EgoInfinity: A Web-Scale 4D Hand-Object Interaction Data Engine for Any-View Robot Retargeting and Video-to-Action Robot Learning
Pith reviewed 2026-06-27 01:33 UTC · model grok-4.3
The pith
EgoInfinity automates lifting of arbitrary internet videos into metric 4D hand-object data for retargeting to any robot.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
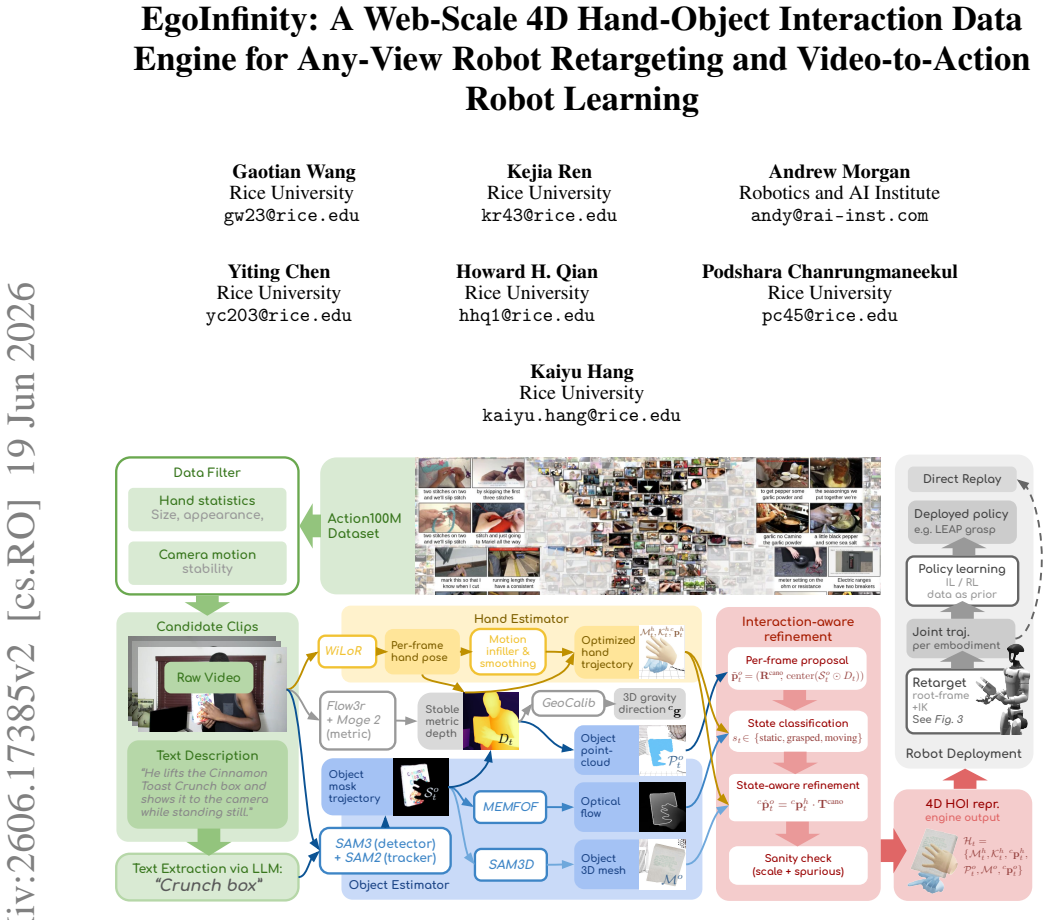
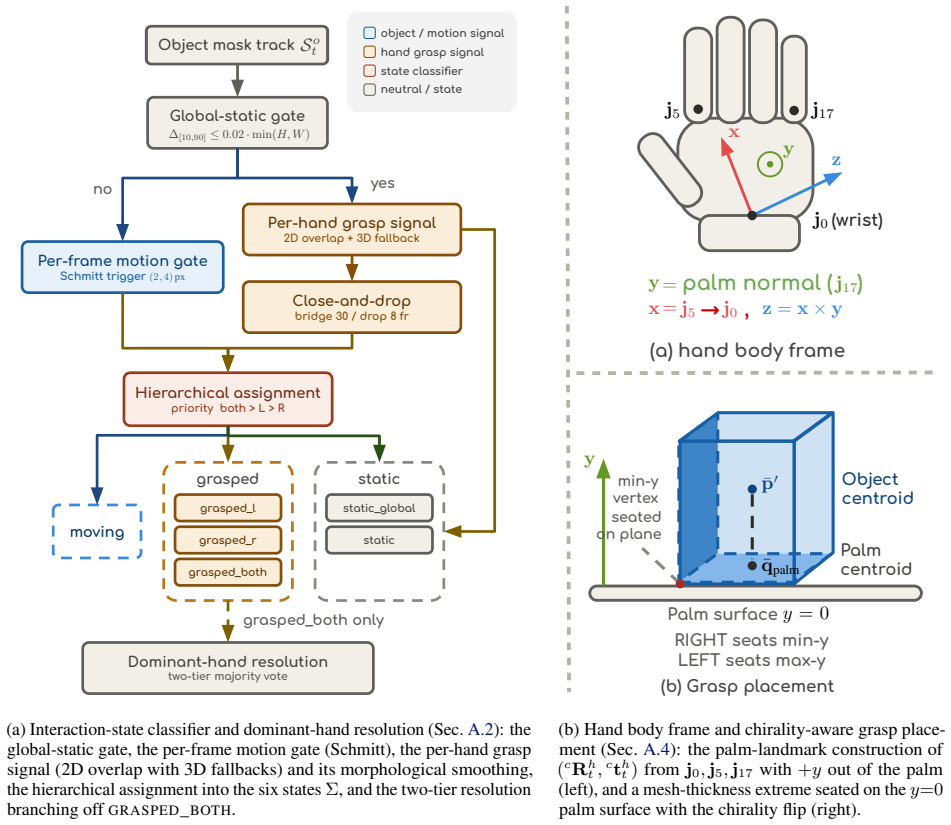
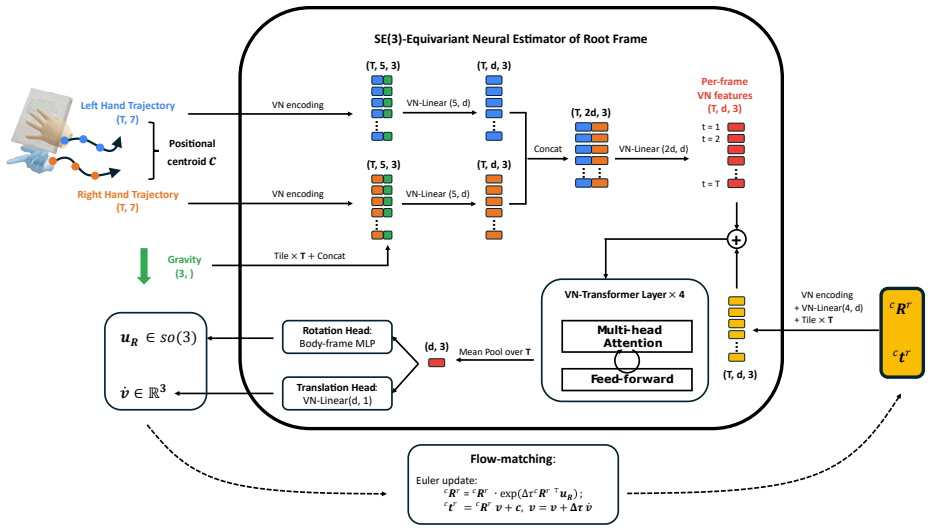
EgoInfinity is a universal 4D hand-object interaction data engine that integrates perception, segmentation, reconstruction, interaction-aware refinement, and retargeting to convert arbitrary RGB videos into physically reliable, metric 4D hand-object representations without human-in-the-loop annotation, using cross-module metric calibration to reduce drift and contact inconsistencies, and a novel motion retargeter to compile 3D hand motions into executable joint trajectories for diverse robot morphologies from any viewpoint.
What carries the argument
The modular engine that chains perception through interaction-aware refinement with cross-module metric calibration, plus the motion retargeter that maps recovered 3D motions to robot joint trajectories.
