Recover, Discover, Plan: Learning Skills and Concepts from Robot Failures
Pith reviewed 2026-06-27 00:11 UTC · model grok-4.3
The pith
ReSYNC turns robot failure recoveries into relational predicates that support abstract planning for unseen long-horizon tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
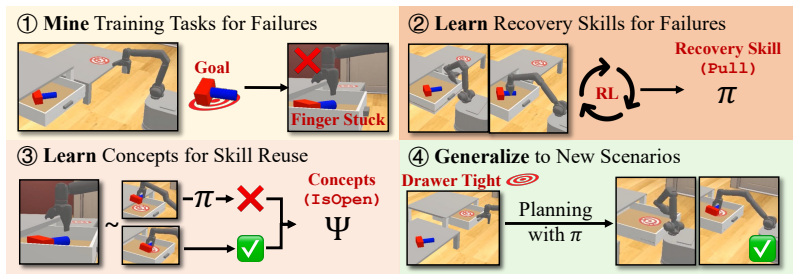
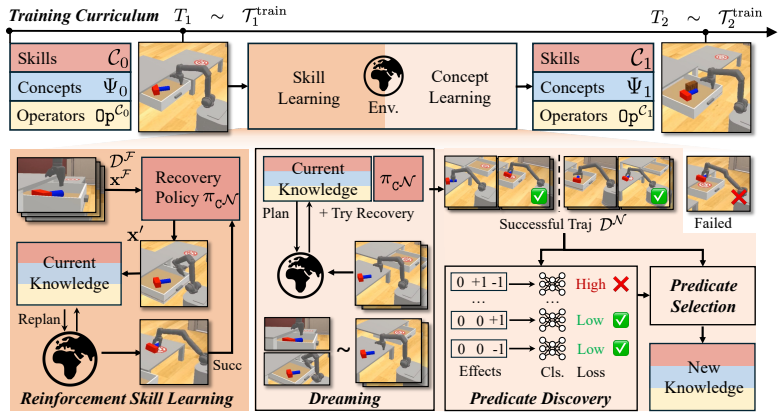
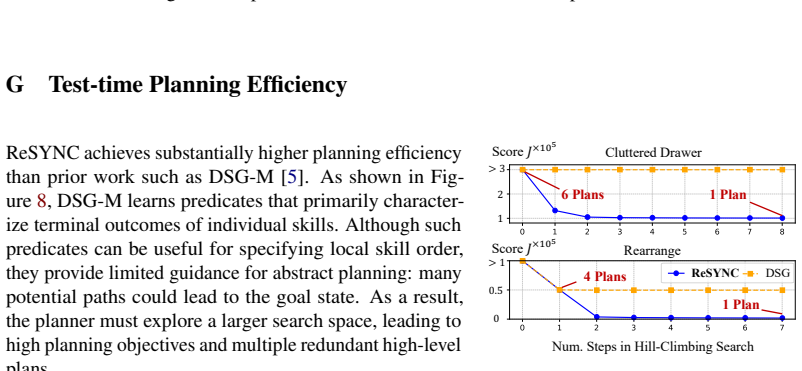
ReSYNC performs an incremental dual-learning process in which reinforcement learning acquires recovery skills from observed failures and a subsequent concept-learning stage discovers new relational predicates that explain and generalize those recoveries. The discovered predicates are incorporated into an abstract planning model that the robot uses at test time to solve previously unseen long-horizon tasks. Across four simulated domains the method solves more problems than strong baselines and achieves over 50 percent higher success rates; the same learned abstractions also support sim-to-real transfer on non-prehensile manipulation tasks.
What carries the argument
ReSYNC's incremental dual-learning loop that alternates RL-based recovery skill acquisition with predicate discovery and refinement to expand an abstraction library for abstract planning.
If this is right
- The robot solves long-horizon problems that were never seen in training by using the expanded predicate library for abstract planning.
- No separate recovery policy needs to be trained for each distinct failure mode.
