High-Order Spectral Element Methods for Wave Propagation on ARM Multicore CPU with SME: Optimizations and Implications
Pith reviewed 2026-06-27 06:09 UTC · model grok-4.3
The pith
SME optimizations on ARM LX2 deliver 4-6× speedup for spectral element wave simulations and shift to higher polynomial orders.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
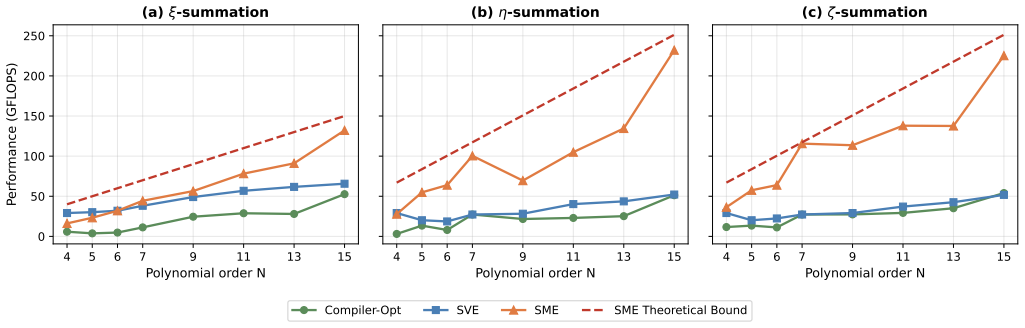
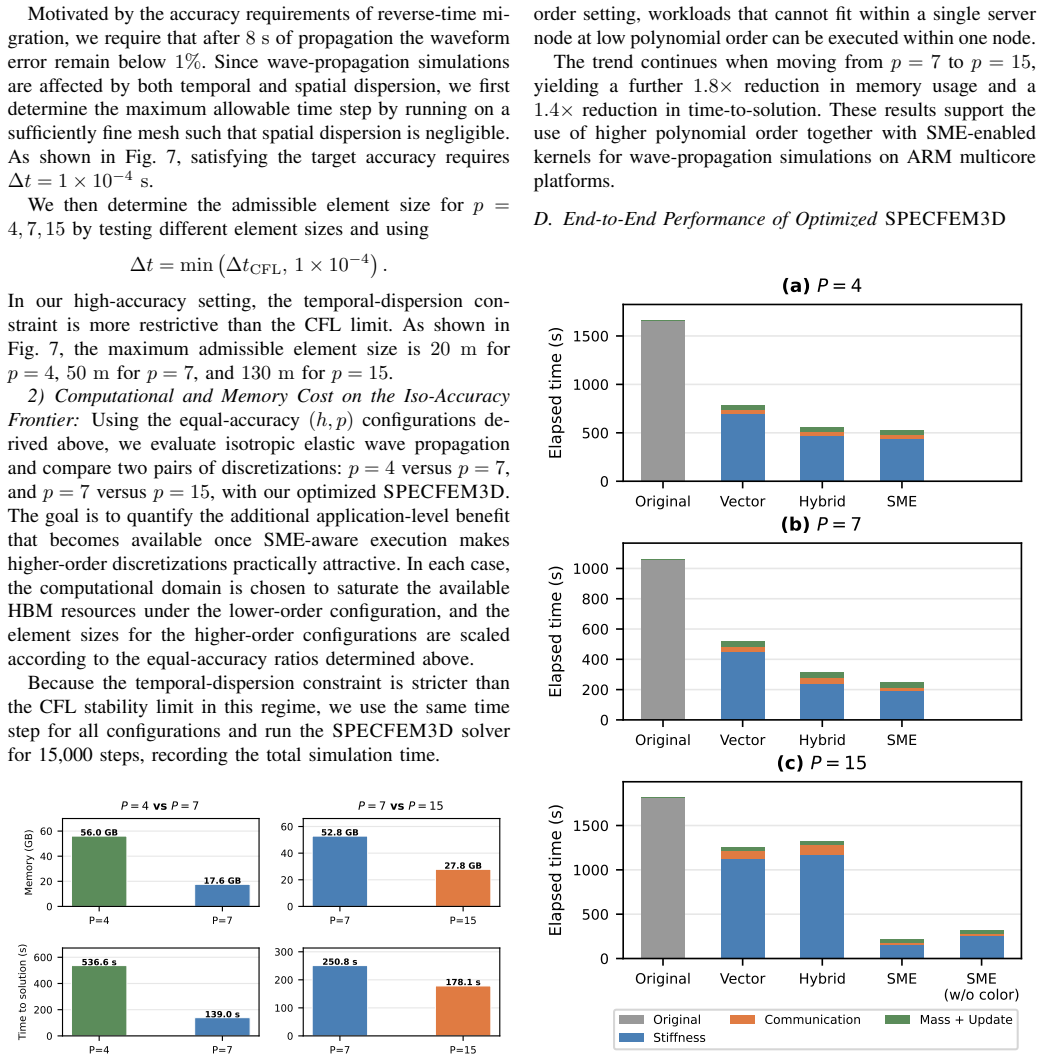
