Charge as a Construct-Validity Factor in Chinese Legal Case Retrieval: A Cross-Benchmark Audit
Pith reviewed 2026-06-27 05:57 UTC · model grok-4.3
The pith
Ranking by shared primary charge recovers 99.2% of the trained-system gap on LeCaRDv2 legal retrieval benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
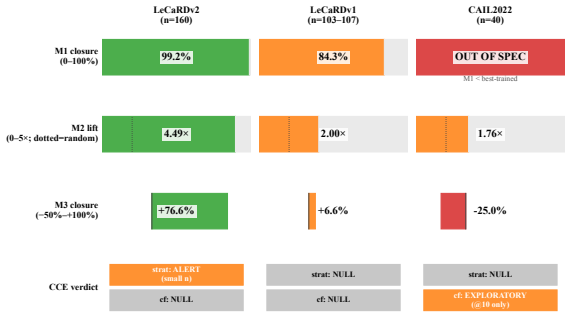
Charge functions as a high-leverage construct-validity factor because LeCaRDv2 defines top relevance via the crime's key constitutive elements, which encode the charge, making same-charge cases relevant by construction. Ranking candidates only by shared primary charge, broken by BM25, closes 99.2% of the BM25-to-best-trained gap on LeCaRDv2 with no detectable difference from the best-trained system. Holding charge fixed collapses the trained reranker's advantage to a small within-charge residual of +0.026 NDCG@10. The charge-to-relevance macro-AUC is 0.871 on LeCaRDv2, lower on the other two collections, and a zero-training charge-pool channel improves first-stage recall as a positive contro
What carries the argument
The charge-controlled evaluation (CCE) protocol that applies established construct-validity and partial-input checks to measure how much retrieval performance is explained by primary-charge matching alone.
If this is right
- The same charge-plus-BM25 rule recovers 84.3% of the gap on LeCaRDv1 and less on CAIL2022 as the charge-to-relevance signal weakens.
- A predicted-charge cascade reproduces 76.6% of the gap on LeCaRDv2 but fails to transfer.
- An exploratory zero-training charge-pool channel raises R@100 by 0.025 on LeCaRDv2 while wrong-charge controls reduce it.
- The CCE protocol returns null or descriptive triggers on all three benchmarks, behaving as designed.
Where Pith is reading between the lines
- New legal retrieval benchmarks could adopt the CCE protocol at design time to confirm that relevance labels test more than charge identity.
- Similar categorical confounds may exist in other specialized retrieval tasks where labels are derived from a single dominant attribute such as topic or category.
- Systems that appear strong on these collections may still require separate testing on charge-balanced or charge-independent data to demonstrate reasoning beyond label construction.
Load-bearing premise
Relevance labels are intended to measure legal reasoning that is independent of whether the candidate shares the query's primary charge.
What would settle it
On a benchmark whose relevance judgments are collected without reference to charge, a charge-plus-BM25 ranker would no longer close nearly all of the gap to trained systems.
Figures
read the original abstract
Chinese Legal Case Retrieval (LCR) benchmarks grade a reference judgment relevant when its legal characterization matches the query, and strong systems now reach NDCG@10 of 0.85-0.88. Most of the BM25-to-best-trained gap is recoverable with no retrieval model: ranking candidates only by shared primary charge, broken by BM25, closes 99.2% of it on LeCaRDv2 -- with no detectable difference from the best-trained system. This reflects benchmark design: LeCaRDv2 defines top relevance via the crime's key constitutive elements, which encode the charge, so same-charge cases are relevant by construction (relevance lift 4.49; charge-to-relevance macro-AUC 0.871). Holding charge fixed, the trained reranker's advantage over BM25 collapses to a small within-charge residual (+0.026 NDCG@10, cluster-bootstrap CI excluding zero, about a quarter), the only non-definitional positive. The effect is not uniform: the same rule recovers 84.3% on LeCaRDv1 and is out of spec on CAIL2022, with the charge-to-relevance signal weakening in step (macro-AUC 0.871/0.759/0.728); a predicted-charge cascade reproduces 76.6% on LeCaRDv2 but does not transfer. The construct is also cashable at first stage: an exploratory zero-training charge-pool channel lifts LeCaRDv2 recall (R@100 +0.025, wrong-charge controls hurt), reported as a positive control for the confound, not a retrieval method or novelty claim. Charge is thus a high-leverage construct-validity factor at the benchmark level -- not auniform explanation of NDCG@10, and not evidence that any system relies on charge. We package established construct-validity and partial-input checks as a reusable charge-controlled protocol (CCE); on all three benchmarks its triggers come back null or descriptive, behaving as designed. We release the scripts, schema, and protocol so future benchmarks can be screened before their NDCG@10 is read as legal-reasoning ability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper audits construct validity in Chinese legal case retrieval benchmarks, claiming that relevance labels are largely determined by primary charge because top relevance is defined via constitutive elements that encode the charge. On LeCaRDv2 it reports that charge-based ranking with BM25 tie-breaking recovers 99.2% of the NDCG@10 gap to the best trained system (no detectable difference), with a relevance lift of 4.49 and charge-to-relevance macro-AUC of 0.871; holding charge fixed reduces the trained-model advantage to a small within-charge residual (+0.026 NDCG@10 with cluster-bootstrap CI excluding zero). The recovery rate and signal strength vary across LeCaRDv1 (84.3%, AUC 0.759) and CAIL2022 (AUC 0.728); a predicted-charge cascade and an exploratory charge-pool first-stage channel are also quantified. The authors release a reusable charge-controlled evaluation (CCE) protocol together with scripts and schema.