- The same learned predicates enable generalization to unseen scenarios in both simulation and real-robot non-prehensile manipulation.
- Continual expansion of the abstraction library improves performance over time without restarting from scratch.
Where Pith is reading between the lines
- Manual engineering of state abstractions for planning could be reduced if the discovery process scales to richer sensor data.
- The same loop might be applied to domains where failures are expensive, by first learning recoveries in simulation and then transferring the resulting predicates.
- Incorrect predicates could propagate planning errors unless an explicit verification step is added later.
Load-bearing premise
The discovered relational predicates will be sufficiently accurate and complete to support reliable planning on tasks outside the specific failures seen during training.
What would settle it
A new long-horizon test task whose solution requires a predicate that was never discovered or refined during the training failures, causing the abstract planner to produce an incorrect or incomplete plan.
Figures





read the original abstract
Intelligent robots should not only recover from failures, but also acquire the abstract knowledge needed to avoid them in the future. While reinforcement learning (RL) can learn reactive recovery behaviors, training a separate policy for every distinct failure mode is highly inefficient. We introduce Recovery-Driven Synthesis of Relational Concepts (ReSYNC), the first approach that progressively discovers and refines state abstractions (relational predicates) from failure-recovery experience to support abstract planning. Unlike purely reactive methods, ReSYNC jointly learns skills and concepts through an incremental dual-learning process. In the skill-learning phase, the robot uses RL to learn to recover from failures seen in training tasks. In the concept-learning phase, the robot discovers new relational predicates and refines its abstract planning model to explain and generalize the learned recovery behaviors. This interaction enables ReSYNC to convert local recoveries seen during training into global failure avoidance at test time. Across four simulated domains, we show that ReSYNC's ability to continually expand and refine its abstraction library allows it to solve long-horizon, previously unseen problems, outperforming strong baselines by over 50%. Additionally, we demonstrate sim-to-real transfer of ReSYNC, where it performs real-world non-prehensile manipulation skills and generalizes to unseen scenarios through abstract planning. Overall, ReSYNC represents a significant step toward robots that autonomously acquire abstractions for scalable, failure-aware planning in the physical world.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReSYNC, an incremental dual-learning framework in which RL is used to acquire recovery skills from observed failures and a concept-learning phase discovers and refines relational predicates that support abstract planning. The interaction between the two phases is claimed to convert local recoveries into global failure-avoidance policies that solve long-horizon, previously unseen tasks. Empirical results are reported across four simulated domains (outperforming strong baselines by more than 50 %) together with a sim-to-real demonstration of non-prehensile manipulation and generalization to unseen scenarios.
Significance. If the empirical claims are substantiated, the work would constitute a meaningful contribution to integrated learning and planning in robotics by showing how failure-recovery experience can be turned into reusable relational abstractions without hand-crafted predicates. The reported performance margin and the sim-to-real transfer are concrete strengths that would be of interest to the robotics community.
minor comments (2)
- [Abstract] The abstract states that ReSYNC 'outperforms strong baselines by over 50 %' but does not name the baselines, the performance metric, or the statistical test used; the results section of the full manuscript should supply these details.
- [Abstract] The description of the concept-learning phase does not indicate how predicate accuracy or sufficiency is verified before the predicates are added to the planning model; if this validation procedure is described later in the paper it should be cross-referenced from the abstract.
Simulated Author's Rebuttal
We thank the referee for their careful summary of ReSYNC and for noting the potential contribution of turning failure-recovery experience into reusable relational abstractions. The recommendation is listed as uncertain, but the report contains no enumerated major comments. We therefore provide no point-by-point responses below. If the referee has additional specific concerns, we are happy to address them in a revision.
