Start Right, Arrive Right: Asynchronous Execution via Initial Noise Selection
Pith reviewed 2026-06-26 17:29 UTC · model grok-4.3
The pith
Selecting the right initial noise lets unmodified flow ODEs generate consistent action chunks for asynchronous robot control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
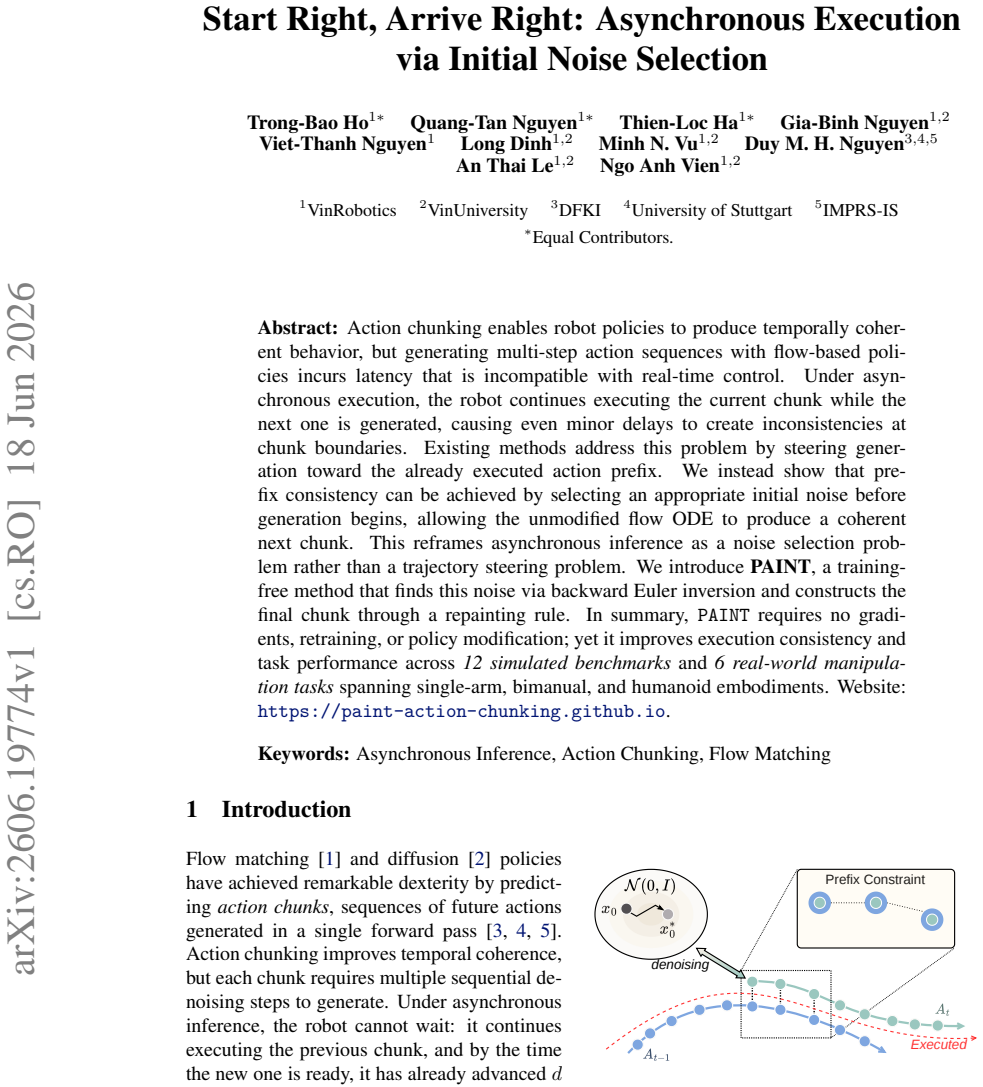
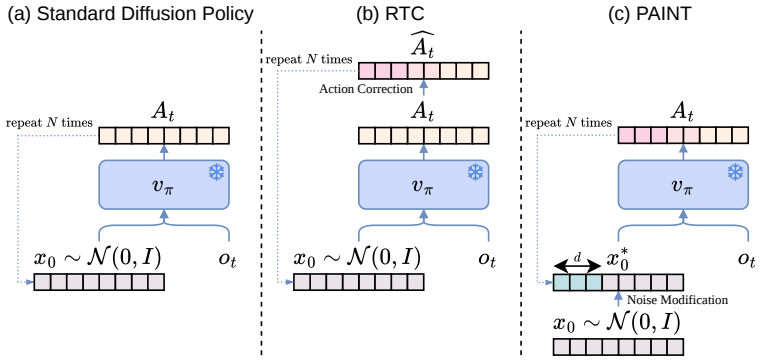
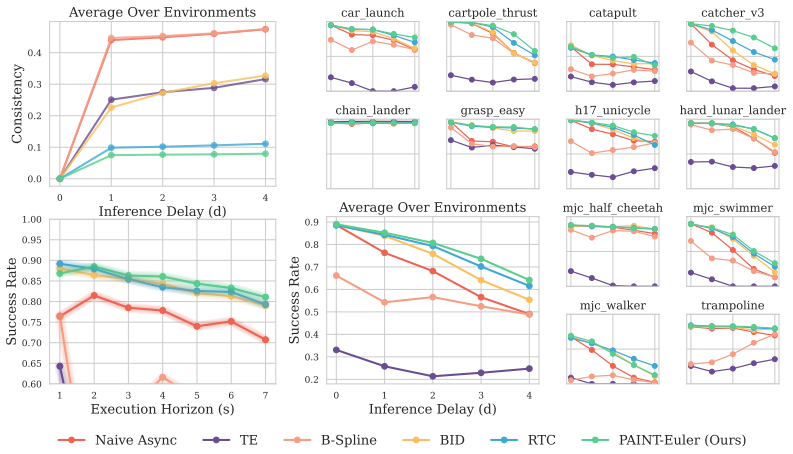
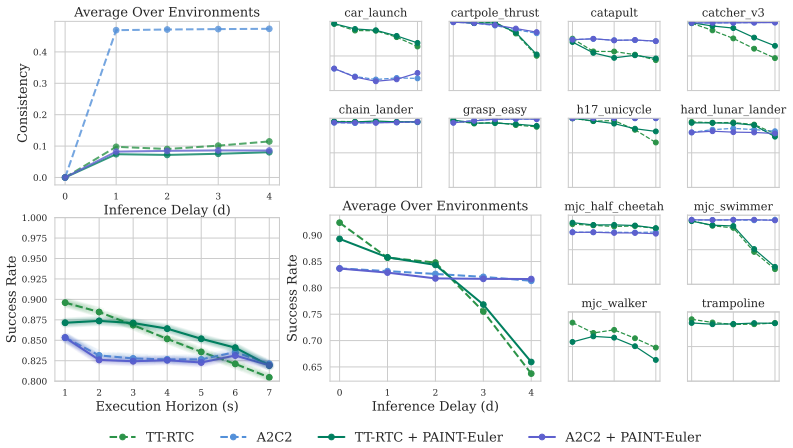
Prefix consistency can be achieved by selecting an appropriate initial noise before generation begins, allowing the unmodified flow ODE to produce a coherent next chunk. This reframes asynchronous inference as a noise selection problem rather than a trajectory steering problem. PAINT finds this noise via backward Euler inversion and constructs the final chunk through a repainting rule; it requires no gradients, retraining, or policy modification yet improves execution consistency and task performance across 12 simulated benchmarks and 6 real-world manipulation tasks.
What carries the argument
Initial noise selection via backward Euler inversion, which enables the unmodified flow ODE to maintain prefix consistency when producing the next action chunk.
If this is right
- Asynchronous execution becomes possible while keeping the original flow policy unchanged.
- Consistency and task performance improve across 12 simulated benchmarks without added computation for steering.
- The same gains appear on 6 real-world tasks spanning single-arm, bimanual, and humanoid robots.
- The method eliminates the need for gradients or policy retraining at deployment time.
Where Pith is reading between the lines
- The noise-selection view may transfer to other continuous generative models used for robot actions.
- Avoiding steering iterations could reduce control-loop latency beyond what the paper measures.
- The repainting rule might combine with other inference accelerations while preserving the core guarantee.