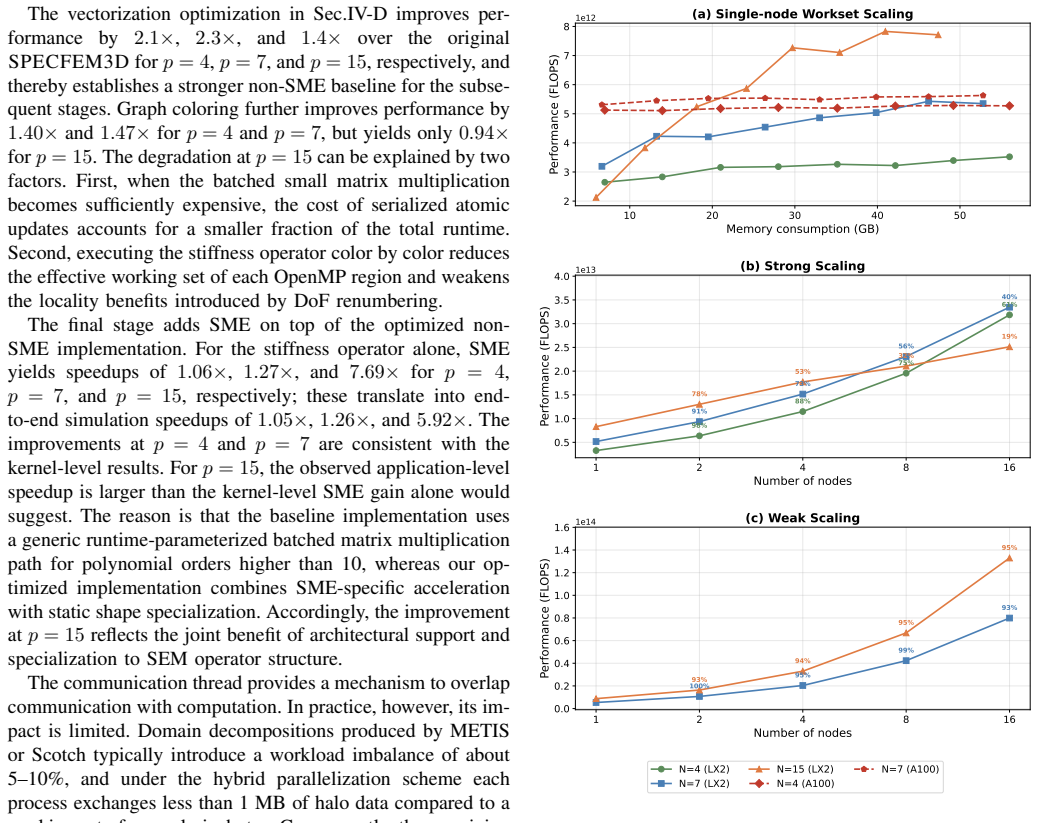
The optimized implementation improves full-application performance by 4--6× over the original code and delivers clear gains over optimized non-SME CPU baselines at fixed polynomial order. The results suggest that SME shifts the performance-favorable operating point toward higher polynomial orders along the dispersion-based iso-accuracy frontier, further reducing time-to-solution and working-set size.
