Better Queries, Cheaper Attention: Adapting Transformers for Efficient Sparse Reconstruction
Pith reviewed 2026-06-26 22:10 UTC · model grok-4.3
The pith
A geometry-aware dynamic-query decoder raises charged-particle trajectory reconstruction efficiency from 94.1% to 98.1% while halving the fake rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
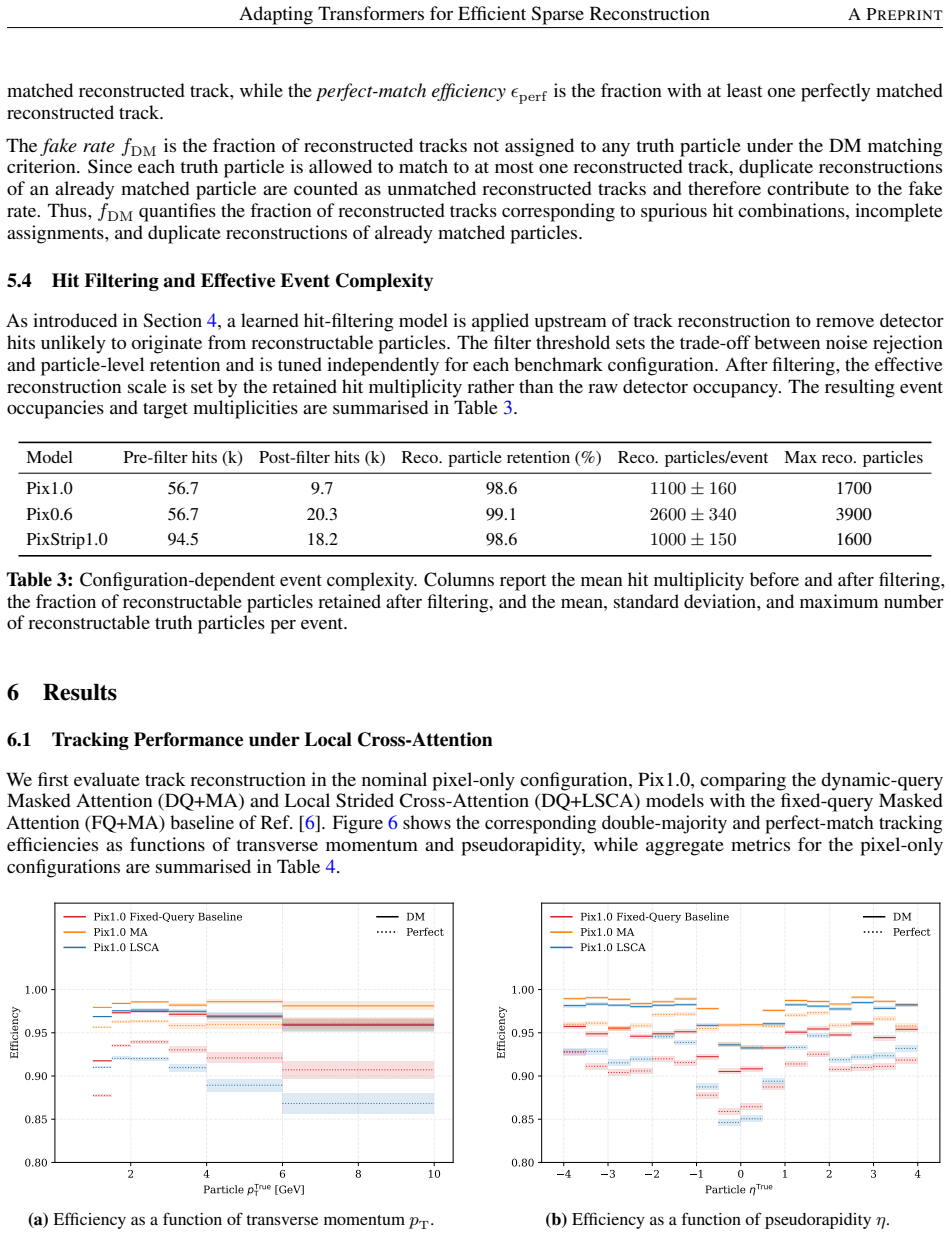
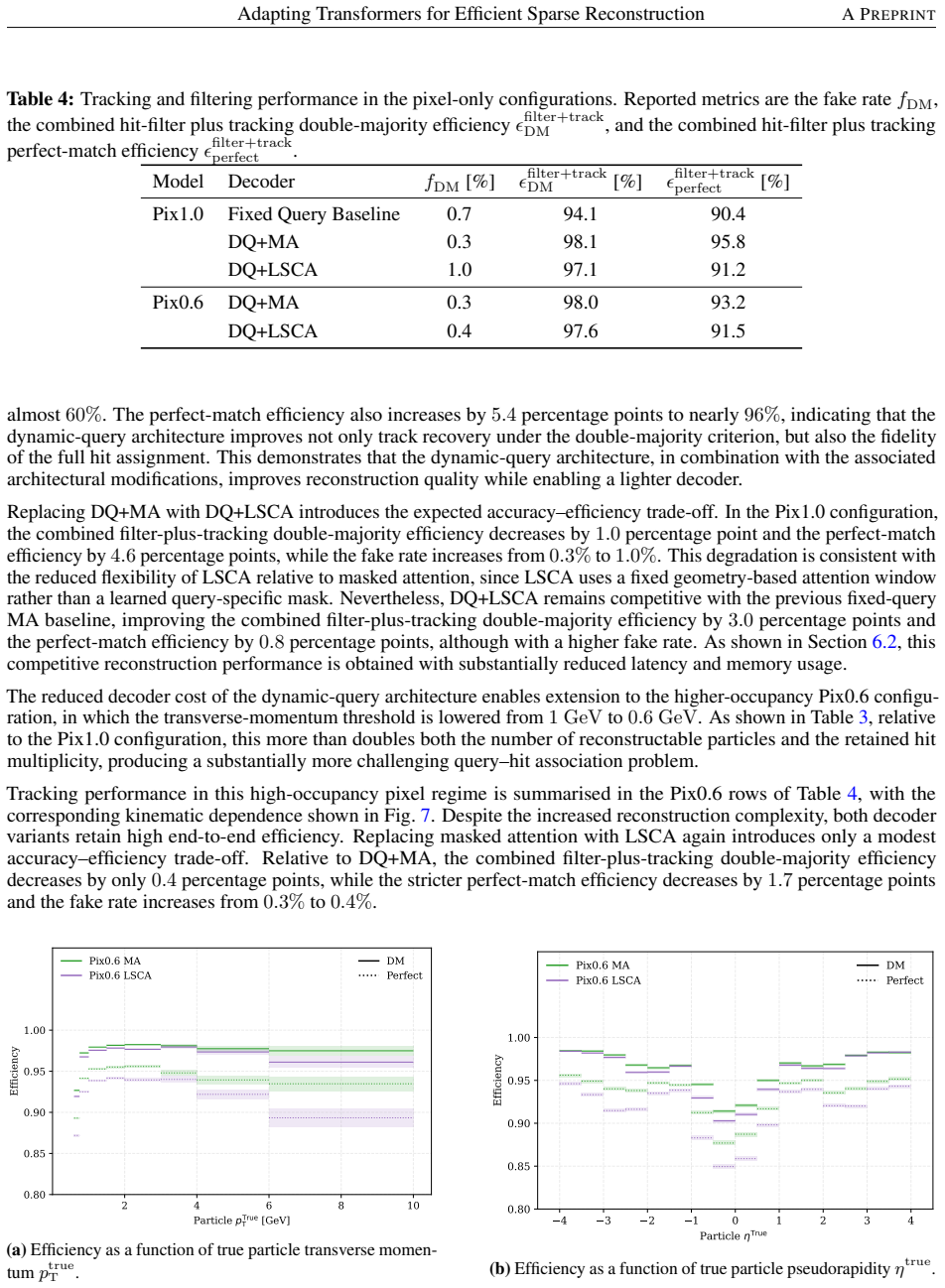
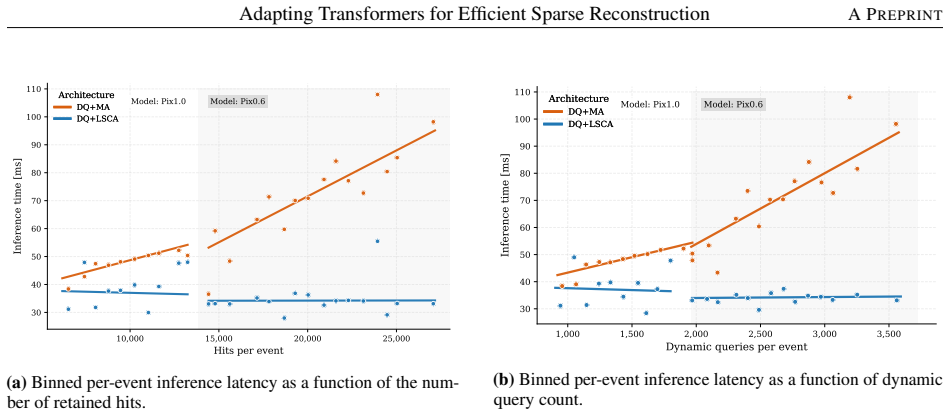
