Symplecticity-preserving prediction of parameter-dependent Hamiltonian dynamics by Generalized Kernel Interpolation
Pith reviewed 2026-06-26 20:12 UTC · model grok-4.3
The pith
A product kernel ansatz produces symplectic large-step predictors for parameter-dependent Hamiltonian dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By employing a product kernel ansatz on a parameter and macro step augmented domain and constructing the prediction through an implicit symplectic-Euler-type update, the resulting large-step predictor is symplectic by construction for every fixed admissible parameter and time-step instance. The training problem is formulated as gradient Hermite-Birkhoff interpolation in a reproducing kernel Hilbert space, and the convergence analysis from the non-augmented setting carries over to yield corresponding prediction error bounds.
What carries the argument
Product kernel ansatz combined with an implicit symplectic-Euler-type update in the generalized kernel interpolation framework, ensuring symplecticity for fixed parameters.
If this is right
- The large-step predictor is symplectic by construction for any admissible fixed parameter and time-step.
- Prediction error bounds are available by direct carry-over of the non-augmented convergence analysis.
- Efficient computation is achieved through greedy center selection in the reproducing kernel Hilbert space.
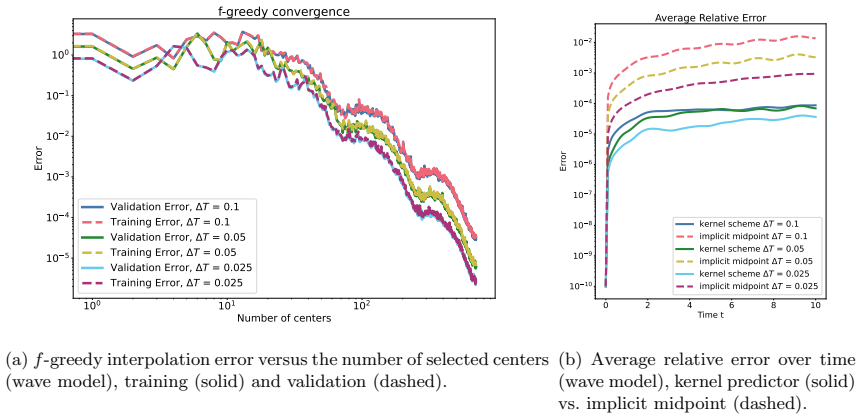
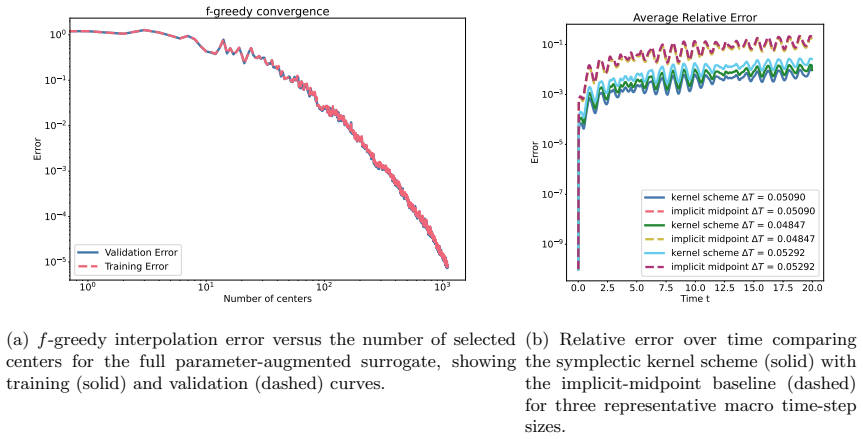
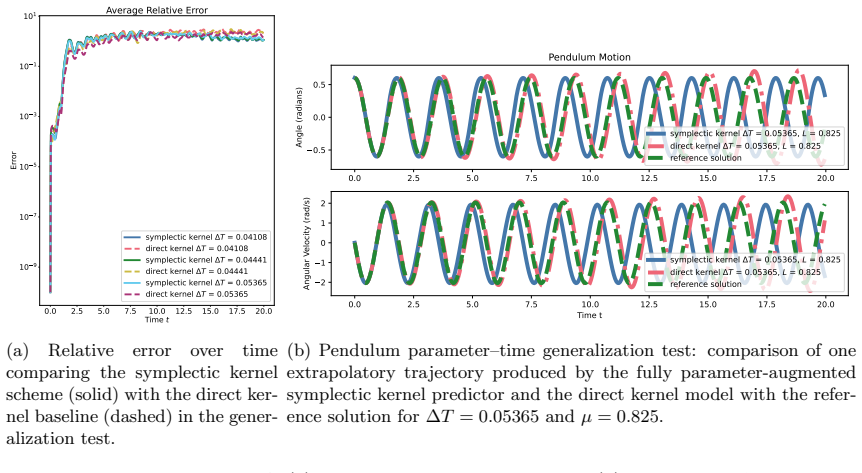
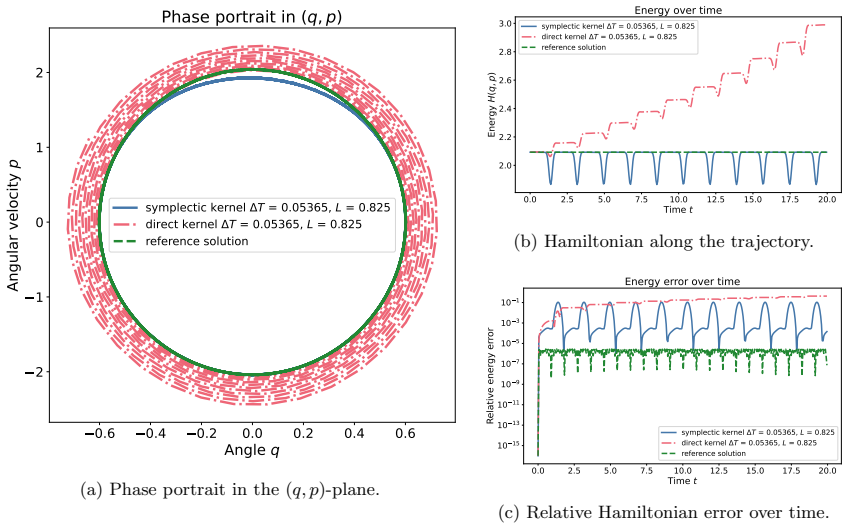
- The method applies to parameter-dependent systems such as pendulums with varying length and discretized wave equations.
Where Pith is reading between the lines
- This framework could be tested on other Hamiltonian systems with multiple parameters to verify broad applicability.
- Extensions to higher-order symplectic integrators might further improve accuracy while retaining the structure preservation.
- The approach opens possibilities for surrogate modeling in optimization or control tasks involving families of Hamiltonian systems.
Load-bearing premise
The convergence analysis from the non-augmented setting carries over to the product-kernel framework.