Load-bearing premise
An appropriate initial noise exists and can be reliably recovered via backward Euler inversion so that the unmodified flow ODE produces a coherent next chunk without steering.
What would settle it
If applying backward Euler inversion on the evaluated benchmarks yields no measurable gain in boundary consistency or task success relative to existing steering methods, the central claim would be falsified.
Figures



read the original abstract
Action chunking enables robot policies to produce temporally coherent behavior, but generating multi-step action sequences with flow-based policies incurs latency that is incompatible with real-time control. Under asynchronous execution, the robot continues executing the current chunk while the next one is generated, causing even minor delays to create inconsistencies at chunk boundaries. Existing methods address this problem by steering generation toward the already executed action prefix. We instead show that prefix consistency can be achieved by selecting an appropriate initial noise before generation begins, allowing the unmodified flow ODE to produce a coherent next chunk. This reframes asynchronous inference as a noise selection problem rather than a trajectory steering problem. We introduce \textbf{PAINT}, a training-free method that finds this noise via backward Euler inversion and constructs the final chunk through a repainting rule. In summary, \texttt{PAINT} requires no gradients, retraining, or policy modification; yet it improves execution consistency and task performance across \textit{12 simulated benchmarks} and \textit{6 real-world manipulation tasks} spanning single-arm, bimanual, and humanoid embodiments. Website: ~\href{https://paint-action-chunking.github.io}{\texttt{https://paint-action-chunking.github.io}}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that asynchronous execution of action chunks from flow-based robot policies can achieve prefix consistency at chunk boundaries by selecting an appropriate initial noise via backward Euler inversion, rather than steering the generation process. This allows the unmodified flow ODE to produce a coherent next chunk. The authors introduce the training-free PAINT method, which uses this inversion and a repainting rule to construct the chunk. They report improved execution consistency and task performance on 12 simulated benchmarks and 6 real-world manipulation tasks across single-arm, bimanual, and humanoid robots.
Significance. If the central claim holds, the work reframes asynchronous inference as an initial-noise selection problem instead of trajectory steering. This could simplify real-time control implementations by avoiding policy modifications, gradients, or retraining. The training-free aspect and evaluation spanning simulation and real hardware across multiple embodiments would indicate practical utility for flow-based policies in robotics.
major comments (2)
- [Abstract / Method description] The central claim (abstract) that backward Euler inversion recovers an initial noise such that the unmodified flow ODE produces a next chunk whose initial segment is consistent with the executed prefix within control tolerances is load-bearing. Backward Euler is first-order; without a quantitative error analysis or bounds on truncation error accumulation in high-dimensional action spaces (as raised by the stress-test note), it is unclear whether the recovered noise guarantees coherence without implicit steering.
- [Abstract] The abstract states that the repainting rule constructs the final chunk and removes dependence on accurate inversion, but provides no derivation or pseudocode showing how repainting interacts with the inverted noise to enforce prefix consistency. This interaction is required to support the claim that the method avoids steering entirely.
minor comments (2)
- [Abstract] The abstract mentions improvements across 12 simulated benchmarks and 6 real tasks but does not specify the metrics, baselines, or statistical significance (e.g., error bars or p-values) used to support the performance claims.
- No mention of code or data release; adding a reproducibility statement would strengthen the training-free claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Method description] The central claim (abstract) that backward Euler inversion recovers an initial noise such that the unmodified flow ODE produces a next chunk whose initial segment is consistent with the executed prefix within control tolerances is load-bearing. Backward Euler is first-order; without a quantitative error analysis or bounds on truncation error accumulation in high-dimensional action spaces (as raised by the stress-test note), it is unclear whether the recovered noise guarantees coherence without implicit steering.
Authors: We agree that the first-order accuracy of backward Euler warrants explicit discussion of truncation error, especially in high-dimensional action spaces. The manuscript provides extensive empirical validation across 12 simulated and 6 real-world tasks showing that the recovered noise yields prefix-consistent chunks within control tolerances when paired with the repainting rule. To address the concern directly, we will add a new subsection in the Methods that derives a practical error bound based on the Lipschitz continuity of the learned velocity field and includes numerical stress tests on error accumulation over typical chunk lengths. revision: yes
-
Referee: [Abstract] The abstract states that the repainting rule constructs the final chunk and removes dependence on accurate inversion, but provides no derivation or pseudocode showing how repainting interacts with the inverted noise to enforce prefix consistency. This interaction is required to support the claim that the method avoids steering entirely.
