BioHarness: Substrate-Aware Evidence Assembly for Biomedical Question Answering across Literature, Knowledge Bases, and Biological Atlases
Pith reviewed 2026-06-26 18:32 UTC · model grok-4.3
The pith
BioHarness raises biomedical QA performance from 65.9 to 71.0 by escalating evidence assembly across literature, databases, and atlases only when literature falls short.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
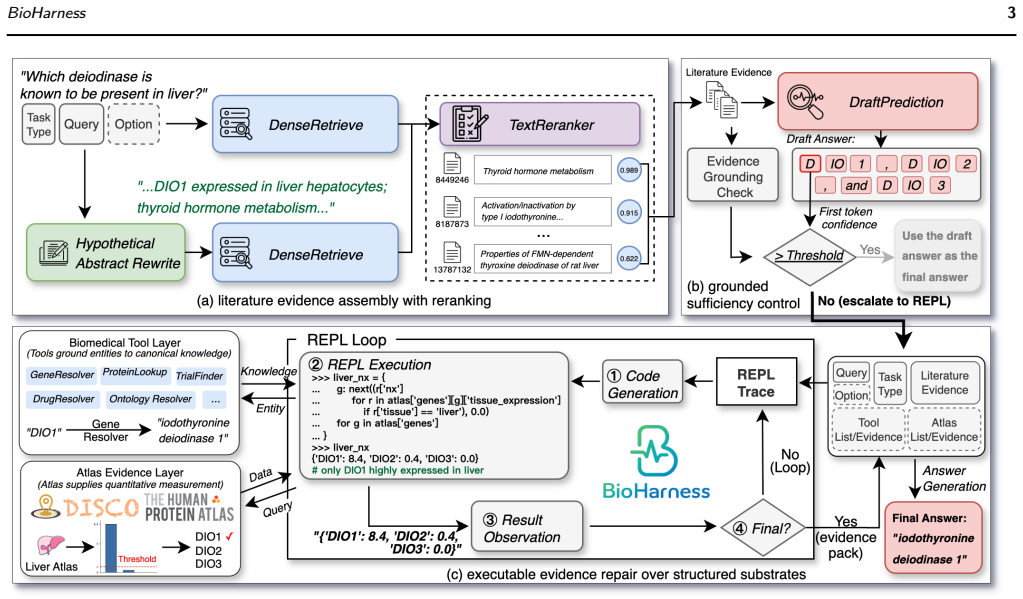
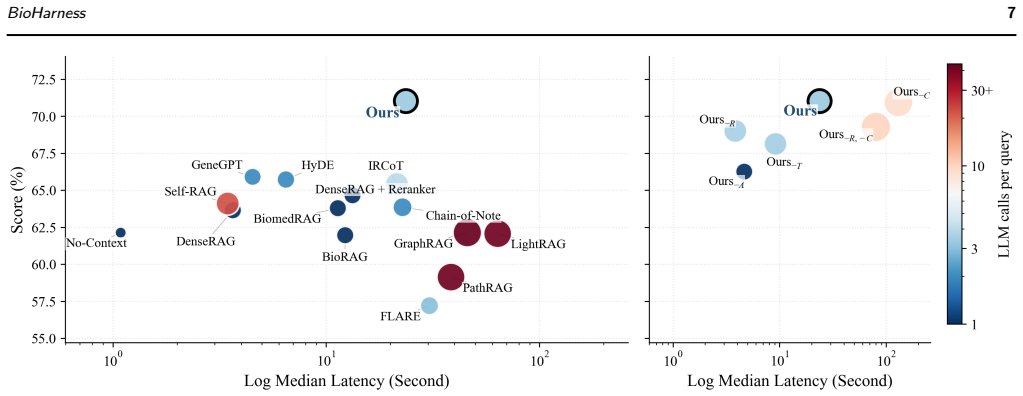
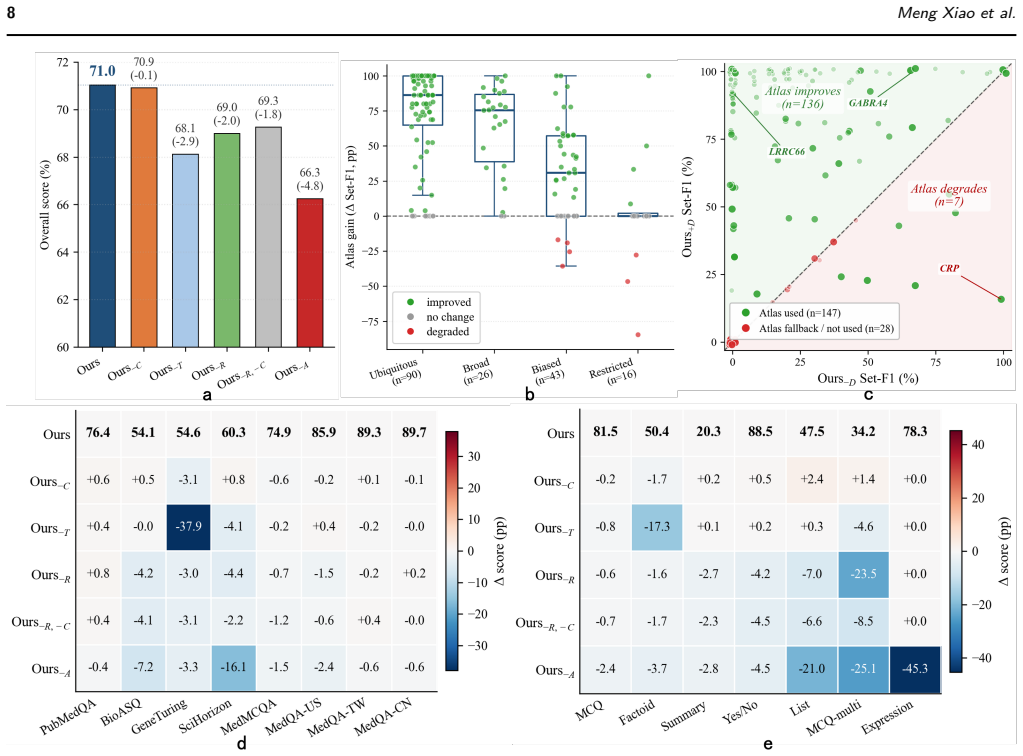
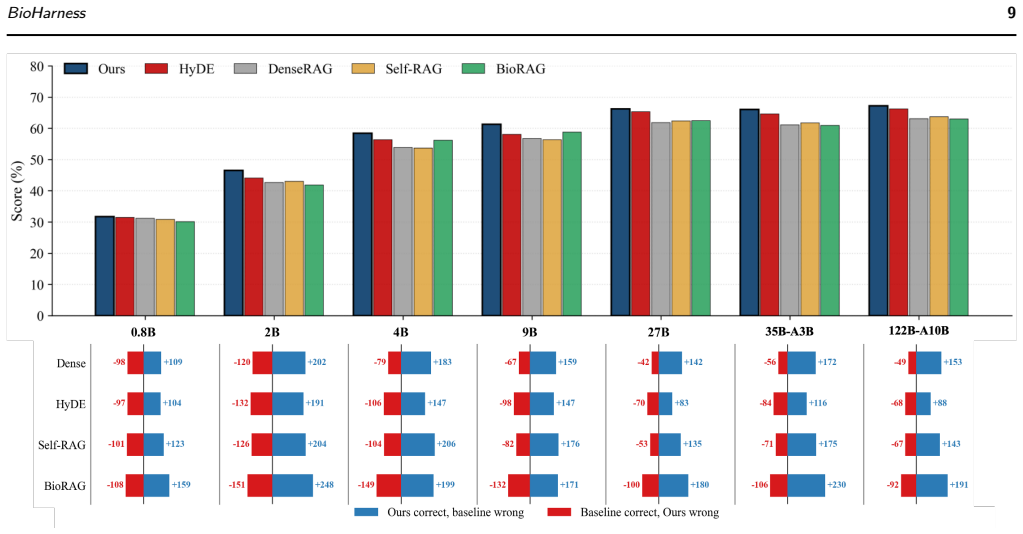
BioHarness is an LLM harness for staged biomedical evidence assembly that first attempts answers from reranked literature and escalates through grounded cascade control to REPL-style evidence assembly over curated knowledge resources or atlas-derived structured measurements only when the current evidence is uncertain, weakly grounded, or substrate-mismatched. Across 19,302 biomedical QA items spanning seven answer formats, BioHarness improves the pooled score from 65.9 to 71.0 over the strongest non-oracle baseline, with ablations showing the gains arise from repairing evidence-substrate mismatches through reranking, entity grounding, and structured measurement access.
What carries the argument
The grounded cascade control that selectively escalates from reranked literature to REPL-style assembly over knowledge bases and biological atlases when literature evidence is insufficient.
If this is right
- Gains come specifically from repairing evidence-substrate mismatches rather than from indiscriminately adding reasoning steps or retrieving more literature.
- The approach works across different backbone model scales.
- Reranking and entity grounding each contribute measurable improvements before escalation occurs.
- Performance lifts hold across seven distinct answer formats in the 19,302-item benchmark.
Where Pith is reading between the lines
- Selective escalation may reduce unnecessary computation and error accumulation in other domains that mix free text with structured data sources.
- The method implies that future biomedical QA pipelines could benefit from explicit substrate-matching checks rather than uniform retrieval pipelines.
