An Analysis of the Effectiveness of Synthetic Speech Data for ASR Fine-tuning in Selected Indic Languages
Pith reviewed 2026-06-26 23:09 UTC · model grok-4.3
The pith
Synthetic speech data augments real recordings to improve ASR fine-tuning for Hindi, Kannada and Telugu.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Incorporating synthetic speech data alongside real-world recordings for ASR fine-tuning in Hindi, Kannada, and Telugu produces performance gains that vary with script sources, synthesis models, and the number of distinct cloned voices used.
What carries the argument
The evaluation of ASR performance variation across script sources for synthesis, different speech synthesis models, and varying numbers of cloned voices in data generation.
If this is right
- Using multiple cloned voices may enhance diversity and thus ASR robustness.
- Script sources affect how well synthetic data matches real distributions.
- Different synthesis models lead to different levels of performance gain.
- Synthetic data can be selectively added based on these factors for better results.
Where Pith is reading between the lines
- If the gains are consistent, it could reduce data collection costs for other Indic languages.
- Future work might test if these findings generalize to more languages or larger models.
- The variation suggests careful selection of synthesis parameters is needed rather than blanket augmentation.
Load-bearing premise
The synthetic speech must be similar enough in distribution to real recordings that any performance changes can be attributed to the augmentation rather than mismatch in audio characteristics.
What would settle it
If experiments show no performance gain or gains that do not vary systematically with the tested factors when using synthetic data, the claim of effectiveness would be falsified.
Figures
read the original abstract
Synthetic data has the potential to be a valuable resource for training machine learning models, particularly Automatic Speech Recognition (ASR) Systems; however, its effectiveness requires systematic evaluation. In this study, we investigate the impact of incorporating synthetic speech data alongside real-world recordings for three Indic languages: Hindi, Kannada, and Telugu. We analyze the performance gains achieved by augmenting synthetic data with real data and independently examine how ASR performance varies with the sources of scripts used to generate synthetic speech. In addition, we evaluate the effect of synthetic speech generated using different speech synthesis models. Finally, we study the impact of voice cloning in synthetic speech generation on ASR performance, including how performance varies with the number of distinct cloned voices used during data generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically evaluates the effectiveness of augmenting real speech recordings with synthetic speech data for fine-tuning ASR models in Hindi, Kannada, and Telugu. It reports WER improvements on held-out test sets from controlled mixtures of real and synthetic data, with ablations examining variation by script source, synthesis model, and number of cloned voices, while controlling for total training duration.
Significance. If the reported WER deltas hold under the described controls, the work supplies practical, language-specific guidance on synthetic data augmentation for low-resource Indic ASR. The design isolates augmentation effects via real-only baselines and explicit duration matching, addressing the distribution-similarity assumption noted in the review. This is a useful contribution to multilingual ASR data strategies.
minor comments (2)
- The abstract describes the experimental factors but does not report any quantitative WER deltas, confidence intervals, or statistical tests; adding one or two key numerical results would improve the standalone readability of the abstract.
- Section headings and figure captions would benefit from explicit cross-references to the specific language and ablation (e.g., “Hindi, script-source ablation”) to help readers navigate the multi-language results.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity; purely empirical study
full rationale
The paper conducts controlled empirical comparisons of ASR fine-tuning performance using real vs. real+synthetic data mixtures for Hindi, Kannada, and Telugu. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the methodology or results. All reported gains are measured on held-out test sets with explicit controls for training duration and ablations over script sources, synthesis models, and voice count. The work is self-contained against external benchmarks with no load-bearing step that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Developing robust machine learning models, especially for speech-related tasks, requires access to large and diverse datasets
Introduction The process of speech data collection is both expensive and time-consuming [1][2]. Developing robust machine learning models, especially for speech-related tasks, requires access to large and diverse datasets. However, for many Indic languages, the availability of such data remains a significant challenge [3]. Although several initiatives hav...
-
[2]
Specifically, we used the Coqui TTS framework, based on the VITS architecture proposed by Kim et al
Synthetic Data Generation To generate synthetic speech data, we employed Text-to-Speech (TTS) models with voice cloning capabilities. Specifically, we used the Coqui TTS framework, based on the VITS architecture proposed by Kim et al. [11], which enables high-quality end-to- end neural speech synthesis with multilingual support. Hindi was natively support...
