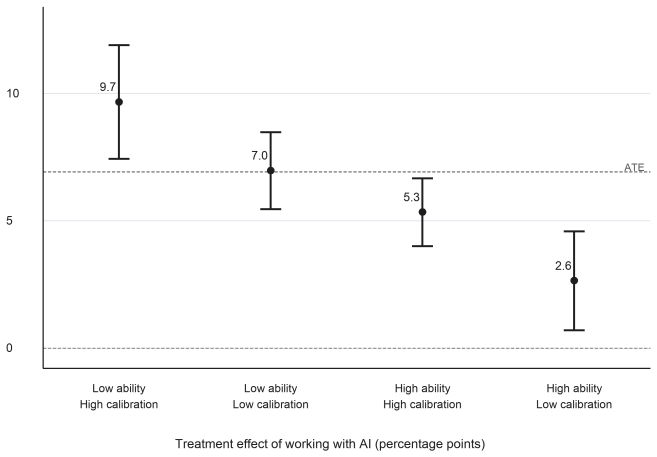
Radiologist chest X-ray data replicates that lower baseline ability and higher belief calibration predict larger gains from AI assistance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
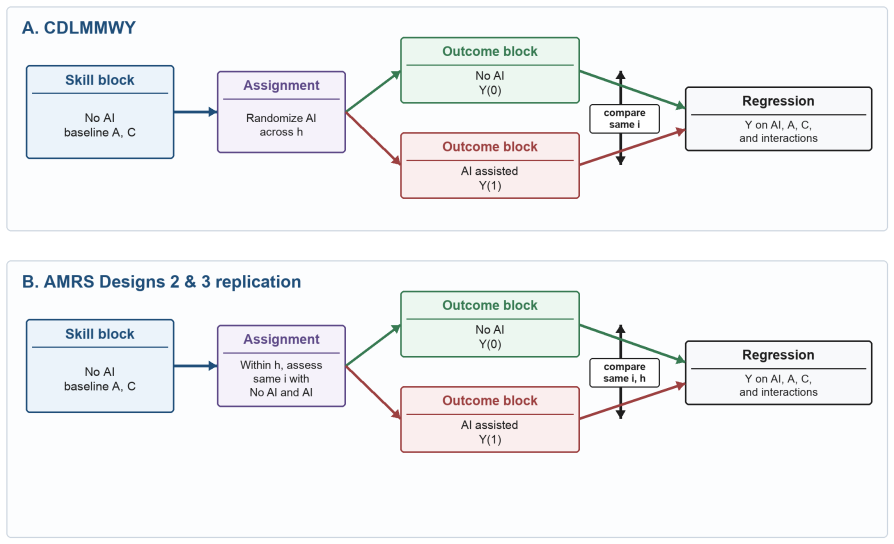
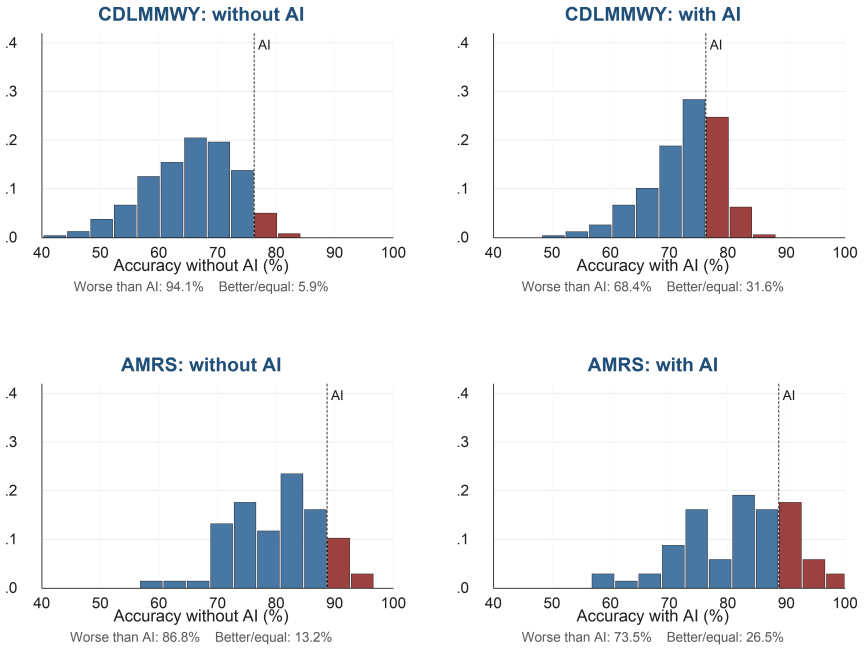
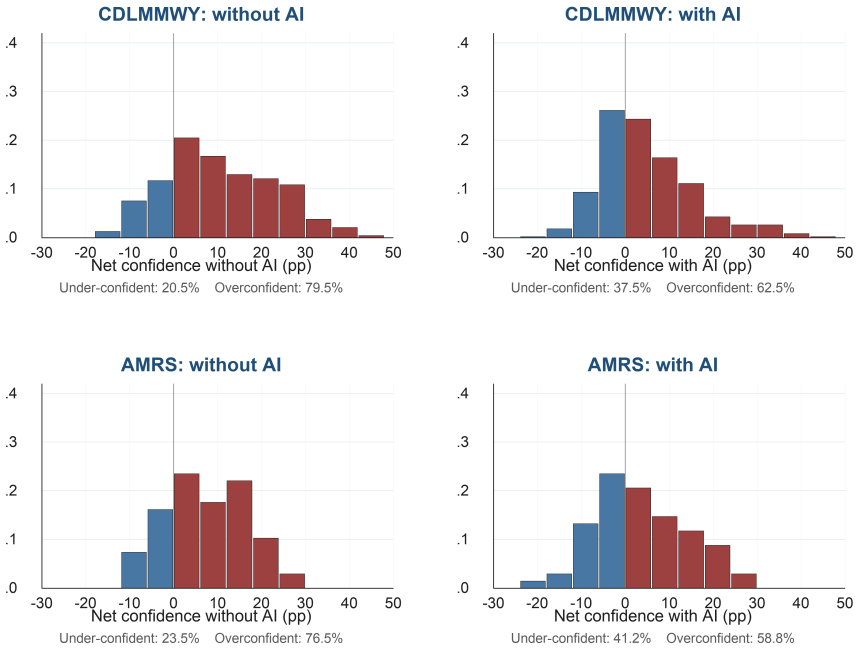
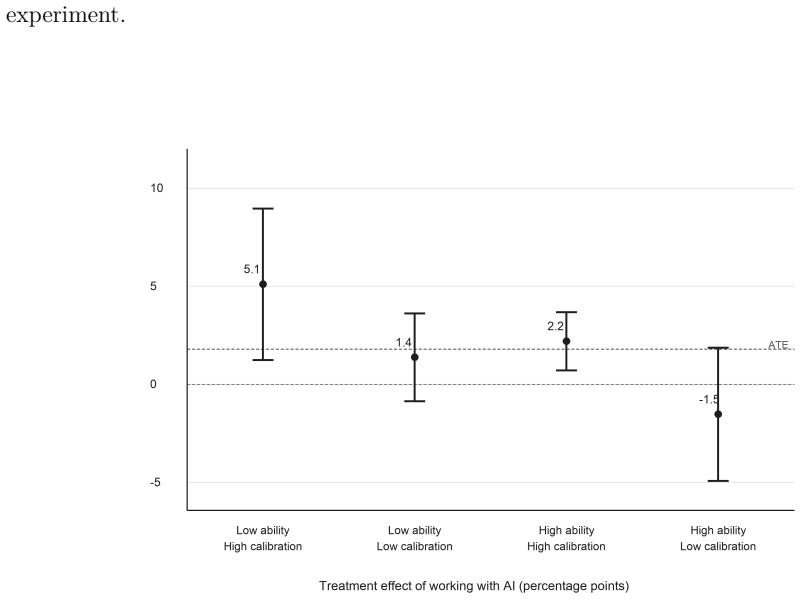
Using the public Collab-CXR repository and its repeated-case designs, the analysis reproduces the core result that lower baseline ability and higher calibration predict larger incremental value from AI, thereby supporting the external validity of the original Caplin et al. findings in a setting with state-of-the-art machine-learning predictions for chest X-rays.
What carries the argument
Replication of ability and belief-calibration measures drawn from repeated-case radiologist assessments in the Collab-CXR data, used to predict incremental value of AI assistance.
If this is right
- AI assistance produces larger productivity increments for experts whose unaided performance is lower.
- Experts whose probability judgments are better calibrated extract more value from the same AI tool.
- The pattern holds when the task is professional chest X-ray interpretation with contemporary machine-learning predictions.