Authors: The full derivation of the repainting rule, its interaction with the inverted noise, and the supporting pseudocode appear in Section 3.2 and Algorithm 1. Briefly, after integrating the unmodified flow ODE from the inverted noise, the rule overwrites the initial segment of the resulting chunk with the executed prefix; this step enforces consistency without altering the ODE itself. We will revise the abstract to include one sentence summarizing this interaction so that the high-level claim is self-contained. revision: yes
Circularity Check
No circularity: method is a training-free inversion procedure validated empirically on external benchmarks
full rationale
The paper reframes asynchronous chunking as an initial-noise selection problem solved by backward Euler inversion plus a repainting rule (PAINT). The central claim is that this unmodified-ODE procedure yields prefix-consistent chunks; this is presented as an algorithmic construction whose correctness is assessed via task success rates on 12 simulated and 6 real-world benchmarks rather than by any definitional equivalence, fitted-parameter renaming, or self-citation chain. No equations reduce the output to the input by construction, and the method is explicitly training-free with no learned parameters tuned to the target consistency metric.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lipman, R
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. In11th International Conference on Learning Representations, ICLR 2023, 2023
2023
-
[2]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[3]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
Pith/arXiv arXiv 2023
-
[4]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[5]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[6]
K. Black, M. Y . Galliker, and S. Levine. Real-time execution of action chunking flow policies. arXiv preprint arXiv:2506.07339, 2025
Pith/arXiv arXiv 2025
- [7]
-
[8]
J. Tang, Y . Sun, Y . Zhao, S. Yang, Y . Lin, Z. Zhang, J. Hou, Y . Lu, Z. Liu, and S. Han. Vlash: Real-time vlas via future-state-aware asynchronous inference.arXiv preprint arXiv:2512.01031, 2025
arXiv 2025
-
[9]
Y . Liu, J. I. Hamid, A. Xie, Y . Lee, M. Du, and C. Finn. Bidirectional decoding: Improving action chunking via closed-loop resampling.arXiv preprint arXiv:2408.17355, 2024
arXiv 2024
-
[10]
J. Mao, X. Wang, and K. Aizawa. Guided image synthesis via initial image editing in diffusion model. InProceedings of the 31st ACM International Conference on Multimedia, pages 5321– 5329, 2023
2023
-
[11]
A. Tong, K. Fatras, N. Malkin, G. Huguet, Y . Zhang, J. Rector-Brooks, G. Wolf, and Y . Bengio. Improving and generalizing flow-based generative models with minibatch optimal transport. arXiv preprint arXiv:2302.00482, 2023
Pith/arXiv arXiv 2023
-
[12]
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[13]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
Pith/arXiv arXiv 2025
-