- If cascade detection proves robust, similar staged harnesses could be tested on non-biomedical tasks where evidence quality varies sharply by source type.
Load-bearing premise
The cascade control can reliably detect when literature evidence is uncertain, weakly grounded, or substrate-mismatched and escalate without introducing new errors or selection bias in the evaluation.
What would settle it
A controlled run that disables the cascade control and forces every answer from literature retrieval alone, then checks whether the 5.1-point pooled-score gain disappears.
Figures





read the original abstract
Motivation: Biomedical question answering often requires evidence beyond topically retrieved literature, including gene alias resolution, database identifier normalization, and atlas-derived biological measurements. However, existing retrieval-augmented generation (RAG) systems typically follow a fixed workflow and lack an explicit mechanism for deciding when retrieved text is sufficient, when curated biomedical knowledge is required, or when executable evidence assembly over structured measurements should be invoked. This motivates a substrate-aware large language model (LLM) harness that selectively assembles sufficient evidence across literature, knowledge bases, and biological atlases. Results: We introduce BioHarness, an LLM harness for staged biomedical evidence assembly across literature retrieval, curated biomedical knowledge resources, and atlas-derived structured measurements. BioHarness first attempts to answer from reranked literature evidence and escalates through grounded cascade control to REPL-style evidence assembly only when the current evidence is uncertain, weakly grounded, or substrate-mismatched. Across 19,302 biomedical QA items spanning seven answer formats, BioHarness improves the pooled score from 65.9 to 71.0 over the strongest non-oracle baseline. Ablations, case studies, and backbone-scaling analyses show that these gains arise from repairing evidence-substrate mismatches through reranking, entity grounding, and structured measurement access, rather than from indiscriminately invoking more reasoning steps, retrieving additional literature, or relying on a particular answer-model scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BioHarness, an LLM-based harness for biomedical QA that performs substrate-aware staged evidence assembly: it first attempts answers from reranked literature, then escalates via cascade control to knowledge-base grounding or REPL-style structured measurements from atlases only when literature evidence is uncertain, weakly grounded, or substrate-mismatched. Across 19,302 held-out QA items spanning seven answer formats, it reports a pooled-score lift from 65.9 to 71.0 over the strongest non-oracle baseline, with ablations, case studies, and backbone-scaling analyses claimed to show that gains arise from mismatch repair rather than indiscriminate extra steps or retrieval.
Significance. If the cascade mechanism can be shown to operate without selection bias or path-dependent artifacts, the work would offer a concrete, extensible control structure for multi-substrate RAG in biomedicine, addressing a recognized limitation of fixed-workflow systems. The evaluation scale (19k items) and explicit ablation design are positive features that could support reproducible follow-up if the missing validation metrics are supplied.
major comments (2)
- [Results] Results section (pooled-score claim and ablation paragraph): The central attribution of the 5.1-point gain to substrate-aware escalation requires that the cascade correctly identifies uncertain/weakly-grounded/mismatched cases without introducing selection bias across the seven answer formats. No precision/recall figures, inter-annotator agreement on mismatch labels, or stratified deltas by cascade path (literature-only vs. escalated) are reported, leaving the mechanistic explanation unverified and load-bearing for the abstract's conclusion.
- [Evaluation] Evaluation description (baseline and controls paragraph): The strongest non-oracle baseline is referenced but its construction, hyper-parameter tuning protocol, and any controls for data leakage or post-hoc selection are not detailed; without these, it is impossible to confirm that the reported delta is not partly an artifact of baseline under-specification.
minor comments (2)
- [Abstract] Abstract and Results: The seven answer formats are named but not enumerated with example items or scoring rubrics; adding a short table would improve reproducibility.
- [Ablations] Ablations paragraph: The claim that gains do not arise from 'indiscriminately invoking more reasoning steps' would be strengthened by reporting the exact number of escalation triggers and their distribution across difficulty strata.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on our manuscript. We address the two major comments point by point below, committing to revisions that strengthen the validation of our claims.
read point-by-point responses
-
Referee: [Results] Results section (pooled-score claim and ablation paragraph): The central attribution of the 5.1-point gain to substrate-aware escalation requires that the cascade correctly identifies uncertain/weakly-grounded/mismatched cases without introducing selection bias across the seven answer formats. No precision/recall figures, inter-annotator agreement on mismatch labels, or stratified deltas by cascade path (literature-only vs. escalated) are reported, leaving the mechanistic explanation unverified and load-bearing for the abstract's conclusion.