Circularity Check
No significant circularity
full rationale
The paper presents an empirical method (ReSYNC) combining RL-based skill recovery with predicate discovery for abstract planning. No equations, derivations, or fitted parameters are described in the provided text that reduce a claimed prediction or result to its own inputs by construction. The performance claims rest on experimental outcomes across domains rather than any self-referential theoretical step. No self-citation load-bearing arguments or uniqueness theorems are invoked in the abstract or description. The derivation chain is self-contained as an algorithmic process whose validity is tested externally via simulation and real-world transfer.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Javed and R
K. Javed and R. S. Sutton. The Big World Hypothesis and Its Ramifications for Artificial Intelligence. InFinding the Frame: An RLC Workshop for Examining Conceptual Frameworks, 2024
2024
-
[2]
S. Vats, M. Likhachev, and O. Kroemer. Efficient Recovery Learning using Model Predictive Meta-Reasoning. InProceedings of the International Conference on Robotics and Automation (ICRA), pages 7258–7264, 2023
2023
- [3]
-
[4]
Bagaria, J
A. Bagaria, J. K. Senthil, and G. Konidaris. Skill Discovery for Exploration and Planning using Deep Skill Graphs. InProceedings of International Conference on Machine Learning (ICML), pages 521–531. PMLR, 2021
2021
-
[5]
Bagaria, A
A. Bagaria, A. D. M. Koch, R. Rodriguez-Sanchez, S. Lobel, and G. Konidaris. Intrinsically Motivated Discovery of Temporally Abstract Graph-based Models of the World. InProceedings of Reinforcement Learning Conference, 2025
2025
-
[6]
A. Li, N. Kumar, T. Lozano-P´erez, and L. P. Kaelbling. Learning to Bridge the Gap: Efficient Novelty Recovery with Planning and Reinforcement Learning. InNeurIPS 2024 Workshop on Open-World Agents, 2024
2024
-
[7]
Silver, R
T. Silver, R. Chitnis, N. Kumar, W. McClinton, T. Lozano-P ´erez, L. Kaelbling, and J. B. Tenenbaum. Predicate Invention for Bilevel Planning. InProceedings of The AAAI Conference on Artificial Intelligence (AAAI), volume 37, pages 12120–12129, 2023
2023
- [8]
-
[9]
B. Li, T. Silver, S. Scherer, and A. Gray. Bilevel Learning for Bilevel Planning. InProceedings of the Robotics: Science And Systems (RSS), 2025
2025
-
[10]
Silver, A
T. Silver, A. Athalye, J. B. Tenenbaum, T. Lozano-P´erez, and L. P. Kaelbling. Learning Neuro- Symbolic Skills for Bilevel Planning. InProceedings of the Conference on Robot Learning (CoRL), 2022
2022
- [11]
-
[12]
Y . S. Shao, Y . Zheng, S. Sun, P. Chaudhari, V . Kumar, and N. Figueroa. Symskill: Symbol and Skill Co-Invention for Data-Efficient and Real-Time Long-Horizon Manipulation.arXiv preprint arXiv:2510.01661, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
D. Abel, D. Arumugam, L. Lehnert, and M. Littman. State abstractions for lifelong reinforce- ment learning. InInternational Conference on Machine Learning. PMLR, 2018
2018
-
[14]
Eysenbach, A
B. Eysenbach, A. Gupta, J. Ibarz, and S. Levine. Diversity is all you need: Learning skills without a reward function. InInternational Conference on Learning Representations, 2019
2019
-
[15]
R. K. Nayyar and S. Srivastava. Autonomous Option Invention for Continual Hierarchical Reinforcement Learning and Planning. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), volume 39, pages 19642–19650, 2025
2025
-
[16]
Shukla, S
