DiffPC: Diffusion-Based Projector Photometric Compensation
Pith reviewed 2026-06-26 21:59 UTC · model grok-4.3
The pith
A diffusion model reformulates projector photometric compensation as a denoising task to handle unknown scenes without specific training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
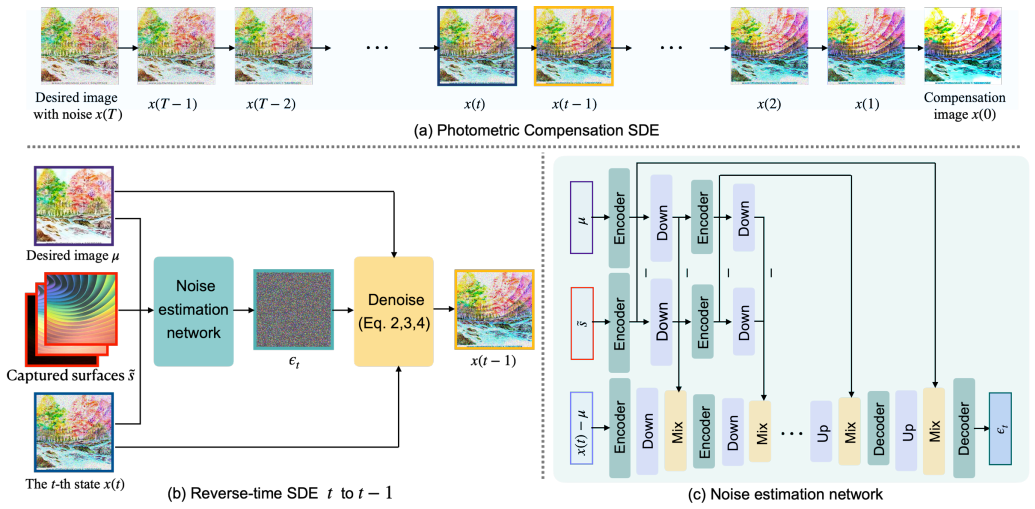
The central claim is that photometric compensation can be achieved by a diffusion model that iteratively removes environment-dependent additive noise from the projected image, using a noise estimation network conditioned on photometry-aware features and content conditions to generate the compensation image.
What carries the argument
The diffusion model operating on an additive trajectory to remove noise, with a noise estimation network that incorporates photometry-aware and content conditions.
If this is right
- The method achieves superior visual performance in unknown scenarios.
- It exhibits significant practical advantages over prior methods that require scene-specific data.
- It provides better consideration for perceptual quality in compensation.
- Compensation images are reconstructed under photometric and content-aware guidance.
Where Pith is reading between the lines
- If true, this could extend to compensating other projection-based displays like in AR or large-scale installations.
- Future work might test whether the additive noise model holds for non-Lambertian surfaces or extreme lighting.
- The iterative nature suggests potential for integration with real-time feedback systems if computation is optimized.
Load-bearing premise
Photometric distortions can be accurately modeled as environment-dependent additive noise, allowing the compensation problem to be reformulated as a denoising task with physical constraints.
What would settle it
An experiment showing that the diffusion model fails to produce accurate compensations in a scene where distortions are not well-approximated by additive noise, or does not outperform existing methods in unknown scenarios.