- Individual-level traits can be used to forecast heterogeneous returns to AI deployment in expert domains.
Where Pith is reading between the lines
- If the same ability and calibration measures predict AI value in other expert fields, organizations could screen or train on those traits before rolling out assistance tools.
- The replication leaves open whether calibration can be improved through feedback, which would then raise the returns to AI for a given expert.
- Because the data come from a repeated-case design, the result may be sensitive to how closely the repeated cases match the distribution of real clinical variation.
Load-bearing premise
The radiologist assessments collected in the repeated-case designs of the Collab-CXR data allow faithful reproduction of the ability and belief calibration measures used in the original study.
What would settle it
Re-running the same regression specifications on the Collab-CXR repeated-case observations and finding no statistically detectable relationship between lower baseline ability or higher calibration and larger AI gains would falsify the replication claim.
Figures
read the original abstract
Artificial intelligence (AI) systems increasingly assist human experts, but the consequences of AI assistance on productivity can be heterogeneous. Caplin, Deming, S. Li, Martin, Marx, Weidmann, and Ye (2025b) provide evidence that two characteristics, ability and belief calibration, help to determine the returns to AI assistance. This note shows that their results replicate to a setting where professional radiologists analyze chest X-rays with access to state-of-the-art machine learning predictions. I leverage the public Collab-CXR data repository described by Moehring, Kutwal, Huang, Banerjee, Jacobi, Eber, Mendoza, Chung, Dayan, Gupta, Bui, Truong, Pareek, Langlotz, Lungren, Agarwal, Rajpurkar, and Salz (2025) and first analyzed for human-AI collaboration by Agarwal, Moehring, Rajpurkar, and Salz (2023). To faithfully reproduce the analysis in Caplin, Deming, S. Li, Martin, Marx, Weidmann, and Ye (2025b), I use the radiologist assessments from the repeated-case designs, which include 68 radiologists and 11,420 paired radiologist-patient-pathology observations. The results of this replication support the external validity of their core findings: lower baseline ability and higher calibration predict larger incremental value from AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper replicates Caplin et al. (2025b) using the public Collab-CXR dataset of 68 radiologists and 11,420 paired observations from repeated-case designs. It claims that lower baseline ability and higher belief calibration predict larger incremental value from AI assistance, thereby supporting the external validity of the original findings in a professional radiology setting with state-of-the-art ML predictions.
Significance. If the replication faithfully reproduces the original ability and calibration measures, the result strengthens the generalizability of the ability-calibration framework to high-stakes expert domains with real productivity consequences. The use of a large public dataset with repeated cases is a clear strength for reproducibility and external validity testing.
major comments (1)
- [Abstract] The central claim that the replication 'faithfully reproduce[s]' the Caplin et al. (2025b) results rests on the assumption that the repeated-case designs in Collab-CXR produce ability (baseline accuracy) and calibration (belief-performance alignment) variables constructed identically to the original study, including any normalization or scoring of beliefs and incremental-value regressions. The provided abstract states this but supplies no equations, variable definitions, or comparison table confirming the mapping.
minor comments (1)
- The manuscript would benefit from an explicit appendix or table listing the exact variable constructions (e.g., how baseline accuracy is scored, how beliefs are elicited and normalized) side-by-side with the corresponding definitions from Caplin et al. (2025b).
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for highlighting the need for greater transparency in documenting the replication protocol. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] The central claim that the replication 'faithfully reproduce[s]' the Caplin et al. (2025b) results rests on the assumption that the repeated-case designs in Collab-CXR produce ability (baseline accuracy) and calibration (belief-performance alignment) variables constructed identically to the original study, including any normalization or scoring of beliefs and incremental-value regressions. The provided abstract states this but supplies no equations, variable definitions, or comparison table confirming the mapping.