Pith/arXiv arXiv 2026
-
[3]
For all fine-tuning experiments, the Whisper models were trained using a learning rate of1×10−5 with 1,000 warmup steps
Experiments We evaluated performance gains using WER with the Whisper Small ASR model. For all fine-tuning experiments, the Whisper models were trained using a learning rate of1×10−5 with 1,000 warmup steps. Training was conducted for up to 20 epochs with a per-device batch size of 32, utilizing FP16 mixed preci- sion to optimize memory and compute effici...
1912
-
[4]
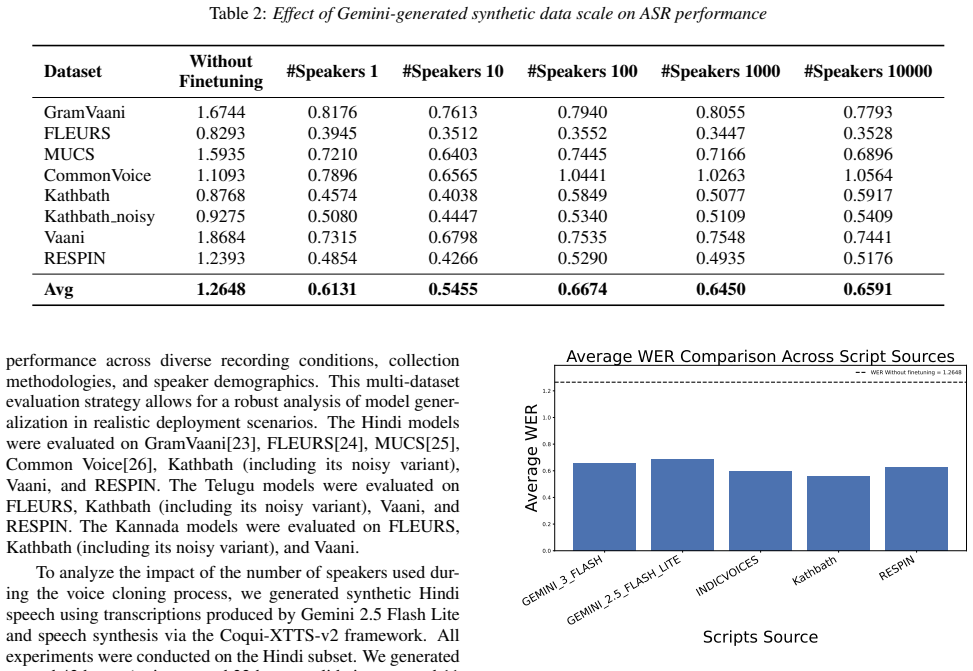
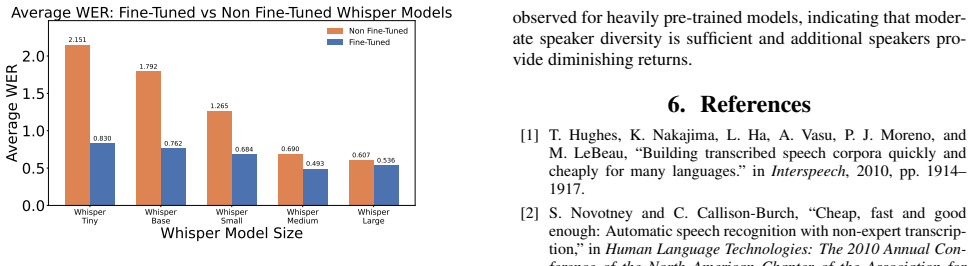
Results As shown in Table 1, the fine-tuned models consistently show performance improvements when augmented with synthetically generated data. For models trained on Vaani data, adding syn- thetic speech generated using RESPIN transcriptions reduces the average Word Error Rate (WER) by 15.06% for Hindi, 9.27% for Kannada, and 13.19% for Telugu. Although t...
-
[5]
However, the observed per- formance gains remain lower than those achieved using real- world data, highlighting the continued importance of authen- tic recordings
Conclusion From our experiments, it is evident that incorporating synthetic data leads to consistent improvements in ASR performance across all evaluated languages. However, the observed per- formance gains remain lower than those achieved using real- world data, highlighting the continued importance of authen- tic recordings. Additionally, the source and...