Figures


read the original abstract
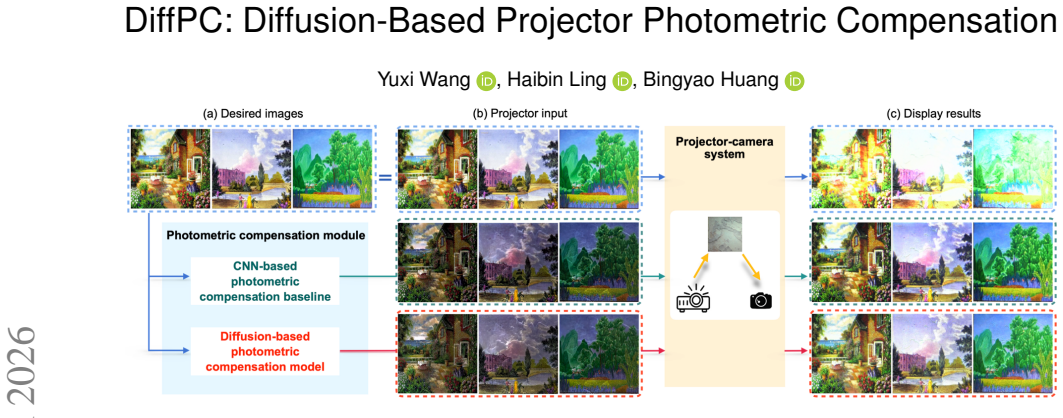
Projector photometric compensation corrects color distortions introduced by surface texture, reflection, and ambient lighting. Existing deep learning-based methods usually require professional scene-specific data collection and lack consideration for perceptual quality. To address this limitation, we present a diffusion-based photometric compensation method that reconstructs compensation images under photometric and content-aware guidance. Specifically, we first model the photometric distortions introduced during projection as environment-dependent additive noise, thereby reformulating the photometric compensation problem as a denoising task with physical constraints. Next, we introduce a diffusion model, which generates compensation images by following an additive trajectory to iteratively remove the noise. Finally, to accurately estimate the noise at each timestep, by analyzing the factors that contribute to distortions in the physical process of projection and capturing, we design a noise estimation network that incorporates features of both photometry-aware and content conditions. Experiments show that our method achieves superior visual performance in unknown scenarios, thereby exhibiting significant practical advantages over prior methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DiffPC, a diffusion-based method for projector photometric compensation. It models photometric distortions as environment-dependent additive noise, reformulating the task as a denoising problem with physical constraints. A diffusion model generates compensation images via an additive trajectory, using a photometry-aware and content-conditioned noise estimation network. The central claim is that the approach achieves superior visual performance in unknown scenarios over prior methods without requiring scene-specific data collection.
Significance. If the modeling and results hold, the work could advance practical photometric compensation by leveraging diffusion models for perceptual quality and generalization to unseen scenes, reducing reliance on per-scene calibration data common in prior DL methods.
major comments (2)
- [Abstract] Abstract: the claim that photometric distortions can be modeled as 'environment-dependent additive noise' (allowing reformulation as a denoising task) is load-bearing for the entire approach, including the diffusion trajectory and photometry-aware estimator; however, the standard projector-camera model is I_c = (I_p * A) + L where A is spatially varying albedo, so compensation requires division by A and an additive-only model cannot recover this, risking content-dependent residuals on non-white surfaces.
- [Abstract] Abstract: the statement 'Experiments show that our method achieves superior visual performance in unknown scenarios' is the central empirical claim, yet the provided text supplies no quantitative metrics, baseline comparisons, error analysis, ablation studies, or implementation details, preventing verification of whether the performance claims are supported.
minor comments (1)
- [Abstract] The abstract would benefit from explicit mention of how physical constraints are enforced in the diffusion process or the specific architecture of the noise estimation network.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the presentation of our modeling assumptions and empirical claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that photometric distortions can be modeled as 'environment-dependent additive noise' (allowing reformulation as a denoising task) is load-bearing for the entire approach, including the diffusion trajectory and photometry-aware estimator; however, the standard projector-camera model is I_c = (I_p * A) + L where A is spatially varying albedo, so compensation requires division by A and an additive-only model cannot recover this, risking content-dependent residuals on non-white surfaces.
Authors: We appreciate the referee highlighting the distinction between the standard multiplicative albedo model and our additive formulation. Our approach treats the net photometric distortion (arising from surface texture, reflection, and ambient light) as an environment-dependent additive perturbation to enable the diffusion-based denoising trajectory. This is an explicit modeling choice that trades exact physical fidelity for practical generalization to unseen scenes without per-scene data collection. We will revise the abstract and add a dedicated paragraph in the method section to clarify this approximation, discuss its implications for non-white surfaces, and note that residual errors may remain in cases of strong color variation. revision: yes
-
Referee: [Abstract] Abstract: the statement 'Experiments show that our method achieves superior visual performance in unknown scenarios' is the central empirical claim, yet the provided text supplies no quantitative metrics, baseline comparisons, error analysis, ablation studies, or implementation details, preventing verification of whether the performance claims are supported.