What carries the argument
SME-aware batched small-matrix kernel for SEM tensor-product operators combined with dispersion-based iso-accuracy analysis of the (h,p) tradeoff
If this is right
- Full-application performance improves by 4-6× at fixed polynomial order compared to original code.
- Clear gains over optimized non-SME CPU baselines.
- SME shifts the performance-favorable operating point toward higher polynomial orders.
- Time-to-solution and working-set size are further reduced.
- The practical discretization tradeoff for SEM changes on modern ARM multicore platforms.
Where Pith is reading between the lines
- This approach might generalize to other matrix-extension equipped processors beyond the LX2.
- Similar optimizations could affect discretization choices in other high-order methods like discontinuous Galerkin.
- Hardware features like SME may require rethinking standard performance models for PDE solvers.
- Testing on larger problem sizes could confirm the memory-aware scheme's benefits.
Load-bearing premise
The batched SME-aware small-matrix kernel and memory-aware hybrid MPI+OpenMP scheme can be implemented correctly on the LX2 processor without introducing numerical errors or hidden performance penalties, and the dispersion-based iso-accuracy analysis accurately captures the accuracy behavior of the full application across the tested (h,p) combinations.
What would settle it
Running the optimized code on the LX2 processor and measuring less than 4× speedup at fixed order, or observing no shift in the iso-accuracy performance point toward higher p, would falsify the central performance claims.
Figures

read the original abstract
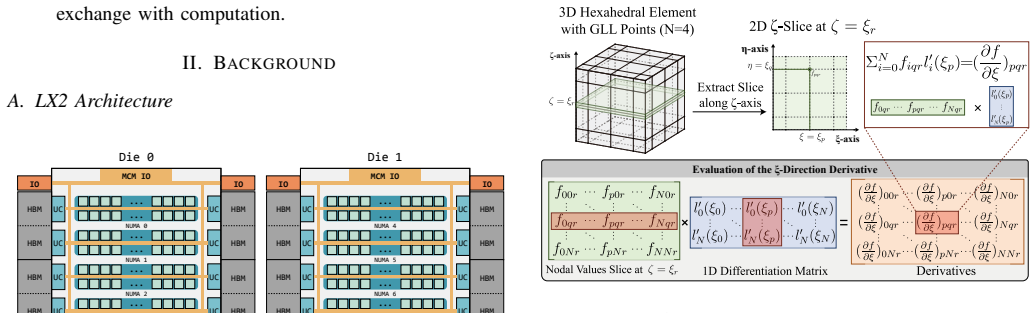
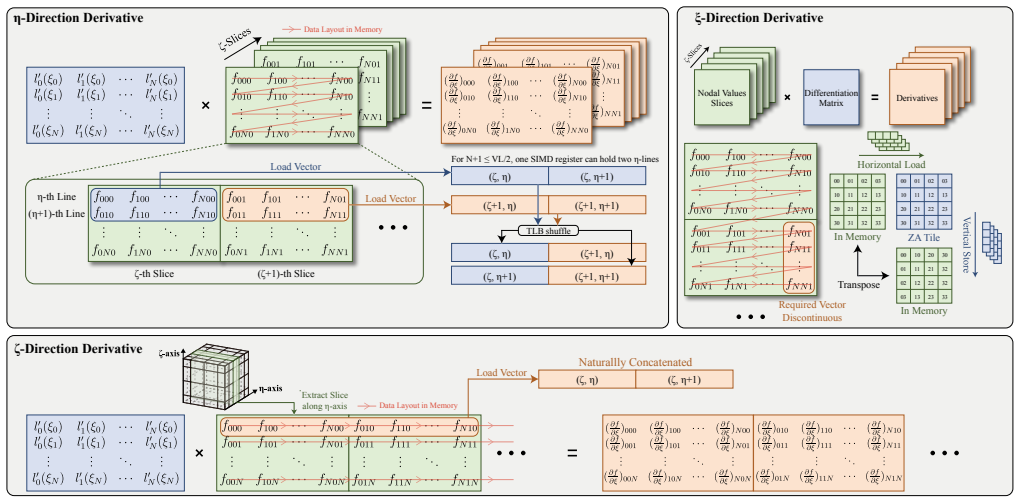
Wave propagation based on the spectral element method (SEM) is a representative HPC workload, but existing SEM implementations are not well matched to emerging ARM multicore CPUs with Scalable Matrix Extension (SME). We present an SME-enabled optimization of \textsc{SPECFEM3D} on the emerging LX2 processor that combines an SME-aware batched small-matrix kernel for SEM tensor-product operators, a memory-aware hybrid MPI+OpenMP execution scheme for limited-HBM systems, and a dispersion-based iso-accuracy study of the $(h,p)$ tradeoff. At fixed polynomial order, the optimized implementation improves full-application performance by 4--6$\times$ over the original