What would settle it
A counterexample where the learned predictor for a fixed parameter violates the symplectic condition, or where the derived error bounds fail to hold in numerical tests for the augmented case.
Figures
read the original abstract
We extend the kernel-based symplectic predictor of [1] to a parameter-augmented setting in which the learned flow-map surrogate depends not only on the state, but also on additional variables such as physical parameters and macro time-step sizes. The method uses a product kernel ansatz on a parameter and macro step augmented domain and constructs the prediction through an implicit symplectic-Euler-type update. Hence, for every fixed admissible parameter and time-step instance, the resulting large-step predictor is symplectic by construction. The training problem is formulated as gradient Hermite--Birkhoff interpolation in a reproducing kernel Hilbert space. Efficient surrogates are obtained by greedy center selection. We show that the convergence analysis from the non-augmented setting carries over to the product-kernel framework and derive corresponding prediction error bounds. Numerical experiments for a pendulum with varying length and time-step size and for a parameter-dependent discretized wave equation illustrate the accuracy and structure-preserving behavior of the proposed approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends the kernel-based symplectic predictor of [1] to parameter-dependent Hamiltonian dynamics via a product kernel on an augmented domain (state, parameters, macro time-step). Predictions are obtained from an implicit symplectic-Euler-type update on the resulting surrogate; the authors state that this construction ensures symplecticity for every fixed admissible parameter and time-step. Training is posed as gradient Hermite-Birkhoff interpolation in the RKHS, with greedy center selection for efficiency. The manuscript asserts that the convergence analysis and error bounds from the non-augmented case carry over to the product-kernel setting and illustrates the approach on a length-varying pendulum and a parameter-dependent discretized wave equation.