If this is right
- Web-scale generation of training data becomes feasible from existing internet videos rather than new lab collection.
- The same 4D data supports retargeting across different robot bodies and from partial or arbitrary viewpoints.
- Real-robot execution of skills such as grasping, cutting, wiping, and pouring can be learned directly from recovered motions.
- Advances in any single module automatically improve the overall data engine output.
- Open-world robot learning gains access to manipulation diversity that lab datasets cannot match.
Where Pith is reading between the lines
- The approach could extend to non-manipulation tasks if the refinement steps generalize beyond hand-object contacts.
- Data volume might eventually allow training policies that handle rare edge-case interactions not present in curated sets.
- Integration with newer reconstruction models would directly raise the physical fidelity of the output without redesigning the pipeline.
- Testing on robots with very different kinematics, such as soft or multi-fingered hands, would reveal the retargeter's limits.
Load-bearing premise
Cross-module metric calibration together with interaction-aware refinement will reliably correct drift and contact inconsistencies that arise when chaining standalone perception and reconstruction modules, all without human annotation or post-hoc fixes.
What would settle it
Real-robot trials showing persistent contact errors, object penetrations, or trajectory drift that exceed the rates seen with manually annotated data on the same tasks.
Figures



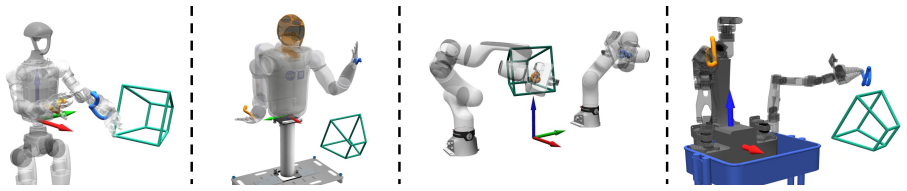




read the original abstract
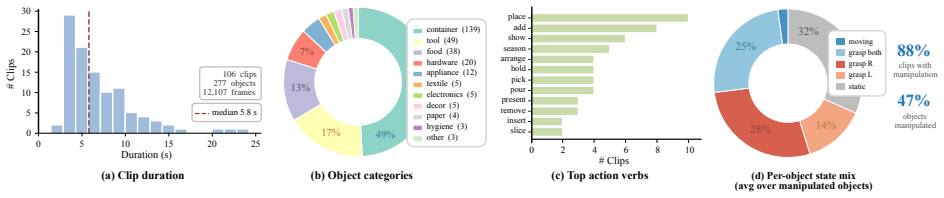
Internet videos constitute the largest reservoir of embodied human manipulation knowledge, yet converting arbitrary RGB footage into actionable robot training data remains a major bottleneck. Existing lab- or factory-collected datasets are narrow in scale and diversity, limiting open-world robot learning. Instead of proposing a static dataset, we introduce EgoInfinity, a universal 4D hand-object interaction data engine that enables web-scale data generation for robot retargeting and learning. EgoInfinity is a modular engine integrating perception, segmentation, reconstruction, interaction-aware refinement, and retargeting to automate this traditionally unscalable video-to-action problem without human-in-the-loop annotation. Its modular design lets the engine continuously benefit from advances in any incorporated component. With EgoInfinity, in-the-wild human manipulation videos are lifted into agent-agnostic, metric 4D hand-object representations, including hand trajectories, 6-DoF object poses, and contact-relevant states. Rather than naively connecting standalone components, EgoInfinity combines cross-module metric calibration with interaction-aware refinement to improve physical reliability, reducing drift and contact inconsistencies common in pure visual reconstruction. We further propose a novel motion retargeter that compiles the recovered 3D hand motions into executable joint trajectories for diverse robot morphologies, enabling video-to-action retargeting on any robot from arbitrary viewpoints and shot sizes (e.g., the human body is only partially visible). We validate EgoInfinity across perception fidelity, kinematic feasibility, contact consistency, cross-embodiment generalization, and real-robot skill acquisition (e.g., grasping, cutting, wiping, and pouring), demonstrating a scalable bridge from internet videos to executable robot behavior for open-world robot learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EgoInfinity, a modular web-scale data engine that automates conversion of arbitrary internet videos into metric 4D hand-object interaction data (hand trajectories, 6-DoF object poses, contact states) for robot retargeting and learning. It integrates perception, segmentation, reconstruction, interaction-aware refinement, and retargeting modules, using cross-module metric calibration to mitigate drift and contact inconsistencies, and proposes a novel motion retargeter for any-view, any-embodiment robot execution. The paper claims validation across perception fidelity, kinematic feasibility, contact consistency, cross-embodiment generalization, and real-robot tasks (grasping, cutting, wiping, pouring) without human annotation.
