ReSiReg: Towards Spatially Consistent Semantics in Language-Conditioned Robotic Tasks
Pith reviewed 2026-06-26 20:50 UTC · model grok-4.3
The pith
ReSiReg reconstructs VLM patch features as soft mixtures of language prototypes to enforce spatial consistency for robotic tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
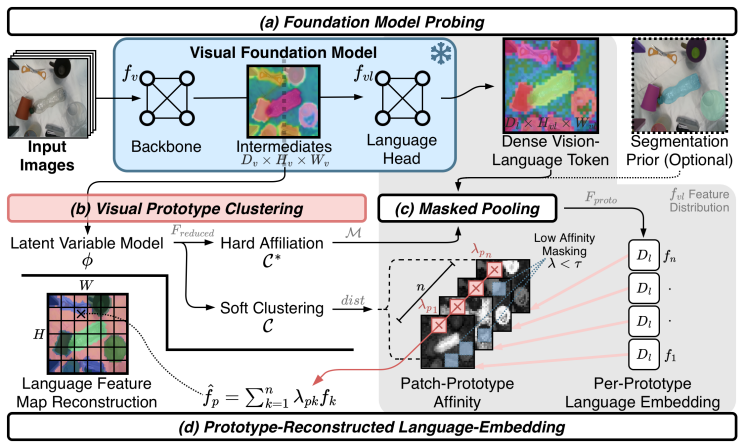
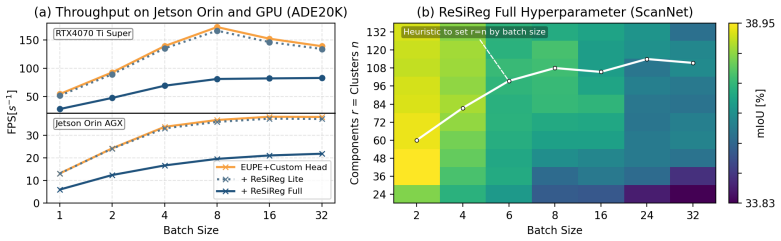
ReSiReg clusters VLM intermediates into visual prototypes, derives language descriptors for those prototypes, and reconstructs each patch embedding as a soft mixture of the prototype-level language embeddings; the resulting features raise dense language-grounded retrieval accuracy on OVSS and 3D mapping tasks, generate more spatially consistent target activations during real-world manipulation, and deliver a compact 25 M parameter dense VLM that remains competitive with ViT-B baselines.
What carries the argument
ReSiReg reconstruction: prototype clustering of VLM intermediates followed by soft-mixture language-embedding reconstruction of each patch.
If this is right
- Dense retrieval metrics rise on open-vocabulary semantic segmentation across multiple VLM backbones.
- Language-conditioned 3D mapping accuracy improves when the same reconstructed features are used.
- Activation maps for instructed objects become spatially smoother and more contiguous in real manipulation footage.
- A 25 M parameter model achieves competitive dense performance with larger ViT-B baselines.
Where Pith is reading between the lines
- The prototype reconstruction step could be inserted after any frozen VLM without retraining the original network.
- Similar consistency gains might appear in other dense prediction settings such as depth or normal estimation.
- The method supplies an explicit trade-off knob (number of prototypes) between compactness and spatial fidelity.
Load-bearing premise
VLM intermediate activations already contain recoverable spatial structure that clustering into prototypes can capture while preserving language grounding.
What would settle it
On OVSS benchmarks the reconstructed features produce equal or lower mIoU than the raw VLM features under identical evaluation protocols.
Figures


read the original abstract
Vision-Language Models (VLMs) enable robots to follow open-language instructions. However, dense VLM embeddings have shown to be noisy and lack spatial consistency. This is problematic for robotic applications, which require simultaneous reasoning over semantics and 3D space. We examine spatial structure across recent VLMs and propose ReSiReg, a feature reconstruction method that uses spatially consistent VLM intermediates to improve dense language-grounded retrieval. ReSiReg clusters intermediates into visual prototypes, derives their language descriptors, and reconstructs each patch as a soft mixture of prototype-level language embeddings. We evaluate quantitatively on OVSS and 3D mapping across backbones, and qualitatively in real-world manipulation scenes. Quantitative results show improved dense retrieval; manipulation scenes show more spatially consistent target activations. We further provide a compact 25M dense VLM for robotic applications, substantially smaller than and competitive with ViT-B baselines. Available at https://resireg.github.io
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ReSiReg, a feature reconstruction technique for dense VLM embeddings in robotic applications. It clusters VLM intermediates into visual prototypes, derives language descriptors for those prototypes, and reconstructs each image patch as a soft mixture of the prototype-level language embeddings. The method is evaluated quantitatively on open-vocabulary semantic segmentation (OVSS) and 3D mapping tasks across multiple backbones, with additional qualitative assessment in real-world manipulation scenes; a compact 25M-parameter dense VLM is also released and claimed to be competitive with ViT-B baselines.