Significance. If the direct measurements hold, the work is significant because it supplies a concrete, reproducible demonstration that benchmark design can embed a high-leverage construct-validity factor (charge) that accounts for nearly all observed gains over BM25 on one dataset and a substantial fraction on others. Credit is due for the parameter-free arithmetic, cluster-bootstrap CIs, explicit cross-benchmark comparison, and the public release of the CCE protocol and code, which together enable falsifiable screening of future benchmarks without requiring new modeling assumptions.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, detailed summary of our findings, and recommendation to accept. The report accurately captures the core claims, measurements, and contributions regarding construct validity in the benchmarks.
Circularity Check
No significant circularity
full rationale
The paper performs direct, reproducible computations of standard IR metrics (NDCG@10, recall) on public benchmark data, comparing a simple charge-primary ranking rule plus BM25 tie-break against trained systems and reporting bootstrap CIs. Relevance labels are taken verbatim from the benchmark definitions (constitutive elements encoding charge), and the analysis quantifies the definitional overlap without fitting any parameters to the target NDCG values or invoking self-citations as load-bearing premises. No equations reduce reported quantities to fitted inputs by construction, no uniqueness theorems are imported from prior author work, and the released protocol consists of established construct-validity checks whose outputs are descriptive rather than self-referential. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Cluster-bootstrap confidence intervals are valid for the NDCG differences reported.
Reference graph
Works this paper leans on
-
[1]
Learning Interpretable Legal Case Retrieval via Knowledge-Guided Case Reformulation
Deng, Chenlong and Mao, Kelong and Dou, Zhicheng , title =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =. 2024 , publisher =. doi:10.18653/v1/2024.emnlp-main.73 , url =
-
[2]
2026 , eprint =
Li, Minghan and Lv, Tianrui and Zhang, Chao and Zhou, Guodong , title =. 2026 , eprint =
2026
-
[3]
and Smith, Noah A
Gururangan, Suchin and Swayamdipta, Swabha and Levy, Omer and Schwartz, Roy and Bowman, Samuel R. and Smith, Noah A. , title =. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages =. 2018 , publisher =
2018
-
[4]
Proceedings of the Seventh Joint Conference on Lexical and Computational Semantics (*SEM) , pages =
Poliak, Adam and Naradowsky, Jason and Haldar, Aparajita and Rudinger, Rachel and Van Durme, Benjamin , title =. Proceedings of the Seventh Joint Conference on Lexical and Computational Semantics (*SEM) , pages =. 2018 , publisher =
2018
-
[5]
Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , year =
Rodriguez, Pedro and Azab, Mahmoud and Silvert, Becka and Sanchez, Renato and Labson, Linzy and Shah, Hardik and Moon, Seungwhan , title =. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , year =
-
[6]
2026 , eprint =
Shao, Kan , title =. 2026 , eprint =
2026
-
[7]
2025 , eprint =
Freiesleben, Timo and Zezulka, Sebastian , title =. 2025 , eprint =
2025
-
[8]
Tang, Yanran and Qiu, Ruihong and Yin, Hongzhi and Li, Xue and Huang, Zi , title =. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2024 , publisher =. doi:10.1145/3626772.3657693 , url =
-
[9]
IEEE Access , volume =
Hei, Mengzhe and Liu, Qingbao and Zhang, Sheng and Shi, Honglin and Duan, Jiashun and Zhang, Xin , title =. IEEE Access , volume =. 2024 , doi =
2024
-
[10]