code and delivers clear gains over optimized non-SME CPU baselines. Beyond these implementation-level gains, our results suggest that SME shifts the performance-favorable operating point toward higher polynomial orders along the dispersion-based iso-accuracy frontier, further reducing time-to-solution and working-set size. These results indicate that SME affects not only kernel efficiency, but also the practical discretization tradeoff for SEM on modern ARM multicore platforms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an SME-enabled optimization of SPECFEM3D on the LX2 ARM processor. It combines an SME-aware batched small-matrix kernel for SEM tensor-product operators, a memory-aware hybrid MPI+OpenMP execution scheme for limited-HBM systems, and a dispersion-based iso-accuracy analysis of the (h,p) tradeoff. The central empirical claims are that, at fixed polynomial order, the optimized code achieves 4--6× full-application speedup over the original implementation and outperforms optimized non-SME baselines, while SME shifts the performance-favorable operating point toward higher polynomial orders along the iso-accuracy frontier, reducing time-to-solution and working-set size.
Significance. If the reported speedups and discretization shift are substantiated, the work would be significant for the HPC community adapting high-order wave-propagation codes to emerging ARM platforms with SME. It would provide concrete evidence that a hardware matrix-extension feature can alter both kernel efficiency and the practical (h,p) operating point, which is a non-trivial implication for algorithm-hardware co-design in spectral methods.
major comments (3)
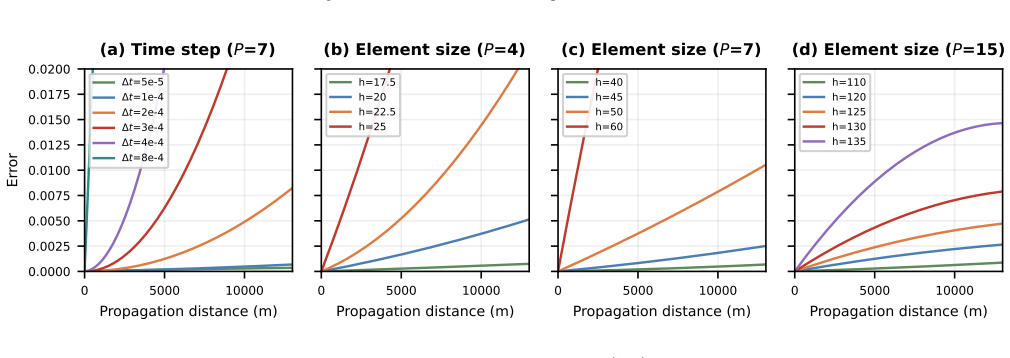
- [Abstract, §1] Abstract and §1: The claims of 4--6× full-application speedup and a shift in the performance-favorable (h,p) point are stated without any supporting measured data, error bars, verification steps, or implementation details. The central empirical assertions therefore rest on uninspectable assertions rather than reproducible evidence.
- [§3] §3 (kernel and execution scheme): The batched SME-aware small-matrix kernel and memory-aware hybrid MPI+OpenMP scheme are described at a high level, but no concrete implementation details, pseudocode, or correctness arguments are supplied to confirm that numerical errors or hidden performance penalties are avoided on the LX2 processor.