Significance. If the reported gains in spatial consistency and retrieval accuracy hold under rigorous evaluation, the work would offer a practical route to more reliable language-grounded dense perception for robotics while reducing model size, addressing a known limitation of current VLMs in tasks that jointly require semantics and 3D structure.
major comments (2)
- [Abstract, §3] Abstract and §3: The central performance claims (improved dense retrieval on OVSS/3D mapping and spatially consistent activations) are stated without any numerical results, baselines, metrics, or statistical details in the provided text. This prevents assessment of whether the gains are load-bearing or merely incremental.
- [§4] §4 (method description): The assumption that VLM intermediates already contain recoverable spatial structure that clustering can capture is stated but not accompanied by an ablation that isolates the contribution of the soft-mixture reconstruction versus the clustering step alone; without this, it is unclear whether the reconstruction step is necessary for the claimed consistency improvement.
minor comments (2)
- The link to the project page is given but no supplementary material or code repository is referenced in the text; including these would aid reproducibility.
- [§4] Notation for the soft-mixture weights and prototype descriptors should be defined explicitly with equations rather than prose only.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3: The central performance claims (improved dense retrieval on OVSS/3D mapping and spatially consistent activations) are stated without any numerical results, baselines, metrics, or statistical details in the provided text. This prevents assessment of whether the gains are load-bearing or merely incremental.
Authors: The abstract and §3 provide a high-level overview of the approach and claims, consistent with typical paper structure. Full quantitative results—including specific metrics (mIoU on OVSS, retrieval accuracy on 3D mapping), baselines (e.g., CLIP ViT-B and other dense VLMs), and comparisons—are detailed in the Experiments section with tables and figures. To enable immediate assessment without requiring readers to reach later sections, we will revise the abstract to incorporate key numerical improvements (e.g., relative gains over baselines). This is a partial revision, as the complete experimental details and statistics remain in §5. revision: partial
-
Referee: [§4] §4 (method description): The assumption that VLM intermediates already contain recoverable spatial structure that clustering can capture is stated but not accompanied by an ablation that isolates the contribution of the soft-mixture reconstruction versus the clustering step alone; without this, it is unclear whether the reconstruction step is necessary for the claimed consistency improvement.
Authors: Clustering extracts visual prototypes from VLM intermediates, while the soft-mixture reconstruction step is required to derive prototype-level language descriptors and produce the final spatially consistent patch embeddings used for retrieval. The components are interdependent, as clustering alone does not generate the reconstructed language-grounded features. We agree an explicit ablation (e.g., hard prototype assignment without soft reconstruction) would clarify the reconstruction's necessity and will add this analysis to the revised manuscript. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes ReSiReg as a post-processing reconstruction applied to existing VLM intermediates via clustering into prototypes followed by soft-mixture language embedding reconstruction. No equations, fitted parameters, or self-citations appear in the provided text that would reduce any claimed improvement or prediction to an input quantity by construction. The method is presented as operating on prior VLM outputs with independent quantitative evaluation on OVSS/3D mapping and qualitative real-world tests; the derivation chain therefore remains self-contained against external benchmarks rather than internally tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S. Schwaiger, S. Thalhammer, W. W ¨ober, and G. Steinbauer-Wagner. Otas: Open-vocabulary token alignment for outdoor segmentation. 2025. doi:10.48550/arXiv.2507.08851. URL https://arxiv.org/abs/2507.08851
-
[2]
Alama, A
O. Alama, A. Bhattacharya, H. He, S. Kim, Y . Qiu, W. Wang, C. Ho, N. Keetha, and S. Scherer. Rayfronts: Open-set semantic ray frontiers for online scene understanding and exploration. In 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5930–5937, 2025
2025
-
[3]
Huang, C
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei. V oxposer: Composable 3d value maps for robotic manipulation with language models. InConference on Robot Learning, pages 540–562. PMLR, 2023
2023
-
[4]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. In M. Meila and T. Zhang, editors,Proceedings of the 38th Inter- national Conference on Machine Learning, volume 139 ofProceedings of Machine Lear...