Significance. If the integration claims hold, EgoInfinity could enable scalable, annotation-free generation of physically reliable 4D training data from internet videos, addressing the narrow scale of existing lab datasets and supporting open-world, cross-embodiment robot learning via video-to-action pipelines.
major comments (2)
- [Abstract] Abstract: the assertion of validation 'across perception fidelity, kinematic feasibility, contact consistency, cross-embodiment generalization, and real-robot skill acquisition' supplies no quantitative results, error bars, dataset sizes, or specific metrics, making it impossible to evaluate whether the interaction-aware refinement actually reduces drift and contact violations as claimed.
- [Abstract] Abstract: the central claim that 'cross-module metric calibration with interaction-aware refinement' reliably produces physically consistent 4D data from in-the-wild videos (reducing drift and contact inconsistencies common in standalone pipelines) is load-bearing yet unsupported by any ablation, before/after metrics, or failure-case analysis in the provided text.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We agree that the abstract would be strengthened by incorporating quantitative highlights and clearer pointers to supporting evidence for the central claims. We will revise the abstract in the next version and ensure the main text explicitly presents the requested ablations, metrics, and analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of validation 'across perception fidelity, kinematic feasibility, contact consistency, cross-embodiment generalization, and real-robot skill acquisition' supplies no quantitative results, error bars, dataset sizes, or specific metrics, making it impossible to evaluate whether the interaction-aware refinement actually reduces drift and contact violations as claimed.
Authors: We agree the abstract, being a concise summary, omits specific numbers. In revision we will add a sentence reporting key quantitative outcomes from the experiments (e.g., drift reduction percentages, contact-consistency scores, dataset sizes, and real-robot success rates with error bars) so readers can immediately assess the refinement's contribution. revision: yes
-
Referee: [Abstract] Abstract: the central claim that 'cross-module metric calibration with interaction-aware refinement' reliably produces physically consistent 4D data from in-the-wild videos (reducing drift and contact inconsistencies common in standalone pipelines) is load-bearing yet unsupported by any ablation, before/after metrics, or failure-case analysis in the provided text.
Authors: The abstract summarizes results that are detailed in the methods and experiments sections of the full manuscript. To directly address the concern we will revise the abstract to reference those supporting results and, if the current body does not already contain them, add explicit before/after comparisons, ablations isolating the calibration and refinement modules, and representative failure cases. revision: yes
Circularity Check
No circularity: modular pipeline with no self-defining equations or fitted predictions
full rationale
The paper describes an engineering pipeline integrating perception, segmentation, reconstruction, calibration, and retargeting modules to generate 4D data from videos. No mathematical derivations, equations, or parameter-fitting steps are shown that would reduce outputs to inputs by construction. Claims about reduced drift via cross-module calibration are presented as design choices validated empirically, not as tautological predictions. No self-citations, uniqueness theorems, or ansatzes are invoked in the abstract or description to load-bear the central claims. This matches the default expectation of a self-contained system description without circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