Significance. If the symplecticity-by-construction argument and the carry-over of error bounds are rigorously established, the work supplies a practical route to structure-preserving surrogates for parametric Hamiltonian systems. This is relevant to numerical analysis and scientific machine learning, where preserving geometric invariants while incorporating parameters is valuable for long-time integration, optimization, and uncertainty quantification. The explicit reduction to the base symplectic-Euler structure for fixed parameters is a clear methodological strength.
major comments (2)
- [Abstract / product-kernel section] Abstract and the section on the product-kernel construction: the central claim that 'the resulting large-step predictor is symplectic by construction' for fixed parameters rests on the product kernel K((x,μ),(y,ν)) = K_state(x,y)·K_param(μ,ν) reducing the implicit update to a scaled version of the non-augmented case. The manuscript must explicitly derive that the canonical equations and the symplectic form are inherited without additional restrictions; this step is load-bearing for the main theorem.
- [Convergence analysis section] The section asserting carry-over of convergence analysis: the claim that 'the convergence analysis from the non-augmented setting carries over to the product-kernel framework' and yields corresponding prediction error bounds requires an explicit verification that the RKHS norm, fill-distance constants, and approximation rates remain controlled by the parameter kernel factor. Without this argument the error-bound statement cannot be assessed.
minor comments (2)
- The notation for the product kernel and the augmented domain should be introduced with a dedicated display equation before the implicit-update formula to improve readability.
- [Numerical experiments] In the numerical experiments, the dependence of the observed error on the number of greedy centers and on the macro time-step size should be tabulated or plotted to make the claimed accuracy and structure preservation quantitative.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on the manuscript. We address the two major comments below and will revise the manuscript accordingly to strengthen the rigor of the central claims.
read point-by-point responses
-
Referee: [Abstract / product-kernel section] Abstract and the section on the product-kernel construction: the central claim that 'the resulting large-step predictor is symplectic by construction' for fixed parameters rests on the product kernel K((x,μ),(y,ν)) = K_state(x,y)·K_param(μ,ν) reducing the implicit update to a scaled version of the non-augmented case. The manuscript must explicitly derive that the canonical equations and the symplectic form are inherited without additional restrictions; this step is load-bearing for the main theorem.
Authors: We agree that an explicit derivation is required to fully substantiate the symplecticity claim. In the revised manuscript we will insert a dedicated derivation in the product-kernel section. This derivation will show step-by-step how the product-kernel ansatz reduces the implicit update, for any fixed admissible parameter and macro time-step, to a scaled instance of the original symplectic-Euler step, thereby confirming that the canonical equations and the symplectic two-form are inherited directly without further restrictions. revision: yes
-
Referee: [Convergence analysis section] The section asserting carry-over of convergence analysis: the claim that 'the convergence analysis from the non-augmented setting carries over to the product-kernel framework' and yields corresponding prediction error bounds requires an explicit verification that the RKHS norm, fill-distance constants, and approximation rates remain controlled by the parameter kernel factor. Without this argument the error-bound statement cannot be assessed.