2021
-
[5]
Cherti, R
M. Cherti, R. Beaumont, R. Wightman, M. Wortsman, G. Ilharco, C. Gordon, C. Schuhmann, L. Schmidt, and J. Jitsev. Reproducible scaling laws for contrastive language-image learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2818–2829, 2023
2023
-
[6]
C. Zhou, C. C. Loy, and B. Dai. Extract free dense labels from clip. In S. Avidan, G. Brostow, M. Ciss ´e, G. M. Farinella, and T. Hassner, editors,Computer Vision – ECCV 2022, pages 696–712, Cham, 2022. Springer Nature Switzerland
2022
-
[7]
Wysocza ´nska, O
M. Wysocza ´nska, O. Sim´eoni, M. Ramamonjisoa, A. Bursuc, T. Trzci´nski, and P. P´erez. Clip- dinoiser: Teaching clip a few dino tricks for open-vocabulary semantic segmentation. In A. Leonardis, E. Ricci, S. Roth, O. Russakovsky, T. Sattler, and G. Varol, editors,Computer Vision – ECCV 2024, pages 320–337, Cham, 2025. Springer Nature Switzerland
2024
-
[8]
O. Alama, D. Jariwala, A. Bhattacharya, S. Kim, W. Wang, and S. Scherer. Radseg: Unleash- ing parameter and compute efficient zero-shot open-vocabulary segmentation using agglom- erative models. 2025. doi:10.48550/arXiv.2511.19704. URLhttps://arxiv.org/abs/ 2511.19704
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.19704 2025
-
[9]
R.-Z. Qiu, G. Yang, W. Zeng, and X. Wang. Language-driven physics-based scene synthesis and editing via feature splatting. InEuropean Conference on Computer Vision (ECCV), pages 368–383, 2024
2024
-
[10]
F. Wang, J. Mei, and A. Yuille. Sclip: Rethinking self-attention for dense vision-language inference. In A. Leonardis, E. Ricci, S. Roth, O. Russakovsky, T. Sattler, and G. Varol, editors, Computer Vision – ECCV 2024, pages 315–332, Cham, 2025. Springer Nature Switzerland
2024
-
[11]
S. Bai, Y . Liu, Y . Han, H. Zhang, Y . Tang, J. Zhou, and J. Lu. Self-calibrated clip for training- free open-vocabulary segmentation.IEEE Transactions on Image Processing, 34:8271–8284, 2025. 10
2025
-
[12]
Y . Shi, M. Dong, and C. Xu. Harnessing vision foundation models for high-performance, training-free open vocabulary segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 23487–23497, October 2025
2025
-
[13]
M. Lan, C. Chen, Y . Ke, X. Wang, L. Feng, and W. Zhang. Proxyclip: Proxy attention improves clip for open-vocabulary segmentation. In A. Leonardis, E. Ricci, S. Roth, O. Russakovsky, T. Sattler, and G. Varol, editors,Computer Vision – ECCV 2024, pages 70–88, Cham, 2025. Springer Nature Switzerland
2024
-
[14]
Ranzinger, G
M. Ranzinger, G. Heinrich, J. Kautz, and P. Molchanov. Am-radio: Agglomerative vision foundation model reduce all domains into one. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12490–12500, June 2024
2024
-
[15]
Heinrich, M
G. Heinrich, M. Ranzinger, H. Yin, Y . Lu, J. Kautz, A. Tao, B. Catanzaro, and P. Molchanov. Radiov2.5: Improved baselines for agglomerative vision foundation models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22487–22497, 2025
2025
-
[16]
C. Jose, T. Moutakanni, D. Kang, F. Baldassarre, T. Darcet, H. Xu, D. Li, M. Szafraniec, M. Ramamonjisoa, M. Oquab, O. Sim ´eoni, H. V . V o, P. Labatut, and P. Bojanowski. Dinov2 meets text: A unified framework for image- and pixel-level vision-language alignment. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR...
