From Tokens to Energy Flexibility: Quantization-Enabled Demand Response for Data Centers with LLM Inference Workloads
Pith reviewed 2026-06-26 19:39 UTC · model grok-4.3
The pith
Model quantization serves as a dispatchable resource that cuts LLM data center operating costs by 34.3 percent in demand response without reducing token output.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
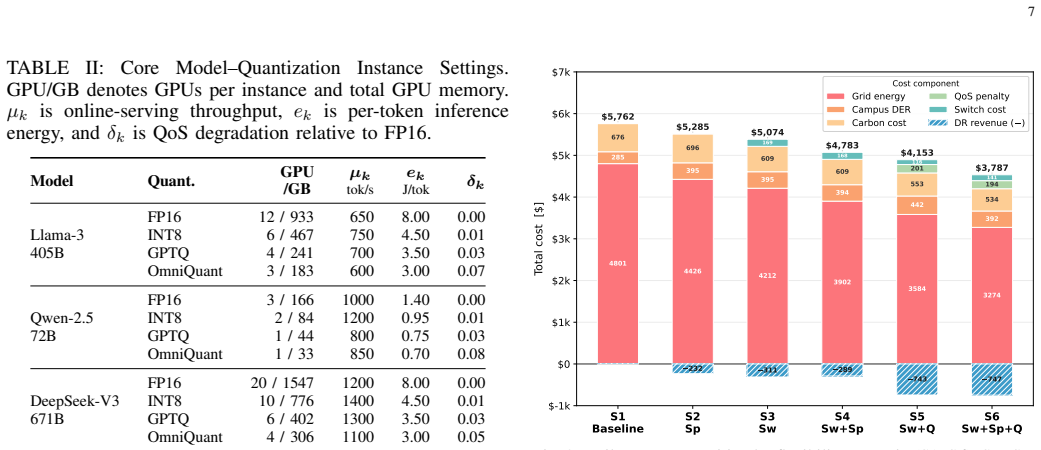
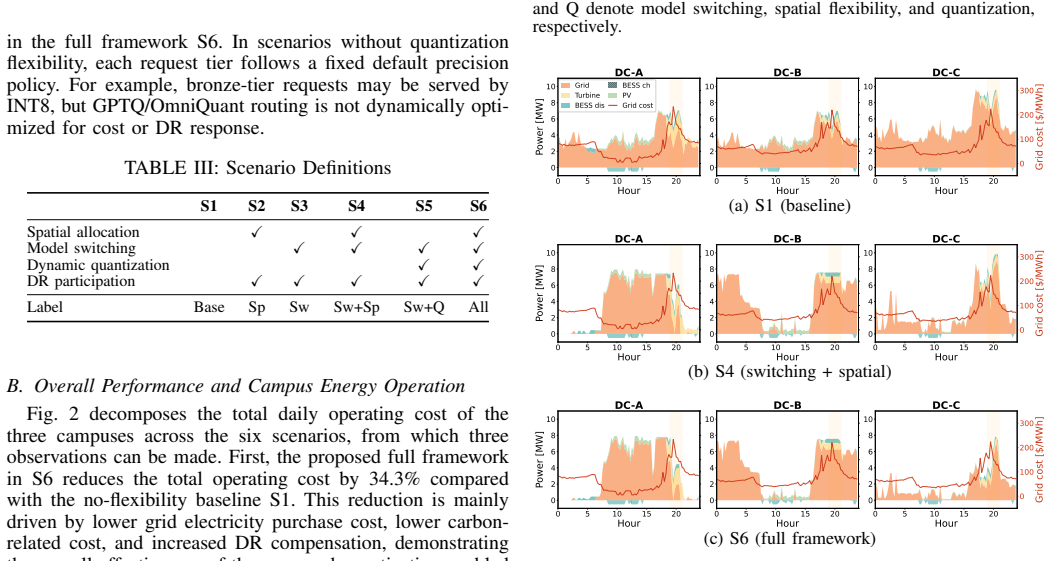
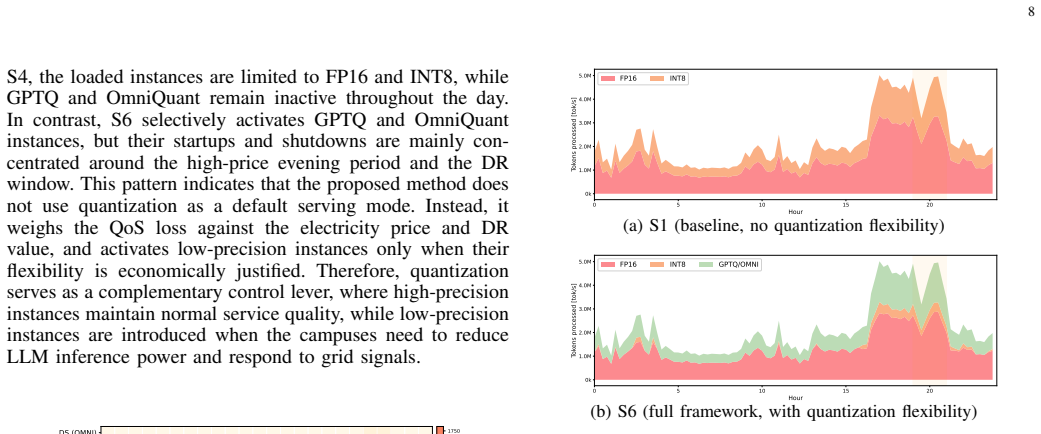
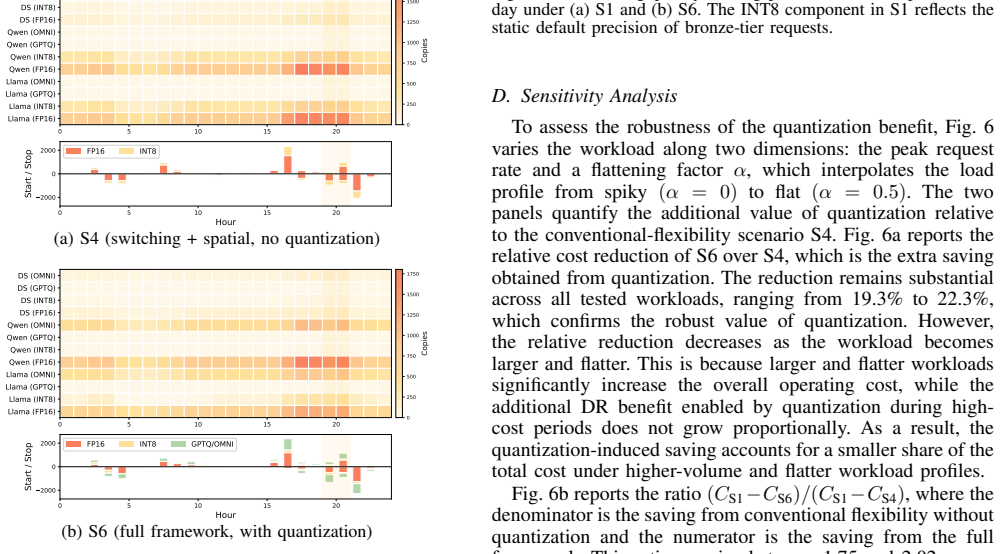
By mapping quantization configurations to a set of dispatchable parameters and embedding them in a two-stage demand-response optimization that includes instance switching and routing, the framework enables LLM data centers to reduce total operating costs by 34.3% while serving the same token volume.
What carries the argument
The quantization-to-power model that converts each model-quantization configuration into dispatchable parameters for use in the DR optimization.
If this is right
- Data centers can adjust LLM precision to respond to grid conditions.
- Operating costs drop 34.3% with no loss in token service.
- Multi-campus coordination incorporates both cost and carbon signals.
- Model quantization becomes a viable alternative to workload shifting for energy management.
Where Pith is reading between the lines
- Similar quantization approaches could apply to other compute-intensive AI tasks like image generation.
- Grid operators might design new tariffs that reward variable-precision computing.
- Hardware accelerators optimized for rapid precision switching could amplify the savings.
Load-bearing premise
The established quantization-to-power model accurately predicts power usage and performance for each configuration without significant unaccounted effects on latency or accuracy.