[14]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[15]
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi, C. Pascal, M. Russi, A. Marafioti, et al. Smolvla: A vision-language-action model for afford- able and efficient robotics.arXiv preprint arXiv:2506.01844, 2025. 9
Pith/arXiv arXiv 2025
-
[16]
S. H. Høeg, Y . Du, and O. Egeland. Streaming diffusion policy: Fast policy synthesis with variable noise diffusion models.arXiv preprint arXiv:2406.04806, 2024
arXiv 2024
-
[17]
Jiang, X
S. Jiang, X. Fang, N. Roy, T. Lozano-P ´erez, L. P. Kaelbling, and S. Ancha. Streaming flow policy: Simplifying diffusion/flow policies by treating action trajectories as flow trajectories. InICRA 2025 Workshop: Beyond Pick and Place, 2025
2025
- [18]
-
[19]
N. R. Arachchige, Z. Chen, W. Jung, W. C. Shin, R. Bansal, P. Barroso, Y . H. He, Y . C. Lin, B. Joffe, S. Kousik, et al. Sail: Faster-than-demonstration execution of imitation learning policies.arXiv preprint arXiv:2506.11948, 2025
arXiv 2025
-
[20]
Y . Lu, Z. Liu, X. Fan, Z. Yang, J. Hou, J. Li, K. Ding, and H. Zhao. Faster: Rethinking real-time flow vlas.arXiv preprint arXiv:2603.19199, 2026
Pith/arXiv arXiv 2026
-
[21]
F. Yang, P. Jing, K. Qu, N. Zhao, and Y . Su. Abpolicy: Asynchronous b-spline flow policy for real-time and smooth robotic manipulation.International Conference on Robotics and Automation (ICRA), 2026
2026
-
[22]
P. Wang, K. Hong, C. Peng, K. Driggs-Campbell, M. Tomizuka, C. Xu, and C. Tang. Dis- cretertc: Discrete diffusion policies are natural asynchronous executors.arXiv preprint arXiv:2604.25050, 2026
Pith/arXiv arXiv 2026
-
[23]
A. Agouzoul. Understanding asynchronous inference methods for vision-language-action models.arXiv preprint arXiv:2605.08168, 2026
Pith/arXiv arXiv 2026
-
[24]
J. Mao, X. Wang, and K. Aizawa. The lottery ticket hypothesis in denoising: Towards semantic-driven initialization. InEuropean Conference on Computer Vision, pages 93–109. Springer, 2024
2024
-
[25]
O. Patil, O. Biza, T. Weng, K. Schmeckpeper, W. Thomason, X. Zhang, R. Walters, N. Gopalan, S. Castro, and E. Rosen. You’ve got a golden ticket: Improving generative robot policies with a single noise vector.arXiv preprint arXiv:2603.15757, 2026
Pith/arXiv arXiv 2026
-
[26]
Wagenmaker, Y
A. Wagenmaker, Y . Zhang, M. Nakamoto, S. Park, W. Yagoub, A. Nagabandi, A. Gupta, and S. Levine. Steering your diffusion policy with latent space reinforcement learning. In9th Annual Conference on Robot Learning, 2025
2025
-
[27]
Y . Duan, H. Yin, and D. Kragic. Real-time iteration scheme for diffusion policy.arXiv preprint arXiv:2508.05396, 2025
arXiv 2025
-
[28]
J. Jia, G. Li, X. Chen, T. An, Y . Hu, J. Li, X. Guo, and J. Yang. Action-to-action flow matching. arXiv preprint arXiv:2602.07322, 2026
Pith/arXiv arXiv 2026
-
[29]
J. Lu, X. Qin, Y . Jiang, K. Wang, C. Zhang, B. Liang, J. Yang, M. Xu, and L. Zhao. Unified noise steering for efficient human-guided VLA adaptation.arXiv preprint arXiv:2605.10821, 2026