2025
-
[17]
Bolya, P.-Y
D. Bolya, P.-Y . Huang, P. Sun, J. H. Cho, A. Madotto, C. Wei, T. Ma, J. Zhi, J. Rajasegaran, H. Rasheed, J. Wang, M. Monteiro, H. Xu, S. Dong, N. Ravi, D. Li, P. Doll ´ar, and C. Feicht- enhofer. Perception encoder: The best visual embeddings are not at the output of the network
-
[18]
Perception Encoder: The best visual embeddings are not at the output of the network
doi:10.48550/arXiv.2504.13181. URLhttps://arxiv.org/abs/2504.13181
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.13181
-
[19]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, R. Howes, P.-Y . Huang, H. Xu, V . Sharma, S.-W. Li, W. Galuba, M. Rabbat, M. Assran, N. Ballas, G. Synnaeve, I. Misra, H. J´egou, J. Mairal, P. La- batut, A. Joulin, and P. Bojanowski. Dinov2: Learning robust visual features withou...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.07193 2023
-
[20]
Vision Transformers Need Registers
T. Darcet, M. Oquab, J. Mairal, and P. Bojanowski. Vision transformers need registers. 2023. doi:10.48550/arXiv.2309.16588. URLhttps://arxiv.org/abs/2309.16588
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.16588 2023
-
[21]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, F. Massa, D. Haziza, L. Wehrstedt, J. Wang, T. Darcet, T. Moutakanni, L. Sentana, C. Roberts, A. Vedaldi, J. Tolan, J. Brandt, C. Couprie, J. Mairal, H. J´egou, P. Labatut, and P. Bojanowski. Dinov3. 2025. doi:10.48550/arXiv.2508.1...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.10104 2025
-
[22]
W ¨ober.Nonlinear and nonparametric methods for statistical shape analysis
W. W ¨ober.Nonlinear and nonparametric methods for statistical shape analysis. Doc- toral dissertation, University of Natural Resources and Life Sciences, Vienna (BOKU), Vi- enna, Austria, 2023. URLhttps://epub.boku.ac.at/obvbokhs/content/titleinfo/ 11864305
2023
-
[23]
J. Kerr, C. M. Kim, K. Goldberg, A. Kanazawa, and M. Tancik. Lerf: Language embedded radiance fields. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 19672–19682, 2023
2023
-
[24]
Yamazaki, T
K. Yamazaki, T. Hanyu, K. V o, T. Pham, M. Tran, G. Doretto, A. Nguyen, and N. Le. Open- fusion: Real-time open-vocabulary 3d mapping and queryable scene representation. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 9411–9417, 2024. 11
2024
-
[25]
Hajimiri, I
S. Hajimiri, I. Ben Ayed, and J. Dolz. Pay attention to your neighbours: Training-free open- vocabulary semantic segmentation. InProceedings of the Winter Conference on Applications of Computer Vision (WACV), pages 5061–5071, February 2025
2025
-
[26]
Y . Man, S. Zheng, Z. Bao, M. Hebert, L.-Y . Gui, and Y .-X. Wang. Lexicon3d: Probing visual foundation models for complex 3d scene understanding. InAdvances in Neural Information Processing Systems, 2024
2024
-
[27]
B. Cao, K. Chen, K.-K. Maninis, K. Chen, A. Karpur, Y . Xia, S. Dua, T. Dabral, G. Han, B. Han, J. Ainslie, A. Bewley, M. Jacob, R. Wagner, W. Ramos, K. Choromanski, M. Seyed- hosseini, H. Zhou, and A. Araujo. Tipsv2: Advancing vision-language pretraining with en- hanced patch-text alignment. 2026. doi:10.48550/arXiv.2604.12012. URLhttps://arxiv. org/abs/...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.12012 2026