What would settle it
Deployment measurements showing that actual power consumption deviates substantially from the model's predictions or that token latency increases beyond service level agreements when quantization is adjusted for demand response.
Figures

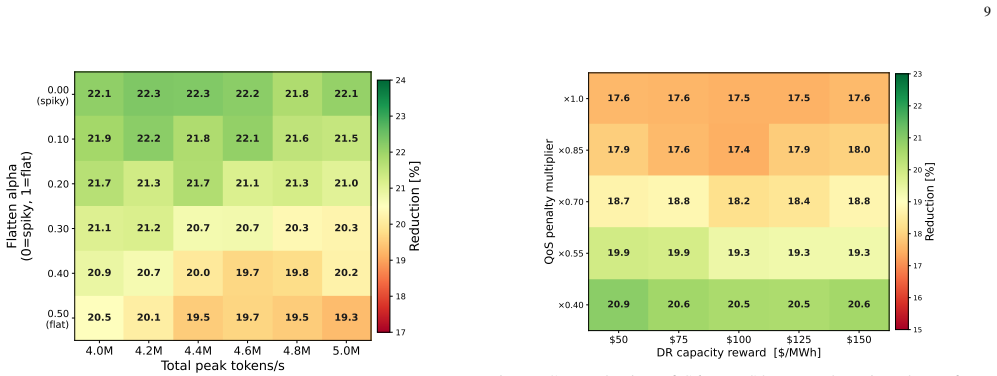
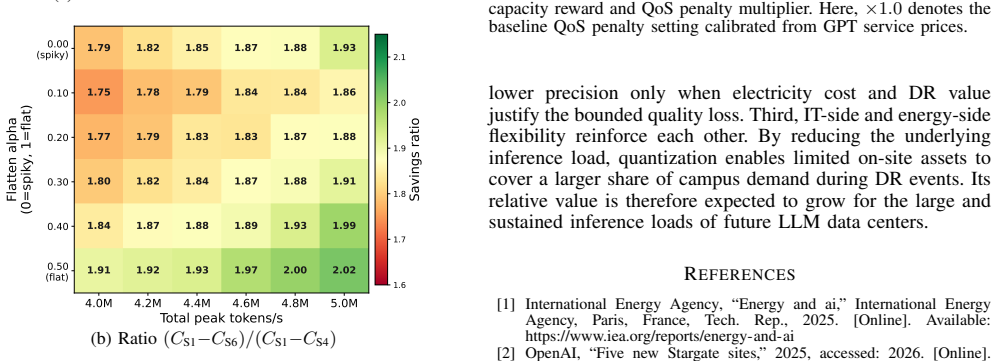
read the original abstract
The rapid growth of large language model (LLM) inference is creating significant data-center loads that face increasing energy-management challenges under tightening grid conditions and demand response (DR) requirements. Conventional data-center energy management mainly relies on temporal and spatial workload shifting and campus-level energy asset scheduling, but it usually treats LLM inference demand as an aggregate load. As a result, these approaches fail to exploit the internal characteristics of LLM serving and therefore overlook the flexibility offered by LLM-specific techniques such as model quantization. To unlock this flexibility, this paper proposes a quantization-enabled energy management framework for grid-responsive LLM inference data centers. First, a quantization-to-power model is established to map each model--quantization configuration to a compact set of dispatchable parameters. Second, a two-stage quantization-enabled DR model is developed to account for model instance switching, request routing, and precision selection. Third, a multi-campus co-optimization method is introduced for DR participation by integrating grid-side electricity and carbon signals with the quantization-enabled DR model. Case studies show that the proposed framework reduces total data-center operating cost by 34.3\% without curtailing served token volume, validating model quantization as an effective flexibility lever for grid-responsive LLM data-center energy management.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a quantization-enabled energy management framework for LLM inference data centers participating in demand response. It first establishes a quantization-to-power model mapping model-quantization configurations to dispatchable parameters, then develops a two-stage DR optimization incorporating instance switching, request routing, and precision selection, and finally introduces multi-campus co-optimization using grid electricity and carbon signals. Case studies are reported to achieve a 34.3% reduction in total operating cost without curtailing served token volume.