Authors: The abstract is a concise summary; the full manuscript contains quantitative evaluations (PSNR, SSIM, LPIPS), baseline comparisons, ablation studies on the photometry-aware and content-conditioned components, and implementation details in Sections 4 and 5. To address the concern, we will revise the abstract to include a brief reference to the key quantitative improvements (e.g., higher perceptual quality scores in unseen environments) while keeping the length appropriate. revision: yes
Circularity Check
No circularity; explicit modeling assumption with independent experimental claims
full rationale
The paper states an explicit modeling choice ('model the photometric distortions ... as environment-dependent additive noise, thereby reformulating the photometric compensation problem as a denoising task') and proceeds to a diffusion architecture and estimator. No equations, fitted parameters renamed as predictions, or self-citation chains are shown that reduce any claimed result to the inputs by construction. Performance claims rest on experiments rather than tautological derivation. This is the common case of a self-contained reformulation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Photometric distortions can be modeled as environment-dependent additive noise allowing reformulation as a denoising task.
Reference graph
Works this paper leans on
-
[1]
Akiyama, T
R. Akiyama, T. Fukiage, and S. Nishida. Perceptually-based optimization for radiometric projector compensation. InIEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), pp. 750– 751, 2022. 2
2022
-
[2]
T. Amano and H. Kato. Appearance control using projection with model predictive control. In2010 20th International Conference on Pattern Recognition, pp. 2832–2835, 2010. doi: 10.1109/ICPR.2010.694 2
-
[3]
Ashdown, T
M. Ashdown, T. Okabe, I. Sato, and Y . Sato. Robust content-dependent photometric projector compensation. In2006 Conference on Computer Vision and Pattern Recognition Workshop (CVPRW’06), pp. 6–6, 2006. 2
2006
-
[4]
Bimber, D
O. Bimber, D. Iwai, G. Wetzstein, and A. Grundhöfer. The visual com- puting of projector-camera systems. InACM SIGGRAPH 2008 Classes, SIGGRAPH ’08, article no. 84, 25 pages. Association for Computing Machinery, New York, NY , USA, 2008. 2
2008
-
[5]
Bokaris, M
P.-A. Bokaris, M. Gouiffès, C. Jacquemin, and J.-M. Chomaz. Photo- metric compensation to dynamic surfaces in a projector-camera system. InEuropean Conference on Computer Vision Workshops, pp. 283–296. Cham, 2014. 1
2014
-
[6]
X. Chen, C. Liang, D. Huang, E. Real, K. Wang, H. Pham, X. Dong, T. Luong, C.-J. Hsieh, Y . Lu, and Q. V . Le. Symbolic discovery of opti- mization algorithms. InProceedings of the 37th International Conference on Neural Information Processing Systems, article no. 2140, 29 pages. Curran Associates Inc., Red Hook, NY , USA, 2023. 5
2023
-
[7]
Chung, B
H. Chung, B. Sim, and J. C. Ye. Come-closer-diffuse-faster: Accelerat- ing conditional diffusion models for inverse problems through stochastic contraction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 12413–12422, June 2022. 2
2022
-
[8]
X. Cong, Y . Wu, Q. Chen, and C. Lei. Automatic controllable colorization via imagination. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2609–2619, 2024. doi: 10.1109/ CVPR52733.2024.00252 1
arXiv 2024
-
[9]
Y . Deng, H. Ling, and B. Huang. Lapig: Language guided projector image generation with surface adaptation and stylization.IEEE Transactions on Visualization and Computer Graphics, 31(5):2515–2524, 2025. 3
2025
-
[10]
Y . Erel, D. Iwai, and A. H. Bermano. Neural projection mapping using reflectance fields.IEEE Transactions on Visualization and Computer Graphics, 29(11):4339–4349, 2023. 3