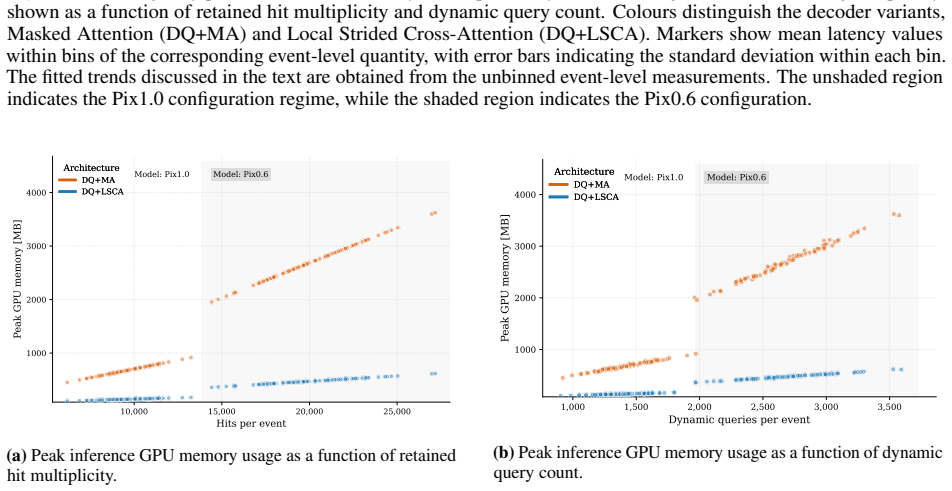
The paper claims that its dynamic-query (DQ) architecture, which initializes decoder queries from encoder-level measurement representations serving as trajectory seeds, raises reconstruction efficiency from 94.1% to 98.1% and cuts the fake rate by more than a factor of two relative to a fixed-query baseline. Adding Local Strided Cross-Attention (LSCA), which replaces learned mask-gated attention with a geometry-defined local support that limits attention to physically plausible query-hit pairs, further reduces end-to-end inference latency by nearly 50% and peak allocated memory by more than a factor of 10 in a simplified High-Luminosity LHC detector model.
What carries the argument
Geometry-aware dynamic-query decoder paired with Local Strided Cross-Attention (LSCA) that restricts cross-attention to geometry-defined local support regions.