Significance. If the quantization-to-power model is shown to be accurate under dynamic request rates and the case-study schedules prove feasible, the work would demonstrate a new, LLM-specific flexibility resource that integrates directly with existing DR mechanisms, potentially expanding the set of controllable loads available to grid operators.
major comments (2)
- [Abstract (framework description)] The central 34.3% cost-reduction result rests on the quantization-to-power model (first step of the framework) producing accurate dispatchable parameters that fully capture any latency or throughput effects from precision changes. No derivation, measurement protocol, or validation against dynamic workloads is described, so it is impossible to assess whether the two-stage DR optimization overstates available flexibility.
- [Abstract (case studies)] The multi-campus co-optimization inherits the same limitation: if the per-configuration power and performance parameters are not validated under time-varying request rates, the reported cost savings without token curtailment cannot be confirmed as operationally achievable.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. The two major comments correctly identify a gap in the exposition of the quantization-to-power model. We address each point below and will revise the manuscript to provide the requested derivation, protocol, and validation details.
read point-by-point responses
-
Referee: [Abstract (framework description)] The central 34.3% cost-reduction result rests on the quantization-to-power model (first step of the framework) producing accurate dispatchable parameters that fully capture any latency or throughput effects from precision changes. No derivation, measurement protocol, or validation against dynamic workloads is described, so it is impossible to assess whether the two-stage DR optimization overstates available flexibility.
Authors: We agree that the manuscript does not provide sufficient detail on the derivation of the quantization-to-power model or its validation under dynamic workloads. In the revised version we will expand the model-development section to include: (i) the analytical derivation mapping quantization bit-widths to the dispatchable power, latency, and throughput parameters; (ii) the measurement protocol (hardware platform, workload generator, and data-collection procedure); and (iii) additional empirical validation results obtained under time-varying request-rate traces that confirm the parameters capture latency and throughput effects. These additions will allow readers to evaluate whether the two-stage optimization overstates flexibility. revision: yes
-
Referee: [Abstract (case studies)] The multi-campus co-optimization inherits the same limitation: if the per-configuration power and performance parameters are not validated under time-varying request rates, the reported cost savings without token curtailment cannot be confirmed as operationally achievable.
Authors: We concur that the multi-campus results rest on the same unvalidated parameters. The expanded model section described above will directly support the case-study claims. In addition, we will augment the case-study section with a sensitivity analysis that re-optimizes the schedules under perturbed request-rate traces and reports the resulting cost and token-volume outcomes, thereby demonstrating operational achievability of the 34.3 % savings. revision: yes
Circularity Check
No circularity: derivation chain is self-contained with independent case-study validation
full rationale
The paper first establishes a quantization-to-power model mapping configurations to dispatchable parameters, then builds a two-stage DR optimization incorporating switching/routing/precision, and finally applies multi-campus co-optimization. The 34.3% cost reduction is reported as an outcome of case studies rather than a quantity defined by or fitted to the result itself. No equations, self-citations, or steps reduce any claimed prediction to its own inputs by construction; the central empirical claim rests on external case-study execution rather than tautological re-labeling of fitted parameters or self-referential uniqueness theorems.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Energy and ai,