A. Shukla, S. Tao, and H. Su. Maniskill-hab: A benchmark for low-level manipulation in home rearrangement tasks. InProceedings of the International Conference on Learning Representations (ICLR), 2025. 10
2025
-
[17]
P. W. Battaglia, J. B. Hamrick, V . Bapst, A. Sanchez-Gonzalez, V . Zambaldi, M. Malinowski, A. Tacchetti, D. Raposo, A. Santoro, R. Faulkner, et al. Relational Inductive Biases, Deep Learning, and Graph Networks.arXiv preprint arXiv:1806.01261, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is All You Need. InProceedings of the Advances in Neural Information Processing Systems (NeurIPS), volume 30, 2017
2017
-
[19]
GPT-5.4 Thinking System Card, Mar
OpenAI. GPT-5.4 Thinking System Card, Mar. 2026. URL https://openai.com/index/ gpt-5-4-thinking-system-card/
2026
-
[20]
L. P. Kaelbling and T. Lozano-P ´erez. Hierarchical Task and Motion Planning in the Now. InProceedings of the International Conference on Robotics and Automation (ICRA), pages 1470–1477. IEEE, 2011
2011
-
[21]
C. R. Garrett, T. Lozano-P´erez, and L. P. Kaelbling. Pddlstream: Integrating Symbolic Planners and Blackbox Samplers via Optimistic Adaptive Planning. InProceedings of the International Conference on Automated Planning and Scheduling (ICAPS), volume 30, pages 440–448, 2020
2020
-
[22]
Chitnis, T
R. Chitnis, T. Silver, J. B. Tenenbaum, T. Lozano-P´erez, and L. P. Kaelbling. Learning Neuro- Symbolic Relational Transition Models for Bilevel Planning. InProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4166–4173, 2022
2022
-
[23]
Kumar, T
N. Kumar, T. Silver, W. McClinton, L. Zhao, S. Proulx, T. Lozano-P´erez, L. P. Kaelbling, and J. Barry. Practice Makes Perfect: Planning To Learn Skill Parameter Policies. InProceedings of the Robotics: Science And Systems (RSS), 2024
2024
-
[24]
Konidaris, L
G. Konidaris, L. P. Kaelbling, and T. Lozano-P´erez. From skills to symbols: Learning symbolic representations for abstract high-level planning.Journal of Artificial Intelligence Research (JAIR), 2018
2018
- [25]
-
[26]
R. S. Sutton, D. Precup, and S. Singh. Between MDPs and Semi-MDPs: A Framework for Temporal Abstraction in Reinforcement Learning.Artificial intelligence, 1999
1999
-
[27]
Bacon, J
P.-L. Bacon, J. Harb, and D. Precup. The option-critic architecture. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), volume 31, 2017
2017
-
[28]
Zhang and S
S. Zhang and S. Whiteson. DAC: The Double Actor-Critic Architecture for Learning Options. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), volume 32, 2019
2019
-
[29]
S. Moon, J. Yeom, B. Park, and H. O. Song. Discovering Hierarchical Achievements in Reinforcement Learning via Contrastive Learning. InProceedings of the Advances in Neural Information Processing Systems (NeurIPS), volume 36, pages 63674–63686, 2023
2023
-
[30]
Eysenbach, T
B. Eysenbach, T. Zhang, S. Levine, and R. R. Salakhutdinov. Contrastive Learning as Goal- Conditioned Reinforcement Learning. InProceedings of the Advances in Neural Information Processing Systems (NeurIPS), volume 35, pages 35603–35620, 2022
2022
-
[31]
Eysenbach, R
B. Eysenbach, R. Salakhutdinov, and S. Levine. Search on the Replay Buffer: Bridging Planning and Reinforcement Learning. InProceedings of the Advances in Neural Information Processing Systems (NeurIPS), volume 32, 2019
2019
-
[32]
Semi-parametric Topological Memory for Navigation
N. Savinov, A. Dosovitskiy, and V . Koltun. Semi-Parametric Topological Memory for Naviga- tion.arXiv preprint arXiv:1803.00653, 2018. 11