If this is right
- Trajectory reconstruction efficiency reaches 98.1% instead of the 94.1% fixed-query baseline.
- The fake rate drops by more than a factor of two.
- End-to-end inference latency falls by nearly 50%.
- Peak allocated inference memory falls by more than a factor of 10.
Where Pith is reading between the lines
- The same seeding-plus-local-support pattern could be tested on other sparse scientific reconstruction tasks such as neutrino event reconstruction or medical tomography.
- Hardware implementations of the strided local support could be benchmarked against dense attention kernels to quantify additional speedups.
- Varying the stride and support radius in LSCA on multiple detector layouts would show how tightly the gains depend on accurate geometric ordering.
Load-bearing premise
The geometry-defined local support in LSCA captures every physically relevant query-hit interaction without omissions, and results on the simplified detector model generalize to full-scale real detector conditions.
What would settle it
A run of the DQ+LSCA model on full-scale HL-LHC simulation data that shows reconstruction efficiency below 98% or memory reduction below a factor of five would falsify the performance claims.
Figures

read the original abstract
Query-based transformer decoders are effective for object reconstruction from sparse scientific sensor measurements, but their scalability to high-multiplicity data is limited by fixed, input-independent query sets and costly decoder cross-attention. We introduce a geometry-aware dynamic-query decoder that couples input-conditioned query construction with structured sparse cross-attention. Decoder queries are initialised from selected encoder-level measurement representations that serve as candidate trajectory seeds, making both query content and query multiplicity input-dependent. Local Strided Cross-Attention (LSCA) exploits the induced geometric ordering by replacing learned mask-gated cross-attention with a geometry-defined local support that restricts attention to physically plausible query-hit interactions and exposes sparsity for block-sparse execution. We study this architecture for charged-particle trajectory reconstruction in a simplified High-Luminosity Large Hadron Collider detector, where thousands of trajectories must be reconstructed from tens of thousands of sparse measurements. In the nominal configuration, the dynamic-query (DQ) architecture increases trajectory reconstruction efficiency from 94.1% to 98.1% and reduces the fake rate by more than a factor of two relative to the fixed-query baseline. The DQ+LSCA model reduces end-to-end inference latency by nearly 50% and peak allocated inference memory by more than a factor of 10 relative to the fixed-query baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a geometry-aware dynamic-query (DQ) decoder coupled with Local Strided Cross-Attention (LSCA) for transformer-based charged-particle trajectory reconstruction from sparse measurements. On a simplified HL-LHC detector model, the DQ architecture raises reconstruction efficiency from 94.1% to 98.1% and cuts the fake rate by more than a factor of two versus a fixed-query baseline; adding LSCA further reduces end-to-end inference latency by ~50% and peak memory by >10×.
Significance. If the empirical gains hold under the stated assumptions, the work demonstrates a practical route to scaling query-based transformers to the high-multiplicity regime required by HL-LHC tracking, by making both query count and attention support input-dependent and geometrically structured. The combination of efficiency and resource reductions is directly relevant to real-time and offline reconstruction pipelines.
major comments (2)
- [Abstract] Abstract (nominal configuration paragraph): The headline efficiency (94.1% → 98.1%) and fake-rate claims rest on the premise that the strided local support exactly matches all physically allowed trajectory-hit interactions. The manuscript provides no ablation varying stride or support radius to confirm that enlarging the window leaves efficiency unchanged; without this diagnostic the central performance attribution to LSCA remains unverified.
- [Abstract] Abstract and experimental setup: All quantitative results are obtained exclusively on a simplified toy geometry. Because the central claims concern practical utility for HL-LHC reconstruction, the absence of any transfer test to a full-scale, misaligned, or material-inclusive detector model leaves open whether the reported gains survive the transition to realistic conditions.
minor comments (2)
- The description of the fixed-query baseline should explicitly state query multiplicity, initialization, and training protocol so that the 94.1% reference point can be reproduced.