-
[6]
Building transcribed speech corpora quickly and cheaply for many languages
T. Hughes, K. Nakajima, L. Ha, A. Vasu, P. J. Moreno, and M. LeBeau, “Building transcribed speech corpora quickly and cheaply for many languages.” inInterspeech, 2010, pp. 1914– 1917
2010
-
[7]
Cheap, fast and good enough: Automatic speech recognition with non-expert transcrip- tion,
S. Novotney and C. Callison-Burch, “Cheap, fast and good enough: Automatic speech recognition with non-expert transcrip- tion,” inHuman Language Technologies: The 2010 Annual Con- ference of the North American Chapter of the Association for Computational Linguistics, 2010, pp. 207–215
2010
-
[8]
The state and fate of linguistic diversity and inclusion in the NLP world,
P. Joshi, S. Santy, A. Budhiraja, K. Bali, and M. Choudhury, “The state and fate of linguistic diversity and inclusion in the NLP world,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault, Eds. Online: Association for Computational Linguistics, Jul. 2020, pp. 6282...
2020
-
[9]
Census of india 2011: Language data,
Office of the Registrar General & Census Commissioner, India, “Census of india 2011: Language data,” https://censusindia.gov. in, 2011, government of India
2011
-
[10]
You do not need more data: Improving end- to-end speech recognition by text-to-speech data augmentation,
A. Laptev, R. Korostik, A. Svischev, A. Andrusenko, I. Meden- nikov, and S. Rybin, “You do not need more data: Improving end- to-end speech recognition by text-to-speech data augmentation,” in2020 13th International Congress on Image and Signal Pro- cessing, BioMedical Engineering and Informatics (CISP-BMEI). IEEE, 2020, pp. 439–444
2020
-
[11]
Using synthetic audio to improve the recognition of out-of-vocabulary words in end-to-end asr systems,
X. Zheng, Y . Liu, D. Gunceler, and D. Willett, “Using synthetic audio to improve the recognition of out-of-vocabulary words in end-to-end asr systems,” inICASSP 2021-2021 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 5674–5678
2021
-
[12]
E. Casanova, C. Shulby, A. Korolev, A. C. Junior, A. d. S. Soares, S. Alu ´ısio, and M. A. Ponti, “Asr data augmentation in low- resource settings using cross-lingual multi-speaker tts and cross- lingual voice conversion,”arXiv preprint arXiv:2204.00618, 2022
arXiv 2022
-
[13]
Hifi-gan: Generative adversarial net- works for efficient and high fidelity speech synthesis,
J. Kong, J. Kim, and J. Bae, “Hifi-gan: Generative adversarial net- works for efficient and high fidelity speech synthesis,”Advances in neural information processing systems, vol. 33, pp. 17 022– 17 033, 2020
2020
-
[14]
Is syn- thetic data truly effective for training speech language models?
T. Mizumoto, A. Kojima, Y . Fujita, L. Liu, and Y . Sudo, “Is syn- thetic data truly effective for training speech language models?” inProc. Interspeech 2025, 2025, pp. 1808–1812
2025
-
[15]
B. Hilmes, N. Rossenbachet al., “On the effect of purely synthetic training data for different automatic speech recognition architec- tures,”arXiv preprint arXiv:2407.17997, 2024
arXiv 2024
-
[16]
Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,
J. Kim, J. Kong, and J. Son, “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,” inPro- ceedings of the 38th International Conference on Machine Learn- ing (ICML), 2021
2021
-
[17]
Syspin s1.0 corpus – a tts corpus of 900+ hours in nine indian languages,
A. et. al., “Syspin s1.0 corpus – a tts corpus of 900+ hours in nine indian languages,” 2025. [Online]. Available: https://spiredatasets.ee.iisc.ac.in/syspincorpus
2025
-
[18]
Respin- s1. 0: A read speech corpus of 10000+ hours in dialects of nine in- dian languages,
S. Kumar, A. Singh, J. Bandekar, S. Murthy, S. Sharma, S. Badi- ger, S. Udupa, A. Nagireddi, S. R. KM, R. Saxenaet al., “Respin- s1. 0: A read speech corpus of 10000+ hours in dialects of nine in- dian languages,” inThe Thirty-ninth Annual Conference on Neu- ral Information Processing Systems Datasets and Benchmarks Track, 2024
2024
-
[19]