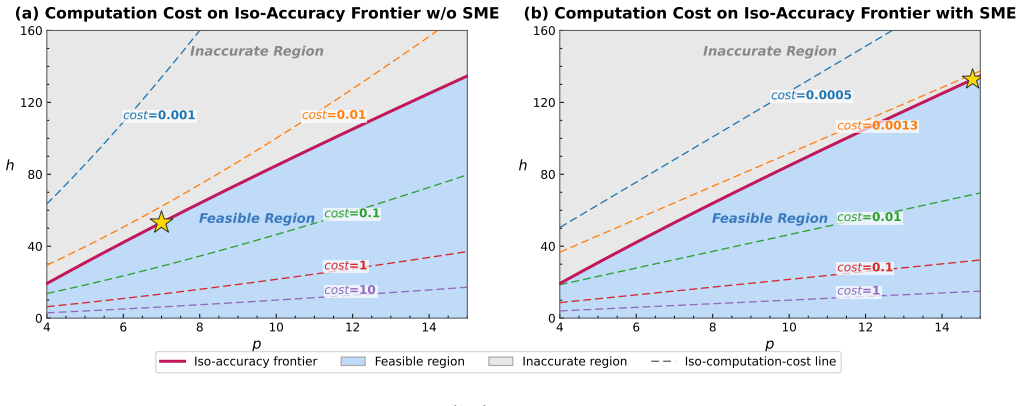
- [§4] §4 (iso-accuracy study): The dispersion-based iso-accuracy frontier analysis is presented as the basis for the claim that SME favors higher p; however, no tables or figures showing the actual dispersion errors, timing, or working-set sizes across the tested (h,p) combinations are referenced, leaving the shift claim unsupported.
minor comments (2)
- [§2] Notation for the tensor-product operators and the definition of the SME-aware kernel should be made consistent between the text and any pseudocode or equations.
- [§3] The manuscript should include a clear statement of the baseline compiler flags, OpenMP scheduling, and MPI configuration used for the non-SME comparisons.
Simulated Author's Rebuttal
We thank the referee for the thorough review and constructive suggestions. The comments highlight opportunities to strengthen the traceability of our empirical claims and to provide more explicit implementation details. We will revise the manuscript accordingly to address each point, adding references, pseudocode, and supporting tables/figures while preserving the original results and analysis. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract, §1] Abstract and §1: The claims of 4--6× full-application speedup and a shift in the performance-favorable (h,p) point are stated without any supporting measured data, error bars, verification steps, or implementation details. The central empirical assertions therefore rest on uninspectable assertions rather than reproducible evidence.
Authors: We agree that the abstract and §1 would be strengthened by explicit cross-references to the supporting data. The 4--6× speedups (with error bars from repeated runs) and baseline comparisons are reported in §5, while the (h,p) shift is quantified via dispersion analysis and timings in §4 and §5. In revision we will insert direct citations (e.g., “see Fig. 5 and Table 3”) into the abstract and §1, briefly note the verification procedure (comparison against reference SPECFEM3D output on LX2), and mention that all timings include standard deviation bars. These additions make the claims traceable without changing any numerical results. revision: yes
-
Referee: [§3] §3 (kernel and execution scheme): The batched SME-aware small-matrix kernel and memory-aware hybrid MPI+OpenMP scheme are described at a high level, but no concrete implementation details, pseudocode, or correctness arguments are supplied to confirm that numerical errors or hidden performance penalties are avoided on the LX2 processor.
Authors: Section 3 presents the algorithmic structure but lacks the requested low-level artifacts. In the revised manuscript we will add (i) pseudocode for the SME batched tensor-product kernel (new Algorithm 1) and the hybrid MPI+OpenMP scheduler (new Algorithm 2), (ii) a short correctness argument confirming that the SME path uses the same double-precision arithmetic as the original code and introduces no additional rounding, and (iii) a brief verification subsection showing bit-wise agreement with the reference implementation on LX2 for representative elements. These changes directly address the concern about hidden penalties. revision: yes
-
Referee: [§4] §4 (iso-accuracy study): The dispersion-based iso-accuracy frontier analysis is presented as the basis for the claim that SME favors higher p; however, no tables or figures showing the actual dispersion errors, timing, or working-set sizes across the tested (h,p) combinations are referenced, leaving the shift claim unsupported.