R. Hoque, P. Huang, D. J. Yoon, M. Sivapurapu, and J. Zhang. Egodex: Learning dexterous manipulation from large-scale egocentric video.arXiv preprint arXiv:2505.11709, 2025
Pith/arXiv arXiv 2025
-
[2]
Banerjee, S
P. Banerjee, S. Shkodrani, P. Moulon, S. Hampali, S. Han, F. Zhang, L. Zhang, J. Fountain, E. Miller, S. Basol, et al. Hot3d: Hand and object tracking in 3d from egocentric multi-view videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7061–7071, 2025
2025
-
[3]
X. Zhan, L. Yang, Y . Zhao, K. Mao, H. Xu, Z. Lin, K. Li, and C. Lu. Oakink2: A dataset of bimanual hands-object manipulation in complex task completion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 445–456, 2024
2024
-
[4]
D. Chen, T. Kasarla, Y . Bang, M. Shukor, W. Chung, J. Yu, A. Bolourchi, T. Moutakanni, and P. Fung. Action100m: A large-scale video action dataset.arXiv preprint arXiv:2601.10592, 2026. 8
arXiv 2026
-
[5]
J. Ma, E. Zhang, H. Yang, D. Li, C. Xu, G. Wang, and H. Wang. Robot learning from human videos: A survey. arXiv preprint arXiv:2604.27621, 2026
Pith/arXiv arXiv 2026
-
[6]
Bharadhwaj, R
H. Bharadhwaj, R. Mottaghi, A. Gupta, and S. Tulsiani. Track2act: Predicting point tracks from internet videos enables generalizable robot manipulation. InEuropean Conference on Computer Vision, pages 306–324. Springer, 2024
2024
-
[7]
C. Wen, X. Lin, J. So, K. Chen, Q. Dou, Y . Gao, and P. Abbeel. Any-point trajectory modeling for policy learning. arXiv preprint arXiv:2401.00025, 2023
Pith/arXiv arXiv 2023
-
[8]
S. Bahl, R. Mendonca, L. Chen, U. Jain, and D. Pathak. Affordances from human videos as a versatile represen- tation for robotics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13778–13790, 2023
2023
-
[9]
S. Ye, J. Jang, B. Jeon, S. J. Joo, J. Yang, B. Peng, A. Mandlekar, R. Tan, Y .-W. Chao, B. Y . Lin, et al. Latent action pretraining from videos. InInternational Conference on Learning Representations, volume 2025, pages 28213–28239, 2025
2025
-
[10]
Grauman, A
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger, H. Jiang, M. Liu, X. Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18995–19012, 2022
2022
-
[11]
H. Luo, Y . Wang, W. Zhang, H. Yuan, Y . Feng, H. Xu, S. Zheng, and Z. Lu. Joint-aligned latent action: Towards scalable vla pretraining in the wild.arXiv preprint arXiv:2602.21736, 2026
arXiv 2026
-
[12]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[13]
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
Pith/arXiv arXiv 2024
-
[14]
G. Chen, M. Wang, T. Cui, Y . Mu, H. Lu, T. Zhou, Z. Peng, M. Hu, H. Li, L. Yuan, et al. Vlmimic: Vision language models are visual imitation learner for fine-grained actions.Advances in Neural Information Processing Systems, 37:77860–77887, 2024
2024
-
[15]
V . Jain, M. Attarian, N. J. Joshi, A. Wahid, D. Driess, Q. Vuong, P. R. Sanketi, P. Sermanet, S. Welker, C. Chan, et al. Vid2robot: End-to-end video-conditioned policy learning with cross-attention transformers.arXiv preprint arXiv:2403.12943, 2024
arXiv 2024
-
[16]
N. Wake, A. Kanehira, K. Sasabuchi, J. Takamatsu, and K. Ikeuchi. Gpt-4v (ision) for robotics: Multimodal task planning from human demonstration.IEEE Robotics and Automation Letters, 9(11):10567–10574, 2024
2024
-
[17]
M. Lepert, J. Fang, and J. Bohg. Phantom: Training robots without robots using only human videos.arXiv preprint arXiv:2503.00779, 2025