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
F. Yang, D. Lyu, B. Liu, and S. Gustafson. PEORL: Integrating Symbolic Planning and Hierarchical Reinforcement Learning for Robust Decision-Making. InProceedings of the International Joint Conference on Artificial Intelligence (IJCAI), pages 4860–4866, 2018
2018
-
[34]
Y . Jiang, F. Yang, S. Zhang, and P. Stone. Integrating Task-Motion Planning with Reinforcement Learning for Robust Decision Making in Mobile Robots.arXiv preprint arXiv:1811.08955, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[35]
V . Sarathy, D. Kasenberg, S. Goel, J. Sinapov, and M. Scheutz. Spotter: Extending Symbolic Planning Operators through Targeted Reinforcement Learning.arXiv preprint arXiv:2012.13037, 2020
-
[36]
S. Goel, Y . Shukla, V . Sarathy, M. Scheutz, and J. Sinapov. Rapid-learn: A Framework for Learning to Recover for Handling Novelties in Open-world Environments. In2022 IEEE International Conference on Development and Learning (ICDL), pages 15–22. IEEE, 2022
2022
-
[37]
Aeronautiques, A
C. Aeronautiques, A. Howe, C. Knoblock, I. D. McDermott, A. Ram, M. Veloso, D. Weld, D. W. Sri, A. Barrett, D. Christianson, et al. Pddl—the planning domain definition language. Technical Report, Tech. Rep., 1998
1998
-
[38]
M. Helmert. The Fast Downward Planning System.Journal of Artificial Intelligence Research, 26:191–246, 2006
2006
-
[39]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal Policy Optimization Algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
KinDER: A Physical Reasoning Benchmark for Robot Learning and Planning
Y . Huang, B. Li, V . Saxena, Y . Liang, U. A. Mishra, L. Ji, L. Zha, J. Wu, N. Kumar, S. Scherer, et al. KinDER: A Physical Reasoning Benchmark for Robot Learning and Planning.arXiv preprint arXiv:2604.25788, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
P. Yin, T. Westenbroek, Z. Zhang, J. Tran, I. Dagnino, E. Shilamkar, N. Mbiziwo-Tiapo, S. Bagaria, X. Liu, G. Mullins, A. Kolobov, and A. Gupta. Emergent Dexterity via Diverse Resets and Large-Scale Reinforcement Learning. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[42]
F. Bjelonic, F. Tischhauser, and M. Hutter. Towards Bridging the Gap: Systematic Sim-to-Real Transfer for Diverse Legged Robots.arXiv preprint arXiv:2509.06342, 2025
-
[43]
Solving Rubik's Cube with a Robot Hand
I. Akkaya, M. Andrychowicz, M. Chociej, M. Litwin, B. McGrew, A. Petron, A. Paino, M. Plappert, G. Powell, R. Ribas, et al. Solving Rubik’s Cube with a Robot Hand.arXiv preprint arXiv:1910.07113, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[44]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion Policy: Visuomotor Policy Learning via Action Diffusion. InRobotics: Science and Systems (RSS), 2023
2023
-
[45]
SAM 3: Segment Anything with Concepts
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huang, et al. SAM 3: Segment Anything with Concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
P. Liu, L. P. Kaelbling, J. B. Tenenbaum, and J. Mao. Lifelong Experience Abstraction and Planning. InICML 2025 Workshop on Programmatic Representations for Agent Learning, 2025
2025
-
[47]
M. Fu, J. Yu, K. El-Refai, E. Kou, H. Xue, H. Huang, W. Xiao, G. Wang, F.-F. Li, G. Shi, et al. CaP-X: A Framework for Benchmarking and Improving Coding Agents for Robot Manipulation. arXiv preprint arXiv:2603.22435, 2026. 12