Authors: Section 4 derives the analytic dispersion relations and sketches the iso-accuracy frontier, but the concrete numerical evidence for the shift is distributed across later performance figures. To make the claim self-contained, we will insert a new compact table (Table 2) in §4 that tabulates, for each tested (h,p) pair on the frontier: dispersion error, measured wall-clock time per element, and working-set size. The table will be explicitly referenced in the text of §4, thereby directly supporting the statement that SME moves the favorable operating point to higher p. revision: yes
Circularity Check
No significant circularity; empirical performance and accuracy results stand independently
full rationale
The paper reports measured speedups (4-6x) from SME-aware kernels and hybrid MPI+OpenMP on LX2, plus an empirical dispersion-based iso-accuracy study of (h,p) tradeoffs. No derivation reduces a claimed prediction to a fitted input by construction, no self-citation is load-bearing for the central result, and no ansatz or uniqueness theorem is smuggled in. The claims are framed as outcomes of code changes and direct benchmarking rather than self-referential definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Three-dimensional curved grid finite-difference modelling for non-planar rupture dynamics,
Z. Zhang, W. Zhang, and X. Chen, “Three-dimensional curved grid finite-difference modelling for non-planar rupture dynamics,”Geophys- ical Journal International, vol. 199, no. 2, pp. 860–879, 2014
2014
-
[2]
Simulating the wenchuan earthquake with accurate surface topography on sunway taihulight,
B. Chen, H. Fu, Y . Wei, C. He, W. Zhang, Y . Li, W. Wan, W. Zhang, L. Gan, W. Zhang, Z. Zhang, G. Yang, and X. Chen, “Simulating the wenchuan earthquake with accurate surface topography on sunway taihulight,” ser. SC ’18. IEEE Press, 2018
2018
-
[3]
69.7-pflops extreme scale earthquake simulation with crossing multi-faults and topography on sunway,
W. Wan, L. Gan, W. Wang, Z. Yin, H. Tian, Z. Zhang, Y . Wang, M. Hua, X. Liu, S. Xiang, Z. He, Z. Wang, P. Gao, X. Duan, W. Liu, W. Xue, H. Fu, G. Yang, X. Chen, Z. Song, Y . Chen, X. Liu, and W. Zhang, “69.7-pflops extreme scale earthquake simulation with crossing multi-faults and topography on sunway,” inProceedings of the International Conference for H...
-
[4]
Reverse time migration: A prospect of seismic imaging methodology,
H.-W. Zhou, H. Hu, Z. Zou, Y . Wo, and O. Youn, “Reverse time migration: A prospect of seismic imaging methodology,”Earth- Science Reviews, vol. 179, pp. 207–227, 2018. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0012825217306256
2018
-
[5]
A practical implementation of 3d tti reverse time migration with multi-gpus,
C. Li, G. Liu, and Y . Li, “A practical implementation of 3d tti reverse time migration with multi-gpus,”Comput. Geosci., vol. 102, no. C, p. 68–78, May 2017. [Online]. Available: https://doi.org/10.1016/j.cageo.2017.02.011
-
[6]
D. Komatitsch and J. Tromp, “Introduction to the spectral element method for three-dimensional seismic wave propagation,”Geophysical Journal International, vol. 139, no. 3, pp. 806–822, 12 1999. [Online]. Available: https://doi.org/10.1046/j.1365-246x.1999.00967.x
-
[7]
Spectral-element simulations of global seismic wave propagation—i. validation,
——, “Spectral-element simulations of global seismic wave propagation—i. validation,”Geophysical Journal International, vol. 149, no. 2, pp. 390–412, 05 2002. [Online]. Available: https://doi.org/10.1046/j.1365-246X.2002.01653.x
-
[8]
C. G. Canuto, M. Y . Hussaini, A. M. Quarteroni, and T. A. Zang, Spectral Methods: Evolution to Complex Geometries and Applications to Fluid Dynamics (Scientific Computation). Berlin, Heidelberg: Springer- Verlag, 2007
2007
-
[9]
Efficient exascale discretizations: High-order finite element methods,
T. Germann, T. Kolev, P. Fischer, M. Min, J. Dongarra, J. Brown, V . Dobrev, T. Warburton, S. Tomov, M. S. Shephard, A. Abdelfattah, V . Barra, N. Beams, J.-S. Camier, N. Chalmers, Y . Dudouit, A. Karakus, I. Karlin, S. Kerkemeier, Y .-H. Lan, D. Medina, E. Merzari, A. Obabko, W. Pazner, T. Rathnayake, C. W. Smith, L. Spies, K. Swirydowicz, J. Thompson, A...