International Energy Agency, “Energy and ai,” International Energy Agency, Paris, France, Tech. Rep., 2025. [Online]. Available: https://www.iea.org/reports/energy-and-ai
2025
-
[2]
Five new Stargate sites,
OpenAI, “Five new Stargate sites,” 2025, accessed: 2026. [Online]. Available: https://openai.com/index/five-new-stargate-sites/
2025
-
[3]
The carbon footprint of machine learning training will plateau, then shrink,
D. Patterson, J. Gonzalez, U. Holzle, Q. Le, C. Liang, L.-M. Munguia, D. Rothchild, D. So, M. Texier, and J. Dean, “The carbon footprint of machine learning training will plateau, then shrink,”Computer, vol. 55, no. 7, pp. 18–28, 2022
2022
-
[4]
Modeling demand response capability by inter- net data centers processing batch computing jobs,
J. Li, Z. Bao, and Z. Li, “Modeling demand response capability by inter- net data centers processing batch computing jobs,”IEEE Transactions on Smart Grid, vol. 6, no. 2, pp. 737–747, 2015
2015
-
[5]
Electric demand response management for distributed large-scale internet data centers,
Z. Chen, L. Wu, and Z. Li, “Electric demand response management for distributed large-scale internet data centers,”IEEE Transactions on Smart Grid, vol. 5, no. 2, pp. 651–661, 2014
2014
-
[6]
Making data centers fit for demand response: Introducing greensda and greensla contracts,
R. Basmadjian, J. F. Botero, G. Giuliani, X. Hesselbach, S. Klingert, and H. de Meer, “Making data centers fit for demand response: Introducing greensda and greensla contracts,”IEEE Transactions on Smart Grid, vol. 9, no. 4, pp. 3453–3464, 2018
2018
-
[7]
Spatio-temporal load balancing for energy cost optimization in distributed internet data centers,
J. Luo, L. Rao, and X. Liu, “Spatio-temporal load balancing for energy cost optimization in distributed internet data centers,”IEEE Transactions on Cloud Computing, vol. 3, no. 3, pp. 387–397, 2015
2015
-
[8]
Multi-objective low-carbon scheduling method for data centers based on ensemble reinforcement learning,
Y . Wang, W. Sun, P. Ren, and G. Harrison, “Multi-objective low-carbon scheduling method for data centers based on ensemble reinforcement learning,”IEEE Transactions on Smart Grid, vol. 17, no. 1, pp. 297– 308, 2026
2026
-
[9]
Carbon- aware spatial-temporal scheduling for multiple ai data center parks with training and inference workloads characteristics,
J. Han, E. Du, B. Du, Y . Li, N. Zhang, and C. Kang, “Carbon- aware spatial-temporal scheduling for multiple ai data center parks with training and inference workloads characteristics,”IEEE Transactions on Industry Applications, pp. 1–14, 2026
2026
-
[10]
Supply restoration of data centers in flexible distribution networks with spatial- temporal regulation,
J. Jian, J. Zhao, H. Ji, L. Bai, J. Xu, P. Li, J. Wu, and C. Wang, “Supply restoration of data centers in flexible distribution networks with spatial- temporal regulation,”IEEE Transactions on Smart Grid, vol. 15, no. 1, pp. 340–354, 2024
2024
-
[11]
Unlocking spatio-temporal flexi- bility of data centers in multiple regional peer-to-peer energy transaction markets,
T. Jin, L. Bai, M. Yan, and X. Chen, “Unlocking spatio-temporal flexi- bility of data centers in multiple regional peer-to-peer energy transaction markets,”IEEE Transactions on Power Systems, vol. 40, no. 5, pp. 3914– 3927, 2025
2025
-
[12]
Agent coordination via contextual regression (AgentCON- CUR) for data center flexibility,
V . Dvorkin, “Agent coordination via contextual regression (AgentCON- CUR) for data center flexibility,”IEEE Transactions on Power Systems, vol. 40, no. 2, pp. 1832–1842, 2025
2025
-
[13]