Authors: We accept that the carry-over statement needs explicit verification. The revised convergence-analysis section will contain a detailed argument establishing that the RKHS norm of the augmented interpolant is controlled by the product structure, that the fill-distance constants remain bounded under standard assumptions on the parameter kernel, and that the approximation rates therefore carry over, yielding the stated prediction error bounds. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central claim of symplecticity by construction for fixed admissible parameters follows directly from the product kernel reducing to a scaled version of the state kernel, rendering the implicit symplectic-Euler update identical (up to scaling) to the non-augmented base method; this inheritance requires no additional fitting or external justification. The statement that convergence analysis carries over from the prior non-augmented work is a separate technical extension and is not load-bearing for the structure-preservation result. No derivation step reduces the main claim to a self-definition, fitted input renamed as prediction, or self-citation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The convergence analysis from the non-augmented setting carries over to the product-kernel framework
Reference graph
Works this paper leans on
-
[1]
R. Herkert, T. Ehring, and B. Haasdonk. Symplecticity-preserving prediction of hamilto- nian dynamics by generalized kernel interpolation.arXiv preprint arXiv:2601.18364, 2026. doi:10.48550/arXiv.2601.18364
-
[2]
T. Qin, K. Wu, and D. Xiu. Data driven governing equations approximation us- ing deep neural networks.Journal of Computational Physics, 395:620–635, 2019. doi:10.1016/j.jcp.2019.06.042
-
[3]
V. Churchill and D. Xiu. Flow map learning for unknown dynamical systems: Overview, implementation, and benchmarks.Journal of Machine Learning for Modeling and Computing, 4(2):173–201, 2023. doi:10.1615/JMachLearnModelComput.2023049717
-
[4]
N. M. Boffi, M. S. Albergo, and E. Vanden-Eijnden. How to build a consistency model: Learning flow maps via self-distillation.arXiv preprint arXiv:2505.18825, 2025. doi:10.48550/arXiv.2505.18825
-
[5]
A. C. da Silva.Lectures on Symplectic Geometry. Springer Berlin Heidelberg, Berlin, Heidel- berg, 2008. ISBN 978-3-540-45330-7. doi:10.1007/978-3-540-45330-7
-
[6]
E. Hairer, M. Hochbruck, A. Iserles, and C. Lubich. Geometric numerical integration.Ober- wolfach Reports, 3(1):805–882, 2006. doi:10.4171/OWR/2006/14
-
[7]
arXiv preprint arXiv:1906.01563 doi:10.48550/arXiv.1906.01563,arXiv:1906.01563
S. Greydanus, M. Dzamba, and J. Yosinski. Hamiltonian neural networks.Advances in Neural Information Processing Systems, 32, 2019. doi:10.48550/arXiv.1906.01563
-
[8]
T. Bertalan, F. Dietrich, I. Mezi´ c, and I. G. Kevrekidis. On learning Hamiltonian sys- tems from data.Chaos: An Interdisciplinary Journal of Nonlinear Science, 29(12), 2019. doi:10.1063/1.5128231
-
[9]
Z. Chen, J. Zhang, M. Arjovsky, and L. Bottou. Symplectic recurrent neural networks. In International Conference on Learning Representations, 2020. doi:10.48550/arXiv.1909.13334
-
[10]
P. Jin, Z. Zhang, A. Zhu, Y. Tang, and G. E. Karniadakis. SympNets: Intrinsic structure- preserving symplectic networks for identifying Hamiltonian systems.Neural Networks, 132: 166–179, 2020. doi:10.1016/j.neunet.2020.08.017
-
[11]
J. W. Burby, Q. Tang, and R. Maulik. Fast neural Poincar´ e maps for toroidal magnetic fields. Plasma Physics and Controlled Fusion, 63(2):024001, 2020. doi:10.1088/1361-6587/abcbaa
-
[12]
R. Chen and M. Tao. Data-driven prediction of general Hamiltonian dynamics via learning exactly-symplectic maps. InInternational conference on machine learning, pages 1717–1727. PMLR, 2021. doi:10.48550/arXiv.2103.05632
-
[13]