-
[10]
Acceleration of tensor-product operations for high-order finite element methods,
K. Swirydowicz, N. Chalmers, A. Karakus, and T. Warburton, “Acceleration of tensor-product operations for high-order finite element methods,”Int. J. High Perform. Comput. Appl., vol. 33, no. 4, p. 735–757, Jul. 2019. [Online]. Available: https://doi.org/10.1177/1094342018816368
-
[11]
Forward and adjoint simulations of seismic wave propagation on fully unstructured hexahedral meshes,
D. Peter, D. Komatitsch, Y . Luo, R. Martin, N. Le Goff, E. Casarotti, P. Le Loher, F. Magnoni, Q. Liu, C. Blitz, T. Nissen-Meyer, P. Basini, and J. Tromp, “Forward and adjoint simulations of seismic wave propagation on fully unstructured hexahedral meshes,”Geophysical Journal International, vol. 186, no. 2, pp. 721–739, 08 2011. [Online]. Available: http...
-
[12]
High-performance finite elements with mfem,
J. Andrej, N. Atallah, J.-P. B ¨acker, J.-S. Camier, D. Copeland, V . Dobrev, Y . Dudouit, T. Duswald, B. Keith, D. Kim, T. Kolev, B. Lazarov, K. Mittal, W. Pazner, S. Petrides, S. Shiraiwa, M. Stowell, and V . Tomov, “High-performance finite elements with mfem,”The International Journal of High Performance Computing Applications, Jun. 2024. [Online]. Ava...
-
[13]
SEM3D: A 3d high-fidelity numerical earthquake simu- lator for broadband (0–10 hz) seismic response prediction at a regional scale,
S. Touhami, F. Gatti, F. Lopez-Caballero, D. A. C. Cruz, and D. Clouteau, “SEM3D: A 3d high-fidelity numerical earthquake simu- lator for broadband (0–10 hz) seismic response prediction at a regional scale,”Geosciences, vol. 12, no. 3, p. 112, 2022
2022
-
[14]
A look back on 30 years of the gordon bell prize,
G. Bell, D. H. Bailey, J. Dongarra, A. H. Karp, and K. Walsh, “A look back on 30 years of the gordon bell prize,”Int. J. High Perform. Comput. Appl., vol. 31, no. 6, p. 469–484, Nov. 2017. [Online]. Available: https://doi.org/10.1177/1094342017738610
-
[15]
S. Henneking, S. Venkat, V . Dobrev, J. Camier, T. Kolev, M. Fernando, A.-A. Gabriel, and O. Ghattas, “Real-time bayesian inference at extreme scale: A digital twin for tsunami early warning applied to the cascadia subduction zone,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’25....