-
[28]
J. Zhou, C. Wei, H. Wang, W. Shen, C. Xie, A. Yuille, and T. Kong. Image bert pre-training with online tokenizer. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[29]
M. Tschannen, A. Gritsenko, X. Wang, M. F. Naeem, I. Alabdulmohsin, N. Parthasarathy, T. Evans, L. Beyer, Y . Xia, B. Mustafa, O. H´enaff, J. Harmsen, A. Steiner, and X. Zhai. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features. 2025. doi:10.48550/arXiv.2502.14786. URLhttps://arxiv.org/abs...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.14786 2025
-
[30]
C. Zhu, S. Suri, C. Jose, M. Oquab, M. Szafraniec, W. Wen, Y . Xiong, P. Labatut, P. Bo- janowski, R. Krishnamoorthi, and V . Chandra. Efficient universal perception encoder. 2026. doi:10.48550/arXiv.2603.22387. URLhttps://arxiv.org/abs/2603.22387
-
[31]
B. Zhou, H. Zhao, X. Puig, T. Xiao, S. Fidler, A. Barriuso, and A. Torralba. Semantic under- standing of scenes through the ade20k dataset.International Journal of Computer Vision, 127 (3):302–321, Mar 2019. ISSN 1573-1405. doi:10.1007/s11263-018-1140-0
-
[32]
C. Min, J. Mei, H. Zhai, S. Wang, T. Sun, F. Kong, H. Li, F. Mao, F. Liu, S. Wang, Y . Nie, Q. Zhu, L. Xiao, D. Zhao, and Y . Hu. Advancing off-road autonomous driving: The large-scale orad-3d dataset and comprehensive benchmarks. 2025. doi:10.48550/arXiv.2510.16500. URL https://arxiv.org/abs/2510.16500
-
[33]
A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Niessner. Scannet: Richly- annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017
2017
-
[34]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015. doi:10.48550/arXiv.1503.02531
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1503.02531 2015
-
[35]
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R ¨adle, C. Rolland, L. Gustafson, E. Mintun, J. Pan, K. V . Alwala, N. Carion, C.-Y . Wu, R. Girshick, P. Doll ´ar, and C. Feichtenhofer. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. URLhttps://arxiv.org/abs/2408.00714
Pith/arXiv arXiv 2024
-
[36]
J. Ansel, E. Yang, H. He, N. Gimelshein, A. Jain, M. V oznesensky, B. Bao, P. Bell, D. Berard, E. Burovski, G. Chauhan, A. Chourdia, W. Constable, A. Desmaison, Z. DeVito, E. Ellison, W. Feng, J. Gong, M. Gschwind, B. Hirsh, S. Huang, K. Kalambarkar, L. Kirsch, M. La- zos, M. Lezcano, Y . Liang, J. Liang, Y . Lu, C. Luk, B. Maher, Y . Pan, C. Puhrsch, M. ...
arXiv 2024
-
[37]
Following [16], the loss is applied over the CLS token and an average of the patch token
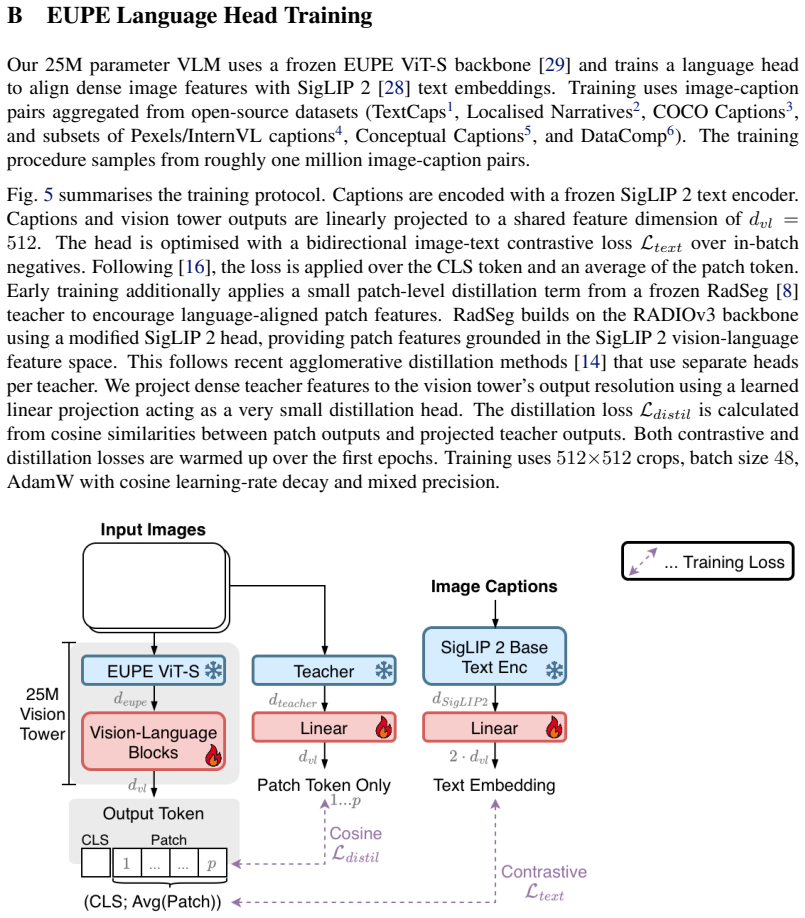
The head is optimised with a bidirectional image-text contrastive lossL text over in-batch negatives. Following [16], the loss is applied over the CLS token and an average of the patch token. Early training additionally applies a small patch-level distillation term from a frozen RadSeg [8] teacher to encourage language-aligned patch features. RadSeg build...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.