Pith/arXiv arXiv 2025
-
[18]
G. Li, Y . Lyu, Z. Liu, C. Hou, J. Zhang, and S. Zhang. H2r: A human-to-robot data augmentation for robot pre-training from videos.arXiv preprint arXiv:2505.11920, 2025
arXiv 2025
-
[19]
M. Lepert, J. Fang, and J. Bohg. Masquerade: Learning from in-the-wild human videos using data-editing.arXiv preprint arXiv:2508.09976, 2025
Pith/arXiv arXiv 2025
-
[20]
S. Nair, A. Rajeswaran, V . Kumar, C. Finn, and A. Gupta. R3m: A universal visual representation for robot manipulation.arXiv preprint arXiv:2203.12601, 2022
Pith/arXiv arXiv 2022
-
[21]
Y . J. Ma, S. Sodhani, D. Jayaraman, O. Bastani, V . Kumar, and A. Zhang. Vip: Towards universal visual reward and representation via value-implicit pre-training.arXiv preprint arXiv:2210.00030, 2022. 9
Pith/arXiv arXiv 2022
-
[22]
Radosavovic, T
I. Radosavovic, T. Xiao, S. James, P. Abbeel, J. Malik, and T. Darrell. Real-world robot learning with masked visual pre-training. InConference on Robot Learning, pages 416–426. PMLR, 2023
2023
-
[23]
C.-L. Cheang, G. Chen, Y . Jing, T. Kong, H. Li, Y . Li, Y . Liu, H. Wu, J. Xu, Y . Yang, et al. Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation.arXiv preprint arXiv:2410.06158, 2024
Pith/arXiv arXiv 2024
-
[24]
X. Chen, H. Wei, P. Zhang, C. Zhang, K. Wang, Y . Guo, R. Yang, Y . Wang, X. Xiao, L. Zhao, et al. Villa-x: enhancing latent action modeling in vision-language-action models.arXiv preprint arXiv:2507.23682, 2025
Pith/arXiv arXiv 2025
-
[25]
M. K. Govind, D. Reilly, P. Wang, and S. Das. Unilact: Depth-aware rgb latent action learning for vision-language- action models.arXiv preprint arXiv:2602.20231, 2026
Pith/arXiv arXiv 2026
-
[26]
R. A. Potamias, J. Zhang, J. Deng, and S. Zafeiriou. Wilor: End-to-end 3d hand localization and reconstruction in-the-wild. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12242–12254, 2025
2025
-
[27]
R. Wang, S. Xu, Y . Dong, Y . Deng, J. Xiang, Z. Lv, G. Sun, X. Tong, and J. Yang. Moge-2: Accurate monocular geometry with metric scale and sharp details.Advances in Neural Information Processing Systems, 38:35928– 35959, 2026
2026
-
[28]
Z. Cong, Q. Zhao, M. Jeon, and S. Tulsiani. Flow3r: Factored flow prediction for scalable visual geometry learning.arXiv preprint arXiv:2602.20157, 2026
arXiv 2026
-
[29]
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. Rädle, C. Rolland, L. Gustafson, et al. Sam 2: Segment anything in images and videos. InInternational Conference on Learning Representations, volume 2025, pages 28085–28128, 2025
2025
-
[30]
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
Pith/arXiv arXiv 2025
-
[31]
S. D. Team, X. Chen, F.-J. Chu, P. Gleize, K. J. Liang, A. Sax, H. Tang, W. Wang, M. Guo, T. Hardin, X. Li, A. Lin, J. Liu, Z. Ma, A. Sagar, B. Song, X. Wang, J. Yang, B. Zhang, P. Dollár, G. Gkioxari, M. Feiszli, and J. Malik. Sam 3d: 3dfy anything in images. 2025. URLhttps://arxiv.org/abs/2511.16624
Pith/arXiv arXiv 2025
-
[32]
Bargatin, E
V . Bargatin, E. Chistov, A. Yakovenko, and D. Vatolin. Memfof: High-resolution training for memory-efficient multi-frame optical flow estimation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8187–8196, 2025
2025
-
[33]
Veicht, P.-E
A. Veicht, P.-E. Sarlin, P. Lindenberger, and M. Pollefeys. Geocalib: Learning single-image calibration with geometric optimization. InEuropean Conference on Computer Vision, pages 1–20. Springer, 2024
2024
-
[34]
Zhang, J
J. Zhang, J. Deng, C. Ma, and R. A. Potamias. Hawor: World-space hand motion reconstruction from egocentric videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1805–1815, 2025