work page internal anchor Pith review arXiv 2026
-
[48]
R. Zabounidis, Y . Wu, S. Stepputtis, W. Kim, Y . Li, T. Mitchell, and K. Sycara. SCALAR: Learn- ing and Composing Skills through LLM Guided Symbolic Planning and Deep RL Grounding. arXiv preprint arXiv:2603.09036, 2026
-
[49]
J. Luo, T. Ding, K. H. R. Chan, H. Min, C. Callison-Burch, and R. Vidal. Concept Lancet: Image Editing with Compositional Representation Transplant. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 28502–28512, 2025
2025
-
[50]
J. Luo, J. Yang, T. Neiman, L. Fan, B. Yin, S. Tran, M. Shah, and R. Vidal. Dictionary-Aligned Concept Control for Safeguarding Multimodal LLMs.arXiv preprint arXiv:2604.08846, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
A. Athalye, N. Kumar, T. Silver, Y . Liang, T. Lozano-P´erez, and L. P. Kaelbling. Predicate Invention from Pixels via Pretrained Vision-Language Models.arXiv preprint arXiv:2501.00296, 2024
-
[52]
N. Kumar, W. Shen, F. Ramos, D. Fox, T. Lozano-P´erez, L. P. Kaelbling, and C. R. Garrett. Open-World Task and Motion Planning via Vision-Language Model Generated Constraints. IEEE Robotics and Automation Letters (RA-L), 11:3366–3373, 2026. URL https://arxiv. org/abs/2411.08253
-
[53]
J. Duan, W. Pumacay, N. Kumar, Y . R. Wang, S. Tian, W. Yuan, R. Krishna, D. Fox, A. Man- dlekar, and Y . Guo. AHA: A Vision-Language-Model for Detecting and Reasoning Over Failures in Robotic Manipulation. InProceedings of the International Conference on Learning Representations (ICLR), 2025. URLhttps://arxiv.org/abs/2410.00371
- [54]
-
[55]
C. Xu, T. K. Nguyen, E. Dixon, C. Rodriguez, P. Miller, R. Lee, P. Shah, R. Ambrus, H. Nishimura, and M. Itkina. Can we detect failures without failure data? uncertainty-aware runtime failure detection for imitation learning policies. InProceedings of the Robotics: Science And Systems (RSS), 2025
2025
-
[56]
Z. Yang, B. Hedegaard, A. Jaafar, Y . Wei, S. Thompson, S. S. Raman, H. Fu, S. Tellex, G. Konidaris, D. Paulius, et al. SkillWrapper: Generative Predicate Invention for Skill Abstrac- tion.arXiv preprint arXiv:2511.18203, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Z. Yang, J. Mao, Y . Du, J. Wu, J. B. Tenenbaum, T. Lozano-P ´erez, and L. P. Kaelbling. Compositional Diffusion-Based Continuous Constraint Solvers. InConference on Robot Learning (CoRL), 2023. URLhttps://arxiv.org/pdf/2309.00966.pdf. 13 Table 4: Important notations used in this work. Symbol Description x∈ XContinuous world state; state space xo Feature ...
-
[58]
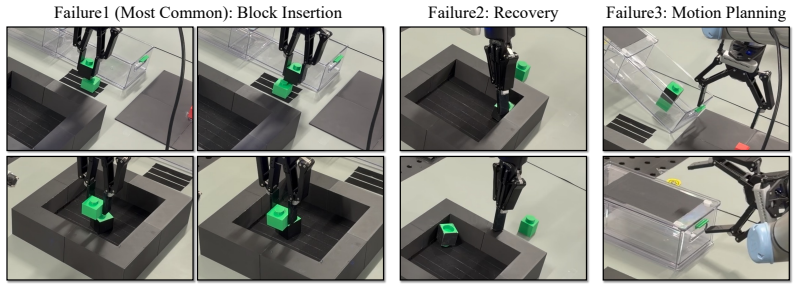
One block is initially placed near a box corner, causing the nominal insertion behavior to fail
Cornered Insertion-S.A UR7e arm with a Robotiq 2F-140 gripper must insert one block onto another to form a tower. One block is initially placed near a box corner, causing the nominal insertion behavior to fail. Train and test tasks differ in goal specification. • State and actions:States are SE(3) object poses, estimated from wrist-camera scans using SAM3...
-
[59]
overfitting
Cornered Insertion-L.This domain uses the same hardware setup but adds a lid and a drawer, requiring the robot to place the completed tower into the drawer. Although it shares the recovery skill with Cornered Insertion-S, its task structure leads to different discovered concepts and planning operators. •State and actions:Same as Cornered Insertion-S. •Obj...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.