- Figure captions and text should clarify whether the reported latency and memory figures include the full encoder-decoder pipeline or only the decoder stage.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's significance and for the constructive comments. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract (nominal configuration paragraph): The headline efficiency (94.1% → 98.1%) and fake-rate claims rest on the premise that the strided local support exactly matches all physically allowed trajectory-hit interactions. The manuscript provides no ablation varying stride or support radius to confirm that enlarging the window leaves efficiency unchanged; without this diagnostic the central performance attribution to LSCA remains unverified.
Authors: We agree that an explicit ablation would strengthen the attribution. The LSCA stride and support radius are derived from the maximum hit displacements permitted by the toy detector geometry and the track curvature model; the 98.1% efficiency indicates the support is sufficient. In the revised manuscript we will add a methods paragraph detailing this geometric derivation together with a sensitivity table showing that moderate enlargements of the window leave efficiency and fake rate unchanged. revision: yes
-
Referee: [Abstract] Abstract and experimental setup: All quantitative results are obtained exclusively on a simplified toy geometry. Because the central claims concern practical utility for HL-LHC reconstruction, the absence of any transfer test to a full-scale, misaligned, or material-inclusive detector model leaves open whether the reported gains survive the transition to realistic conditions.
Authors: The manuscript explicitly positions the study as a controlled demonstration on a simplified HL-LHC toy model to isolate the effects of dynamic queries and structured attention. We acknowledge that transfer to full-scale, misaligned, and material-inclusive simulations is required to assess real-world utility; such experiments lie beyond the present scope. revision: no
- Validation on full-scale, misaligned, or material-inclusive detector models
Circularity Check
No circularity: empirical gains measured on held-out data
full rationale
The paper proposes a dynamic-query decoder with LSCA and reports direct empirical improvements (efficiency 94.1%→98.1%, latency reduction ~50%) on held-out simulation data relative to a fixed-query baseline. No equations, parameter fits, or self-citations are used to derive the claimed metrics; the results are obtained by running the architectures on independent test samples. The derivation chain is therefore self-contained against external benchmarks with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard transformer encoder-decoder attention mechanisms form a valid baseline for sparse reconstruction
Reference graph
Works this paper leans on
-
[1]
Ashish Vaswani et al. “Attention Is All You Need” (2017). arXiv:1706.03762 [cs.CL]
Pith/arXiv arXiv 2017
-
[2]
End-to-End Object Detection with Transformers
Nicolas Carion et al. “End-to-End Object Detection with Transformers” (2020). arXiv:2005.12872 [cs.CV]
arXiv 2020
-
[3]
Masked-attention Mask Transformer for Universal Image Segmentation
Bowen Cheng et al. “Masked-attention Mask Transformer for Universal Image Segmentation” (2022). arXiv: 2112.01527 [cs.CV]. 17 Adapting Transformers for Efficient Sparse ReconstructionA PREPRINT
arXiv 2022
-
[4]
Mask3D: Mask Transformer for 3D Semantic Instance Segmentation