Li, Haitao and Shao, Yunqiu and Wu, Yueyue and Ai, Qingyao and Ma, Yixiao and Liu, Yiqun , title =. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2024 , publisher =. doi:10.1145/3626772.3657887 , url =
-
[11]
Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =
Ma, Yixiao and Shao, Yunqiu and Wu, Yueyue and Liu, Yiqun and Zhang, Ruizhe and Zhang, Min and Ma, Shaoping , title =. Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2021 , publisher =
2021
-
[12]
2022 , howpublished =
2022
-
[13]
and Walker, Steve and Jones, Susan and Hancock-Beaulieu, Micheline M
Robertson, Stephen E. and Walker, Steve and Jones, Susan and Hancock-Beaulieu, Micheline M. and Gatford, Mike , title =. Proceedings of the Third Text REtrieval Conference (. 1995 , publisher =
1995
-
[14]
Chen, Jianlyu and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng , title =. Findings of the Association for Computational Linguistics: ACL 2024 , pages =. 2024 , publisher =. doi:10.18653/v1/2024.findings-acl.137 , url =
-
[15]
SAILER: Structure-Aware Pre-trained Language Model for Legal Case Retrieval
Li, Haitao and Ai, Qingyao and Chen, Jia and Dong, Qian and Wu, Yueyue and Liu, Yiqun and Chen, Chong and Tian, Qi , title =. Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2023 , publisher =. doi:10.1145/3539618.3591761 , url =
-
[16]
Findings of the Association for Computational Linguistics: EMNLP 2020 , pages =
Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Wang, Shijin and Hu, Guoping , title =. Findings of the Association for Computational Linguistics: EMNLP 2020 , pages =. 2020 , publisher =. doi:10.18653/v1/2020.findings-emnlp.58 , url =
-
[17]
2025 , eprint =
Zhang, Yanzhao and Li, Mingxin and Long, Dingkun and Zhang, Xin and Lin, Huan and Yang, Baosong and Xie, Pengjun and Yang, An and Liu, Dayiheng and Lin, Junyang and Huang, Fei and Zhou, Jingren , title =. 2025 , eprint =
2025
-
[18]
2025 , eprint =
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and Huang, Chengen and Lv, Chenxu and Zheng, Chujie and Liu, Dayiheng and Zhou, Fan and Huang, Fei and Hu, Feng and Ge, Hao and Wei, Haoran and Lin, Huan and Tang, Jialong and Yang, Jian and Tu, Jianhong and Zhang, Jianwei and Yang, Jia...
2025
-
[19]
Thomas and Pavlick, Ellie and Linzen, Tal , title =
McCoy, R. Thomas and Pavlick, Ellie and Linzen, Tal , title =. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages =. 2019 , publisher =. doi:10.18653/v1/P19-1334 , url =
-
[20]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages =
Niven, Timothy and Kao, Hung-Yu , title =. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages =. 2019 , publisher =. doi:10.18653/v1/P19-1459 , url =
-
[21]
Bowman, Samuel R. and Dahl, George E. , title =. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages =. 2021 , publisher =. doi:10.18653/v1/2021.naacl-main.385 , url =
-
[22]
and Hanna, Alex and Paullada, Amandalynne , title =
Raji, Deborah and Denton, Emily and Bender, Emily M. and Hanna, Alex and Paullada, Amandalynne , title =. Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks , year =
-
[23]
Chalkidis, Ilias and Pasini, Tommaso and Zhang, Sheng and Tomada, Letizia and Schwemer, Sebastian and S. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2022 , publisher =. doi:10.18653/v1/2022.acl-long.301 , url =
-
[24]
Colin and Miller, Douglas L
Cameron, A. Colin and Miller, Douglas L. , title =. Journal of Human Resources , volume =. 2015 , doi =
2015
-
[25]
Scandinavian Journal of Statistics , volume =
Holm, Sture , title =. Scandinavian Journal of Statistics , volume =. 1979 , url =
1979
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.