Synergising hierarchical data centers and power networks: A privacy-preserving approach,
J. Liu, F. Teng, and F. Y . Hou, “Synergising hierarchical data centers and power networks: A privacy-preserving approach,”IEEE Transactions on Smart Grid, vol. 16, no. 6, pp. 5083–5098, 2025
2025
-
[14]
Toward optimal operation of internet data center microgrid,
J. Li and W. Qi, “Toward optimal operation of internet data center microgrid,”IEEE Transactions on Smart Grid, vol. 9, no. 2, pp. 971– 979, 2018. 10
2018
-
[15]
Distributed real-time energy management in data center microgrids,
L. Yu, T. Jiang, and Y . Zou, “Distributed real-time energy management in data center microgrids,”IEEE Transactions on Smart Grid, vol. 9, no. 4, pp. 3748–3762, 2018
2018
-
[16]
Coordinated planning of multiple energy hubs considering the spatiotemporal load regulation of data centers,
S. Zhang, J. Lyu, W. Jin, H. Cheng, C. Li, and X. Wang, “Coordinated planning of multiple energy hubs considering the spatiotemporal load regulation of data centers,”IEEE Transactions on Power Systems, vol. 39, no. 2, pp. 4193–4207, 2024
2024
-
[17]
Integrated planning of internet data centers and battery energy storage systems in smart grids,
C. Guo, F. Luo, Z. Cai, Z. Y . Dong, and R. Zhang, “Integrated planning of internet data centers and battery energy storage systems in smart grids,”Applied Energy, vol. 281, p. 116093, 2021
2021
-
[18]
Carbon-aware computing for datacenters,
A. Radovanovi ´c, R. Koningstein, I. Schneider, B. Chen, A. Duarte, B. Roy, D. Xiao, M. Haridasan, P. Hung, N. Care, S. Talukdar, E. Mullen, K. Smith, M. Cottman, and W. Cirne, “Carbon-aware computing for datacenters,”IEEE Transactions on Power Systems, vol. 38, no. 2, pp. 1270–1280, 2023
2023
-
[19]
Collaborative planning of cyber physical distribution system considering the flexibility of data centers,
S. Wu, Q. Wang, and B. Chen, “Collaborative planning of cyber physical distribution system considering the flexibility of data centers,”Energy Reports, vol. 9, no. S7, pp. 656–664, 2023
2023
-
[21]
Available: https://arxiv.org/abs/2604.05376
[Online]. Available: https://arxiv.org/abs/2604.05376
-
[22]
P. Colangelo, A. K. Coskun, J. Megrue, C. Roberts, S. Sengupta, V . Sivaram, E. Tiao, A. Vijaykar, C. Williams, D. C. Wilson, Z. MacFarland, D. Dreiling, N. Morey, A. Ratnayake, and B. Vairamohan, “Turning AI data centers into grid- interactive assets: Results from a field demonstration in Phoenix, Arizona,”arXiv preprint arXiv:2507.00909, 2025. [Online]....
arXiv 2025
-
[23]
Splitwise: Efficient generative LLM inference using phase splitting,
P. Patel, E. Choukse, C. Zhang, A. Shah, ´I. Goiri, S. Maleki, and R. Bianchini, “Splitwise: Efficient generative LLM inference using phase splitting,” in2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), 2024, pp. 118–132
2024
-
[24]
Tokenpowerbench: Benchmarking the power consumption of llm infer- ence,
C. Niu, W. Zhang, J. Li, Y . Zhao, T. Wang, X. Wang, and Y . Chen, “Tokenpowerbench: Benchmarking the power consumption of llm infer- ence,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 38, 2026, pp. 32 582–32 590
2026
-
[25]
From prompts to power: Measuring the energy footprint of LLM inference,
F. Caravaca, ´A. Cuevas, and R. Cuevas, “From prompts to power: Measuring the energy footprint of LLM inference,”arXiv preprint arXiv:2511.05597, 2025. [Online]. Available: https://arxiv.org/abs/2511 .05597
arXiv 2025
-
[26]
Providing load flexibility by reshaping power profiles of large language model workloads,
Y . Wang, Q. Guo, and M. Chen, “Providing load flexibility by reshaping power profiles of large language model workloads,”Advances in Applied Energy, vol. 19, p. 100232, 2025
2025
-
[28]
Available: https://arxiv.org/abs/2511.00807
[Online]. Available: https://arxiv.org/abs/2511.00807
-
[29]
EcoServe: Designing carbon-aware AI inference systems,