2023
-
[11]
Y . Erel, O. Kozlovsky-Mordenfeld, D. Iwai, K. Sato, and A. H. Bermano. Casper dpm: Cascaded perceptual dynamic projection mapping onto hands. InSIGGRAPH Asia 2024 Conference Papers, article no. 137, 10 pages. New York, NY , USA, 2024. 3
2024
-
[12]
Fujii, M
K. Fujii, M. Grossberg, and S. Nayar. A projector-camera system with real- time photometric adaptation for dynamic environments. InIEEE Computer Society Conference on Computer Vision and Pattern Recognition, vol. 2,
-
[13]
Grossberg, H
M. Grossberg, H. Peri, S. Nayar, and P. Belhumeur. Making one object look like another: controlling appearance using a projector-camera system. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2004. CVPR 2004., vol. 1, pp. I–I, 2004. 2
2004
-
[14]
Grundhöfer
A. Grundhöfer. Practical non-linear photometric projector compensation. In2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops, pp. 924–929, 2013. 2
2013
-
[15]
Grundhöfer and D
A. Grundhöfer and D. Iwai. Robust, error-tolerant photometric projector compensation.IEEE Transactions on Image Processing, 24(12):5086– 5099, 2015. 2
2015
-
[16]
Hamasaki, Y
T. Hamasaki, Y . Itoh, Y . Hiroi, D. Iwai, and M. Sugimoto. Hysar: Hybrid material rendering by an optical see-through head-mounted display with spatial augmented reality projection.IEEE Transactions on Visualization and Computer Graphics, 24(4):1457–1466, 2018. 1
2018
-
[17]
Hashimoto and K
N. Hashimoto and K. Yoshimura. Radiometric compensation for non- rigid surfaces by continuously estimating inter-pixel correspondence.The Visual Computer, 37(1):175–187, 2021. 2
2021
-
[18]
Heusel, H
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. InProceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, 12 pages, p. 6629–6640. Curran Associates Inc., Red Hook, NY , USA, 2017. 5
2017
-
[19]
Hiratani, D
K. Hiratani, D. Iwai, Y . Kageyama, P. Punpongsanon, T. Hiraki, and K. Sato. Shadowless projection mapping using retrotransmissive optics. IEEE Transactions on Visualization and Computer Graphics, 29(5):2280– 2290, 2023. 1
2023
-
[20]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems, vol. 33, pp. 6840–
-
[21]
Curran Associates, Inc., 2020. 2
2020
-
[22]
Huang and H
B. Huang and H. Ling. End-to-end projector photometric compensation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6803–6812, 2019. 1, 2, 4, 5, 7, 9
2019
-
[23]
Huang, T
B. Huang, T. Sun, and H. Ling. End-to-end full projector compensa- tion.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(6):2953–2967, 2022. 1, 2, 3, 5, 7
2022
-
[24]
Huang, F
S. Huang, F. Song, L. Wang, Y . Huang, Y . He, S. Bai, T. Chen, and M. Ishikawa. High-speed active vision pose perception and tracking method based on pan-tilt mirrors for 6-dof dynamic projection mapping. Optics and Lasers in Engineering, 188:108888, 2025. 1
2025
-
[25]
Huang, T.-C
T.-H. Huang, T.-C. Wang, and H. H. Chen. Radiometric compensation of images projected on non-white surfaces by exploiting chromatic adapta- tion and perceptual anchoring.IEEE Transactions on Image Processing, 26(1):147–159, 2017. 2
2017
-
[26]
D. Iwai. Projection mapping technologies: A review of current trends and future directions.Proceedings of the Japan Academy. Series B, Physical and biological sciences, 100:234–251, 03 2024. 1
2024
-
[27]
X. Ju, X. Liu, X. Wang, Y . Bian, Y . Shan, and Q. Xu. Brushnet: A plug-and- play image inpainting model with decomposed dual-branch diffusion. In European Conference on Computer Vision, pp. 150–168. Springer Nature Switzerland, Cham, 2024. 3
2024
-
[28]
Kageyama, M
Y . Kageyama, M. Isogawa, D. Iwai, and K. Sato. Prodebnet: Projector deblurring using convolutional neural network.Optics Express, 28, 06
-
[29]
Kageyama, D