Authors: We agree that additional metrics would better substantiate the mechanistic explanation. The manuscript relies on ablations and case studies to attribute gains to mismatch repair rather than extra steps. Since the cascade decisions are generated by the LLM without separate human annotations for mismatch labels, inter-annotator agreement is not applicable. We will revise the results section to include precision and recall for escalation decisions where possible, and stratified deltas by cascade path to demonstrate lack of selection bias. revision: yes
-
Referee: [Evaluation] Evaluation description (baseline and controls paragraph): The strongest non-oracle baseline is referenced but its construction, hyper-parameter tuning protocol, and any controls for data leakage or post-hoc selection are not detailed; without these, it is impossible to confirm that the reported delta is not partly an artifact of baseline under-specification.
Authors: We acknowledge that the baseline details are insufficiently specified in the current manuscript. In the revised version, we will expand the evaluation description to fully detail the construction of the strongest non-oracle baseline, the hyper-parameter tuning protocol used, and the controls implemented to address data leakage and post-hoc selection biases. revision: yes
Circularity Check
No significant circularity in empirical evaluation on held-out QA items
full rationale
The paper reports an empirical performance gain (65.9 to 71.0 pooled score) on 19,302 held-out biomedical QA items across seven formats, attributing it to substrate-aware cascade escalation validated by ablations. No mathematical derivation chain, self-definitional steps, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described results. The evaluation is presented as external to the system design, with gains shown to arise from specific mechanisms rather than by construction from the inputs themselves. This is a standard empirical systems paper whose central claim remains independent of its own fitted values or prior self-references.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
From local to global: A graph rag approach to query-focused summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph rag approach to query-focused summarization. arXiv preprint arXiv:2404.16130,
-
[2]
Lightrag: Simple and fast retrieval-augmented generation.arXiv preprint arXiv:2410.05779, 2(3),
Zirui Guo, Lianghao Xia, Yanhua Yu, Tian Ao, and Chao Huang. Lightrag: Simple and fast retrieval-augmented generation.arXiv preprint arXiv:2410.05779, 2(3),
-
[3]
Xiaohan Huang, Meng Xiao, Chuan Qin, Qingqing Long, Jinmiao Chen, Yuanchun Zhou, and Hengshu Zhu. Scihorizon- gene: Benchmarking llm for life sciences inference from gene knowledge to functional understanding.arXiv preprint arXiv:2601.12805,
-
[4]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.arXiv preprint arXiv:2009.13081,
arXiv 2009
-
[5]
PubMedQA: A dataset for biomedical research question answering
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. PubMedQA: A dataset for biomedical research question answering. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors,Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Proce...
2019
-
[6]
URLhttps://doi.org/10.18653/v1/D19-1259
Association for Computational Linguistics. doi: 10.18653/v1/D19-1259. URL https://aclanthology.org/D19-1259/. Qiao Jin, Zheng Yuan, Guangzhi Xiong, Qianlan Yu, Huaiyuan Ying, Chuanqi Tan, Mosha Chen, Songfang Huang, Xiaozhong Liu, and Sheng Yu. Biomedical question answering: a survey of approaches and challenges.ACM Computing Surveys (CSUR), 55(2):1–36,
-
[7]
Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221,
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield- Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221,
-
[8]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 6769–6781,
2020
-
[9]
Junyu Luo, Weizhi Zhang, Ye Yuan, Yusheng Zhao, Junwei Yang, Yiyang Gu, Bohan Wu, Binqi Chen, Ziyue Qiao, Qingqing Long, et al. Large language model agent: A survey on methodology, applications and challenges.arXiv preprint arXiv:2503.21460,
-
[10]
Squad: 100,000+ questions for machine comprehension of text
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100,000+ questions for machine comprehension of text. InProceedings of the 2016 conference on empirical methods in natural language processing, pages 2383–2392,
2016
-
[11]
Biorag: A rag-llm framework for biological question reasoning
Chengrui Wang, Qingqing Long, Meng Xiao, Xunxin Cai, Chengjun Wu, Zhen Meng, Xuezhi Wang, and Yuanchun Zhou. Biorag: A rag-llm framework for biological question reasoning. 14 Meng Xiao et al. arXiv preprint arXiv:2408.01107,
-
[12]
React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629,
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629,
-
[13]
Chain-of-note: Enhancing robustness in retrieval-augmented language models
Wenhao Yu, Hongming Zhang, Xiaoman Pan, Peixin Cao, Kaixin Ma, Jian Li, Hongwei Wang, and Dong Yu. Chain-of-note: Enhancing robustness in retrieval-augmented language models. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 14672–14685, 2024a. Yue Yu, Wei Ping, Zihan Liu, Boxin Wang, Jiaxuan You, Chao Zhang, ...
arXiv 2024
-
[14]
Large language models in biomedicine and healthcare.npj Artificial Intelligence, 1(1): 44, 2025
Juexiao Zhou, Haoyang Li, Siyuan Chen, Zhangtianyi Chen, Zhongyi Han, and Xin Gao. Large language models in biomedicine and healthcare.npj Artificial Intelligence, 1(1): 44, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.