Y . Li, Z. Hu, E. Choukse, R. Fonseca, G. E. Suh, and U. Gupta, “EcoServe: Designing carbon-aware AI inference systems,”arXiv preprint arXiv:2502.05043, 2025. [Online]. Available: https://arxiv.org/ abs/2502.05043
arXiv 2025
-
[30]
SmoothQuant: Accurate and efficient post-training quantization for large language models,
G. Xiao, J. Lin, M. Seznec, H. Wu, J. Demouth, and S. Han, “SmoothQuant: Accurate and efficient post-training quantization for large language models,” inProceedings of the 40th International Con- ference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 202. PMLR, 2023, pp. 38 087–38 099
2023
-
[31]
Systematic characterization of LLM quantization: A performance, energy, and quality perspective,
T. Shi and Y . Ding, “Systematic characterization of LLM quantization: A performance, energy, and quality perspective,”arXiv preprint arXiv:2508.16712, 2025. [Online]. Available: https://arxiv.org/abs/2508 .16712
arXiv 2025
-
[32]
LLM.int8(): 8-bit matrix multiplication for transformers at scale,
T. Dettmers, M. Lewis, Y . Belkada, and L. Zettlemoyer, “LLM.int8(): 8-bit matrix multiplication for transformers at scale,” inAdvances in Neural Information Processing Systems, vol. 35. Curran Associates, Inc., 2022, pp. 30 318–30 332
2022
-
[33]
ParoQuant: Pairwise rotation quantization for efficient reasoning LLM inference,
Y . Liang, H. Chen, S. Han, and Z. Liu, “ParoQuant: Pairwise rotation quantization for efficient reasoning LLM inference,”arXiv preprint arXiv:2511.10645, 2026. [Online]. Available: https://arxiv.org/abs/2511 .10645
arXiv 2026
-
[34]
GPTQ: Accurate post-training quantization for generative pre-trained transformers,
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh, “GPTQ: Accurate post-training quantization for generative pre-trained transformers,” in International Conference on Learning Representations, 2023
2023
-
[35]
AWQ: Activation-aware weight quantiza- tion for on-device LLM compression and acceleration,
J. Lin, J. Tang, H. Tang, S. Yang, W.-M. Chen, W.-C. Wang, G. Xiao, X. Dang, C. Gan, and S. Han, “AWQ: Activation-aware weight quantiza- tion for on-device LLM compression and acceleration,” inProceedings of Machine Learning and Systems, vol. 6, 2024, pp. 87–100
2024
-
[36]
“give me bf16 or give me death
E. Kurtic, A. N. Marques, S. Pandit, M. Kurtz, and D. Alistarh, ““give me bf16 or give me death”? accuracy-performance trade-offs in llm quantization,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 26 872–26 886
2025
-
[37]
Efficient memory management for large language model serving with PagedAttention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with PagedAttention,” inACM Symposium on Operating Systems Principles (SOSP), 2023, pp. 611–626
2023
-
[38]
Characterizing power management opportunities for LLMs in the cloud,
P. Patel, E. Choukse, C. Zhang, ´I. Goiri, B. Warrier, N. Mahalingam, and R. Bianchini, “Characterizing power management opportunities for LLMs in the cloud,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3. ACM, 2024, pp. 207–222
2024
-
[39]
Roofline: An insightful visual performance model for multicore architectures,
S. Williams, A. Waterman, and D. Patterson, “Roofline: An insightful visual performance model for multicore architectures,”Communications of the ACM, vol. 52, no. 4, pp. 65–76, 2009
2009
-
[40]
Llm-inference- bench: Inference benchmarking of large language models on ai acceler- ators,
K. T. Chitty-Venkata, S. Raskar, B. Kale, F. Ferdaus, A. Tanikanti, K. Raffenetti, V . Taylor, M. Emani, and V . Vishwanath, “Llm-inference- bench: Inference benchmarking of large language models on ai acceler- ators,” inSC24-W: Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2024, pp. 1362–1379
2024
-
[41]
Achieving top inference performance with the NVIDIA H100 Tensor Core GPU and NVIDIA TensorRT- LLM,
D. Salvator and A. Eassa, “Achieving top inference performance with the NVIDIA H100 Tensor Core GPU and NVIDIA TensorRT- LLM,” NVIDIA Technical Blog, 2023. [Online]. Available: https: //developer.nvidia.com/blog/achieving-top-inference-performance-wit h-the-nvidia-h100-tensor-core-gpu-and-nvidia-tensorrt-llm/