Y . Kageyama, D. Iwai, and K. Sato. Online projector deblurring using a convolutional neural network.IEEE Transactions on Visualization and Computer Graphics, 28(5):2223–2233, 2022. 2
2022
-
[30]
Kawar, M
B. Kawar, M. Elad, S. Ermon, and J. Song. Denoising diffusion restoration models. InProceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, article no. 1714, 14 pages. Curran Associates Inc., Red Hook, NY , USA, 2022. 2
2022
-
[31]
Kurth, V
P. Kurth, V . Lange, M. Stamminger, and F. Bauer. Real-time adaptive color correction in dynamic projection mapping. In2020 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), pp. 174–184, 2020. 2
2020
-
[32]
Y . Li, W. Yin, J. Li, and X. Xie. Physics-based efficient full projector com- pensation using only natural images.IEEE Transactions on Visualization and Computer Graphics, pp. 1–15, 2023. 1, 2
2023
-
[33]
J. Luo, R. Li, C. Jiang, X. Zhang, M. Han, T. Jiang, H. Fan, and S. Liu. Diff- shadow: Global-guided diffusion model for shadow removal.Proceedings of the AAAI Conference on Artificial Intelligence, 39(6):5856–5864, Apr
-
[34]
Z. Luo, F. K. Gustafsson, Z. Zhao, J. Sjölund, and T. B. Schön. Im- age restoration with mean-reverting stochastic differential equations. In Proceedings of the 40th International Conference on Machine Learning, ICML’23, article no. 957, 22 pages. JMLR.org, 2023. 1, 2, 3, 4
2023
-
[35]
Z. Luo, F. K. Gustafsson, Z. Zhao, J. Sjölund, and T. B. Schön. Refusion: Enabling large-size realistic image restoration with latent-space diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pp. 1680–1691, June 2023. 4, 5
2023
-
[36]
X. Lv, S. Zhang, C. Wang, Y . Zheng, B. Zhong, C. Li, and L. Nie. Fourier priors-guided diffusion for zero-shot joint low-light enhancement and de- blurring. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 25378–25388, 2024. doi: 10.1109/CVPR52733. 2024.02398 1, 2
-
[37]
Miyashita, Y
L. Miyashita, Y . Watanabe, and M. Ishikawa. Midas projection: Markerless and modelless dynamic projection mapping for material representation. ACM Transactions on Graphics, 37(6):1–12, 2018. 1
2018
-
[38]
Miyatake, T
Y . Miyatake, T. Hiraki, D. Iwai, and K. Sato. Haptomapping: Visuo-haptic augmented reality by embedding user-imperceptible tactile display control signals in a projected image.IEEE Transactions on Visualization and Computer Graphics, 29(4):2005–2019, 2023. 1
2005
-
[39]
Narita, Y
G. Narita, Y . Watanabe, and M. Ishikawa. Dynamic projection mapping onto deforming non-rigid surface using deformable dot cluster marker. IEEE Transactions on Visualization and Computer Graphics, 23(3):1235– 1248, 2017. 1
2017
-
[40]
S. K. Nayar, H. Peri, M. D. Grossberg, and P. N. Belhumeur. A projec- tion system with radiometric compensation for screen imperfections. In Proceedings of the IEEE ICCV Workshop on Projector-Camera Systems (PROCAMS), 2003. 2
2003
-
[41]
A. Q. Nichol and P. Dhariwal. Improved denoising diffusion probabilistic models. InProceedings of the 38th International Conference on Machine Learning, pp. 8162–8171, 2021. 5
2021
-
[42]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10684–10695, June 2022. 2
2022
-
[43]
Saharia, J
C. Saharia, J. Ho, W. Chan, T. Salimans, D. J. Fleet, and M. Norouzi. Image super-resolution via iterative refinement.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(4):4713–4726, 2023. 1, 2
2023
-
[44]
Sharma, W
G. Sharma, W. Wu, and E. N. Dalal. The ciede2000 color-difference formula: Implementation notes, supplementary test data, and mathematical observations.Color Research and Application, 30:21–30, 2005. 5
2005
-
[45]
Shih, J.-S
K.-T. Shih, J.-S. Liu, F. Shyu, and H. H. Chen. Enhancement and speedup of photometric compensation for projectors by reducing inter-pixel cou- pling and calibration patterns.IEEE Transactions on Image Processing, 30:418–430, 2021. 1, 2