-
[16]
Co-design and system for the supercomputer “fugaku
S. Matsuoka, M. Sato, H. Kobayashiet al., “Co-design and system for the supercomputer “fugaku”,”IEEE Micro, 2022
2022
-
[17]
Riken launches international initiative with fujitsu and nvidia to accelerate development of fugakunext,
RIKEN, “Riken launches international initiative with fujitsu and nvidia to accelerate development of fugakunext,” https://www.riken.jp/en/news pubs/news/2025/20250822 1/index.html, 2025, accessed: 2026-04-07
2025
-
[18]
Arm architecture reference manual for a-profile architecture,
Arm Ltd., “Arm architecture reference manual for a-profile architecture,” https://developer.arm.com/documentation/ddi0487/latest/, 2024, includes the Scalable Matrix Extension (SME); accessed 2026-04-07
2024
-
[19]
The deal.ii finite element library: Design, features, and insights,
D. Arndt, W. Bangerth, D. Davydov, T. Heister, L. Heltai, M. Kronbichler, M. Maier, J.-P. Pelteret, B. Turcksin, and D. Wells, “The deal.ii finite element library: Design, features, and insights,”Computers & amp; Mathematics with Applications, vol. 81, p. 407–422, Jan. 2021. [Online]. Available: http://dx.doi.org/10.1016/j.camwa.2020.02.022
-
[20]
Gpu algorithms for efficient exascale discretizations,
A. Abdelfattah, V . Barra, N. Beams, R. Bleile, J. Brown, J.-S. Camier, R. Carson, N. Chalmers, V . Dobrev, Y . Dudouit, P. Fischer, A. Karakus, S. Kerkemeier, T. Kolev, Y .-H. Lan, E. Merzari, M. Min, M. Phillips, T. Rathnayake, R. Rieben, T. Stitt, A. Tomboulides, S. Tomov, V . Tomov, A. Vargas, T. Warburton, and K. Weiss, “Gpu algorithms for efficient ...
arXiv 2021
-
[21]
Libxsmm: accelerating small matrix multiplications by runtime code generation,
A. Heinecke, G. Henry, M. Hutchinson, and H. Pabst, “Libxsmm: accelerating small matrix multiplications by runtime code generation,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’16. IEEE Press, 2016
2016
-
[22]
A parallel graph coloring heuristic,
M. T. Jones and P. E. Plassmann, “A parallel graph coloring heuristic,” SIAM Journal on Scientific Computing, vol. 14, no. 3, pp. 654–669,
-
[23]
Available: https://doi.org/10.1137/0914041
[Online]. Available: https://doi.org/10.1137/0914041
-
[24]
Parallel assembly of finite element matrices on multicore computers,
P. Krysl, “Parallel assembly of finite element matrices on multicore computers,”Computer Methods in Applied Mechanics and Engineering, vol. 428, p. 117076, 2024. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0045782524003323
2024
-
[25]
Assembly of finite element methods on graphics processors,
C. Cecka, A. Lew, and E. Darve, “Assembly of finite element methods on graphics processors,”International Journal for Numerical Methods in Engineering, vol. 85, pp. 640 – 669, 02 2011
2011
-
[26]
High-order finite-element seismic wave propagation modeling with mpi on a large gpu cluster,
D. Komatitsch, G. Erlebacher, D. G ¨oddeke, and D. Mich ´ea, “High-order finite-element seismic wave propagation modeling with mpi on a large gpu cluster,”Journal of Computational Physics, vol. 229, pp. 7692– 7714, 10 2010
2010
-
[27]
Hybrid mpi/openmp parallel programming on clusters of multi-core smp nodes,
R. Rabenseifner, G. Hager, and G. Jost, “Hybrid mpi/openmp parallel programming on clusters of multi-core smp nodes,” in2009 17th Eu- romicro International Conference on Parallel, Distributed and Network- based Processing, 2009, pp. 427–436
2009
-
[28]
G. Schubert, H. Fehske, G. Hager, and G. Wellein, “Hybrid-parallel sparse matrix-vector multiplication with explicit communication overlap on current multicore-based systems,”CoRR, vol. abs/1106.5908, 2011. [Online]. Available: http://arxiv.org/abs/1106.5908
Pith/arXiv arXiv 2011
-
[29]
Optimizing computation-communication overlap in asynchronous task-based programs,
E. Castillo, N. Jain, M. Casas, M. Moreto, M. Schulz, R. Beivide, M. Valero, and A. Bhatele, “Optimizing computation-communication overlap in asynchronous task-based programs,” inProceedings of the ACM International Conference on Supercomputing, ser. ICS ’19. New York, NY , USA: Association for Computing Machinery, 2019, p. 380–391. [Online]. Available: h...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.