2025
-
[35]
Pavlakos, D
G. Pavlakos, D. Shan, I. Radosavovic, A. Kanazawa, D. Fouhey, and J. Malik. Reconstructing hands in 3d with transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9826–9836, 2024
2024
-
[36]
B. Wen, W. Yang, J. Kautz, and S. Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17868–17879, 2024
2024
-
[37]
Y . Ye, J. Li, R. Rong, and C. K. Liu. Whole: World-grounded hand-object lifted from egocentric videos.arXiv preprint arXiv:2602.22209, 2026
arXiv 2026
-
[38]
H. Fu, W. Wang, X. Qiao, R. A. Potamias, T. Komura, S. Yang, Z. Liu, and B. Zhao. Egograsp: World-space hand-object interaction estimation from egocentric videos.arXiv preprint arXiv:2601.01050, 2026. 10
arXiv 2026
-
[39]
J. Shin, J. Lee, J. Lee, I. Bae, D. Lee, H. Im, Y . Lee, and H.-G. Jeon. Compose: When to trust hands for object pose tracking.arXiv preprint arXiv:2605.23523, 2026
Pith/arXiv arXiv 2026
-
[40]
K. Li, P. Li, T. Liu, Y . Li, and S. Huang. Maniptrans: Efficient dexterous bimanual manipulation transfer via residual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6991–7003, 2025
2025
-
[41]
Z. Chen, S. Chen, E. Arlaud, I. Laptev, and C. Schmid. Vividex: Learning vision-based dexterous manipulation from human videos. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 3336–
-
[42]
Kareer, D
S. Kareer, D. Patel, R. Punamiya, P. Mathur, S. Cheng, C. Wang, J. Hoffman, and D. Xu. Egomimic: Scaling imitation learning via egocentric video. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 13226–13233. IEEE, 2025
2025
-
[43]
S. Park, H. Bharadhwaj, and S. Tulsiani. Demodiffusion: One-shot human imitation using pre-trained diffusion policy.arXiv preprint arXiv:2506.20668, 2025
arXiv 2025
-
[44]
R.-Z. Qiu, S. Yang, X. Cheng, C. Chawla, J. Li, T. He, G. Yan, D. J. Yoon, R. Hoque, L. Paulsen, et al. Humanoid policy˜ human policy.arXiv preprint arXiv:2503.13441, 2025
arXiv 2025
-
[45]
Romero, D
J. Romero, D. Tzionas, and M. J. Black. Embodied hands: Modeling and capturing hands and bodies together. ACM Transactions on Graphics, (Proc. SIGGRAPH Asia), 36(6), Nov. 2017
2017
-
[46]
Yan and J
W. Yan and J. Chu. FoundationPose++, Mar. 2025. URL https://github.com/teal024/ FoundationPose-plus-plus
2025
-
[47]
H. Li, I. Zhang, R. Ouyang, X. Wang, Z. Zhu, Z. Yang, Z. Zhang, B. Wang, C. Ni, W. Qin, et al. Mimicdreamer: Aligning human and robot demonstrations for scalable vla training.arXiv preprint arXiv:2509.22199, 2025
arXiv 2025
-
[48]
H. Ci, X. Liu, P. Yang, Y . Song, and M. Z. Shou. H2r-grounder: A paired-data-free paradigm for translating human interaction videos into physically grounded robot videos.arXiv preprint arXiv:2512.09406, 2025
arXiv 2025
-
[49]
C. Deng, O. Litany, Y . Duan, A. Poulenard, A. Tagliasacchi, and L. J. Guibas. Vector neurons: A general framework for so (3)-equivariant networks. InProceedings of the IEEE/CVF international conference on computer vision, pages 12200–12209, 2021
2021
-
[50]
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[51]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In2012 IEEE/RSJ international conference on intelligent robots and systems, pages 5026–5033. IEEE, 2012
2012
-
[52]
J. Zhou, Z. Gao, F. Hong, Z. Liu, G. Zhang, W. Dai, R. Zhen, C. Lyu, H. Wu, Y . Mao, et al. Touchanything: A dataset and framework for bimanual tactile estimation from egocentric video.arXiv preprint arXiv:2605.13083, 2026. 11 Appendix: Implementation and Data Details This supplementary material is organized into three parts. Sec. A details the data engin...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.