2021
-
[46]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations, 2021. 2
2021
-
[47]
Sugimoto, D
M. Sugimoto, D. Iwai, K. Ishida, P. Punpongsanon, and K. Sato. Di- rectionally decomposing structured light for projector calibration.IEEE Transactions on Visualization and Computer Graphics, 27(11):4161–4170,
-
[48]
T. Ueda, D. Iwai, T. Hiraki, and K. Sato. Illuminated focus: Vision augmentation using spatial defocusing via focal sweep eyeglasses and high-speed projector.IEEE Transactions on Visualization and Computer Graphics, 26(5):2051–2061, 2020. 1
2051
-
[49]
Y . Wang, H. Ling, and B. Huang. Compenhr: Efficient full compensation for high-resolution projector. InIEEE Conference Virtual Reality and 3D User Interfaces (VR), pp. 135–145, 2023. 1, 2, 5
2023
-
[50]
Y . Wang, H. Ling, and B. Huang. Vicomp: Video compensation for projector-camera systems.IEEE Transactions on Visualization and Com- puter Graphics, pp. 1–10, 2024. doi: 10.1109/TVCG.2024.3372079 1, 2
-
[51]
Y . Wang, W. Yang, X. Chen, Y . Wang, L. Guo, L.-P. Chau, Z. Liu, Y . Qiao, A. C. Kot, and B. Wen. Sinsr: Diffusion-based image super-resolution in a single step. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 25796–25805, 2024. 1
2024
-
[52]
Z. Wang, A. Bovik, H. Sheikh, and E. Simoncelli. Image quality assess- ment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612, 2004. 5
2004
-
[53]
Whang, M
J. Whang, M. Delbracio, H. Talebi, C. Saharia, A. G. Dimakis, and P. Mi- lanfar. Deblurring via stochastic refinement. In2022 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pp. 16272– 16282, 2022. 1, 2
2022
-
[54]
Y . Xiao, Q. Yuan, K. Jiang, J. He, X. Jin, and L. Zhang. Ediffsr: An efficient diffusion probabilistic model for remote sensing image super- resolution.IEEE Transactions on Geoscience and Remote Sensing, 62:1– 14, 2024. 2
2024
-
[55]
D. Yan, L. Yuan, E. Wu, Y . Nishioka, I. Fujishiro, and S. Saito. Colorizedif- fusion: Improving reference-based sketch colorization with latent diffusion model. In2025 IEEE/CVF Winter Conference on Applications of Com- puter Vision (WACV), pp. 5092–5102, 2025. doi: 10.1109/W ACV61041. 2025.00498 1
work page doi:10.1109/w 2025
-
[56]
Yoshida, T
R. Yoshida, T. Hara, Y . Takeda, K. Murase, D. Iwai, and K. Sato. A mixed reality car a-pillar design support system utilizing projection mapping. IEEE Transactions on Visualization and Computer Graphics, 31(10):7674– 7683, 2025. 1
2025
-
[57]
Z. Yue, J. Wang, and C. C. Loy. Resshift: efficient diffusion model for image super-resolution by residual shifting. InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, article no. 583, 14 pages, 2023. 2
2023
-
[58]
Zabari, A
N. Zabari, A. Azulay, A. Gorkor, T. Halperin, and O. Fried. Diffusing colors: Image colorization with text guided diffusion. InSIGGRAPH Asia 2023 Conference Papers, SA ’23, article no. 61, 11 pages. Association for Computing Machinery, New York, NY , USA, 2023. 1
2023
-
[59]
Zhang, W
L. Zhang, W. You, K. Shi, and S. Gu. Uncertainty-guided perturbation for image super-resolution diffusion model. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 1
2025
-
[60]
Zhang, W
L. Zhang, W. You, K. Shi, and S. Gu. Uncertainty-guided perturbation for image super-resolution diffusion model. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pp. 17980–17989, June 2025. 2
2025
-
[61]
Zhang, P
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. The un- reasonable effectiveness of deep features as a perceptual metric. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 586–595, 2018. 5
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.