2023
-
[42]
M. F. Argerich, J. Furst, and M. Patino-Martinez, “Watt counts: Energy- aware benchmark for sustainable LLM inference on heterogeneous GPU architectures,”arXiv preprint arXiv:2604.09048, 2026. [Online]. Available: https://arxiv.org/abs/2604.09048
Pith/arXiv arXiv 2026
-
[43]
OmniQuant: Omnidirectionally calibrated quantization for large language models,
W. Shao, M. Chen, Z. Zhang, P. Xu, L. Zhao, Z. Li, K. Zhang, G. Peng, Y . Qiao, and P. Luo, “OmniQuant: Omnidirectionally calibrated quantization for large language models,” inInternational Conference on Learning Representations, 2024
2024
-
[44]
ServerlessLLM: Low-latency serverless inference for large language models,
Y . Fu, L. Xue, Y . Huang, A.-O. Brabete, D. Ustiugov, Y . Patel, and L. Mai, “ServerlessLLM: Low-latency serverless inference for large language models,” in18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). Santa Clara, CA, USA: USENIX Association, Jul. 2024, pp. 135–153
2024
-
[45]
Carbon emission flow from generation to demand: A network-based model,
C. Kang, T. Zhou, Q. Chen, J. Wang, Y . Sun, Q. Xia, and H. Yan, “Carbon emission flow from generation to demand: A network-based model,”IEEE Transactions on Smart Grid, vol. 6, no. 5, pp. 2386–2394, 2015
2015
-
[46]
Llama 3 model card,
Meta AI, “Llama 3 model card,” 2024, accessed: 2026. [Online]. Available: https://github.com/meta-llama/llama3
2024
-
[47]
Alibaba Cloud, “Qwen2.5 technical report,”arXiv preprint arXiv:2412.15115, 2024. [Online]. Available: https://arxiv.org/abs/ 2412.15115
Pith/arXiv arXiv 2024
-
[48]
DeepSeek-AI, “DeepSeek-V3 technical report,”arXiv preprint arXiv:2412.19437, 2024. [Online]. Available: https://arxiv.org/abs/ 2412.19437
Pith/arXiv arXiv 2024
-
[49]
NVIDIA H100 Tensor Core GPU datasheet,
NVIDIA, “NVIDIA H100 Tensor Core GPU datasheet,” NVIDIA Corporation, Tech. Rep., 2023. [Online]. Available: https://www.nvidia .com/en-us/data-center/h100/
2023
-
[50]
NVIDIA DGX H100 datasheet,
——, “NVIDIA DGX H100 datasheet,” NVIDIA Corporation, Tech. Rep., 2022. [Online]. Available: https://www.nvidia.com/content/dam/e n-zz/Solutions/Data-Center/nvidia-dgx-h100-datasheet.pdf
2022
-
[51]
Empirically-calibrated h100 node power models for accurate ai training energy estimation,
A. C. Newkirk, J. Fernandez, J. Koomey, I. Latif, E. Strubell, A. Shehabi, and C. Samaras, “Empirically-calibrated h100 node power models for accurate ai training energy estimation,”Environmental Research: Energy, vol. 2, no. 4, p. 045016, 2025
2025
-
[52]
BurstGPT: A real-world workload dataset to optimize LLM serving systems,
Y . Wang, Y . Chen, Z. Li, X. Kang, Y . Fang, Y . Zhou, Y . Zheng, Z. Tang, X. He, R. Guo, X. Wang, Q. Wang, A. C. Zhou, and X. Chu, “BurstGPT: A real-world workload dataset to optimize LLM serving systems,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’25). Toronto, ON, Canada: ACM, 2025, pp. 5831–5841
2025
-
[53]
Open access same-time information system (OASIS),
California Independent System Operator, “Open access same-time information system (OASIS),” 2024, accessed: 2026. [Online]. Available: http://oasis.caiso.com/
2024
-
[54]
Demand response issues and performance 2024,
California ISO Department of Market Monitoring, “Demand response issues and performance 2024,” California Independent System Operator, Tech. Rep., Mar. 2025. [Online]. Available: https://www.caiso.com/do cuments/demand-response-issues-and-performance-2024-mar-14-2025. pdf
2024
-
[55]
Cap-and-invest program: Summary of auction settlement prices and results,
California Air Resources Board, “Cap-and-invest program: Summary of auction settlement prices and results,” 2026, accessed: 2026; 2026 auction reserve price USD 27.94/tCO 2. [Online]. Available: https://ww2.arb.ca.gov/our-work/programs/cap-and-trade-program/aucti on-information
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.