Indicvoices: Towards building an inclusive multilingual speech dataset for indian languages,
T. Javed, J. Nawale, E. George, S. Joshi, K. Bhogale, D. Mehen- dale, I. Sethi, A. Ananthanarayanan, H. Faquih, P. Palitet al., “Indicvoices: Towards building an inclusive multilingual speech dataset for indian languages,” inFindings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 10 740–10 782
2024
-
[20]
Indicsuperb: A speech processing universal performance benchmark for indian languages,
T. Javed, K. Bhogale, A. Raman, P. Kumar, A. Kunchukuttan, and M. M. Khapra, “Indicsuperb: A speech processing universal performance benchmark for indian languages,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 11, 2023, pp. 12 942–12 950
2023
-
[21]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen et al., “Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabil- ities,”arXiv preprint arXiv:2507.06261, 2025
Pith/arXiv arXiv 2025
-
[22]
A new era of intelligence with gemini 3,
Gemini Team, “A new era of intelligence with gemini 3,” https://blog.google/products-and-platforms/products/gemini/ gemini-3/, November 2025
2025
-
[23]
Rasmalai : Resources for Adap- tive Speech Modeling in IndiAn Languages with Accents and In- tonations,
A. Sankar, Y . Lacombe, S. Thomas, P. Srinivasa Varadhan, S. Gandhi, and M. M. Khapra, “Rasmalai : Resources for Adap- tive Speech Modeling in IndiAn Languages with Accents and In- tonations,” inInterspeech 2025, 2025, pp. 4128–4132
2025
-
[24]
Parler-tts,
Y . Lacombe, V . Srivastav, and S. Gandhi, “Parler-tts,” https: //github.com/huggingface/parler-tts, 2024
2024
-
[25]
Natural language guidance of high-fidelity text-to-speech with synthetic annotations,
D. Lyth and S. King, “Natural language guidance of high-fidelity text-to-speech with synthetic annotations,” 2024
2024
-
[26]
Indri: Multimodal audio language model,
11mlabs, “Indri: Multimodal audio language model,” https:// github.com/indri-voice/indri, 2024
2024
-
[27]
Vaani: Capturing the language landscape for an inclusive digital india,
S. Pulikodan, A. Singh, A. Basu, N. Desai, P. K. J, P. D. Bhat, R. Dharmaraju, R. Gupta, S. Udupa, S. Kumar, S. Sharma, V . Sanka, D. Tewari, H. Dhand, A. Kamat, S. Singh, S. Vashishth, P. Talukdar, R. Acharya, and P. K. Ghosh, “Vaani: Capturing the language landscape for an inclusive digital india,” 2026. [Online]. Available: https://arxiv.org/abs/2603.28714
Pith/arXiv arXiv 2026
-
[28]
Gram vaani asr challenge on spontaneous telephone speech recordings in regional variations of hindi,
A. Bhanushali, G. Bridgman, P. Ghosh, P. Kumar, S. Kumar, A. Raj Kolladath, N. Ravi, A. Seth, A. Seth, A. Singhet al., “Gram vaani asr challenge on spontaneous telephone speech recordings in regional variations of hindi,” inProc. Interspeech 2022, 2022, pp. 3548–3552
2022
-
[29]
Fleurs: Few-shot learning evaluation of universal representations of speech,
A. Conneau, M. Ma, S. Khanuja, Y . Zhang, V . Axelrod, S. Dalmia, J. Riesa, C. Rivera, and A. Bapna, “Fleurs: Few-shot learning evaluation of universal representations of speech,” in2022 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2023, pp. 798–805
2023
-
[30]
Mucs 2021: Multilingual and code-switching asr challenges for low resource indian languages,
A. Diwan, R. Vaideeswaran, S. Shah, A. Singh, S. Raghavan, S. Khare, V . Unni, S. Vyas, A. Rajpuria, C. Yarra, A. Mittal, P. K. Ghosh, P. Jyothi, K. Bali, V . Seshadri, S. Sitaram, S. Bharadwaj, J. Nanavati, R. Nanavati, and K. Sankaranarayanan, “Mucs 2021: Multilingual and code-switching asr challenges for low resource indian languages,” inInterspeech 20...
2021
-
[31]
Com- mon voice: A massively-multilingual speech corpus,
R. Ardila, M. Branson, K. Davis, M. Kohler, J. Meyer, M. Hen- retty, R. Morais, L. Saunders, F. Tyers, and G. Weber, “Com- mon voice: A massively-multilingual speech corpus,” inProceed- ings of the twelfth language resources and evaluation conference, 2020, pp. 4218–4222
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.