P. Horn, V. S. Ulibarrena, B. Koren, and S. P. Zwart. A generalized framework of neural networks for Hamiltonian systems.Journal of Computational Physics, 521:113536, 2024. doi:10.1016/j.jcp.2024.113536
-
[14]
P. Horn and B. Koren. Parametric generalized hamiltonian neural networks.Available at SSRN 6427896. doi:10.2139/ssrn.6427896. 16
-
[15]
K. Janik and P. Benner. Time-adaptive sympnets for separable hamiltonian systems.arXiv preprint arXiv:2509.16026, 2025. doi:10.48550/arXiv.2509.16026
-
[16]
Wendland.Scattered Data Approximation
H. Wendland.Scattered Data Approximation. Cambridge Monographs on Applied and Computational Mathematics. Cambridge University Press, Cambridge, UK, 2004. doi:10.1017/CBO9780511617539
-
[17]
K. T. Carlberg, A. Jameson, M. J. Kochenderfer, J. Morton, L. Peng, and F. D. Witherden. Recovering missing CFD data for high-order discretizations using deep neural networks and dynamics learning.J. Comput. Phys., 395:105–124, 2019. doi:10.1016/j.jcp.2019.05.041
-
[18]
F. D¨ oppel, T. Wenzel, R. Herkert, B. Haasdonk, and M. Votsmeier. Goal-Oriented Two- Layered Kernel Models as Automated Surrogates for Surface Kinetics in Reactor Simulations. Chemie Ingenieur Technik, 96:759–768, 2024. doi:10.1002/cite.202300178
-
[19]
La Rocca and H
A. La Rocca and H. Power. A double boundary collocation hermitian approach for the solution of steady state convection–diffusion problems.Computers & Mathematics with applications, 55(9):1950–1960, 2008
1950
-
[20]
De Marchi, A
S. De Marchi, A. Iske, and G. Santin. Image reconstruction from scattered radon data by weighted positive definite kernel functions.Calcolo, 55(1):2, 2018
2018
-
[21]
G. Santin and B. Haasdonk. Kernel methods for surrogate modeling. InModel Order Reduc- tion, volume 2. De Gruyter, 2021. doi:10.1515/9783110498967-009
-
[22]
D. Wirtz and B. Haasdonk. A vectorial kernel orthogonal greedy algorithm.Dolomites Research Notes on Approximation, 6:83–100, 2013. doi:10.14658/PUPJ-DRNA-2013- Special Issue-10
-
[23]
T. Wenzel, G. Santin, and B. Haasdonk. Analysis of target data-dependent greedy kernel algorithms: Convergence rates forf-,f·P- andf /P-greedy.Constructive Approximation, 57 (1):45–74, 2023. doi:10.1007/s00365-022-09592-3
-
[24]
G. Santin, T. Wenzel, and B. Haasdonk. On the optimality of target-data-dependent kernel greedy interpolation in Sobolev reproducing kernel Hilbert spaces.SIAM Journal on Numer- ical Analysis, 62(5):2249–2275, 2024. doi:10.1137/23M1587956
-
[25]
Bernard Haasdonk, Gabriele Santin, Tizian Wenzel, and Daniel Winkle. Refined rates of convergence for target-data dependent greedy generalized interpolation with sobolev kernels.Applied Mathematics Letters, 181:110005, 2026. ISSN 0893-9659. doi:https://doi.org/10.1016/j.aml.2026.110005. URLhttps://www.sciencedirect.com/ science/article/pii/S0893965926001369
-
[26]
T. Ehring and B. Haasdonk. Hermite kernel surrogates for the value function of high- dimensional nonlinear optimal control problems.Advances in Computational Mathematics, 50(3):36, 2024. doi:10.1007/s10444-024-10128-5
-
[27]
K. Albrecht and A. Iske. On the convergence of generalized kernel-based interpola- tion by greedy data selection algorithms.BIT Numerical Mathematics, 65(1):5, 2025. doi:10.1007/s10543-024-01048-3
-
[28]
Cline.Variational principles in classical mechanics
D. Cline.Variational principles in classical mechanics. University of Rochester River Campus Librarie, 2017
2017
-
[29]
Benner, W
P. Benner, W. Schilders, S. Grivet-Talocia, A. Quarteroni, G. Rozza, and L. Miguel Silveira. Model Order Reduction: Volume 2: Snapshot-Based Methods and Algorithms. De Gruyter,
-
[30]
doi:10.1515/9783110671490. 17
-
[31]
B. M. Afkham and J. S. Hesthaven. Structure preserving model reduction of parametric Hamiltonian systems.SIAM Journal on Scientific Computing, 39(6):A2616–A2644, 2017. doi:10.1137/17M1111991. 18
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.