Jonas Schult et al. “Mask3D: Mask Transformer for 3D Semantic Instance Segmentation”.Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). 2023, pp. 8216–8223.DOI: 10.1109/ ICRA48891.2023.10160590
arXiv 2023
-
[5]
Secondary vertex reconstruction with MaskFormers
Samuel Van Stroud et al. “Secondary vertex reconstruction with MaskFormers”. In:Eur. Phys. J. C84.10 (2024), p. 1020.DOI:10.1140/epjc/s10052-024-13374-5. arXiv:2312.12272 [hep-ex]
-
[6]
Transformers for Charged Particle Track Reconstruction in High Energy Physics
Samuel Van Stroud et al. “Transformers for Charged Particle Track Reconstruction in High Energy Physics”. In: Phys. Rev. X15.4 (2025), p. 041046.DOI:10.1103/md46-yqgd. arXiv:2411.07149 [hep-ex]
-
[7]
GLOW: A Unified Particle Flow Transformer
Dmitrii Kobylianskii et al. “GLOW: A Unified Particle Flow Transformer”.Proc. 8th Machine Learning and the Physical Sciences Workshop at the 39th Conference on Neural Information Processing Systems. 2025. arXiv: 2508 . 20092 [hep-ex].URL: https : / / ml4physicalsciences . github . io / 2025 / files / NeurIPS _ ML4PS_2025_65.pdf
2025
-
[8]
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Ze Liu et al. “Swin Transformer: Hierarchical Vision Transformer using Shifted Windows”.Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 2021, pp. 10012–10022. arXiv: 2103.14030 [cs.CV].URL:https://arxiv.org/abs/2103.14030
Pith/arXiv arXiv 2021
-
[9]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Tri Dao et al. “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness”. In:arXiv e-prints, arXiv:2205.14135 (May 2022), arXiv:2205.14135.DOI: 10 . 48550 / arXiv . 2205 . 14135. arXiv: 2205.14135 [cs.LG]
Pith/arXiv arXiv 2022
-
[10]
Longformer: The long-document transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. “Longformer: The long-document transformer”.Findings of the Association for Computational Linguistics: EMNLP 2020. 2020, pp. 3459–3471. arXiv: 2004.05150 [cs.CL].URL:https://arxiv.org/abs/2004.05150
Pith/arXiv arXiv 2020
-
[11]
Big Bird: Transformers for longer sequences
Manzil Zaheer et al. “Big Bird: Transformers for longer sequences”.Advances in Neural Information Processing Systems (NeurIPS). V ol. 33. 2020, pp. 17283–17297. arXiv: 2007.14062 [cs.LG] .URL: https://arxiv. org/abs/2007.14062
Pith/arXiv arXiv 2020
-
[12]
URL https://doi.org/10.48550/arXiv.2501
Xu Zhao et al. “Fast Segment Anything”. In:arXiv preprint arXiv:2306.12156(2023).DOI: 10.48550/arXiv. 2306.12156. arXiv:2306.12156 [cs.CV]
work page internal anchor Pith review doi:10.48550/arxiv 2023
-
[13]
Flex Attention: A Programming Model for Generating Optimized Attention Kernels
Juechu Dong et al. “Flex Attention: A Programming Model for Generating Optimized Attention Kernels”. In: arXiv preprint arXiv:2412.05496(2024).DOI: 10.48550/arXiv.2412.05496. arXiv: 2412.05496 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.05496 2024
-
[14]
Moritz Kiehn et al. “The TrackML high-energy physics tracking challenge on Kaggle”.European Physical Journal Web of Conferences. V ol. 214. European Physical Journal Web of Conferences. July 2019, 06037, p. 06037.DOI:10.1051/epjconf/201921406037
-
[15]
TrackML: A High Energy Physics Particle Tracking Challenge
Polo Calafiura et al. “TrackML: A High Energy Physics Particle Tracking Challenge”.2018 IEEE 14th Interna- tional Conference on e-Science (e-Science). 2018, pp. 344–344.DOI:10.1109/eScience.2018.00088
-
[16]
Locality-Sensitive Hashing-Based Efficient Point Transformer with Applications in High-Energy Physics