Pith/arXiv arXiv 2026
-
[30]
J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models. InInternational Con- ference on Learning Representations, 2021
2021
-
[31]
Meiri, D
B. Meiri, D. Samuel, N. Darshan, G. Chechik, S. Avidan, and R. Ben-Ari. Fixed-point inver- sion for text-to-image diffusion models.arXiv e-prints, pages arXiv–2312, 2023
2023
-
[32]
Z. Pan, R. Gherardi, X. Xie, and S. Huang. Effective real image editing with accelerated iterative diffusion inversion. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15912–15921, 2023. 10
2023
-
[33]
Zhang, J
G. Zhang, J. P. Lewis, and W. B. Kleijn. Exact diffusion inversion via bidirectional integration approximation. InEuropean Conference on Computer Vision, pages 19–36. Springer, 2024
2024
-
[34]
S. Hong, K. Lee, S. Y . Jeon, H. Bae, and S. Y . Chun. On exact inversion of dpm-solvers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7069–7078, 2024
2024
-
[35]
Z. Li, S. Tang, and N. Azizan. Reverse flow matching: A unified framework for online rein- forcement learning with diffusion and flow policies.arXiv preprint arXiv:2601.08136, 2026
Pith/arXiv arXiv 2026
-
[36]
Y . Lipman, M. Havasi, P. Holderrieth, N. Shaul, M. Le, B. Karrer, R. T. Chen, D. Lopez-Paz, H. Ben-Hamu, and I. Gat. Flow matching guide and code.arXiv preprint arXiv:2412.06264, 2024
Pith/arXiv arXiv 2024
-
[37]
Matthews, M
M. Matthews, M. Beukman, C. Lu, and J. N. Foerster. Kinetix: Investigating the training of general agents through open-ended physics-based control tasks. InThe Thirteenth Interna- tional Conference on Learning Representations, 2025
2025
-
[38]
I. O. Tolstikhin, N. Houlsby, A. Kolesnikov, L. Beyer, X. Zhai, T. Unterthiner, J. Yung, A. Steiner, D. Keysers, J. Uszkoreit, et al. Mlp-mixer: An all-mlp architecture for vision. Advances in neural information processing systems, 34:24261–24272, 2021
2021
-
[39]
Z. Fu, T. Z. Zhao, and C. Finn. Mobile aloha: Learning bimanual mobile manipulation with low-cost whole-body teleoperation.arXiv preprint arXiv:2401.02117, 2024
Pith/arXiv arXiv 2024
-
[40]
J. Song, A. Vahdat, M. Mardani, and J. Kautz. Pseudoinverse-guided diffusion models for inverse problems. InInternational conference on learning representations, 2023
2023
-
[41]
C. Pan, G. Anantharaman, N.-C. Huang, C. Jin, D. Pfrommer, C. Yuan, F. Permenter, G. Qu, N. Boffi, G. Shi, et al. Much ado about noising: Dispelling the myths of generative robotic control.arXiv preprint arXiv:2512.01809, 2025
arXiv 2025
-
[42]
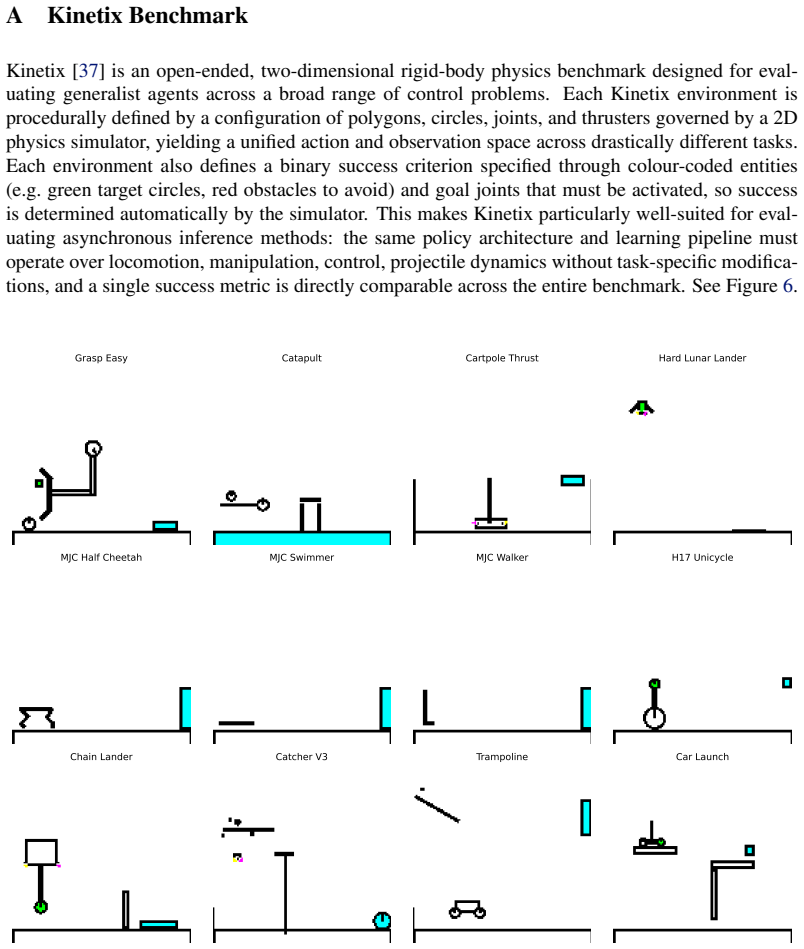
X. Ye, R. H. Yang, J. Jin, Y . Li, and A. Rasouli. Ra-dp: Rapid adaptive diffusion policy for training-free high-frequency robotics replanning. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 6227–6234. IEEE, 2025. 11 Appendix Contents A Kinetix Benchmark 13 A.1 Baseline Details . . . . . . . . . . . . . . . . . . ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.