Authors: We agree that the abstract would be strengthened by explicit documentation of the variable mappings. The full manuscript already details the replication protocol, including use of the repeated-case design to construct baseline accuracy (ability) and belief-performance alignment (calibration) exactly as specified in Caplin et al. (2025b), along with the same incremental-value regressions. To make this transparent at the abstract level, we will revise the abstract to include brief definitions of these measures and the regression specifications. We will also add a concise comparison table (in the main text or appendix) that lists the original variable constructions alongside their Collab-CXR implementations, confirming identical normalization, scoring, and regression forms. This revision directly addresses the concern while preserving the note's brevity. revision: yes
Circularity Check
Independent replication on external public dataset with no self-referential fitting or definitional circularity
full rationale
The paper is a replication study that applies the analysis framework from Caplin et al. (2025b) to a new, publicly available Collab-CXR dataset of radiologist assessments. It explicitly states it uses repeated-case designs to reproduce the original ability and calibration measures on 68 radiologists and 11,420 observations, then checks whether lower baseline ability and higher calibration predict larger AI incremental value. No equations, variable constructions, or fitted parameters from the original study are redefined or reused as predictions within this paper; the core claim is external validity on independent data. The single self-citation to the original work (which shares an author) is not load-bearing for any derivation here, as the replication itself provides the test. No self-definitional steps, fitted inputs renamed as predictions, or ansatzes smuggled via citation appear in the provided text. This is a standard, self-contained replication.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Radiologist assessments in the repeated-case designs are comparable to the original study's measures of ability and belief calibration.
Reference graph
Works this paper leans on
-
[1]
and Heidari, Hoda and Jalali, Mohammad S
Gonzalez, Cleotilde and Donahue, Kate and Goldstein, Daniel G. and Heidari, Hoda and Jalali, Mohammad S. and Schelble, Beau and Singh, Aarti and Woolley, Anita Williams , title =. PNAS Nexus , volume =. 2026 , doi =
2026
-
[2]
Frontiers in Robotics and AI , volume =
Kargarnovin, Shaida and Hernandez, Christopher Ivan and Reiners, Dirk and Cruz-Neira, Carolina and Bochenek, Grace and Karwowski, Waldemar , title =. Frontiers in Robotics and AI , volume =. 2026 , doi =
2026
-
[3]
npj Artificial Intelligence , volume =
Liu, Peng and Zhang, Jiaxin and Chen, Shuaiqi and Chen, Shanguang , title =. npj Artificial Intelligence , volume =. 2025 , doi =
2025
-
[4]
npj Digital Medicine , volume =
Wekenborg, Magdalena Katharina and Gilbert, Stephen and Kather, Jakob Nikolas , title =. npj Digital Medicine , volume =. 2025 , doi =
2025
-
[5]
Harvard Data Science Review , volume =
Beck, Jacob and Eckman, Stephanie and Kern, Christoph and Kreuter, Frauke , title =. Harvard Data Science Review , volume =. 2026 , doi =
2026
-
[6]
Trust the AI, Doubt Yourself: The Effect of Urgency on Self-Confidence in Human-AI Interaction
Shajari, Baran and Liu, Xiaoran and Dagenais, Kyanna and David, Istvan , title =. arXiv preprint , year =. doi:10.48550/arXiv.2604.07535 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.07535
-
[7]
2022.Human-AI Teaming: State-of-the-Art and Research Needs
Human-AI Teaming: State-of-the-Art and Research Needs , year =. doi:10.17226/26355 , url =
-
[9]
2023 , doi =
Agarwal, Nikhil and Moehring, Alex and Rajpurkar, Pranav and Salz, Tobias , title =. 2023 , doi =
2023
-
[10]
National Bureau of Economic Research Working Paper , year =
Autor, David , title =. National Bureau of Economic Research Working Paper , year =
-
[11]
, title =
Brynjolfsson, Erik and Li, Danielle and Raymond, Lindsey R. , title =
-
[12]
Caplin, Andrew and Deming, David J. and Li, S. and Martin, Daniel and Marx, Philip and Weidmann, Ben and Ye, K. J. , title =. Management Science , year =. doi:10.1287/mnsc.2024.08994 , url =
-
[13]
and Li, S
Caplin, Andrew and Deming, David J. and Li, S. and Martin, Daniel and Marx, Philip and Weidmann, Ben and Ye, K. J. , title =. 2025 , doi =
2025
-
[14]
and Huang, R
Moehring, Alex and Kutwal, M. and Huang, R. and Banerjee, O. and Jacobi, A. and Eber, C. and Mendoza, D. and Chung, M. and Dayan, E. and Gupta, Y. and Bui, T. D. T. and Truong, S. Q. H. and Pareek, A. and Langlotz, C. P. and Lungren, M. P. and Agarwal, Nikhil and Rajpurkar, Pranav and Salz, Tobias , title =. Scientific Data , volume =. 2025 , doi =
2025
-
[15]
Science , volume =
Noy, Shakked and Zhang, Whitney , title =. Science , volume =. 2023 , publisher =
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.