Siqi Miao et al. “Locality-Sensitive Hashing-Based Efficient Point Transformer with Applications in High-Energy Physics”.Proceedings of the 41st International Conference on Machine Learning (ICML). V ol. 235. PMLR
-
[17]
arXiv:2402.12535.URL:https://arxiv.org/abs/2402.12535
-
[18]
Locality-Sensitive Hashing-Based Efficient Point Transformer for Charged Particle Recon- struction
Shitij Govil et al. “Locality-Sensitive Hashing-Based Efficient Point Transformer for Charged Particle Recon- struction”.39th Annual Conference on Neural Information Processing Systems: Includes Machine Learning and the Physical Sciences (ML4PS). Oct. 2025. arXiv:2510.07594 [hep-ex]
arXiv 2025
-
[19]
IEEE Transactions on Neural Networks20(1), 61–80 (2008)
Franco Scarselli et al. “The Graph Neural Network Model”. In:IEEE Transactions on Neural Networks20.1 (2009), pp. 61–80.DOI:10.1109/TNN.2008.2005605
-
[20]
ATLAS Collaboration.Optimizations of the ATLAS ITk GNN Reconstruction Pipeline. Tech. rep. ATL-PHYS- PUB-2025-046. Geneva: CERN, 2025.URL:https://cds.cern.ch/record/2948192
arXiv 2025
-
[21]
LHC Machine
Lyndon Evans and Philip Bryant. “LHC Machine”. In:JINST3 (2008), S08001.DOI: 10 . 1088 / 1748 - 0221/3/08/S08001
2008
-
[22]
The ATLAS Experiment at the CERN Large Hadron Collider
ATLAS Collaboration. “The ATLAS Experiment at the CERN Large Hadron Collider”. In:JINST3 (2008), S08003.DOI:10.1088/1748-0221/3/08/S08003
-
[23]
The CMS Experiment at the CERN LHC
CMS Collaboration. “The CMS Experiment at the CERN LHC”. In:JINST3 (2008), S08004.DOI: 10.1088/ 1748-0221/3/08/S08004
2008
-
[24]
HybridNorm: Towards Stable and Efficient Transformer Training via Hybrid Normalization
Zhijian Zhuo et al. “HybridNorm: Towards Stable and Efficient Transformer Training via Hybrid Normalization”. In:arXiv preprint arXiv:2503.04598(2025).DOI: 10 . 48550 / arXiv . 2503 . 04598. arXiv: 2503 . 04598 [cs.LG]
arXiv 2025
-
[25]
GLU Variants Improve Transformer
Noam Shazeer. “GLU Variants Improve Transformer”. In:arXiv preprint arXiv:2002.05202(2020).DOI: 10.48550/arXiv.2002.05202. arXiv:2002.05202 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2002.05202 2002
-
[26]
Stefan Elfwing, Eiji Uchibe, and Kenji Doya. “Sigmoid-Weighted Linear Units for Neural Network Function Approximation in Reinforcement Learning”. In:Neural Networks107 (2018), pp. 3–11.DOI: 10.1016/j. neunet.2017.12.012. 18 Adapting Transformers for Efficient Sparse ReconstructionA PREPRINT
work page doi:10.1016/j 2018
-
[27]
Generalised Dice Overlap as a Deep Learning Loss Function for Highly Unbalanced Segmentations
Carole H. Sudre et al. “Generalised Dice Overlap as a Deep Learning Loss Function for Highly Unbalanced Segmentations”.Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support. V ol. 10553. Lecture Notes in Computer Science. Cham: Springer, 2017, pp. 240–248.DOI: 10.1007/ 978-3-319-67558-9_28. arXiv:1707.03237 [cs.CV]
Pith/arXiv arXiv 2017
-
[28]
Focal Loss for Dense Object Detection
Tsung-Yi Lin et al. “Focal Loss for Dense Object Detection”.Proceedings of the IEEE International Conference on Computer Vision (ICCV). 2017, pp. 2980–2988.DOI: 10.1109/ICCV.2017.324 . arXiv: 1708.02002 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/iccv.2017.324 2017
-
[29]
Algorithm 1015: A Fast Scalable Solver for the Dense Linear (Sum) Assignment Problem
Stefan Guthe and Daniel Thuerck. “Algorithm 1015: A Fast Scalable Solver for the Dense Linear (Sum) Assignment Problem”. In:ACM Trans. Math. Softw.47.2 (Apr. 2021).ISSN: 0098-3500.DOI: 10.1145/3442348. 19
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.